文章目录
- 3 种绘制密度图方法对比
- 多组数据、同一个核函数
- 渐变颜色填充
- “山脊”图
- 同一坐标系中多个密度图的绘制
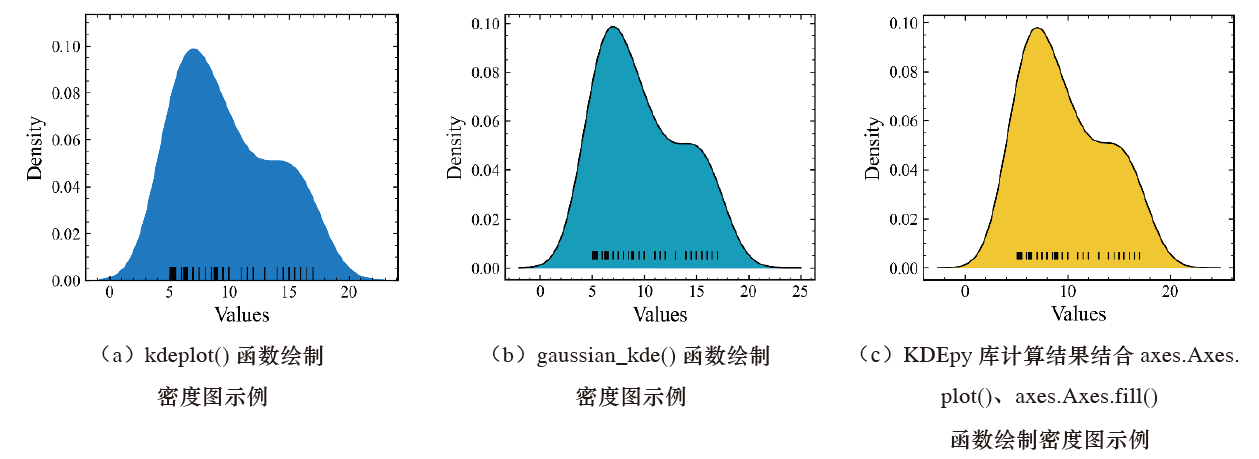
Seaborn 的 kdeplot() 函数是 Python 中绘制密度图的方式之一,Matplotlib 在现阶段则没有具体的绘制密度图的函数,一般是结合 Scipy 库中的 gaussian_kde() 函数结果进行绘制。
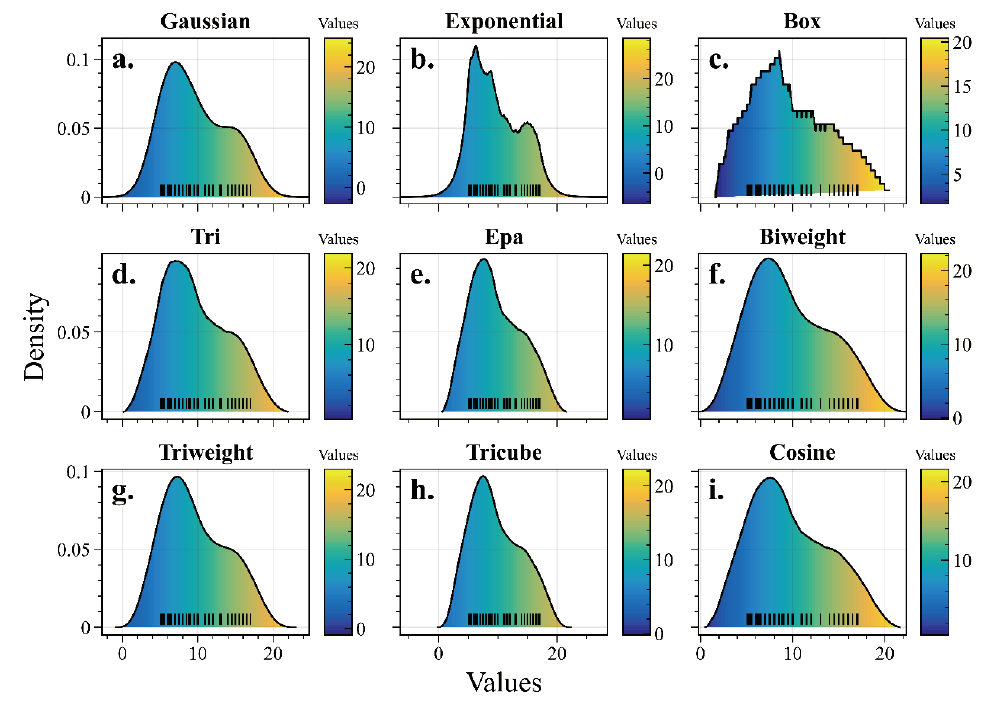
Python 的 scikit-learn 库中 neighbors.KernelDensity () 模块提供 Gaussian、Tophat、Epanechnikov、Exponential、Linear 和 Cosine 6 种核函数来进行核密度估计计算。Python 的 KDEpy 库更是提供了多达 9 种核函数,包括 Gaussian、Exponential、Box、Tri、Epa、Biweight、Triweight、Tricube、
Cosine。
KDEpy 库中的 9 种核函数示意图如下所示:

3 种绘制密度图方法对比
下面使用 Seaborn 中的 kdeplot () 函数、Scipy 库中的 gaussian_kde () 函数,以及 KDEpy 库的计算结果结合 Matplotlib 中的 axes.Axes.Plot()、axes.Axes.Fill () 函数 3 种方法分别绘制密度图。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["font.family"] = "Times New Roman"
plt.rcParams["xtick.minor.visible"] = True
plt.rcParams["ytick.minor.visible"] = True
plt.rcParams["xtick.direction"] = "in"
plt.rcParams["ytick.direction"] = "in"
plt.rcParams["xtick.labelsize"] = 12
plt.rcParams["ytick.labelsize"] = 12#构建数据集
data_01 = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]data_02 = [5.1,5.2,5.3,5.4,5.5,6.0,7.0,7.3,7.4,7.5,8.0,8.2,8.4,8.6,8.8,9.0,9.2,9.4,9.6,9.8,10,10.2,11,11.5,12,12.5,13,13.5,15,16]
data_03 = [5.1,5.2,5.3,5.4,5.6,6.0,6.1,6.2,6.4,6.8,7.1,8.2,8.8,9.0,9.2,10.2,10.4,10.8,11,11.6,12,12.4,12.6,12.8,13,13.2,13.4,13.6,13.7,13.8]data_04 = [5.0,5.2,5.3,5.4,5.6,5.8,6.0,6.2,6.4,6.6,6.8,7.0,7.2,7.4,7.6,8.0,9.0,9.2,9.6,9.8,10,10.3,11,12,16,16,18,18.5,19,22]
data_df = pd.DataFrame({"data_01":data_01,"data_02":data_02,"data_03":data_03,"data_04":data_04})#(a) kdeplot()函数绘制密度图示例
fig,ax = plt.subplots(figsize=(4,3.5),dpi=100,facecolor="w")
kde_01 = sns.Kdeplot (x="data_01", data=data_df, color=" #1180D5 ", alpha=1, shade=True, ax=ax)
Sns.Rugplot (data=data_df, x="data_01", color='k', height=. 05, ax=ax)
Ax. Set_xlabel ("Values")
Ax. Set_ylabel ("Density")Plt.Show ()#(b) gaussian_kde ()函数绘制密度图示例
From scipy import stats
Density = stats. Kde. Gaussian_kde (data_01)
X = np.Linspace (-2,25,500)
Y = density (x)Fig, ax = plt.Subplots (figsize=(4,3.5), dpi=100, facecolor="w")
Ax.Plot (x, y, lw=1, color="k")
ax.Fill (x, y, color=" #07A6C5 ")
# 添加单独数据
Ax.Plot (data_01, [0.005]*len (data_01), '|', color='k', lw=1)
Ax. Set_xlabel ("Values")
Ax. Set_ylabel ("Density")
Plt.Show ()#(c) KDEpy 库计算结果结合 axes.Axes.Plot ()、axes.Axes.Fill ()函数绘制密度图示例
From KDEpy import FFTKDE
X, y = FFTKDE (kernel="gaussian", bw=2). Fit (data_01). Evaluate ()Fig, ax = plt.Subplots (figsize=(4,3.5), dpi=100, facecolor="w")
Ax.Plot (x, y, lw=1, color="k",)
ax.Fill (x, y, color=" #FBCD2D ")
# 添加单独数据、
Ax.Plot (data_01, [0.005]*len (data_01), '|', color='k', lw=1)
Ax. Set_xlabel ("Values")
Ax. Set_ylabel ("Density")
Plt.Show ()
使用 Seaborn 中的 kdeplot () 函数绘制密度图较为简单,结合 rugplot () 函数可以绘制沿 X 轴的数据分布情况。其他两种方法较 kdeplot () 函数麻烦一些,但这两种方法绘制出的密度图更为清楚。
注意,这里的核密度估计结果都是通过高斯核函数得到的。
多组数据、同一个核函数
对于具有不同数值分布情况的多组样本数据,我们经常使用同一个核函数对它进行拟合并将结果绘制成密度图。这种情况一般发生在数据探索阶段,上述方法常用于查看每个维度数据的分布情况或对不同数据间的差异进行对比。
下面为 Matplotlib 绘制的多组样本数据使用同一个核函数的核密度图,展示了不同数据的分布情况。

import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams["font.family"] = "Times New Roman"
plt.rcParams["xtick.minor.visible"] = True
plt.rcParams["ytick.minor.visible"] = True
plt.rcParams["xtick.direction"] = "in"
plt.rcParams["ytick.direction"] = "in"
plt.rcParams["xtick.labelsize"] = 12
plt.rcParams["ytick.labelsize"] = 12#构建数据集
data_01 = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]data_02 = [5.1,5.2,5.3,5.4,5.5,6.0,7.0,7.3,7.4,7.5,8.0,8.2,8.4,8.6,8.8,9.0,9.2,9.4,9.6,9.8,10,10.2,11,11.5,12,12.5,13,13.5,15,16]
data_03 = [5.1,5.2,5.3,5.4,5.6,6.0,6.1,6.2,6.4,6.8,7.1,8.2,8.8,9.0,9.2,10.2,10.4,10.8,11,11.6,12,12.4,12.6,12.8,13,13.2,13.4,13.6,13.7,13.8]data_04 = [5.0,5.2,5.3,5.4,5.6,5.8,6.0,6.2,6.4,6.6,6.8,7.0,7.2,7.4,7.6,8.0,9.0,9.2,9.6,9.8,10,10.3,11,12,16,16,18,18.5,19,22]
data_df = pd.DataFrame({"data_01":data_01,"data_02":data_02,"data_03":data_03,"data_04":data_04})nrow = 2
ncol = 2
ax_label = ["a.","b.","c.","d."]
titles = ["Type One","Type Two","Type Three","Type Four"]
indexs = [i for i in data_df.columns] fig,axs = plt.subplots(nrow,ncol,figsize=(5,4),dpi=100,facecolor="w",sharey=True,sharex=True,constrained_layout=True)
for ax, index,label in zip(axs.flat, indexs,ax_label):x,y = NaiveKDE(kernel="Gaussian",bw=2).fit(data_df[index].values).evaluate()ax.plot(x,y, lw=1,color="#1BB71B")ax.fill(x,y,color="#1BB71B",alpha=.6)# 添加单独数据、ax.plot(data_df[index].values, [0.005]*len(data_df[index].values), '|', color='k',lw=1)ax.text(0.05, 0.95, label, transform=ax.transAxes,fontsize=16, fontweight='bold', va='top')ax.text(0.65, 0.95, index,transform=ax.transAxes,fontsize=14, fontweight='bold', va='top')
fig.supxlabel('Values')
fig.supylabel('Density')
plt.show()
针对同一组样本数据使用不同核函数计算并绘制核密度图结果的操作,更倾向于研究不同的核函数,涉及的内容很单一。
下图为对同一组数据使用不同核函数绘制的核密度图结果。

import numpy as np
import pandas as pd
import seaborn as sns
import proplot as pplt
from KDEpy import NaiveKDE
import matplotlib.pyplot as plt
from proplot import rcrc["axes.labelsize"] = 15
rc['tick.labelsize'] = 12
rc["suptitle.size"] = 16
rc["font.family"] = "Times New Roman"kde_kernels = NaiveKDE._available_kernels.keys()
fig, axs = pplt.subplots(ncols=3, nrows=3,refwidth=1.5,refheight=1.2)
axs.format(abc='a.', abcloc='ul',abcsize=15,xlabel='Values', ylabel='Density',
)
for ax, kernel in zip(axs,kde_kernels):x,y = NaiveKDE(kernel=kernel,bw=2).fit(data_01).evaluate()ax.plot(x,y, lw=1,color="#DB3132")ax.fill(x,y,color="#DB3132",alpha=.6)# 添加单独数据、ax.plot(data_01, [0.005]*len(data_01), '|', color='k',lw=.5)ax.format(title=str.capitalize(kernel),titleweight='bold',titlesize=12)
plt.show()
渐变颜色填充
为了更好的视觉效果,需要对绘制密度图的原始数据值进行颜色映射,即用一个连续渐变颜色条表示具体的绘图数值,且对应颜色填充在密度图曲线范围内。这里需要通过自定义绘制方式实现该效果。
下图展示利用 Matplotlib、ProPlot、SciencePlots 库分别绘制的带渐变颜色(gradient color)填充的密度图。

import numpy as np
import pandas as pd
from KDEpy import FFTKDE
from colormaps import parula#构建数据集
data_01 = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]#(a)利用Matplotlib绘制的带渐变颜色填充的密度图
import matplotlib.pyplot as plt
from matplotlib.axes import Axesplt.rcParams["font.family"] = "Times New Roman"
plt.rcParams["axes.linewidth"] = 1
plt.rcParams["axes.labelsize"] = 15
plt.rcParams["xtick.minor.visible"] = True
plt.rcParams["ytick.minor.visible"] = True
plt.rcParams["xtick.direction"] = "in"
plt.rcParams["ytick.direction"] = "in"
plt.rcParams["xtick.labelsize"] = 12
plt.rcParams["ytick.labelsize"] = 12
plt.rcParams["xtick.top"] = False
plt.rcParams["ytick.right"] = Falsex, y = FFTKDE(kernel="gaussian", bw=2).fit(data_01).evaluate()
img_data = x.reshape(1, -1)cmap = parula
fig,ax = plt.subplots(figsize=(4,3.5),dpi=100,facecolor="w")
ax.plot(x,y, lw=1,color="k")
# 添加单独数据、
ax.plot(data_01, [0.005]*len(data_01), '|', color='k',lw=1)
#ax.tick_params(which="both",direction='in')
ax.set_xlabel("Values")
ax.set_ylabel("Density")
ax.set_title("Gaussian Kernel",size=15)extent=[*ax.get_xlim(), *ax.get_ylim()]
im = Axes.imshow(ax, img_data, aspect='auto',cmap=cmap,extent=extent)
fill_line,= ax.fill(x, y,facecolor='none')
im.set_clip_path(fill_line)
colorbar = fig.colorbar(im,ax=ax,aspect=12,label="Values")
#colorbar.ax.tick_params(which="both",direction='in')
#colorbar.ax.set_title("Values",fontsize=10)plt.show() #(b)利用ProPlot绘制的带渐变颜色填充的密度图from colormaps import parula
#from matplotlib.axes import Axes
from proplot.axes import Axes
from proplot import rcrc["font.family"] = "Times New Roman"
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 10
rc["suptitle.size"] = 16x, y = FFTKDE(kernel="gaussian", bw=2).fit(data_01).evaluate()
img_data = x.reshape(1, -1)cmap = parula
fig = pplt.figure(suptitle="Gaussian",figsize=(3.5,3))
ax = fig.subplot(xlabel='x axis', ylabel='y axis')
ax.format(abc='a.', abcloc='ul',abcsize=16,xlabel='Values', ylabel='Density',suptitle='Gaussian Kernel')
ax.plot(x,y, lw=1,color="k")
# 添加单独数据、
ax.plot(data_01, [0.005]*len(data_01), '|', color='k',lw=1)
fill_line,= ax.fill(x, y,facecolor='none')
extent=[*ax.get_xlim(), *ax.get_ylim()]
im = Axes.imshow(ax, img_data, aspect='auto',cmap=cmap,extent=extent)
im.set_clip_path(fill_line)
fig.colorbar(im,title="Values",tickminor=True,tickdirection="in")plt.show() #(c)利用SciencePlots 绘制的带渐变颜色填充的密度图from KDEpy import NaiveKDE
from colormaps import parula
from matplotlib.axes import Axescustomer_ages = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]
x, y = NaiveKDE(kernel="gaussian",bw=2).fit(customer_ages).evaluate()
img_data = x.reshape(1, -1)
cmap = parulafrom matplotlib.axes import Axes
with plt.style.context(['science']):fig,ax = plt.subplots(figsize=(4,3.5),dpi=100,facecolor="w")ax.plot(x,y, lw=1,color="k")# 添加单独数据、ax.plot(data_01, [0.005]*len(data_01), '|', color='k',lw=1)#ax.tick_params(which="both",direction='in')ax.set_xlabel("Values")ax.set_ylabel("Density")ax.set_title("Gaussian Kernel",size=15)ax.text(.05,.88,"a.",transform=ax.transAxes,fontsize=25,fontweight="bold")extent=[*ax.get_xlim(), *ax.get_ylim()]im = Axes.imshow(ax, img_data, aspect='auto',cmap=cmap,extent=extent)fill_line,= ax.fill(x, y,facecolor='none')im.set_clip_path(fill_line)colorbar = fig.colorbar(im,ax=ax,aspect=12,label="Values")
plt.show()
需要注意的是,这里的连续填充颜色系为自定义的 parula 颜色系(MATLAB 经典的颜色系),只需将 colormaps.py 文件添加到当前绘制环境中即可导入定义好的 parula 颜色系。
对于“多组数据、同一个核函数”或“同组数据、不同核函数”的情况,它们颜色填充密度图的绘制方法与同组数据一致。
下图为利用 ProPlot 库绘制的“同组数据、不同核函数”情况对应的渐变颜色填充密度图。
from colormaps import parula
from proplot.axes import Axes
from KDEpy import NaiveKDE
from proplot import rcrc["font.family"] = "Times New Roman"
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 10
rc["suptitle.size"] = 16data_01 = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]cmap = parula
kde_kernels = NaiveKDE._available_kernels.keys()
fig, axs = pplt.subplots(ncols=3, nrows=3,refwidth=1.5,refheight=1.2)
axs.format(abc='a.', abcloc='ul',abcsize=16,xlabel='Values', ylabel='Density',
)
for ax, kernel in zip(axs,kde_kernels):x,y = NaiveKDE(kernel=kernel,bw=2).fit(data_01).evaluate()img_data = x.reshape(1, -1)ax.plot(x,y, lw=1,color="k")fill_line,= ax.fill(x, y,facecolor='none')# 添加单独数据、ax.plot(data_01, [0.005]*len(data_01), '|', color='k',lw=.5)ax.format(title=str.capitalize(kernel),titleweight='bold',titlesize=12)extent=[*ax.get_xlim(), *ax.get_ylim()]im = Axes.imshow(ax, img_data, aspect='auto',cmap=cmap,extent=extent)im.set_clip_path(fill_line)colorbar = fig.colorbar(im,tickminor=True,tickdirection="in",ax=ax)colorbar.ax.set_title("Values",fontsize=8)
plt.show()
“山脊”图
在对多组数据进行密度图绘制时,除上述介绍的使用子图对每组数据进行绘制以外,我们还可以将多组数据绘制结果进行堆叠摆放,即使用“山脊”图(ridgeline chart)进行表示。
“山脊”图通常用来表示不同类别的数据在同一因素的分布差异情况。在 Matplotlib 中,我们可以使用 Matplotlib 的“原生”方法绘制“山脊”图,也可以使用 JoyPy 库绘制。
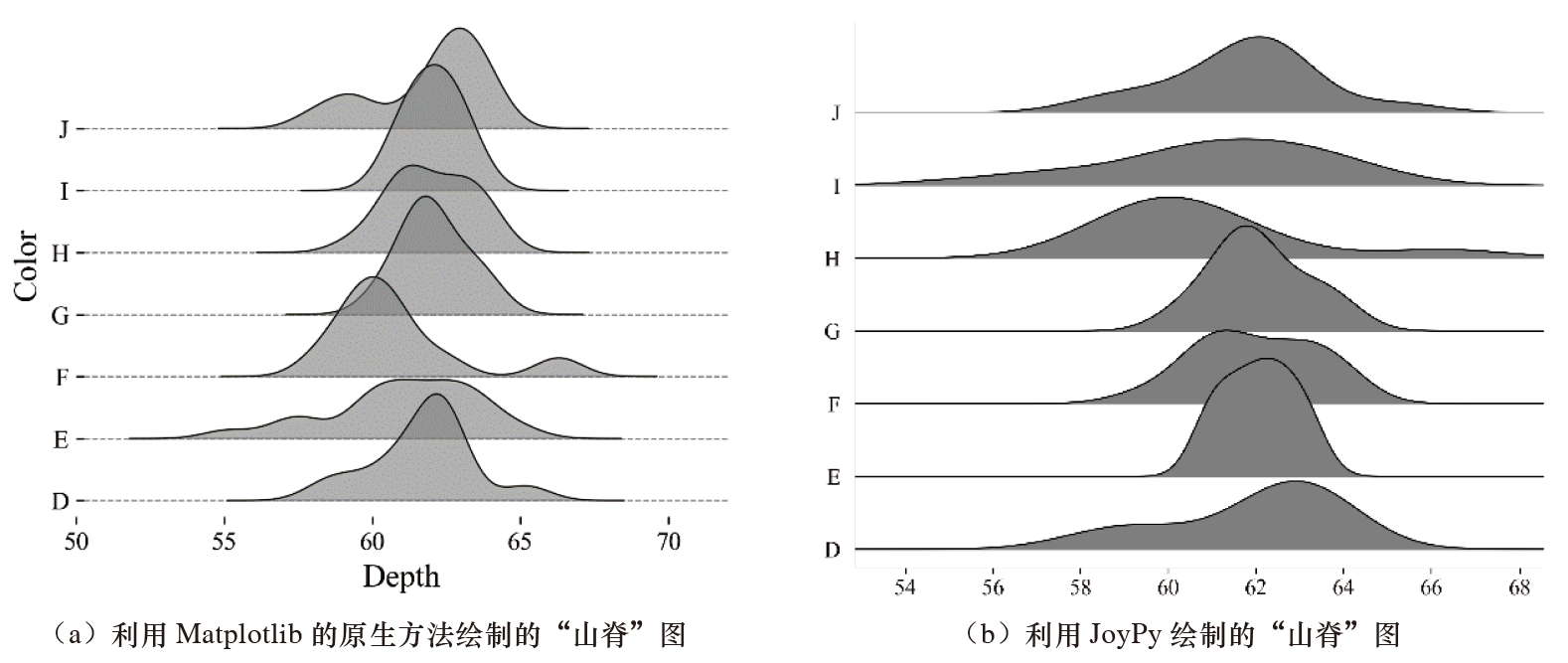
sord_index = [i for i in group_data.color.unique()]
sord_index = sorted(sord_index, key=str.lower)
fig,ax = plt.subplots(figsize=(5.5,4.5), dpi=100)
for i,index in zip(range(len(sord_index)), sord_index):data = group_data.loc[group_data["color"]==index, "depth"].valuesx,y = NaiveKDE(kernel="Gaussian", bw=.8).fit(data).evaluate()ax.plot(x, 6*y+i, lw=.6, color="k", zorder=100-i)ax.fill(x, 6*y+i, lw=1, color="gray", alpha=.6, zorder=100-i)ax.grid(which="major", axis="y", ls="--", lw=.7, color="gray", zorder=-1)ax.yaxis.set_tick_params(labelleft=True)ax.set_yticks(np.arange(len(sord_index)))ax.set_yticklabels(sord_index)
我们可以使用 JoyPy 库绘制每组数据的直方“山脊”图,将 joyplot()函数中的参数 hist 设置为 True 即可,还可以通过设置 colormap 参数来对“山脊”图进行颜色映射。
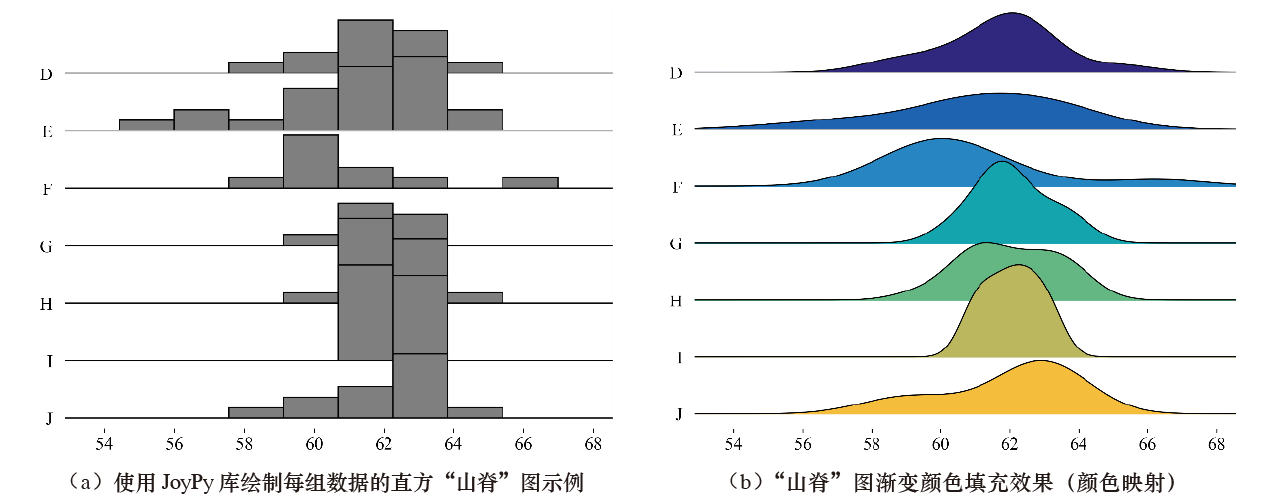
# 直方"山脊"图的绘制
fig, axes = joypy.joyplot(group_data, by="color",column="depth", labels=sord_index, grid="y",linewidth=1, figsize=(7,6), color="gray",hist=True, xlabelsize=15, ylabelsize=15)
# 渐变颜色填充"山脊"图的绘制
from colormaps import parula
fig, axes = joypy.joyplot(group_data, by="color",column="depth", labels=sord_index, grid="y",linewidth=1, figsize=(7,6), hist=False,colormap=parula, xlabelsize=15, ylabelsize=15)
由于 JoyPy 库的功能还不够完善,因此,建议读者使用 Matplotlib 的原生方法绘制“山脊”图。
如果想使用连续渐变颜色对“山脊”图中的每组数据进行填充,并且用连续渐变颜色值表示数据大小,那么可以参考渐变颜色填充密度图的绘制方法。
需要注意的是,由于绘制脚本中涉及循环绘制语句,因此,在保存成矢量文件(如 PDF 文件)时,会出现裁剪失败问题。想要解决这一问题,我们只需要在编写脚本前添加如下代码。
# 在将多个绘图对象保存为PDF文件时,需要进行如下设置
plt.rcParams["image.composite_image"] = False
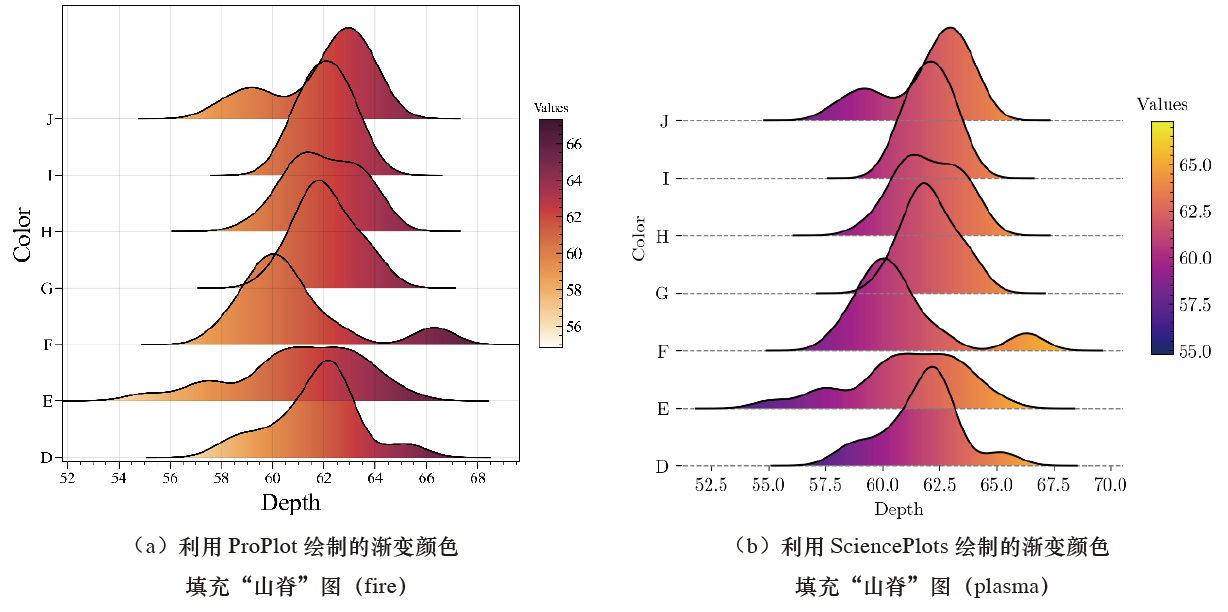
下图为利用 Matplotlib 绘制的渐变颜色填充“山脊”图,其中,图(a)使用了颜色映射样式“plasma”,图(b)使用了颜色映射样式“parula”,不同颜色代表不同的变量(Depth)数值大小。

# 在将多个绘图对象保存为PDF文件时,需要进行如下设置
plt.rcParams["image.composite_image"] = False
fig,ax = plt.subplots(figsize=(5.5, 4.5), dpi=100)
for i,index in zip(range(len(sord_index)), sord_index):data = group_data.loc[group_data["color"]==index,"depth"].valuesx,y = NaiveKDE(kernel="Gaussian", bw=.8).fit(data).evaluate()img_data = x.reshape(1, -1)ax.plot(x,6*y+i, lw=1, color="k", zorder=100-i)fill_line, = ax.fill(x, 6*y+i, facecolor="none")ax.grid(which="major", axis="y", ls="--",lw=.7, color="gray", zorder=-1)ax.set_xlim(50,72)ax.yaxis.set_tick_params(labelleft=True)ax.set_yticks(np.arange(len(sord_index)))ax.set_yticklabels(sord_index)ax.set_xlabel("Depth")ax.set_ylabel("Color")ax.tick_params(which ="both",top=False,right=False)ax.tick_params(which = "minor", axis="both", left=False,bottom=False)
for spin in ["top", "right", "bottom", "left"]:ax.spines[spin].set_visible(False)extent=[*ax.get_xlim(), *ax.get_ylim()]im = Axes.imshow(ax, img_data, aspect='auto',cmap="plasma", extent=extent)im.set_clip_path(fill_line)
colorbar = fig.colorbar(im, aspect=10, shrink=0.5)
colorbar.ax.set_title("Values", fontsize=10)
使用 ProPlot 和 SciencePlots 库分别绘制的渐变颜色填充“山脊”图。
import pandas as pd
import numpy as np
import proplot as ppltgroup_data = pd.read_csv(r"第3章 单变量图形的绘制\山脊图绘制数据.csv")
sord_index = [i for i in group_data.color.unique()]
sord_index = sorted(sord_index,key=str.lower)# a)利用ProPlot绘制的渐变颜色填充“山脊”图(fire)
from proplot.axes import Axes
from proplot import rc
rc["font.family"] = "Times New Roman"
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 10
rc["suptitle.size"] = 16
rc["image.composite_image"] = Falsefig = pplt.figure(figsize=(5.,4.5))
ax = fig.subplot()
ax.format(xlabel='Depth', ylabel='Color',ytickminor=False)
for i,index in zip(range(len(sord_index)),sord_index):data = group_data.loc[group_data["color"]==index,"depth"].valuesx,y = NaiveKDE(kernel="Gaussian",bw=.8).fit(data).evaluate()img_data = x.reshape(1,-1)ax.plot(x,6*y+i, lw=1,color="k",zorder=100 - i)fill_line, = ax.fill(x,6*y+i,facecolor="none")ax.yaxis.set_tick_params(labelleft=True)ax.set_yticks(np.arange(len(sord_index)))ax.set_yticklabels(sord_index)extent=[*ax.get_xlim(), *ax.get_ylim()]#im = Axes.imshow(ax, img_data, aspect='auto',cmap=cmap,extent=extent) Fireim = Axes.imshow(ax, img_data, aspect='auto',cmap="Fire",extent=extent)im.set_clip_path(fill_line)colorbar = fig.colorbar(im,tickminor=True,tickdirection="in",length=.5,width=.2)
colorbar.ax.set_title("Values",fontsize=8)
plt.show() #b)利用SciencePlots绘制的渐变颜色填充“山脊”图(plasma)from matplotlib.axes import Axes
# 保存多个ax为pdf文件需要设置
plt.rcParams["image.composite_image"] = False
with plt.style.context(['science']):fig,ax = plt.subplots(figsize=(5.5,4.5),dpi=100,facecolor="w")for i,index in zip(range(len(sord_index)),sord_index):data = group_data.loc[group_data["color"]==index,"depth"].valuesx,y = NaiveKDE(kernel="Gaussian",bw=.8).fit(data).evaluate()img_data = x.reshape(1,-1)ax.plot(x,6*y+i, lw=1,color="k",zorder=100 - i)fill_line, = ax.fill(x,6*y+i,facecolor="none")#ax.axhline(i,ls="--",lw=.7,color="gray",zorder=100 - i)ax.grid(which="major",axis="y",ls="--",lw=.7,color="gray",zorder=-1)#ax.set_xlim(50,72)ax.yaxis.set_tick_params(labelleft=True)ax.set_yticks(np.arange(len(sord_index)))ax.set_yticklabels(sord_index)ax.set_xlabel("Depth")ax.set_ylabel("Color")ax.tick_params(which ="both",top=False,right=False)ax.tick_params(which = "minor",axis="both",left=False,bottom=False)for spin in ["top","right","bottom","left"]:ax.spines[spin].set_visible(False)extent=[*ax.get_xlim(), *ax.get_ylim()]im = Axes.imshow(ax, img_data, aspect='auto',cmap="plasma",extent=extent)im.set_clip_path(fill_line)colorbar = fig.colorbar(im,aspect=10,shrink=0.5)colorbar.ax.set_title("Values",fontsize=10)
plt.show()
同一坐标系中多个密度图的绘制
在将多个密度图绘制在同一坐标系时,除了使用 Matplotlib 库进行循环绘制以外,还可以使用 Seaborn 库进行快速绘制。
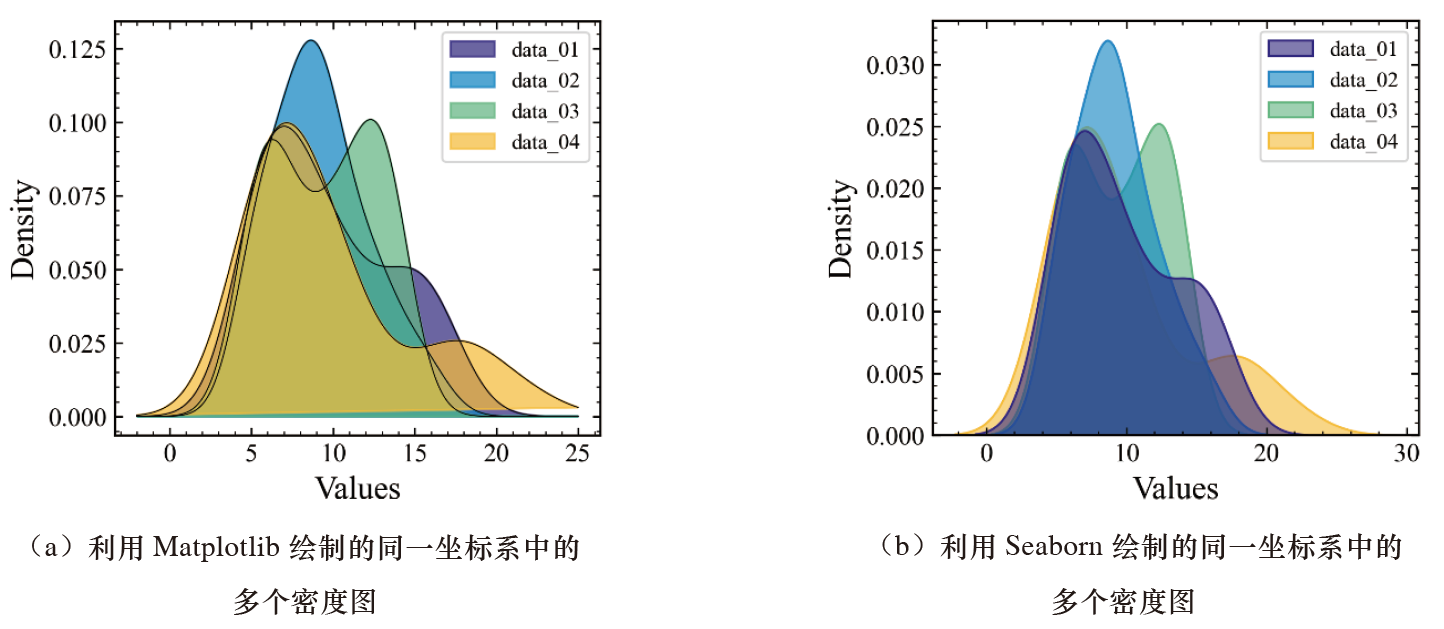
下图为使用 Matplotlib 和 Seaborn 分别绘制的“同一坐标系中的多个密度图”。
# 利用Matplotlib 绘制
from scipy import stats
palette = ["#352A87", "#108ED2", "#65BE86", "#FFC337"]
fig,ax = plt.subplots(figsize=(4, 3.5), dpi=100)
for i, index, color inzip(range(len(palette)), data_df.columns, palette):data = data_df[index].valuesdensity = stats.kde.gaussian_kde(data)x = np.linspace(-2, 25, 500)y = density(x)ax.plot(x, y, lw=.5, color="k", zorder=5-i)ax.fill(x, y, color=color, label=index, alpha=.7)
ax.set_xlabel("Values")
ax.set_ylabel("Density")
ax.legend()# 利用Seaborn绘制
fig,ax = plt.subplots(figsize=(4, 3.5), dpi=100)
sns.kdeplot(data=data_df, shade=True, palette= palette, alpha=.6, ax=ax)
ax.set_xlabel("Values")
注意,使用 Seaborn 绘制的同一坐标系中的多个密度图的默认顺序与 Matplotlib 绘制结果不同。
在 ProPlot 库的编辑环境中绘制 Seaborn 的绘图对象时,两者虽然都是基于 Matplotlib 开发的高级封装库,但二者之间还存在较大的差异,无法较好地在特定图形绘制中形成统一的语法标准,导致 ProPlot 库在绘制 Seaborn 图形对象时的绘图定制化操作较弱。
下图为使用 ProPlot、SciencePlots 库分别绘制的“同一坐标系中的多个密度图”。
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as pltdata_01 = [5.1,5.2,5.3,5.4,5.5,6.0,6.2,6.3,6.4,6.5,7.0,7.5,8.0,8.5,8.8,8.9,9.0,9.5,10,11,11.5,12,13,14,14.5,15,15.5,16,16.5,17]data_02 = [5.1,5.2,5.3,5.4,5.5,6.0,7.0,7.3,7.4,7.5,8.0,8.2,8.4,8.6,8.8,9.0,9.2,9.4,9.6,9.8,10,10.2,11,11.5,12,12.5,13,13.5,15,16]
data_03 = [5.1,5.2,5.3,5.4,5.6,6.0,6.1,6.2,6.4,6.8,7.1,8.2,8.8,9.0,9.2,10.2,10.4,10.8,11,11.6,12,12.4,12.6,12.8,13,13.2,13.4,13.6,13.7,13.8]data_04 = [5.0,5.2,5.3,5.4,5.6,5.8,6.0,6.2,6.4,6.6,6.8,7.0,7.2,7.4,7.6,8.0,9.0,9.2,9.6,9.8,10,10.3,11,12,16,16,18,18.5,19,22]
data_df = pd.DataFrame({"data_01":data_01,"data_02":data_02,"data_03":data_03,"data_04":data_04})#a)利用ProPlot 绘制的结果 from scipy import stats
from proplot import rc
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 12
rc["suptitle.size"] = 15
palette = ["#352A87","#108ED2","#65BE86","#FFC337"]fig = pplt.figure(figsize=(3.5,3))
ax = fig.subplot()
ax.format(abc='a.', abcloc='ul',abcsize=16,xlabel='Values', ylabel='Density')for i, index,color in zip(range(len(palette)),data_df.columns,palette):data = data_df[index].valuesdensity = stats.kde.gaussian_kde(data)x = np.linspace(-2,25,500)y = density(x)ax.plot(x,y, lw=.5,color="k",zorder=5-i)ax.fill(x,y,color=color,label=index,alpha=.7)
ax.legend(ncols=1,frame=False,loc='ur')plt.show() #b)利用ProPlot seaborn对象绘制的结果 from proplot import rc
rc["axes.labelsize"] = 15
rc['tick.labelsize'] = 10
rc["suptitle.size"] = 16
rc["legend.fontsize"] = 5palette = ["#352A87","#108ED2","#65BE86","#FFC337"]fig = pplt.figure(figsize=(3.5,3))
ax = fig.subplot()
ax.format(abc='a.', abcloc='ul',abcsize=16,xlabel='Values', ylabel='Density')sns.kdeplot(data=data_df,shade=True,palette = palette,alpha=.6,ax=ax)
plt.show() #c)利用SciencePlots绘制的结果 使用全局变量设置,字体显示正常import matplotlib.pyplot as plt
plt.style.use('science')from scipy import stats
palette = ["#352A87","#108ED2","#65BE86","#FFC337"]
titles = ["Type One","Type Two","Type Three","Type Four"]
fig,ax = plt.subplots(figsize=(4,3.5),dpi=100,facecolor="w")
for i, index,color,label in zip(range(len(palette)),data_df.columns,palette,titles):data = data_df[index].valuesdensity = stats.kde.gaussian_kde(data)x = np.linspace(-2,25,500)y = density(x)ax.plot(x,y, lw=.5,color="k",zorder=5-i)ax.fill(x,y,color=color,label=label,alpha=.7)
ax.set_xlabel("Values")
ax.set_ylabel("Density")
ax.legend()plt.show()
参考书籍:宁海涛.科研论文配图绘制指南——基于Python[M].北京:人民邮电出版社,2023:49-58.