提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、hadoop的作用?
-
- hadoop是什么?
- hadoop能做什么?
- 搭建HadoopHA高可用集群
-
- 1普通集群配置文件
- 2 高可用集群配置
- 整理和记录搭建hadoop HA高可用集群用到的命令
- 总结
一、hadoop的作用?
hadoop是什么?
Hadoop是一个开源的框架,可编写和运行分布式应用,处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
HDFS|sbin/start-dfs.sh
NameNode | 主节点 |sbin/hadoop-daemon.sh start namenode
DataNode | 数据存储节点 |sbin/hadoop-daemon.sh start datanode
Yarn|sbin/start-yarn.sh
ResourceManager|全局的资源管理器|sbin/yarn-daemon.sh start resourcemanager
NodeManager|分节点资源和任务管理器|
hadoop能做什么?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
搭建HadoopHA高可用集群
1普通集群配置文件
-
hdfs-site.xml
<configuration><!-- <property><name>dfs.replication</name><value>1</value></property>--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop-3:50090</value></property> </configuration> -
core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop-1:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value></property> </configuration> -
slaves
hadoop-1 hadoop-2 hadoop-3 -
yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop-2</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>106800</value></property> </configuration> -
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop-1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop-1:19888</value></property> </configuration>
2 高可用集群配置
-
hdfs-site.xml
<configuration><property><!-- 为namenode集群定义一个services name --><name>dfs.nameservices</name><value>ns1</value></property><property><!-- nameservice 包含哪些namenode,为各个namenode起名 --><name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value></property><property><!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --><name>dfs.namenode.rpc-address.ns1.nn1</name><value>hadoop-1:8020</value></property><property><!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --><name>dfs.namenode.rpc-address.ns1.nn2</name><value>hadoop-2:8020</value></property><property><!--名为nn1的namenode 的http地址和端口号,web客户端 --><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop-1:50070</value></property><property><!--名为nn2的namenode 的http地址和端口号,web客户端 --><name>dfs.namenode.http-address.ns1.nn2</name><value>hadoop-2:50070</value></property><property><!-- namenode间用于共享编辑日志的journal节点列表 --><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop-1:8485;hadoop-2:8485;hadoop-3:8485/ns1</value></property><property><!-- journalnode 上用于存放edits日志的目录 --><name>dfs.journalnode.edits.dir</name><value>/opt/data/tmp/dfs/jn</value></property><property><!-- 客户端连接可用状态的NameNode所用的代理类 --><name>dfs.client.failover.proxy.provider.ns1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><!-- --><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><property><!-- 配置故障自动转移 --><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.replication.max</name><value>32767</value></property> </configuration> -
core-site.xml
fs.defaultFS hdfs://ns1 hadoop.tmp.dir /opt/data/tmp dfs.nameservices ns1 dfs.namenode.name.dir file://${hadoop.tmp.dir}/dfs/name dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data ha.zookeeper.quorum hadoop-1:2181,hadoop-2:2181,hadoop-3:2181 -
slaves
hadoop-1 hadoop-2 hadoop-3 -
yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>106800</value></property><property><!-- 启用resourcemanager的ha功能 --><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><!-- 为resourcemanage ha 集群起个id --><name>yarn.resourcemanager.cluster-id</name><value>yarn-cluster</value></property><property><!-- 指定resourcemanger ha 有哪些节点名 --><name>yarn.resourcemanager.ha.rm-ids</name><value>rm12,rm13</value></property><property><!-- 指定第一个节点的所在机器 --><name>yarn.resourcemanager.hostname.rm12</name><value>hadoop-2</value></property><property><!-- 指定第二个节点所在机器 --><name>yarn.resourcemanager.hostname.rm13</name><value>hadoop-3</value></property><property><!-- 指定resourcemanger ha 所用的zookeeper 节点 --><name>yarn.resourcemanager.zk-address</name><value>hadoop-1:2181,hadoop-2:2181,hadoop-3:2181</value></property><property><!-- --><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><!-- --><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property> </configuration> -
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop-1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop-1:19888</value></property> </configuration>
整理和记录搭建hadoop HA高可用集群用到的命令
1、上传文件到文件服务器
#创建文件目录
[root@hadoop-1 hadoop]$ bin/hdfs dfs -mkdir /input#上传文件
[root@hadoop-1 hadoop]$ bin/hdfs dfs -put /opt/data/wc.input /input/wc.input#运行程序
[root@hadoop-1 hadoop]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output#查看HDFS根目录
[root@hadoop-1 hadoop]$ hadoop fs -ls / 或 bin/hdfs fs -ls /#在根目录创建一个目录test
[root@hadoop-1 hadoop]$ hadoop fs -mkdir /test 或 bin/hdfs fs -mkdir /test
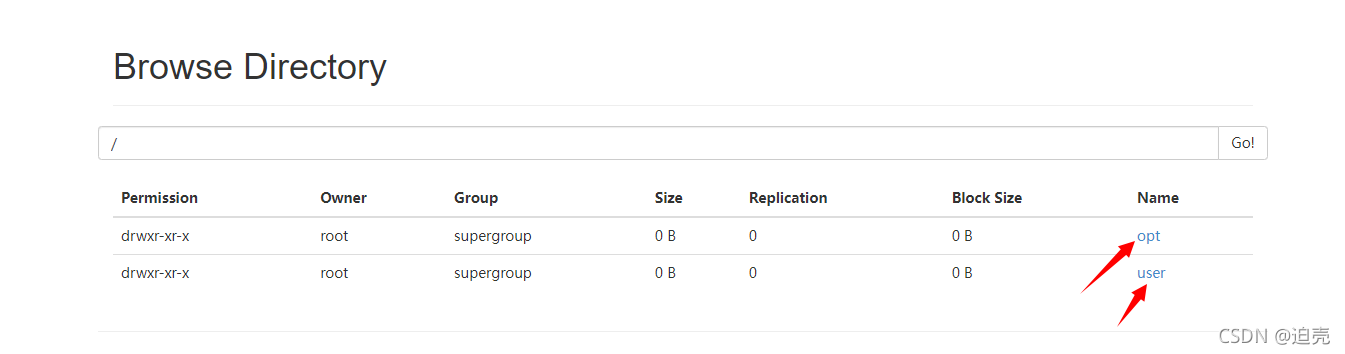
2、查看文件服务器指定目录下是否上传过文件
[root@hadoop-1 hadoop]$ bin/hdfs dfs -ls /input
如图:
3、namenode服务格式化的方式
-
直接格式化
[root@hadoop-1 hadoop]$ bin/hdfs namenode -format -
集群节点格式化—将所有的node(包含namenode、datanode、journalnode的clusterId保持一致)
[root@hadoop-1 hadoop]$ bin/hdfs namenode -format -clusterId hadoop-federation-clusterId -
以standby的状态启动namenode,该状态下namenode不处理请求`
[root@hadoop-1 hadoop]$ bin/hdfs namenode -bootstrapStandby
4、查看namenode是否在使用中或Active状态
[root@hadoop-1 hadoop]# hdfs dfsadmin -report
5、查看服务是否启动
-
使用jps查看是否有namenode
-
没有就使用
[root@hadoop-1 hadoop]$ sbin/hadoop-daemon.sh start namenode -
或者使用启动namenode
[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/start-dfs.sh -
如果启动失败,有可能是namenode格式化多次导致的,需要先清理core-site.xml下配置的hadoop.tmp.dir路径下生成的data、name、jn(journalnode)文件
<property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property>再使用方法3-2的方式再次启动
-
如果还是失败,需要查看报错日志
[root@hadoop-1 hadoop]cd logs
[root@hadoop-1 logs]tail -fn 300 hadoop-root-namenode-hadoop-1.log再根据报错日志百度找到问题所在
6、datanode启动失败
-
查看DataNode是否启动输入命令jps
-
如果发现没有datanode,执行以下
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start datanode -
发现执行后依然没有启动成功,查看core-site.xml是否配置datanode的环境路径
<property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value></property> -
如果配置了没有生效,(没有就配置,重启服务5-3的命令即可),就进入到该路径下查看是否生成了current文件
[root@hadoop-1 hadoop]# cd /opt/data/tmp/dfs/data/current/如果出来了VERSION文件,即启动过,查看namenode的VERSION和datanode的版本是否一致

没有的话,就将datanode的版本号改成namnode一致的,如果还是失败,可能是元数据需要的空间过多,需要删除一些日志文件来保证datanode正常运行。如share/doc和logs/hadoop-root*#删除hadoop的功能文档文件 [root@hadoop-1 hadoop]# cd share/doc [root@hadoop-1 doc]# rm -rf *#删除hadoop的日志文件 [root@hadoop-1 hadoop]# cd logs/ [root@hadoop-1 doc]# rm -rf hadoop-root* -
再次启动datanode
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start datanode到了这一步大部分人可能datanode重启成功了,不过还可能有部分人因为配置文件的原因导致启动失败,这里建议将配置文件重新过一下这位大神的配置文件写的非常详细非常适合刚开始学习搭建hadoop集群的开发人员 https://blog.csdn.net/hliq5399/article/details/78193113/
6、查看linux服务器之间是否可以相互访问
-
使用ping来查看是否可以相互访问Ip
[root@hadoop-1 hadoop]ping hadoop-2

-
由于大部分配置都是通过服务器IP别名来配置的,因此需要在DNS域名服务上配置域名转换,确保自己的hostname已经更改,未更改以下操作无效,https://blog.csdn.net/qq_22310551/article/details/84966044 该大神较全面的讲解了hostname的配置,已经配置解析
[root@hadoop-1 hadoop]# cat /etc/hosts#127.0.0.1 localhost #::1 localhost #192.168.149.110 hadoop-1#127.0.0.1 localhost192.168.149.110 hadoop-1192.168.149.120 hadoop-2192.168.149.130 hadoop-3
代码如下(示例):
1、配置虚拟机hostname;
vi /etc/sysconfig/network
#设置成这样
NETWORKING=yes
HOSTNAME=hadoop-1#关闭--查看更改效果
more /etc/sysconfig/network
hostname
more /proc/sys/kernel/hostname#然后重启虚拟机,永久改变
reboot#切记/etc/hosts 和hostname没有任何关系 仅仅是一个dns 域名转换器
2、配置window的域名,可以直接通过域名访问linux对应IP服务器
C:WindowsSystem32driversetc#打开hosts 添加配置如
192.168.149.110 hadoop-1
192.168.149.120 hadoop-2
192.168.149.130 hadoop-3
以后可以直接用hadoop-1代替192.168.149.110来访问了。
快速配置 scp -r /opt/data/tmp/dfs/jn/ hadoop-2:/opt/data/tmp/dfs/
该处使用的url网络请求的数据。
-
查看服务是否启动----一般来讲8020端口是namenode启动后的端口,访问不了说明namenode无法被使用,8485是journalnode启动后的端口
#查看端口是否启动 [root@hadoop-1 hadoop]# netstat -tpnl

-
其中IP为0.0.0.0的端口的说明该服务可以支持多种方式远程访问:
如0.0.0.0:80 可以使用127.0.0.1:80 或 服务IP:80 或 DNS域名转换:80#域名转换 [root@hadoop-1 hadoop]# curl hadoop-1:80或在节点hadoop-2上访问hadoop-1端口
[root@hadoop-2 hadoop]# curl hadoop-1:80IP为127.0.0.1的说明只能在本地访问,如在hadoop-2节点上无法通过curl 127.0.0.1 6010访问到hadoop-1的服务。
IP为192.168.149.110说明其它服务器可以远程访问该端口 -
使用telnet来检测自己是否可以访问自己已启动的服务如
[root@hadoop-1 hadoop]# telnet hadoop-1 8020Trying 192.168.149.110...Connected to hadoop-1.Escape character is '^]'.发现连接成功,telnet需要自己通过百度下载
#安装
yum install telnet-server -y
yum install xinetd -y
yum install telnet
启动systemctl start telnet.socket
#加入开机启动
systemctl enable telnet.socket -
如果访问不了,也有可能是你没有输入访问账号、密码什么的(前提是防火墙都关闭了)通过设置ssh的方式免密访问
#生成密匙,需要一路回车[root@hadoop-1 hadoop]$ ssh-keygen -t rsa #发放密钥[root@hadoop-1 hadoop]$ ssh-copy-id hadoop-1[root@hadoop-1 hadoop]$ ssh-copy-id hadoop-2[root@hadoop-1 hadoop]# $ ssh-copy-id hadoop-3这样hadoop-2、hadoop-3就可以免密访问hadoop-1的服务了
7、启动资源管理resourceManager,该服务未启动会导致hadoop无法上传文件
-
启动方式 一次性启动全部服务(包含resourceManager)
[root@hadoop-1 hadoop]# sbin/start-all.sh -
单个启动
#启动yarn
[root@hadoop-1 hadoop]$ sbin/start-yarn.sh
#启动resourcemanager 在指定服务器上启动
[root@hadoop-2 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
[root@hadoop-3 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
8、服务启动后网站http://hadoop-1:50070/dfshealth.html#tab-overview添加链接描述里的namenode处于standby,可以采用强制激活
#nn1是配置文件里的路径
[root@hadoop-1 hadoop]$ bin/hdfs haadmin -transitionToActive -forcemanual nn1[root@hadoop-1 hadoop]$ vi etc/hadoop/hdfs-site.xml
<property><!--名为nn1的namenode 的http地址和端口号,web客户端 --><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop-1:50070</value>
</property>
9、任务节点journalnode的启动方式
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start journalnode
10、在hadoop中创建一个zNode
[root@hadoop-1 hadoop]$ bin/hdfs zkfc -formatZK
11、启动namenode、datanode、journalnode、zkfc
[root@hadoop-1 hadoop]$ sbin/start-dfs.sh
总结
提示:这篇文章只是作者开发过程中遇到的一些问题,并没有罗列太多,大部分都是namenode格式化太多导致的问题,只有愿意花费精力都很好结局