- 鉴于自己最近在做后端开发的工作时,发现自己的SQL能力实在太差,开始学习SQL语句基础,学习过程中在本博客进行笔记记录,课程参考:https://www.bilibili.com/video/BV1UE41147KC?p=2
基本概念
DBMS: 数据库管理系统,数据库管理的软件应用,用来管理所有的数据
关系型数据库 : DBMS的一种,每个数据存储对象以表的形式进行分别,表与表之间建立关联关系,因此成为关系型数据库。
非关系型数据库: DBMS的一种,每种数据之间没有表与表之间的关联关系,不能够用SQL语句进行查询。
**SQL全称: ** Structured Query Language ,结构化查询语言
本次学习目标
- 基础的增、删、改、查
- 学习汇总数据、展示报告
- 使用子查询做复杂的查询
- 使用基础内置函数做一些数字、日期、文本数据处理
- 创建视图、存储过程、函数
- 学习使用触发器、时间、事务、并发
-
学习设计数据库 -
学习索引基础知识、如何使用 - 数据库安全问题
SQL语句基本编写原则
基本语句组成示例
USE xxxDB; // 指定使用数据库
SELECT *
FROM customers
WHERE customer_id = 1
ORDER BY first_name;
1、尽管SQL语句不区分大小写,但是关键词最好大写,便于区分,例如 select -> SELECT ,where -> WHERE
2、SQL语句基本逻辑数据: SELETE -> FROM -> 条件查询语句 -> ORDER BY ,先后不按照规定来会导致语句错误
3、每个条件区分可以使用换行符区分
选择语句
SELECT
select用来查询出相关的数据,例如:
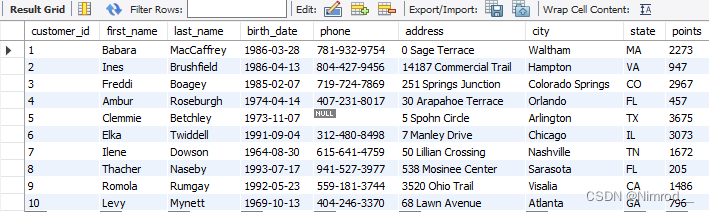
SELECT *
FROM customers;
就是选择customers中的所有列。
其中 * 代表的是选择全部,我们也可以指定选择某列数据,例如:
SELECT first_name, last_name
FROM customers;
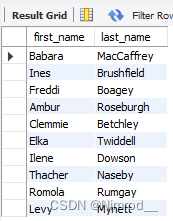
只选择first_name跟last_name列进行展示。
同时,我们还可以对列进行基本的算数运算操作,例如:
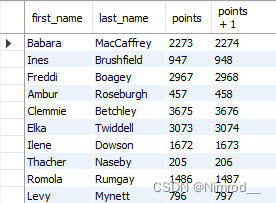
除此之外,还可以给查询的列取别名,例如:
SELECT first_name, last_name, points, points + 1 as points_after_caculator
FROM customers;
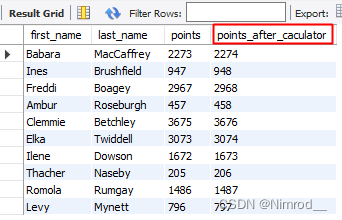
可以看到我们的列已经展示出来了我们想要的别名。
DISTINCT:
DISTINCT 关键词用来做去重,对我们查询到的数据进行去重。
WHERE:
where语句用来做条件查询,例如:
SELECT *
FROM customers
WHERE points > 3000;
查询所有points 大于 3000的顾客,查询结果:

比较运算符有:
>
>=
<
<=
=
!=
<> // 不等于
AND OR NOT操作符
操作符用来做where的扩展条件补充,例如除了积分外,我们还要筛选出生年月大于1990年的顾客:
AND :
与,与代码中的 &效果一致
SELECT *
FROM customers
WHERE points > 1000 AND birth_date > '1990-01-01';
结果:

OR :
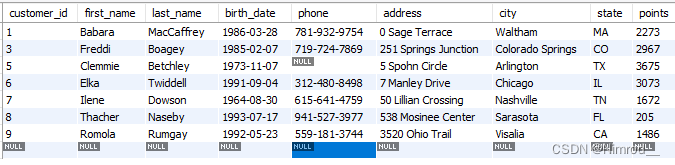
或,与代码中的 ||效果一致满足其中一个条件即可,例如:
SELECT *
FROM customers
WHERE points > 1000 OR birth_date > '1990-01-01';
此时选择的便是出生日期为90之前,或者积分大于1000的顾客,结果:
- 对于多个条件都出现时,优先计算AND联合起来的条件,再计算OR的条件,存在一定的计算优先级。
例如:
SELECT *
FROM customers
WHERE points > 1000 OR birth_date > '1990-01-01' AND state = 'VA';
就是计算了 birth_date > '1990-01-01' AND state = 'VA' 后,再计算OR的结果,结果:

其效果与增加了括号的效果一致。
NOT :
非,与代码中的 !=效果一致,不满足该条件才满足要求,例如:
SELECT *
FROM customers
WHERE NOT (points > 1000 OR birth_date > '1990-01-01');
选择非的条件,NOT一般放在where 后面,NOT后面的条件用括号进行区分,清晰SQL语句。
结果:

IN
用来联合所有的条件,例如查询多个相同的条件:
SELECT *
FROM customers
WHERE state = 'VA' OR state = 'FL' OR state = 'GA';
等同于:
SELECT *
FROM customers
WHERE state IN ('VA', 'FL', 'GA');
结果:

BETWEEN
条件区间,类似于数学上的[x, y]
例如选择分数为 1000到 3000之间的顾客,可以使用where语句:
SELECT *
FROM customers
WHERE points >= 1000 AND points <= 3000;
等同于:
SELECT *
FROM customers
WHERE points BETWEEN 1000 AND 3000;
结果:

LIKE
模糊匹配预算符,按照一定的模式匹配字符串,例如:匹配所有以b开头的名字顾客:
SELECT *
FROM customers
WHERE last_name LIKE 'b%';
结果:

具体的匹配规则可以参考正则匹配符号。
REGEXP(正则表达式)
做正则表达式匹配,具体可以参考正则表达式匹配规则,例如,选择所有名字包含field的顾客,使用LIKE:
SELECT *
FROM customers
WHERE last_name LIKE '%field%';
使用REGEXP:
SELECT *
FROM customers
WHERE last_name REGEXP 'field';
二者效果相同,结果:

基本:
^ : 忽略开头
$ : 忽略结尾
| : 逻辑或
具体可以参考正则表达式的规则。
IS NULL
为空判断符,为空才满足该要求。例如:
SELECT *
FROM customers
WHERE phone IS NULL;
查询所有没有phone字段内容的顾客。
结果:

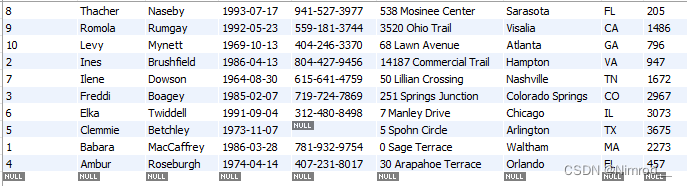
ORDER BY 语句
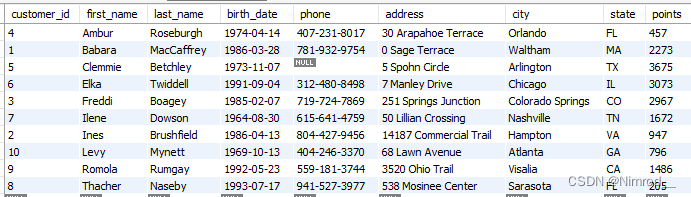
用来排序返回结果,根据不同的ORDER条件进行排序查询,例如,按照first_name排序:
SELECT *
FROM customers
ORDER BY first_name;
结果:
默认为升序排序,我们也可以改为降序:
SELECT *
FROM customers
ORDER BY first_name DESC;
结果:
同时也可以进行多条件排序,例如:
SELECT *
FROM customers
ORDER BY state, first_name;
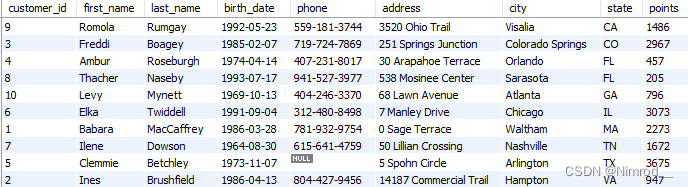
排序的规则时优先第一个,再保证后续规则。
排序规则同时可以作用与别名列表。






![[ACTF2020 新生赛]Exec1命令注入](https://img-blog.csdnimg.cn/9c4fc95a507541b4a5f14b694a370fc7.png)