🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
使用 TensorFlow 编写深度学习模型
下载权重
解码预测
导入其他常用功能
构建模型
从目录输入图像
使用 TensorFlow Keras 导入多个图像和处理的循环函数
使用 TensorFlow 开发迁移学习模型
分析和存储数据
导入 TensorFlow 库
设置模型参数
构建输入数据管道
训练数据生成器
验证数据生成器
使用迁移学习构建最终模型
保存带有检查点的模型
绘制训练历史
了解视觉搜索的架构和应用
视觉搜索的架构
视觉搜索代码及解释
预测上传图片的类别
预测所有图像的类别
使用 tf.data 处理视觉搜索输入管道
概括
视觉搜索是一种显示与用户上传到零售网站的图像相似的图像的方法。通过使用 CNN 将图像转换为特征向量来找到类似的图像。视觉搜索在在线购物中有很多应用,因为它补充了文本搜索,以更好、更精细地表达用户对产品的选择。购物者喜欢视觉发现,并发现它是传统购物体验中无法提供的独特之处。
在本章中,我们将使用在第 4 章“图像深度学习”和第 5 章“神经网络架构和模型”中学到的深度神经网络概念。我们将使用迁移学习为我们的图像类开发神经网络模型,并将其应用于视觉搜索。本章中的练习将帮助您开发足够的实践知识来编写自己的神经网络和迁移学习代码。
本章涵盖的主题如下:
- 使用 TensorFlow 编写深度学习模型
- 使用TensorFlow开发学习模型
- 了解视觉搜索的架构和应用
- 使用视觉搜索输入数据管道tf.data
使用 TensorFlow 编写深度学习模型
我们在第 5 章“神经网络架构和模型”中了解了各种深度学习模型的架构。在本节中,我们将学习如何使用 TensorFlow/Keras 加载图像、探索和预处理数据,然后应用三个 CNN 模型(VGG16、ResNet 和 Inception)预训练的权重来预测对象类别。
本节的代码可以在以下位置找到:https ://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter06/Chapter6_CNN_PretrainedModel.ipynb
让我们深入研究代码并了解其每一行的用途。
下载权重
下载权重的代码如下:
from tensorflow.keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.applications import InceptionV3
from keras.applications.inception_v3 import preprocess_input上述代码执行以下两个任务:
- 权重将作为上述代码输出的一部分下载如下:
- Download VGG16 weight, the *.h5 file
- Download Resnet50 weight, the *.h5 file
- Download InceptionV3 weight, the *.h5 file
- 它对图像进行预处理,以将当前图像标准化为ImageNet RGB数据集。由于模型是在ImageNet数据集上开发的,如果没有这一步,模型很可能会导致错误的类别预测。
解码预测
ImageNet 数据有 1000 个不同的类别。在 ImageNet 上训练的神经网络(例如 Inception)会将类输出为整数。我们需要使用解码将整数转换为相应的类名。例如,如果输出的整数值是311,我们需要解码是什么311意思。通过解码,我们就知道311对应的是折叠椅。
解码预测的代码如下:
from tensorflow.keras.applications.vgg16 import decode_predictions
from tensorflow.keras.applications.resnet50 import decode_predictions
from tensorflow.keras.applications.inception_v3 import decode_predictions前面的代码使用命令将类整数映射到类名decode_predictions。如果没有这一步,您将无法预测类名。
导入其他常用功能
本节介绍 Keras 和 Python 的通用包的导入。Keraspreprocessing是 Keras 的图像处理模块。其他常用导入函数的代码如下所示:
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
import os
from os import listdir您可以在前面的代码中观察到以下内容:
- 我们加载了 Keras 图像预处理功能。
- numpy是一个 Python 数组处理函数。
- matplotlib是一个 Python 绘图函数。
- 该os模块需要访问目录以进行文件输入。
构建模型
在本节中,我们将导入一个模型。模型构建的代码如下所示(每个代码片段的解释都在代码下方):
model = Modelx(weights='imagenet', include_top=True,input_shape=(img_height, img_width, 3))
Modelx = VGG16 or ResNet50 or InceptionV3模型构建具有三个重要参数:
- weights 是我们在之前下载的ImageNet图像上使用的预训练模型。
- 该include_top函数指示是否应包含最终的密集层。对于预训练模型的类别预测,这始终是True; 但是,在本章的后面部分(使用 TensorFlow 开发迁移学习模型部分),我们将了解到,在迁移学习期间,此功能设置False为仅包含卷积层。
- input_shape是通道的高度、宽度和数量。由于我们正在处理彩色图像,因此通道数设置为3。
从目录输入图像
从目录输入图像的代码如下所示:
folder_path = '/home/.../visual_search/imagecnn/'
images = os.listdir(folder_path)
fig = plt.figure(figsize=(8,8))前面的代码指定了图像文件夹路径并定义了图像属性,以便能够在以后的部分中下载图像。它还将图形大小指定为 8 x 8。
使用 TensorFlow Keras 导入多个图像和处理的循环函数
本节介绍如何批量导入多张图片,将它们一起处理,而不是一张一张地导入。这是一项需要学习的关键技能,因为在大多数生产应用程序中,您不会一个一个地导入图像。使用 TensorFlow Keras 导入和处理多个图像的循环函数代码如下:
for image1 in images:i+=1im = image.load_img(folder_path+image1, target_size=(224, 224))img_data = image.img_to_array(im) img_data = np.expand_dims(img_data, axis=0)img_data = preprocess_input(img_data)resnet_feature = model_resnet.predict(img_data,verbose=0)label = decode_predictions(resnet_feature)label = label[0][0]fig.add_subplot(rows,columns,i)fig.subplots_adjust(hspace=.5)plt.imshow(im)stringprint ="%.1f" % round(label[2]*100,1)plt.title(label[1] + " " + str(stringprint) + "%")plt.show()上述代码执行以下步骤:
- 循环使用作为循环的中间值的images属性。image1
- 该image.load函数将每个新图像添加到文件夹路径。请注意,目标大小224适用于 VGG16 和 ResNet 以及299Inception。
- 将图像转换为数组函数并使用 NumPy 数组扩展其维度,然后按照下载权重部分preprocessing中的说明应用该函数。
- 接下来,它使用model.predict()函数计算特征向量。
- 然后,预测解码类标签名称。
- 该label函数存储为一个数组,它有两个元素:类名和置信度%。
- 接下来的几节涉及使用matplotlib库进行绘图:
- fig.add_subplot具有三个元素:rows、columns和i– 例如,共有 9 张图像排列为三列和三行,i术语将从1到9是1第一张图像和9最后一张图像。
- fig.subplots_adjust在图像之间添加垂直空间。
- plt.title为每个图像添加标题。
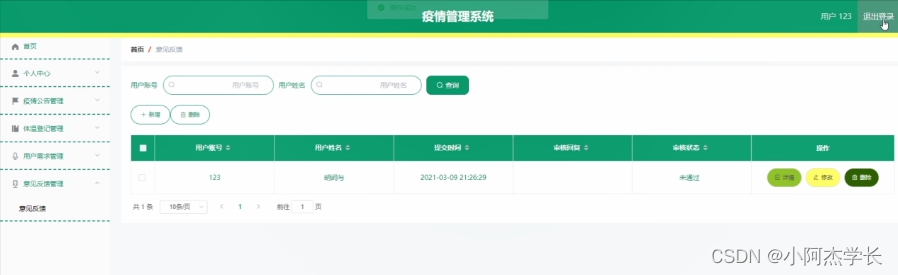
为了验证模型,将九个不同的图像存储在一个目录中,并逐个通过每个模型以生成预测。使用三种不同的神经网络模型对每个目标图像的最终预测输出如下表所示:
| 目标图像 | VGG16 | 资源网 | 成立之初 |
| 餐桌 | 餐桌 58% | 台球桌 30.1% | 办公桌 51% |
| 炒锅 | 钢包 55% | 钢包 87% | 钢包 30% |
| 沙发 | 工作室沙发 42% | 工作室沙发 77% | 工作室沙发 58% |
| 床 | 工作室沙发 35% | 四柱 53% | 工作室沙发 44% |
| 水瓶 | 水瓶 93% | 水瓶 77% | 水瓶 98% |
| 行李 | 折叠椅 39% | 背包 66% | 邮袋 35% |
| 背包 | 背包 99.9% | 背包 99.9% | 背包 66% |
| 长椅 | 工作室沙发 79% | 工作室沙发 20% | 工作室沙发 48% |
| 越野车 | 小型货车 74% | 小型货车 98% | 小型货车 52% |
下图显示了九个类的 VGG16 输出:

在上图中,您可以观察到以下内容:
- 每个图形尺寸为 224 x 224,顶部印有标签,带有置信百分比。
- 有三个不正确的预测:炒锅(预测为勺子)、床(预测为工作室沙发)和行李(预测为折叠椅)。
下图显示了九个类的 ResNet 预测输出:

在上图中,您可以观察到以下内容:
- 每个图形尺寸为 224 x 224,顶部印有标签,带有置信百分比。
- 有两个错误的预测:炒锅(预测为勺子)和行李箱(预测为背包)。
下图显示了九个类的 Inception 预测输出:

由此,您可以观察到以下情况:
- 每个图形尺寸为 224 x 224,顶部印有标签,带有置信百分比。
- 有两个不正确的预测:锅(预测为勺子)和床(预测为工作室沙发)。
通过这个练习,我们现在了解了如何使用预训练模型来预测众所周知的类对象,而无需训练单个图像。我们可以这样做的原因是,每个模型都使用具有 1,000 个类别的 ImageNet 数据库进行训练,并且模型的结果权重可供计算机视觉社区使用,以供其他人使用。
在下一节中,我们将学习如何使用迁移学习来训练我们的模型以针对我们的自定义图像进行预测,而不是从直接从 ImageNet 数据集开发的模型中进行推断。
使用 TensorFlow 开发迁移学习模型
我们在第 5 章“神经网络架构和模型”中介绍了迁移学习的概念,在使用 TensorFlow 编码深度学习模型部分演示了如何基于预训练模型预测图像类别。我们观察到预训练模型在大型数据集上获得了合理的准确性,但我们可以通过在我们自己的数据集上训练模型来改进这一点。一种方法是构建整个模型(例如 ResNet)并在我们的数据集上对其进行训练——但这个过程可能需要大量时间来运行模型,然后为我们自己的数据集优化模型参数。
另一种更有效的方法(称为迁移学习)是从基础模型中提取特征向量,而无需在 ImageNet 数据集上训练顶层,然后添加我们自定义的全连接层,包括激活、丢弃和 softmax,以构成我们的最终模型。我们冻结了基础模型,但新添加的组件的顶层仍然未冻结。我们在自己的数据集上训练新创建的模型以生成预测。从大型模型中迁移学习到的特征图,然后通过微调高阶模型参数在我们自己的数据集上自定义它们的整个过程称为迁移学习。迁移学习工作流程以及相关的 TensorFlow/Keras 代码将在接下来的几节中进行说明,首先是分析和存储数据。
分析和存储数据
首先,我们将从分析和存储数据开始。在这里,我们正在构建一个具有三个不同类的家具模型:bed、chair和sofa。我们的目录结构如下。每张图像都是尺寸为 224 x 224 的彩色图像。
Furniture_images:
- train(2,700 张图片)
- bed(900 张图片)
- chair(900 张图片)
- sofa(900 张图片)
- val(300 张图片)
- bed(100 张图片)
- chair(100 张图片)
- sofa(100 张图片)
导入 TensorFlow 库
我们的下一步是导入 TensorFlow 库。以下代码导入 ResNet 模型权重和预处理输入,类似于我们在上一节中所做的。我们在第 5 章“神经网络架构和模型”中了解了这些概念:
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.layers import Dense, Activation, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import SGD, Adam
img_width, img_height = 224, 224该代码还导入了几个深度学习参数,例如Dense(全连接层)Activation、、、Flatten和Dropout。然后,我们导入 Sequential 模型 API 以创建逐层模型、随机梯度下降( SGD ) 和 Adam 优化器。图像高度和宽度适用224于 ResNet 和 VGG 以及299Inception 模型。
设置模型参数
对于我们的分析,我们设置模型参数,如以下代码块所示:
NUM_EPOCHS = 5
batchsize = 10
num_train_images = 900
num_val_images = 100然后构建基本模型,类似于我们在上一节中的示例,除了我们不通过设置 include_top=False包含顶层模型:
base_model = ResNet50(weights='imagenet',include_top=False,input_shape=(img_height, img_width, 3))在此代码中,我们使用基础模型仅使用卷积层生成特征向量。
构建输入数据管道
我们将导入一个图像数据生成器,该生成器使用旋转、水平翻转、垂直翻转和数据预处理等数据增强来生成张量图像。数据生成器将重复训练和验证数据。
训练数据生成器
让我们看一下训练数据生成器的以下代码:
from keras.preprocessing.image import ImageDataGenerator
train_dir = '/home/…/visual_search/furniture_images/train'
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=90,horizontal_flip=True,vertical_flip=True)Flow for directory API——用于从目录导入数据。它具有以下参数:
- Directory:这是一个文件夹路径,应该设置为所有三个类的图像都存在的路径。在这种情况下,一个示例是train目录的路径。要获取路径,您可以将文件夹拖到终端,它会显示路径,然后您可以复制和粘贴。
- Target_size: 将其设置为模型拍摄的图像大小,例如 Inception 为 299 x 299,ResNet 和 VGG16 为 224 x 224。
- Color_mode:设置grayscale为黑白图像和RGB彩色图像。
- Batch_size:每批次的图像数量。
- class_mode:如果您只有两个类要预测,则设置为二进制;如果没有,请设置为categorical.
- shuffle:True如果要重新排序图像,请设置为;否则,设置为False。
- seed:用于应用随机图像增强和打乱图像顺序的随机种子。
下面的代码展示了如何编写最终的训练数据生成器,它将被导入到模型中:
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(img_height, img_width), batch_size=batchsize)验证数据生成器
接下来,我们将在以下代码中重复验证过程。该过程与训练生成器的过程相同,除了我们将验证图像目录而不是训练图像目录:
from keras.preprocessing.image import ImageDataGenerator
val_dir = '/home/…/visual_search/furniture_images/val'
val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,rotation_range=90,horizontal_flip=True,vertical_flip=True)
val_generator = val_datagen.flow_from_directory(val_dir,target_size=(img_height, img_width),batch_size=batchsize)前面的代码显示了最终的验证数据生成器。
使用迁移学习构建最终模型
我们首先定义一个名为 的函数build_final_model(),该函数接受基本模型和模型参数,例如 dropout、全连接层和类数。我们首先使用layer.trainable = False. 然后我们将基本模型输出特征向量展平以进行后续处理。接下来,我们添加一个全连接层和 dropout 到展平的特征向量,以使用 softmax 层预测新类:
def build_final_model(base_model, dropout, fc_layers, num_classes):for layer in base_model.layers:layer.trainable = Falsex = base_model.outputx = Flatten()(x)for fc in fc_layers:# New FC layer, random initx = Dense(fc, activation='relu')(x)x = Dropout(dropout)(x)# New softmax layerpredictions = Dense(num_classes, activation='softmax')(x)final_model = Model(inputs=base_model.input, outputs=predictions)return final_model
class_list = ["bed", "chair", "sofa"]
FC_LAYERS = [1024, 1024]
dropout = 0.3final_model=build_final_model(base_model,dropout=dropout,fc_layers=FC_LAYERS,num_classes=len(class_list))
该模型是使用adam具有分类交叉熵损失的优化器编译的:
adam = Adam(lr=0.00001)
final_model.compile(adam, loss='categorical_crossentropy', metrics=['accuracy'])使用该model.fit_generator命令开发和运行最终模型。历史记录存储时期、每步时间、损失、准确度、验证损失和验证准确度:
history = final_model.fit(train_dir,epochs=NUM_EPOCHS,steps_per_epoch=num_train_images // batchsize,callbacks=[checkpoint_callback],validation_data=val_dir, validation_steps=num_val_images // batchsize)model.fit()这里解释了的各种参数。Notemode.fit_generator将在未来被弃用,并将被model.fit()前面所示的函数取代:
- train_dir:这输入训练数据;其操作细节已在上一节中进行了说明。
- epochs: 一个整数,表示训练模型的 epoch 数。纪元从1增加到 的值epochs。
- steps_per_epoch: 这是一个整数。它显示了训练完成和下一个 epoch 开始训练之前的总步数(样本批次)。它的最大值等于(训练图像数/ batch_size)。因此,如果有 900 张训练图像并且批量大小为 10,则每个 epoch 的步数为 90。
- workers:较高的值可确保 CPU 创建足够的批次供 GPU 处理,并且 GPU 永远不会保持空闲状态。
- shuffle: 这是一个布尔类型。它表示在每个 epoch 开始时对批次进行重新排序。它仅与Sequence( keras.utils.Sequence) 一起使用。is not时steps_per_epoch无效None。
- Validation_data: 这是一个验证生成器。
- validation_steps:这是生成器中使用的步骤总数(样本批次),validation_data等于验证数据集中的样本数量除以批次大小。
保存带有检查点的模型
TensorFlow 模型可以运行很长时间,因为每个 epoch 需要几分钟才能完成。TensorFlow 有一个名为的命令Checkpoint,它使我们能够在每个 epoch 完成时保存中间模型。因此,如果您必须在中间中断模型,因为损失已经饱和或将您的 PC 用于其他目的,那么您不必从头开始 - 您可以使用迄今为止开发的模型进行分析。以下代码块显示了对前一个代码块的添加以执行检查点:
from tensorflow.keras.callbacks import ModelCheckpoint
filecheckpath="modelfurn_weight.hdf5"
checkpointer = ModelCheckpoint(filecheckpath, verbose=1, save_best_only=True) history = final_model.fit_generator(train_generator, epochs=NUM_EPOCHS, workers=0,steps_per_epoch=num_train_images // batchsize, shuffle=True, validation_data=val_generator,validation_steps=num_val_images // batchsize, callbacks = [checkpointer])上述代码的输出如下:
89/90 [============================>.] - ETA: 2s - loss: 1.0830 - accuracy: 0.4011 Epoch 00001: val_loss improved from inf to 1.01586, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 257s 3s/step - loss: 1.0834 - accuracy: 0.4022 - val_loss: 1.0159 - val_accuracy: 0.4800Epoch 2/5 89/90 [============================>.] - ETA: 2s - loss: 1.0229 - accuracy: 0.5067 Epoch 00002: val_loss improved from 1.01586 to 0.87938, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 253s 3s/step - loss: 1.0220 - accuracy: 0.5067 - val_loss: 0.8794 - val_accuracy: 0.7300Epoch 3/5 89/90 [============================>.] - ETA: 2s - loss: 0.9404 - accuracy: 0.5719 Epoch 00003: val_loss improved from 0.87938 to 0.79207, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 256s 3s/step - loss: 0.9403 - accuracy: 0.5700 - val_loss: 0.7921 - val_accuracy: 0.7900Epoch 4/5 89/90 [============================>.] - ETA: 2s - loss: 0.8826 - accuracy: 0.6326 Epoch 00004: val_loss improved from 0.79207 to 0.69984, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 254s 3s/step - loss: 0.8824 - accuracy: 0.6322 - val_loss: 0.6998 - val_accuracy: 0.8300Epoch 5/5 89/90 [============================>.] - ETA: 2s - loss: 0.7865 - accuracy: 0.7090 Epoch 00005: val_loss improved from 0.69984 to 0.66693, saving model to modelfurn_weight.hdf5 90/90 [==============================] - 250s 3s/step - loss: 0.7865 - accuracy: 0.7089 - val_loss: 0.6669 - val_accuracy: 0.7700输出显示每个 epoch 的损失和准确性,并将相应的文件保存为hdf5文件。
绘制训练历史
matplotlib使用 Python函数显示了显示每个 epoch 的训练精度和训练损失的线图。我们将matplotlib首先导入,然后定义训练和验证损失和准确性的参数:
以下代码是使用 Keras 和 TensorFlow 绘制模型输出的标准代码。我们首先定义图形大小(8 x 8)并使用 subplot 函数显示(2,1,1)和(2,1,2)。然后我们定义标签、限制和标题:
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,5.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()让我们看一下前面代码的输出。不同模型之间的精度比较如下图所示。它显示了 Inception 的训练参数:

在前面的屏幕截图中,您可以观察到Inception 的准确率在五个 epoch 内达到了大约 90%。接下来,我们绘制 VGG16 的训练参数:

上图显示 VGG16 的准确率在五个 epoch 内达到了 80% 左右。接下来,我们绘制 ResNet 的训练参数:
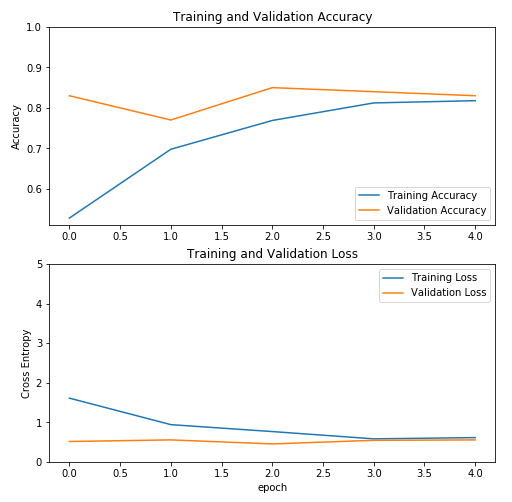
前面的屏幕截图显示,ResNet 的准确率在四个 epoch 内达到了 80% 左右。
对于所有三个模型,准确率在四个 epoch 中始终达到至少80%。Inception 模型的结果具有最高的准确性。
了解视觉搜索的架构和应用
视觉搜索使用深度神经网络技术对图像及其内容进行检测和分类,并使用它在图像数据库中进行搜索以返回匹配结果列表。视觉搜索与零售行业特别相关,因为它允许零售商显示大量与客户上传的图像相似的图像以增加销售收入。视觉搜索可以与语音搜索相结合以进一步增强搜索。视觉信息比文本信息更相关,这导致视觉搜索更受欢迎。许多不同的公司,包括谷歌、亚马逊、Pinterest、Wayfair、沃尔玛、必应、ASOS、Neiman Marcus、宜家、Argos 等都建立了强大的视觉搜索引擎来改善他们的客户体验。
视觉搜索的架构
ResNet、VGG16 和 Inception 等深度神经网络模型基本上可以分解为两个组件:
- 第一个组件识别图像的低级内容,例如特征向量(边缘)。
- 第二个分量表示图像的高级内容,例如最终的图像特征,它是各种低级内容的集合。下图说明了一个分类七类的卷积神经网络:

从上图可以看出,整个图像分类神经网络模型可以分为两层:卷积层和顶层。全连接层之前的最后一个卷积层是一个形状为 ( # of images, X, Y, # of channels ) 的特征向量,它被展平 ( # of images, X*Y*# of channels ) 以生成一个 n-维向量。
# of images表示训练图像的数量。因此,如果您有 1,000 个训练图像,则该值将是 1,000。
X表示层的宽度。典型值为
14。Y表示层的高度,可以是 14 之类的东西。
# of channels表示过滤器的数量或 Conv2D 的深度。典型值为 512。
在视觉搜索中,我们通过使用欧几里得距离或余弦相似度等工具比较它们的特征向量的相似度来计算两幅图像的相似度。视觉搜索的架构如下所示:
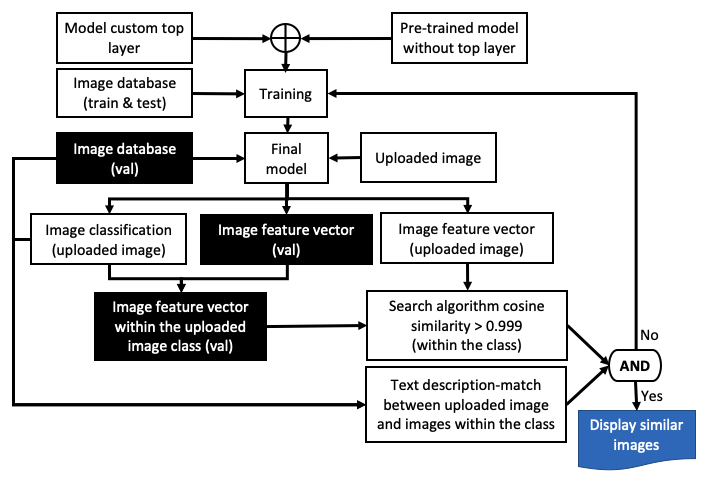
此处列出了各个步骤:
- 使用迁移学习来开发新模型,方法是将顶层从 ResNet、VGG16 或 Inception 等知名模型中分离出来,然后添加自定义顶层,包括全连接层、dropout、激活和 softmax 层。
- 使用新数据集训练新模型。
- 通过我们刚刚开发的新模型运行图像,上传图像并找到其特征向量和图像类。
- 为了节省搜索时间,请仅在与上传图像对应的目录类中搜索。
- 使用诸如欧几里得距离或余弦相似度之类的算法进行搜索。
- 如果余弦相似度 > 0.999,则显示搜索结果;如果没有,请使用上传的图像重新训练模型或调整模型参数并重新运行该过程。
- 为了进一步加快搜索速度,请使用生成的边界框检测上传图像和搜索图像数据库和目录中对象的位置。
上述流程图有几个关键组成部分:
- 模型开发:这包括选择一个合适的预训练模型,删除其顶部附近的层,冻结之前的所有层,并添加一个新的顶层以匹配我们的类。这意味着,如果我们使用在 1,000 个类的 ImageNet 数据集上训练的预训练模型,我们将移除它的顶层并用我们的新顶层替换它,只有 3 个类bed—— 、chair和sofa。
- 模型训练:这涉及首先编译模型,然后开始使用该model.fit()函数进行训练。
- 模型输出:上传的图片和测试图片库中的每张图片都经过模型生成特征向量。上传的图像也用于确定模型类。
- 搜索算法:搜索算法在给定类指定的测试图像文件夹中执行,而不是在整个测试图像集内执行,从而节省时间。搜索算法依赖于 CNN 模型选择的正确类别。如果类匹配不正确,那么最终的视觉搜索将导致不正确的结果。为了解决这个问题,可以采取几个步骤:
- 使用新图像集重新运行模型,增加训练图像大小,或改进模型参数。
- 然而,无论使用多少数据, CNN 模型永远不会有 100% 的准确率。因此,为了解决这个问题,视觉搜索结果通常由文本关键字搜索来补充。例如,客户可能会写道,您能找到一张与上传图片中显示的床相似的床吗?在这种情况下,我们知道上传的类是一张床。这是使用自然语言处理( NLP ) 完成的。
- 解决该问题的另一种方法是针对多个预训练模型运行相同的上传图像,如果类预测彼此不同,则采用模式值。
接下来,我们将详细解释用于视觉搜索的代码。
视觉搜索代码及解释
在本节中,我们将解释用于视觉搜索的 TensorFlow 代码及其功能:
1.首先,我们将为上传的图像指定一个文件夹(共有三个文件夹,我们为每种图像类型切换)。请注意,此处显示的图像只是示例;您的图像可能不同:
#img_path = '/home/…/visual_search/ test/bed/bed1.jpg'
#img_path ='/home/…/visual_search/test/chair/chair1.jpg'
#img_path ='/home/…/visual_search/test/sofa/sofa1.jpg'2.然后,我们将上传图像,将图像转换为数组,并像之前一样对图像进行预处理:
img = image.load_img(img_path, target_size=(224, 224))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)上述代码是在进一步处理之前将图像转换为数组的标准代码。
预测上传图片的类别
上传新图像后,我们的任务将是找出它属于哪个类。为此,我们计算图像可能属于的每个类别的概率,并选择概率最高的类别。此处的示例说明了使用 VGG 预训练模型的计算,但相同的概念适用于其他地方:
vgg_feature = final_model.predict(img_data,verbose=0)
vgg_feature_np = np.array(vgg_feature)
vgg_feature1D = vgg_feature_np.flatten()
print (vgg_feature1D)
y_prob = final_model.predict(img_data)
y_classes = y_prob.argmax(axis=-1)
print (y_classes)model.predict()在前面的代码中,我们使用函数和类名来计算图像属于特定类的概率,probability.argmax用于指示概率最高的类。
预测所有图像的类别
以下函数导入必要的包以从目录中获取文件并进行相似度计算。然后,我们根据上传图像的输入类指定要定位的文件夹:
import os
from scipy.spatial import distance as dist
from sklearn.metrics.pairwise import cosine_similarity
if y_classes == [0]:path = 'furniture_images/val/bed'
elif y_classes == [1]:path = 'furniture_images/val/chair'
else:path = 'furniture_images/val/sofa'以下函数循环遍历测试目录中的每个图像,并将图像转换为一个数组,然后使用该数组来使用训练好的模型预测特征向量:
mindist=10000
maxcosine =0
i=0
for filename in os.listdir(path):image_train = os.path.join(path, filename)i +=1imgtrain = image.load_img(image_train, target_size=(224, 224))img_data_train = image.img_to_array(imgtrain)img_data_train = np.expand_dims(img_data_train, axis=0)img_data_train = preprocess_input(img_data_train)vgg_feature_train = final_model.predict(img_data_train)vgg_feature_np_train = np.array(vgg_feature_train)vgg_feature_train1D = vgg_feature_np_train.flatten()eucldist = dist.euclidean(vgg_feature1D,vgg_feature_train1D)if mindist > eucldist:mindist=eucldistminfilename = filename#print (vgg16_feature_np)dot_product = np.dot(vgg_feature1D,vgg_feature_train1D)#normalize the results, to achieve similarity measures independent #of the scale of the vectorsnorm_Y = np.linalg.norm(vgg_feature1D)norm_X = np.linalg.norm(vgg_feature_train1D)cosine_similarity = dot_product / (norm_X * norm_Y)if maxcosine < cosine_similarity:maxcosine=cosine_similaritycosfilename = filenameprint ("%s filename %f euclediandist %f cosine_similarity" %(filename,eucldist,cosine_similarity))print ("%s minfilename %f mineuclediandist %s cosfilename %f maxcosinesimilarity" %(minfilename,mindist, cosfilename, maxcosine))您可以在前面的代码中观察到以下内容:
- 每个特征向量与上传的图像特征向量进行比较,计算欧几里得距离和余弦相似度。
- 通过确定欧几里得距离的最小值和余弦相似度的最大值来计算图像相似度。
- 确定并显示与最小距离对应的图像文件。
包括迁移学习和视觉搜索在内的完整代码可以在本书的 GitHub存储库中找到,地址为: https ://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter06/ Chapter6_Transferlearning_VisualSearch.ipynb。
下图展示了使用三种不同的模型和两种不同的搜索算法——欧几里得距离和余弦相似度对上传的一张床的图像进行视觉搜索预测:

在上图中,可以观察到以下内容:
- Inception 模型预测了一个不准确的类别,这导致视觉搜索模型预测了错误的类别。
- 请注意,视觉搜索模型无法捕捉到预测错误类别的神经网络。我们还可以使用其他模型检查相同上传图像的类别预测,以查看模式(多数)值——在这种情况下,它是bedResNet 和 VGG 预测bed的,而 Inception 预测sofa的。
- 总而言之,由于我们不知道给定模型是否能正确预测类别,我们推荐的方法是同时使用三个或更多不同的模型来预测上传图像的类别,然后选择具有多数值的预测类别。使用这种方法,我们将增加对预测的信心。
下图显示了使用不同上传图像的预测,这似乎是正确的:

下图显示了使用三种不同的模型和两种不同的搜索算法——欧几里得距离和余弦相似度对上传的椅子图像进行视觉搜索预测:

您可以在上图中观察到以下内容:
- 尽管余弦相似度函数显示的图像与欧几里得距离函数显示的图像不同,但预测在所有情况下都是正确的。
- 两者似乎都非常接近,两种显示方法为我们提供了一种显示多个图像的方法。这意味着如果用户上传一张椅子的图片并想在在线目录中找到类似的椅子,我们的系统将显示两张图片供用户选择,而不是一张图片,这将增加我们销售的机会椅子。如果两幅图像相同,算法将只显示一幅图像,否则将显示两幅图像。另一种选择是使用相同的算法显示前两个匹配项。
下图显示了使用三种不同模型和两种不同搜索算法(欧几里得距离和余弦相似度)对上传的沙发图像进行视觉搜索预测:

您可以在上图中观察到以下内容:
- 尽管余弦相似度函数显示的图像与欧几里得距离函数显示的图像不同,但预测在所有情况下都是正确的。
- 两者似乎都非常接近,两种显示方法为我们提供了一种显示多张图像的方法。如前所述,使用与上传图像相似的两个图像,用户有更多选项可供选择。
使用 tf.data 处理视觉搜索输入管道
TensorFlow tf.dataAPI 是一种高效的数据管道,它处理数据的速度比 Keras 数据输入过程快一个数量级。它在分布式文件系统中聚合数据并对其进行批处理。有关详细信息,请参阅:https ://www.tensorflow.org/guide/data 。
以下屏幕截图显示了tf.data与 Keras 图像输入过程的图像上传时间比较:
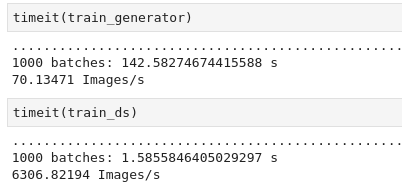
请注意,1000 张图像大约需要 1.58 秒,这比 Keras 图像输入过程快了大约 90 倍。
以下是一些常见的功能tf.data:
- 要使此 API 正常工作,您需要导入该pathlib库。
- tf.data.Dataset.list_files用于创建与模式匹配的所有文件的数据集。
- tf.strings.splot根据分隔符拆分文件路径。
- tf.image.decode_jpeg将 JPEG 图像解码为张量(注意转换不能有文件路径)。
- tf.image.convert_image_dtype将图像转换为 dtype float 32。
以下链接提供了更新的视觉搜索代码:
Mastering-Computer-Vision-with-TensorFlow-2.0/Chapter6_Transferlearning_VisualSearch_tfdata_tensor.ipynb at master · PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0 · GitHub
tf.data如前所述,此代码包括。此外tf.data,它还通过在 中进行以下更改来解冻模型的顶部build_final_model:
layer.trainable = True
layer_adjust = 100
for layer in base_model.layers[:layer_adjust]: layer.trainable = False前面的更改使模型能够在第 100 层之后开始训练,而不是只训练最后几层。此更改提高了准确性,如下图所示:
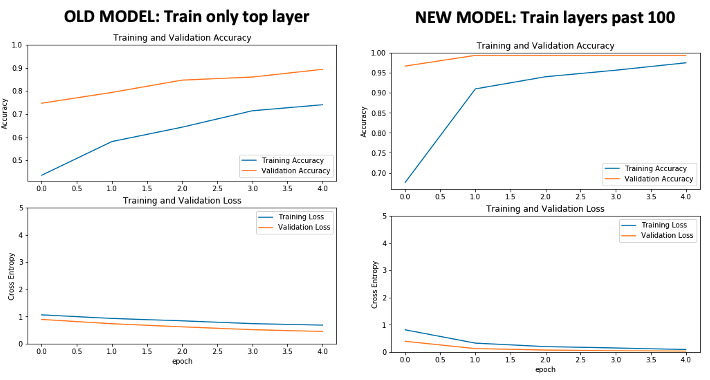
训练需要更多时间,但模型准确率接近 100%,而不是大约 90%。
概括
在本章中,我们学习了如何使用 TensorFlow/Keras 为上一章学习的深度学习模型开发迁移学习代码。我们学习了如何从包含多个类的目录中导入经过训练的图像,并使用它们来训练模型并使用它们进行预测。然后,我们学习了如何保持模型的基础层冻结,移除顶层,并用我们自己的顶层替换它,并用它训练生成的模型。
我们研究了视觉搜索的重要性以及如何使用迁移学习来增强视觉搜索方法。我们的示例包含三种不同类别的家具——我们了解模型的准确性以及如何改善由此产生的损失。在本章中,我们还学习了如何使用 TensorFlowtf.data输入管道在训练期间进行更快的图像处理。