(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
多语言合成与小样本合成技术应用实践
一 简介
1.1 语音合成的简介
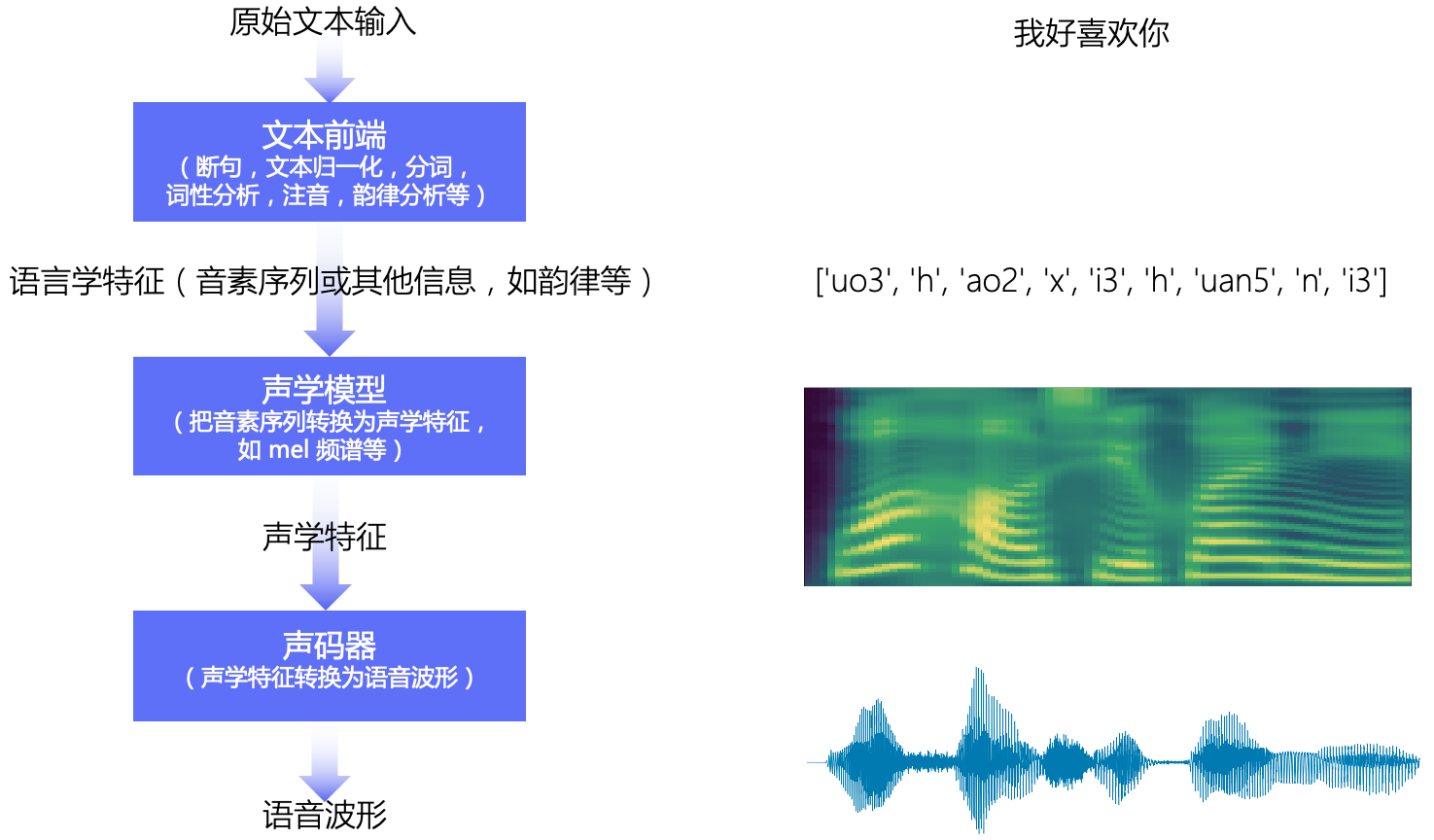
语音合成是一种将文本转换成音频的技术。通常语音合成的整体流程如图1所示。可以分为:文本前端,声学模型,声码器三大模块。
- 文本前端模块将原始文本转换为字符/音素
- 声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等
- 声码器将声学特征转换为波形
1.2 中英混合语音合成的简介
中英混合语音合成指的是给定一个既包含中文又包含英文(也可以只包含中文或英文)的文本,通过语音合成的三大步骤,转换成只包含给定文本的音频的技术。在日常交互中,很多句子会包含中英混合的词汇,比如『GPS 导航』『JAVA 工程师』『深度学习框架 PaddlePaddle』等等。因此中英混合的语音合成技术在各种交互场景中有较大的需求。常见的两类中英混合语音合成的方案如下:
【数据层面】
1、单人双语数据
- 同一发音人录制中文、英文、中英混合音频
- 优点:合成的中英混合音频可具有较高质量
- 缺点:数据的采集难度大(对发音人要求高),合成音频仅一个音色
2、多人数据
- 多个发音人,每个发音人仅录制中文,英文二种语言中的一种语言的音频
- 优点:数据采集难度降低;合成的中英混合音频可选择多种音色(录制音频的所有发音人)
- 缺点:相对使用单人双语数据训练的模型,合成音频的质量稍微略低
【技术层面】
- 将文本信息和音色信息尽可能分离开,然后额外加入音色信息去合成音频声学特征(mel谱)
- 将中文音素和英文音素统一映射到国际音标上,相当于将两种语言合成了一种新的语言
由于数据的受限,本次直播课主要讲述基于多人数据的中英混合方案和效果。后续我们会考虑从技术层面去持续优化合成效果。
1.3 小样本合成的简介
小样本合成指的是使用少量某个说话人的数据(音频和标注)来训练一个模型,使用该模型可以合成该说话人音色的音频的技术。近年来,很多应用都开始支持自定义音色,即合成具有某一特定音色的音频(个性化合成),该功能能够大幅度地提升应用的趣味性和吸引力。个性化合成的几类方案如下:
【全新模型训练】
1、特定发音人全量数据
- 录制特定说话人全量数据,类似于 csmsc / ljspeech
- 优点:合成的音频可具有高音频质量和音色相似度
- 缺点:录制数据量大,10小时以上;训练模型时间长
2、特定发音人几百条数据
- 录制特定说话人几百条数据,类似于 aishell3 / vctk 某个发音人
- 优点:合成的音频可具有较高音色相似度
- 缺点:训练模型时间长;音频质量取决于其他发音人的音频质量
【使用预训练模型】
1、小样本微调
- 录制特定说话人少量数据(当前方案尝试的数据量在200条以下)
- 优点:录制音频数量较少,更方便应用;训练模型所需耗时短;合成的音频可具有不错的音频质量和音色相似度
- 缺点:音色相似度和音频质量比不上【全新模型训练】下 特定发音人全量数据 方案效果
2、单条数据 voice clone
- 仅需录制一条特定说话人的音频
- 优点:录制音频仅一条,无需重新训练模型
- 缺点:音色相似度和音频质量比不上上述几种方案
本次直播课主要讲述小样本微调方案,仅需少量数据可快速实现合成具有较高音频质量和音色相似度的音频。
二 中英混合语音合成
本次直播课主要描述在多个说话人,每个说话人仅说单种语言(中文或英文)的数据集上的中英混合语音合成方案,基本流程如图2所示。使用多说话人数据集进行训练用于解决音色不一致问题;文本前端在中文段和英文段之间加入 sp 用于解决粘连问题。

!wget https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/zh_en_demos/001_csmsc_ljspeech.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/zh_en_demos/001_csmsc_ljspeech_add.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/zh_en_demos/001_four_datasets.wav
import IPython.display as dp
dp.Audio("./001_csmsc_ljspeech.wav")
dp.Audio("./001_csmsc_ljspeech_add.wav")
dp.Audio("./001_four_datasets.wav")
2.1 数据准备
| 语言 | 数据集 | 音频信息 | 描述 |
|---|---|---|---|
| 中文 | CSMSC | 48KHz, 16bit | 单说话人,女声,约12小时,具有高音频质量 |
| 中文 | AISHELL-3 | 44.1kHz,16bit | 多说话人(218人),约85小时,音频质量不一致(有的说话人音频质量较高) |
| 英文 | LJSpeech-1.1 | 22050Hz, 16bit | 单说话人,女声,约24小时,具有高音频质量 |
| 英文 | VCTK | 48kHz, 16bit | 多说话人(110人), 约44小时,音频质量不一致(有的说话人音频质量较高) |
2.2 模型训练
训练声学模型:使用上述数据训练 fastspeech2 的24KHz模型;预训练声码器:使用aishell3 训练的 HiFiGAN 模型。
首先到中英混合语音合成示例目录下。
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
cd PaddleSpeech/examples/zh_en_tts/tts3
根据 README.md, 下载数据集和其对应的强制对齐文件, 并放置在对应的位置。
./run.sh
run.sh 包含预处理、训练、合成、静态图推理等步骤:
#!/bin/bashset -e
source path.shgpus=0,1
stage=0
stop_stage=100datasets_root_dir=~/datasets
mfa_root_dir=./mfa_results/
conf_path=conf/default.yaml
train_output_path=exp/default
ckpt_name=snapshot_iter_99200.pdz# with the following command, you can choose the stage range you want to run
# such as `./run.sh --stage 0 --stop-stage 0`
# this can not be mixed use with `$1`, `$2` ...
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then# prepare data./local/preprocess.sh ${conf_path} ${datasets_root_dir} ${mfa_root_dir} || exit -1
fiif [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then# train model, all `ckpt` under `train_output_path/checkpoints/` dirCUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${train_output_path} || exit -1
fiif [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; then# synthesize, vocoder is pwgan by defaultCUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
fiif [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then# synthesize_e2e, vocoder is pwgan by defaultCUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
fiif [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then# inference with static model, vocoder is pwgan by defaultCUDA_VISIBLE_DEVICES=${gpus} ./local/inference.sh ${train_output_path} || exit -1
fiif [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then# install paddle2onnxversion=$(echo `pip list |grep "paddle2onnx"` |awk -F" " '{print $2}')if [[ -z "$version" || ${version} != '1.0.0' ]]; thenpip install paddle2onnx==1.0.0fi./local/paddle2onnx.sh ${train_output_path} inference inference_onnx fastspeech2_mix# considering the balance between speed and quality, we recommend that you use hifigan as vocoder./local/paddle2onnx.sh ${train_output_path} inference inference_onnx hifigan_aishell3
fi# inference with onnxruntime, use fastspeech2 + pwgan by default
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then./local/ort_predict.sh ${train_output_path}
fi
./run.sh --stage 0 --stop_stage 0 表示执行数据预处理步骤:
#!/bin/bashstage=0
stop_stage=100config_path=$1
datasets_root_dir=$2
mfa_root_dir=$3# 1. get durations from MFA's result
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; thenecho "Generate durations_baker.txt from MFA results ..."python3 ${MAIN_ROOT}/utils/gen_duration_from_textgrid.py \--inputdir=${mfa_root_dir}/baker_alignment_tone \--output durations_baker.txt \--config=${config_path}
fiif [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; thenecho "Generate durations_ljspeech.txt from MFA results ..."python3 ${MAIN_ROOT}/utils/gen_duration_from_textgrid.py \--inputdir=${mfa_root_dir}/ljspeech_alignment \--output durations_ljspeech.txt \--config=${config_path}
fiif [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; thenecho "Generate durations_aishell3.txt from MFA results ..."python3 ${MAIN_ROOT}/utils/gen_duration_from_textgrid.py \--inputdir=${mfa_root_dir}/aishell3_alignment_tone \--output durations_aishell3.txt \--config=${config_path}
fiif [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; thenecho "Generate durations_vctk.txt from MFA results ..."python3 ${MAIN_ROOT}/utils/gen_duration_from_textgrid.py \--inputdir=${mfa_root_dir}/vctk_alignment \--output durations_vctk.txt \--config=${config_path}
fiif [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then# concat duration fileecho "concat durations_baker.txt, durations_ljspeech.txt, durations_aishell3.txt and durations_vctk.txt to durations.txt"cat durations_baker.txt durations_ljspeech.txt durations_aishell3.txt durations_vctk.txt > durations.txt
fi# 2. extract features
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; thenecho "Extract baker features ..."python3 ${BIN_DIR}/preprocess.py \--dataset=baker \--rootdir=${datasets_root_dir}/BZNSYP/ \--dumpdir=dump \--dur-file=durations.txt \--config=${config_path} \--num-cpu=20 \--cut-sil=True \--write_metadata_method=a
fiif [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; thenecho "Extract ljspeech features ..."python3 ${BIN_DIR}/preprocess.py \--dataset=ljspeech \--rootdir=${datasets_root_dir}/LJSpeech-1.1/ \--dumpdir=dump \--dur-file=durations.txt \--config=${config_path} \--num-cpu=20 \--cut-sil=True \--write_metadata_method=a
fiif [ ${stage} -le 7 ] && [ ${stop_stage} -ge 7 ]; thenecho "Extract aishell3 features ..."python3 ${BIN_DIR}/preprocess.py \--dataset=aishell3 \--rootdir=${datasets_root_dir}/data_aishell3/ \--dumpdir=dump \--dur-file=durations.txt \--config=${config_path} \--num-cpu=20 \--cut-sil=True \--write_metadata_method=a
fiif [ ${stage} -le 8 ] && [ ${stop_stage} -ge 8 ]; thenecho "Extract vctk features ..."python3 ${BIN_DIR}/preprocess.py \--dataset=vctk \--rootdir=${datasets_root_dir}/VCTK-Corpus-0.92/ \--dumpdir=dump \--dur-file=durations.txt \--config=${config_path} \--num-cpu=20 \--cut-sil=True \--write_metadata_method=a
fi# 3. get features' stats(mean and std)
if [ ${stage} -le 9 ] && [ ${stop_stage} -ge 9 ]; thenecho "Get features' stats ..."python3 ${MAIN_ROOT}/utils/compute_statistics.py \--metadata=dump/train/raw/metadata.jsonl \--field-name="speech"python3 ${MAIN_ROOT}/utils/compute_statistics.py \--metadata=dump/train/raw/metadata.jsonl \--field-name="pitch"python3 ${MAIN_ROOT}/utils/compute_statistics.py \--metadata=dump/train/raw/metadata.jsonl \--field-name="energy"
fi# 4. normalize and covert phone/speaker to id, dev and test should use train's stats
if [ ${stage} -le 10 ] && [ ${stop_stage} -ge 10 ]; thenecho "Normalize ..."python3 ${BIN_DIR}/normalize.py \--metadata=dump/train/raw/metadata.jsonl \--dumpdir=dump/train/norm \--speech-stats=dump/train/speech_stats.npy \--pitch-stats=dump/train/pitch_stats.npy \--energy-stats=dump/train/energy_stats.npy \--phones-dict=dump/phone_id_map.txt \--speaker-dict=dump/speaker_id_map.txtpython3 ${BIN_DIR}/normalize.py \--metadata=dump/dev/raw/metadata.jsonl \--dumpdir=dump/dev/norm \--speech-stats=dump/train/speech_stats.npy \--pitch-stats=dump/train/pitch_stats.npy \--energy-stats=dump/train/energy_stats.npy \--phones-dict=dump/phone_id_map.txt \--speaker-dict=dump/speaker_id_map.txtpython3 ${BIN_DIR}/normalize.py \--metadata=dump/test/raw/metadata.jsonl \--dumpdir=dump/test/norm \--speech-stats=dump/train/speech_stats.npy \--pitch-stats=dump/train/pitch_stats.npy \--energy-stats=dump/train/energy_stats.npy \--phones-dict=dump/phone_id_map.txt \--speaker-dict=dump/speaker_id_map.txt
fi
2.3 文本前端的设计
中英混合语音合成的文本前端在paddlespeech/t2s/frontend/mix_frontend.py。
安装 paddlespeech
from IPython.display import clear_output
!pip install paddlespeech==1.2.0
# 清理很长的内容
clear_output()
# 本项目的依赖需要用到 nltk 包,但是有时会因为网络原因导致不好下载,此处手动下载一下放到百度服务器的包
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz
clear_output()
获取预训练模型和数据
!wget -P download https://paddlespeech.bj.bcebos.com/t2s/chinse_english_mixed/models/fastspeech2_mix_ckpt_1.2.0.zip
!unzip -o -d download download/fastspeech2_mix_ckpt_1.2.0.zip
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_aishell3_ckpt_0.2.0.zip
!unzip -o -d download download/hifigan_aishell3_ckpt_0.2.0.zip
clear_output()
1. 将文本进行中英文分段
from paddlespeech.t2s.frontend.mix_frontend import MixFrontend
phone_vocab_path = "download/fastspeech2_mix_ckpt_1.2.0/phone_id_map.txt"
frontend = MixFrontend(phone_vocab_path=phone_vocab_path)text = "我有一本书,名字叫《The Little Prince》. 这本书售价15.8元。"
segments = frontend.get_segment(text)
print(segments)
2. 每一段分别传入对应的文本前端
from paddlespeech.t2s.frontend.mix_frontend import MixFrontend
import paddlephone_vocab_path = "download/fastspeech2_mix_ckpt_1.2.0/phone_id_map.txt"
frontend = MixFrontend(phone_vocab_path=phone_vocab_path)segments = [('我有一本书,名字叫《', 'zh'), ('The Little Prince》. ', 'en'), ('这本书售价15.8元。', 'zh')]
add_sp = True
phones_list = []for seg in segments:content = seg[0]lang = seg[1]if content != '':if lang == "en":input_ids = frontend.en_frontend.get_input_ids(content, merge_sentences=False, to_tensor=True)else:input_ids = frontend.zh_frontend.get_input_ids(content,merge_sentences=False,get_tone_ids=False,to_tensor=True)if add_sp:input_ids["phone_ids"][-1] = paddle.concat([input_ids["phone_ids"][-1], frontend.sp_id_tensor])for phones in input_ids["phone_ids"]:phones_list.append(phones)
print("length: ", len(phones_list))
print(phones_list)
2.4 推理
文本前端 --> 声学模型推理 --> 声码器推理
import paddle
import yaml
import soundfile as sf
from yacs.config import CfgNode
from paddlespeech.t2s.frontend.mix_frontend import MixFrontend
from paddlespeech.t2s.exps.syn_utils import get_am_inference
from paddlespeech.t2s.exps.syn_utils import get_voc_inference
from paddlespeech.t2s.exps.syn_utils import run_frontendsentence = "我有一本书,名字叫《The Little Prince》. 这本书售价15.8元。"# text frontend
phones_dict = "download/fastspeech2_mix_ckpt_1.2.0/phone_id_map.txt"
frontend = MixFrontend(phone_vocab_path=phones_dict)
print("frontend done!")# load AM
am_config_file = "download/fastspeech2_mix_ckpt_1.2.0/default.yaml"
am_ckpt = "download/fastspeech2_mix_ckpt_1.2.0/snapshot_iter_99200.pdz"
am_stat = "download/fastspeech2_mix_ckpt_1.2.0/speech_stats.npy"
speaker_dict = "download/fastspeech2_mix_ckpt_1.2.0/speaker_id_map.txt"
with open(am_config_file) as f:am_config = CfgNode(yaml.safe_load(f))
am_inference = get_am_inference(am="fastspeech2_mix",am_config=am_config,am_ckpt=am_ckpt,am_stat=am_stat,phones_dict=phones_dict,tones_dict=None,speaker_dict=speaker_dict)
print("acoustic model done!")# load Voc
voc_config_file = "download/hifigan_aishell3_ckpt_0.2.0/default.yaml"
voc_ckpt = "download/hifigan_aishell3_ckpt_0.2.0/snapshot_iter_2500000.pdz"
voc_stat = "download/hifigan_aishell3_ckpt_0.2.0/feats_stats.npy"
with open(voc_config_file) as f:voc_config = CfgNode(yaml.safe_load(f))
voc_inference = get_voc_inference(voc="hifigan_aishell3",voc_config=voc_config,voc_ckpt=voc_ckpt,voc_stat=voc_stat)
print("voc done!")# get phone id
frontend_dict = run_frontend(frontend=frontend,text=sentence,merge_sentences=False,get_tone_ids=False,lang="mix")
phone_ids = frontend_dict['phone_ids']# inference
flags = 0
for i in range(len(phone_ids)):part_phone_ids = phone_ids[i]spk_id = 174 # baker:174, ljspeech:175, aishell3:0~173, vctk:176~282spk_id = paddle.to_tensor(spk_id)mel = am_inference(part_phone_ids, spk_id)wav = voc_inference(mel)if flags == 0:wav_all = wavflags = 1else:wav_all = paddle.concat([wav_all, wav])
print("infer successfully.")# save audio
wav = wav_all.numpy()
sf.write("./out.wav", wav, am_config.fs)# play audio
import IPython.display as dp
dp.Audio(wav.T, rate=am_config.fs)
三 小样本合成
本次直播课主要描述在小数据量(小于200条训练样本)上进行特定说话人的语音合成方案。该方案的具体流程如图3所示。我们在预训练模型上采用微调的方式去训练一个新的声学模型(fastspeech2),该声学模型可以生成与训练样本同一音色的音频mel谱。
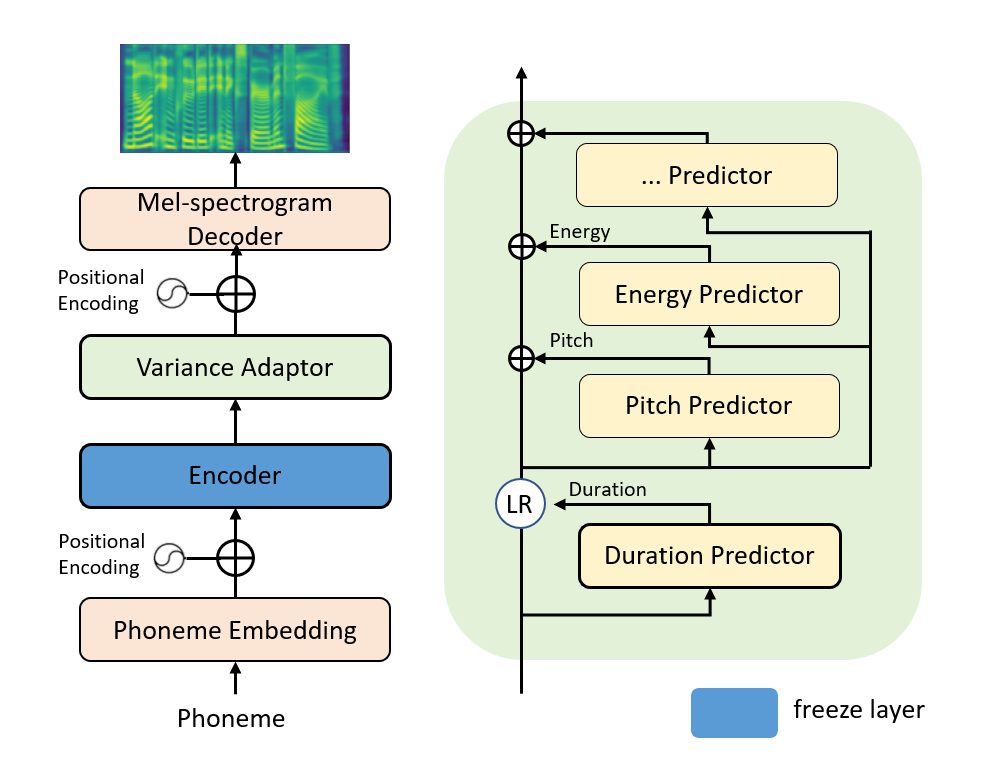
3.1 数据准备
训练数据包含高质量的音频数条以及对应的标签文件。音频数据的质量决定声学模型的效果。
-
音频数据
音频质量:高质量,无噪声,高采样率(要求大于等于与训练模型的采样率24000)
音频格式:wav 格式音频,音频时长在5s左右(一句话的时长) -
标签文件
格式:音频名(去掉格式后缀)|拼音(中文)/单词(英文)
中文示例:000001|ka2 er2 pu3 pei2 wai4 sun1 wan2 hua2 ti1
英文示例:LJ001-0001|Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition
3.2 模型训练
首先到小样本合成的示例目录下。根据README准备好数据,预训练模型,执行 run.sh 即可开始训练。
#!/bin/bashset -e
source path.shinput_dir=./input/csmsc_mini
newdir_name="newdir"
new_dir=${input_dir}/${newdir_name}
pretrained_model_dir=./pretrained_models/fastspeech2_aishell3_ckpt_1.1.0
mfa_tools=./tools
mfa_dir=./mfa_result
dump_dir=./dump
output_dir=./exp/default
lang=zh
ngpu=1
finetune_config=./conf/finetune.yamlckpt=snapshot_iter_96699gpus=1
CUDA_VISIBLE_DEVICES=${gpus}
stage=0
stop_stage=100# with the following command, you can choose the stage range you want to run
# such as `./run.sh --stage 0 --stop-stage 0`
# this can not be mixed use with `$1`, `$2` ...
source ${MAIN_ROOT}/utils/parse_options.sh || exit 1# check oov
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; thenecho "check oov"python3 local/check_oov.py \--input_dir=${input_dir} \--pretrained_model_dir=${pretrained_model_dir} \--newdir_name=${newdir_name} \--lang=${lang}
fi# get mfa result
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; thenecho "get mfa result"python3 local/get_mfa_result.py \--input_dir=${new_dir} \--mfa_dir=${mfa_dir} \--lang=${lang}
fi# generate durations.txt
if [ ${stage} -le 2 ] && [ ${stop_stage} -ge 2 ]; thenecho "generate durations.txt"python3 local/generate_duration.py \--mfa_dir=${mfa_dir}
fi# extract feature
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; thenecho "extract feature"python3 local/extract_feature.py \--duration_file="./durations.txt" \--input_dir=${new_dir} \--dump_dir=${dump_dir} \--pretrained_model_dir=${pretrained_model_dir}
fi# create finetune env
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; thenecho "create finetune env"python3 local/prepare_env.py \--pretrained_model_dir=${pretrained_model_dir} \--output_dir=${output_dir}
fi# finetune
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; thenecho "finetune..."python3 local/finetune.py \--pretrained_model_dir=${pretrained_model_dir} \--dump_dir=${dump_dir} \--output_dir=${output_dir} \--ngpu=${ngpu} \--epoch=100 \--finetune_config=${finetune_config}
fi# synthesize e2e
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; thenecho "in hifigan syn_e2e"python3 ${BIN_DIR}/../synthesize_e2e.py \--am=fastspeech2_aishell3 \--am_config=${pretrained_model_dir}/default.yaml \--am_ckpt=${output_dir}/checkpoints/${ckpt}.pdz \--am_stat=${pretrained_model_dir}/speech_stats.npy \--voc=hifigan_aishell3 \--voc_config=pretrained_models/hifigan_aishell3_ckpt_0.2.0/default.yaml \--voc_ckpt=pretrained_models/hifigan_aishell3_ckpt_0.2.0/snapshot_iter_2500000.pdz \--voc_stat=pretrained_models/hifigan_aishell3_ckpt_0.2.0/feats_stats.npy \--lang=zh \--text=${BIN_DIR}/../sentences.txt \--output_dir=./test_e2e/ \--phones_dict=${dump_dir}/phone_id_map.txt \--speaker_dict=${dump_dir}/speaker_id_map.txt \--spk_id=0
fi
3.3 调优策略的说明
由于我们进行微调的数据量远远小于预训练模型的训练数据量,因此很多训练参数需要做对应的修改和调整。我们将常用于修改的的训练参数单独存放在 conf/finetune.yaml,如下:
###########################################################
# PARAS SETTING #
###########################################################
# Set to -1 to indicate that the parameter is the same as the pretrained model configurationbatch_size: -1
learning_rate: 0.0001 # learning rate
num_snapshots: -1# frozen_layers should be a list
# if you don't need to freeze, set frozen_layers to []
# fastspeech2 layers can be found on conf/fastspeech2_layers.txt
# example: frozen_layers: ["encoder", "duration_predictor"]
frozen_layers: ["encoder"]
【一些经验结论】
- batch_size 在内存足够的情况下可以尽量大
- learning_rate 微调需要比预训练模型的lr(0.001)小
- num_snapshots 可以调整用于多保存些模型,可查看合成效果(loss 指标不是唯一标准,并且训练步数太多也可能过拟合)
- frozen_layers 数据量比较小的情况下可以冻结一些层的参数,通常冻结与输入近的层
fastspeech2 的模型层信息我们也放到了 conf/fastspeech2_layers.txt 中,后续大家感兴趣可以尝试冻结其他层查看效果。
感谢开发者编写的finetune教学文档:训练一个自己的TTS模型
感谢开发者的finetune经验分享:多种卡通音色和方言的中英文混合
我们的基于CSMSC数据的更多实验结果:Finetune FastSpeech2 for CSMSC
3.4 效果展示
尝试使用自己的录音(朋友的音色)finetune 中英文混合语音合成
!wget https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/zh_en_demos/000001.wav
!wget https://paddlespeech.bj.bcebos.com/Parakeet/docs/demos/zh_en_demos/001_lili.wav
# 训练样本示例
import IPython.display as dp
dp.Audio("./000001.wav")
# 合成音频
import IPython.display as dp
dp.Audio("./001_lili.wav")
目前我们有一个前端页面的demo示例,大家可以根据README去搭建一个网页,然后在页面上可以比较快速的去合成自己的声音,
关注 PaddleSpeech
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:
- 扫描二维码
- 添加运营小姐姐微信
- 通过后回复【语音】
- 系统自动邀请加入技术群

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。