文章篇幅较长,可以先收藏防止迷路~
目录
- zap日志库
- 1. why zap?
- 2. 简单使用
- 3. 自定义logger例子
- 4. Gin项目使用zap
- 6. lumberjack 日志切割组件
zap日志库
在许多Go语言项目中,我们需要一个好的日志记录器能够提供下面这些功能:
- 能够将事件记录到文件中,而不是应用程序控制台;
- 日志切割-能够根据文件大小、时间或间隔等来切割日志文件;
- 支持不同的日志级别。例如INFO,DEBUG,ERROR等;
- 能够打印基本信息,如调用文件/函数名和行号,日志时间等;
1. why zap?
-
比较全的日志级别
-
支持结构化日志
-
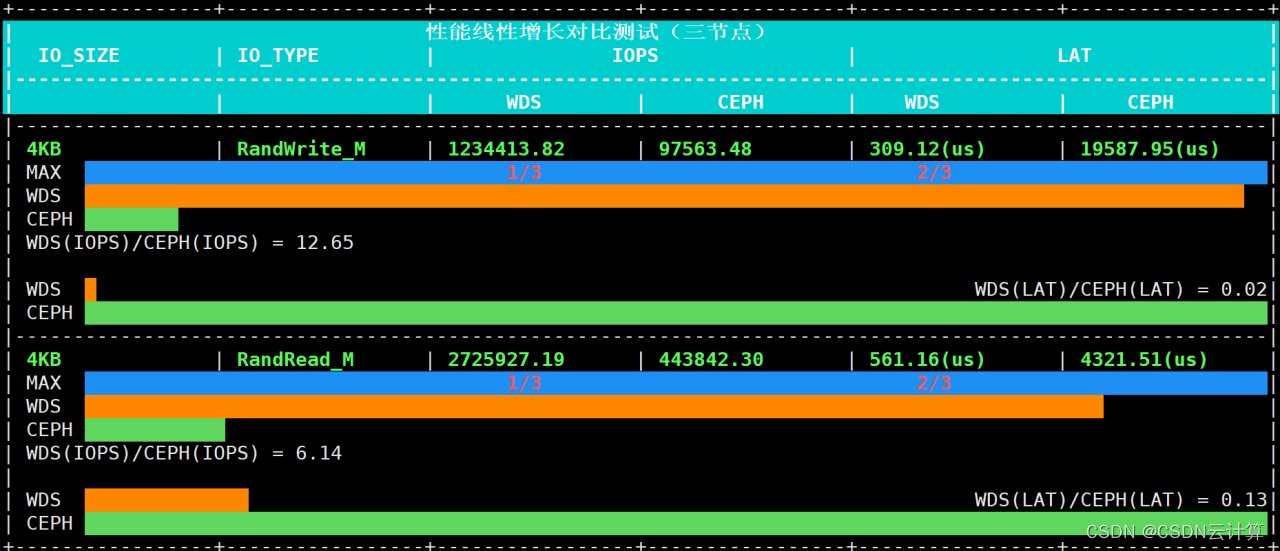
性能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RKcZFu8o-1662037156664)(images/image-20220901184049353.png)]](https://img-blog.csdnimg.cn/0c81f59697834c86bdb7eb29e689ff17.png)
2. 简单使用
go get -u go.uber.org/zap
Zap提供了两种类型的日志记录器 — Sugared Logger 和 Logger
-
Sugared Logger并重性能与易用性,支持结构化和printf风格的日志记录。 -
Logger非常强调性能,不提供 printf 风格的 api (减少了 interface{} 与 反射的性能损耗),如下例子:func main() {// sugaredsugar := zap.NewExample().Sugar()sugar.Infof("hello! name:%s,age:%d", "xiaomin", 20) // printf 风格,易用性// loggerlogger := zap.NewExample()logger.Info("hello!", zap.String("name", "xiaomin"), zap.Int("age", 20)) // 强调性能 }输出结果:
// output {"level":"info","msg":"hello! name:xiaomin,age:20"} {"level":"info","msg":"hello!","name":"xiaomin","age":20}
zap 有三种默认配置创建出一个 logger,分别为 example,development,production,示例:
func main() {// examplelogger := zap.NewExample()logger.Info("example")// Developmentlogger,_ = zap.NewDevelopment()logger.Info("Development")// Productionlogger,_ = zap.NewProduction()logger.Info("Production")
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qbe0kc6L-1662037156665)(images/image-20220901184439347.png)]](https://img-blog.csdnimg.cn/213ce6894ac04054a3bacdf246826c33.png)
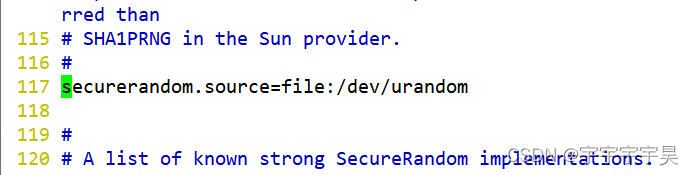
可以看出:日志等级,日志输出格式,默认字段都有所差异。
也可以自定义 logger,如下:
func main() {encoder := getEncoder()sync := getWriteSync()core := zapcore.NewCore(encoder, sync, zapcore.InfoLevel)logger := zap.New(core)logger.Info("info 日志",zap.Int("line", 1))logger.Error("info 日志", zap.Int("line", 2))
}// 负责设置 encoding 的日志格式
func getEncoder() zapcore.Encoder {return zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
}// 负责日志写入的位置
func getWriteSync() zapcore.WriteSyncer {file, _ := os.OpenFile("./log.txt", os.O_CREATE|os.O_APPEND|os.O_RDWR, os.ModePerm)syncFile := zapcore.AddSync(file)syncConsole := zapcore.AddSync(os.Stderr)return zapcore.NewMultiWriteSyncer(syncConsole, syncFile)
}
运行结果:
// output
// 创建 log.txt,追加日志
// console 打印日志
//{"level":"info","ts":1636471657.16419,"msg":"info 日志","line":1}
//{"level":"error","ts":1636471657.1643898,"msg":"info 日志","line":2}
从 New(core zapcore.Core, options ...Option) *Logger 出发,需要构造 zapcore.Core
- 通过
NewCore(enc Encoder, ws WriteSyncer, enab LevelEnabler) Core方法,又需要传入三个参数Encoder: 负责设置 encoding 的日志格式, 可以设置 json 或者 text结构,也可以自定义json中 key 值,时间格式…ws WriteSyncer: 负责日志写入的位置,上述例子往 file 与 console 同时写入,这里也可以写入网络。LevelEnabler: 设置日志记录级别
3. 自定义logger例子
./util/zap.go
-
定义结构体:
package utilimport ("net""net/http""net/http/httputil""os""runtime/debug""strings""time""github.com/gin-gonic/gin""github.com/natefinch/lumberjack""go.uber.org/zap""go.uber.org/zap/zapcore" )type LogConfig struct {Level string `json:"level"` // Level 最低日志等级,DEBUG<INFO<WARN<ERROR<FATAL 例如:info-->收集info等级以上的日志FileName string `json:"file_name"` // FileName 日志文件位置MaxSize int `json:"max_size"` // MaxSize 进行切割之前,日志文件的最大大小(MB为单位),默认为100MBMaxAge int `json:"max_age"` // MaxAge 是根据文件名中编码的时间戳保留旧日志文件的最大天数。MaxBackups int `json:"max_backups"` // MaxBackups 是要保留的旧日志文件的最大数量。默认是保留所有旧的日志文件(尽管 MaxAge 可能仍会导致它们被删除。) } -
日志配置:
var logger *zap.Logger// 负责设置 encoding 的日志格式 func getEncoder() zapcore.Encoder {// 获取一个指定的的EncoderConfig,进行自定义encodeConfig := zap.NewProductionEncoderConfig()// 设置每个日志条目使用的键。如果有任何键为空,则省略该条目的部分。// 序列化时间。eg: 2022-09-01T19:11:35.921+0800encodeConfig.EncodeTime = zapcore.ISO8601TimeEncoder// "time":"2022-09-01T19:11:35.921+0800"encodeConfig.TimeKey = "time"// 将Level序列化为全大写字符串。例如,将info level序列化为INFO。encodeConfig.EncodeLevel = zapcore.CapitalLevelEncoder// 以 package/file:行 的格式 序列化调用程序,从完整路径中删除除最后一个目录外的所有目录。encodeConfig.EncodeCaller = zapcore.ShortCallerEncoderreturn zapcore.NewJSONEncoder(encodeConfig) }// 负责日志写入的位置 func getLogWriter(filename string, maxsize, maxBackup, maxAge int) zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: filename, // 文件位置MaxSize: maxsize, // 进行切割之前,日志文件的最大大小(MB为单位)MaxAge: maxAge, // 保留旧文件的最大天数MaxBackups: maxBackup, // 保留旧文件的最大个数Compress: false, // 是否压缩/归档旧文件}// AddSync 将 io.Writer 转换为 WriteSyncer。// 它试图变得智能:如果 io.Writer 的具体类型实现了 WriteSyncer,我们将使用现有的 Sync 方法。// 如果没有,我们将添加一个无操作同步。return zapcore.AddSync(lumberJackLogger) }// InitLogger 初始化Logger func InitLogger(lCfg LogConfig) (err error) {// 获取日志写入位置writeSyncer := getLogWriter(lCfg.FileName, lCfg.MaxSize, lCfg.MaxBackups, lCfg.MaxAge)// 获取日志编码格式encoder := getEncoder()// 获取日志最低等级,即>=该等级,才会被写入。var l = new(zapcore.Level)err = l.UnmarshalText([]byte(lCfg.Level))if err != nil {return}// 创建一个将日志写入 WriteSyncer 的核心。core := zapcore.NewCore(encoder, writeSyncer, l)logger = zap.New(core, zap.AddCaller())// 替换zap包中全局的logger实例,后续在其他包中只需使用zap.L()调用即可zap.ReplaceGlobals(logger) return }函数解释:
-
getEncoder():负责设置 encoding 的日志格式,如果看不懂上面代码里的注释,可以结合这里的例子理解每一步的作用:encodeConfig := zap.NewProductionEncoderConfig() // 打印格式: {"level":"info","ts":1662032576.6267354,"msg":"test","line":1}encodeConfig.EncodeTime = zapcore.ISO8601TimeEncoder // 打印格式:{"level":"info","ts":"2022-09-01T19:43:07.178+0800","msg":"test","line":1}encodeConfig.TimeKey = "time" // 打印格式:{"level":"info","time":"2022-09-01T19:43:20.558+0800","msg":"test","line":1}encodeConfig.EncodeLevel = zapcore.CapitalLevelEncoder // 打印格式:{"level":"INFO","time":"2022-09-01T19:43:41.192+0800","msg":"test","line":1}encodeConfig.EncodeCaller = zapcore.ShortCallerEncoder // 打印格式:{"level":"INFO","time":"2022-09-01T19:41:39.819+0800","caller":"test/test.go:20","msg":"test","line":1} // 这个需要注意,是要结合 logger := zap.New(core, zap.AddCaller()),一起使用的 -
getLogWriter(filename string, maxsize, maxBackup, maxAge int):负责日志写入的位置关于
lumberjack.Logger,下面会单独讲述,这里只需要知道这个函数的作用是设置日志写入的位置即可。如果同时想要打印到文件和控制台可以这样:
syncFile := zapcore.AddSync(lumberJackLogger) // 打印到文件 syncConsole := zapcore.AddSync(os.Stderr) // 打印到控制台 return zapcore.NewMultiWriteSyncer(syncFile, syncConsole) -
InitLogger(lCfg LogConfig):初始化Logger-
getLogWriter和getEncoder刚才已经讲过了,这里不再赘述; -
UnmarshalText(),我们lCfg.Level是string类型,而这个方法就是可以通过string解码出对应的zapcore.Level类型,我们查看源码可以看到,这个类型其实是int8类型的别名:type Level int8 const (DebugLevel Level = iota - 1InfoLevelWarnLevel ... )例如,我们的
lCfg.Level="debug",l.UnmarshalText([]byte(lCfg.Level))解析后,此时l的日志等级就是DebugLevel -
AddCaller():将 Logger 配置为 使用 zap 的 调用者 的 文件名、行号和函数名注释每条消息。{"level":"INFO","time":"2022-09-01T19:41:39.819+0800","caller":"test/test.go:20","msg":"test","line":1}
-
-
ReplaceGlobals():替换zap包中全局的logger实例,后续在其他包中只需使用zap.L()调用即可;
-
测试:
main.go
package mainimport ("fmt""ginstudy02/util""net/http""go.uber.org/zap"
)func main() {lc := util.LogConfig{Level: "debug",FileName: fmt.Sprintf("./log/%v.log", time.Now().Unix()),MaxSize: 1,MaxBackups: 5,MaxAge: 30,}err := util.InitLogger(lc)if err != nil {fmt.Println(err)}// L():获取全局loggerlogger := zap.L()// 调用内核的Sync方法,刷新所有缓冲的日志条目。// 应用程序应该注意在退出之前调用Sync。defer logger.Sync()simpleHttpGet(logger, "www.sogo.com")simpleHttpGet(logger, "http://www.sogo.com")
}func simpleHttpGet(logger *zap.Logger, url string) {sugarLogger := logger.Sugar()sugarLogger.Debugf("Trying to hit GET request for %s", url)resp, err := http.Get(url)if err != nil {sugarLogger.Errorf("Error fetching URL %s : Error = %s", url, err)} else {sugarLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)resp.Body.Close()}
}
执行结果:
./log/1662027710.log
{"level":"DEBUG","time":"2022-09-01T17:46:58.378+0800","caller":"ginstudy02/main.go:53","msg":"Trying to hit GET request for www.sogo.com"}
{"level":"ERROR","time":"2022-09-01T17:46:58.393+0800","caller":"ginstudy02/main.go:56","msg":"Error fetching URL www.sogo.com : Error = Get \"www.sogo.com\": unsupported protocol scheme \"\""}
{"level":"DEBUG","time":"2022-09-01T17:46:58.393+0800","caller":"ginstudy02/main.go:53","msg":"Trying to hit GET request for http://www.sogo.com"}
{"level":"INFO","time":"2022-09-01T17:46:58.681+0800","caller":"ginstudy02/main.go:58","msg":"Success! statusCode = 200 OK for URL http://www.sogo.com"}
可以看到这里是json格式的,是因为我们在getEncoder()中返回的是一个JSON Encoder的编码器,现在,我们希望将编码器从JSON Encoder更改为普通Encoder。为此,我们需要将NewJSONEncoder()更改为NewConsoleEncoder();
//return zapcore.NewJSONEncoder(encodeConfig)
return zapcore.NewConsoleEncoder(encodeConfig)
再次运行:
2022-09-01T17:53:09.870+0800 DEBUG ginstudy02/main.go:53 Trying to hit GET request for www.sogo.com
2022-09-01T17:53:09.887+0800 ERROR ginstudy02/main.go:56 Error fetching URL www.sogo.com : Error = Get "www.sogo.com": unsupported protocol scheme ""
2022-09-01T17:53:09.887+0800 DEBUG ginstudy02/main.go:53 Trying to hit GET request for http://www.sogo.com
2022-09-01T17:53:10.145+0800 INFO ginstudy02/main.go:58 Success! statusCode = 200 OK for URL http://www.sogo.com
4. Gin项目使用zap
util/zap.go
在上面的代码的基础上,添加下面两个中间件:
// GinLogger 接收gin框架默认的日志
func GinLogger() gin.HandlerFunc {return func(c *gin.Context) {start := time.Now()path := c.Request.URL.Path // 请求路径 eg: /testquery := c.Request.URL.RawQuery //query类型的请求参数:?name=1&password=2// 挂起当前中间件,执行下一个中间件c.Next()cost := time.Since(start)// Field 是 Field 的别名。给这个类型起别名极大地提高了这个包的 API 文档的可导航性。// type Field struct {// Key string// Type FieldType // 类型,数字对应具体类型,eg: 15--->string// Integer int64// String string// Interface interface{}//}logger.Info(path,zap.Int("status", c.Writer.Status()), // 状态码 eg: 200zap.String("method", c.Request.Method), // 请求方法类型 eg: GETzap.String("path", path), // 请求路径 eg: /testzap.String("query", query), // 请求参数 eg: name=1&password=2zap.String("ip", c.ClientIP()), // 返回真实的客户端IP eg: ::1(这个就是本机IP,ipv6地址)zap.String("user-agent", c.Request.UserAgent()), // 返回客户端的用户代理。 eg: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36zap.String("errors", c.Errors.ByType(gin.ErrorTypePrivate).String()), // 返回Errors 切片中ErrorTypePrivate类型的错误zap.Duration("cost", cost), // 返回花费时间)}
}// GinRecovery recover掉项目可能出现的panic,并使用zap记录相关日志
func GinRecovery(stack bool) gin.HandlerFunc {return func(c *gin.Context) {defer func() {if err := recover(); interface{}(err) != nil {// 检查断开的连接,因为它不是保证紧急堆栈跟踪的真正条件。var brokenPipe bool// OpError 是 net 包中的函数通常返回的错误类型。它描述了错误的操作、网络类型和地址。if ne, ok := interface{}(err).(*net.OpError); ok {// SyscallError 记录来自特定系统调用的错误。if se, ok := ne.Err.(*os.SyscallError); ok {if strings.Contains(strings.ToLower(se.Error()), "broken pipe") {brokenPipe = true}}}// DumpRequest 以 HTTP/1.x 连线形式返回给定的请求httpRequest, _ := httputil.DumpRequest(c.Request, false)if brokenPipe {logger.Error(c.Request.URL.Path,zap.Any("error", err),zap.String("request", string(httpRequest)),)// 如果连接死了,我们就不能给它写状态c.Error(interface{}(err).(error))c.Abort() // 终止该中间件return}if stack {logger.Error("[Recovery from panic]",zap.Any("error", err),zap.String("request", string(httpRequest)),zap.String("starck", string(debug.Stack())), // 返回调用它的goroutine的格式化堆栈跟踪。)} else {logger.Error("[Recovery from panic]",zap.Any("error", err),zap.String("request", string(httpRequest)),)}// 调用 `Abort()` 并使用指定的状态代码写入标头。// StatusInternalServerError:500c.AbortWithStatus(http.StatusInternalServerError)}}()c.Next()}
}测试:
./main.go
func main() { r := gin.New()r.Use(util.GinLogger(), util.GinRecovery(false))r.GET("./test", func(c *gin.Context) {lc := util.LogConfig{Level: "debug",FileName: fmt.Sprintf("./log/%v.log", time.Now().Unix()),MaxSize: 1,MaxBackups: 5,MaxAge: 30,}err := util.InitLogger(lc)if err != nil {fmt.Println(err)}logger := zap.L().Sugar()// 调用内核的Sync方法,刷新所有缓冲的日志条目。应用程序应该注意在退出之前调用Sync。defer logger.Sync()})r.Run()
}
请求地址:http://localhost:8080/test
测试结果:
./log/test.log
{"level":"INFO","time":"2022-09-01T18:11:47.600+0800","caller":"util/zap.go:105","msg":"/test","status":200,"method":"GET","path":"/test","query":"","ip":"::1","user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36","errors":"","cost":0.0001746}
6. lumberjack 日志切割组件
Golang 语言标准库的 log 包和 zap 日志库 不支持日志切割,然而如果我们业务每天产生海量日志,日志文件就会越来越大,甚至会触发磁盘空间不足的报警,此时如果我们移动或者删除日志文件,需要先将业务停止写日志,很不方便。
而且大日志文件也不方便查询,多少有点失去日志的意义。所以实际业务开发中,我们通常会按照日志文件大小或者日期进行日志切割。
Golang 语言第三方库 lumberjack 的作用就是进行日志切割;
lumberjack 提供了一个滚动记录器 logger,它是一个控制写入日志的文件的日志组件,目前最新版本是 v2.0,需要使用 gopkg.in 导入。
-
安装:
go get -u github.com/natefinch/lumberjack -
导入方式:
import "gopkg.in/natefinch/lumberjack.v2" -
使用:
-
与标准库的 log 包一起使用,只需在应用程序启动时将它传递到 SetOutput 函数即可:
log.SetOutput(&lumberjack.Logger{Filename: "./log/test.log",MaxSize: 1, // 单位: MBMaxBackups: 3,MaxAge: 28, //单位: 天Compress: true, // 默认情况下禁用 }) -
与Go第三方库zap 一起使用:
func getLogWriter(filename string, maxsize, maxBackup, maxAge int) zapcore.WriteSyncer {lumberJackLogger := &lumberjack.Logger{Filename: filename, // 文件位置MaxSize: maxsize, // 进行切割之前,日志文件的最大大小(MB为单位)MaxAge: maxAge, // 保留旧文件的最大天数MaxBackups: maxBackup, // 保留旧文件的最大个数Compress: false, // 是否压缩/归档旧文件}// AddSync 将 io.Writer 转换为 WriteSyncer。// 它试图变得智能:如果 io.Writer 的具体类型实现了 WriteSyncer,我们将使用现有的 Sync 方法。// 如果没有,我们将添加一个无操作同步。return zapcore.AddSync(lumberJackLogger) }
可以看出,重点在
lumberjack.Logger上,查看源码我们可以知道:-
Logger 是一个写入指定文件名的 io.WriteCloser。
-
Logger 在第一次写入时打开或创建日志文件。如果文件存在并且小于 MaxSize 兆字节,lumberjack 将打开并附加到该文件。如果文件存在并且其大小 >= MaxSize 兆字节,则通过将当前时间放在文件扩展名之前的名称中的时间戳中来重命名文件(如果没有扩展名,则放在文件名的末尾)。然后使用原始文件名创建一个新的日志文件。
每当写入会导致当前日志文件超过 MaxSize 兆字节时,当前文件将被关闭、重命名,并使用原始名称创建新的日志文件。因此,你给 Logger 的文件名始终是“当前”日志文件。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sVRrlpF1-1662037156666)(images/image-20220901205644931.png)]](https://img-blog.csdnimg.cn/0e1ab5b7f61c4d7a865ae12c69ad7219.png)
可以看到,原文件写到MaxSize大小之后,会被重命名,格式为:原文件名+当前时间(时间格式为time.Time 格式),而创建一个新的文件,命名为原文件名。
-
备份
备份使用提供给 Logger 的日志文件名,格式为
name-timestamp.ext其中name是不带扩展名的文件名,timestamp是使用 time.Time 格式格式化的日志轮换时间2006-01-02T15-04-05.000,扩展名ext是原始扩展名。例如,如果您的 Logger.Filename 是
/var/log/foo/server.log,则在 2016 年 11 月 11 日下午 6:30 创建的备份将使用文件名/var/log/foo/server-2016- 11-04T18-30-00.000.log -
清理旧的日志文件
每当创建新的日志文件时,可能会删除旧的日志文件。根据编码时间戳的最新文件将被保留,最多等于 MaxBackups 的数量(如果 MaxBackups 为 0,则保留所有文件)。无论 MaxBackups 是什么,任何编码时间戳早于 MaxAge 天的文件都会被删除。请注意,时间戳中编码的时间是轮换时间,可能与上次写入该文件的时间不同。 -
如果 MaxBackups 和 MaxAge 都为 0,则不会删除旧的日志文件。
type Logger struct {// Filename 写入日志的文件。备份的日志文件将保留在同一目录下。// 如果为空,则在os.TempDir()中使用-lumberjack.log。Filename string `json:"filename" yaml:"filename"`// MaxSize 是日志文件在轮换之前的最大大小(以 MB 为单位)。默认为 100 兆字节。MaxSize int `json:"maxsize" yaml:"maxsize"`// MaxAge 是根据文件名中编码的时间戳保留旧日志文件的最大天数。// 请注意,一天被定义为 24 小时,由于夏令时、闰秒等原因,可能与日历日不完全对应。// 默认情况下不会根据年龄删除旧日志文件。MaxAge int `json:"maxage" yaml:"maxage"`// MaxBackups 是要保留的旧日志文件的最大数量。// 默认是保留所有旧的日志文件(尽管 MaxAge 可能仍会导致它们被删除。)MaxBackups int `json:"maxbackups" yaml:"maxbackups"`// LocalTime 确定用于格式化备份文件中时间戳的时间是否是计算机的本地时间。默认是使用 UTC 时间。LocalTime bool `json:"localtime" yaml:"localtime"`// Compress 确定是否应使用 gzip 压缩旋转的日志文件。默认是不执行压缩。Compress bool `json:"compress" yaml:"compress"`... } -