文章目录
- 1.SQL性能分析的概念
- 2.分析数据库中SQL的执行频率
- 3.数据库中的慢查询日志
- 3.1.开启慢查询日志功能
- 3.2.模拟慢SQL查询观察日志内容
- 4.Profile查看SQL每个阶段的耗时
- 4.1.开启Profile操作
- 4.2.随便执行一些查询语句
- 4.3.查询执行SQL的耗时
- 4.4.查询某一条SQL每个阶段的耗时
- 4.5.查询某条SQL的CPU使用情况
- 5.Explain分析SQL的执行计划
- 5.1.Explain执行计划中各个字段的含义
- 5.2.分析几个SQL的执行计划重点演示id字段的含义
- 5.3.分析几个SQL的执行计划重点演示什么样的SQL会产生什么样的访问表类型
1.SQL性能分析的概念
在做SQL优化这类的操作时,我们首先要明确什么类型的SQL语句在数据库中的执行频率最高,往往要做SQL优化的都是SELECT查询语句,增删改的写入基本是固定的格式,也不需要优化。
例如当一个表中的数据量很大,但是基本上都是写入和更新的动作,那么我们大可不必去对表的索引和查询语句优化,是没有太大必要的,往往的优化都是对大量的查询进行优化的。
在SQL优化过程中,索引的优化占据了主导的地方,往往会对频繁查询的字段建立一个索引,增大查询的速度。
2.分析数据库中SQL的执行频率
在性能分析中,首先要明确数据库中哪类的SQL操作占的比例比较大,从而对症下药。
通过以下指令可以查询数据库中各项SQL操作的占比。
mysql> show global status like 'Com_______';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_binlog | 0 |
| Com_commit | 30 |
| Com_delete | 23 |
| Com_import | 0 |
| Com_insert | 192 |
| Com_repair | 0 |
| Com_revoke | 5 |
| Com_select | 4325 |
| Com_signal | 0 |
| Com_update | 67 |
| Com_xa_end | 0 |
+---------------+-------+
11 rows in set (0.00 sec)
Com后面是7个下划线,表示后面的内容是7个,查询SQL的执行频率可以是全局下的统计,也可以是当前会话中的统计。
global是查询全局的SQL执行频率,session是查询当前会话中的SQL查询频率。
我们重点关注Com_select、Com_insert、Com_update、Com_delete四类SQL的频率。
根据上面输出的结果,可以分析出该数据库的查询操作占比很高。
3.数据库中的慢查询日志
通过前面的SQL执行频率,我们能得知,在数据库中查询的频率最为频繁,那么应该如何定位哪些查询语句需要优化呢?针对这些需求可以通过MySQL的慢查询日志,从中得到应该对那些SQL进行优化。
慢查询日志记录了所有执行时间超过指定参数的所有SQL查询语句,通过long_query_time参数可以设置SQL执行的超时时间,当超过该参数值的所有SQL语句将被记录到慢查询日志中,该参数的单位是秒,默认是10秒。
慢查询日志默认情况下没有开启,可以通过下面的指令查看有没有开启慢查询日志。
mysql> show variables like 'slow_query_log';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| slow_query_log | OFF |
+----------------+-------+
1 row in set (0.00 sec)
3.1.开启慢查询日志功能
1.配置MySQL的配置文件开启慢查询日志
[root@mysql ~]# vim /etc/my.cnf
slow_query_log=1 #开启慢查询日志
long_query_time=2 #设置查询SQL的超时时间,当超过2秒后,就被记录到慢查询日志中2.重启MySQL
[root@mysql ~]# systemctl restart mysqld3.慢SQL日志文件路径
[root@mysql ~]# ll /var/lib/mysql/mysql.sock.lock
-rw------- 1 mysql mysql 5 5月 29 17:14 /var/lib/mysql/mysql.sock.lock
3.2.模拟慢SQL查询观察日志内容
1)执行一个超长时间的查询SQL
找一张数据量大的表,执行查询指令。
select * from dabiao;
2)观察慢SQL日志
[root@mysql ~]# cat /var/lib/mysql/mysql-slow.log
/usr/sbin/mysqld, Version: 8.0.26 (MySQL Community Server - GPL). started with:
Tcp port: 3306 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument
# Time: 2022-05-29T09:17:14.628770Z
# User@Host: root[root] @ [192.168.20.118] Id: 8
# Query_time: 38.426420 Lock_time: 0.000587 Rows_sent: 27126 Rows_examined: 27126
use db_1;
SET timestamp=1653815796; #SQL执行的时间
select * from dabiao; #完整的SQL语句
我们可以定期的翻一翻慢SQL日志,找出执行频繁且时间很长的SQL,进行优化。
4.Profile查看SQL每个阶段的耗时
在前面提到的慢SQL日志,虽然超过了我们指定时间,就会被记录到慢SQL里,但是也很有可能一些小的业务逻辑,SQL写的不是那么好,本来1秒就可以搞定的查询,结果用了七八秒,加入慢查询的时间是10秒,那么就不会记录到慢SQL里。
这时我们就可以通过Profile这个工具来分析当前会话或者全局模式下执行的SQL耗时,也可以指定查询某一条SQL每个阶段的耗时。
4.1.开启Profile操作
1)首先查一下当前数据库支不支持profile
mysql> select @@have_profiling;
+------------------+
| @@have_profiling |
+------------------+
| YES |
+------------------+
1 row in set, 1 warning (0.00 sec)
2)查看当前MySQL是否开启profile
默认是关闭状态,0表示关闭,1表示开启。
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+
1 row in set, 1 warning (0.00 sec)
3)开启profile操作
可以针对当前会话session开启profile,也可以针对global开启。
mysql> set global profiling = 1;mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 1 |
+-------------+
1 row in set, 1 warning (0.00 sec)
4.2.随便执行一些查询语句
mysql> select * from tb_user;
mysql> select * from tb_user where id = 1 ;
mysql> select * from tb_user where xm = '余伟' ;
4.3.查询执行SQL的耗时
通过以下指令可以看到每条SQL语句的耗时,可以看到查询同样的一条数据,例如9和12,指定主键索引查询的耗时为0.00083750,指定常规索引查询的耗时为0.00100925,有明显的差距。
mysql> show profiles;
+----------+------------+---------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------+
| 1 | 0.00069850 | select @@version_comment limit 1 |
| 2 | 0.00041775 | select @@profiling |
| 3 | 0.00039950 | SELECT DATABASE() |
| 4 | 0.00038075 | SELECT DATABASE() |
| 5 | 0.00381225 | show databases |
| 6 | 0.00467850 | show tables |
| 7 | 0.00531375 | select * from db_user |
| 8 | 0.01484700 | select * from tb_user |
| 9 | 0.00083750 | select * from tb_user where id = 1 |
| 10 | 0.00070725 | select * from tb_user where name = 余伟 |
| 11 | 0.00044275 | select * from tb_user where name = '余伟' |
| 12 | 0.00100925 | select * from tb_user where xm = '余伟' |
+----------+------------+---------------------------------------------+
12 rows in set, 1 warning (0.00 sec)
4.4.查询某一条SQL每个阶段的耗时
查询刚刚show profiles结构中id为9的SQL每个执行阶段的耗时,主要看executing字段对应的耗时。
mysql> show profile for query 9;
+--------------------------------+----------+
| Status | Duration |
+--------------------------------+----------+
| starting | 0.000141 |
| Executing hook on transaction | 0.000014 |
| starting | 0.000044 |
| checking permissions | 0.000020 |
| Opening tables | 0.000113 |
| init | 0.000019 |
| System lock | 0.000024 |
| optimizing | 0.000029 |
| statistics | 0.000142 |
| preparing | 0.000038 |
| executing | 0.000112 |
| end | 0.000019 |
| query end | 0.000011 |
| waiting for handler commit | 0.000023 |
| closing tables | 0.000023 |
| freeing items | 0.000033 |
| cleaning up | 0.000033 |
+--------------------------------+----------+
17 rows in set, 1 warning (0.00 sec)
4.5.查询某条SQL的CPU使用情况
mysql> show profile cpu for query 9;
+--------------------------------+----------+----------+------------+
| Status | Duration | CPU_user | CPU_system |
+--------------------------------+----------+----------+------------+
| starting | 0.000141 | 0.000000 | 0.000134 |
| Executing hook on transaction | 0.000014 | 0.000000 | 0.000012 |
| starting | 0.000044 | 0.000000 | 0.000045 |
| checking permissions | 0.000020 | 0.000000 | 0.000019 |
| Opening tables | 0.000113 | 0.000000 | 0.000115 |
| init | 0.000019 | 0.000000 | 0.000017 |
| System lock | 0.000024 | 0.000000 | 0.000024 |
| optimizing | 0.000029 | 0.000000 | 0.000029 |
| statistics | 0.000142 | 0.000000 | 0.000144 |
| preparing | 0.000038 | 0.000000 | 0.000036 |
| executing | 0.000112 | 0.000000 | 0.000116 |
| end | 0.000019 | 0.000000 | 0.000014 |
| query end | 0.000011 | 0.000000 | 0.000012 |
| waiting for handler commit | 0.000023 | 0.000000 | 0.000023 |
| closing tables | 0.000023 | 0.000000 | 0.000023 |
| freeing items | 0.000033 | 0.000000 | 0.000033 |
| cleaning up | 0.000033 | 0.000000 | 0.000033 |
+--------------------------------+----------+----------+------------+
17 rows in set, 1 warning (0.00 sec)
5.Explain分析SQL的执行计划
在前面判定一个SQL的执行效率是否高,主要是根据执行的时长来决定的,但是不一定精准。
我们可以通过EXPLAIN或者DESC指令,去分析一条SQL的执行计划,可以根据执行计划返回的内容判断SQL执行的效率。
EXPLAIN的语法结构:EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件
5.1.Explain执行计划中各个字段的含义
下面是EXPLAIN分析一个SQL的执行计划所输出的内容,可以看到包含了很多字段,那么这些字段有什么含义呢?我们下面一起来看一下。

几个主要字段的含义如下:
-
id字段:
- 代表select查询的序列号,表示查询语句中select语句或者操作表的顺序。
- 单表查询只有一行数据,id永远为1。
- 多表查询时,如果id相同,那么执行顺序从上到下依次执行。
- 如果没有多表查询,例如子查询,一条SQL语句中有多个select语句,那么此时id显示的就会不同,id的值越大,那么就会越先执行。
-
select_type字段:
- 表示该条SQL语句的查询类型,常见的取值有SIMPLE(简单表查询,不使用表连接或者子查询,只是单表查询)、PRIMARY(主查询)、UNION(联合查询)、SUBQUERY(SELECT/WHERE之后包含的子查询)。
-
table字段:
- 查询的表名。
-
type字段:
- 连接表的类型、访问表的类型,性能由好到差的连接类型为:NULL、system、const、eq_ref、ref、range、index、all。
- 其中性能最好的是NULL,性能最差的是all,但是几乎在业务数据库中不可能会出现NULL类型的表连接,因为NULL表示不访问任何表。
- system表示查询的是系统表,访问系统表时才会看到类型是system。
- conset类型可以说是性能很好的类型了,当使用主键索引、唯一索引作为条件访问表时就会出现conset类型,此时性能是最好的。
- 当使用常规索引,也就是我们创建的索引作为条件访问表时,类型就是ref。
- 当出现index类型时,表示虽然也是用索引查询表了,但是对索引进行了全部扫描,性能也不高。
- 在优化SQL时,尽量将连接类型优化到前面几个类型访问表,性能是最好的,当然也需要根据业务的自身逻辑去优化,尽量不要出现all,当出现all时就表示要全表扫描了。
-
possible_keys字段:
- 显示可能会使用到表中的那些索引,一个或者多个。
-
key字段:
- 实际使用哪个索引查询的数据,如果为NULL,就表示没有使用使用索引。
-
key_len字段:
- 索引使用的字节数,该值为索引字段最大的可能长度,但是也非实际使用的长度,虽然不是特别精准,但是长度越短越好。
-
rows字段:
- 认为要执行查询的行数,也就是认为要查询多少行才能拿到对应的结果,也是一个估值,不是那么精准。
-
filtered字段:
- 表示返回结果的行数占读取行数的百分比,该字段的值越大越好,越大表示我们读取的行就是我们要查询结果的行,更加精准,性能高。
在这么多字段中,我们重点关注id、type、possible_key、key、key_len、filtered这几个字段的值,根据这些值就有了优化SQL的因素。
5.2.分析几个SQL的执行计划重点演示id字段的含义
id字段:代表select查询的序列号,表示查询语句中select语句或者操作表的顺序。
- 单表查询只有一行数据,id永远为1。
- 多表查询时,如果id相同,那么执行顺序从上到下依次执行。
- 如果没有多表查询,例如子查询,一条SQL语句中有多个select语句,那么此时id显示的就会不同,id的值越大,那么就会越先执行。
1)单表查询只有一行数据,id永远为1。
explain select * from tb_user where id = '1';
2)多表查询时,如果id相同,那么执行顺序从上到下依次执行。
只要是多表查询,那么多行记录的id不会自增,而是显示相同的值,并且执行顺序是从上到下依次执行的。
下面这条SQL是查询每个人员属于哪个部门的,共用到两张表分别是人员信息表和部门信息表。
SELECTr.xm,r.zw,b.bmmc
FROMryxxb AS rLEFT OUTER JOIN bmxxb AS b ON r.bm_id = b.id;
下面我们通过EXPLAIN来分析该条SQL的执行顺序。
explain select r.xm,r.zw,b.bmmc from ryxxb as r left outer join bmxxb as b on r.bm_id = b.id;
分析结果如下,id值相同,表的执行顺序从上到下,首先查询部门表,然后再查询人员信息表。

一般情况下from之后的表都是先执行的,如果是三张表的多表查询,其中包含中间表,那么中间表一定是第二个执行的。
3)ID值不同,谁的ID值大谁先执行。
我们执行一个子查询的SQL,分析他的执行计划。
下面这个子查询的SQL是要查询人员信息表中薪资大于销售部全部人员薪资的其他人员信息。
下面这个SQL中select执行的顺序首先是SELECT id FROM bmxxb WHERE bmmc = '销售部',然后是SELECT xz FROM ryxxb WHERE bm_id IN这一条,最后是select * from ryxxb 。
SELECT*
FROMryxxb
WHERExz > ALL (SELECT xz FROM ryxxb WHERE bm_id IN ( SELECT id FROM bmxxb WHERE bmmc = '销售部' ));
通过explain观察执行计划。
explain select * from ryxxb where xz > all (select xz from ryxxb where bm_id in (select id from bmxxb where bmmc = '销售部'));
执行计划如下,可以看到ID有不一样的了,那么ID值越大就说明越先执行,那么bmxxb肯定是第一个执行,此时还有一个ID为2的表,相同ID,按照顺序执行,那么第二个执行的就是ryxxb表,ID为1最小,那么就会最后执行ryxxb表。

5.3.分析几个SQL的执行计划重点演示什么样的SQL会产生什么样的访问表类型
1)NULL类型的访问表,性能最高。
NULL类型几乎在业务逻辑中出现的很少,因为不查询任何表时,才会返回NULL。
explain select 'A' ;

2)conset类型的访问表,性能较好。
当使用主键索引或者唯一索引访问表时,都会出现conset类型。
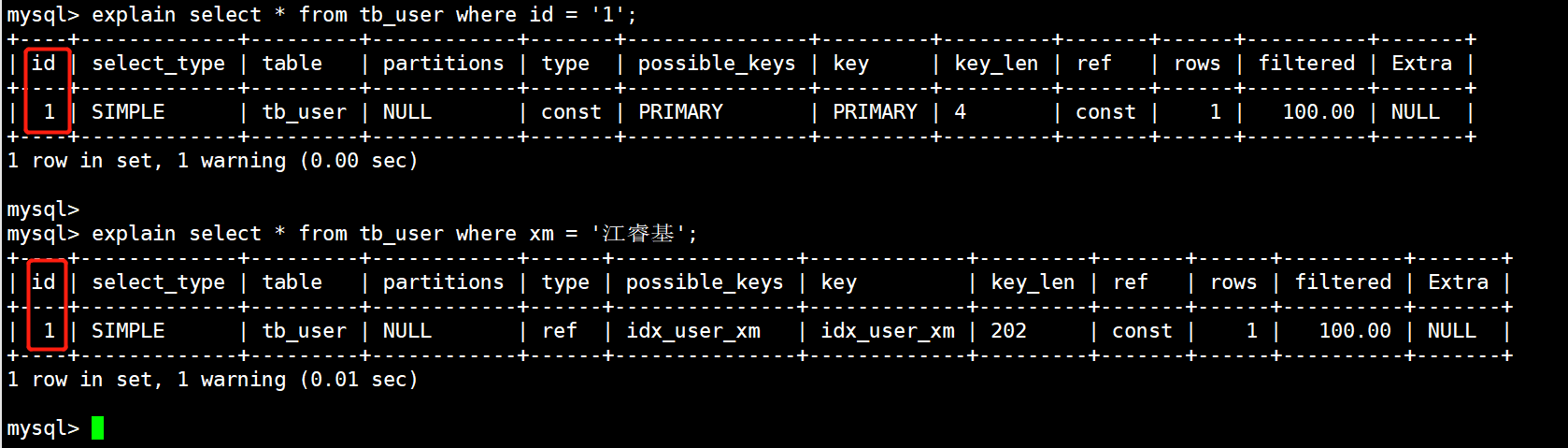
explain select * from tb_user where id = '1' ;

3)ref类型的访问表,性能略好。
当使用常规索引访问表时,会出现ref类型。
mysql> explain select * from tb_user where xm = '江睿基' ;