背景
在做性能监控需求的过程中,会存在很多监控任务需要定时执行。比如在卡顿监控的实现中,我们需要每50ms 执行一次主线程调用栈的任务,此时由于任务本身可能存在一些耗时,可能需要对任务下次调度的时间做一些调整,避免相差太大。
这里以 Handler 执行为例最终实现的代码可能是这样的
public class MyHandler extends Handler {private long lastExecTime = System.nanoTime();private long delayTime = 50 * 1000000; // 转换为纳秒@Overridepublic void handleMessage(Message msg) {long startTime = System.nanoTime();// 执行任务doTask();// 计算下一次任务执行的延迟时间long timeDiff = System.nanoTime() - lastExecTime;long nextDelayTime = Math.max(delayTime - timeDiff, 0);// 记录本次执行时间和延迟时间lastExecTime = System.nanoTime();delayTime = nextDelayTime;// 发送下一次任务消息sendEmptyMessageDelayed(0, delayTime / 1000000); // 转换为毫秒}private void doTask() {// 需要执行的任务}
}
由于Handler通常是挂载到某一个指定的线程上,如果每个不同的定时任务(比如Cpu采集、内存采集任务)都创建一个Thread,会造成线程浪费,而如果每个定时任务的Handler同附属在到同一个线程Looper上,又可能会因为某一个任务执行比较耗时,影响了其他任务的调度,因此我们希望不同的采集任务之间尽可能隔离。
此时就需要使用到线程池方式来动态分配或复用线程,Java本身提供 ScheduledExecutorService� 类,它相比 ExecutorService 多支持了延迟执行任务或定时执行任务的能力。
public interface ScheduledExecutorService extends ExecutorService {public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit);public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit);}
最终在Apm项目中我创建了一个全局通用的ScheduledExecutorService 对象来支持内部各个监控任务定时执行的需求,这里我最终使用的是 **scheduleAtFixedRate **来进行任务注册调度的。
问题
在某个性能采集功能上线后,偶然发现一些用户采集的数据异常,跟踪异常用户采集的性能日志发现,这些性能日志上报的时间异常,本来是10S执行一次的任务,但从收集的日志上看,1S内执行了几百次(出现异常的概率较低,平均每天1个设备左右)。
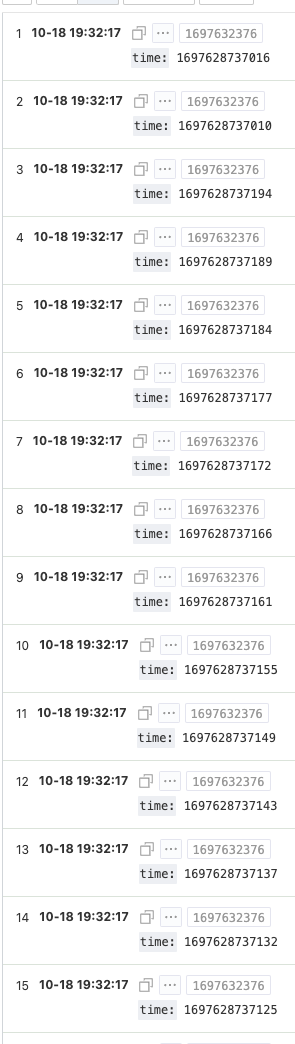
从日志time上可以确认,这并不是重复的日志,因此只可能是任务调度的间隔发生了异常,再Review相关代码后,确认配置的任务间隔参数值 不可能出现几毫米的情况。
在线下进行了多次自测后,未复现该问题。
源码分析
问题在线下无法复现,那么此时只能猜测是不是线程池内部的调度逻辑存在什么问题,因此需要深入分析下线程池执行定时任务这块的代码实现。并且这里刚好借此问题,学习下ScheduledThreadPoolExecutor是如何实现延迟及定时任务实现
首先由于要支持任务延迟执行的能力,因此在SchedudledThreadPoolExecutor构造函数中使用的是一个特殊的Queue:DelayedWorkQueue。
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE,DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,new DelayedWorkQueue());}DelayedWorkQueue 是一个支持优先级排序的Queue,为了提高新任务入队时的性能,内部并不是线性排序的,采取的是类似最小堆的方式存储。
当一个新的任务入队时,首先会调用DelayQueue.offer()方法,offer()函数先进行数组扩容的一些判断,如果数组长度为0,就直接插入到队首,如果不为0 则调用siftUp() ,siftUp()函数内部会基于最小堆的特性,将元素插入合适的位置, 这里判断优先级的方式是直接调用compare()函数
public boolean offer(Runnable x) {if (x == null)throw new NullPointerException();RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;final ReentrantLock lock = this.lock;lock.lock();try {int i = size;if (i >= queue.length)grow();size = i + 1;if (i == 0) {queue[0] = e;setIndex(e, 0);} else {siftUp(i, e);}if (queue[0] == e) {leader = null;available.signal();}} finally {lock.unlock();}return true;}private void siftUp(int k, RunnableScheduledFuture<?> key) {while (k > 0) {int parent = (k - 1) >>> 1;RunnableScheduledFuture<?> e = queue[parent];//基于优先级排序if (key.compareTo(e) >= 0)break;//替换元素queue[k] = e;setIndex(e, k);k = parent;}queue[k] = key;setIndex(key, k);}
compare() 函数的实现是基于 ScheduledFutureTask�的 time属性进行排序,其中如果time 时间一样,则基于入队时间进行排序
public int compareTo(Delayed other) {if (other == this) // compare zero if same objectreturn 0;if (other instanceof ScheduledFutureTask) {ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;long diff = time - x.time;if (diff < 0)return -1;else if (diff > 0)return 1;else if (sequenceNumber < x.sequenceNumber)return -1;elsereturn 1;}long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;}
因此,我们接下来分析对于scheduleAtFixedRate调度的任务,它的time是如何设置的。
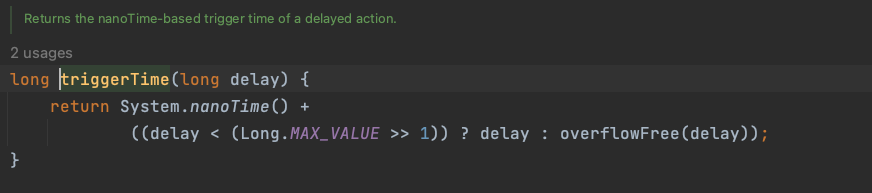
在构造ScheduledFutureTask 对象时,任务的初始化执行时间是通过 triggerTime()计算的, triggerTime() 内部以
System.nanoTime()为时间基线,计算下一次任务的执行时间。
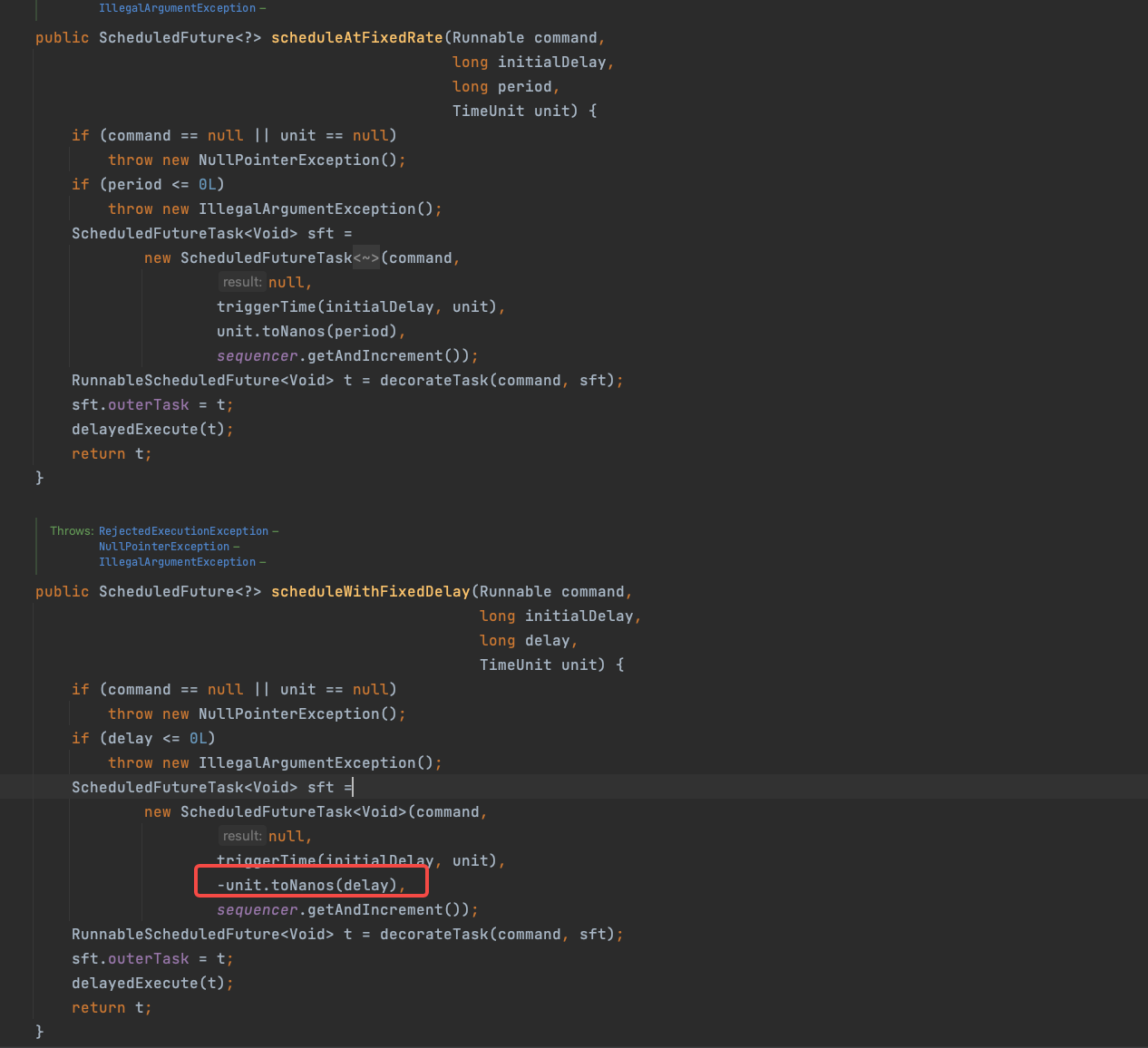
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit) {if (command == null || unit == null)throw new NullPointerException();if (period <= 0L)throw new IllegalArgumentException();ScheduledFutureTask<Void> sft =new ScheduledFutureTask<Void>(command,null,// 调用triggerTime 设置任务下一次执行的时间triggerTime(initialDelay, unit),unit.toNanos(period),sequencer.getAndIncrement());RunnableScheduledFuture<Void> t = decorateTask(command, sft);sft.outerTask = t;delayedExecute(t);return t;}/*** Returns the nanoTime-based trigger time of a delayed action.*/long triggerTime(long delay) {return System.nanoTime() +((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));}接下来我们分析 在任务插入到队列直到第一次被执行时的逻辑, 首先任务被执行时,会判断该任务是不是一个周期性任务,如果不是周期性任务,则执行后该任务就结束。 而如果是周期性执行的任务,会调用 runAndReset()函数。
/*** Overrides FutureTask version so as to reset/requeue if periodic.*/public void run() {boolean periodic = isPeriodic();if (!canRunInCurrentRunState(periodic))cancel(false);else if (!periodic) //非周期性任务,直接调用super.run();else if (super.runAndReset()) { //周期性任务,调用runAndReset()//更新任务的time属性setNextRunTime();//重新入队,等待下次调度reExecutePeriodic(outerTask);}}protected boolean runAndReset() {if (state != NEW ||!RUNNER.compareAndSet(this, null, Thread.currentThread()))return false;boolean ran = false;int s = state;try {Callable<V> c = callable;if (c != null && s == NEW) {try {c.call(); // don't set resultran = true;} catch (Throwable ex) {setException(ex);}}} finally {// runner must be non-null until state is settled to// prevent concurrent calls to run()runner = null;// state must be re-read after nulling runner to prevent// leaked interruptss = state;if (s >= INTERRUPTING)handlePossibleCancellationInterrupt(s);}return ran && s == NEW;}
在runAndReset()函数内部,会执行原始的调度任务,这里的reset主要是判断和重置 的一些状态。比如如果发现目前的state不是NEW,则说明该任务已经被取消了,就不进行原始任务的执行。 另外由于是一个周期性任务,任务执行后,并不会把该Task的状态设置为 COMPLETING�
在任务执行完成后,会调用 setNextRuntime() 重置任务下一次执行的时间,并且将任务重新offer到队列中。
/*** Sets the next time to run for a periodic task.*/private void setNextRunTime() {long p = period;if (p > 0)time += p;elsetime = triggerTime(-p);}
这里period >0时,会用Task当前的time + period 计算下一次任务执行的时间,
而 period <0 时,是调用 triigerTime(-p) 计算时间的, triggerTime()函数内部计算时间上面讲过,是用
当前的System.naonoTime() 作为基准时间计算的。
初次看到这里时,肯定会疑惑 **period**为负数又是个什么情况,这里跟踪代码后发现,
原来 scheduleAtFixedRate() 和 scheduleWithFIxedDelay() 2个函数实现时的唯一区别,就是
scheduleWithFixedDelay时会将传入的 period 设置为负数,也就说底层通过 period 的正负来判断开发者调用的是哪个函数,封装通用逻辑函数时,省去了一个参数。
代码分析到这里,我们也就理解了这2个函数计算任务下一次调度时间的不同点:
- scheduleAtFixedRate�():计算任务下一次执行的时间,不是根据当前基准时间计算的,而是上一次任务设置的time的值
- scheduleWithFIxedDelay():计算任务下一次执行的时间,是以当前基准时间计算的
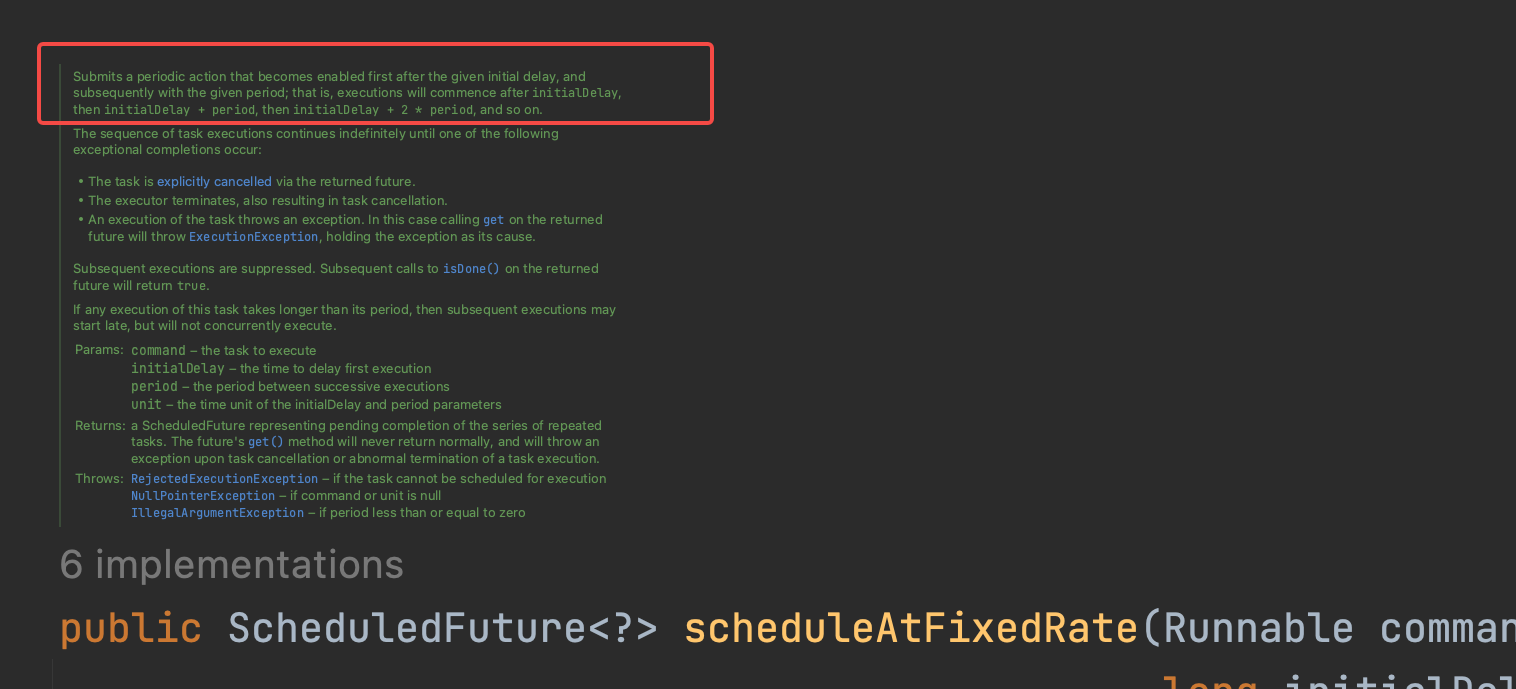
此时再回到 系统对 shceudleAtFixRate函数的定义上,其实在函数注释上已经解释的很清楚了。
Submits a periodic action that becomes enabled first after the given initial delay, and
subsequently with the given period; that is, executions will commence after initialDelay,
then initialDelay + period, then initialDelay + 2 * period, and so on.
任务初始执行的时间是基于设置的延迟时间开始执行的,之后每一次执行的时间也是基于该初始时间调度的,
比如初始时间是 1000,周期是1000, 那么后续任务的执行时间正常情况下应该是 **2000 3000 4000**。
而 shceduleAtFixedDelay 是以任务执行结束后,后System.nanotime()重新计算下次调度时间的。
scheduleAtFixedRate()** **这种以任务初始时间作为计算任务调度时间会有什么情况的现象出现呢?
问题复现
从上文中的实现中,可以发现Java线程池对于周期性任务,下一次的任务调度会依赖于上一次任务的执行结束,如果任务的执行时间,超过任务设置的间隔时间,那么后续任务执行的间隔,会变成任务的执行耗时为间隔。
这里写了个Demo测试下,创建一个执行耗时为5S的任务,设置任务执行间隔为2S
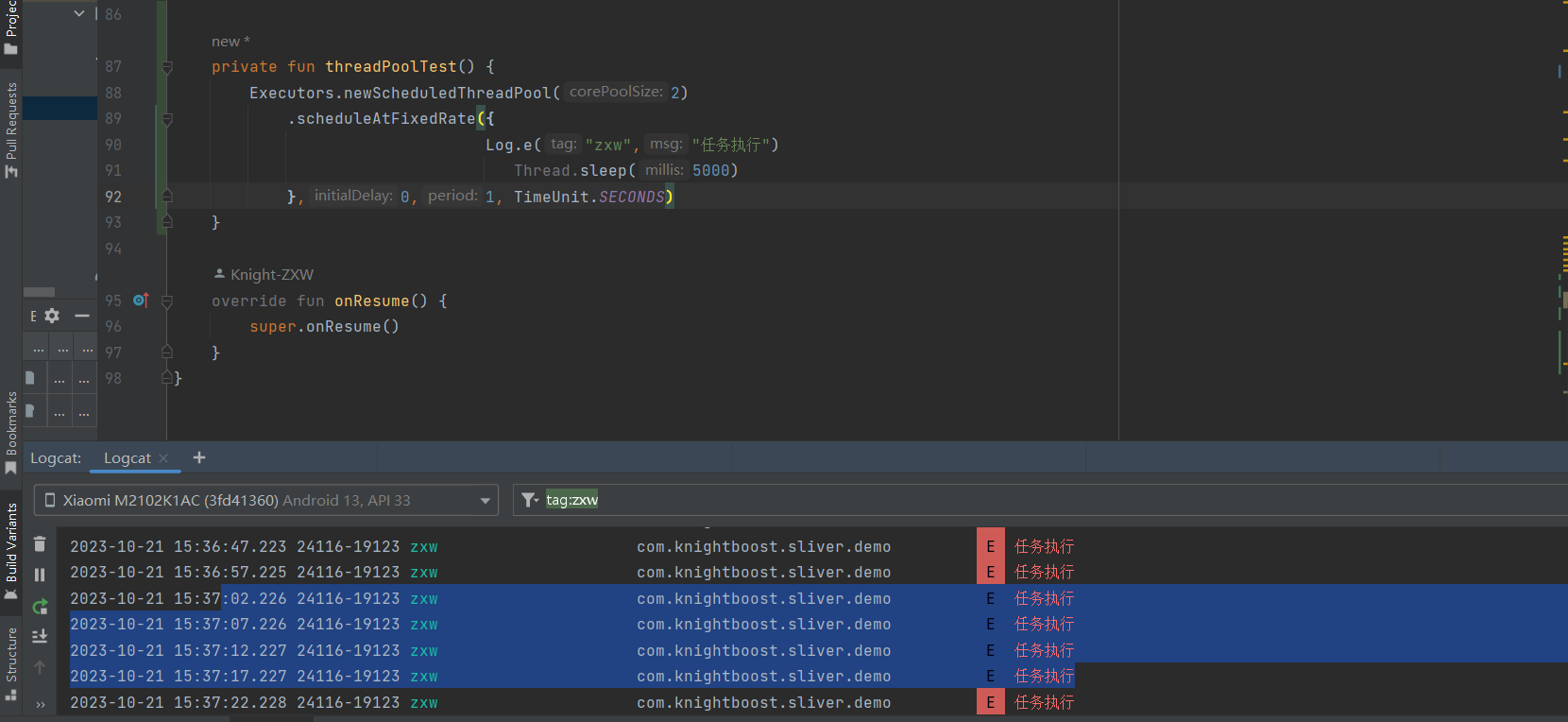 此时间戳上,可以发现 最终任务其实没有按2秒的时间执行。
此时间戳上,可以发现 最终任务其实没有按2秒的时间执行。
不过这个案例和我在线上遇到的案例不一样,线上的场景所执行的任务通常只需要耗时几十毫秒,执行的间隔为10S。 但是我们要知道,线上环境和线下执行的环境可能是不一样,在线下这个任务可能只有几十毫秒,但线上会不会因为各种异常情况,导致这个任务在某一次执行的时候超时很多? 比如因为时间片分配不足,或者是其他特殊情况,比如GC暂停了线程?。如果是这种情况,理论上是会出现由于某一次超时,导致任务的 time 属性一直< System.nanoTime(), 然后又由于后续任务的执行耗时可能又恢复正常,导致任务无限被调度,当然每一次调度后 time = time + period, 直到任务的time属性值> System.nanoTime()才停止!
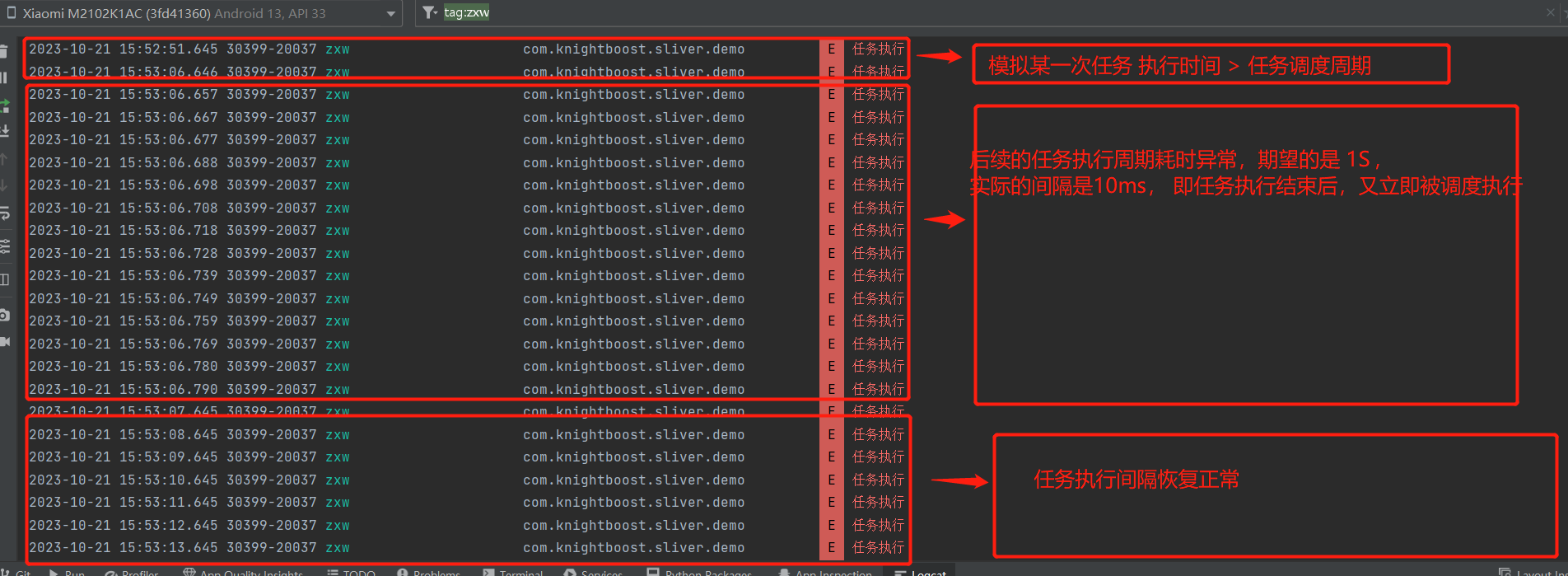
下面这个Demo,我默认任务调度时间为1S, 模拟第一次执行时耗时异常为15S, 可以发现后续十四次的任务调度都出现异常,次数~= 执行超时的时间/任务调度间隔。
从另一个角度来说,这保证了**shceudleAtFixRate**最终执行的次数 总是等于 时间间隔/任务调度间隔,不会因为某一次任务执行耗时较长,导致总次数变少。
解决方式
对我周期性性能采样的任务,我们可以接受某一次运行间隔异常,但无法接受 任务瞬间调度次数异常的情况,因为这可能会消耗大量的CPU或者其他资源。因此最终将任务调度改为使用 scheduleAtFixDelay()函数执行,并且记录任务执行时实际的间隔,如果间隔超过一定阈值,则可以根据任务的特性,选择丢弃本次采样的结果,或者是对数据结果进行一些校准。