文章目录
- 网络分层
- 应用层
- 找到服务器的 IP
- 查接口、对象的耗时
- 删除指定网站的Cookie
- 表示层、会话层
- tcpdump、wireshard
- 传输层
- telnet: 路径可达性测试
- nc: 路径可达性测试
- netstat:查看当前连接状态
- iftop:查看当前连接的传输速率
- netstat -s: 查看丢包和乱序的统计
- ss:新一代 netstat
- 网络层
- traceroute: 查看网络路径状况
- mtr: 连续多次路径探测
- route、netstat、ip: 查看路由
- 数据链路层、物理层
- ethtool: 查看网卡驱动
- 抓包
- 抓包文件格式
- tcpdump 用法
- 如何抓取报文
- 如何过滤报文
- Wireshark 用法
- 确认是在哪端抓的包
- 定位应用层的请求和响应
- 只截到一部分报文
- 乱序有问题吗
- TCP 握手
- 借助 iptables、tcpdump 的重试观察实验
- server 设置为 DROP 策略
- server 设置为 REJECT 策略
- client 用 tcpdump 指定监听的 port
- client 用 tcpdump 不指定监听的 port
- TCP 状态转移
- 常见误区的更正
- UDP 其实并没有握手
- 一台机器其实不止 65535 个连接
- 两端其实可以同时发起握手
- TCP 挥手
- connection reset by peer 原因
- 过滤报文
- 分析报文
- 四次挥手确实必须两个 FIN
- 挥手其实可以同时发起
- 挥手一方发送 FIN 时,其实只有一方停止发送数据,另一方会继续发送数据
- 防火墙
- 关注重点报文
- 对比两端报文
- Web 站点访问被 reset
- 访问 LDAPS 服务报 connection reset by peer
- 防火墙配置动手实践
- 实验1:telnet 第三方站点
- 实验2:插入 RST 报文,连接失败
- 实验3:丢弃 RST 报文,连接成功
- 保活机制
- TCP 长连接为何总中断?
- MTU 最大分段大小
- 为什么有 DupAck
- 为什么重传失败
- 为什么重传只有两次?
- MTU 解决方案
- 调小两端 MTU
- 在 iptables 的 nat 表和 FORWARD 处添加规则:改报文的 MSS 值
- 什么是网卡的 TSO 和 GRO
- IP 分片
网络分层
- TCP是有前后顺序的,对应的socket类型是SOCK_STREAM
- UDP是无序的数据单元,对应的socket类型是SOCK_DGRAM
一个TCP流对应的是五元组:传输协议类型、源IP、源端口、目标IP、目标端口, 例如(TCP, myip, myport, www.baidu.com, 443)
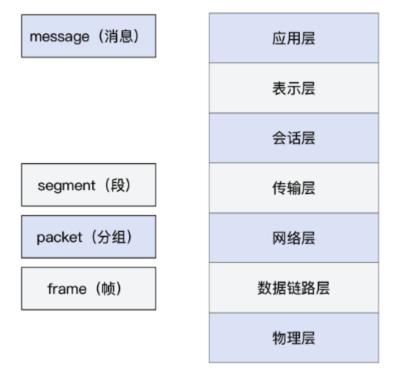
各分层和数据的术语如下:
- 广义的packet,是报文,是一种相对宽泛的说法,基本上每一层都可使用,例如应用层叫HTTP报文,网络层叫IP报文。
- frame是帧,是第二层数据链路层的概念,包含帧头、载荷、帧尾。
- 狭义的packet,是分组,是IP报文。
- TCP segment 是段, 应用层将message交给传输层,若该message大小超出传输层数据单元的限制(如超出TCP的MSS),则会被划分为多个segments。此过程叫做分段(segmentation),也是TCP层重要的职责之一。
下面介绍各层排查工具:
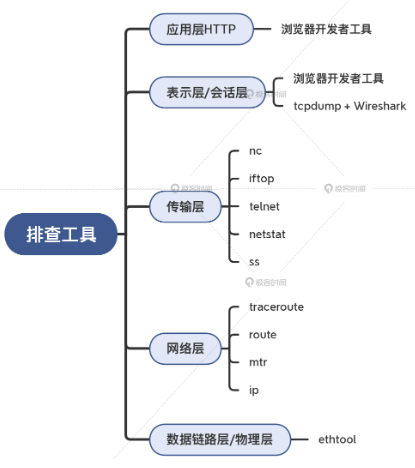
应用层
Chrome 的 F12 打开开发者工具,其可以做以下工作:
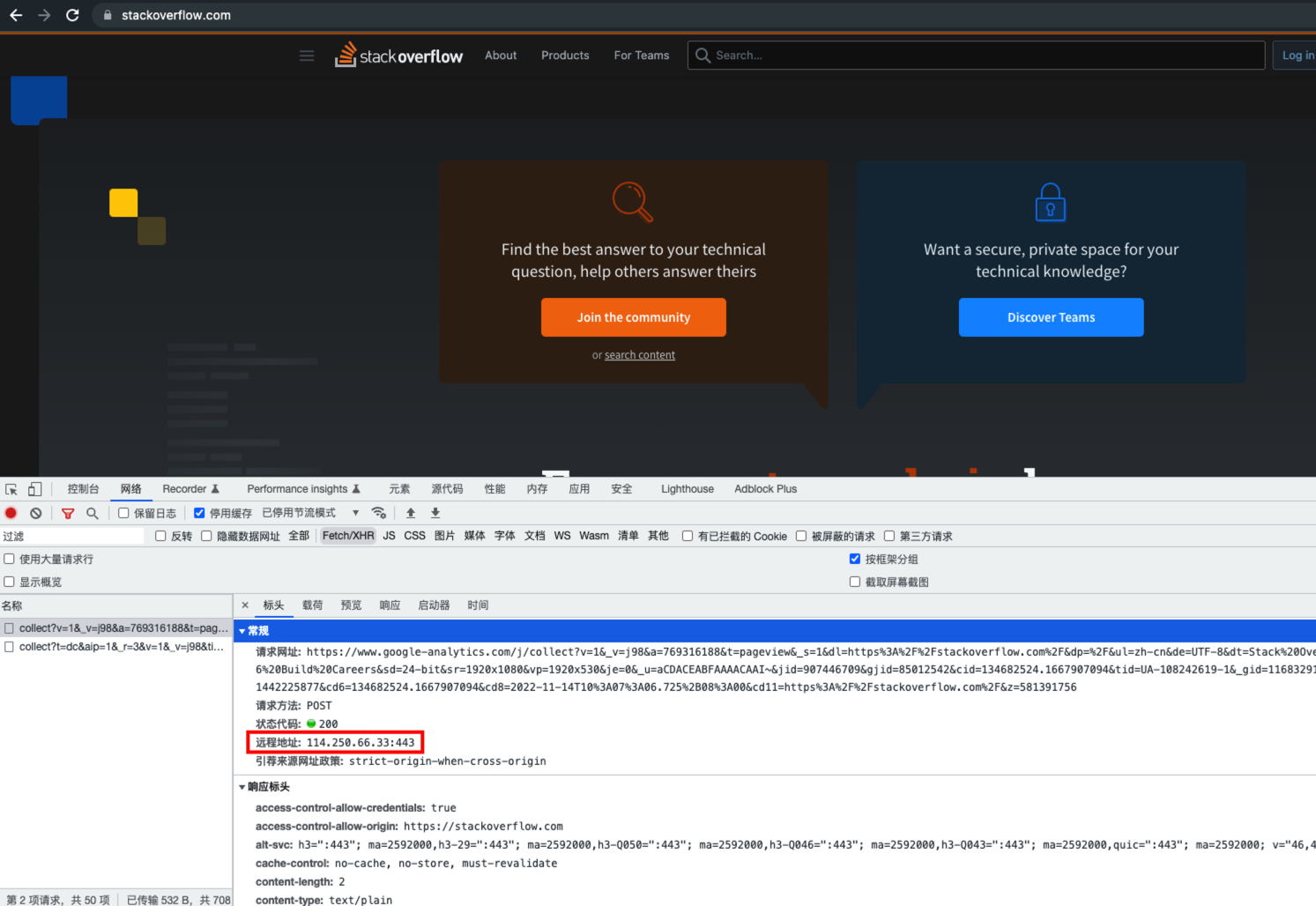
找到服务器的 IP
- 如下图中的 Remote Address:
查接口、对象的耗时
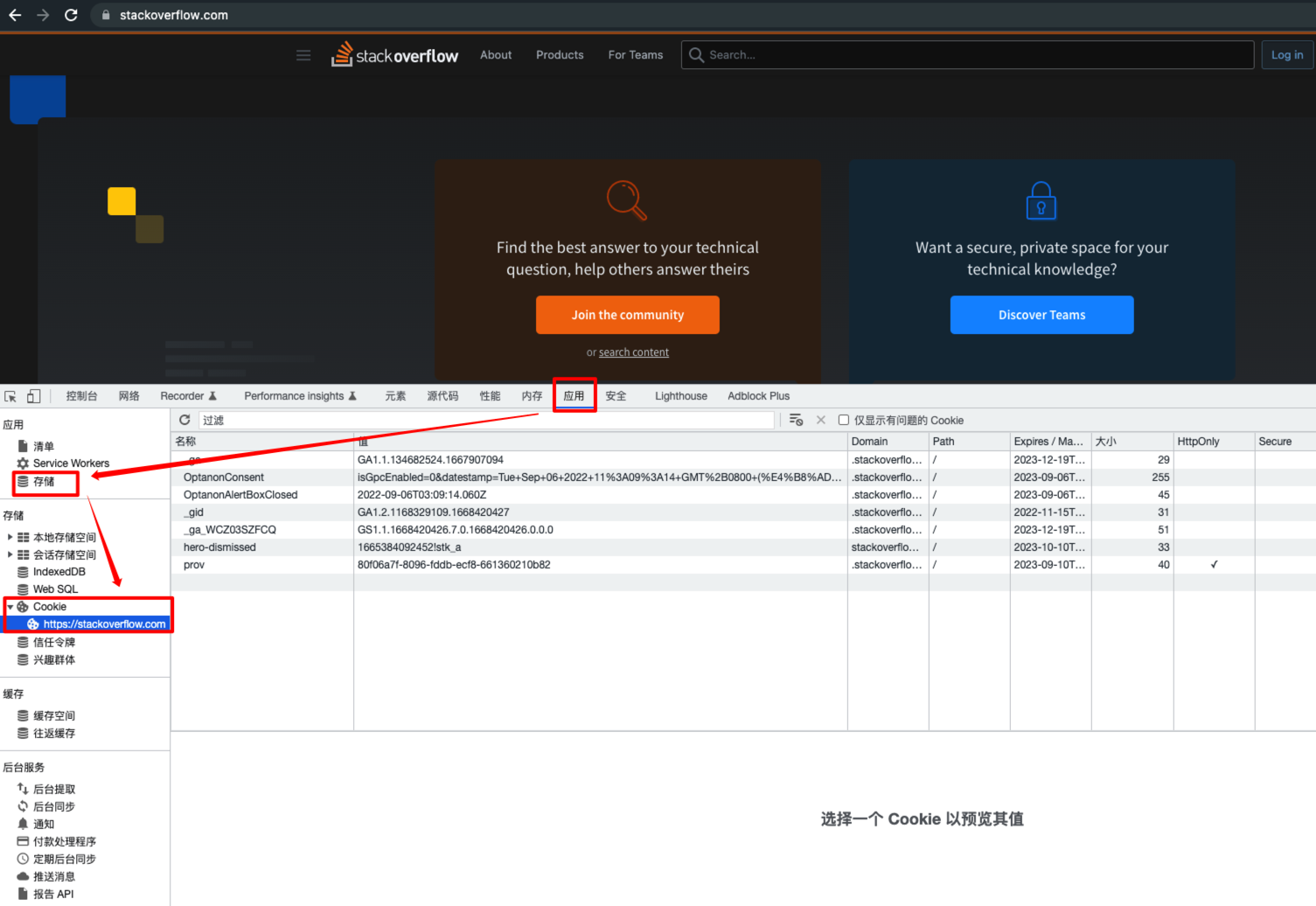
删除指定网站的Cookie
在 Storage -> Cookie 中清除对应的条目,下次再访问此网站即可被视为全新的访问了
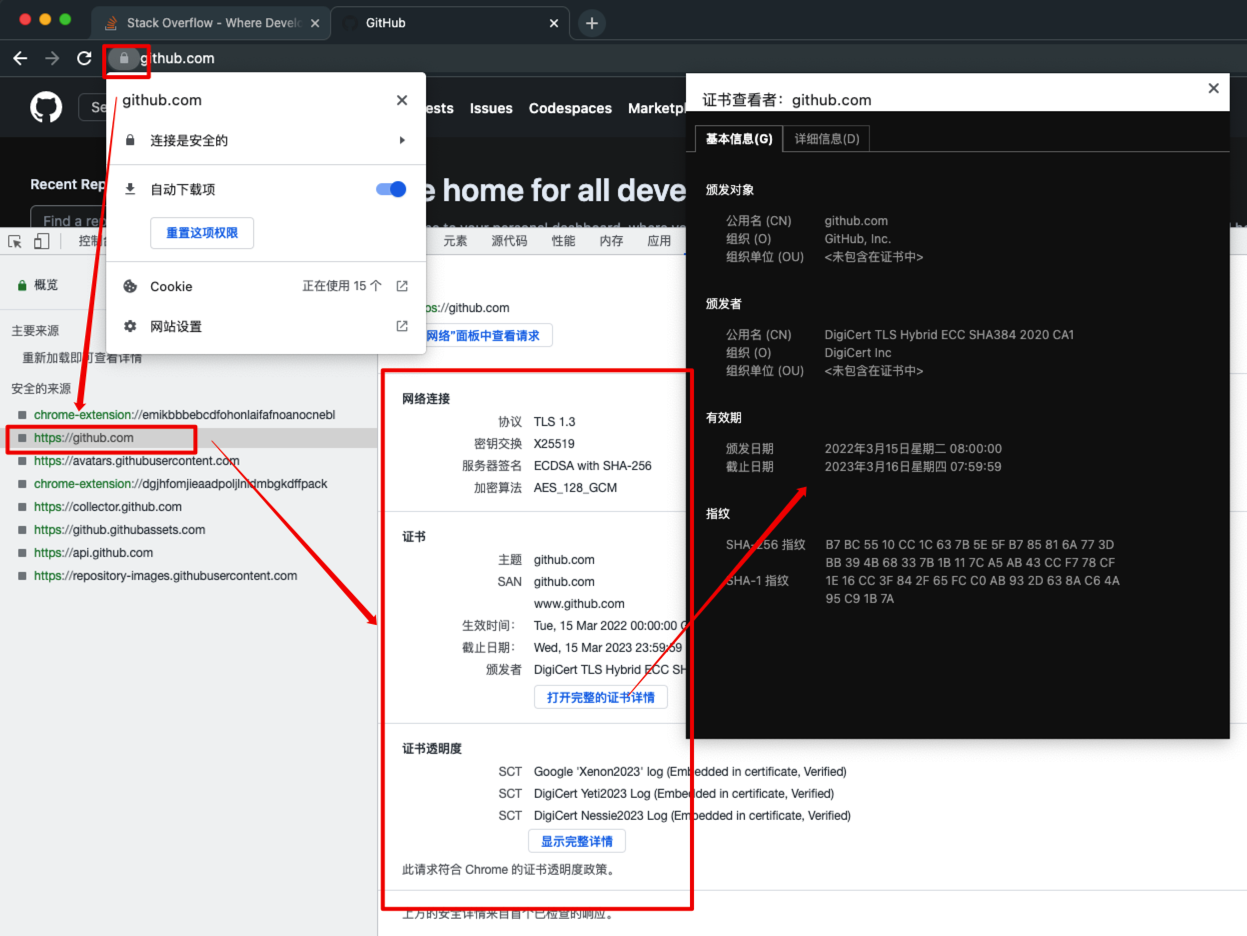
表示层、会话层
- 可以查看网站的 TLS 证书,示例如下:
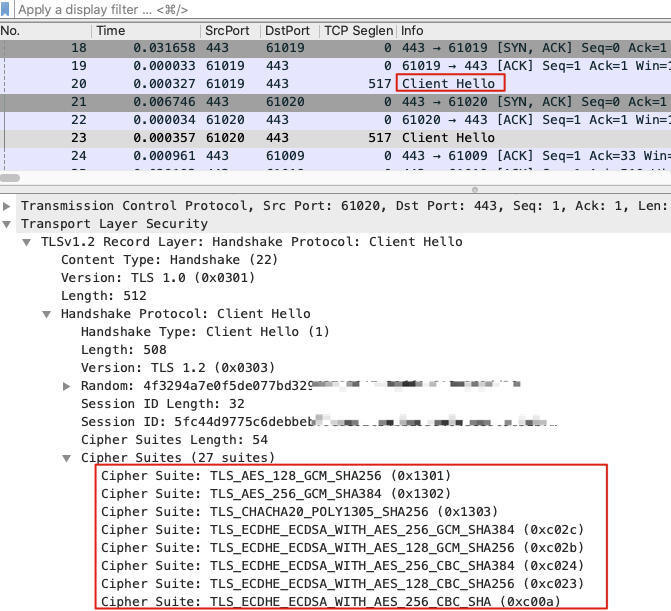
tcpdump、wireshard
- 可以用 tcpdump 或 wireshard 查看 TLS 握手、秘钥交换、密文传输的细节。例如下图可以看到 TLS 握手阶段,双方协商过程中各自展示 CIpher Suite,而在 Chrome 的开发者工具中只能看到协商完毕后的结果,如下图:
传输层
telnet: 路径可达性测试
NAMEtelnet — user interface to the TELNET protocolSYNOPSIStelnet [-468ELadr] [-S tos] [-b address] [-e escapechar] [-l user] [-n tracefile] [host [port]]DESCRIPTIONThe telnet command is used for interactive communication with another host using the TELNET protocol. It begins in command mode, where it prints a telnet prompt ("telnet> "). If telnet is invoked with a host argument, it per‐forms an open command implicitly; see the description below.telnet www.baidu.com 443
Trying 110.242.68.4...
Connected to www.a.shifen.com.
Escape character is '^]'.
^CConnection closed by foreign host.telnet www.github.com 443
Trying 20.205.243.166...
Connected to github.com.
Escape character is '^]'.
^CConnection closed by foreign host.telnet 192.168.2.133 22
Trying 192.168.2.133...
Connected to 192.168.2.133.
Escape character is '^]'.
SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.10
^CConnection closed by foreign host.telnet 192.168.2.133 443
Trying 192.168.2.133...
telnet: connect to address 192.168.2.133: Connection refused
telnet: Unable to connect to remote host
nc: 路径可达性测试
NAMEnc — arbitrary TCP and UDP connections and listensSYNOPSISnc [-46bCDdhklnrStUuvZz] [-I length] [-i interval] [-O length] [-P proxy_username] [-p source_port] [-q seconds] [-s source] [-T toskeyword] [-V rtable] [-w timeout] [-X proxy_protocol] [-x proxy_address[:port]] [destination][port]DESCRIPTIONThe nc (or netcat) utility is used for just about anything under the sun involving TCP, UDP, or UNIX-domain sockets. It can open TCP connections, send UDP packets, listen on arbitrary TCP and UDP ports, do port scanning, anddeal with both IPv4 and IPv6. Unlike telnet(1), nc scripts nicely, and separates error messages onto standard error instead of sending them to standard output, as telnet(1) does with some.Common uses include:· simple TCP proxies· shell-script based HTTP clients and servers· network daemon testing· a SOCKS or HTTP ProxyCommand for ssh(1)· and much, much morenc -w 2 -zv 192.168.2.99 8000-8009
Connection to 192.168.2.99 8000 port [tcp/*] succeeded!
nc: connect to 192.168.2.99 port 8001 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8002 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8003 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8004 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8005 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8006 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8007 (tcp) failed: Connection refused
nc: connect to 192.168.2.99 port 8008 (tcp) failed: Connection refused
Connection to 192.168.2.99 8009 port [tcp/*] succeeded!nv -w 2 -zv www.baidu.com 443
Connection to www.baidu.com 443 port [tcp/https] succeeded!
netstat:查看当前连接状态
NAMEnetstat - Print network connections, routing tables, interface statistics, masquerade connections, and multicast membershipsnetstat -ant | less
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:1947 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 192.168.2.99:47356 192.168.103.243:8080 ESTABLISHED
tcp 0 1 192.168.2.99:60912 142.251.42.234:443 SYN_SENT
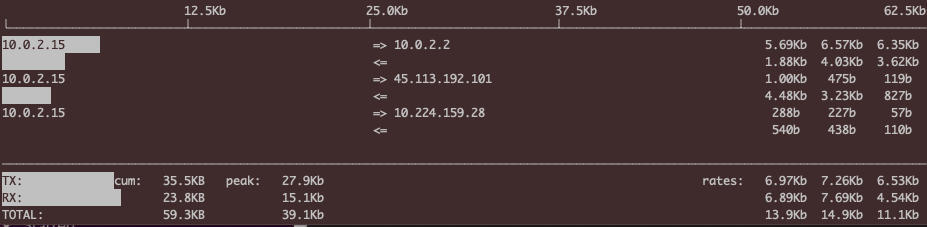
iftop:查看当前连接的传输速率
NAMEiftop - display bandwidth usage on an interface by hostSYNOPSISiftop -h | [-nNpblBP] [-i interface] [-f filter code] [-F net/mask] [-G net6/mask6]DESCRIPTIONiftop listens to network traffic on a named interface, or on the first interface it can find which looks like an external interface if none is specified, and displays a table of current bandwidth usage by pairs of hosts.iftop must be run with sufficient permissions to monitor all network traffic on the interface; see pcap(3) for more information, but on most systems this means that it must be run as root.By default, iftop will look up the hostnames associated with addresses it finds in packets. This can cause substantial traffic of itself, and may result in a confusing display. You may wish to suppress display of DNS trafficby using filter code such as not port domain, or switch it off entirely, by using the -n option or by pressing r when the program is running.By default, iftop counts all IP packets that pass through the filter, and the direction of the packet is determined according to the direction the packet is moving across the interface. Using the -F option it is possible toget iftop to show packets entering and leaving a given network. For example, iftop -F 10.0.0.0/255.0.0.0 will analyse packets flowing in and out of the 10.* network.Some other filter ideas:not ether host ff:ff:ff:ff:ff:ffIgnore ethernet broadcast packets.port http and not host webcache.example.comCount web traffic only, unless it is being directed through a local web cache.icmp How much bandwidth are users wasting trying to figure out why the network is slow?
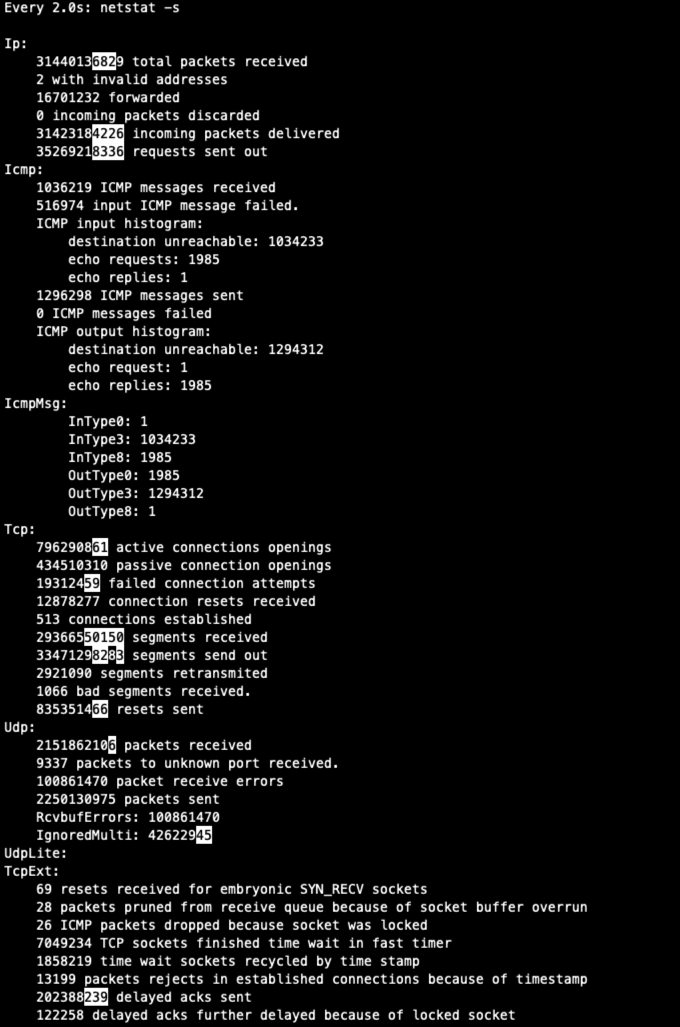
netstat -s: 查看丢包和乱序的统计
netstat 处理可获取实时连接状态,还可获取历史统计信息。例如你怀疑一台机器网络很不稳定,除了用 PING,还可用 netstat -s 获取更详细信息。例如其中的 TCP 丢包和乱序的计数值,可以帮你判断传输层的状况。
netstat -s
...
Tcp:796288992 active connections openings434510098 passive connection openings19310764 failed connection attempts12878149 connection resets received511 connections established29366081857 segments received33470764155 segments send out2921003 segments retransmited1066 bad segments received.835349688 resets sent
TcpExt:69 resets received for embryonic SYN_RECV sockets28 packets pruned from receive queue because of socket buffer overrun26 ICMP packets dropped because socket was locked7049182 TCP sockets finished time wait in fast timer1858219 time wait sockets recycled by time stamp...
还可用 watch --diff netstat -s 查看动态变化,如下图所示:
当然你可以把 netstat -s 的输出值写入 TSDB,并用 Grafana 展示历史曲线,可得到历史任意时刻的值,和抖动速率,这是更专业的运维操作。
ss:新一代 netstat
netstat 的功能被拆分到 ss 和 ip 两个命令中,并分别得到加强。
SS(8) System Manager's Manual SS(8)NAMEss - another utility to investigate socketsSYNOPSISss [options] [ FILTER ]DESCRIPTIONss is used to dump socket statistics. It allows showing information similar to netstat. It can displaymore TCP and state information than other tools.ss -s
Total: 78
TCP: 0 (estab 0, closed 0, orphaned 0, timewait 0)Transport Total IP IPv6
RAW 0 0 0
UDP 2 1 1
TCP 0 0 0
INET 2 1 1
FRAG 0 0 0
网络层
traceroute: 查看网络路径状况
TRACEROUTE6(8) iputils TRACEROUTE6(8)NAMEtraceroute6 - traces path to a network hostSYNOPSIStraceroute6 [-dnrvV] [-i interface] [-m max_ttl] [-p port] [-q max_probes] [-s source] [-w wait time]{destination} [size]DESCRIPTIONDescription can be found in traceroute(8), all the references to IP replaced to IPv6. It is needless tocopy the description from there.
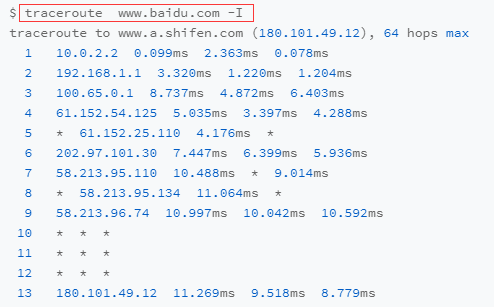
mtr: 连续多次路径探测
mtr 是 traceroute 的超集,有丰富的探测报告,它的 每一跳丢包的百分比 是定位路径中节点问题的重要指标。当遇到连接状况时好时坏时,单纯的一次 traceroute 难以看清楚,则可用 mtr 获取更全面的链路状态。
MTR(8) System Administration MTR(8)NAMEmtr - a network diagnostic toolSYNOPSISmtr [-4|-6] [-F FILENAME] [--report] [--report-wide] [--xml] [--gtk] [--curses] [--displaymode MODE][--raw] [--csv] [--json] [--split] [--no-dns] [--show-ips] [-o FIELDS] [-y IPINFO] [--aslookup] [-i IN‐TERVAL] [-c COUNT] [-s PACKETSIZE] [-B BITPATTERN] [-G GRACEPERIOD] [-Q TOS] [--mpls] [-I NAME] [-a AD‐DRESS] [-f FIRST-TTL] [-m MAX-TTL] [-U MAX-UNKNOWN] [--udp] [--tcp] [--sctp] [-P PORT] [-L LOCALPORT][-Z TIMEOUT] [-M MARK] HOSTNAMEDESCRIPTIONmtr combines the functionality of the traceroute and ping programs in a single network diagnostic tool.As mtr starts, it investigates the network connection between the host mtr runs on and HOSTNAME by send‐ing packets with purposely low TTLs. It continues to send packets with low TTL, noting the response timeof the intervening routers. This allows mtr to print the response percentage and response times of theinternet route to HOSTNAME. A sudden increase in packet loss or response time is often an indication ofa bad (or simply overloaded) link.The results are usually reported as round-trip-response times in milliseconds and the percentage of pack‐etloss.root@node# mtr www.baidu.com -r -c 10
Start: 2022-11-14T23:15:07+0800
HOST: abc Loss% Snt Last Avg Best Wrst StDev1.|-- y.mshome.net 0.0% 10 0.9 1.1 0.4 1.4 0.32.|-- bogon 0.0% 10 5.9 5.3 4.8 6.3 0.43.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.04.|-- bogon 0.0% 10 24.1 30.0 19.8 50.3 11.15.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.06.|-- 36.112.243.137 0.0% 10 17.3 31.5 16.5 65.0 14.07.|-- 36.112.243.153 0.0% 10 42.6 32.6 19.3 44.0 8.98.|-- 36.110.248.126 80.0% 10 43.0 31.2 19.4 43.0 16.79.|-- 36.110.249.58 70.0% 10 36.1 34.5 27.7 39.6 6.110.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.011.|-- 220.181.17.94 0.0% 10 42.8 39.4 24.8 54.3 9.912.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.013.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.014.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.015.|-- 220.181.38.149 0.0% 10 46.8 34.7 19.3 49.6 11.7
route、netstat、ip: 查看路由
ROUTE(8) Linux System Administrator's Manual ROUTE(8)NAMEroute - show / manipulate the IP routing tableSYNOPSISroute [-CFvnNee] [-A family |-4|-6]route [-v] [-A family |-4|-6] add [-net|-host] target [netmask Nm] [gw Gw] [metric N] [mss M] [window W][irtt I] [reject] [mod] [dyn] [reinstate] [[dev] If]route [-v] [-A family |-4|-6] del [-net|-host] target [gw Gw] [netmask Nm] [metric M] [[dev] If]route [-V] [--version] [-h] [--help]DESCRIPTIONRoute manipulates the kernel's IP routing tables. Its primary use is to set up static routes to specifichosts or networks via an interface after it has been configured with the ifconfig(8) program.When the add or del options are used, route modifies the routing tables. Without these options, routedisplays the current contents of the routing tables.y# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default y.mshome.net 0.0.0.0 UG 0 0 0 eth0
192.168.128.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0y# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.128.1 0.0.0.0 UG 0 0 0 eth0
192.168.128.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0y# netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window irtt Iface
default y.mshome.net 0.0.0.0 UG 0 0 0 eth0
192.168.128.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0y# ip route
default via 192.168.128.1 dev eth0 proto kernel
192.168.128.0/20 dev eth0 proto kernel scope link src 192.168.129.90
数据链路层、物理层
ethtool: 查看网卡驱动
ETHTOOL(8) System Manager's Manual ETHTOOL(8)NAMEethtool - query or control network driver and hardware settingsy# ethtool -S eth0
NIC statistics:tx_scattered: 0tx_no_memory: 0tx_no_space: 0tx_too_big: 0tx_busy: 0tx_send_full: 0rx_comp_busy: 0rx_no_memory: 0stop_queue: 0wake_queue: 0vlan_error: 0vf_rx_packets: 0vf_rx_bytes: 0vf_tx_packets: 0vf_tx_bytes: 0vf_tx_dropped: 0tx_queue_0_packets: 547tx_queue_0_bytes: 170662...
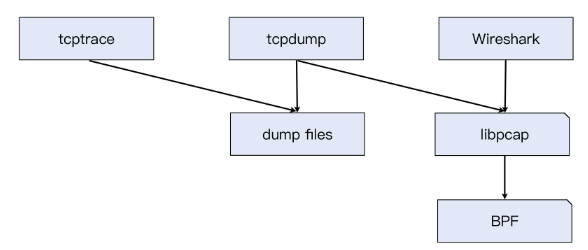
抓包
BPF(Berkeley Packet Filter)利用基于寄存器的虚拟机方式,可以高效稳定地过滤报文。
libpcap 提供 API 给用户空间程序(如 tcpdump、Wireshark等)。
tcpdump、Wireshark等调用 libpcap 的 API 来抓包。
各工具的拓扑结构如下:
抓包文件格式
- pcap:是 libpcap 程序的格式,因此基于 libpcap 的旧版本的 tcpdump、Wireshark 的格式也都是 pcap。其中除了报文数据,还包括抓包文件的元信息、版本号、抓包时间、各报文被抓取的最大长度。
- cap:是由 tcpdump 之外的其他抓包程序使用的格式,例如 Wireshark 可读取此格式。
- pcapng:因为现代机器有多个网口,此格式会包含哪个网口的信息,新版本的 tcpdump、Wireshark 均用此格式。如下图右侧即为指明为 en0 网口的包:

tcpdump 用法
TCPDUMP(8) System Manager's Manual TCPDUMP(8)NAMEtcpdump - dump traffic on a networkSYNOPSIStcpdump [ -AbdDefhHIJKlLnNOpqStuUvxX# ] [ -B buffer_size ][ -c count ][ -C file_size ] [ -G rotate_seconds ] [ -F file ][ -i interface ] [ -j tstamp_type ] [ -m module ] [ -M secret ][ --number ] [ -Q in|out|inout ][ -r file ] [ -V file ] [ -s snaplen ] [ -T type ] [ -w file ][ -W filecount ][ -E spi@ipaddr algo:secret,... ][ -y datalinktype ] [ -z postrotate-command ] [ -Z user ][ --time-stamp-precision=tstamp_precision ][ --immediate-mode ] [ --version ][ expression ]DESCRIPTIONTcpdump prints out a description of the contents of packets on a network interface that match the boolean expres‐sion; the description is preceded by a time stamp, printed, by default, as hours, minutes, seconds, and fractionsof a second since midnight. It can also be run with the -w flag, which causes it to save the packet data to afile for later analysis, and/or with the -r flag, which causes it to read from a saved packet file rather than toread packets from a network interface. It can also be run with the -V flag, which causes it to read a list ofsaved packet files. In all cases, only packets that match expression will be processed by tcpdump.Tcpdump will, if not run with the -c flag, continue capturing packets until it is interrupted by a SIGINT signal(generated, for example, by typing your interrupt character, typically control-C) or a SIGTERM signal (typicallygenerated with the kill(1) command); if run with the -c flag, it will capture packets until it is interrupted by aSIGINT or SIGTERM signal or the specified number of packets have been processed.
如何抓取报文
tcpdump host 192.168.2.99 # 抓去往或来自某IP的报文
tcpdump port 22 # 抓某端口的流量
其参数如下:
-w 文件名,可以把报文保存到文件;
-c 数量,可以抓取固定数量的报文,这在流冖较高时,可以避免一不小心抓取过多报文;
-s 长度,可以只抓取每个报文的一定长度。例如 tcpdump -s 74 -w file.pcap,默认是抓 1500 字节,而我们可以手动指定每个报文只抓前74个字节,如下图所示:
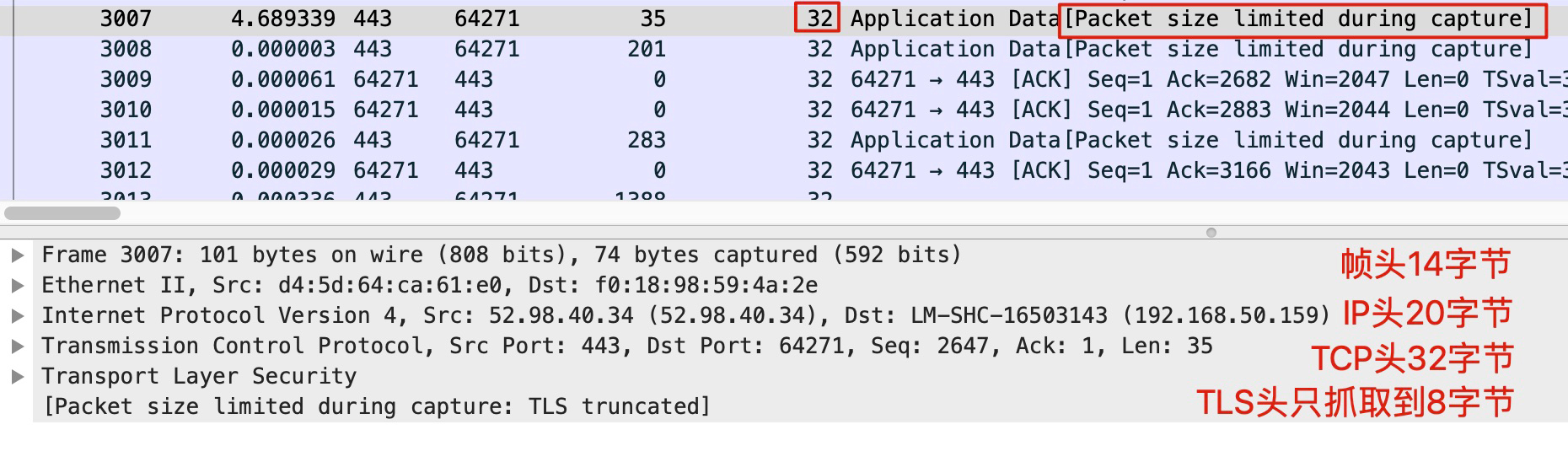
-n,不做地址转换(比如P 地址转换为主机名,port 80 转换为 http)
-v/-vv/-vvv,可以打印更加详细的报文信息;
-e,可以打印二层信息,特别是 MAC 地址;
-p,关闭混杂模式。所谓混杂模式,也就是嗅探(Sniffering),就是把目的地址不是本机地址的网络报文也抓取下来。
-X 抓包时显示报文内容
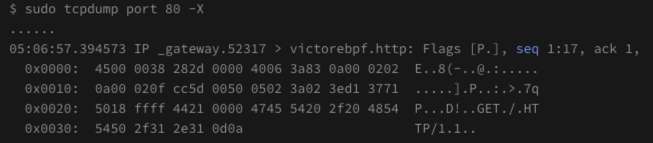
-r 读取抓包文件, 如 tcpdump -r file. pcap ' tep [tepflags] & (tcp-rst) != 0"
-r -w 过滤后转存,如 tcpdump -r file. pcap ' tep [tcpflags] & (tcp-rst) 1= 0 -W rst.pcap
如何过滤报文
最近我们有个实际的需求,要统计我们某个 HTTPS VIP 的访问流量里,TLS 版本(现在主要是TLS1.0、11、1.2、13) 的分布。为了控制抓包文件的大小,我们义不想什么 TLS报文都抓,只想抓取 TLS 版本信息。这该如何做到呢?要知道,针对这个需求,tcpdump 本身没有一个现成的过滤器。
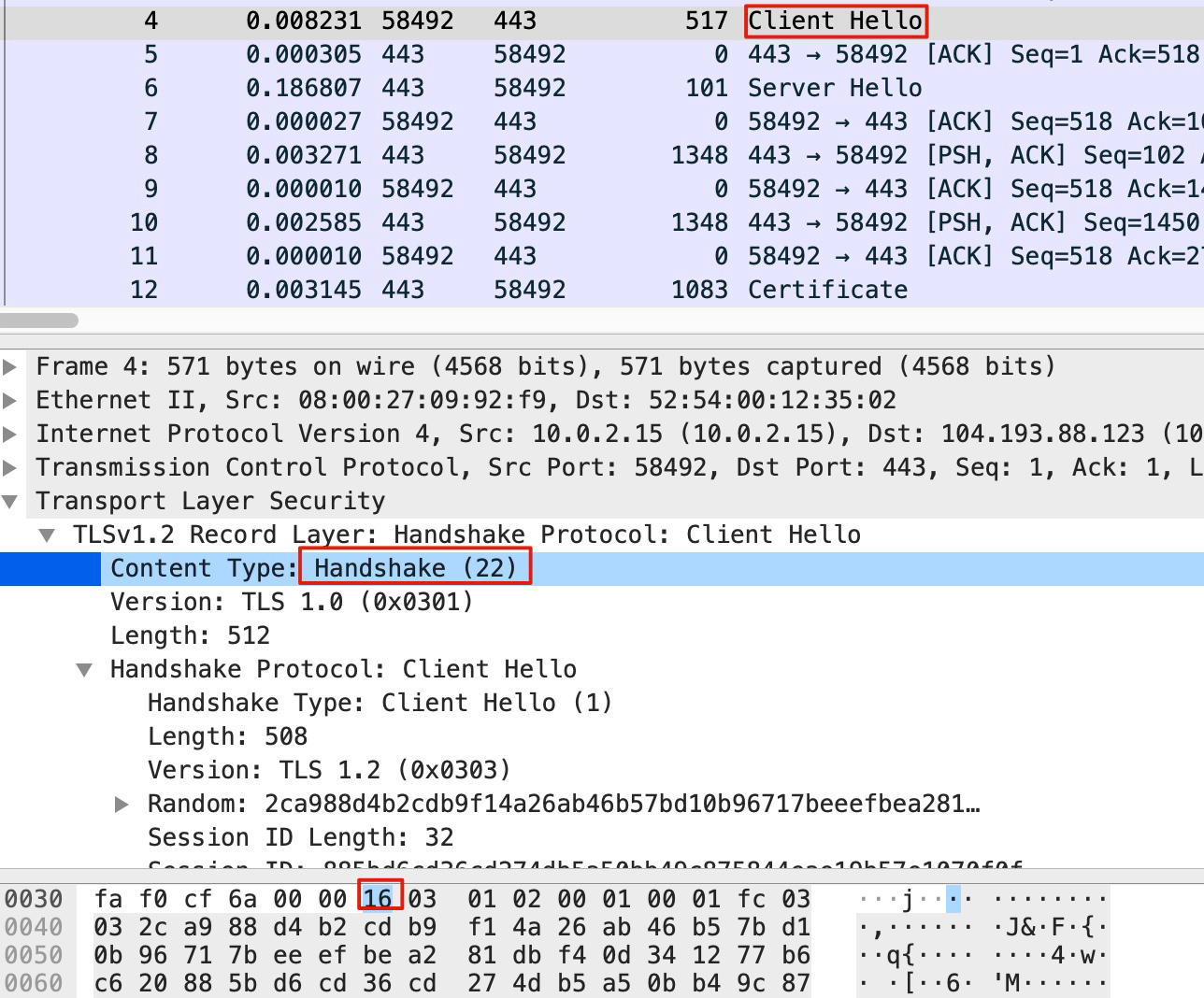
其实,BPF 本身是基于偏移量来做报文解析的,所以我们也可以在 tcpdump 中使用这种偏移量技术,实现我们的需求。下面这个命令,就可以抓取到 TLS 握手阶段的 Client Hello 报文:
tcpdump -w file.pcap 'dst port 443 && tcp[20]==22 && tcp [25]==1
我给你解榉一下上面的三个过滤条件。
- dst port 443:这个最简单,就是抓取从客户端发过来的访问 HTTPS 的报文。
- topl20]-=22:这是提取了 TCP 的第21 个字节(因为初始序号是从 。 开始的),由于 TCP 头部占20字节,TLS 又是 TCP 的载荷,那么 TLS 的第1个字节就是 TCP 的第21个字节,也就是 TCP1201,这个位置的值如果是 22(十进制〉,那么就表明这个是 TLS握手报文。
- top[25]==1:同理,这是 TCP 头部的第26 个字节,如果它等于1,那么就表明这个是 Client Hello 类型的 TLS 握手报文。
下面是抓包文件里的样子:
这里你可能会有疑问:上面的图里,TCP[20]的位置的值不是16 吗?其实,这个是十六进制的16,换算成十进制,就是22了。
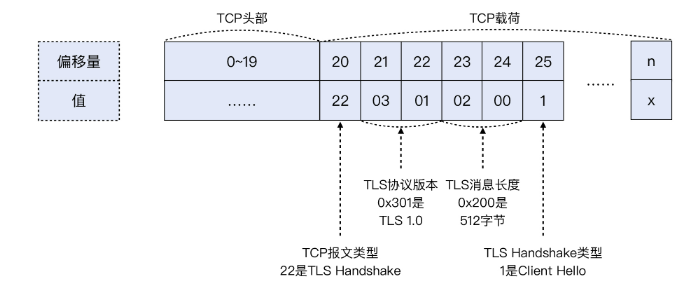
我又画了一张示意图来表示报文偏移量及其含义,希望能帮你理解其中的奥妙,具体 TCP 各位的含义如下:
tcpdump 预定义了一些相对方便的过滤器
- 例如若向过滤出 TCP RST 报文,可用如下写法:
用过滤器的写法为 tcpdump -w file.pcap 'tcp[tcpflags]&(tcp-rst) != 0'
或者用偏移量的写法则为 tcpdump -w file.pcap 'tcp[13]&4 != 0'
- 例如抓取 TCP SYN 包,可用如下写法:
tcpdump 'tcp[13] = 2' -w file.pcap
tcpdump -s 34 -w file.pcap
tcpdump host xxxx and 'tcp[tcpflags] == tcp-syn'
Wireshark 用法
确认是在哪端抓的包
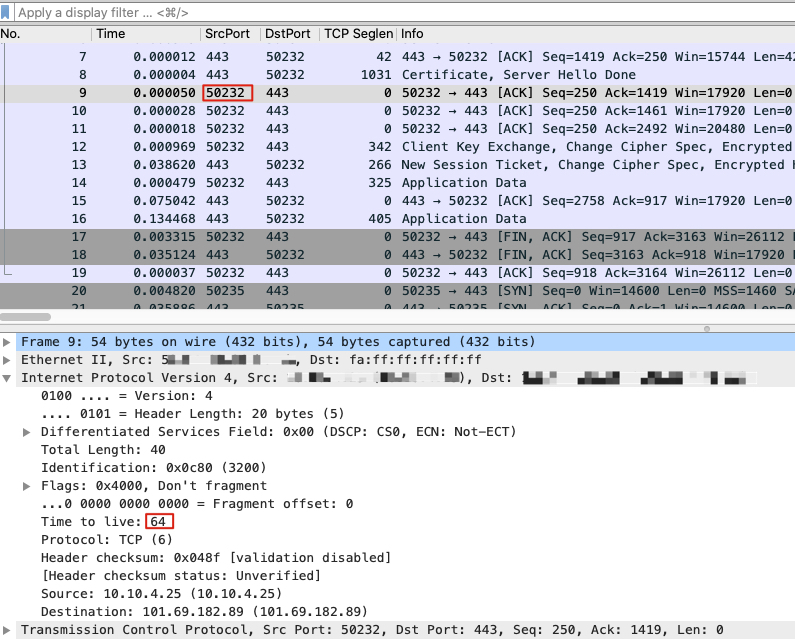
为了确认是在客户端还是服务端做的抓包,可用 IP 的 TTL 属性判断。
因为客户端(即发起端)的 TTL 都是64、128、256中的某一个,而服务端(即接收端)报文的 TTL 都会因为中间经过若干网络跳数而减少。
因此若报文的 TTL 为 64、128、256之一,则一定是客户端的报文,如下图所示:
定位应用层的请求和响应
只要在 Wireshark 中选中请求报文,则会自动匹配对应的响应报文。如下图是一个 HTTP Server 端的抓包,向右的箭头表示数据进来,向左的箭头表示数据出去。

只截到一部分报文
若出现上图错误,不必关注,可能因为不是用 ctrl + c 方式结束的(如 kill -9),导致 tcpdump 被强行终止,使得一部分被抓取的报文还在内存中,没来得及由 tcpdump 正常写入到 pcap 文件中。
可通过用 ctrl + c、kill (不带 -9参数)来停止 tcpdump。
乱序有问题吗
乱序是通常存在的,但若超过 10% 都乱序,则可能传输质量严重有问题,可能导致传输失败,或者应用层的各种卡顿、报错。
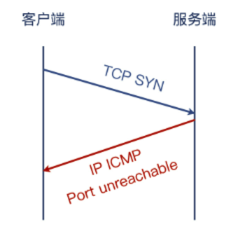
TCP 握手
- client 发 SYN
- server 收到 SYN 后,回复 SYN + ACK
- client 收到 SYN + ACK 后,回复 ACK
其中 SYN 会在两端各发一次,表示 “我准备好了,可以开始连接了”。其中 ACK 也是两端各发一次,表示 “我知道你准备好了,我们开始通信吧!”。
其实很像现在腾讯会议开会或打电话时,若总共有两个人。
- a 先说:能听到吗?
- b 听到后再说:我能听到你,你能听到我吗?
- a 听到后说:我能听到你。开始正题吧!
这里其实共有4个报文,但是是3次发送,因为 server 的 SYN + ACK 是合并发送的(术语是 Piggybacking,即搭顺风车之意),这样可以节省一次发送次数。
如果 server 不想接受这次握手,可以有如下两种选择:
- 已读未回:术语叫做静默丢包。即不搭理这次连接,当做什么都没发生。这种情况因为 server 做了静默丢包,而 client 就不知道到底是如下哪种行为了。
- 情况1:client 发送的 SYN 在网络中丢失了,从而导致 server 压根没收到
- 情况2:client 发送的 SYN 已到达 server,但 server 就是选择已读不回。
- 情况3:client 发送的 SYN 已到达 server,server 也回复了 SYN + ACK,但 server 回复的包在网络中丢失了从而导致 client 未收到。
- 通常 client 为了应对上述这三种情况,会重试。
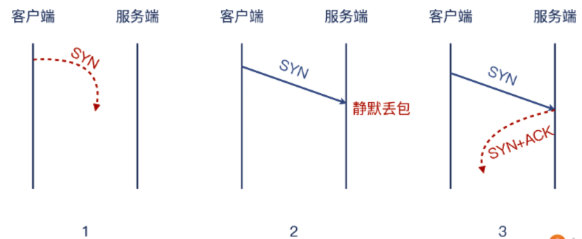
- 已读直接拒绝:这也是非常猛的行为了。
借助 iptables、tcpdump 的重试观察实验
server 设置为 DROP 策略
export PS1='[\u@server]\$'# server 端,让iptables 静默丢弃发往自己 9999 端口的数据包
root@server:~# iptables -I INPUT -p tcp --dport 9999 -j DROP# server 端,查看设置的 iptables
root@server:~# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP tcp -- anywhere anywhere tcp dpt:9999Chain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destination
export PS1='[\u@client]\$'# 在 client 端,启动 tcpdump
[root@client]#tcpdump -i any -w telnet-9999.pcap port 9999
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes# 此时在 client,向 server 发起 telnet,会被挂起,直到2min左右才失败退出
[root@client]#telnet 192.168.2.server 9999
Trying 192.168.2.server...# 我们手动再 client 端,ctrl + c 终止 client, 即可得到 tcpdump 的文件如下:
-rw-r--r-- 1 root root 668 Nov 16 12:14 telnet-9999.pcap
然后我们用 WireShark 打开这个名为 telnet-9999.pcap 的抓包文件,如下图:
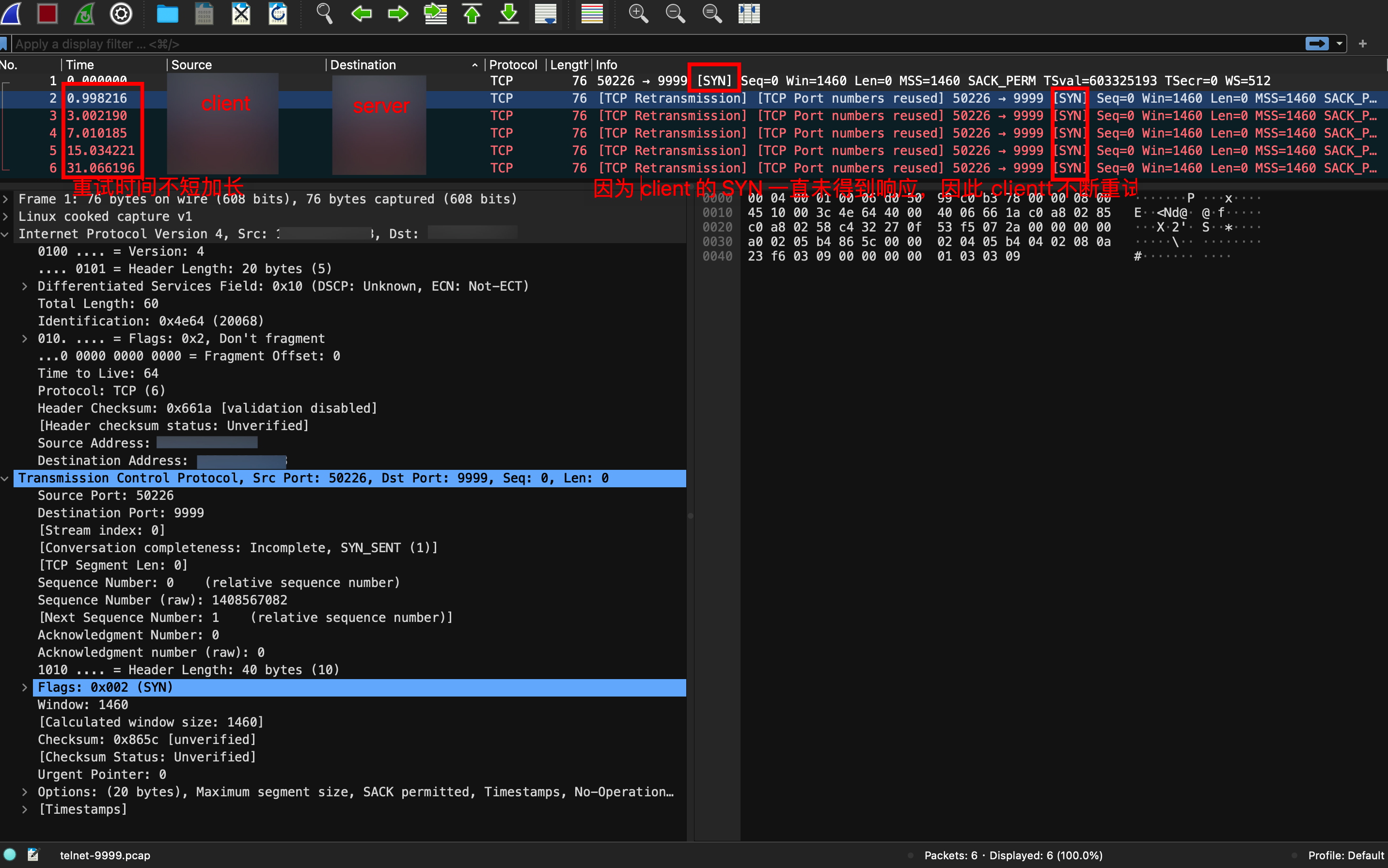
可看到,因为 client 的握手一直未成功,client 总共发了6个包,后五个均为重试。
- 每次重试时间间隔都是上次重试的二倍。这里的翻倍时间是
指数退避策略(Exponential backoff),且每次不是精确的整数秒,这样来让加大重试成功的几率。 - 到第6次重试失败时,client 就彻底放弃了。这个参数是由 Linux 内核的
net.ipv4.tcp_syn_retries = 6参数控制的。
[root@client]#sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6[root@client]#man tcp | grep -A 3 tcp_syn_retriestcp_syn_retries (integer; default: 6; since Linux 2.2)The maximum number of times initial SYNs for an active TCP connection attempt will be retransmitted. This value should not be higher than 255. The default value is 6, which corresponds to retrying for up to approxi‐mately 127 seconds. Before Linux 3.7, the default value was 5, which (in conjunction with calculation based on other kernel parameters) corresponded to approximately 180 seconds.
server 设置为 REJECT 策略
export PS1='[\u@server]\$'# 设置 server 为 REJECT 策略
[root@server]#iptables -I INPUT -p tcp --dport 9999 -j REJECT
[root@server]#iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
REJECT tcp -- anywhere anywhere tcp dpt:9999 reject-with icmp-port-unreachable
DROP tcp -- anywhere anywhere tcp dpt:9999Chain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destination
client 用 tcpdump 指定监听的 port
# 然后在 client 端,启动 tcpdump 来抓包
[root@client]#tcpdump -i any -w telnet-9999.pcap host 192.168.2.server port 9999
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes# 然后在 client 端,用 telnet 来向 server 握手
[root@client]#telnet 192.168.2.server 9999
Trying 192.168.2.server...
telnet: Unable to connect to remote host: Connection refused # 我们会发现果然立刻就被拒绝了# 在 client 端,通过 ctrl + c 手动中指 tcpdump 后,日志打印果然抓到了一个包
^C
1 packet captured
1 packet received by filter
0 packets dropped by kernel
然后我们用 Wireshark 分析,效果如下,因为用 tcpdump 只指定监听了 9999 端口,而 server 端返回的 拒绝信号是用 ICMP 报文,所以下图只能看到 client 发送的消息,而看不到 server 回复的拒绝消息:
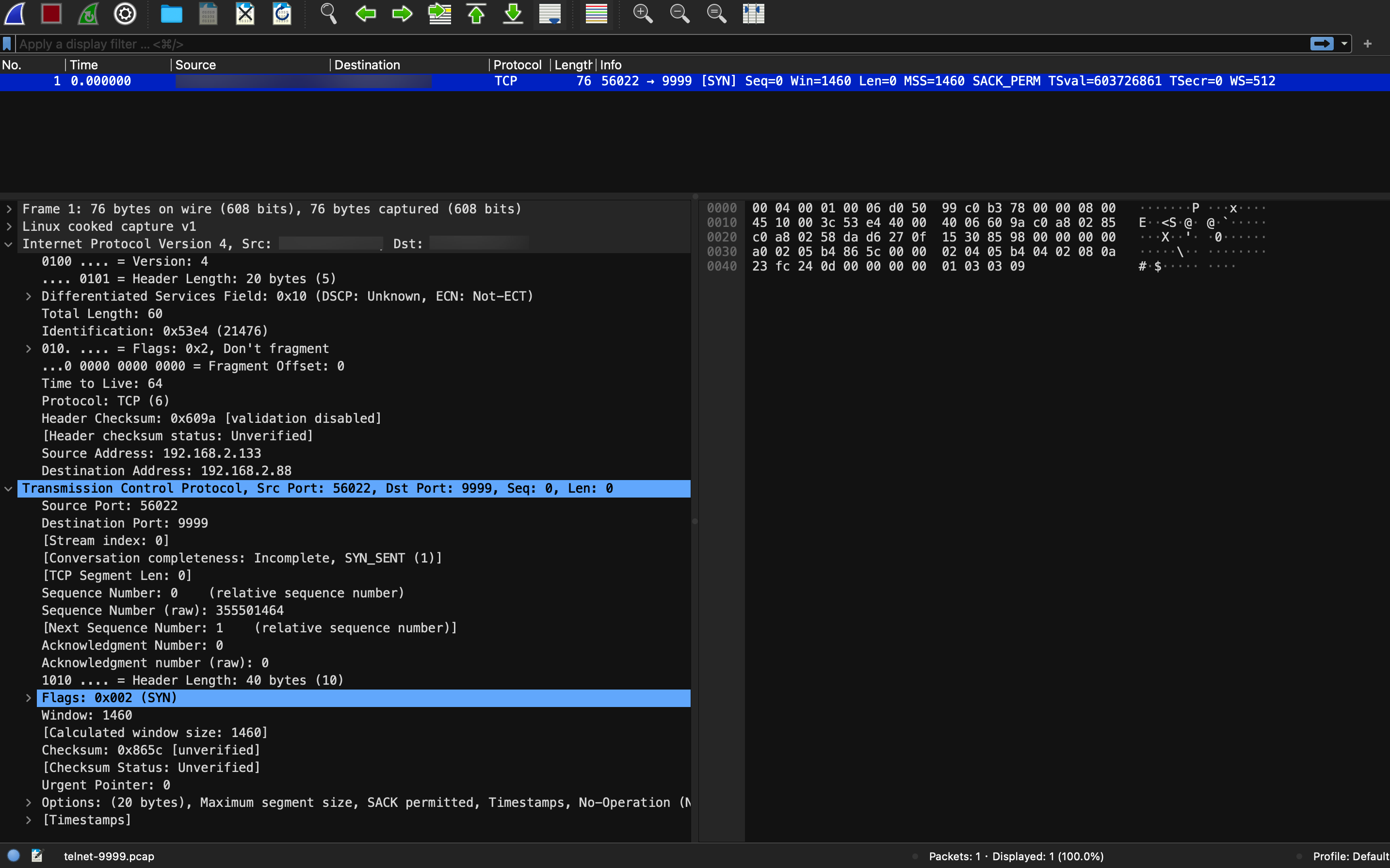
client 用 tcpdump 不指定监听的 port
# 然后在 client 端,启动 tcpdump 来抓包
[root@client]#tcpdump -i any -w telnet-anyport.pcap host 192.168.2.server
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes# 然后在 client 端,用 telnet 来向 server 握手
[root@client]#telnet 192.168.2.server 9999
Trying 192.168.2.server...
telnet: Unable to connect to remote host: Connection refused # 我们会发现果然立刻就被拒绝了# 在 client 端,通过 ctrl + c 手动中指 tcpdump 后,日志打印果然抓到了一个包
^C
2 packets captured
2 packets received by filter
0 packets dropped by kernel
然后我们用 Wireshark 分析,效果如下,可以看到 client 发送的消息,和 server 回复的拒绝消息:
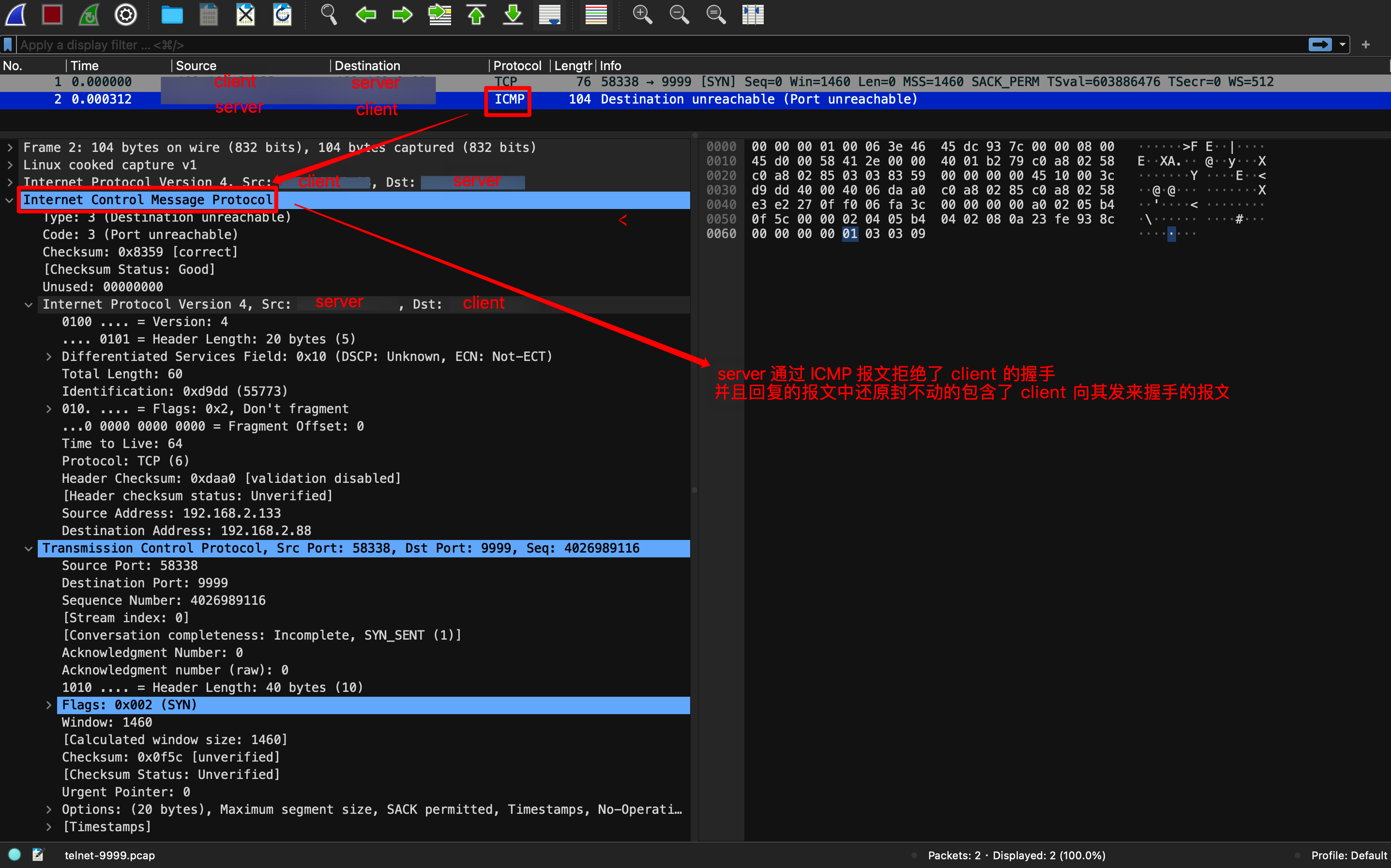
其实 server 选择用 ICMP 回复拒绝报文,是因为默认的 iptables DROP 策略是 ICMP 报文,即下文中的reject-with icmp-port-unreachable:
root@server]#iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
REJECT tcp -- anywhere anywhere tcp dpt:9999 reject-with icmp-port-unreachable
DROP tcp -- anywhere anywhere tcp dpt:9999Chain FORWARD (policy ACCEPT)
target prot opt source destinationChain OUTPUT (policy ACCEPT)
target prot opt source destination
当然我们也可以设置为 --reject with tcp-reset。但无论哪种拒绝报文(TCP RST 或 ICMP port unreachable),client 端的 connect() 都会返回 ECONNREFUSED,即最终让 telnet 报错 “connection refused”。
实验做完记得用 iptables -D INPUT 1 来删除刚才设置的规则。
TCP 状态转移
出自《UNIX 网络编程:套接字联网 API》一书:
两端的交互和状态转移如下:
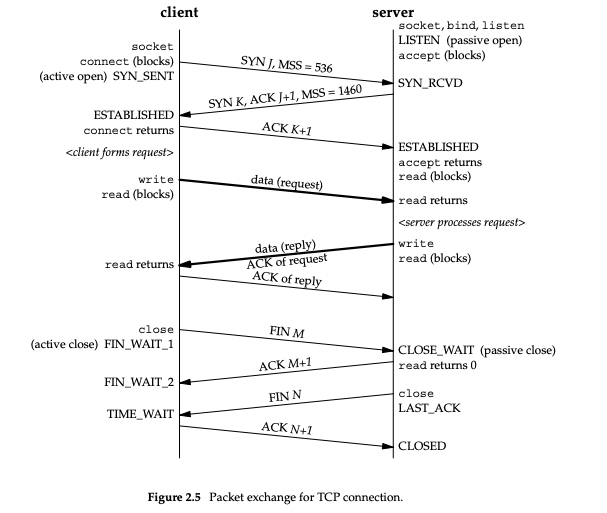
其中前三次握手的过程如下:
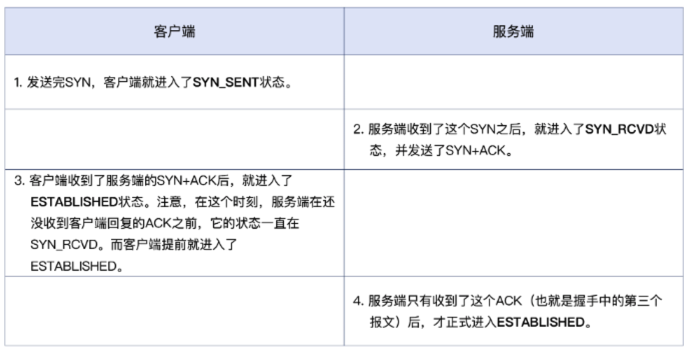
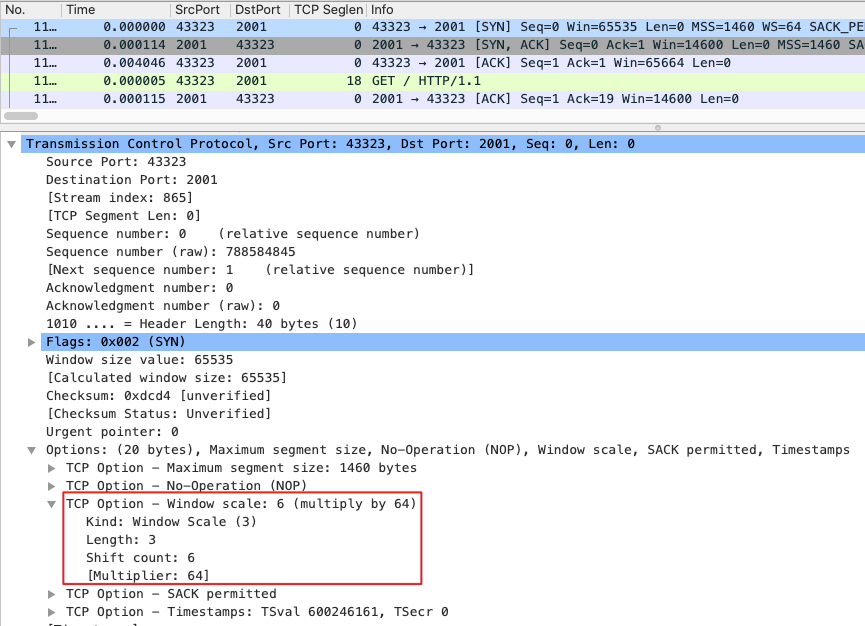
TCP 的窗口大小,只有第一次握手时的报文会包含,后续报文均不再包含此字段(避免话痨,让重复信息浪费带宽)。因为 TCP 协议是在1981年确立的,当时网络带宽太小了,所以预留的字段不够。因此现代的 TCP 窗口大小,都是用 TCP 扩展部分 TCP Options 里的 WindowScale 字段来标识将 65535 右移的位数。
例如下图的 TCP Options.Kind 为 3,表示意为 Window Scale。而 Shift Offset = 6,则 65536 右移 6 位,即把 65535 乘以 math.pow(2, 6),如下图:
常见误区的更正
UDP 其实并没有握手
- 因为 UDP 不是面向连接的,所以只要没有明确拒绝,nc 命令都视为连通。
- 因为 TCP 是面向连接的,所以只要没有明确接受,nc 命令都视为不连通。
所以,当我们用 nc 命令探测 UDP 端口时,不通的结果是可信的,而能通的结果却并不可信而只能作为参考。
例如下文实验
# server 端并没有程序在监听 22 端口# 但在 client 端,用 nc 命令,却得到 established 的响应,而这并不说明 server 的 22 端口被监听
[root@client]#nc -v -w 2 192.168.2.server 22
Connection to 192.168.2.server 22 port [tcp/ssh] succeeded!
SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.4
一台机器其实不止 65535 个连接
因为连接是四元组,虽然端口范围是 0 ~ 65535,但如果有 n 个 clientIP 的机器都来连接 serverIP,每个 clientIP 都有最多 65535 个连接,则共有 n * 65535 个连接。
所以一台 Web 服务器,支持 100w 个连接是完全可能的。
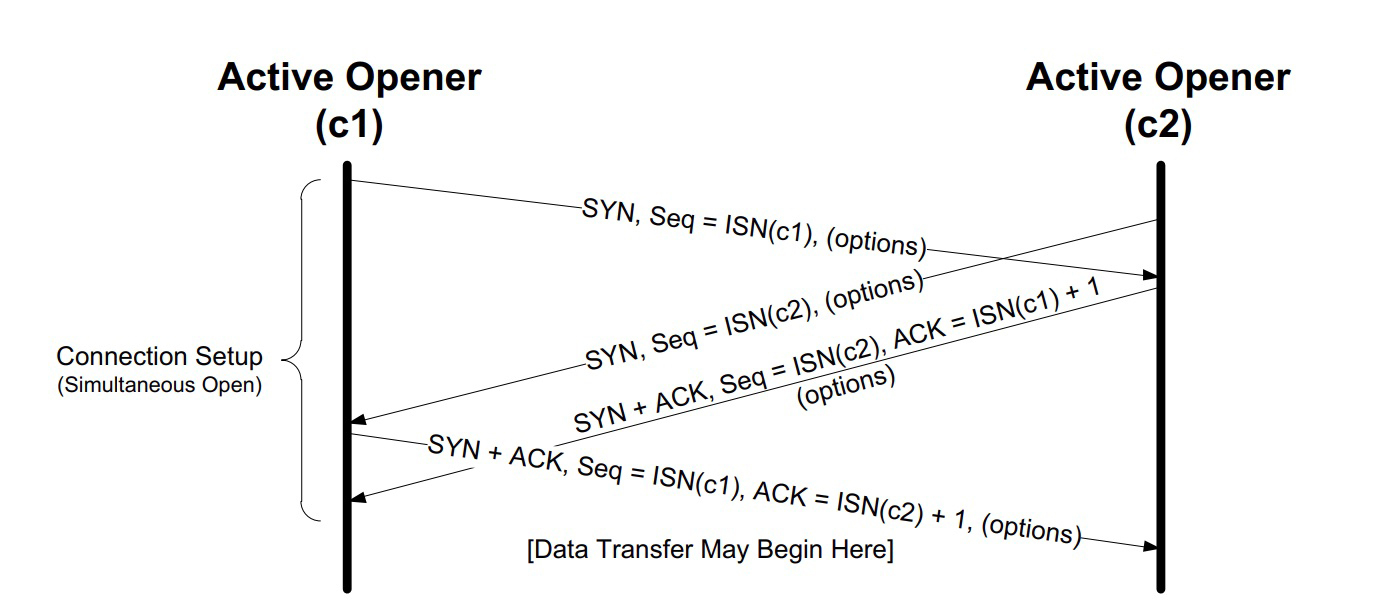
两端其实可以同时发起握手
如果两端同时向对端发送 SYN,虽然这种情况很罕见,但其实两端也是可以建立 TCP 连接的。如下图所示:
TCP 挥手
我们经常看到应用层 connection reset by peer 的报错,其实对应到传输层/网络层是指:对端(peer)回复了 TCP RST,从而终止了一次 TCP 连接。
为了解决问题,我们经常要将应用层的信息,翻译成传输层/网络层的信息。
- 应用层信息包括如下:
- 应用层日志:成功日志、报错日志
- 应用层性能数据:RPS(每秒的请求数)、transaction time(处理时间)
- 应用层载荷:HTTP 请求和响应的 header、body
- 传输层/网络层信息包括如下:
- 传输层:TCP 序列号、确号、MSS、接收窗口、拥塞窗口、时延、重复确认、选择性确认、重传、丢包
- 网络层:IP 的 TTL、MTU、跳数、路由表
connection reset by peer 原因
我们以一个 Nginx server 有很多 connection reset by peer 的报错作为分析案例,报错日志如下:

过滤报文
既然有了应用层日志,我们就可以用 tcpdump 抓包,用 Wireshark 打开抓包文件,并用如下过滤条件:
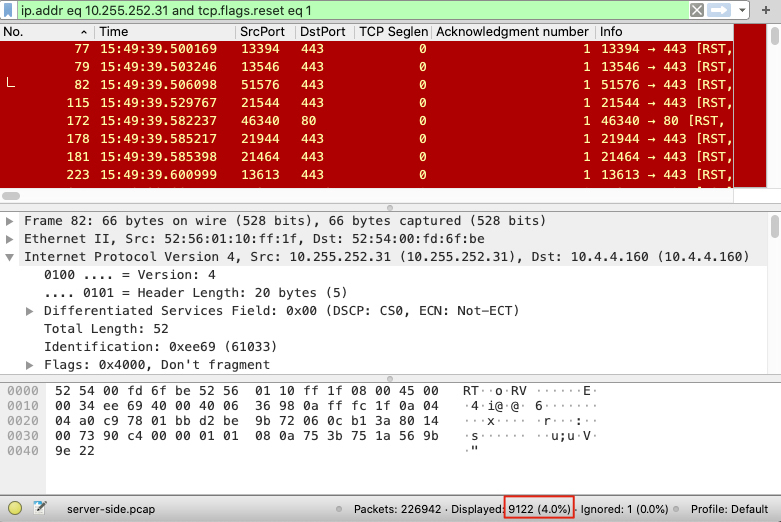
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1
我们即可在 Wireshark 中看到很多 RST 报文,而且右下角表示过滤后有 9122 这么多条的结果,共占了 4% 之多:
然后,选中某行报文,右键单击,选中 Follow => TCP Stream,找到它所属的整个 TCP 报文如下。可以看到这是三次握手的第三次报文,没有得到期望的 ACK,而是得到了 RST + ACK,从而导致握手失败了。但这种连三次握手都未成功而导致连接建立失败,并不会在 Nginx 日志中打印:

因此我们还需继续打磨 Wireshark 的过滤器,通过如下条件过滤掉握手阶段的 RST:
ip.addr eq 10.255.242.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1)
这样过滤出的报文如下:
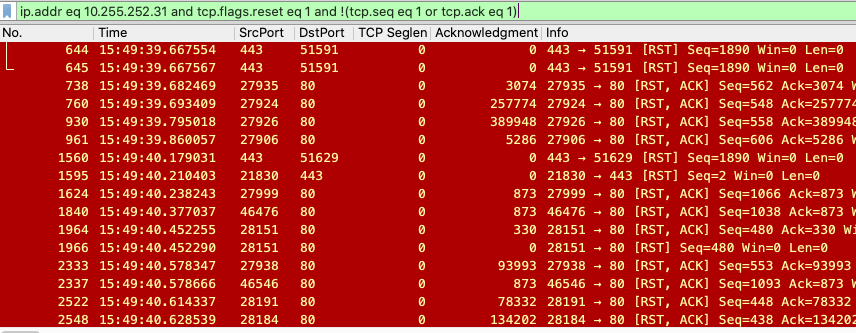
报文还是太多,我们可以再加上应用层信息的过滤:
ip.addr eq 10.255.242.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 or tcp.ack eq 1) and frame.time >= "dec 01, 2015 15:49:48" and frame.time <= "dec 01, 2015 15:49:49"
终于成功地锁定了只有 3个 RST 的报文,如下:

接下来,对比这 3个 RST 所在的 TCP 流里的应用层数据(即 HTTP 请求和响应),和应用层 Nginx 日志中的请求和响应做对比,即可得到是哪个 RST 引起的 Nginx 报错了。
分析报文
11393 号报文详情如下:
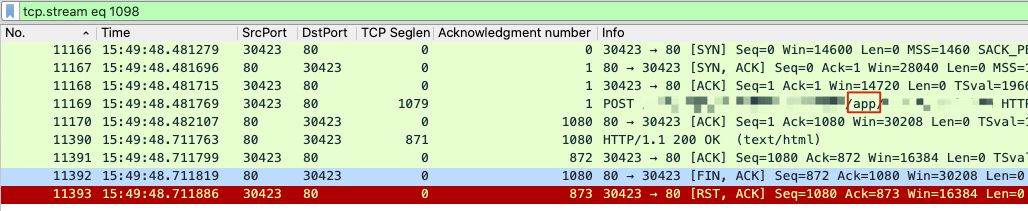
11448 号报文详情如下,因为其中可以也看到 11450号报文,所以说明 11448 和 11450 是在同一个流里的:
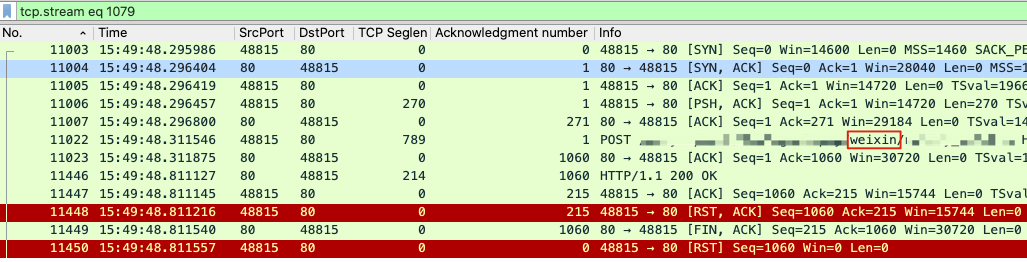
因此,3 个 RST 分属于 2 个 HTTP 事务。而我们 Nginx 日志在 “dec 01, 2015 15:49:48” 时的日志的 URL 是http://xxx/yyy/weixin/zzz 信息的,如下图(实际是一行 Nginx 日志,只是在本博文中分为两行来展示):


所以,我们匹配到的是 11448 和 11450 这两个报文,其实过程如下如所示:
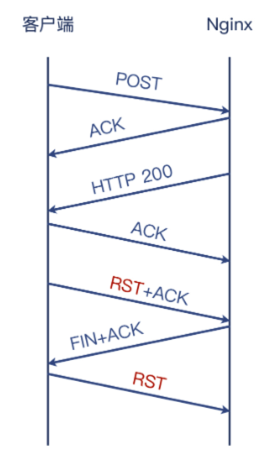
其实 server 收到 client 发送的 POST 报文,并且成功回复 HTTP 200 的响应,而且 client 也收到了 HTTP 200 的响应。
但是 client 端随后错误地发起了 RST + ACK 报文,导致 server 端调用的 recv() 方法收到 ECONNRESET 的报错,从而让 server
打印了 connection reset by peer 的日志。(
因为结论是 client 端使用方式有问题,即 client 直接用 RST 来断开连接的方式并不妥当,需要走查代码。
- 例如可能是由于 client 在 Receive Buffer 中还有未读数据的情况下调用 close() 而引起的
- 可能由于网络不稳定引起的
- 可能由于防火墙发出的 RST 引起的
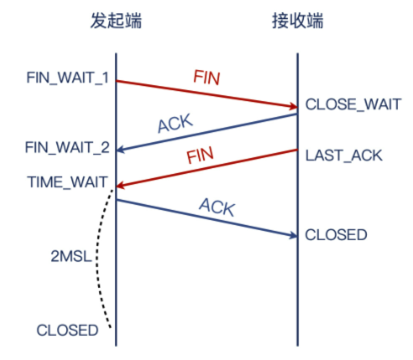
四次挥手确实必须两个 FIN
常规的四次挥手过程如下,其可有 client 端发起,也可有 server 端发起:
例如下文的抓包文件,看起来只有一个 FIN 并不符合理论,我们就针对这个报文做一个分析:

我们查看倒数第三行的 POST 报文详情如下,其中就有第一个 FIN,其实是被合并(Piggybacking)到 POST 报文里了,只是 Wireshark 并没有很好的可视化出来而已。:
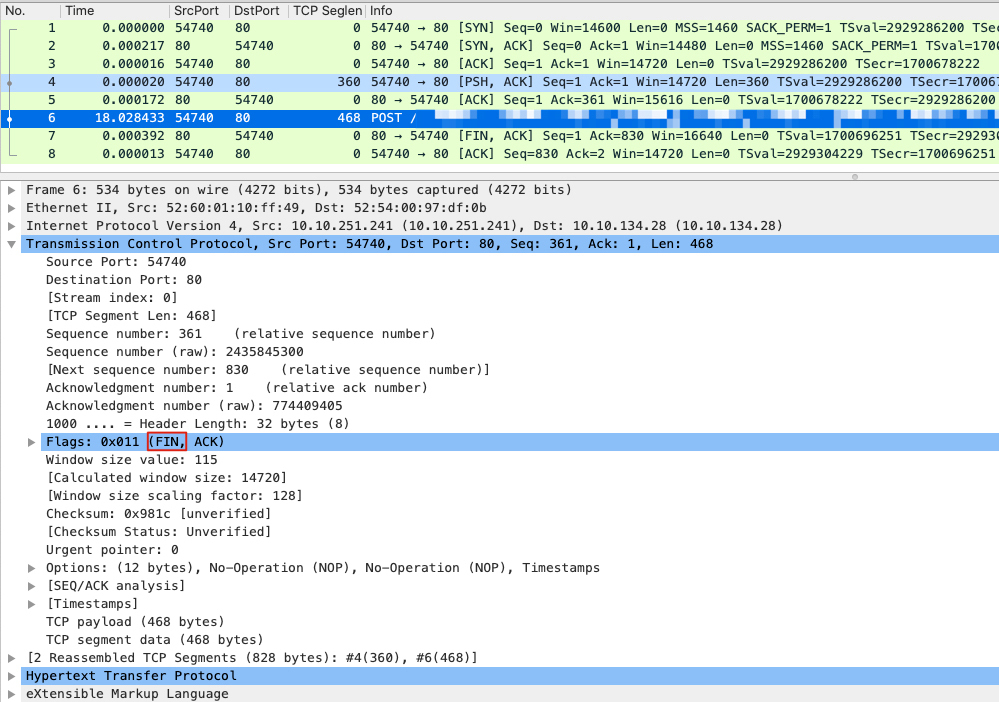
所以其实真实情况如下图右半部分所示:

所以,如果看到 Wireshark 的 FIN,并不能确认其就是四次挥手的第一个 FIN,还需要看其附近的报文详情里是否有 FIN 标志位,才能确认挥手发生的起点。
挥手时候的四个报文是
- 发起端:FIN
- 对端:ACK
- 对端:FIN
- 发起端:ACK
其中,2和3经常会在一起发送。除此以外,1和经常和发起端的其他报文一起发送
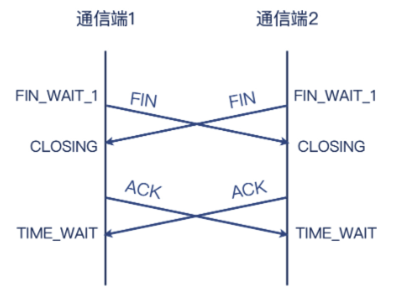
挥手其实可以同时发起
两端确实可以同时主动发起 FIN,此时两端同时进入 FIN_WAIT1 状态,都因为收到对方的 FIN 而进入 CLOSING 状态,都因为收到对方的
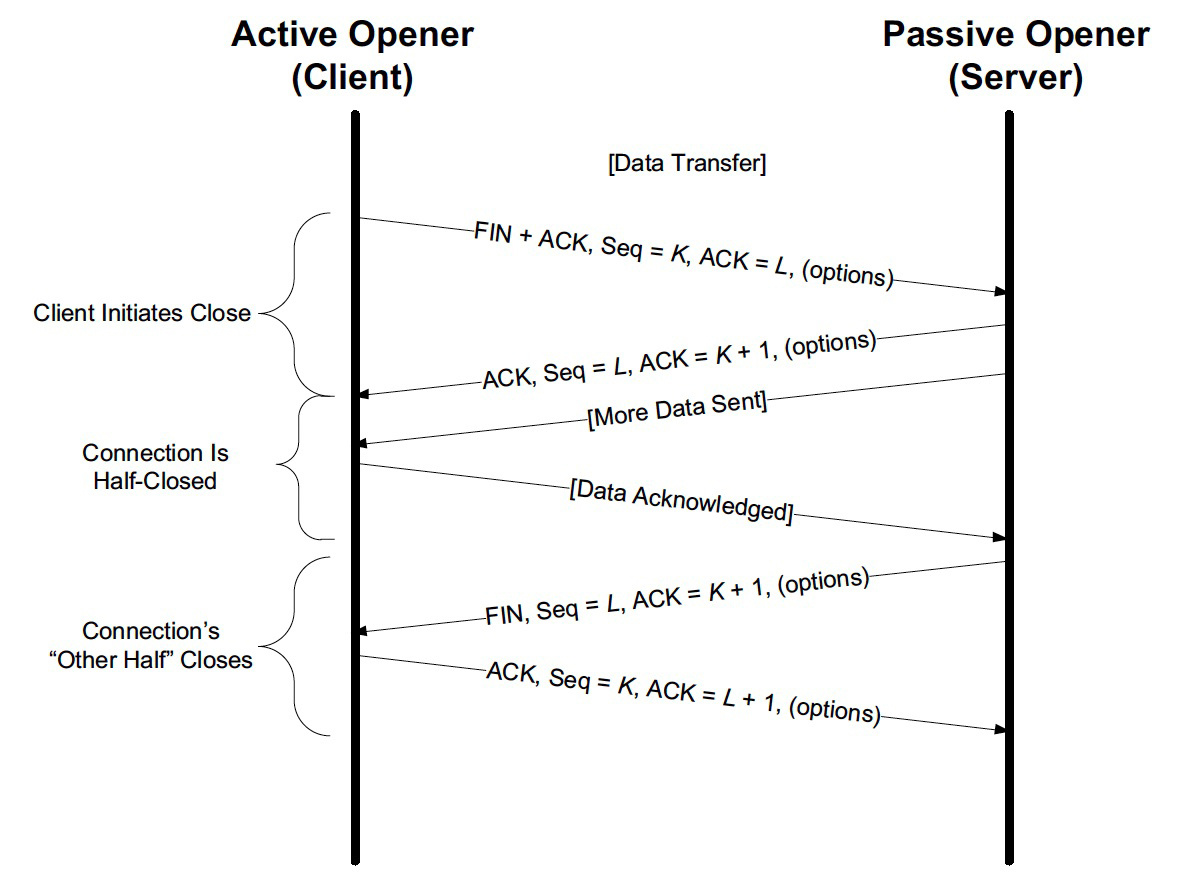
挥手一方发送 FIN 时,其实只有一方停止发送数据,另一方会继续发送数据
- 一端(A)发送 FIN,表示“我要关闭,不再发送新的数据了,但我可以接收新的数据”。
- 另一端(B)可以回复 ACK,表示“我知道你那头不会再发送了,我这头未必哦”.
- B 可以继续发送新的数据给 A,A 也会回复 ACK 表示确认收到新数据。
- 在发送完这些新数据后,B 才启动了自己的关闭过程,也就是发送 FIN 给 A,表示“我的事情终于忙好了,我也要关闭,不会再发送新数据了*。
- 这时候才是真正的两端都关闭了连接。
还是搬运了 Stevens 的图过来供你參考,也再次致敬 Stexens 大师!
防火墙
抓包后,可以带你左下角 或 Analyze => Analyze Information 来分析报文,如下图:
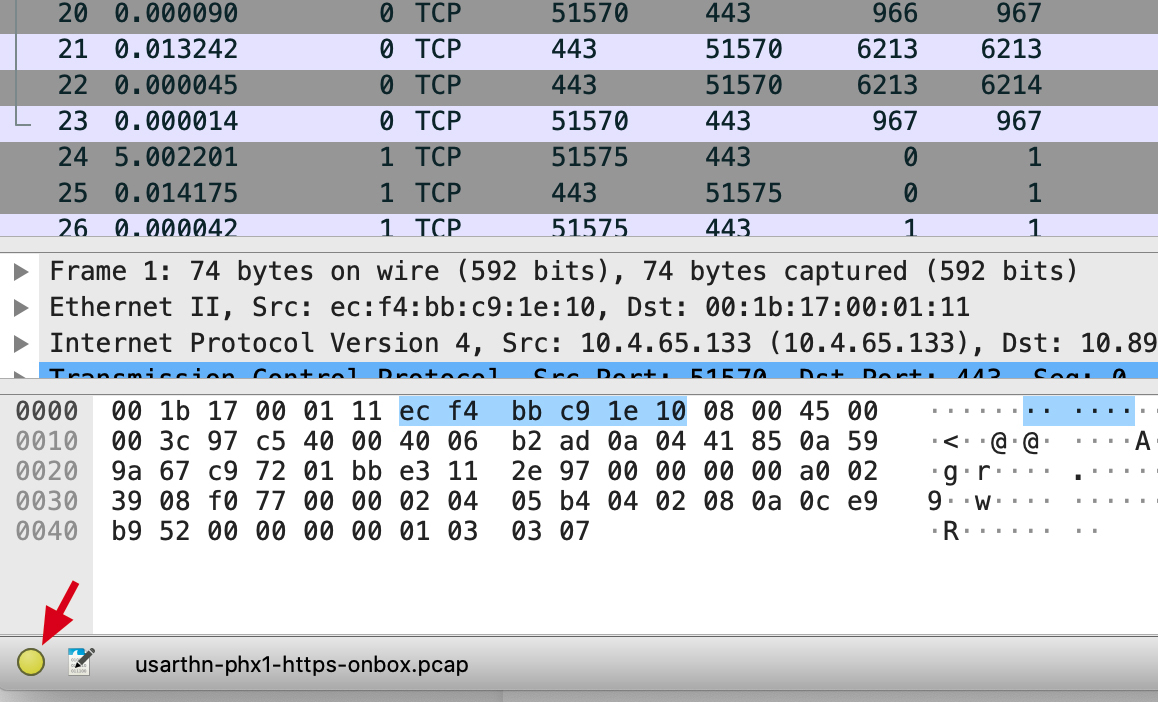
分析后的报文如下:
- 黄色:警告(可能有问题,值得关注)
- 浅蓝色:允许范围内的小问题(如TCP本身容许一定程度的重传)
- 蓝色:正常的TCP、UDP行为

关注重点报文
选中某行报文,邮件 Follow => TCP Stream 即可看到完整的 TCP 流,如下图:

然后,我们即可看到过滤后的,这个 TCP 流的全部报文了,如下图。其中左上角的 tcp.stream eq 8 是 Wireshark 自动生成的过滤条件:
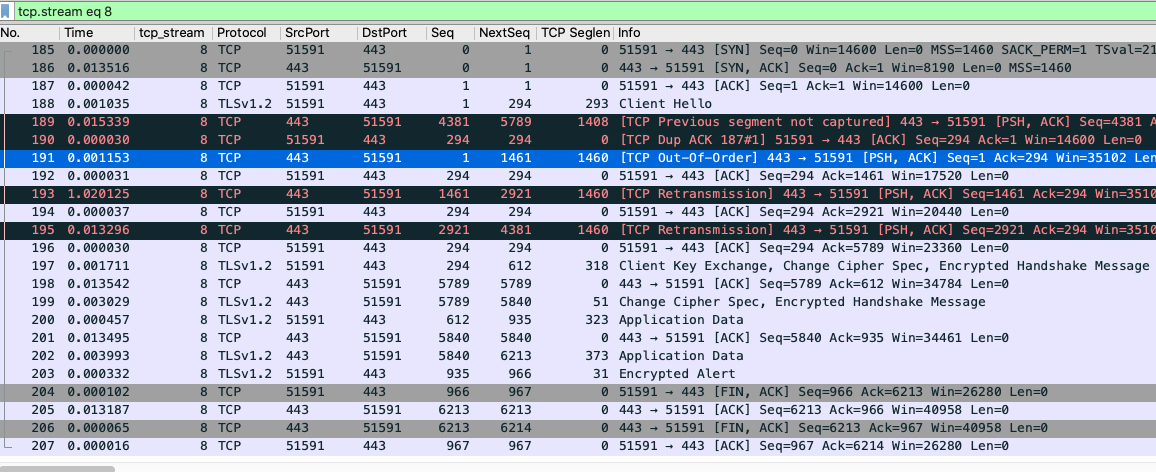
其中 Wireshark 自动帮我们标注的红色报文是需要我们重点关注的:
- 189:服务端(HTTPS)回复给客户端的报文,TCP previous segment not captured 意思是,它之前的报文没有在应该出现的位置上被抓到(并不排除这些报文在之后被抓到) 190:客户端回复给服务端的重复确认报文(DupAck),可能(Dup/Ack 报文数量多的话)会引起重传。
- 191:服务端(HTTPS)给客户端的报文,是 TCP Out-of-Order,即乱序报文。
- 193:服务端(HTTPS)给客户端的 TCP Retransmission,即重传报文。
- 195:也是服务端 (HTTPS)给客户端的重传报文。
以上都是根据 Wireshark 给我们提示的信息所做的一些解读,主要是针对 TCP行为方面的, 这也足从 Wireshark 中读取出来的重要信息之一。另外一个重要的信息源是耗时(也就是时间列展示的时间间隔)。显然,在192 和193 号报义之间,有1.020215 秒的时间间隔。
要知道,对于内网通信来说,时间是以毫秒计算的。一般内网的微服务的处理时间,等于网络往返时间 + 应用处理时间。比如,同机房环境内,往返时间(Round Trip Time)一般在 1ms 以内。比如一个应用本身的处理时间是10ms,内网往返时间是 1ms,那么整体耗时就是 11ms。
然而,这里单单一个 193 号报文就引发了1秒的耗时,确实出乎意料。因此我们可以基本判定:这个超长的耗时,很可能就是导致问题的直接原因。
对比两端报文
那为什么有这1s的耗时呢,可能就是因为 TCP 的超时重传(Retransmisstion Timeout)机制导致的,所以需要对比 client 端 和 server 端两端的报文。
可以用 TCP 的序列号,来定位到两端报文的位置。TCP 序列号是4 Byte,可以表示 math.pow(2, 32) 即 4GB的报文,很少有报文会超过 4GB 的,因此我们可用此精确定位此 TCP 流在两端抓包文件中的位置。
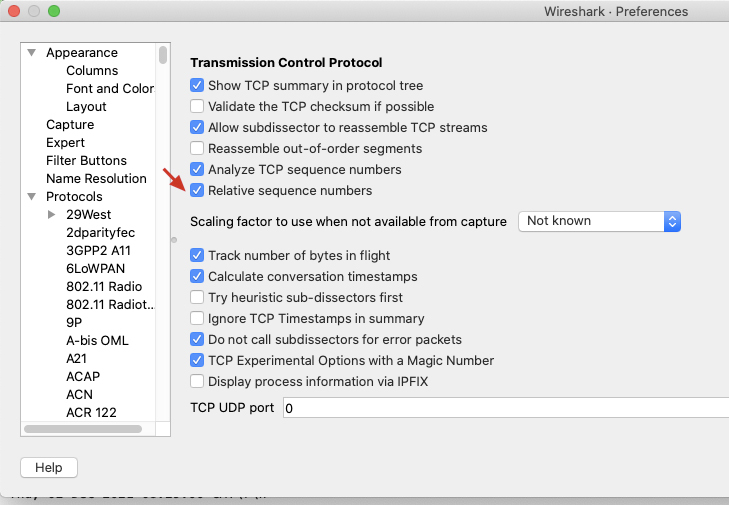
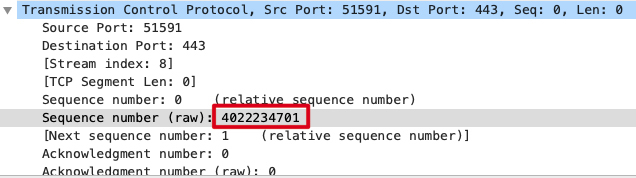
首先,记录 client 端抓包文件中那条 TCP 流的某个报文的 TCP 序列号,例如选择 SYN 包的序列号为 4022234701(注意要选择 raw 序列号,而不是 Wireshark 的握手之后的从1开始的相对序列号,需要按下图在设置中取消 Relative sequence numbers 的勾选):
得到 client 端的 raw 序列号如下:
然后,在 server 端通过 tcp.sq_raw eq 4022234701 找到同样的 SYN 包,如下:

然后,在 server 端,通过 Follow => TCP Stream 跟踪这个 SYN 包所属的整个 TCP 流,两端报文对比(左侧为 server,右侧为 client)如下,其中前四个报文顺序正常,但随后 server 一口气发送的4个包(这里称他们为1、2、3、4),到了 client 却变为了 (4、1、2、3)的顺序。也就是 Wireshark 提升我们的 Out Of Order(包1、2、3)和 TCP previous segment not captured(包4):
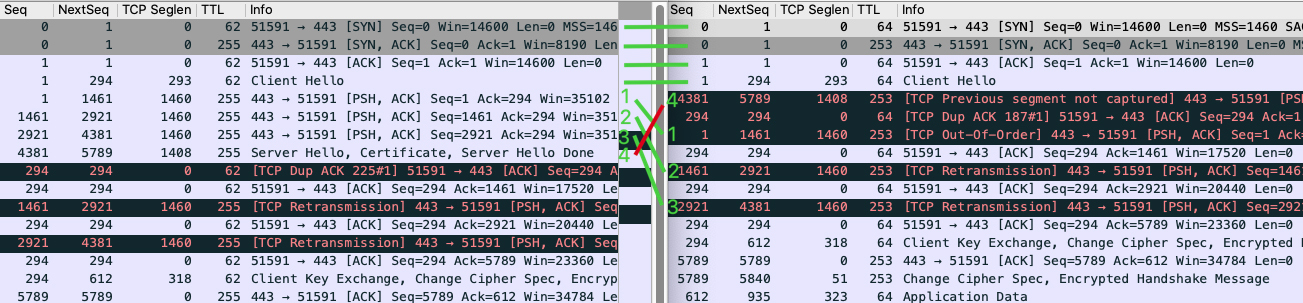
下面,我们再从 server 端的角度,看一下报文顺序、重传、1s 耗时,这3者的关系:

前面刚说到“服务端发送 4 个报文后,客户端收到的是 4、1、2、3”。因为后面3 个报文的顺序还是正确的,真正乱序的其实只是 4,所以就导致了这样一个状况:乱序是乱序的,但是 “不够乱”,也就是不能满足快速重传的条件“3 个重复确认”。
这样的话,服务端就不得不用另外一种方式做重传,即超时重传。当然,这里的1 秒超时是硬件 LB 的设置值,而 Linux 的默认设置是200毫秒。
不过,撇开这些细节不谈,我们现在知道了一个重要的事实:客户端和服务端之间,有报文乱序的情况。
我们查看了其他 T心P 流,也有很多类似的乱序报文,而这种程度的乱序发生在内网是不应该的,因为内网比公网要稳定很多。以我个人的经验,内网环境常见的丢包率在万分之一上下, 乱序的几率我没有严格考证过,因为跟各个环境的具体拓扑和配置的关系太大了。但从经验上看,乱序几率大概在百分之一以下到千分之一左右都属正常。
我们把这两个抓包文件以及分析过程和推论,发给了网络安全部门。他们对于实际的抓包信息也很重视,经过排查,发回了一个我仙“期待已久”但一直无法证实的推测:问题出现在防火墙上!
具体来说,是这样两个事实:
- 在客户端和服务端之间,各有一道防火墙,两者之间设立有隧道;
- 因为软件 Bug 的问题,这个隧道在大包的封包拆包的过程中,很容易发生乱序。
就像下图这样:

-
为什么隧道会引发乱序?
首先,隧道本身并不直接引起乱序。隧道是在原有的网络封装上再加上一层额外的封装,比如 PIP 隧道,就是在P 头部外面再包上一层P头部,于是形成了在原有P 层面里的又一个 IP 层,即“隧道”(各种隧道技术也是 SDN 技术的核心基础)。由于这个封装和拆封都会消耗
统资源,加上代码方面处理不好,那么出 Bug 的概率就大大增加了。这就是在这个案例里, 隧道会引发乱序的原因。 -
为什么 HTTP 事务没有被影响,只有 HTTPS 被影响?
在这个案例里,HTTP 确实一直没有被影响到。因为从抓包来看,这个场景的 HTTP 的 TCP 载荷,其实远没有达到一个 MSS 的大小。我们来看一下当时的 HTTP 抓包:
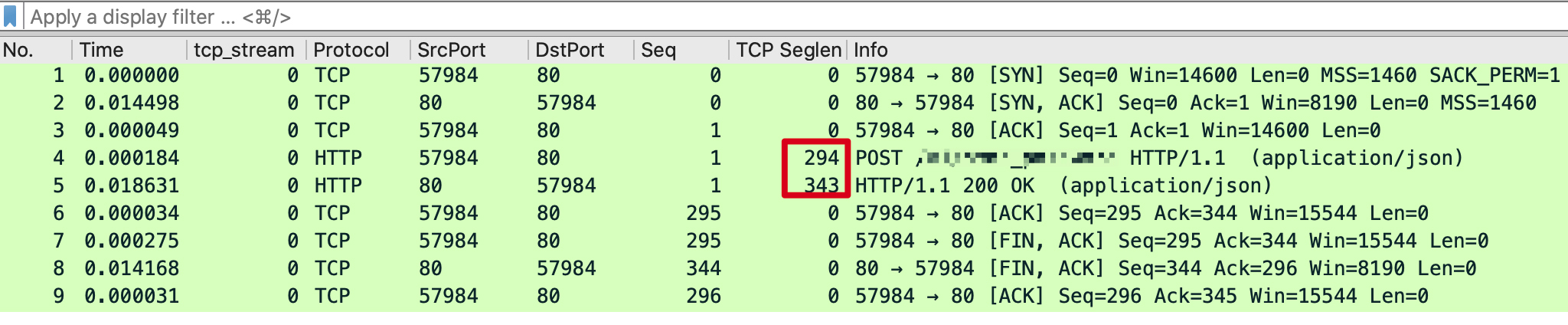
TCP 载荷只有两三百字节,远小于 MSS 的 1460 字节。这个跟隧道的关系是很大的,因为隧道会增加报文的大小。
比如通常 MTU 为1500 字节的IP 报义,做了IPIP 隧道封装后,就会达到1520 字节,所以一般有隧道的场景下,主机的MTU 都需要改小以适配隧道需求。如果网络没有启用 Jumbo Frame,那这个 1520 字节的报文,就会被路由器/防火墙拆分为2个报文。而到了接收端,又得把这两个报文合并起来。这一拆一合,出问题的概率就大大增加了。
补充:在 Linux 中,设置了 ipip 隧道后,这个隧道接口的MTU 会自动降低 20字节,也就是从默认 1500 降低到1480字节。
这个案例里是特殊的防火墙,它的 MTU 的逻辑跟 Linux 有所不同。
事实上,在大包情况下,这个隧道号发的是两种不同的开销:
- IPIP 本身的隧道头的封包和拆包;
- IP 层因为超过 MTU 而引发的报文分片和合片。
因为 HTTPS 是基于 TLS 加密的,TLS握手阶段的多个 TCP 段(segment)就都撑满了 MSS(也就是前面分析的1、2、3 的数据包),于是就触发了防火墙隧道的 Bug.
到这里,你可能又会问了:这个例子中的丢包和乱序问题,其实也不限于防火墙,在路由器交换机层面也是有可能发生的,有没有办法可以更加确定地定位到防火墙,而不是其他网络设备呢?
- 小结
这次的“两侧抓包”,实际上就起到了决定性的作用。那么除了当前这个案例,总的来说,还有哪些情况下适合做“两侧抓包”呢?我个人的看法是这样的:
- 有条件的话(比如对两侧设备都有权限),就尽量做两侧抓包。这样可以收集到更多的信息。有更全面的信息,也就更容易作出更准确的判断。这好比我们做数学或者物理题,条件越充足,解题也相对越顺利。即使信息有所富余,也不会干扰到排查工作的正确性。当然这会损失一些效率,就看你怎么权衡了。
- 有丢包或者重传的情况的话,更应该做两侧抓包。因为只有通过比较两侧报文,才能确定具体的丢包位置等信息,而这些信意对于排查工作十分关键。我们经常会出现的情况是,完全不同的两种故障原因,在一侧(比如客户端)看起来很可能是相同的现象。这就好比,一个一半黑一半白的球体,当其中的一面正对着我们的时候,我们是完全不知道另外一面可能是完全不同的颜色。对于网络排查也是如此。
- 有些信息在单侧抓包里就能明确下来的,一般就没必要做两侧抓包了。
另外,一般用使序列号,在两个不同的抓包文件中如何定位到同个报文。
在一侧的文件中找到某个报文的裸序列号,作为搜索条件,在另外一侧的报文中搜索得到同样这个报文。这正是利用了 TCP 裸序列号在网络中传输的一致性(不变性)。后面的课程中, 我还将介绍更多这种“寻找同样报文”的方法,基本思想也都是基于某些信息在网络传输的一致性。
Web 站点访问被 reset
首先,过滤被访问的网站 IP,如下:
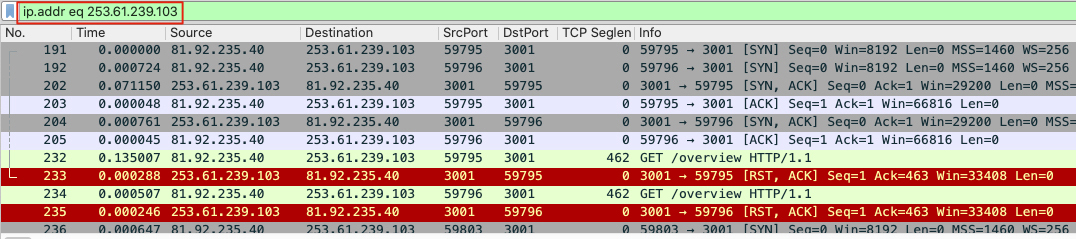
通过 ip. addr eq 253.61.239.103 and tcp. flags.reset eq 选出有问题的数据包,过滤出整个 TCP 流,并 Follow => TCP Stream 如下:
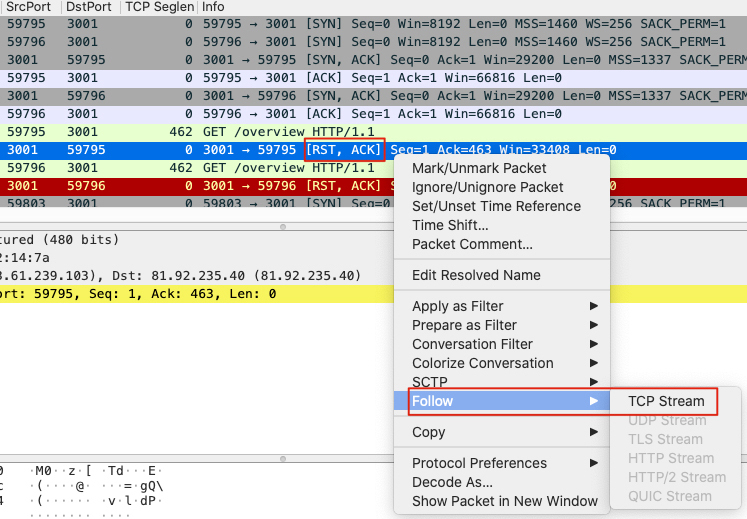
然后,Wireshark 会弹窗显示解读好的应用层信息,如下:
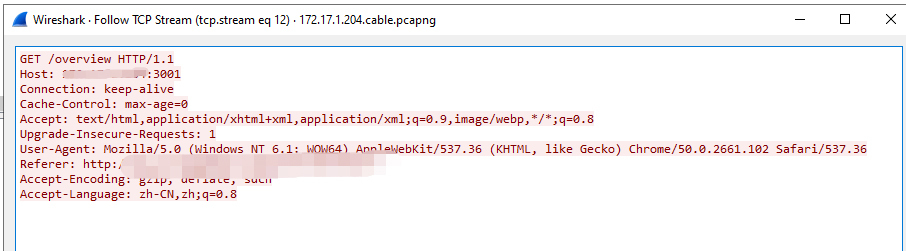
关闭弹窗,即可显示 TCP 流,如下:

可见,TCP 3次 握手后,client 发起了 GET /overview HTTP/1.1 的 HTTP 请求,但 server 端回复了 TCP RST,从而导致访问失败,如下图:
其实我们可以借助 TTL 知识来排查:
TTL是P包(网络层)的一个属性,字面上就差不多是生命长度的意思,每一个三层设备都会把路过的IP 包的TTL 值减去1。而IP 包的归宿,无非以下几种:
- 网络包最终达到目的地;
- 进入路由黑洞并被丢弃;
- 因为网络设备问题被中途丢弃;
- 持续被路由转发并 TTL 减1,直到TTL 为口而被丢弃。
在 RFC791 中规定了 TTL 值为 8位,所以取值范围是 0~255。

因为 TTL 是从出发后就开始递减的,那么必然,网络上我们能抓到的包,它的当前TTL一定比出发时的值要小。而且,我们可能也早就知道,TTL 从初始值到当前值的差值,就是经过的三层设备的数量。
不同的操作系统其初始TTL 值不同,一般来说 Windows 是128, Linux 是 64。由此,我们就可以做一些快速的判断了。比如我自己测试 ping www.baidu.com,收到的L是 52,意味着这个回包在公网经过了 64 - 52 = 12 跳第三层路由设备,如下图:
root@node:~# ping www.baidu.com
PING www.a.shifen.com (110.242.68.3) 56(84) bytes of data.
64 bytes from 110.242.68.3: icmp_seq=1 ttl=52 time=10.7 ms
64 bytes from 110.242.68.3: icmp_seq=2 ttl=52 time=9.57 ms
64 bytes from 110.242.68.3: icmp_seq=3 ttl=52 time=9.63 ms
64 bytes from 110.242.68.3: icmp_seq=4 ttl=52 time=9.19 ms
^C
--- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 9.198/9.787/10.740/0.575 ms
因为内网路由设备很稳定,所以内网同一个连接中的 TTL 一般是稳定的,若波动则不正常。我们按此思路,继续看之前过滤出的 5 个数据包如下:
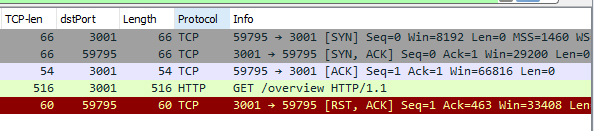
因为列表默认不显示 TTL,所以我们可在详情看到,并右键添加到列表里,如下图:


你也能很清楚地看到,同样的服务端,在三次握手中(SYN+ACK 报文)的 TTL 是59,在导致连接中断的 RST 包里却变成了 64!显然,这个 RST 包井不是跟我们握手的那个服务端发出的,否则 TTL 值就不会变化。
发出这个包的会是谁呢?其实,一般就是防火墙设备。由于防火週也遵循 IP 协议,而这里的 TTL 值是 64,这就说明这个防火墙跟客户端之间没有别的三层环节,或者说是三层直连的。
我们可以用一张简单的图来概括这个案子:

这样,我们底气大增!根据我们提供的信息,负责防火墙的同事就去复查了下,果然有发现:
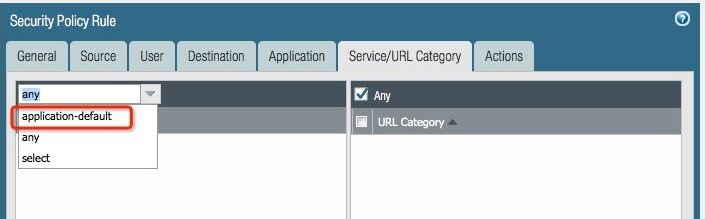
防火墙上对二楼有线网络有一条可疑的策略,跟其他线路不同。这条策略的出发点是:每个网络协议规定了协议数据格式以及标准端口号,所以协议数据跟端口号不匹配的话,就可以认为是“有害”流量。因为 HTTP 协议标准端口是 TCP 80,但是我们这个 Web 站点是3001端口的,被防火墙认为不一致,所以就拒掉了。
我们来看一下当时的防火墙的配置如下图,这里的 application-default 就是说,端口需要跟协议匹配。要不然就会被禁止,也就是回复 RST 给客户端,终止这条连接。这个防火墙策路被修正后,问题也立刻被解決了。
访问 LDAPS 服务报 connection reset by peer
client 的抓包如下,其中有一个 RST:

server 的抓包如下,其中也有一个 RST:

但奇怪的是,client 发送的 Hello Client,却并未在 server 端发现,这是为什么呢?我们猜测如下图:
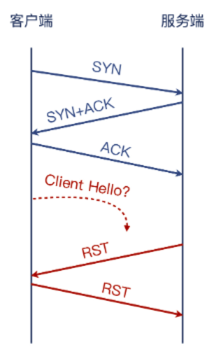
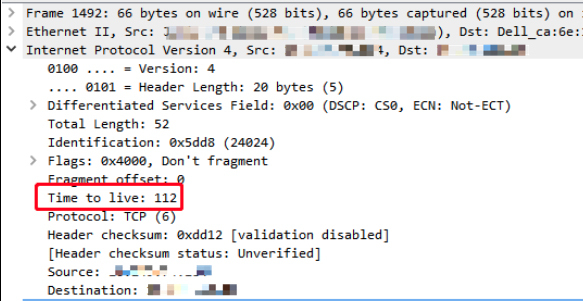
- 进一步,我们排查 server 端的 TTL,从 server 视角来看,它收到的报文只有三个:SYN 包、ACK 包、最后的 RST 包。我们选择 SYN 和 RST,来对比看下它们的TTL是多少。下图是SYN包:
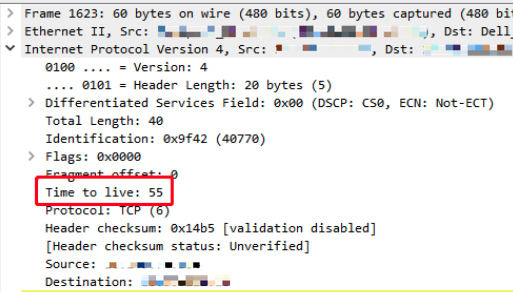
下图是 RST 包:
显然,跟之前的案例类似,这里的下TL 也发生了明显的变化。你应该也明白了,这两个包并不是同一个设备发出的。
- 同样,client 端收到的 SyNACK 包的 TTL是 110:
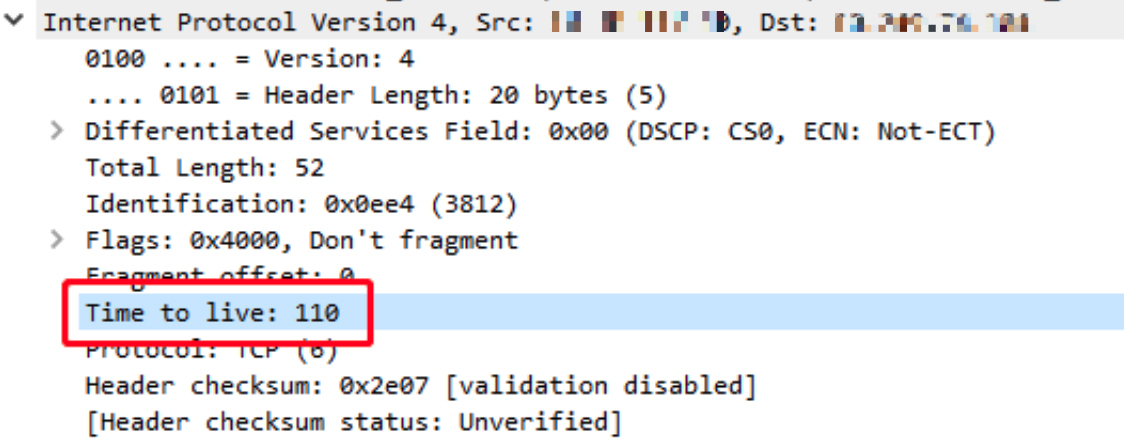
client 端收到的 RST 包的TTL是 54:
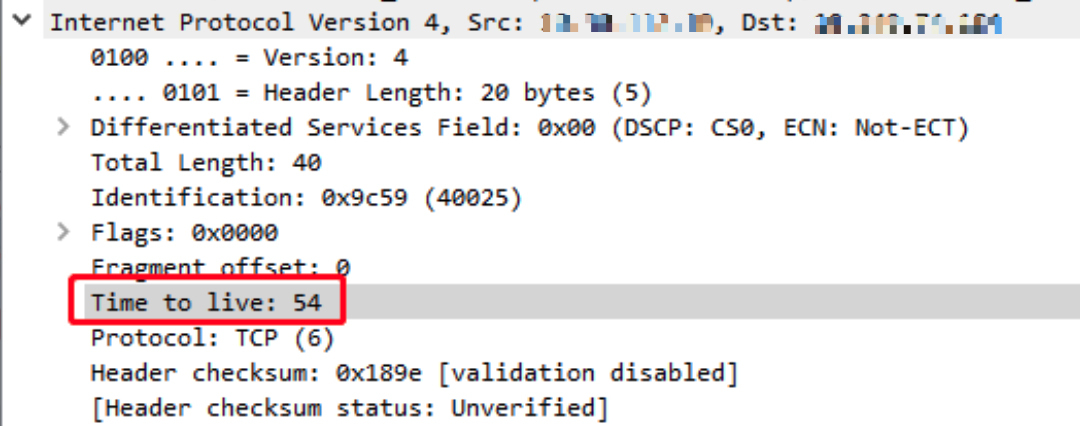
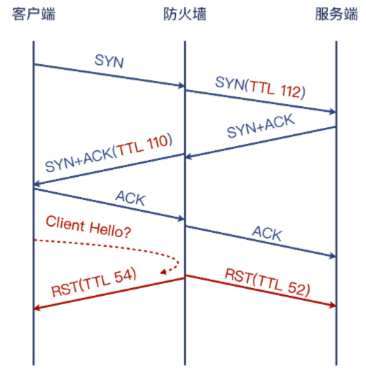
- 终于,结合两侧的抓包,我们就可以把这个拼图给拼完整了,而 Client Hello 报文丢失之谜, 也将揭晓。更新一下前面的示意图,会变成下面这样。显然,Client Hello 报文就是被防火墙丢弃了。可见,防火墙的拦截行为可能出现在多个方向上(面对客户端时代表服务端,面对服务端时代表客户端),毕竟报文都要经过它,它如果想乱来,通信两端还真的无法控制它。从上图来看,防火墙两边“截胡”,两边拒绝。两边还都只好乖乖地听话,结束了连接。你都不能说它 “没有武德”,因为整个过程都是完全遵照了 TCP 规范的,防火墙做得不可谓不周到。
- 如何应对防火墙发的 RST 报文,对我们的毒害呢?
我们可以对这条 iptables 规则设定精确的限定条件,使得它既能帮助我们丢弃“有害” 的 RST 报文,同时也不影响到其他正常连接的交互。
在报文进采的方向,报文会经过这样的处理流程:PREROUTING -> INPUT -> 本地处理 -> OUTPUT -> POSTROUTING
防火墙配置动手实践
现在“理都懂"了,让我们来动手实操一下。我们需要搭建这公一个测试环境:
虚拟机1(下面简称为1):配置为 client,实验时会在这台上执行 telnet,模拟访问行为。
虚拟机2(下面简称为2):配置为 client 的网关,这样它就可以劫持流量,模拟防火墙行为。
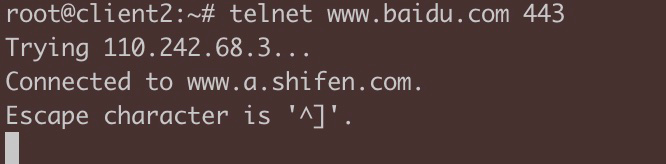
实验1:telnet 第三方站点
在1上,直接 telnet www.baidu.com 443, 可以成功。
然后我们需要配置一下,让1访问 www.baidu.com 的流量强制经过2,这样后续我们就可以让2来操控1 和 baidu 之间的连接了。接下来步骤稍多,感谢你的耐心。
在虚拟机1上,我们需要完成这么几件事:
# 创建隧道,隧道另一头就是虚拟机2,我们将在那里模拟一个“防火墙”。在上节课里,我们了解了 ipip 隧道,这里的 GRE 隧道也是类似的工作原理。
ip tun add tun0 mode gre remote 172.17.158.46 local 172.17.158.48 ttl 64
ip Link set tun0 up
ip addr add 100.64.0.1 peer 16016410.2 dev tun0# 添加路由项,使得本地去往第三方站点的流量,都走这条路由,也就是通过隧到达虚拟机 2,然后2来转发报文。
ip route add 110.242.68.0/24 via 100.64.0.2 dev tun0# 当然了,虚拟机2上面也需要做对等的隧道配置
ip tun add tun0 mode gre remote 172.17.158.48 Local 172.17.158.46 ttl 64
ip Link set tun0 up
ip addr add 100.64.0.2 peer 100.64.0.1 dev tun0# 虚拟机1把报文发到虚拟机2,但是如果后者不做配置,默认是会丢弃这些报文的,所以还需要在2上开启 ip_forward
sysctl het.ipv4.ip_forward=1# 我们在2上运行 tcpdump port 443,然后 1 上运行 telnet owww.baidu.com 443。在2的 topdump 窗口里,已经可以看到从1 过来的流量了!
rooteserver$tcpdump port 443
tcpdump:verbose output suppressed, use -V or -vv for full protocol decode
Listening on eth0, Link-type EN1OMB (Ethernet), capture size 262144 bytes
16:53:36.054124 IP 100.64.0.1.34396 > 110.242.68.3.https: Flags [S], seq 33644156, options [mss 1436, sackOK, TS val 2049305210 ecr O,nop, wscale 7], Length 0
16:53:37-084514 IP 100.64.0.1.34396 > 110.242.68.3.https: Flags [S], seq 33644156, options [mss 1436, sackOK,TS val 2049306241 ecr O,nop,wscale 7], Length 0
16:53:39.100482 IP 100.64.0.1.34396 > 110.242.68.3.https: Flags [S], seq 33644156, options [mss 1436, sackOK, TS val 2049308257 ecr O, nop,wscale 7], length 0
咦?抓包里只有 SYN 包而没有 SYN+ACK,1这头的 telnet 也挂起,没响应了,这是怎么回事?

原来,我们还需要设置一下 NAT,要不然出去的报文源 IP 是 100.64.0.1,回包也会回这个地址,显然回不到2了。
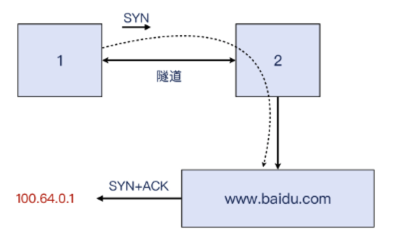
所以还需要在2 上启用 SNAT:
iptables -t nat -A POSTROUTING -d 110.242.68.0/24 -j MASQUERADE
我们再试试在1上发起 telnet www.baidu.com 443,果然成功了。
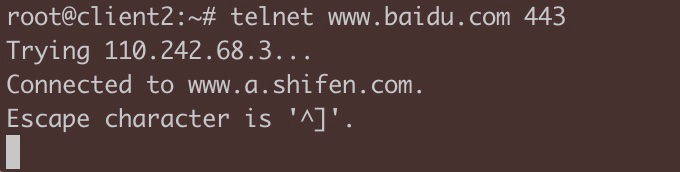
2 上的 tcpdump 也抓取到了正常连接的报文(这里就不贴了)。
实验2:插入 RST 报文,连接失败
现在,我们需要在2 上配置一个“插入 RST 报文”的动作,这样就可以模拟“防火墙阻隔 TCP 连接”的效果了。
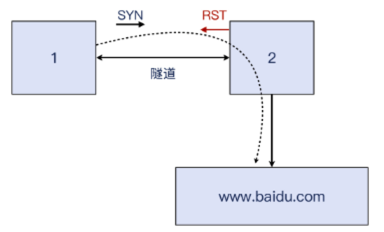
我们可以在2 上运行这条 iptables 命令:
iptables -I FORWARD -P tcp -m tcp --tcp-flags SYN SYN -j REJECT --reiect-with tcp-reset
有了这条命令,2 就用 TCP RST 拒绝了转发链(也就是命令中的 FORWARD 链)上的SYN 报文。1上的 telnet 立刻收到了拒绝:

2 上的 tcpdump 抓包窗口里也看到了握手和拒绝的报文:
rooteserver$tcpdump -i any port 443
tcpdump: verbose output suppressed, use -V or -vv for. full protocol decode
Listening on any, Link-type LINUX SLL (Linux cooked vi),capture size 262144 bytes
17:02:16.623480 IP 100.64.0.1.34428 > 110.242.68.3.https: Flags [S], seq 33145736, options [mss 1436, sackOK, TS val 2049825780 ecr O, nop, wscale 7], Length 0
17:02:16.623518 IP 110.242.68.3.https > 100.64.0.1.34428: Flags [R.], seq o, ack 3314573699, win 0, Length o
可见,这个 RST 实实在在地起到了类仪防火墙的作用,让你的连接无法建立。你看,其实防火墙也没那么神秘,我们也可以实现。可以小小地鼓励一下你自己!
实验3:丢弃 RST 报文,连接成功
这套实验的核心目标是实现对 RST 干扰报文的规避,也就是丢弃这类报文。让我们继续实验,在1上添加这么一条 iptables 规则:
iptables -I INPUT -S 110.242.68.0/24 -p tcp =-sport 443 -m tcp --tcp-flags RST RST -m ttl --ttl-eq 64 -j DROP
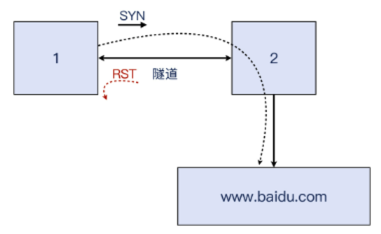
有了这条规则,我们就对符合条件的 TCP 报义进行了丢弃,这个条件就是“来自 110.242.68.0/24 网段的 TCP 源端口为443 的,带 RST 标志位的,TTL 等于 64的报文”。
这里的 TTL 条件就是关键了。在实际场景下,你就可以根据防火墙插入的RST 报文的TTL 的实际特征,写一条精确匹配的规则,把它跟正常报文区分开,进行精准的丢奔。
我们还是在1 上 telnet,然后发现这次不再被 reset,而是挂起了。在1的 topdump 中,也看到 SYN 发出了,对方也回复了 RST,但是我们并没有被真的被 reset。这里,正是这条丢奔 RST 报文的 iptables 规则起到了效果。
rooteclient2:~# tcpdump -i any host 110.242.68.4 and port 443
tcpdump: verbose output suppressed, use -v Or -VV for full protocol decode
Listening on any, Link-type LINUX SLL (Linux cooked v1), capture Size 262144 bytes
17:27:50.748194 IP client2.53438> 110.242.68.4.https: Flags [s], seq 1164905016, options [mss 1436, sackOK,TS Val 2201853747 ecr O, nop,wscale 7], Length O
17:27:50.748433 IP 110.242.68.4.https > client2.53438: Flags [R. ], seq o, ack 1164905017, win 0 Length 0
在实际场景中,只要设置前面提到的 iptables 丢弃特定 RST 报文的规则,就还有很大的几率能让这条连接继续保持下去,应用也运行下去。防火墙居然对你无效了,你除了长舒一口气, 会不会心里也冒出“终于翻身当主人”的感觉?
那么,除了这种丢弃有害 RST 的办法,还有没有别的办法呢?
就上面探讨的丢弃 RST 的方法来说,这是一个“应对式”的策略,也就是有人要“害我”,那我把“毒药”给扔了。但仍然是“被动”的方法。如果思考得更进一步,我们有没有办法,使得别人都没有机会来害我呢?就是你连“下毒”的机会也没有?这就是“主动”的策略了。
我个人看法是,可以到网络层(P层)去寻找机会。利用 IPSec(比如 IPv6 默认启用了 IPsec),我们就获得了在第三层加密的能力。因为就连P 报文本身都是加密的,那么即使防火墙要插入报文,因为它不具备密钥,所以这个报文会被接收端认为非法而被丢弃。这样就有希望真正摆脱防火墙对传输层(TCP/UDP)的这种控制。
- 小结
通过两端抓包后进行网络包的对比分析,排查定位到防火墙的存在,这种方法对于丢包、乱序等场景特别有用。
通过分析 TTL 值的变化,快速定位到防火墙的存在。这种方法,对于连接被重置(RST)的场景,十分有效。
我们需要记住以下几个关键要点:
-
需要在受影响的客户端或者服务端进行抓包.这样你才能获取到你需要的关键信息,而这种信息,单纯通过应用层日志等途径,是很难获取的,这也是应用层排查的天然的不定。对此,你需要有清醒的认识,井深刻理解网络层排查技术的重要性和不可替代性。 分析抓包文件,识别下TL的变化。这里,你需要了解网络层和IP 协议的相关知识点。同时也要明白,即使一个知识点看似简单,其背后的设计原理,都大有文章。对每个技术细节的推敲,能帮助我们打造出更为强大的技术底蕴。
-
灵活运用 Wire Shark 自定义列。我们通过添加自定义列,让每个报文的TTL 值都在主视图中展现,极大地方便了对这些 TTL 的比较。所以我们除了掌握协议知识以外,也要挖掘各类工具的使用技巧。所谓“工欲善其事,必先利其器”也。
-
另外,在这节课的最后,我们也通过一系列实验,再一次深入理解了 RST 报文的作用,以及可能的规避方法。在这个过程中,我们学习了:
3.1 GRE 隧道的搭建和用途:你可以用 ip tunnel add 命令创建 GRE 隧道,并用 ip route add 命令配置路由项,让某些网络的流量转而走这个隧道网关。注意,即使是一个二层不可达的 PP,通过隧道也可以“包装成”二层可达,进而可以配置为网关。这一点,如果不借助隧道, 是无法实现的。
3.2 用 iptables 实现对报文的操控:在你需要模拟一些问题场景的时候,不妨多发掘一下 iptables 的“潜能”,比如可以丢弃符合某种条件的报文:iptables -I INPUT -S 110.242.68.0/24 -p tcp --sport 443 -m tep --tcp-flags RST RST - ttl --ttl-eq 64 一j DROP
3.3 我们也学习了如何用 iptables 结合内核配置,实现一个简单的 NAT 网关:
iptables -t nat -A POSTROUTING -d 110.242.68.0/24 -j MASQUERADE
sysctl het.ipv4. ip_forward=1
-
MAC地址中的组织唯一标识符 (OUI)由,IEEE(电气和电子工程师协会)分配给厂商,那么通过MAC地址可以辨别出厂商,防火墙的主要厂商也不多,从这块信息大约能判断出回包的是不是防火墙,因为是通过二层信息判断,所以这个方法是有局限性的。
-
traceroute 是可以看到路径上所有的三层设备的,这里强调“三层”,是因为只有工作在IP层的路由性质的设备(包括三层交换机)才会回复ICMP消息。如果是纯二层设备,不会回复ICMP消息,也就在traceroute输出里看不到它。
防火墙也经常出现在traceroute输出里,不过一般它的ip也不特殊,名称上(如果有反向解析记录的话)也未必说自己是防火墙。当然,事实上很多时候防火墙是没有反向解析记录的,也就是traceroute不加-n,那么别的节点可能显示为名称,但防火墙只是显示为ip,虽然准确率不太高,不过倒是可以用来参考。
用TTL来判断是非常准的,几乎不会“失手”。但是题目不能用TTL了,那么IP层还有什么可以借用的吗?比如IP ID,因为ID号是通信两端自己各自生成的连续号码,防火墙插入报文的话,一般来说IP ID就不同了。你如果也有被防火墙干扰的抓包文件,可以观察IP ID在RST报文里跟其他正常报文是否不同。
保活机制
TCP 长连接为何总中断?
这个应用的架构比较简单:客户在云平台上部署了多台云主机,其中一台云主机专门做加解密,称之为加密服务器。另外几台云主机作为这台加密服务器的客户端,跟这台加密服务器保持TCP长连接。这些客户端会不时地跟加密服务器进行通信,完成加密操作。每45秒,客户端还会发送一次心跳包,这有两个作用:
维持这个长连接不被中断,即心跳保活,让长连接在两端保持下去;
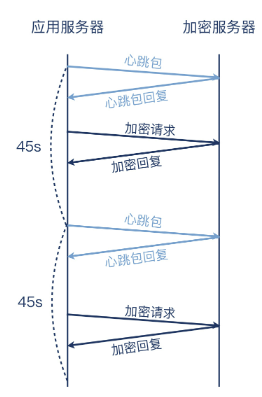
如果加密服务器能在1秒内对心跳包进行回复,那么客户端就认为服务端正常可用,后续的数据交互(即加密请求)将继续在这条长连接上进行。而如果服务端未能在1秒内回复,那么客户端会认为该长连接已经中断,于是重启应用,发起一条新的长连接,并在日志中记录一次报错。
用类Python语法来描述,大体是这样的:
while true:sleep(45)if Keep_alive_probe() is true:continueelse :restart()log_error()
首先,对于TCP Keep-alive,你需要掌握:
- 默认TCP 连接并不启用Keep-alive,若要打开的话要显式地调用setsockopt(),来设置保活包的发送间隔、等待时间、重试个数等配置。在全局层面,Linux还默认有3个跟Keep-alive相关的内核配置项可以调整: tcp_Keepalive_time,tcp_Keepalive_probes,还有tcp_Keepalive_intvl。
- TCP心跳包的特点是,它的序列号是上一个包的序列号-1,而心跳回复包的确认号是这个序列号-1+1 (即还是这个序列号)。
然后,对于HTTP Keep-alive 的知识点,你需要理解:
- HTTP/1.0默认是短连接,HTTP/1.1和2默认是长连接。
- Connection: Keep-alive在HTTP/1.0里,能起到维持长连接的作用,而在 HTTP/1.1里面没有这个作用(因为默认就是长连接)。
- Connection: Close在HTTP/1.1里,可以起到优雅关闭连接的作用。这个头部在流量调度场景下也很有用,能明显加快基于DNS/GSLB的流量调整的收敛速度。
MTU 最大分段大小
在 Wireshark 先将过滤后的报文保存成新的抓包文件,再在 Wireshark 中选择 Statistic =》 Flow Graph 可以生成二维数据流图,如下:
为什么有 DupAck
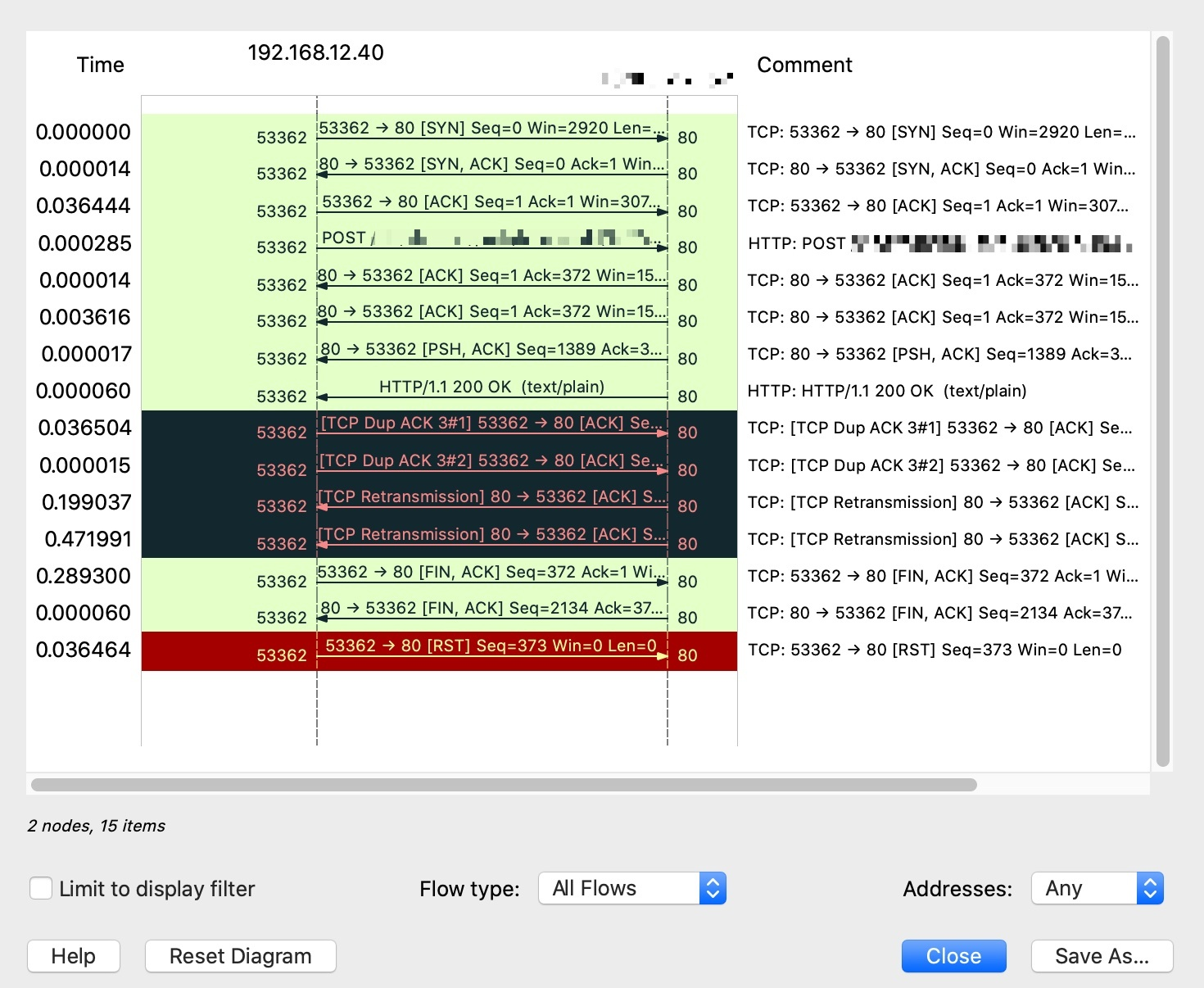
DupAck 是重复确认,它的出现一般意味着传输中出现丢包、乱序等情况。
下文中,因为两个 DupAck 的 ACK 均为1,所以是握手阶段完成时的确认号。Å即 client 握手成功后并未收到 server 发来的报文,所以其 ACK 停留在 1。如下图:

完整的流程图如下:
为什么重传失败
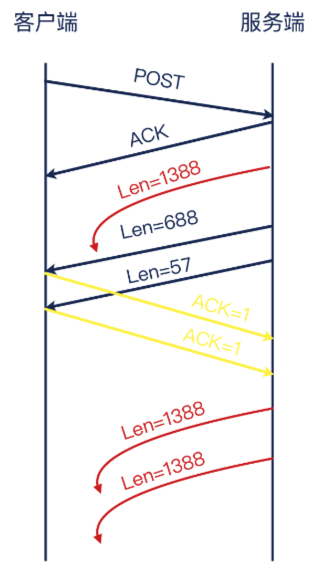
第一个报文就算暂时丢失,后续也有两次重传,为什么这些重传都没成功呢?既然我们同时有成功情况和不成功情况下的抓包文件,那我们直接比较,也许就能找到原因了。
让我们招两个文件中的类似的 TCP 流对比一下:

你能发现其中的不同吗?这应该还是比较容易发现的,它就是:HTTP 响应报文的大小。两次测试中,虽然HTTP 响应报文都分成了3个 TCP 报文,但最大报文大小不同:左边是1348,右边是1388,相差有 40字节。既然已经提到了报文大小,那你应该会联想到我们这节课的主题,MTU 了吧?
MTU,中文叫最大传输单元,也就是第三层的报文大小的上限。我们知道,网络路径中,小的报文相对容易传输,而大的报文遇到路径中某个 MTU 限制的可能会更大。那么在这里,假如这个问题真的是 MTU 限制导致的,显然,1388会比1348 更容易遇到这个阿题!
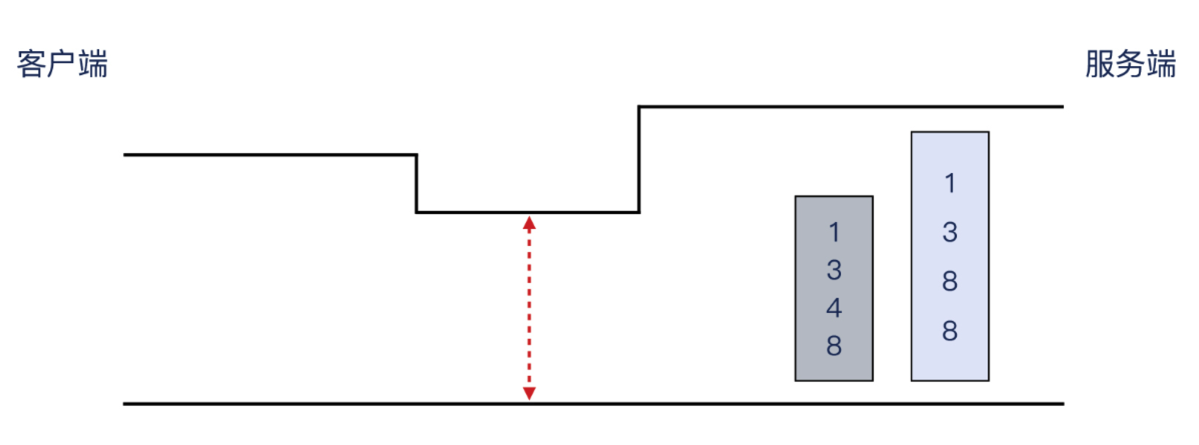
就像上面示意图展示的那样,如果路径中有一个偏小的 MTU 环节,那么完全有可能导致 1388 字节的报文无法通过,而 1348 字节的报文就可以通过。
而且,因为 MTU 是一个静态设置,在同样的路径上,一旦某个尺寸的报文一次没通过,后续的这个尺寸的报文全都不能通过。这样的话,后续重传的两次1388 字节的报文也都失败这个事实,也就可以解释了。
既然问题跟 MTU 有关,我们就检查了客户端到服务端之间的一整条链路,发现了一个之前没
注意到的情况:除了广州到北京之间有一条隧道,在北京 LB 到服务端之间,还有一条额外的隧道。我们在第5讲里学习过,隧道会增加报文的大小。而正是这条额外隧道,造成了报文被封装后,超过了路径最小 MTU 的大小!从下面的示意图中,我们能看到两次路径上的区别所在:

经过 LB 的时候,报文需要做2次封装(Tunnel 1 和 Tunnel2),市绕过 LB 就只要做 1次封装(只有 Tunnel 1)。跟生活中的例子一样,同样体型的两个人,穿两件衣服的那个看起来比穿单衣的那个要显胖一点,也是理所当然。要显瘦,穿薄点。或者实在要穿两件,那只好自己锻炼瘦身(改小自己的 MTU)了!
另外,由于 Tunnel 1 比 Tunnel 2 的封装更大一些,所以服务端选择了不同的传输尺寸,一个是1388,一个是1348。
为什么重传只有两次?
这个解释就是客户端超时,这一点其实我在前面介绍案例的时候就提到过。从TCP 流来看, 从发送 POST 请求开始到 FIN 结束,一共耗时正好在1 秒左右。我们可以把 Time 列从显示时间差(delta time)改为显示绝对时间 (absolute time),得到下图:
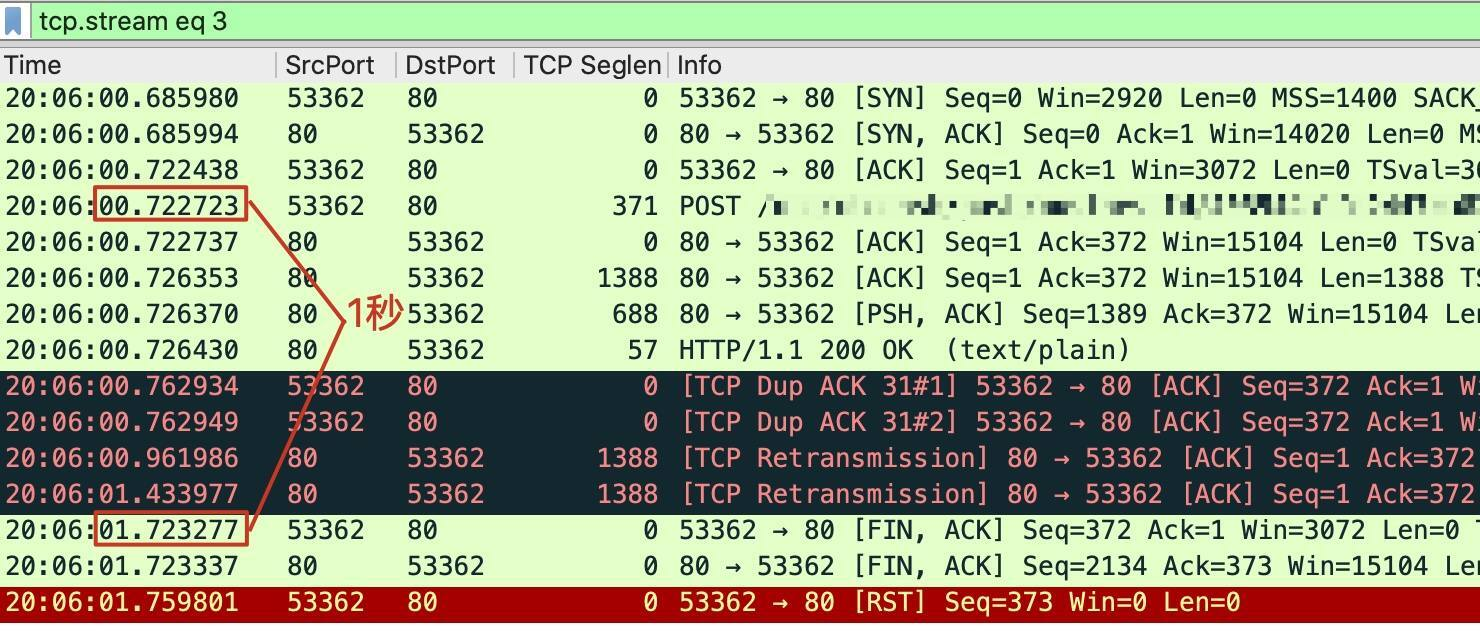
可见,客户端在 0.72 秒发出了 POST 请求,在1.72 秒发出了 TCP 挥手(第一个 FIN),相差正好 1秒,更多的重传还来不及发生,连接就结束了
这种“整数值”,一般是跟某种特定的(有意的)配置有关,而不是偶然。那么显然,这个案例里,客户端压测程序配置了1秒超时,目的也容易理解:这样可以保证即使一些请求没有得到回复,客户端还是可以快速释放资源,开启下一个测试请求。
MTU 解决方案
调小两端 MTU
其实,我估计你在日常工作中也可能遇到过这种 MTU 引发的问题。那一般来说,我们的对策是把两端的 MTU 往下调整,使得报文发出的时候的尺寸就小于路径最小 MTU,这样就可以规避掉这类问题了。
举个例子,在我的测试机上,执行 ip addr 命令,就可以查看到各个接口的 MTU,比如下面的输出里,eno1 口的当前 MTU 是1500:
2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 0c:c4:7a:80:a8:b8 brd ff:ff:ff:ff:ff:ffinet 192.168.2.99/24 brd 192.168.2.255 scope global eno1valid_lft forever preferred_lft foreverinet6 fe80::ec4:7aff:fe80:a8b8/64 scope linkvalid_lft forever preferred_lft forever
而假如,路径上有一个比 1500 更小的 MTU 设备,那为了适配这个状况,我们就需要调小自己的 MTU,这么做很简单,比如执行以下命令,就可以把 MTU 调整为 1400 字节:
sudo ip Link set eno1 mtu 1400
在 iptables 的 nat 表和 FORWARD 处添加规则:改报文的 MSS 值
那除了这个方法,是不是就没有别的方法了呢?其实,我喜欢网络的一个重要原因是,它有很强的“可玩性”。只要我们有可能拆解网络报文,然后遵照协议规范做事情,那还是有不少灵活的操作空间的。你可能会好奇:这听起来有点像“灰色地带”一样,难道网络还能玩“潜规则” 吗?
比如这次的案例,网络环节都是软件路由和软件网关,所以“暗箱操作”也成了可能,我们不需要修改两端 MTU 就能解决这个问题。是不是有点神奇?不过,你理解了 TCP 和 MTU 的关系,就会明白这是如何做到的了。
MTU 本身是三层的概念,而在第四层的TCP 层面,有个对应的概念叫 MSS, Miaximum Segment Size(最大分段尺寸),也就是单纯的 TCP 载荷的最大尺寸。MTU 是三层报文的大小,在 MTU 的基础上刨去 IP 头部 20 字节和 TCP 头部 20 字节,就得到了最常见的 MSS 1460 字节。如果你之前对 MTU 和 MSS还分不清楚的话,现在应该能搞清楚了,如下图:
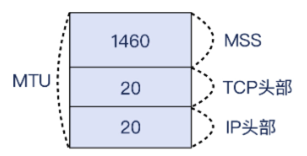
MSS 在 TCP 里是怎么体现的呢?其实我在 TCP 握手那一讲里提到过 Window Scale,你很容易能联想到,MSS 其实也是在握手阶段完成“通知”的。亡SYN 报文里,客户端向服务端通扱了自己的 MSS。而在 SYN+ACK 里,服务端也做了类似的事情。这样,两端就知道了对端的 MSS,在这条连接里发送报文的时候,双方发送的 TCP 载荷都不会超过对方声明的 MSS.
当然,如果发送端本地网口的 MTU 值,比对方的 MSS + IP header + TCP header 更低,那么会以本地 MTU 为准,这一点也不难理解。这里借用一下 RFC879 里的公式:
SndMaxSegSiz = MIN((MTU sizeof(TCPHiR) - sizeof(IPHDR)), MSS)
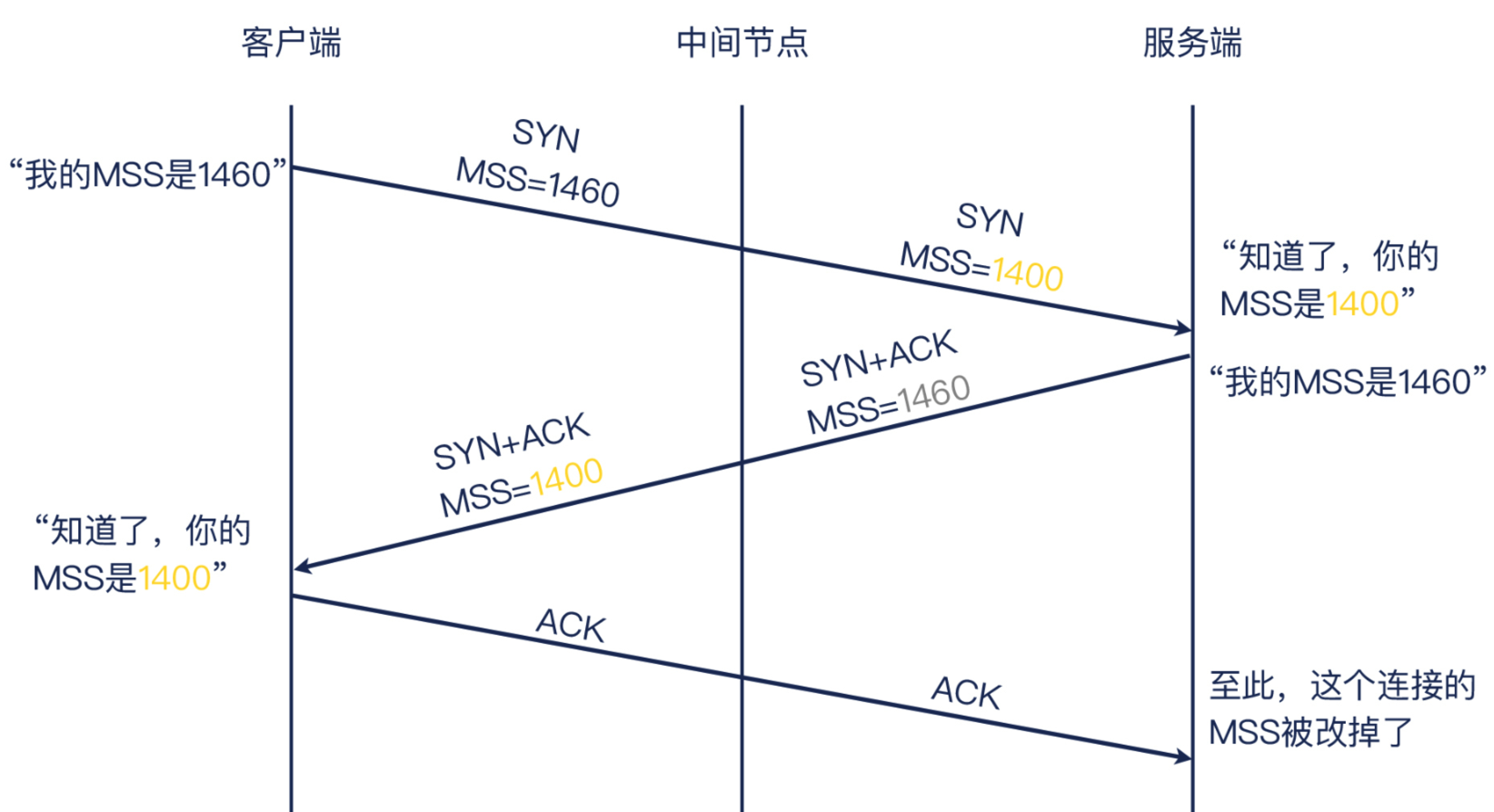
MTU 是两端的静态配置,除非我们登录机器,否则改不了它们的 MTU。但是,它们的 TCP 报文却是在网络上传送的,而我们做“暗箱操作”的机会在于:TCP 本身不加密,这就使得它可以被改变!也就是我们可以在中间环节修改 TCP 报文,让其中的 MSS 变为我们想要的值,比如把它调小。
这星立功的又是一张熟悉的面孔:iptables。在中间环节(比如某个软件路由或者软件网关) 上,在 iptabes 的 nat 表和 FORWARD 链这个位置,我们可以添加规则,修改报文的 MSS 值。比如在这个案例里,我们通过下面这条命令,把经过这个网络环节的下CP 握手报文里的 MSS,改为1400 字节:
iptables -A FORWARD -P tap --tcp-flags SYN SYN -J TCPMSS --set-mss 1400
它工作起来就是下图这样,是不是很巧妙?通过这种途中的修改,两端就以修改后的 MSS 来工作了,这样就避免了用原先过大的 MSS 引!发的问题。我称之为〝暗箱操作”,就是因为这是通信双方都不知道的一个操作,而正是这个操作不动声色地解了问题,如下图:
什么是网卡的 TSO 和 GRO
前面说的都是操作系统会做TCP 分段的情况。但是,这个工作其实还是有一些 CPU 的开销的,毕竟需要把应用层消息切分为多个分段,然后给它们组装 TCP 头部等。而为了提高性能,网卡厂商们提供了一个特性,就是让这个分段的工作从内核下沉到网卡上来完成,这个特性就是 T®P Segmentation Offload。
这里的 offload,如果仅仅翻译成“卸载”,可能还是有点晦涩。其实,它是 off + load,那什么是 load 呢?就是 CPU 的开销。如果网卡硬件芯片完成了这部分计算任务,那公 CPU 就减轻负担了,这就是 offload 一词的真正含义。
TSO 启用后,发送出去的报文可能会超过 MSS。同样的,在接收报文的方向,我们也可以启用 GRO (Generie Receive Offload)。比如下图中,TCP 载荷就有2800字节,这并不是说这些报文真的是以 2800 字节这个尺寸从网络上传输过来的,而是由手接收端启用了 GRO,由接收端的网卡负责把几个小报文“拼接”成了 2800 字节。

所以,如果以后你在 Wireshark 里看到这种超过1460 字节的 TCP 段长度,不要觉得奇怪了,这只是因为你启用了 TSO(发送方向),或者是 GRO(接收方向},而不是 TCP 报文真的就有这么大!
想要确认你的网卡是否启用了这些特性,可以用 ethtool 命令,比如下面这样:
root@node:~# ethtool -k eno1 | grep offload
tcp-segmentation-offload: on
udp-fragmentation-offload: off [fixed]
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: on
tx-vlan-offload: on
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
当然,在上面的输出中,你也能看到有好几种别的 offload。如果你感兴趣,可以自己搜索研究下,这里就不展开了。
对了,要想启用或者关闭 TSO/GRO,也是用 ethtool 命令,比如这样:
$ sudo ethtool -K eno1 tso off
$ sudo ethtool -k eno1 grep offload
tcp-segmentation-offload: off
IP 分片
IP层也有跟 TCP 分段类似的机制,它就是1P 分片。很多人搞不清P 分片和 TCP 分段的区别,甚至经常混为一谈。事实上,它们是两个在不同层面的分包机制,互不影响。
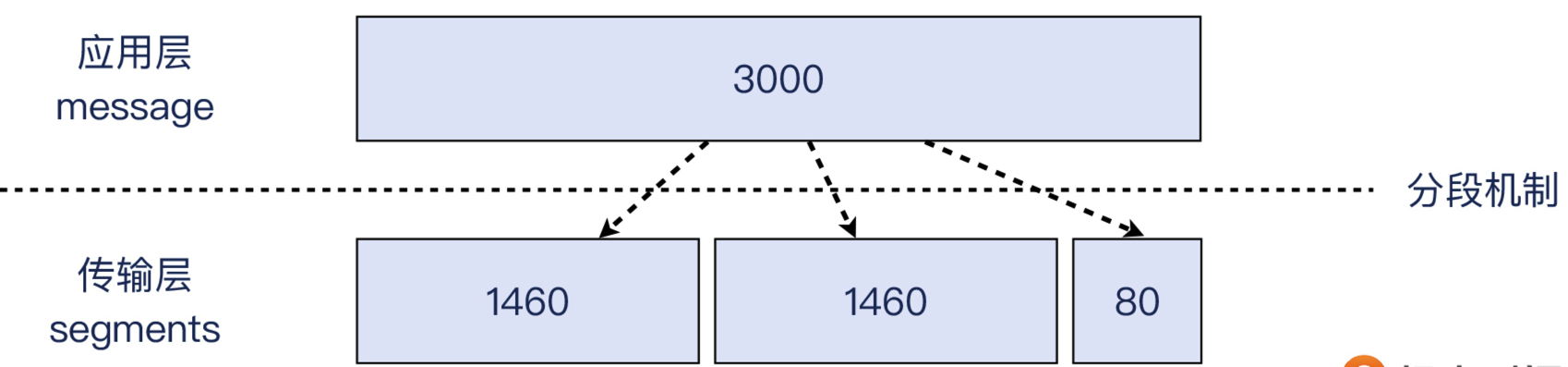
在TCP 这一层,分段的对象是应用层发给 TCP 的消息体 (message)。比如应用给 TCP 协议栈发送了 3000 字节的消息,那么 TCP 发现这个消息超过了 MSS(常见值为 1460),就必须要进行分段,比如可能分成 1460,1460,80 这三个 TOP段。
在 IP 这一层,分片的对象是P 包的载荷,它可以是 TCP 报文,也可以是UDP 报文,还可以是P 层自己的报文比如 ICMP。
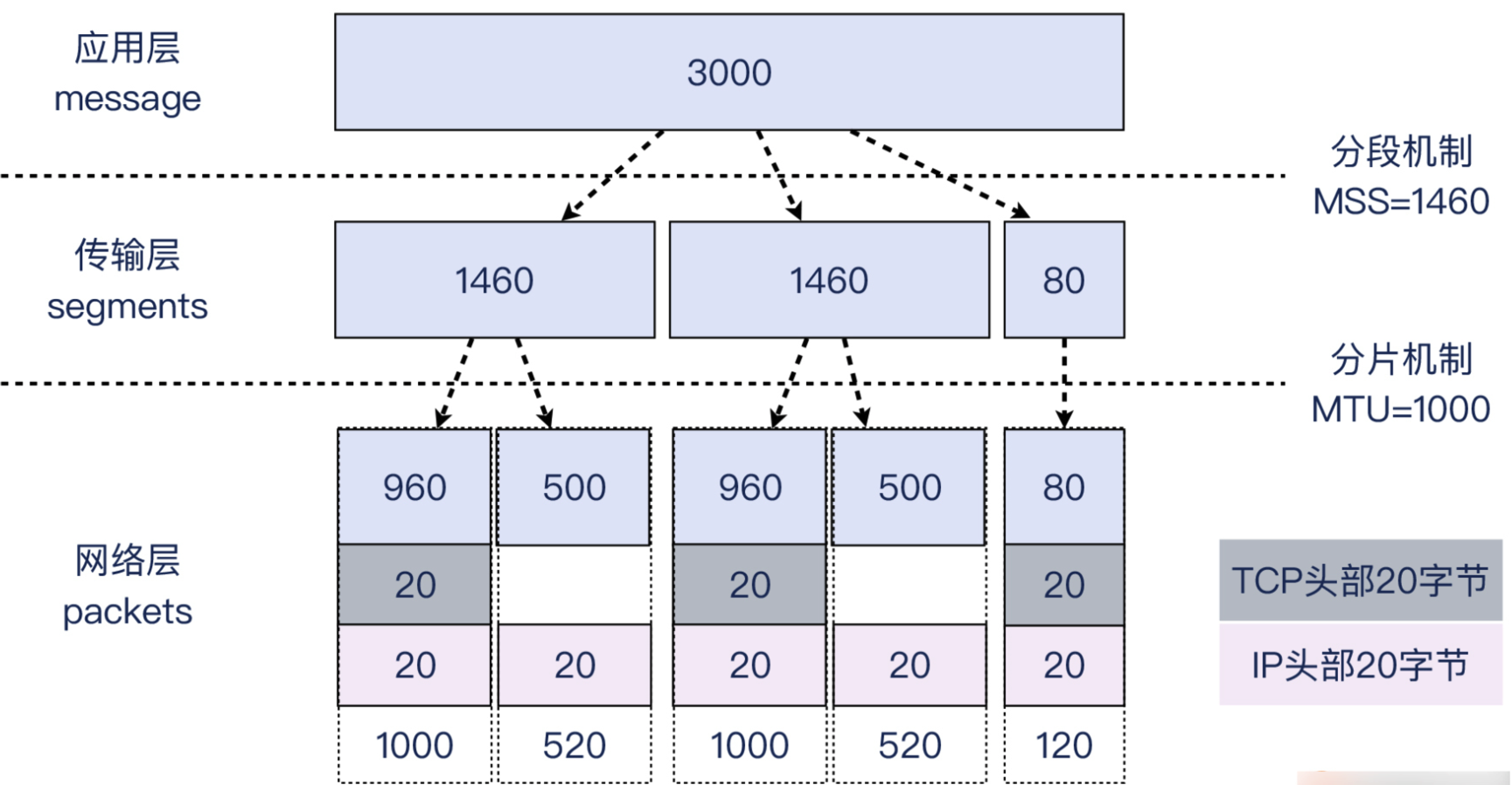
为了帮助你理解 segmentation 和 fragmentation 的区别,我现在假设一个“奇葩”的场景, 也就是 MSS为1460 字节,而 MTU 却只有1000 字节,那么 segmentation 和 fragmentation 将按照如下示意图来工作:
补充:为了方便讨论,我们假设TCP 头部就是没有 Option 扩展的20字节。但实际场景里,很可能 MSS 小于 1460 字节,而 TCP 头部也超过20字节。
当然,实际的操作系统不太会做这种自我矛盾的傻事,这是因为它自身会解决好 MSS 跟 MTU 的关系,比如一般来说,MSS 会自动调整为 MTU 减去 40 字节。但是我们如果把视野扩大到局域网,也就是主机再加上网络设备,那么就有可能发生这样的情况:1460 字节的 TCP 分段由这台主机完成,1000 字节的P 分片由路径中葉台 MTU 为1000 的网络设备完成。
这里其实也有个隐含的条件,就是主机发出的 1500 字节的报文,不能设置 DF (Don’t Fragment)位,否则它既超过了1000这个路径最小 MTU,又不允许分片,那么网络设备只能把它丢弃。
在 Wireshark 里,我们可以清楚地看到 P 报文的这几个标志位:
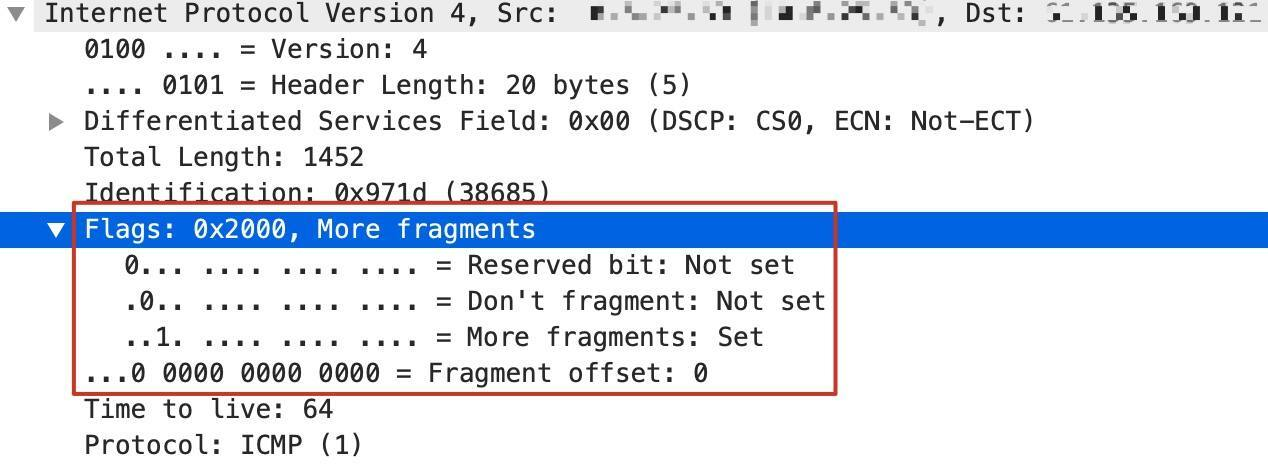
现在我们假设主机发出的报文是不带 DF 位的,那么在这种情况下,这台风络设备会把它切分为一个 1000(也就是960+20+20)字节的报文和一个 520(也就是500+20)字节的报文。1000 字节的P 报文的MF 位(More Fragment) 会设置为1,表示后续还有更多分片,而520字节的IP 报文的 MF 字段为 0。
这样的话,接收端收到第一个 P 报文时发现 MF 是1,就会等第二个 1P 报文到达,又因为第二个报文的MF 是口,那么结合第二个报文的 fragment offset 信息(这个报文在分片流中的位置),就把这两个报文重组为一个新的完整的IP 报文,然后进入正常处理流程,也就是上报给 TCP。
不过在现实场景里,P 分片是需要尽量避免的,原因有很多,主要是因为互联网是一个松散的架构,这就导致路径中的各个环节未必会完全遵照所有的约定。比如你发出了大于 PMTU 的报文,寄希望于 MTU 较小的那个网络环节为你做分片,但事实上它可能不做分片,而是直接丢弃,比如下面两种情况:
- 它考虑到开销等问题,未必做分片,所以直接丢弃。
- 如果你的报文有 DF 标志位,那么也是直接丢弃。
即使它帮你做了分片,但因为开销比较大,增加的时延对性能也是一个不利因装。
另外一个原因是,分片后,TCP 报文头部只在第一个 IP 分片中,后续分片不带 TCP 头部, 那么防火墙就不知道后面这几个报文用的传输层协议是什么,可能判断为有害报文而丢弃。
总之,为了避免这些麻烦,我们还是不要开启P 分片功能。事实上,Linux 默认的配置就是,发出的P 报文都设置了 DF 位,就是明确告诉每个三层设备:“不要对我的报文做分片, 如果超出了你的 MTU,那就直接丢奔,好过你慢腾腾地做分片,反而降低了网络性能”。
- 小结
这次,我们通过拆解一个典型的 MTU 引发的传输问题,学习了 MTU 和MSS、 分段和分片、各种卸载(offload)机制等概念。这里,我帮你再提炼几个要点:
- 在案例分析的过程中,我们解读了 Wireshark 里的信息,特别是两次 DupAck 和两次重传,推导出了问题的根因。这里,你需要了解200ms 超时重传这个知识点,这在平时排查重传问题时也经常用到。
- 借助 Wireshark 的 Flow graph,我们可以更加清晰地看到两端报文的流动过程,这对我们推导问题提供了便利。
- 如果能稳定重现成功和失败这两种不同场景,那就对我们排查工作提供了极大的便利。我们通过对比成功和失败两种场景下的不同的抓包文件,能比较快地定位到问题根因。
- 如果排查中遇到有“整数值”出现,可以重点查一下,一般这跟人为的设置有关系,也有可能就是根因,或者与根因有关。
- 如果你对网络中间环节(包括 LB、网关、防火墙等)有权限,又不想改动两端机器的 MTU,那么可以选择在中间环节实施“暗箱操作”,也就是用 iptables 规则改动双方的 MSS,从而间接地达到“双方不发送超过 MTU 的报文”的目的。
- 我们也学习了如何用 ethtool 工具查看 offload 相关特性,包括 TSO、 LRO、 GRO 等等。
- 同样通过 ethtool,我们还可以对这些特性进行启用或者禁用,这为我们的排查和调优工作提供了更大的余地。
- 抓包示例文件:https://gitee.com/steelvictor/network-analysis/tree/master/08
![[附源码]计算机毕业设计JAVA人力资源管理系统论文2022](https://img-blog.csdnimg.cn/01174571026b402ebe496c5e23abdafe.png)