【调优】大数据常见 Join 的使用场景
上次写了大表和大表 join 的调优方法,今天总结一下大数据常见的 Join 方法。
1.Shuffle Join
大数据采用的是分布式存储,一个表的数据会分散在各个节点。为了进行 join,通常都会进行 shuffle 操作,将 key 相同的数据(即 join on 的条件,比如 t1.uid = t2.uid,则 uid 就是 key)发送到一个节点才能进行 join,关于 shuffle 的原理可以看以前的文章。
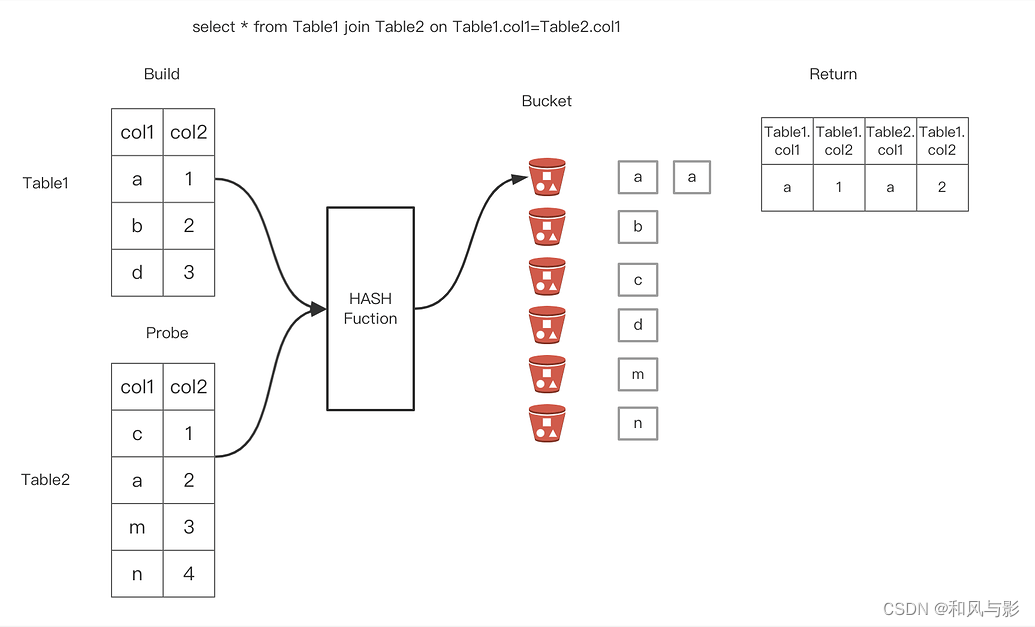
这样,便伴随着大量的数据发送和接收,以及磁盘的读写,造成大量的 IO 操作,影响 Join 操作的性能。
2.Broadcast Join
Broadcast Join 将右表全量发送到左表的 HashJoinNode,再进行 Join 操作。
这种 Join 方式通常用于大表和小表的 Join 中进行调优。大表和小表的 Join 如果采用第一种 Shuffle Join 的方法,则大表的数据也会根据 key 的哈希值在集群中进行分发,造成大量的网络 IO。如果将小表的数据全量发送到每个保存了大表的数据的节点进行 Join,由于大表的数据没有进行分发,只有小表的数据进行分发,这样便可以大量减少网络 IO,提高效率。
3.Colocate Joio
两个表的数据分布都是一样的,只需要本地 Join 即可,没有网络传输开销。
这种 Join 必须在数据存储进来时就按 key 分配存储节点才能够实现。
4.Bucket Shuffle Join
Join 的列是左表的数据分布列(分桶键),所以相比于 shuffle join 只需要将右表的数据发送到左表数据存储计算节点。
在大表和大表 Join 的文章中已经详细阐述过了。
5.Replicated Join
右表的全量数据是分布在每个节点上的(也就是副本个数和BE节点数量一致),不管左表怎么分布,都是走本地 Join。没有网络传输开销。



![[附源码]计算机毕业设计JAVA汽车租赁系统](https://img-blog.csdnimg.cn/6f7a202f91964d7382b633a5304333f0.png)