文章目录
- 线程同步
- 条件变量
- 条件变量的接口
- 生产者消费者场景
- 消费者和消费者的关系
- 生产者和生产者的关系
- 生产者和消费者的关系
- 从何体现出效率的提高
- Blockqueue
- blockqueue.hpp
- 为什么条件变量的接口有锁作为参数
- CP.cc
- 生产者 -> queue -> 消费者兼生产者 -> queue -> 消费者
- 实现大致目的
- 大致步骤
- blockqueue.hpp
- Task.hpp -- 任务头文件
- CP.cc
- 实现效果
- 总结
线程同步
在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题就叫做同步
也就是说当一个线程申请锁成功后,一旦它解锁了就不能够再申请锁,而是要到整个线程队尾进行排队,让下一个线程去申请锁。这样有序的去申请锁就叫做同步。
条件变量
条件变量的使用:一个线程等待条件变量的条件成立而被挂起;另一个线程使条件成立后唤醒等待的线程。
也就是说使用条件变量后,所有的线程必须同步去执行,但条件满足时线程就挂起直到另一个线程唤醒它。
条件变量相当于一个线程执行的必要条件,只有满足条件的线程才能继续执行
条件变量的接口
定义条件变量:pthread_cond_t XXX
全局初始化 = PTHREAD_COND_INITALIZER
局部初始化使用:pthread_cond_init
#include <pthread.h>
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
参数一为条件变量的地址,参数二为可以不关心设为nullptr
销毁条件变量:pthread_cond_destroy
int pthread_cond_destroy(pthread_cond_t *cond);
满足条件变量则挂起等待:pthread_cond_wait
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
参数一为条件变量的地址,参数二为锁的地址(后面会谈到为什么有锁作为参数)
唤醒线程:pthread_cond_signal
int pthread_cond_broadcast(pthread_cond_t *cond);//唤醒全部线程int pthread_cond_signal(pthread_cond_t *cond);//唤醒一个线程
参数都为条件变量的地址
生产者消费者场景
在日常的生活中,这个场景并不会陌生。例如:供货商 -> 超市 -> 顾客。而供货商就相当于生产者,顾客就相当于消费者,超市就充当一个中间商。顾客不可能直接去跟供货商买东西,而供货商也不会直接卖给顾客东西,超市就充当了这样一个中间的角色。
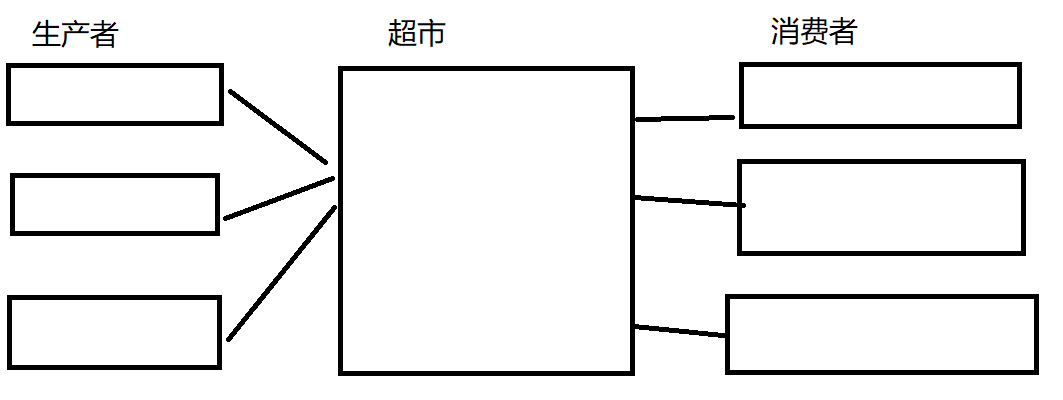
在线程的角度也是如此,假设现在一批线程充当着生产者的角色,另一批线程充当着消费者的角色。那么生产者线程不会直接就将数据传给消费者线程,而是会将数据放入到一个相当于缓冲区中,而这个过程又可以称为 生产者和消费者之间的解耦
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题
那么对于这种模型又会衍生出三种关系:
消费者和消费者的关系
对于消费者而言,因为缓冲区中的空间有限,而消费者线程只需要将数据写入到缓冲区,可是当缓冲区中已经有线程在写入中了,其他的线程就不能往缓冲区里写了,而是要等到前面的线程写完后再判断缓冲区是否还没满才可以写入。这就形成了消费者和消费者之间的互斥关系
生产者和生产者的关系
对于生产者也是同理,一个线程读时其他线程同样需要等待。这也就形成了互斥关系
生产者和消费者的关系
生产者和消费者既有互斥又有同步,当一个线程写时,另一个线程去读这种情况就会导致数据的不安全性,因此互斥就是为了保证共享资源的安全性。而每次缓冲区都只有一个线程去执行时,其他线程在等待一旦执行缓冲区的线程解锁了,等待的线程就可以马上申请锁去执行缓冲区,这样效率就会大大提高,因此同步是为了提高效率的。
从何体现出效率的提高
上面谈到缓冲区每次都只有一个线程在执行。那么在这个线程访问执行时其他线程在干什么呢?
首先线程在读或写之前肯定是会有其他的任务需要做的,比如创建写的数据,创建存放读到的数据空间等等。那么在一个线程访问缓冲区时,其他的线程就可以做这些访问缓冲区前的任务,一旦访问缓冲区的线程完成了,其他的线程就不需要再去完成访问缓冲区前的任务直接就可以访问缓冲区了,这就是效率提高的表现
因此:效率的提高真正体现的并不是访问缓冲区的过程,而是访问缓存区之前的过程,这也就是多消费者多生产者的意义
Blockqueue
阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。
阻塞队列为空时,消费者线程将被阻塞,直到阻塞队列被放入元素
阻塞队列已满时,生产者线程将被阻塞,直到有元素被取出
那么利用这个阻塞队列结合条件变量和锁,就可以编写出一套简单的模型。
blockqueue.hpp
#pragma once#include <iostream>
#include <pthread.h>
#include <queue>// 设置默认的最大容量
static int max = 10;template <class T>
class blockqueue
{
public:blockqueue(const int &maxnum = max): _maxnum(maxnum){pthread_mutex_init(&_lock, nullptr);pthread_cond_init(&_pcond, nullptr);pthread_cond_init(&_ccond, nullptr);}// 插入数据void push(const T &in){// 加锁pthread_mutex_lock(&_lock);// 判断队列是否满了,如果为空则等待// 充当条件判断的语法必须是while,不能用ifwhile (_q.size() == _maxnum)pthread_cond_wait(&_pcond, &_lock);// 插入数据_q.push(in);// 走到这里说明队列一定有数据,就可以唤醒消费者的线程pthread_cond_signal(&_ccond);// 解锁pthread_mutex_unlock(&_lock);}// 拿到头部数据并删除void pop(T *out){// 加锁pthread_mutex_lock(&_lock);// 判断队列是否满了,如果为空则等待// 充当条件判断的语法必须是while,不能用ifwhile (_q.size() == 0)pthread_cond_wait(&_ccond, &_lock);// 拿到头部数据并删除*out = _q.front();_q.pop();// 走到这里说明队列一定不会满,就可以唤醒生产者的线程pthread_cond_signal(&_pcond);// 解锁pthread_mutex_unlock(&_lock);}~blockqueue(){pthread_mutex_destroy(&_lock);pthread_cond_destroy(&_pcond);pthread_cond_destroy(&_ccond);}private:std::queue<T> _q;int _maxnum; // 最大容量pthread_mutex_t _lock;pthread_cond_t _pcond; // 生产者的条件变量pthread_cond_t _ccond; // 消费者的条件变量
};注意:为什么上面的代码里判断条件需要用循环而不是if呢,这就要说到上面的为什么pthread_cond_wait的参数里会有锁了。
为什么条件变量的接口有锁作为参数
首先,能够执行到这个接口说明该线程必定申请锁成功了。如果现在线程执行到了wait这个接口,那么线程就会被阻塞。但是这个线程已经申请了锁其他的线程就没有办法再去申请锁了,那么此时这个线程就一定要解锁,而pthread_cond_wait这个接口就会自动的帮这个线程解锁。
当这个线程阻塞后被其他的线程唤醒后,pthread_cond_wait这个接口就会自动帮这个线程再次加锁,所以为了确保再次加锁的锁是和之前的一样的,pthread_cond_wait接口就会带上锁的地址作为参数。
那么为什么要用循环而不是if呢?最主要的原因是,即使这个线程被唤醒了,但是它仍有可能还是处于不满足条件的情况,因此为了确保数据的安全要再次对这个线程进行判断,直到该线程满足条件才能继续往下执行。
CP.cc
#include "BlockQueue.hpp"
#include <ctime>
#include <unistd.h>// 生产
void *Producer(void *argc)
{blockqueue<int> *t = (blockqueue<int> *)argc;while (1){// 随机产生数据插入int x = rand() % 100 + 1;t->push(x);std::cout << "生产计算数据:" << x << std::endl;sleep(1);}return nullptr;
}// 消费
void *Consumer(void *argc)
{blockqueue<int> *t = (blockqueue<int> *)argc;while (1){// 拿出数据int x;t->pop(&x);std::cout << "消费计算数据:" << x << std::endl;}return nullptr;
}int main()
{// 设置随机种子srand(time(nullptr));blockqueue<int>* dq = new blockqueue<int>();pthread_t c, p;// 创建计算生产者pthread_create(&p, nullptr, Producer, dq);// 创建计算消费者pthread_create(&c, nullptr, Consumer, dq);pthread_join(p, nullptr);pthread_join(c, nullptr);return 0;
}
上面的代码就可以实现单消费者和单生产者的模型。生产者就会往阻塞队列里面写入数据,消费者就可以往阻塞队列里面读数据
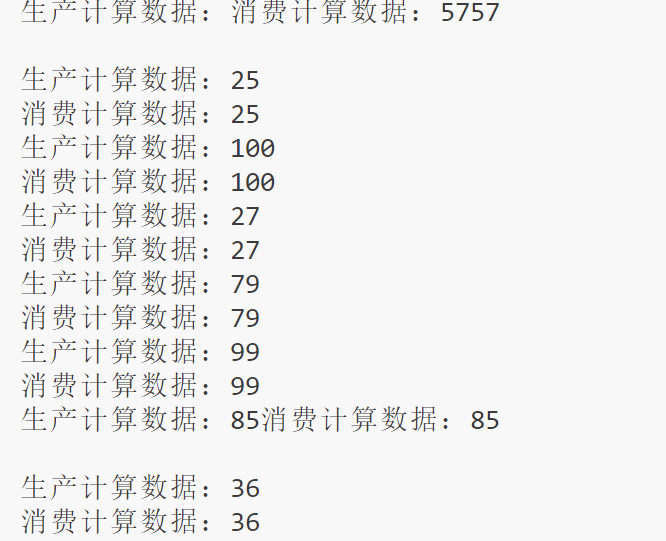
那么根据这个模式再来实现一个加大点难度的模型代码
生产者 -> queue -> 消费者兼生产者 -> queue -> 消费者
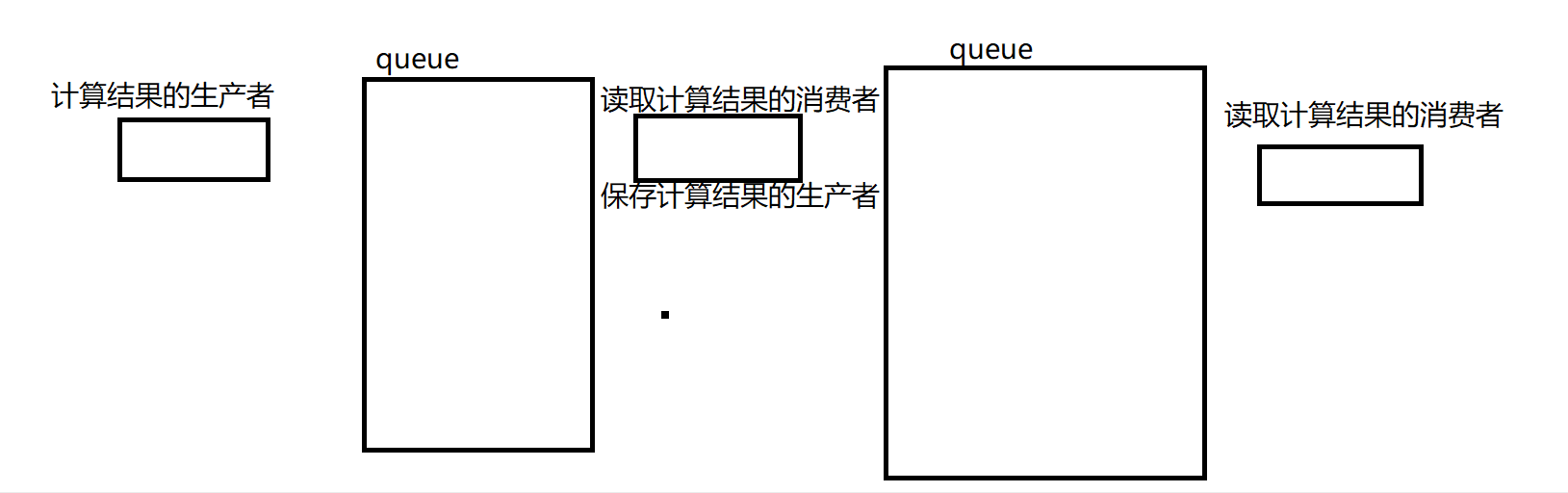
实现大致目的
- 一个生产者,一个消费者兼生产者,一个消费者
- 计算过程由随机数,随机符号
- 第一个消费者读到数据后传到第二个队列中
- 最后读取计算结果的消费者将数据读到文件中
大致步骤
- 因为有不同的任务,所以创建一个任务头文件
- 由于是两个不同的队列,因此可以创建一个队列组的类
- ±*/ 随机
- 以下代码均有注释
blockqueue.hpp
#pragma once#include <iostream>
#include <pthread.h>
#include <queue>// 设置默认的最大容量
static int max = 10;template <class T>
class blockqueue
{
public:blockqueue(const int &maxnum = max): _maxnum(maxnum){pthread_mutex_init(&_lock, nullptr);pthread_cond_init(&_pcond, nullptr);pthread_cond_init(&_ccond, nullptr);}// 插入数据void push(const T &in){// 加锁pthread_mutex_lock(&_lock);// 判断队列是否满了,如果为空则等待// 充当条件判断的语法必须是while,不能用ifwhile (_q.size() == _maxnum)pthread_cond_wait(&_pcond, &_lock);// 插入数据_q.push(in);// 走到这里说明队列一定有数据,就可以唤醒消费者的线程pthread_cond_signal(&_ccond);// 解锁pthread_mutex_unlock(&_lock);}// 拿到头部数据并删除void pop(T *out){// 加锁pthread_mutex_lock(&_lock);// 判断队列是否满了,如果为空则等待// 充当条件判断的语法必须是while,不能用ifwhile (_q.size() == 0)pthread_cond_wait(&_ccond, &_lock);// 拿到头部数据并删除*out = _q.front();_q.pop();// 走到这里说明队列一定不会满,就可以唤醒生产者的线程pthread_cond_signal(&_pcond);// 解锁pthread_mutex_unlock(&_lock);}~blockqueue(){pthread_mutex_destroy(&_lock);pthread_cond_destroy(&_pcond);pthread_cond_destroy(&_ccond);}private:std::queue<T> _q;int _maxnum; // 最大容量pthread_mutex_t _lock;pthread_cond_t _pcond; // 生产者的条件变量pthread_cond_t _ccond; // 消费者的条件变量
};// 将负责计算的队列和负责保存的队列归并成一个类以便后续调用
// 队列组的类
template <class C, class S>
class blockqueues
{
public:// 计算队列blockqueue<C>* _cp;// 保存队列blockqueue<S>* _sc;
};
Task.hpp – 任务头文件
#include <iostream>
#include <string>
#include <functional>
#include <cstdio>// 负责计算的任务类
class CPTask
{// 调用的计算方法,根据传入的字符参数决定typedef std::function<int(int, int, char)> func_t;public:CPTask(){}CPTask(int x, int y, char op, func_t func): _x(x), _y(y), _op(op), _func(func){}// 实现传入的函数调用std::string operator()(){int count = _func(_x, _y, _op);// 将结果以自定义的字符串形式返回char res[2048];snprintf(res, sizeof res, "%d %c %d = %d", _x, _op, _y, count);return res;}// 显示出当前传入的参数std::string tostring(){char res[1024];snprintf(res, sizeof res, "%d %c %d = ", _x, _op, _y);return res;}private:int _x;int _y;char _op;// +-*/func_t _func;// 实现方法
};// 负责计算的任务函数
// 实现+-*/ 随机
int Math(int x, int y, char c)
{int count;switch (c){case '+':count = x + y;break;case '-':count = x - y;break;case '*':count = x * y;break;case '/':{if (y == 0){std::cout << "div zero" << std::endl;count = -1;}elsecount = x / y;break;}default:break;}return count;
}class SCTask
{// 获取保存数据的方法typedef std::function<void(std::string)> func_t;public:SCTask(){}SCTask(const std::string &str, func_t func): _str(str), _func(func){}//调用方法void operator()(){_func(_str);}private:std::string _str;// 数据func_t _func;// 实现方法
};// 负责保存的方法,将数据读取到保存至文件
void Save(const std::string &str)
{std::string res = "./log.txt";FILE *fd = fopen(res.c_str(), "a+");if (!fd)return;fwrite(str.c_str(), 1, sizeof str.c_str(), fd);fputs("\n", fd);fclose(fd);
}
CP.cc
#include "BlockQueue.hpp"
#include <ctime>
#include <unistd.h>
#include "Task.hpp"// 生产
void *Producer(void *argc)
{// 将参数转换回计算队列的类型blockqueue<CPTask> *t = (blockqueue<CPTask> *)((blockqueues<CPTask, SCTask> *)argc)->_cp;while (1){std::string ops("+-*/");// 随机产生数据插入int x = rand() % 100 + 1;int y = rand() % 100 + 1;int opnum = rand() % ops.size();// 随机提取+-*/char op = ops[opnum];// 定义好实现类的对象CPTask C(x, y, op, Math);//将整个对象插入到计算队列中t->push(C);std::cout << "生产计算数据:" << C.tostring() << std::endl;sleep(1);}return nullptr;
}// 消费
void *Consumer(void *argc)
{// 因为这个是身兼两者身份// 因此要有两种队列的类型对象blockqueue<CPTask> *t = (blockqueue<CPTask> *)((blockqueues<CPTask, SCTask> *)argc)->_cp;blockqueue<SCTask> *s = (blockqueue<SCTask> *)((blockqueues<CPTask, SCTask> *)argc)->_sc;while (1){// 计算队列类型拿出数据std::string res;CPTask c;t->pop(&c);res = c();std::cout << "消费计算数据:" << res << std::endl;// 插入保存数据队列SCTask sc(res, Save);s->push(sc);std::cout << "生产保存数据: ......done" << std::endl;}return nullptr;
}void *Saver(void *argc)
{// 将参数转换回保存队列的类型blockqueue<SCTask> *s = (blockqueue<SCTask> *)((blockqueues<CPTask, SCTask> *)argc)->_sc;while (1){// 拿出数据SCTask t;s->pop(&t);//调用方法t();std::cout << "消费保存数据:......done" << std::endl;}return nullptr;
}int main()
{// 设置随机种子srand(time(nullptr));// 创建队列对象blockqueues<CPTask, SCTask> dqs;dqs._cp = new blockqueue<CPTask>;dqs._sc = new blockqueue<SCTask>;pthread_t c, p, s;// 创建计算生产者pthread_create(&p, nullptr, Producer, &dqs);// 创建计算消费者兼保护生产者pthread_create(&c, nullptr, Consumer, &dqs);// 创建保存消费者pthread_create(&c, nullptr, Saver, &dqs);pthread_join(p, nullptr);pthread_join(c, nullptr);pthread_join(s, nullptr);delete dqs._cp;delete dqs._sc;return 0;
}
实现效果
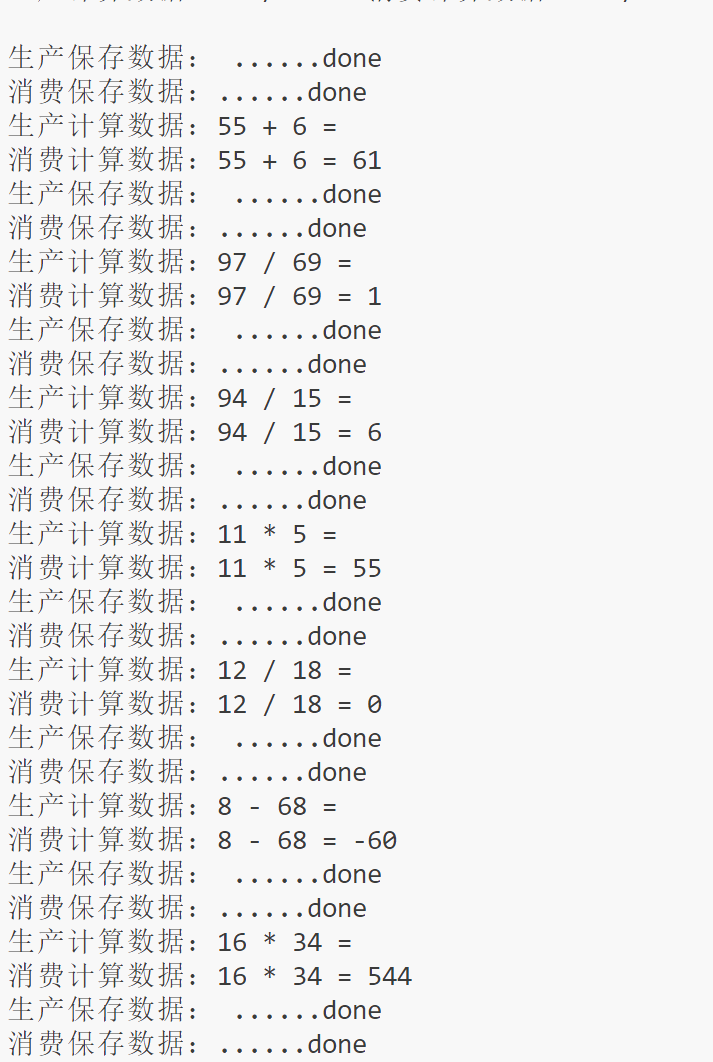
log.txt:
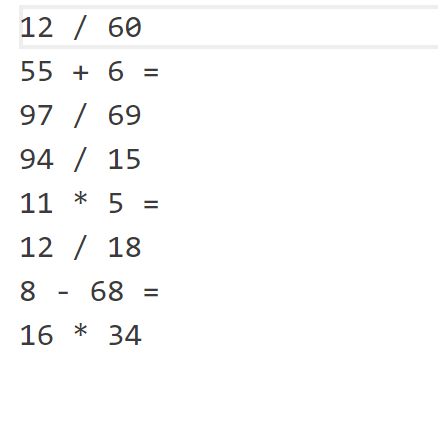
总结
上面的代码都是单线程去做一个工作的,事实上多线程也是可以的,因为对于访问共享资源(缓冲区、阻塞队列)一次只能有一个线程做这个工作。上面也提到了对于效率的提高并不是体现在共享资源内的,而是访问共享资源前的工作。因此多线程的效率提高也就在这方面。
线程的学习需要熟知各个概念和多动手写代码,像这个生产者消费者模型理解起来不算很难,但是上手写代码就非常复杂。线程的接口较多,多练才能熟记