图像视频基础
文章目录
- 图像视频基础
- 图像
- 颜色深度
- 分辨率
- 视频
- 帧率
- 比特率
- 帧类型
- YUV模型
- 色度子采样
图像
颜色深度
存储颜色的强度,需要占用一定大小的数据空间,这个大小被称为颜色深度。假如每个颜色的强度占用 8 bit(取值范围为 0 到 255,即 2 8 2^8 28),那么颜色深度就是 24(8*3)bit(因为RGB三个颜色),我们还可以推导出我们可以使用 2 24 2^{24} 224种不同的颜色。
分辨率
即一个平面内像素的数量。通常表示成宽*高
视频行业常见的分辨率,我们比较熟悉的360P (640x360)、720P (1280x720)、1080P (1920x1080)、4K (3840x2160)、8K (7680x4320)
我发现宽都是高的1.77777倍
视频
帧率
帧率(FRames rate)= 帧数(Frames)/时间(Time)
若单位时间为秒,则等同于 FPS (每秒帧数 Frames Per Second)。
比特率
即常说的码率
比特率 = 宽 * 高 * 颜色深度 * 帧每秒
例如,一段每秒 30 帧,每像素 24 bits,分辨率是 480x240 的视频,如果我们不做任何压缩,它将需要 82,944,000 比特每秒或 82.944 Mbps (30x480x240x24)。
-
对于一个单独的一小时长的视频,分辨率为1080p 和 30fps 的视频
-
每幅图片的大小为: 1920 x 1080 x 24 / 8 ≈ 5.93MB(图片大小计算公式=分辨率*位深/8)
-
一小时的视频大小为:5.93 * 30 * 3600=640440MB ≈625GB
所以要压缩,消除冗余
为此,我们可以
利用视觉特性:和区分颜色相比,我们区分亮度要更加敏锐。
时间上的重复:一段视频包含很多只有一点小小改变的图像。
图像内的重复:每一帧也包含很多颜色相同或相似的区域。
我们的眼睛对亮度比对颜色更敏感
帧类型
I帧(帧内,关键帧)
P帧(预测)
B帧(双向预测)

YUV模型
有一种模型将亮度(LUMA)和色度(cb,cr)分离开,它被称为 YUV模型。
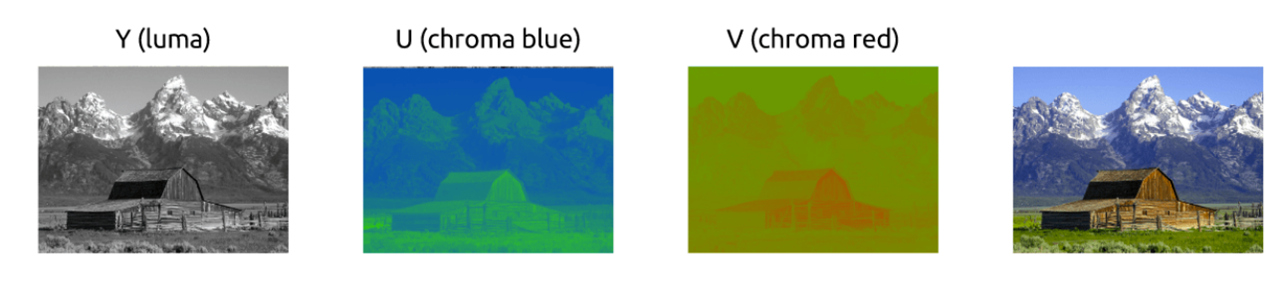
色度子采样
一旦我们能从图像中分离出亮度和色度,我们就可以利用人类视觉系统对亮度比色度更敏感的特点,选择性地剔除信息。色度子采样是一种编码图像时,使色度分辨率低于亮度的技术。
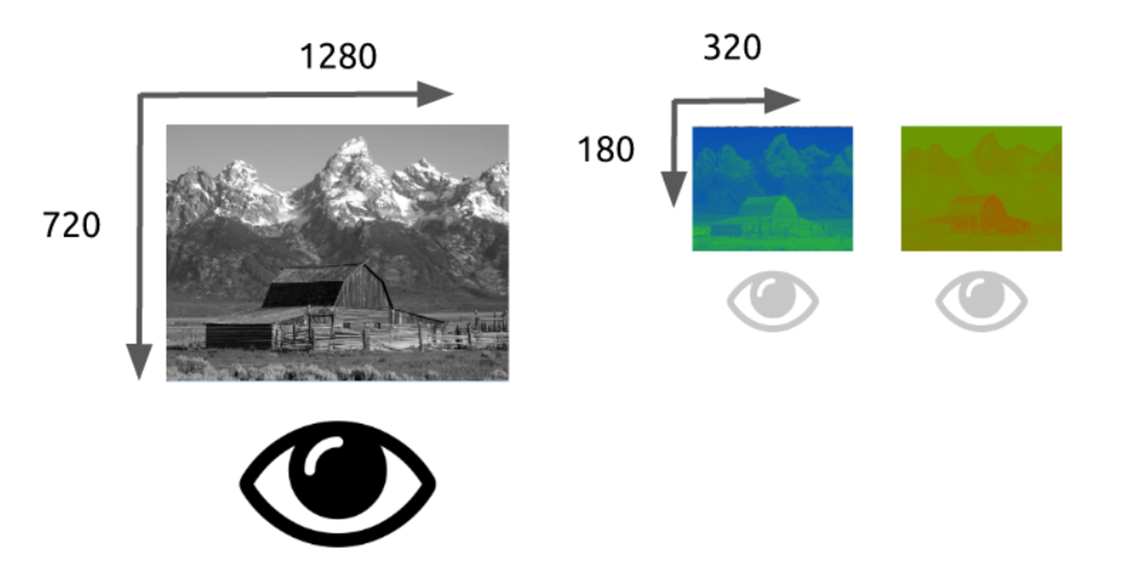
四个亮度像素共享一个色度像素
现代编解码器中使用的常用方案是: 4:4:4 (没有子采样), 4:2:2, 4:2:0,
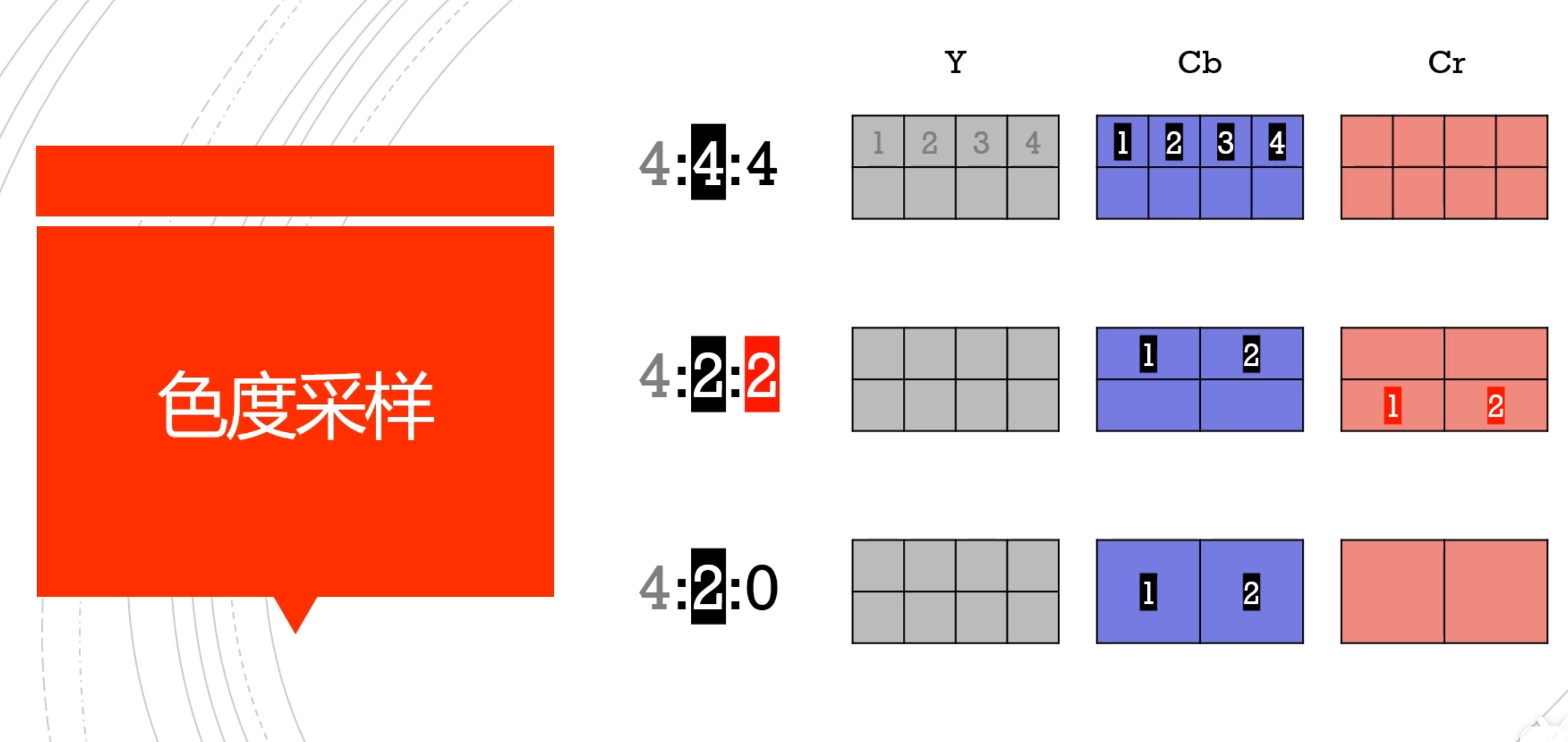
第二个参数代表第一行分成几块
第三个参数代表第二行分成几块
如果我们使用 YCbCr 4:2:0 我们能减少一半的大小