目录
一、B+树结构
1. 二分查找法
2. 二叉查找树
3. 平衡二叉树
4. 平衡多路查找树(B-Tree)
5. B+树
二、操作B+树
1. 插入操作
2. 删除操作
三、B+树索引类型
1. 聚集索引(clustered index)
2. 辅助索引(secondary index)
3. 总结
四、索引管理
1. 索引分裂
2. 快速创建辅助索引(FIC)
3. 在线数据定义(Online DDL)
五、索引使用
1. 联合索引
2. 覆盖索引
3. FORCE/USE INDEX
4. 多范围读(MRR)
5. 索引条件下推(ICP)
六、Cardinality值
1. SHOW INDEX FROM命令
2. Cardinality值
七、参考资料
一、B+树结构
1. 二分查找法
二分查找法(binary search)也称折半查找法,用来查找一组有序数组中的某一数据,每次查找与中间(折半)位置数据比较,每通过一次比较,查找区间缩小一半。注意,二分查找的平均查找效率高于顺序查找。
2. 二叉查找树
二叉查找树是一种经典的数据结构,其特点:左子树的键值 < 根的键值 < 右子树的键值。如下图所示是一棵二叉查找树,经过遍历后输出:2、3、5、6、7、8。
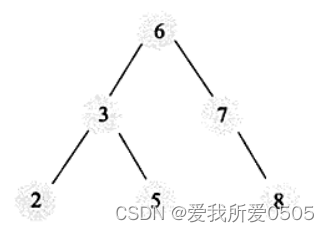
如果按照上图查找5,查找步骤如下:
- step1:找到根,键值6 > 5,往左子树方向查找;
- step2:找到键值3,3 < 5,往右子树方向查找;
- step3:找到键值5,5 = 5,查找结束。
二叉查找树查找5需3次,而顺序查找5也需3次。以同样的方法查找,二叉查找树查找2需3次,而顺序需1次;二叉查找树查找8需3次,而顺序需6次。计算平均查找次数可得:顺序查找的平均次数 (1+2+3+4+5+6)/ 6 = 3.3次,而二叉查找树查找的平均次数 (3+3+3+2+2+1)/ 6 = 2.3次(相同高度的查找次数相同)。所以二叉查找树的平均查找效率高于顺序查找。

上图所示,也是一棵二叉查找树,则平均查找次数(5+5+4+3+2+1)/ 6 = 3.16次。若想二叉查找树查找效率高,则这棵树是平衡的,即:平衡二叉树(AVL树)。
3. 平衡二叉树
平衡二叉树(AVL树)的定义,首先满足二叉查找树的定义(即:左子树的键值 < 根的键值 < 右子树的键值),其次满足任何节点的两个子树的高度差不能大于1。
平衡二叉树的查询速度很快,但是维护一棵平衡二叉树的代价也很大。一般情况下,需要1次或多次的左旋和右旋使得插入或删除后依然保持平衡,如下图所示。维护树的平衡开销大,平衡二叉树多用于内存结构对象中,因此维护的开销相对较小。

4. 平衡多路查找树(B-Tree)
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
硬盘的最小存储单位是扇区(大小512字节),磁盘本身没有block的概念,而文件系统不是一个扇区来读,读取太慢,block是文件存取的最小单位。如InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位,默认每个页的大小为16KB(32个扇区)。
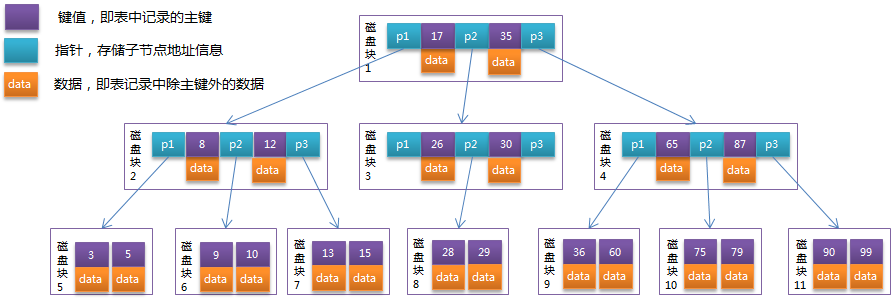
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。如下图所示,每个节点占用一个磁盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
5. B+树
B+树的特点:
- 非叶子节点只存储键值信息;
- 所有叶子节点之间都有一个链指针;
- 数据记录都存放在叶子节点中。
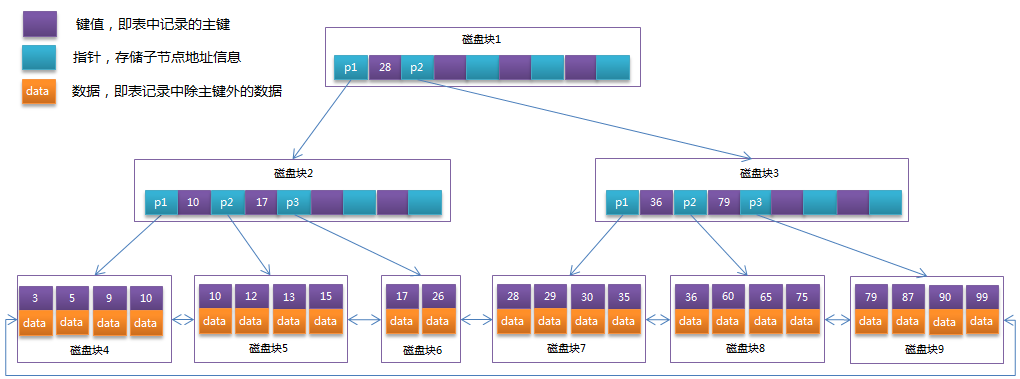
MySQL的InnoDB存储引擎使用B+索引结构,每个磁盘块对应页的形式存储。聚集索引是根据表主键顺序的键值存放(索引组织表),它由索引页(非叶子节点)、数据页(叶子节点)组成。每个叶子节点(数据页)用双向指针链接,数据页中的记录用单向指针链接。所以,聚集索引是索引即数据,数据即索引。
使用工具py_innodb_page_info.py(详细见:py_innodb_page_info.py工具使用_爱我所爱0505的博客-CSDN博客)来分析表空间。t_activity_detail的空间共832页,其中B+树节点页有296页,空闲页有533页。而B+树当前高度是2层,最高层page level <0001>,属于索引页;page level <0000>是数据页。
[root@488c1daa7967 py_innodb_page_info]# python py_innodb_page_info.py -v /home/MySQL5.7/mysql-5.7.35/data/test_mysql/t_activity_detail.ibd
page offset 00000000, page type <File Space Header>
page offset 00000001, page type <Insert Buffer Bitmap>
page offset 00000002, page type <File Segment inode>
page offset 00000003, page type <B-tree Node>, page level <0001>
page offset 00000004, page type <B-tree Node>, page level <0001>
page offset 00000005, page type <B-tree Node>, page level <0001>
page offset 00000006, page type <B-tree Node>, page level <0001>
page offset 00000007, page type <B-tree Node>, page level <0001>
page offset 00000008, page type <B-tree Node>, page level <0001>
page offset 00000009, page type <B-tree Node>, page level <0001>
page offset 0000000a, page type <B-tree Node>, page level <0001>
page offset 0000000b, page type <B-tree Node>, page level <0000>
page offset 0000000c, page type <B-tree Node>, page level <0000>
page offset 0000000d, page type <B-tree Node>, page level <0000>
page offset 0000000e, page type <B-tree Node>, page level <0000>
page offset 0000000f, page type <B-tree Node>, page level <0000>
page offset 00000010, page type <B-tree Node>, page level <0000>
page offset 00000011, page type <B-tree Node>, page level <0000>
......
page offset 000000e3, page type <B-tree Node>, page level <0000>
page offset 00000000, page type <Freshly Allocated Page>
page offset 00000000, page type <Freshly Allocated Page>
......
page offset 00000000, page type <Freshly Allocated Page>
page offset 00000100, page type <B-tree Node>, page level <0000>
page offset 00000101, page type <B-tree Node>, page level <0000>
page offset 00000102, page type <B-tree Node>, page level <0000>
......
page offset 00000146, page type <B-tree Node>, page level <0000>
page offset 00000000, page type <Freshly Allocated Page>
page offset 00000000, page type <Freshly Allocated Page>
......
page offset 00000000, page type <Freshly Allocated Page>
Total number of page: 832:
Freshly Allocated Page: 533
Insert Buffer Bitmap: 1
File Space Header: 1
B-tree Node: 296
File Segment inode: 1二、操作B+树
1. 插入操作
B+树插入必须保证插入后叶子节点中记录依然顺序,如下表所示,3种插入情况。
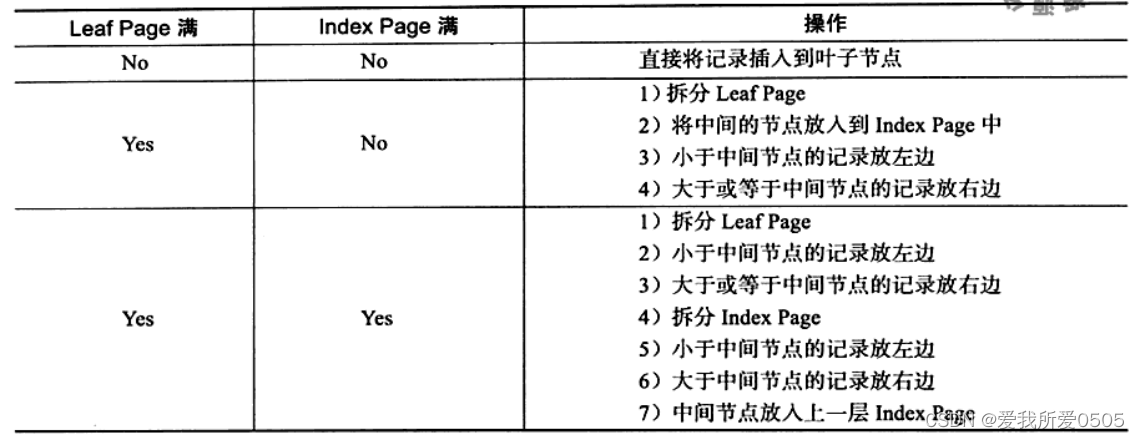

如上图所示,插入键值28时,属第一种情况:数据页不满 + 索引页不满,下图插入键值28:

接着再插入键值70,属第二种情况:数据页满 + 索引页不满。则:50、55、60、65、70,取中间值60,添加到上层索引页中,下图插入键值70:

接着再插入键值95,属第三种情况:数据页满 + 索引页满。需要做两次拆分:
- 第一次拆分数据页:75、80、85、90、95,取中间值85,添加到上层索引页中;
- 第二次拆分索引页:25、50、60、75、85,取中间值60,添加到上层索引页中;
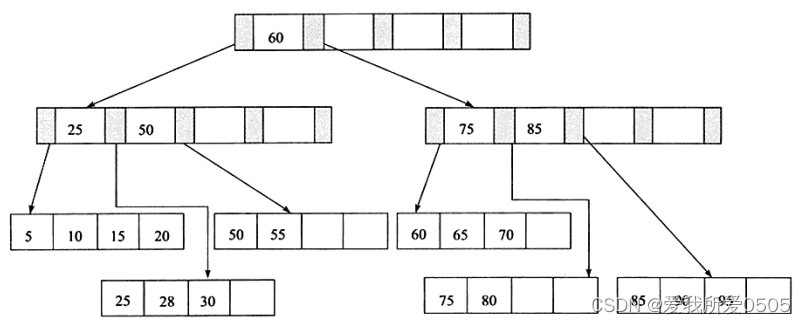
通过上面的插入操作,B+树总是会保持平衡。数据库高并发写的情况下,为了保持平衡,需要做大量的拆分页操作。而页的拆分需要对磁盘操作,所以应尽量避免页的拆分,因此提供了类似于AVL树的旋转功能。
旋转发生条件:数据页已满,但是左右兄弟页未满。这时B+树不会急于拆分页,将记录移动到所在页的兄弟页上,一般首先用左兄弟页做旋转操作。
2. 删除操作
B+树使用填充因子(fill factor)来控制树的删除,50%是填充因子的最小值。如下表所示,3种删除情况。

B+树删除必须保证删除后叶子节点中记录依然顺序。数据页或索引页填充因子小于50%则需要合并页操作。
三、B+树索引类型
MySQL的InnoDB存储引擎采用B+树索引,则B+树索引的本质就是B+树在数据库中的实现。一般B+树的高度2 ~ 4层,即:找到行记录所在的页最多只需2到4次IO。目前磁盘每秒至少100次IO,因此2 ~ 4次IO查询时间只需0.02 ~ 0.04秒。
B+索引类型分为聚集索引(clustered index)、辅助索引(secondary index)。无论哪种索引,则都是B+树,且高度平衡。
1. 聚集索引(clustered index)
聚集索引(clustered index)是按照主键(PRIMARY KEY)构造一个B+树,由叶子节点(数据页)、非叶子节点(索引页)组成,数据页存放行记录的完整数据。聚集索引的特性决定了索引组织表的数据也是索引的一部分,即:数据即索引,索引即数据。
每张表只能拥有一个聚集索引。多数情况下,优化器倾向于使用聚集索引,原因是聚集索引能够在叶子节点中直接找到整行数据内容。对于主键的顺序和范围查询速度非常快。
注意,聚集索引的存储不是物理连续,而是逻辑连续的,如下:
- 叶子节点之间的连接:双向链接
- 行记录之间的连接:单向链接
2. 辅助索引(secondary index)
辅助索引(secondary index)是按照非主键的其他键值构造一个B+树,此时叶子节点存放的行记录是该列的主键值,而不是整行数据内容。
注意,辅助索引的存在与否不影响聚集索引中的组织,每张表可以有多个辅助索引;通过辅助索引获取完整数据,则需要再查询聚集索引。
3. 总结
| 类型 | 数据页 | 索引页 | 描述 |
| 聚集索引 (clustered index) | 主键顺序 存放完整行数据 | 主键有序 (无随机读完整数据) | 1. 根索引在内存中; 2. 主键顺序存放的B+树,叶子节点(数据页)存放行记录的全部数据; 3. 每张表有且只有一个聚集索引; 4. 逻辑连续,即:页是双向链表、记录是单向链表(不是物理连续); 5. 叶子节点称为数据页,存放整行记录(索引即数据,数据即索引); 6. 不是所有主键都是顺序,如:UUID是随机的; 7. 主键为自增长时,不是NULL值,导致插入并非连续。 |
| 辅助索引 (secondary index) | 非主键键值顺序 存放主键 | 键值有序 (离散主键读完整数据) | 1. B+树决定非聚集索引的插入的离散性; 2. 每张表可以由多个辅助索引; 3. 读整行数据,则:顺序读辅助索引,再离散读聚集索引 4. 辅助索引有的时候比较顺序,如:时间字段。 |
四、索引管理
1. 索引分裂
MySQL大并发写时,B+树索引的页分裂并不总是从页的中间拆分,导致页空间的浪费。该问题解决,是通过InnoDB存储引擎的Page Header三个参数(用来保存插入的顺序信息)。这些信息,InnoDB存储引擎决定向左还是向右分裂,同时决定分裂点记录为哪一个。
- PAGE_LAST_INSERT:最后插入记录的位置
- PAGE_DIRECTION:最后插入记录的方向
- PAGE_N_DIRECTION:一个方向连续插入记录的数量
随机插入时,取页的中间记录作为分裂点的记录,与第二章节介绍的B+树插入操作相同。若大并发写的情况下,往同一方向插入记录数量大,如自增主键,则会有如下两种情况:
- 分裂点为当前待插入记录本身
- 分裂点为当前待插入记录的后续记录
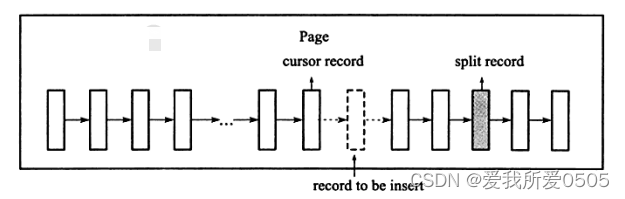
上如所示,InnoDB引擎插入记录时,首先需要定位,定位到的记录为待插入记录的前一条记录,cursor record为定位记录;record to be insert为当前待插入记录;split record为分裂点记录。


2. 快速创建辅助索引(FIC)
MySQL5.5之前创建和删除索引的过程如下,存在很大缺点:创建和删除索引需要很长时间;阻塞大量事务不能访问被修改的表。
- step1:创建临时表,定义新的表结构;
- step2:原表数据导入临时表;
- step3:删除原表;
- step4:临时表重命名原表的表名。
MySQL5.5开始支持快速创建辅助索引(Fast Index Creation _ FIC) ,InnoDB存储引擎对创建辅助索引的表加上S锁,无需重建表,但是大量写事务被阻塞。
- 创建辅助索引:表加S锁(无需重建表),但是写不可用(阻塞)
- 删除辅助索引:更新内部视图,并将索引空间标记为可用,同时删除该索引定义
3. 在线数据定义(Online DDL)
MySQL5.6开始支持在线数据定义(Online DDL),其允许创建辅助索引的同时,还可以进行INSERT、UPDATE、DELETE的DML操作。同时,也可以进行以下的DDL操作。与FIC的区别是:写事务不阻塞。
- 辅助索引的创建与删除
- 改变自增长值
- 添加和删除外键约束
- 列的重命名
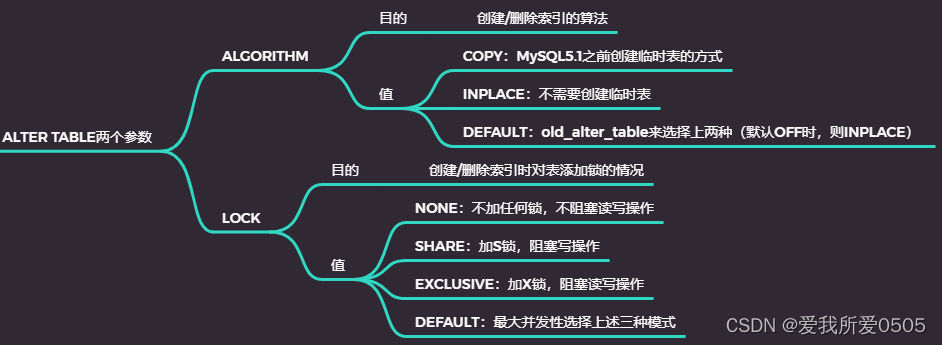
Online DDL实现原理是当创建或删除索引时,DML操作日志写入缓存,待完成后重做日志写入表上,保证了数据的一致性。由参数innodb_online_alter_log_max_size控制缓存大小,默认128MB。同时优化器不会使用正在创建或删除的索引。
下图是创建索引时,两个重要参数:ALGORITHM(创建/删除索引的算法)、LOCK(创建/删除索引时对表添加锁的情况)。
五、索引使用
1. 联合索引
联合索引是对多列进行索引,即:一颗B+树索引,键值的数量 >= 2,如:(a,b),先对a排序,再对b排序,如下所示。

若创建一个(a,b,c)联合索引,有效索引为(a)、(a,b)、(a,b,c);索引失效为(b)、(c)、(a,c)、(b,c)。索引失效原因是创建联合索引时,先根据a排序,再排序b,最后排序c。(b)、(c)、(b,c)都不是以a开头的查询,而(a,c)虽然以a开头,但是没有b而直接查询c,导致联合索引失效。
2. 覆盖索引
覆盖索引是从辅助索引直接获取结果,无需再去查询聚集索引获取完整数据内容。适用于查询主键或统计信息。EXPLAIN执行计划的列Extra为Using index来判定使用了覆盖索引。
如下查询所示,执行SQL,其中count(*)、查询主键值都使用覆盖索引。
#使用覆盖索引
select p.id from test_range_partition p where p.`name`='张三';
select count(*) from test_range_partition p where p.`name`='张三';
#未使用覆盖索引
select p.* from test_range_partition p where p.`name`='张三';
mysql> show create table test_range_partition\G;
*************************** 1. row ***************************Table: test_range_partition
Create Table: CREATE TABLE `test_range_partition` (`id` int(11) NOT NULL COMMENT '主键',`name` varchar(255) DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年龄',PRIMARY KEY (`id`),KEY `index_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
/*!50100 PARTITION BY RANGE (id)
(PARTITION p0 VALUES LESS THAN (10) ENGINE = InnoDB,PARTITION p1 VALUES LESS THAN (20) ENGINE = InnoDB,PARTITION p2 VALUES LESS THAN (30) ENGINE = InnoDB) */
1 row in set (0.00 sec)ERROR:
No query specifiedmysql> EXPLAIN select p.id from test_range_partition p where p.`name`='张三'\G;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: ppartitions: p0,p1,p2type: ref
possible_keys: index_namekey: index_namekey_len: 768ref: constrows: 1filtered: 100.00Extra: Using index
1 row in set, 1 warning (0.00 sec)ERROR:
No query specifiedmysql> EXPLAIN select p.* from test_range_partition p where p.`name`='张三'\G;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: ppartitions: p0,p1,p2type: ref
possible_keys: index_namekey: index_namekey_len: 768ref: constrows: 1filtered: 100.00Extra: NULL
1 row in set, 1 warning (0.00 sec)ERROR:
No query specifiedmysql> EXPLAIN select count(*) from test_range_partition p where p.`name`='张三'\G;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: ppartitions: p0,p1,p2type: ref
possible_keys: index_namekey: index_namekey_len: 768ref: constrows: 1filtered: 100.00Extra: Using index
1 row in set, 1 warning (0.00 sec)3. FORCE/USE INDEX
FORCE INDEX:强制使用指定索引;USE INDEX:告诉优化器使用指定索引,但优化器不一定选择该索引。
mysql> EXPLAIN select d.mgdb_id from t_activity_detail d where d.season_id='1100490203' AND d.mgdb_id like '12000018038%';
+----+-------------+-------+------------+-------+-----------------------+---------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-----------------------+---------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | d | NULL | range | PRIMARY,idx_season_id | idx_season_id | 517 | NULL | 7 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+-----------------------+---------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)mysql> EXPLAIN select d.mgdb_id from t_activity_detail d FORCE INDEX(PRIMARY) where d.season_id='1100490203' AND d.mgdb_id like '12000018038%';
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | range | PRIMARY | PRIMARY | 258 | NULL | 30 | 10.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> EXPLAIN select d.mgdb_id from t_activity_detail d USE INDEX(PRIMARY) where d.season_id='1100490203' AND d.mgdb_id like '12000018038%';
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | range | PRIMARY | PRIMARY | 258 | NULL | 30 | 10.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> EXPLAIN select d.mgdb_id from t_activity_detail d USE INDEX(idx_season_id) where d.season_id='1100490203' AND d.mgdb_id like '12000018038%';
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | d | NULL | range | idx_season_id | idx_season_id | 517 | NULL | 7 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)mysql> EXPLAIN select d.* from t_activity_detail d USE INDEX(PRIMARY) where d.mgdb_id like '%12000018038%';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 6596 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
4. 多范围读(MRR)
MySQL5.6开始支持在Muti-Range Read(MRR _ 多范围读),MRR优化目的是随机访问转为较为顺序的访问,减少磁盘访问次数。其实现原理为:
- step1:获取到辅助索引键值,存放到缓存,此时根据辅助索引键值顺序存放;
- step2:缓存中辅助索引键值根据主键(RowId)排序;
- step3:排序后主键访问聚集索引。
多值参数optimizer_switch控制是否启用MRR优化,其中mrr=on时,则MRR开启,mrr_cost_based则通过cost_based方式使用mrr。如果mrr=on且mrr_cost_based=off,则表示总是启用MRR。
参数read_rnd_buffer_size控制键值缓存区的大小,默认256KB。若实际大小 > 该值时,则执行器对已经缓存的数据根据rowId排序,并通过rowId获取数据。
mysql> show variables like 'optimizer_switch'\G;
*************************** 1. row ***************************
Variable_name: optimizer_switchValue: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on
1 row in set (0.02 sec)ERROR:
No query specifiedmysql> show variables like 'read_rnd_buffer_size'\G;
*************************** 1. row ***************************
Variable_name: read_rnd_buffer_sizeValue: 262144
1 row in set (0.00 sec)
MRR适用于range、ref、eq_ref的查询类型。range查找时,MRR将范围查找,拆分为键值对,进行批量查询。MRR查询的优点:
- 主键顺序查找,重复性降低,提升效率
- 减少缓冲池中页被替换的次数
- 批量处理对键值的查询
5. 索引条件下推(ICP)
MySQL5.6开始支持在Index Condition Pushdown(ICP _ 索引条件下推),取出索引的同时,进行WHERE条件的过滤,即:WHERE部分过滤条件放在存储引擎层。MySQL5.6之前不支持ICP,则根据索引获取记录,再进行WHERE条件的过滤。
ICP的优点,在某些查询下,大大减少上层SQL对记录的索取,从而提高数据库的整体性能。通过测试,MySQL5.6 with ICP比MySQL5.5版本提高23%;MySQL5.6 with ICP & MRR时,提高了400%。通过EXPLAIN执行计划的列Extra为Using index condition来判定使用了ICP优化。
ICP适用于range、ref、eq_ref、ref_or_null的查询类型。如下所示,看出可能使用的索引(possible_keys)有:idx_end_time,idx_start_time,idx_endtime_starttime,但优化器最终使用了key为idx_end_time的索引。列Extra有Using index condition,则表示使用ICP优化。
mysql> EXPLAIN select d.* from t_activity_detail d where (d.start_time BETWEEN '2021-09-01' AND '2021-09-30') AND (d.end_time BETWEEN '2021-09-15' AND '2021-09-30')\G;
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: dpartitions: NULLtype: range
possible_keys: idx_end_time,idx_start_time,idx_endtime_starttimekey: idx_end_timekey_len: 6ref: NULLrows: 797filtered: 18.72Extra: Using index condition; Using where
1 row in set, 1 warning (0.00 sec)
六、Cardinality值
1. SHOW INDEX FROM命令
SHOW INDEX FROM命令查看表的索引信息,若下表所示,每列的含义。
SHOW INDEX FROM t_activity_detail;
| 列名 | 描述 |
| Table | 索引所在的表 |
| Non_unique | 1. 非唯一索引; 2. 主键索引primary key是0,其他1。 |
| Key_name | 索引名称 |
| Seq_in_index | 1. 索引中该列的位置; 2. 查看联合索引,比较直观。 |
| Column_name | 索引列的名称 |
| Collation | 1. 排序规则:列以什么方式存储在索引中; 2. B+树索引,Collation总是A;若是Hash索引,则为null。 |
| Cardinality | 1. Cardinality值表示索引中不重复的记录数量(动态统计); 2. 作用:优化器根据Cardinality值判断是否使用该索引; 3. Cardinality值是动态统计的结果,不是一个精确值; 4. ANALYZE TABLE命令可以更新该值。 |
| Sub_part | 1. 是否是列的部分字符被索引; 2. 若是索引整个列,则该值为null; 示例值是100,则表示列的前100个字符被索引。 |
| Packed | 是否被压缩,没有则为null |
| Null | 1. 索引的列是否含有NULL值; 2. Yes:表示索引的列可以为NULL。 |
| Index_type | 1. 索引类型; 2. B+树索引,则为BTREE。 |
| Comment | 注释 |
| Index_comment | 索引注释 |
mysql> SHOW INDEX FROM t_activity_detail;
+-------------------+------------+-----------------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+---------+----------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------------------+------------+-----------------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+---------+----------------+
| t_activity_detail | 0 | PRIMARY | 1 | mgdb_id | A | 6596 | NULL | NULL | | BTREE | | |
| t_activity_detail | 1 | idx_game_id2 | 1 | game_id | A | 1990 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_game_id2 | 2 | language | A | 5939 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_end_time | 1 | end_time | A | 1812 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_start_time | 1 | start_time | A | 1563 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_match_start_time | 1 | match_start_time | A | 1532 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_stadium_id | 1 | stadium_id | A | 1 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_endtime_starttime | 1 | end_time | A | 1812 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_endtime_starttime | 2 | start_time | A | 1836 | NULL | NULL | YES | BTREE | | |
| t_activity_detail | 1 | idx_season_id | 1 | season_id | A | 413 | NULL | NULL | YES | BTREE | | 赛季ID索引 |
+-------------------+------------+-----------------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+---------+----------------+
10 rows in set (0.00 sec)
2. Cardinality值
B+树索引的适用条件是高选择性且取少量数据。某个字段值范围广,几乎没有重复,属于高选择性;如性别、类型、地区字段等,取值范围小,属于低选择性。
那么怎样查看索引是否是高选择性呢?可以通过SHOW INDEX FROM命令中的列Cardinality来观察。Cardinality值非常关键,表示索引中不重复记录数量的预估值。优化器会根据该值判断是否使用该索引。
InnoDB存储引擎中,Cardinality值是动态统计的结果,其统计发生在INSERT和UPDATE两操作。默认随机对8个叶子节点进行采样,由参数innodb_stats_sample_pages控制每次采样统计的页数,默认8。
下图所示,触发Cardinality值更新条件,分为手动、自动触发。

下表所示, Cardinality值统计的相关参数。
| 参数 | 描述 |
| innodb_stats_sample_pages | Cardinality的每次采样统计的页数,默认8页 |
| innodb_stats_method | 1. Cardinality采样统计对Null的处理; 2. 值:默认nulls_equal(NULL值作为相同记录)、 nulls_unequal(NULL值作为不同记录)、 nulls_ignored(忽略NULL) |
| innodb_stats_persistent | 1. analyze table触发Cardinality统计时,其值是否存入磁盘; 2. 默认ON(减少重新计算每个索引的Cardinality值) |
| innodb_stats_on_metadata | show table status、show index、访问information_schema下的TABLES和STATISTICS时,是否开启Cardinality统计,默认OFF |
| innodb_stats_persistent_ sample_pages | innodb_stats_persistent为ON时,使用analyze table每次采样统计的页数,默认20 |
| innodb_stats_transient_ sample_pages | 代替innodb_stats_sample_pages参数,默认8页 |
七、参考资料
B+ Tree Visualization
mysql中的B+树索引_sinat_32176267的博客-CSDN博客_b+树索引
深入解析mysql中的索引(原理详解)-mysql教程-PHP中文网
InnoDB数据页结构示例_爱我所爱0505的博客-CSDN博客
https://www.jb51.net/article/196415.htm
MySQL 执行计划中Extra的浅析_深圳steven的博客-CSDN博客_mysql执行计划extra

![UVA 10271 佳佳的筷子 Chopsticks [DP的基本运用]](https://img-blog.csdnimg.cn/img_convert/1c4e21dca611d56860841bb26789149d.png)








![[模拟][模电][面试][运放]仪表放大器](https://img-blog.csdnimg.cn/0b55cde3caea4201b0636c3f7d67570e.jpeg)