目录
一.引言
二.摘要 ABSTRACT
三.介绍 INTRODUCTION
1.CTR 在广告系统的作用
2.传统 MLP 存在的问题
3.DIN 的改进
四.近期工作 RELATEDWORK
1.传统推荐算法
2.用户行为抽取
五.背景 BACKGROUD
六.深度兴趣网络 DEEP INTEREST NETWORK
1.特征表示 Feature Representation
2.基线模型 Base Model - Embedding & MLP
3.DIN 模型结构 The structure of Deep Interest Network
七.训练技巧 TRAINING TECHNIQUES
1.小批量感知正则化 Mini-batch Aware Regularization
2.数据自适应激活函数 Data Adaptive Activation Function
8.实验 EXPERIMENTS
8.1 数据集和实验设置 Datasets and Experimental Setup
8.2 对照组 Competitors
8.3 统计指标 Metrics
8.4 模型比较结果 Result from model comparison
8.5 正则化的性能 Performance of regularization
8.6 阿里巴巴实践结果 model comparison on Alibaba Dataset
8.7 DIN 可视化 Visualization of DIN
九.总结
一.引言
DIN (Deep Interest Network) 是阿里巴巴提出的深度兴趣模型,DIN 引入用户兴趣序列,用加权平均代替传统的平均方式,相当于引入了 Attention,充分利用用户历史数据提高 CTR 预估能力。下面对论文做简要回顾。
二.摘要 ABSTRACT
点击率预测是工业应用中的一项重要任务,例如在线广告。
• 传统方法
传统深度学习深度模型遵循类似的 Embedding & MLP范式。该方法通过 Embedding 将大规模稀疏特征转换为低维嵌入向量,再通过 MLP 学习特征之间的非线性关系。该模式下用户特征被压缩到一个固定长度的表示向量中,而不管候选广告是什么。固定长度向量的使用将是一个瓶颈,这给嵌入和 MLP 方法从丰富的历史行为中有效捕捉用户的不同兴趣带来了困难。
• DIN
深度兴趣网络(DIN) 通过设计一个本地激活单元来自适应地学习用户兴趣的表现,从历史行为中学习与特定广告有关的信息。不同的候选广告下用户的表示向量也有所差异,从而大大提高模型的表达能力。
• 其他创新
除了本地激活单元学习兴趣表现外,论文还针对模型训练引入了小批量感知正则化和数据自适应激活函数,可以帮助训练具有数亿个参数的工业深度网络。
• 模型验证
在两个公共数据集与阿里巴巴真实生产环境下证明了模型的有效性,与当时的先进方法相比 DIN 能够提供更好的性能并已成功部署到阿里巴巴在线广告展示系统中。
三.介绍 INTRODUCTION
先了解几个广告系统的常见概念:
CPC (cost-per-click) 每次广告点击的成本
CTR (click-through rate) 预估点击率
eCPM (effective cost per mille) 每 1000 次展示的广告收入
1.CTR 在广告系统的作用
在阿里巴巴电商场景下,广告的表现与 CTR 息息相关。广告是根据 eCPM (effective cost per mille) 进行排名的,eCPM 是投标价格和 CTR (click-through rate) 的乘积,CTR 由模型预估。
eCPM = 收入 / 展示次数 x 1000
收入 = 广告单价 x CTR x 展示次数
将收入带入 eCPM 的公式可以抵消掉展示次数,得到:
eCPM = 广告单价 x CTR x 1000
即该指标与网页展示次数无关,正比于广告单价和广告的点击率,这个其实也很符合我们的直观映像,单价高或者点击频繁都会增加广告收入。除了广告竞价,模型 CTR 预测的效果将直接影响最终的收益。
2.传统 MLP 存在的问题
传统 Embedding & MLP 模式下,只能用有限维度的向量表征用户兴趣,而用户的兴趣是多样性的,为了提高多兴趣表达能力需要对定长 Embedding 进行大量扩展,这将扩大模型参数的数量并在有限的数据下加剧过拟合的风险。此外它增加了计算与存储的负担,在工业在线系统中也是需要权衡的因素。另一方面,在预测候选广告时,没有必要将用户的历史行为平均池化压缩到同一个向量中,因为只有部分商品会影响用户当前的决策。
3.DIN 的改进

• 局部激活单元
DIN 通过引入局部激活单元,通过对历史行为的相关部分进行软搜索,关注相关用户兴趣,并采用加权和池化的方法,得到用户兴趣与候选广告相关的表示。与候选广告相关性越高的行为会获得更高的激活权重,并主导用户兴趣的表现。上图中加权的系数 α 就是通过局部激活单元计算得出。
• MiniBatch 感知正则
同时基于 SGD 的优化方法只更新每个小批中出现的稀疏特征的参数,然而,加上传统的 l2 正则化,计算变得不可接受,这需要为每个小批计算整个参数的 l2 范数。DIN 开发了一种新的小批量感知正则化,其中只有在每个小批量中出现的非零特征参数参与l2范数的计算,使计算可以接受。
• Dice 激活
此外,DIN 还设计了一个数据自适应激活函数 Dice,该函数通过考虑输入分布来推广 PReLU,并被证明有助于训练具有稀疏特征的工业网络。
四.近期工作 RELATEDWORK
1.传统推荐算法
DIN 发布于 2017 年,当时 CTR 预测模型处在结构由浅向深度的发展过程中,同时更注重模型结构的涉及。最早的 LS-PLM 和 FM 模型可以看作是一类只包含一个隐藏层的网络,该网络首先在稀疏输入上使用嵌入层,然后通过特别设计的变换函数进行目标拟合,目的是捕捉特征之间的组合关系。Deep Crossing、Wide&Deep Learning 和 YouTube CTR模型对 LS-PLM 和 FM 进行了扩展,将变换函数替换为复杂的 MLP 网络,极大地增强了模型的能力。除此之外 PNN 试图通过嵌入层之后的产品层来捕获高阶特征交互。DeepFM 在 wide&deep 中引入了一个分解机作为 "wide" 模块。总的来说,这些方法遵循了 Embedding + MLP 的基础结构。
2.用户行为抽取
在用户行为丰富的应用程序中,特征通常包含有可变长度的 id 列表,例如在 YouTube 推荐系统中搜索的关键词或观看的视频。上述模型通常通过求和 / 平均池化将相应的嵌入向量列表转换为固定长度的向量,这造成了信息的丢失。DIN 通过自适应学习给定 ad 的表示向量,提高了模型的表达能力。这里 Attention 注意力机制起源于神经机器翻译 (NMT) 领域。NMT对所有注释进行加权和以获得期望的注释,并且只关注与下一个目标词的生成相关的信息。最近的一项工作,DeepIntent 在搜索广告的背景下应用了注意力。下图为 NMT 的 Attention 形式:

DIN 设计了一个局部激活单元来软搜索相关的用户行为,并采用加权和池来获得用户兴趣相对于给定广告的自适应表示,该方法被证明有助于捕捉查询或广告的主要意图。
五.背景 BACKGROUD
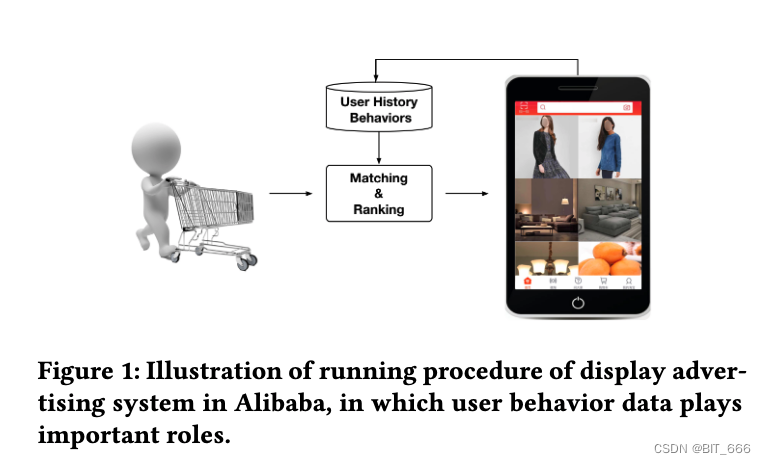
上图演示了阿里巴巴展示广告系统的运行过程,其中用户行为数据起着重要作用。该阶段主要包含两个主要阶段:
• 匹配阶段 Matching
通过协同过滤等方法生成与访问用户相关的候选广告列表
• 排序阶段 Ranking
预测每个给定广告的点击率,随后选择排名靠前的广告商品
每天,数以亿计的用户访问电子商务网站并留下了大量的用户行为数据,这些数据对建立匹配和排名模型至关重要。值得一提的是,具有丰富历史行为的用户包含了多样化的兴趣。
例如,一位年轻的母亲最近浏览了羊毛大衣、T恤、耳环、手提袋、皮包和儿童大衣等商品。这些行为数据提示我们她的购物兴趣。当她访问电子商务网站时,系统会向她显示合适的广告,例如一个新手袋。显然,显示的广告只匹配或激活了这位母亲的部分兴趣。总之,具有丰富行为的用户的兴趣是多种多样的,并且可以在特定的广告下局部激活。我们将在本文后面展示利用这些特征对于构建CTR预测模型起着重要作用。
Tips:
DIN 适用于用户包含丰富历史行为的场景,冷启动用户或行为稀疏行为用户效果不明显。
六.深度兴趣网络 DEEP INTEREST NETWORK
与赞助搜索不同,用户进入显示广告系统时没有明确表达意图。在建立点击率预测模型时,需要有效的方法从丰富的历史行为中提取用户兴趣,描述用户和广告的特征是广告系统点击率建模的基本要素,合理利用这些特征并从中挖掘信息是至关重要的。
1.特征表示 Feature Representation
工业CTR预测任务中的数据多为多组分类形式,如:
[weekday=Friday, gender=Female, visited _cate_ ids={Bag,Book}, ad_cate_ id=Book]
针对分类特征常见处理方法为处理为稀疏的 one-hot 和 multi-hot 形式:

阿里巴巴广告系统中使用的整个特征集如下图所示。它由四个类别组成,其中用户行为特征是典型的 multi-hot 向量,包含丰富的用户兴趣信息。注意,在我们的设置中,没有组合特性。我们用深度神经网络捕捉特征的相互作用。

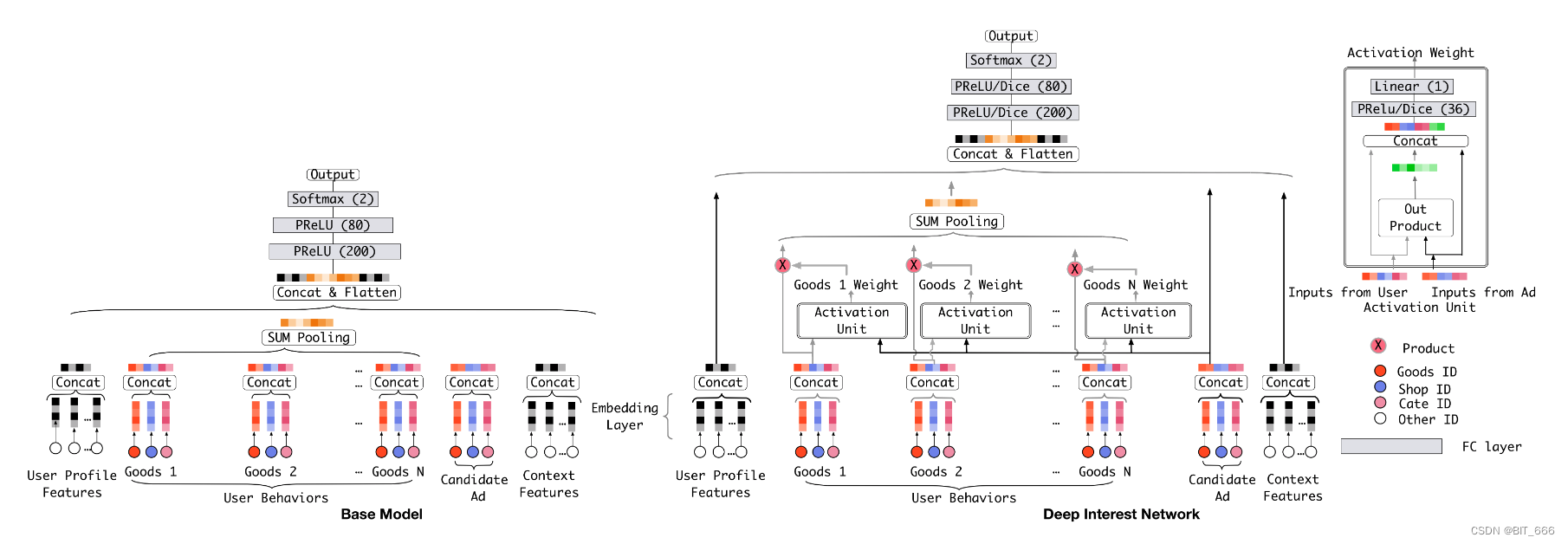
2.基线模型 Base Model - Embedding & MLP
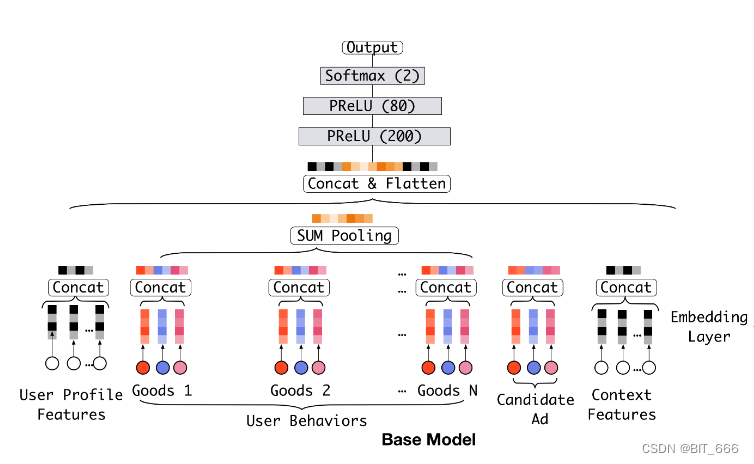
大多数流行推荐模型都遵循 Embedding & MLP 的范式,我们称其为基线模型。它由几个部分组成:
• Embedding Layer
低维输入为 one-hot、multi-hot 的稀疏形式,通过 Embedding 层转换为稠密输入
• Pooling layer and Concat layer
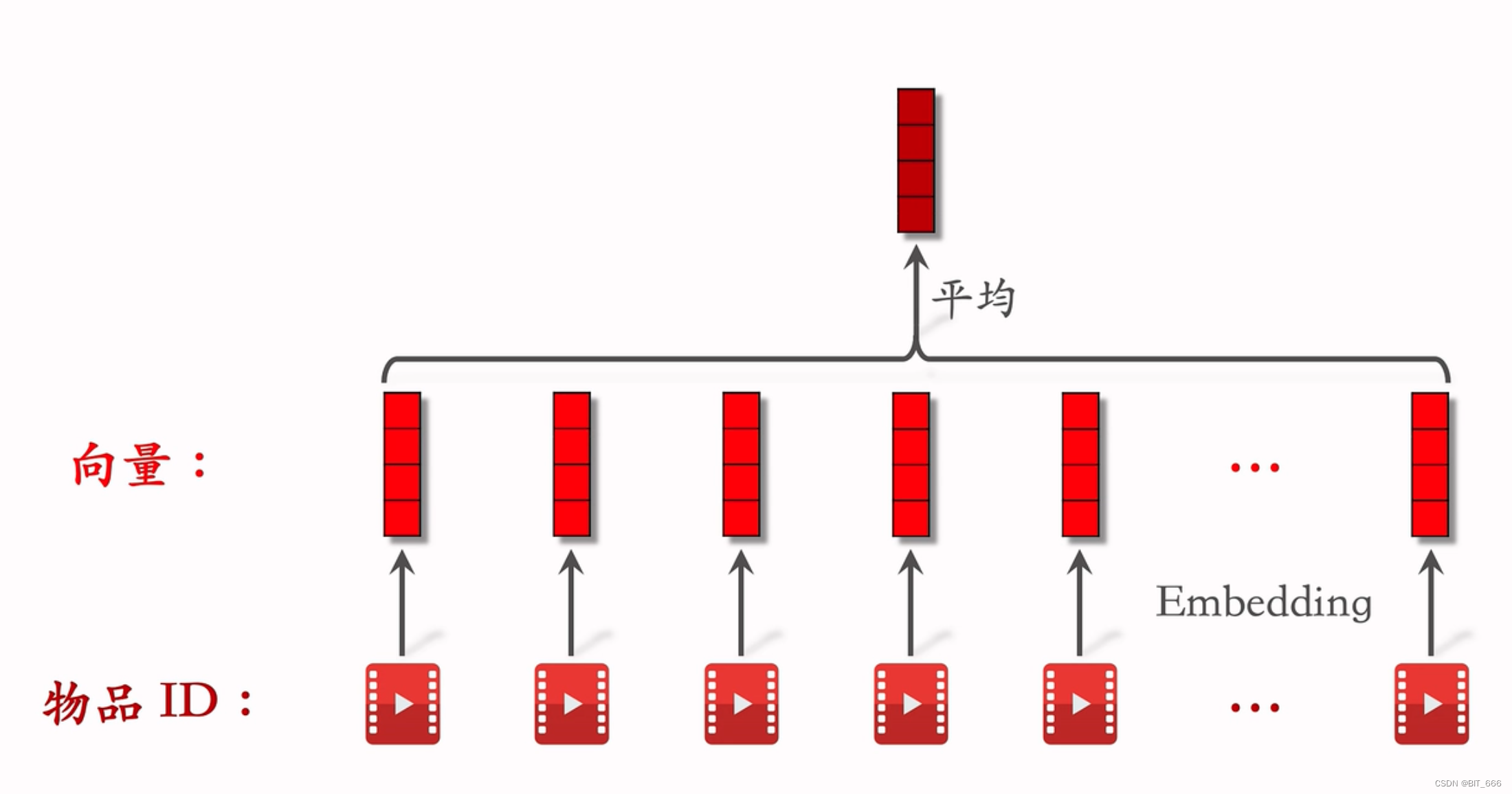
池化层与连接层。不同用户拥有不同数量的历史行为,所以 mulit-hot 向量不同用户的非零值数量也有所不同,这将导致相应的嵌入向量长度不同。由于全连接层网络只能处理固定长度的嵌入,需要做数据预处理对原始用户行为进行补充或截断从而保持相同的长度。两个最常用的池化层是 sum pooling 和 mean pooling,它们对嵌入向量列表应用逐元素求和 、平均操作。嵌入层和池化层都以分组方式操作,将原始稀疏特征映射到多个固定长度的表示向量中。然后将所有向量连接在一起,以获得实例的总体表示向量。
• MLP
给定级联的密集表示向量,使用全连接层自动学习特征的组合。
• Loss
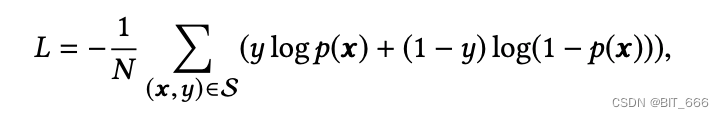
基模型的目标函数为负对数似然函数。其中 S 为规模为 N 的训练集,x 为网络的输入,y ∈ {0,1} 为标签,p(x) 为经过 softmax 层后网络的输出,表示样本 x 被点击的预测概率。
3.DIN 模型结构 The structure of Deep Interest Network
推荐系统中,用户特征毋庸置疑是最重要的特征。

• 定长向量
Base Model 通过 sum-pooling 或者 mean-pooling 对用户行为向量池化得到固定的用户兴趣表征,无论候选集广告是什么,该向量表征都是固定的。这样,维度有限的用户表示向量将成为表达用户多样化兴趣的瓶颈。为了使其足够强大,一个简单的方法是扩大嵌入向量的维数,不幸的是,这将大大增加学习参数的大小。在有限条件下会导致过拟合训练数据并增加计算和存储的负担,这对于工业在线系统来说可能是无法容忍的。
• DIN 向量
实际场景下,与显示广告相关的行为对点击行为有很大的贡献。DIN通过关注给定广告中局部激活利益的表示来模拟这一过程。例如用户最近历史行为中存在电脑主板行为,则他更有可能喜欢推荐的显卡。DIN 通过对用户历史行为进行软搜索,发现与当前商品更匹配的历史行为,并增加其在用户向量表征的权重。该方法可以自适应地计算用户兴趣的表示向量,而不是用同一个向量表示所有用户的不同兴趣。
• 局部激活单元
上图的 Activate Unit 为激活单元。激活单元应用于用户行为特征,作为加权和池来自适应计算给定候选的用户向量:

其中 {e1, e2,…, eH} 为用户 U 的行为嵌入向量列表,长度为 H,Va 为商品 Embedding:
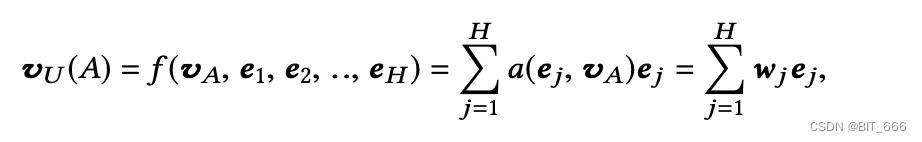
基于该计算公式,相同用户针对不同商品时 vU(A) 表征向量是不同的,其中 a(·) 是一个前馈网络,其输出为激活权值。除了使用历史行为向量 ei 和 Va 商品向量作为输入外,还可以通过元素 +、元素-、元素乘积等一系列交互方式引入更多显式知识协助建模从而得到更精确的激活权值。
• 归一化
上面提到的 Activate Unit 与 NMT 任务重的 Attention 方法具有相同思想,但与传统 Attention 不同的是,DIN 在上述 vU(A) 的计算时,对 ∑w = 1 的约束进行放松,目的是保留用户兴趣的强度。即不使用 softmax 对 a(·) 得到的激活权重进行归一化。文章认为 w 在某种程度上可以视为激活用户兴趣强度的近似值。
例如,如果一个用户的历史行为包含 90% 的服装和 10% 的电子产品。给定 T 恤和手机两个候选广告,T 恤激活了大部分属于衣服的历史行为,并且可能比手机获得更大的 vU 值(更高的兴趣强度)。
• LSTM
我们尝试 LSTM 以顺序的方式对用户历史行为数据建模。但它没有显示出任何改善。与 NLP 任务中文本受语法约束不同,用户历史行为序列可能包含多个并发兴趣。这些兴趣的快速跳跃和突然结束使得用户行为的序列数据显得很嘈杂。一个可能的方向是设计特殊的结构,以序列的方式对这些数据进行建模。我们把它留给未来的研究。
这里其实就是后面阿里提出的 DIEN,其通过获取循环神经网络的状态 h(t) 并刻画用户兴趣转移的概率,后面有机会我们介绍 DIEN。
七.训练技巧 TRAINING TECHNIQUES
在阿里巴巴的广告系统中,商品数量和用户规模高达数亿。在实际应用中,训练具有大规模稀疏输入特征的工业深度网络具有很大的挑战性。本节将介绍两个重要的技术,它们在实践中被证明是有用的。
1.小批量感知正则化 Mini-batch Aware Regularization
过拟合是训练工业网络的一个关键挑战。例如,加入细粒度特征,如 6 亿维的 goods_ids 特征在没有正则化的情况下,在训练的第一个epoch之后,模型性能迅速下降,如下图所示的深绿色线:
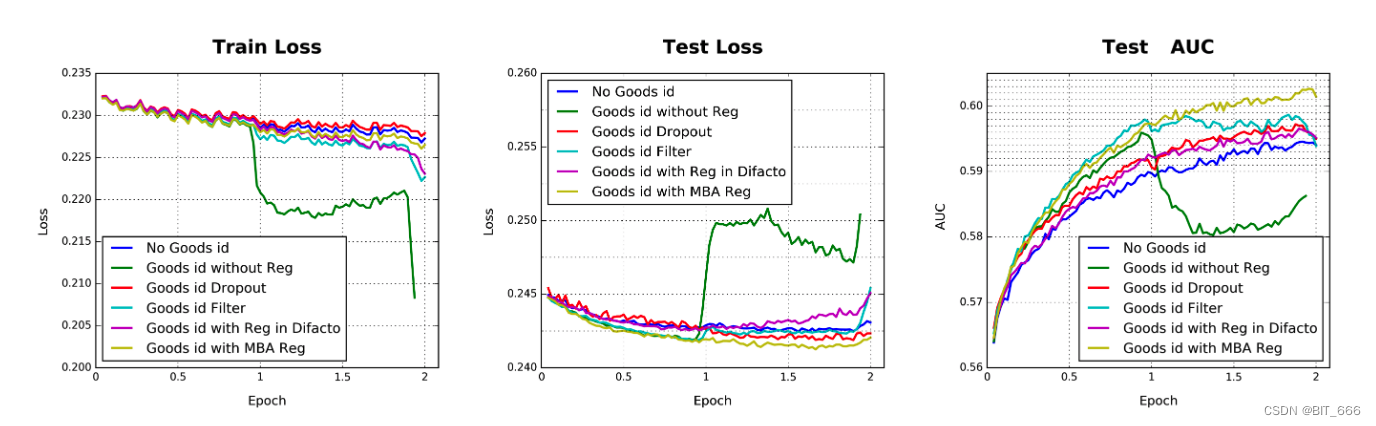
在具有稀疏输入和数亿个参数的训练网络上,直接应用传统的正则化方法 (L1、L2) 是不现实的。以 L2 正则化为例。在不正则化的基于 SGD 的优化方法中,只需要更新每个小批中出现的非零稀疏特征的参数。然而,当加入 L2 正则化时,它需要计算每个小批的整个参数的 L2 范数,这会导致极其繁重的计算,并且对于参数缩放到数亿是不可接受的。
本文提出了一种高效的小批感知正则化器,该正则化器只计算每个小批中出现的稀疏特征参数的 L2 范数,使计算成为可能。实际上,在 CTR 网络中,大部分参数都是由嵌入 Embedding 提供的,而且计算量大。设 W ∈ R[D×K] 为整个嵌入字典的参数,D 为嵌入向量的维数,K 为特征空间的维数。L2 正则化公式如下:

其中 wj ∈ R[D] 是第 j 个嵌入向量,I(xj, 0) 表示实例 x 是否具有特征 id j, nj 表示特征 id j 在所有样本中出现的次数。上式可以通过小批量感知的方式转化为下式:
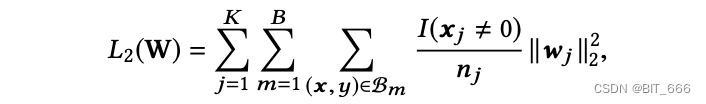
其中 B 为小批数量,Bm 为第 m 个小批。设:
![]()
表示在小批量 Bm 中是否至少有一个实例具有特征 id j。上式可近似为:
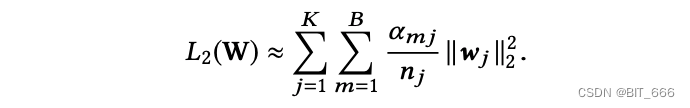
通过这种方式,我们得到了 L2 正则化的一个近似的迷你批处理感知版本。对于第 m 个小 Batch,梯度 w.r.t. 特征 j 的嵌入权值为:

其中只有出现在第 m 个小 Batch 中的特征参数参与正则化计算。
2.数据自适应激活函数 Data Adaptive Activation Function
PReLU 是常见的激活函数,其形式如下:

其中 s 是激活函数 f(·) 输入的一维,p(s) = I(s > 0) 是控制 f(s) 在 f(s) = s 和 f(s) = αs 两个通道之间切换的指示函数。第二个通道中的 α 是一个学习参数。这里我们用 p(s) 作为控制函数。

上图左侧为 PReLU 的控制函数。PReLU 取一个 hard rectified point,其值为 0,当每层输入的分布不同时,这种方法可能不适合。考虑到这一点,我们设计了一种新的数据自适应激活函数 Dice:
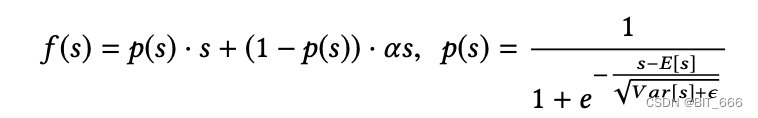
Dice 的控制函数在上图右侧。在训练阶段中,E[s] 和 Var[s] 是每个小批量输入的均值和方差。在测试阶段,E[s] 和 Var[s] 是通过数据上的移动平均 E[s] 和 Var[s] 来计算的。ε 是一个很小的常数,在我们的实践中设置为10−8。
Dice 可以看作是 PReLu 的推广。Dice 的核心思想是根据输入数据的分布自适应调整 rectified point,其值设为输入的平均值。此外,Dice 可以在两个通道之间平稳的切换。当 E(s) = 0, Var[s] = 0时,Dice 退化为 PReLU。
8.实验 EXPERIMENTS
本节将详细介绍模型实验结果,包括数据集、评估指标、实验设置、模型比较和相应的分析。在阿里巴巴展示广告系统收集的两个用户行为公共数据集和数据集上的实验表明,该方法在CTR预测任务中优于最先进的方法。
8.1 数据集和实验设置 Datasets and Experimental Setup
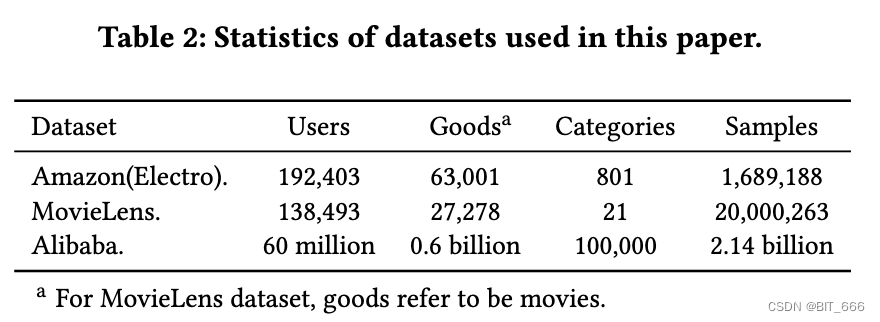
• Amazon Dataset
亚马逊数据集包含亚马逊产品评论和元数据,用作基准数据集。这里使用名为 Electronics 的子集进行了实验,其中包含 192403 个用户、63001 个商品、801 个类别和 1689188 个样本。该数据集中的用户行为丰富,每个用户和商品的评论超过 5。特征包含 goods_id, cate_id, user reviewed goods_id_list 与 cate_id_list。设用户的所有行为为 (b1, b2,., bk , ... , bn ),任务是利用前 k 个评论商品来预测第 (k+1) 个评论商品。训练集用到的数据为 k=1、2、...、n-2。测试集使用前 n-1 个评论的商品预测第 n 个商品。对于所有模型,我们使用 SGD 作为指数衰减的优化器,其中学习率从 1 开始,衰减率设置为 0.1。小批量大小设置为 32。
• MovieLens Dataset
MovieLens 数据包含 138493 个用户、2778 部电影、21 个类别和 20000263 个样本。为了使其适用于 CTR 预测任务,我们将其转换为二进制分类数据。电影的原始用户评分是连续值,范围从 0到 5。我们将评分为 4 和 5 的样本标记为 Positive,其余为 Negative。我们根据 userID 将数据分割成训练和测试数据集。在所有 138493 个用户中,随机选择 100000 个作为训练集 (约 14470000 个样本),其余 38493 个作为测试集 (约 5530000 个样本)。该任务是根据历史行为预测用户是否会对给定电影进行评分以高于 3 (正标签)。特征包括 movie_id、movie_cate_id 和用户评分的 movie_id_list、movie_cate_id_list 并使用与 Amazon 数据集中描述的相同的优化器、学习率和小批量大小。
• Alibaba Dataset
我们从阿里巴巴的在线展示广告系统中收集了流量日志,其中两周的样本用于训练,第二天的样本用于测试。训练集和测试集的大小分别约为 20 亿和 1.4 亿。对于所有深度模型,整个 16 组特征的嵌入向量维度为 12。MLP层设置为192 × 200 × 80 × 2。由于数据量巨大,我们将小批量设置为5000,并使用 Adam 作为优化器。我们应用指数衰减,其中学习率从 0.001 开始,衰减率设置为 0.9。相比亚马逊与电影数据集,阿里巴巴的数据具有更大挑战。
8.2 对照组 Competitors
• LR
浅层模型,将其视为弱 Baseline
• BaseModel
遵循 Embedding & MLP 架构,作为我们模型比较的强大 Baseline
• Wide&Deep
结合浅层与深层模型
• PNN
BaseModel 的改进版本,通过在嵌入层之后引入乘积层来捕获高阶特征交互。
• DeepFM
增加了 Wide&Deep 的特征交叉能力
8.3 统计指标 Metrics
在 CTR 预测领域,AUC 是一个广泛使用的指标。它通过使用预测的 CTR 对所有广告进行排名来衡量订单的好坏,包括用户内和用户间 order。这里引入了用户加权 AUC 的一种变体,它通过平均用户 AUC 来衡量用户内订单的好坏,并且被证明与显示广告系统中的在线性能更相关。我们在实验中调整了这个指标。为简单起见,我们仍然将其称为 AUC。计算如下:
![]()
其中 n 是用户的数量,#impressioni 和 AUCi 是第 i 个用户对应的 impression 和 AUC 的数量。此外,我们引入 RelaImpr 指标来衡量对模型的相对改进。对于随机猜测器,AUC 值为 0.5。因此 RelaImpr 定义如下:
![]()
8.4 模型比较结果 Result from model comparison
Amazon 数据集和 MovieLens 数据集上的模型比较。所有行分别通过比较每个数据集上的 BaseModel 来计算 RelaImpr:
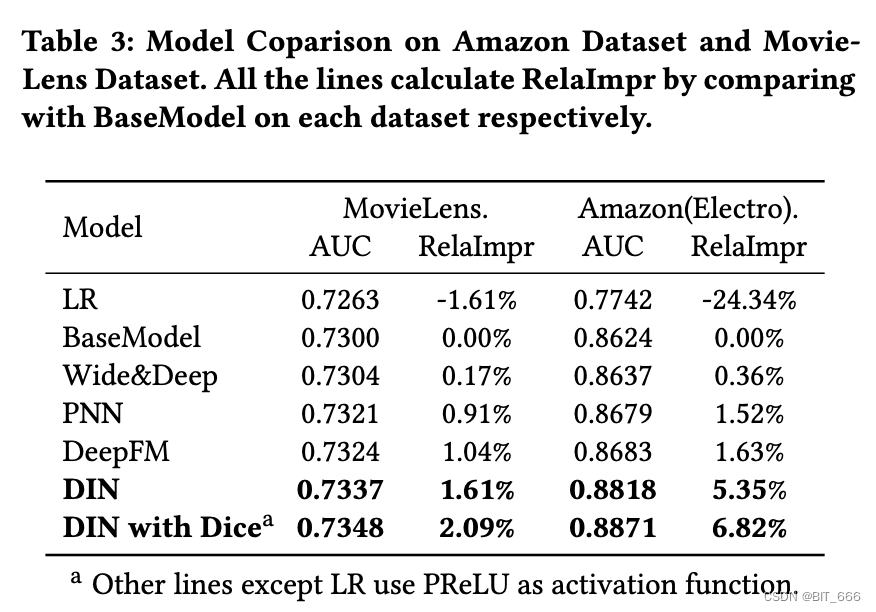
上图显示了 Amazon 数据集和 MovieLens 数据集的结果。所有实验重复 5 次并报告平均结果。随机初始化对 AUC 的影响小于 0.0002。显然,所有深度网络都显着击败了 LR 模型,这确实证明了深度学习的力量。具有专门设计的结构的 PNN 和 DeepFM 比 Wide&Deep 表现更好。DIN 在所有竞争对手中表现最好。特别是在具有丰富用户行为的亚马逊数据集上,DIN 显着突出。我们认为这是DIN中局部激活单元结构的设计。DIN 通过软搜索与候选广告相关的用户行为部分来关注局部相关的用户兴趣。通过这种机制,DIN 获得了用户兴趣的自适应变化表示,与其他深度网络相比,大大提高了模型的表达能力。此外,带有 Dice 的 DIN 比 DIN 带来了进一步的改进,这验证了所提出的数据自适应激活函数 Dice 的有效性。
8.5 正则化的性能 Performance of regularization
由于亚马逊数据集和 MovieLens 数据集中特征的维度都不高 (约 1000 万),因此包括我们提出的 DIN 在内的所有深度模型都不符合过度拟合的严重问题。然而,当涉及到包含更高维稀疏特征的在线广告系统的阿里巴巴数据集时,过度拟合会成为一个很大的挑战。例如,当使用细粒度特征训练深度模型时 (例如 0.6 亿个的 goods_ids 的特征),在第一个 epoch 后会出现严重的过拟合,没有任何正则化,导致模型性能迅速下降,如下图深绿色线:
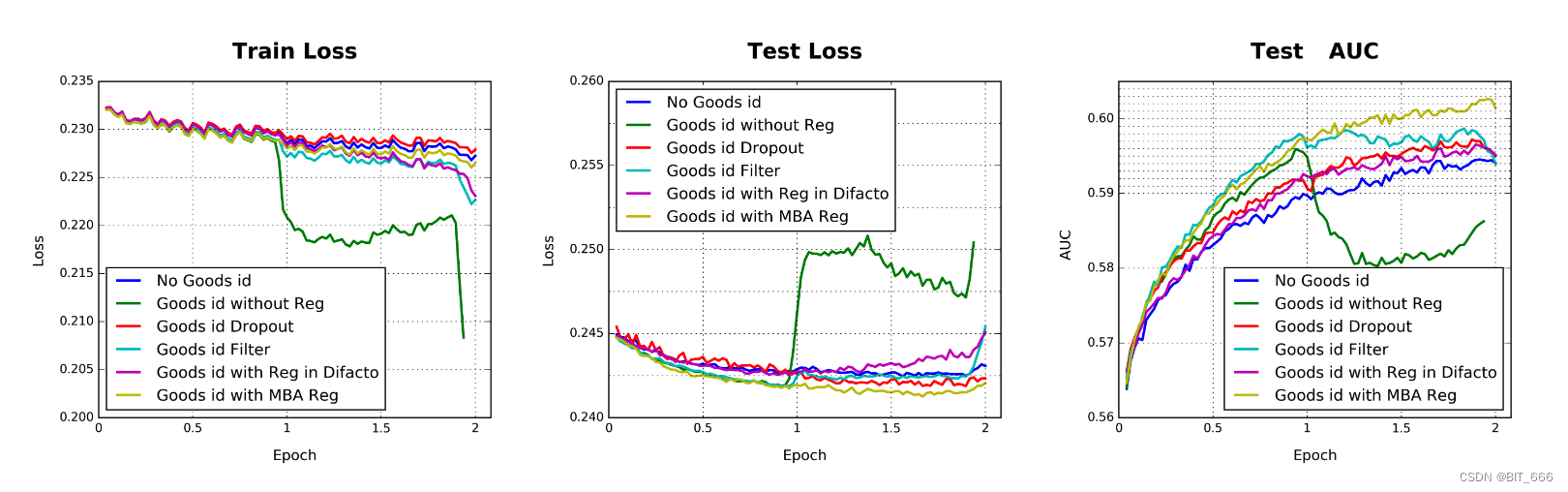
• Dropout
随机丢弃每个样本中 50% 的特征 id。
• Filter
过滤器通过样本中出现频率访问 goods_id,只保留最频繁的。在我们的设置中,剩下 2000 万个 goods_id。
• Regularization in DiFacto
与频繁特征相关的参数较少过度正则化。
• MBA
小批量感知正则化方法。DiFacto 和 MBA 的正则化参数 λ 均设置为 0.01。
不同正则化模型效果如下:

8.6 阿里巴巴实践结果 model comparison on Alibaba Dataset
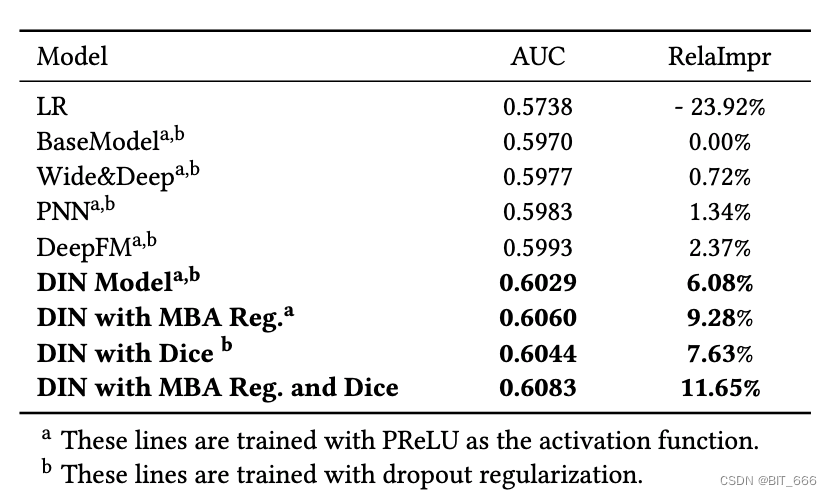
DIN 与 MBA 正则化和 Dice 实现了 BaseModel 的总 11.65% RelaImpr 和 0.0113 的绝对 AUC 增益。即使与在该数据集上表现最佳的竞争对手 DeepFM 相比,DIN 仍然实现了 0.009 的绝对 AUC 增益。值得注意的是,在拥有数亿流量的商业广告系统中,0.001的绝对 AUC 增益是显著的,值得经验地进行模型部署。DIN 显示出更好地理解和利用用户行为数据特征的巨大潜力。此外,这两种技术进一步提高了模型的性能,并为训练大规模工业深度网络提供了强大的帮助。
8.7 DIN 可视化 Visualization of DIN
论文最后进行案例研究,以揭示 DIN 在阿里巴巴数据集上的内部结构。
• Activation Unit 有效性
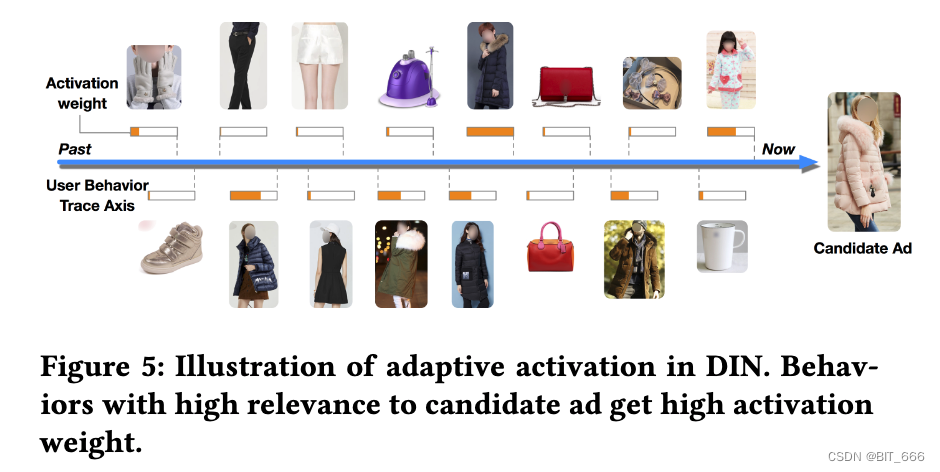
上图展示了用户行为相对于候选广告的激活强度,正如预期的那样,与候选广告高度相关的行为被加权很高。
• 嵌入向量可视化
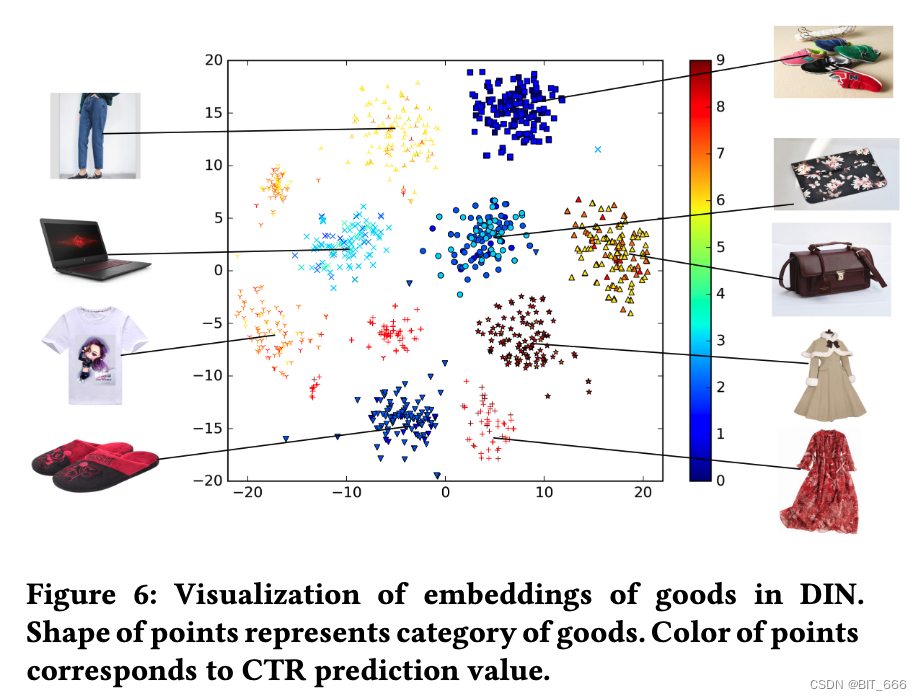
DIN 中商品嵌入的可视化。点的形状代表商品的类别。点的颜色对应于 CTR 预测值。以前面提到的年轻母亲为例,我们随机选择每个类别的 9 个类别(衣服、运动鞋、袋子等)和 100 个商品作为她的候选广告。上图显示了 DIN 学习到的 TSNE 商品嵌入向量的可视化,其中形状相同的点对应同一类别。可以看到,具有相同类别的商品几乎属于一个集群,这清楚地表明了 DIN 嵌入的聚类属性。此外,我们通过预测值对代表候选广告的点进行着色,这也是该母亲在嵌入空间中潜在候选者的兴趣密度分布的热图。结果表明 DIN 可以形成多模态兴趣密度分布。
九.总结
DIN 专注于具有丰富用户行为数据的电子商务行业展示广告场景中 CTR 预测建模的任务。通过 Activate Unit 激活单元捕捉用户兴趣,解决了传统深度 CTR 模型用户兴趣固定的问题,实现了为不同用户在不同广告上获取不同向量。DIN 便于实现,具有很强的工程性,同时创新的引入了 GAUC 的 Metric 以及 Dice 激活函数,结合业务场景与数据对原始方法进行微调取得了很好地实践效果。
论文参考:https://arxiv.org/pdf/1706.06978.pdf
视频简介:DIN 序列模型简介
更多推荐算法相关深度学习:深度学习导读专栏
![[工具]Pytorch-lightning的使用](https://img-blog.csdnimg.cn/d3001cffcd0b4da795f7d57e3b219fd1.png)