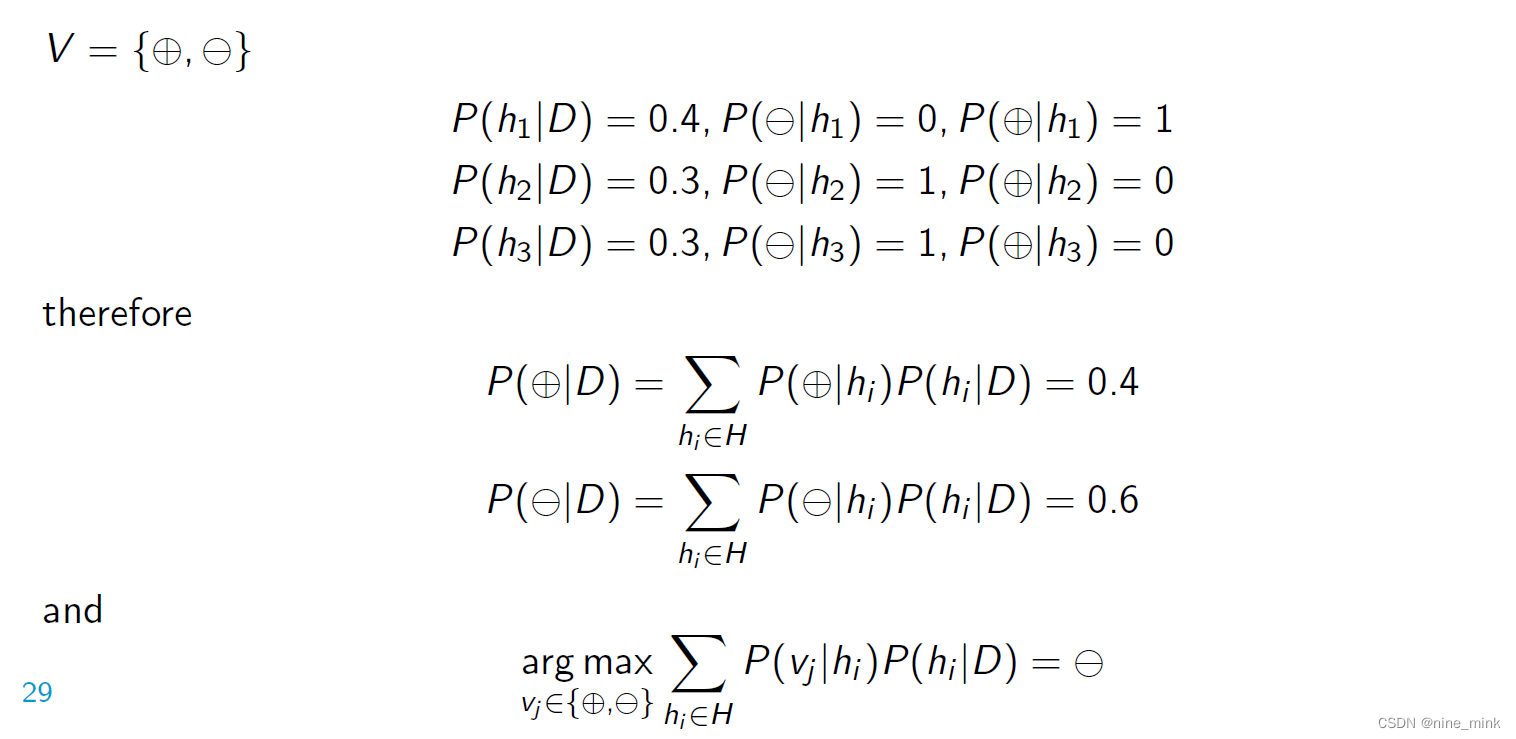一、本文概要:
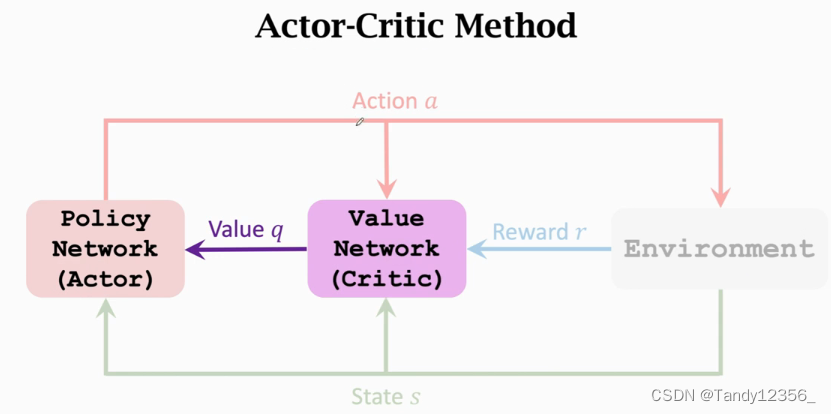
actor是策略网络,用来控制agent运动,你可以把他看作是运动员,critic是价值网络,用来给动作打分,你可以把critic看作是裁判,这节课的内容就是构造这两个神经网络,然后通过环境给的奖励来学习这两个网络
1、首先看一下如何构造价值网络value network:
Π 和QΠ这两个函数我们都不知道,应该怎么办呢?
》可以用两个神经网络分别近似这两个函数,然后用actor-critic方法同时学习这两个神经网络
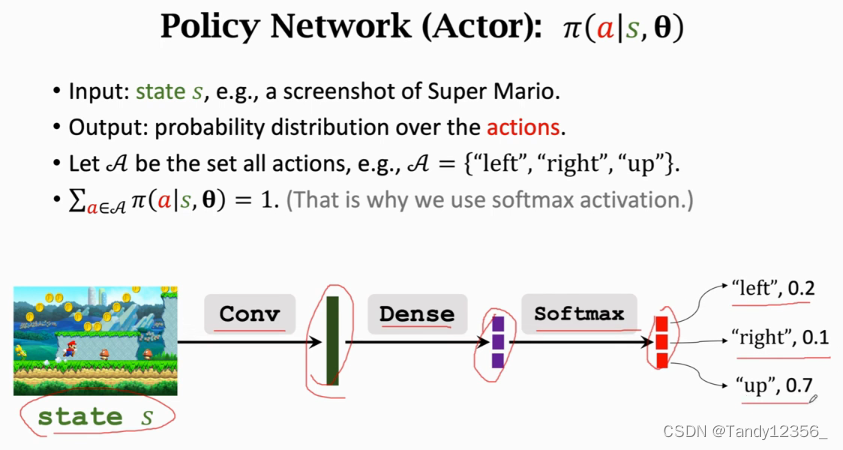
策略网络:Policy network(actor):
我们用策略网络来控制agent做运动,决策是由策略网络做的
价值网络:Value network(critic):
这里的价值网络不控制agent运动,价值网络只是给动作打分而已,所以价值网络被称为critic,它相当于裁判,来给运动员的表现打分
你可以这样理解:actor是一个体操运动员,它可以做动作,如果它想让自己做的更好,就得改进自己的技术,可是它不知道怎样改进自己,这就需要裁判,裁判给运动员打分,运动员就知道什么样的动作得分高,什么样的动作得分低,这样一来运动员就会改进自己,让自己的分数越来越高

我们用策略网络来近似Π函数,用价值网络来近似QΠ函数,Π是策略网络,相当于运动员,q是价值网络相当于裁判
我们现在来搭建这两个神经网络:
1、策略网络
2、价值网络:
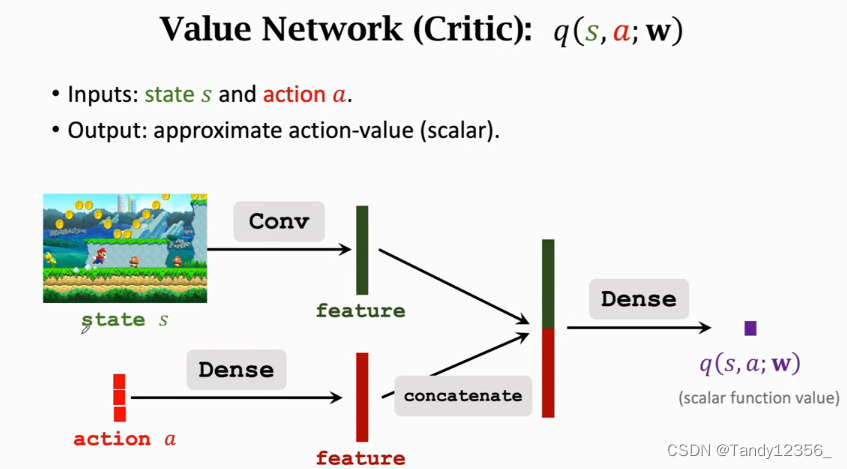
价值网络有两个输入:一个是状态s,一个是动作a,如果动作是离散的,就可以使用onehot-encoding独热编码来表示一个动作, 比如向左可以表示成100,向右可以表示成010,向上表示成001,分别用卷积层和全连接层从输入中提取特征,得到两个特征向量,然后把这两个特征向量给拼接起来,得到一个更高的特征向量,最后用全连接层输出一个实数q(s,a;w),这个数,就是裁判给运动员打的分数,这个分数说明,出在状态s的情况下,做出动作a是好还是坏
这个价值网络可以和策略网络共享卷积层的参数,也可以跟策略网络完全独立,各自有各自的参数
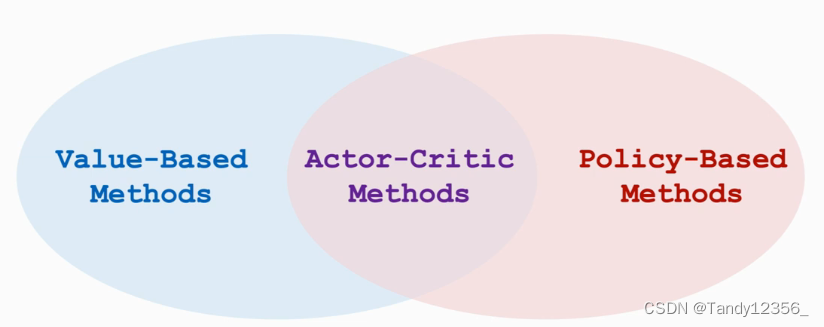
同时训练策略网络和价值网络,就被称为是Actor-Critic Method,可以这样理解Actor-Critic Method:策略网络用来控制agent运动,所以叫做actor,你可以把策略网络当成是一个体操运动员,他要做一连串的动作,价值网络的用途是评价动作的好坏,所以把他叫做critic,你可以把价值网络当作是裁判,他给运动员的动作打分,学习这两个网络的目的是让运动员的平均分越来越高,并且让裁判的打分越来越精准

下面我们来训练这两个神经网络:
我们用了策略网络来近似策略函数Π,用了价值网络来近似动作价值函数QΠ,这样一来,状态价值函数就可以用V(s;θ,w)来近似,θ是策略网络的参数,w是价值网络的参数,训练的时候要更新两个神经网络的参数θ和w,但是更新θ和w的目标是不同的,更新策略网络Π的参数θ,是为了让V函数的值增加,V函数是对策略Π和状态s的评价,如果固定s,V越大则说明策略Π越好,所以很显然我们需要更新参数θ使得V的平均值(期望)增加,学习策略网络Π的时候,监督是由价值网络Q提供的,怎么理解呢?
策略网络Π 相当于体操运动员,它做出动作之后,裁判会给动作打分,裁判相当于价值网络Q,运动员努力改进自己的技术,争取让裁判打的分数更高,裁判打的分数就是监督信号,运动员靠裁判打的分数来改进自己的技术。更新价值网络q的参数w是为了让q的打分更精准,从而更好地估计未来得到的奖励的总和,价值网络q相当于是裁判,一开始是随机初始化的,所以一开始裁判没有判断能力,裁判会逐渐改善自己的水平,让打分越来越精准。裁判是靠什么改进自己的呢?
裁判靠的是环境给的奖励reward,你可以把环境给的奖励理解成是上帝给打的分数,但是上帝不会轻易把他的分数告诉别人,直到运动会结束了,上帝才会把他的打分全部公开,裁判要做的就是要让它的打分越来越接近上帝的打分
通过学习两个神经网络,运动员的得分越来越高,裁判员的打分越来越精准

我们通过如下5个步骤来对两个神经网络做一次更新
 1、观测到当前状态st
1、观测到当前状态st
2、 把状态st当作输入,用策略网络Π来计算概率分布,然后随机抽样得到动作at
3、agent执行动作at,这时候环境会更新状态st+1,并给agent一个奖励rt
4、有了奖励rt,就可以用TD算法来更新价值网络的参数w,也就是让裁判变得更准确
5、最后用policy gradient策略梯度算法,来更新策略网络的参数θ,这会让运动员的技术更好
更新策略网络的参数要用到裁判对动作at的打分,下面具体来讲如何更新这两个神经网络的参数:
1)价值网络q可以用TD算法来更新
1、首先用价值网络q来给动作at和at+1打分,这里的动作是根据策略网络Π随机抽样得到的
2、然后算一下TD target,把计算出来的数值记作yt,其中γ是折扣率,他让未来的奖励没有当前奖励的权重更高
3、用梯度下降更新w,使得yt-qt的值越来越小

2)使用策略梯度算法来更新策略网络Π,让运动员的得分更高:
这里的函数V是状态价值函数,相当于是这位运动员所有动作的平均分(V是动作价值函数的期望也即平均值),策略梯度是函数V关于参数θ的导数,我们直接用一个g(a,θ)就行了,一个g(a,θ)就是对这个期望的蒙特卡洛近似,既然g(a,θ)是对策略梯度的无偏估计,我们就拿g函数来代替策略梯度,具体是这样做的:
首先拿策略网络Π来随机抽样得到动作a,这个随机抽样的目的是为了保证样本的无偏性,必须要根据Π来做随机抽样,否则保证不了无偏性,有了随机梯度g,就可以做一次梯度上升,其中β是学习率,由于梯度是函数V关于θ的导数,所以梯度上升可以增加V函数的值

我们来总结一下Actor-Critic Method:
策略网络actor观测到当前的状态s,它控制agent做出动作a,这个actor就相当于一个体操运动员,他会做出一个动作,它的目标是让自己的动作越来越好,所以他要通过学习来让自己进步,问题是什么样的动作才算更好呢?
运动员自己并不知道什么样的动作才算是更好,所以它很难改进自己的技术,为了让运动员表现的更好,我们请裁判来帮忙,运动员做出动作之后,裁判会根据状态s和动作a来打一个分数,记作q,裁判把分数q告诉运动员,这样运动员就有办法改进自己了
这位运动员要靠裁判打分q来改进自己的技术,这里的技术指的是神经网络里的参数,它通过状态s,自己的动作a,以及裁判打分q来近似算出策略梯度,然后做梯度上升来更新参数,通过改善自己的技术,运动员会获得越来越高的平均分,其实运动员这样做只是在迎合裁判的喜好而已,运动员获得的平均分越来越高,原因是运动员在迎合裁判的喜好,使得裁判的打分q越来越高了,更高的q未必能说明这个运动员变得越来越优秀了,裁判的水平也很重要,迎合一个二流的裁判并不会让一个运动员成为一个顶尖的运动员,这就需要一个顶尖的裁判,来打出最准确的分数,所以为了让运动员变得越来越优秀,还需要裁判不断改进他的打分能力
裁判要靠奖励r来提高它的打分水平,奖励r相当于是上帝的判断,相当于是ground truth,裁判基于状态s和动作a来打分,计算出分值q,可以比较两次相邻打分qt和qt+1,以及奖励rt,然后用TD算法来更新价值网络参数,这样可以让裁判打分越来越精准
最后我们过一遍算法:
1、观测到旧的状态st,用策略网络Π来计算概率分布,再根据算出的概率,来随机抽样得到动作at
2、执行动作at,然后环境会更新st+1并给出一个奖励rt
3、拿新的状态st+1作为输入,用策略网络Π计算出新的概率,然后随机抽样得到新的动作~at+1,这个动作~at+1只是一个假想的动作而已,拿来算一下q值,agent并不会真正去做~at+1(tiuta)这个动作,算法的每一轮循环里面agent只做一次动作,agent这一轮已经做了动作at,所以就不会再做~at+1了
4、算2次价值网络的输出:用st和at作为输入算出裁判打分qt,用st+1和~at+1算出裁判打分qt+1,这里的~at+1用完就丢掉了,agent并不会真正执行~at+1这个动作
5、计算出TD error(预测与TD target之间的差)
6、对价值网络求导,tensorflow和pytorch系统都可以自动做反向传播,自动算出q网络关于参数w的梯度(这里的梯度是q函数的梯度),记作dw,t他的形状和w是完全一样的,是同样大小的矩阵或者张量
7、用TD算法来更新价值网络,让裁判打分变得更精准这里的δt*dw,t是损失函数Loss的梯度,做梯度下降,可以让预测离TD target变得更近
8、对策略网络Π求导,软件系统会自动帮你求导,只要你调用一下gardient函数就行了,这里的dθ,t和θ的形状也是一样的
9、最后一步:用梯度上升来更新策略网络,让运动员的平均分更高这里的qt*dθ,t是策略梯度的蒙特卡洛近似

每一轮迭代都做这9个步骤,每一轮迭代都只做一次动作 ,观测一个奖励,更新一次神经网络的参数论文和书中在这一步大多数使用δt而不是qt,使用qt是标准算法,使用δt叫做policy gradien with baseline,这两种策略梯度的期望完全相等,实际上用baseline效果更好,原因是虽然用不用baseline不影响期望,但是用个好的baseline可以降低方差,让算法收敛的更快

那么baseline是什么呢?
事实上任何接近qt的数都可以被认为是baseline,但是这个baseline不能是动作at的函数
我们可以使用:
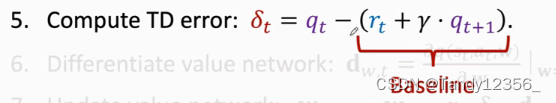 来作为baseline
来作为baseline
最后总结一下actor-critic这部分的内容:
我们的目标函数是V(Π)的期望,我们希望学到策略Π ,让V(Π)的期望越大越好,但是直接学Π函数不容易,所以我们用神经网络来近似Π函数这个神经网络叫做policy network策略网络,当时我们计算策略梯度的时候有个困难,就是我们不知道动作价值函数Q(Π),所以要用神经网络来近似Q(Π)这个神经网络叫做value network价值网络actor-critic method里面有两个神经网络,策略网络Π叫做actor,价值网络q叫做critic

价值网络q的作用是辅助训练策略网络Π,裁判打的分数就相当于监督学习中的标签,运动员就是靠裁判打的分数来改进自己的动作
训练结束之后,价值网络q就没用了,总之呢,actor-critic method的终极目的是用来学习策略网络,而价值网络只是作为裁判员起辅助作用,帮助学习,学完了就不需要这个裁判了
该怎么样训练这两个神经网络呢?
策略网络Π要用到策略梯度算法来训练, 学习策略网络Π的目标是让状态价值函数V的平均值变大
补充一点:使用actor-critic method我们最终既能够学习策略网络Π参数θ使得状态价值函数V的平均值变大,同时也能够使得价值网络q打分越来越准(误差越来越小)

接下来我们将探索AlphaGo的基本原理,看看深度强化学习是如何解决实际问题的!