嘈杂的数据仍然是让我们数据科学家夜不能寐的最常见的机器学习问题之一。
深度学习面对高维的非结构化数据(图像、语音、文本),如何获取特征信息问题也是最头疼的问题。
然而,幸运的是,我们现在可以利用各种技术和技巧,对数据进行压缩降维和重建,其中之一就是自编码器。
深度学习中的自动编码器
- 什么是自编码器
- 自编码器的结构
- 编码器、瓶颈和解码器之间的关系
- 如何训练自编码器
- 5种自编码器
- 1.欠完备自动编码器(Undercomplete Autoencoders)
- 2.稀疏自动编码器
- 算法原理
- 计算公式
- 3.收缩式自动编码器
- 算法原理
- 计算公式
- 4.去噪自动编码器
- 算法原理
- 计算公式
- 5.变分自动编码器VAE(用于生成模型)
- 算法原理
- 算法流程
- 自编码器代码实现
- 线性自编器实现
- 卷积自编器实现
- 变分自编器实现
什么是自编码器
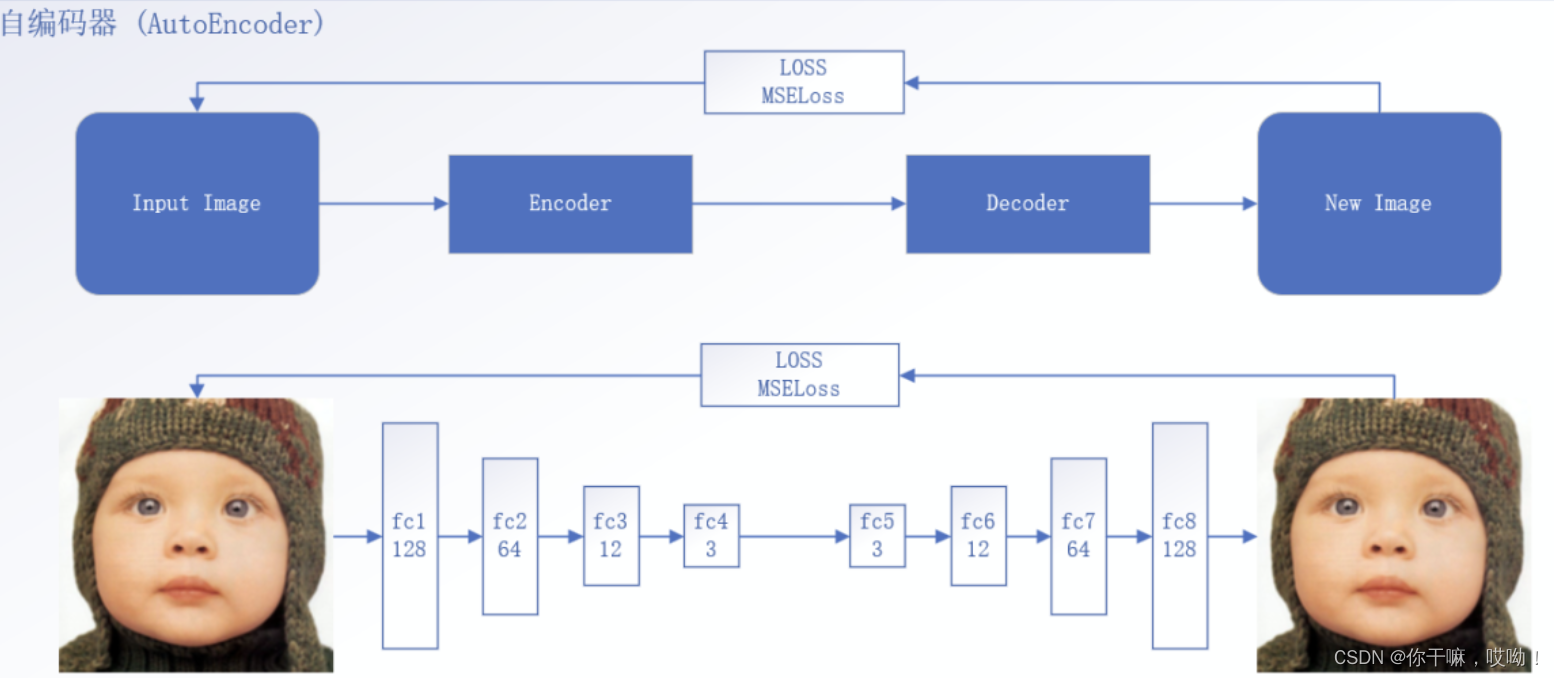
自编码器是一种用于数据压缩的人工神经网络,可以将输入数据压缩为较小的编码,然后将其解码回原始数据。它可以被视为一个无监督学习的算法,因为它不需要标记数据。
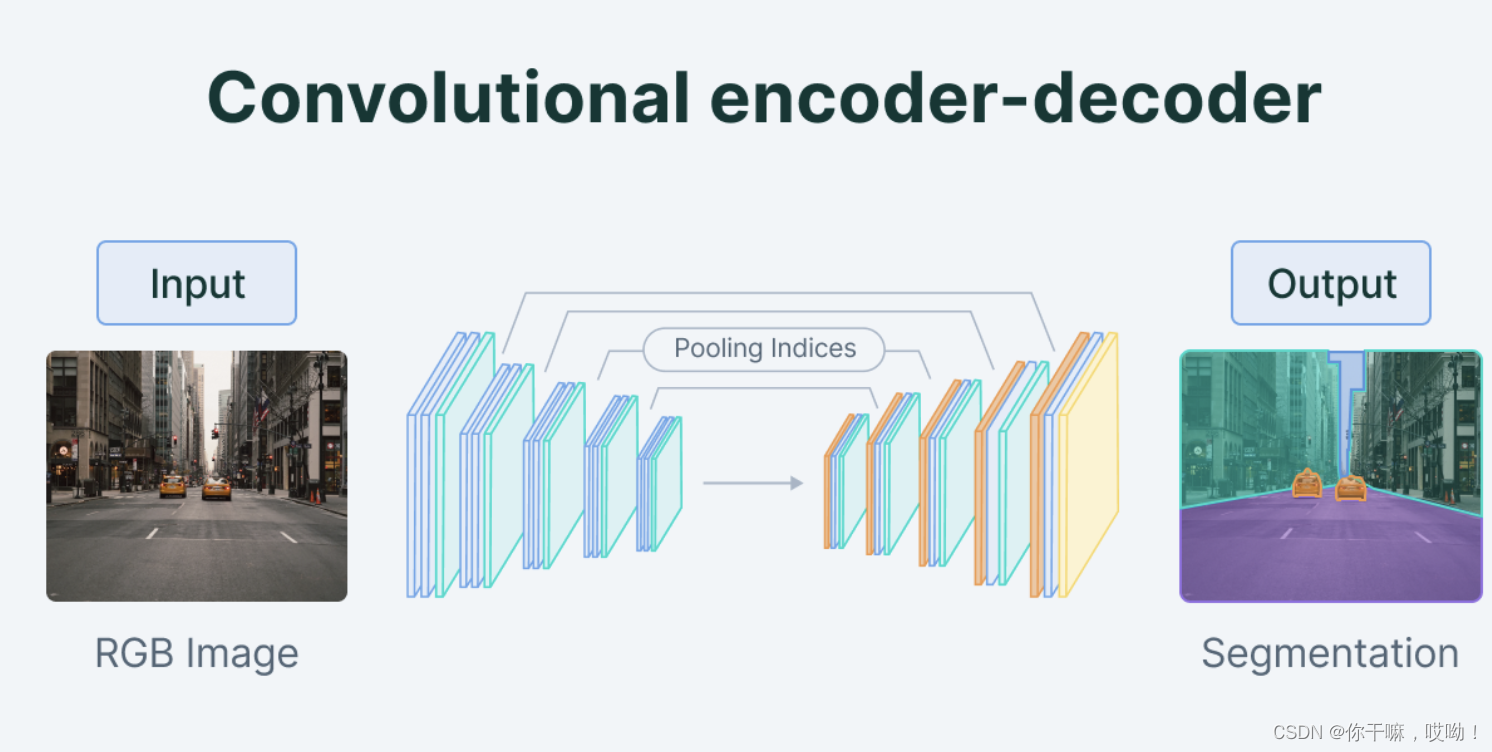
自编码器的结构
让我们从自编码器的架构快速概述开始。自编码器由以下三个部分组成:
- 编码器(Encoder):将训练验证测试集的输入数据压缩成编码表示的模块,编码表示通常比输入数据小几个数量级。
- 瓶颈(Bottleneck):包含压缩的知识表示,因此是网络最重要的部分。
- 解码器(Decoder):帮助网络“解压”知识表示并从其编码形式中重构数据的模块,然后将其与地面实况进行比较。
整个架构如下所示:
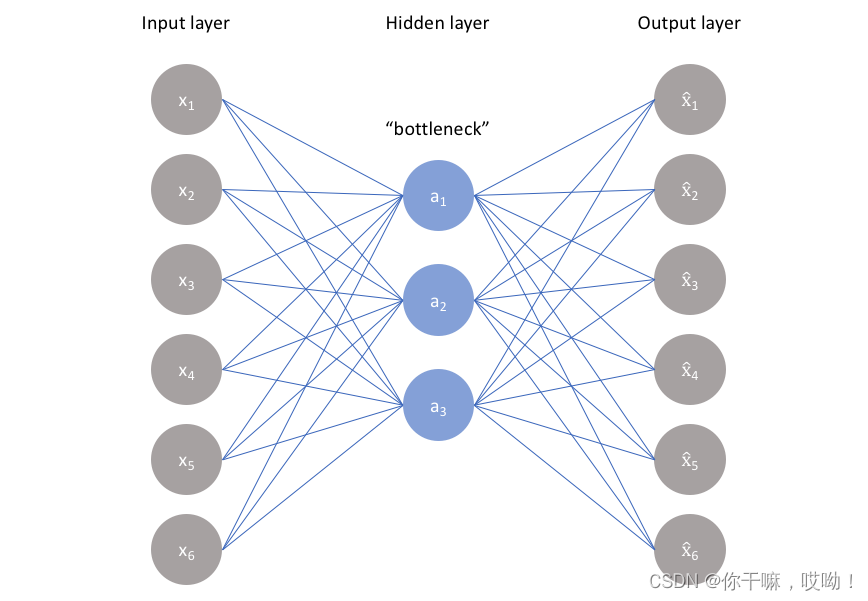
编码器、瓶颈和解码器之间的关系
编码器编码器是一组卷积块,后面跟着池化模块,将模型的输入压缩成被称为瓶颈的紧凑部分。
瓶颈后面是解码器,由一系列上采样模块组成,将压缩的特征转换回图像形式。
对于简单的自编码器,输出预期与输入相同但降噪。
但对于变分自编码器,输出是全新的图像,使用模型提供的输入信息形成。
瓶颈神经网络中最重要的部分,也是最小的部分,是瓶颈。瓶颈存在的目的是限制来自编码器到解码器的信息流,从而只允许最关键的信息通过。由于瓶颈是设计成以最大限度捕获图像所具有的信息,因此我们可以说瓶颈帮助我们形成输入的知识表示。
因此,编码器-解码器结构帮助我们从图像中提取最有用的数据,并在网络内部建立各种输入之间的有用关系。瓶颈作为输入的压缩表示进一步防止神经网络记住输入并在数据上过拟合。作为一个经验法则,记住这一点:瓶颈越小,过拟合的风险越低。然而——非常小的瓶颈会限制可存储的信息量,从而增加重要信息通过编码器的池化层滑出的机会。解码器最后,解码器是一组上采样和卷积块,用于重构瓶颈的输出。由于解码器的输入是压缩的知识表示,因此解码器充当“解压器”,并从其潜在属性中构建图像。
如何训练自编码器
在训练自编码器之前,您需要设置四个超参数:
- 编码大小:编码大小或瓶颈大小是用于调整自编码器的最重要的超参数。瓶颈大小决定数据需要被压缩多少,这也可以作为一个正则化项。
- 层数:像所有神经网络一样,调整自编码器的一个重要超参数是编码器和解码器的深度。较高的深度会增加模型复杂性,较低的深度则更快进行处理。
- 每层节点数:每层节点数定义了我们每层使用的权重。通常情况下,自编码器中每个后续层的节点数都会逐渐减少,因为每个层的输入在层间变得越来越小。
- 重建损失:我们用来训练自编码器的损失函数高度依赖于我们想要自编码器适应的输入和输出类型。如果我们处理的是图像数据,则最常用于重建的损失函数是均方误差(MSE Loss)和L1损失。如果输入和输出在[0,1]范围内,例如MNIST数据集,则我们还可以使用二进制交叉熵作为重建损失。
最后,探讨一下不同类型的自编码器。
5种自编码器
自动编码器(autoencoder)的概念并非新颖。实际上,最早的应用可以追溯到上世纪八十年代。最初用于降维和特征学习,随着时间的推移,autoencoder的概念已经发展成为广泛用于学习数据生成模型的技术。以下是五种流行的autoencoder类型:
1.欠完备自动编码器(Undercomplete Autoencoders)
欠完备自动编码器是最简单的自动编码器之一,早在20世纪80年代就被首次应用于降维和特征学习。它的原理很简单,通过压缩输入数据生成一种潜在空间,然后再将其解压缩回原始数据。因为它是无监督学习,所以不需要标签。欠完备自动编码器可以被看作是一种降维技术,可以将高维数据投射到低维潜在空间中。
其计算公式:
输入数据 xxx 经过编码器 fff 生成一个潜在空间的特征向量 hhh:
h=f(x)h=f(x)h=f(x)
接着,潜在空间的特征向量 hhh 经过解码器 ggg 生成重建数据 x′x'x′:
x′=g(h)x'=g(h)x′=g(h)
欠完备自动编码器的损失函数是重建误差,可以使用多种不同的误差函数来表示,例如 L1 损失或者均方误差等。
通过使用欠完备自动编码器,我们可以将高维的数据压缩到一个低维潜在空间中,并且能够重构原始数据。这种技术在实践中非常有用,例如图像处理、语音信号处理、自然语言处理等领域。与其他降维技术相比,欠完备自动编码器可以学习非线性关系,因此在保持数据信息的同时,可以更好地降维。
如果把这个模型比作一个人的话,就好比你在旅行时只能带一件行李,但你需要尽可能多地带一些物品。所以你必须考虑如何将物品压缩到行李中,而且你还需要在到达目的地后重新组装你的物品。欠完备自动编码器就是这样一个“行李”,它可以帮助你压缩数据并重构数据
2.稀疏自动编码器
稀疏自动编码器是欠完备自动编码器的一种扩展,与欠完备自动编码器相比,它的特点是增加了稀疏性约束,可以更好地学习数据的特征。以下是稀疏自动编码器的算法原理和计算公式:
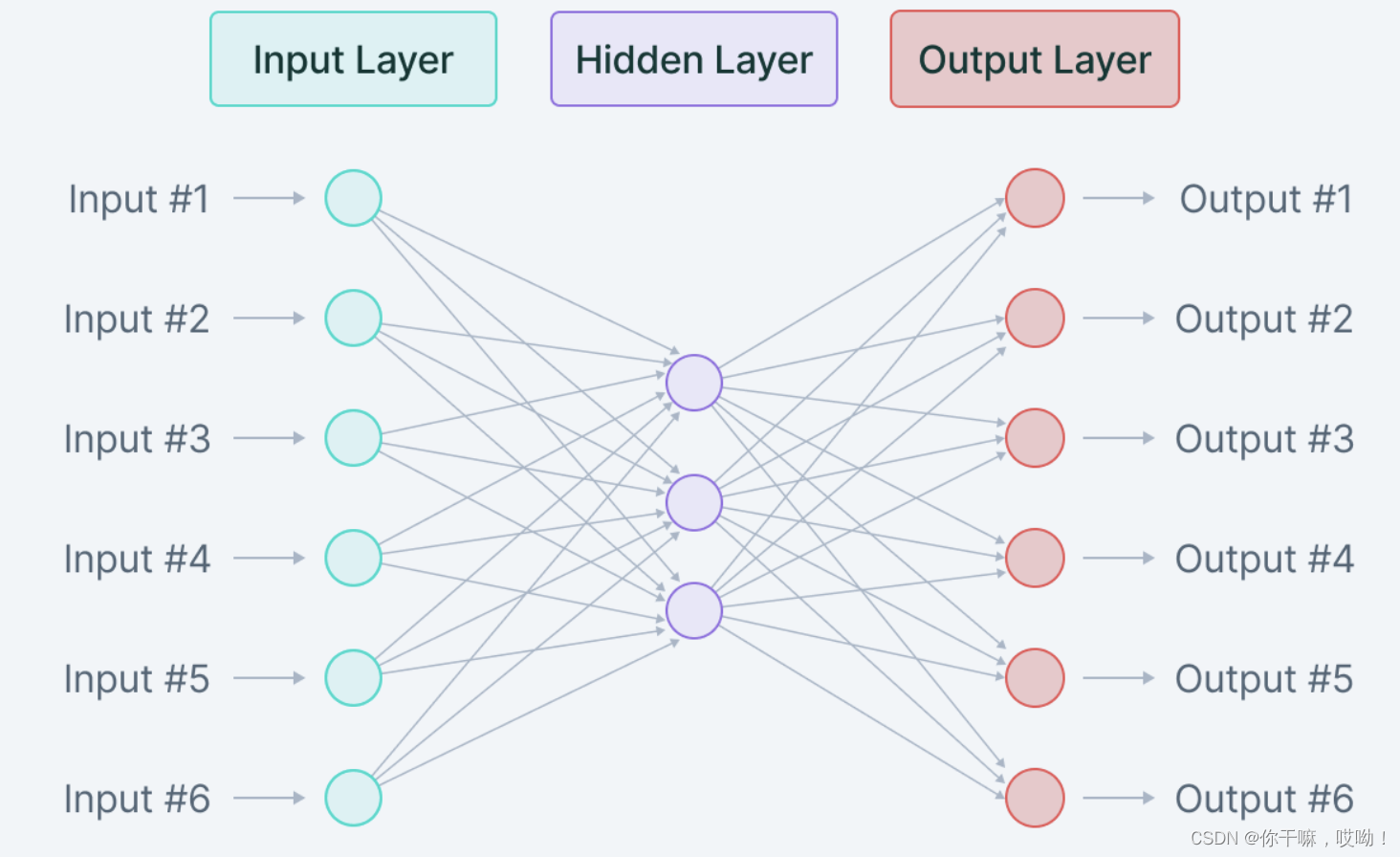
算法原理
稀疏自动编码器通过限制隐藏层神经元的平均激活度,强制要求只有部分神经元会被激活,从而使模型更具有鲁棒性。这一约束可以通过在目标函数中添加惩罚项实现。
计算公式
对于稀疏自动编码器,目标函数由两个部分组成:重构误差和稀疏惩罚项。
重构误差部分与欠完备自动编码器相同,即通过最小化输入与输出之间的误差来训练网络,其公式如下:
Jreconstruction(W,b;x(i))=12∣∣y(x(i))−x(i)∣∣2J_{reconstruction}(W,b;x^{(i)}) = \frac{1}{2}||y(x^{(i)}) - x^{(i)}||^2Jreconstruction(W,b;x(i))=21∣∣y(x(i))−x(i)∣∣2
其中,WWW和bbb是网络的权重和偏置项,x(i)x^{(i)}x(i)是训练数据集中的第iii个样本,y(x(i))y(x^{(i)})y(x(i))是网络的输出。
稀疏惩罚项部分可以通过增加一个稀疏性约束来实现,其公式如下:
Jsparse(a)=∑j=1sKL(ρ∣∣ρj^)J_{sparse}(a) = \sum_{j=1}^{s}KL(\rho || \hat{\rho_j})Jsparse(a)=j=1∑sKL(ρ∣∣ρj^)
其中,sss是隐藏层神经元的数量,aaa是隐藏层的输出,ρ\rhoρ是期望的神经元激活度,ρj^\hat{\rho_j}ρj^是计算得到的平均激活度。KL(ρ∣∣ρj^)KL(\rho || \hat{\rho_j})KL(ρ∣∣ρj^)表示KL散度,可以通过以下公式计算:
KL(ρ∣∣ρj^)=ρlogρρj^+(1−ρ)log1−ρ1−ρj^KL(\rho || \hat{\rho_j}) = \rho log \frac{\rho}{\hat{\rho_j}} + (1 - \rho)log\frac{1-\rho}{1-\hat{\rho_j}}KL(ρ∣∣ρj^)=ρlogρj^ρ+(1−ρ)log1−ρj^1−ρ
在目标函数中,稀疏惩罚项的权重可以通过超参数来调整。
稀疏自动编码器可以类比于人脑的学习过程。人脑在学习新事物时,会尝试着找到其中的一些特征来加深对事物的理解。同样,稀疏自动编码器通过强制网络只学习部分特征,使得网络更具有鲁棒性和泛化能力,从而能够更好地学习和理解输入数据。
3.收缩式自动编码器
收缩式自动编码器(Contractive Autoencoder)是一种可以学习数据的低维表示的无监督学习算法。相较于欠完备自动编码器和稀疏自动编码器,收缩式自动编码器更关注于数据的局部结构。
该算法的出现可以追溯到 Rifai 等人在 2011 年的一篇论文《Contractive Auto-Encoders: Explicit Invariance During Feature Extraction》,论文提出的收缩式自动编码器主要是在欠完备自动编码器的基础上加入了对数据的局部结构进行约束,使得编码器对于微小变化的鲁棒性更好,从而学习到更加稳定和具有可解释性的低维表示。
算法原理
收缩式自动编码器在欠完备自动编码器的基础上,添加了一个额外的项来惩罚网络对输入数据的微小变化。这个额外的项是通过计算编码层对输入数据的 Jacobian 矩阵 Frobenius 范数得到的。Frobenius 范数衡量了矩阵每个元素的平方和的平方根,因此这个额外的项衡量的是编码器在输入数据微小变化时对于编码的微小变化,从而实现对数据局部结构的约束。
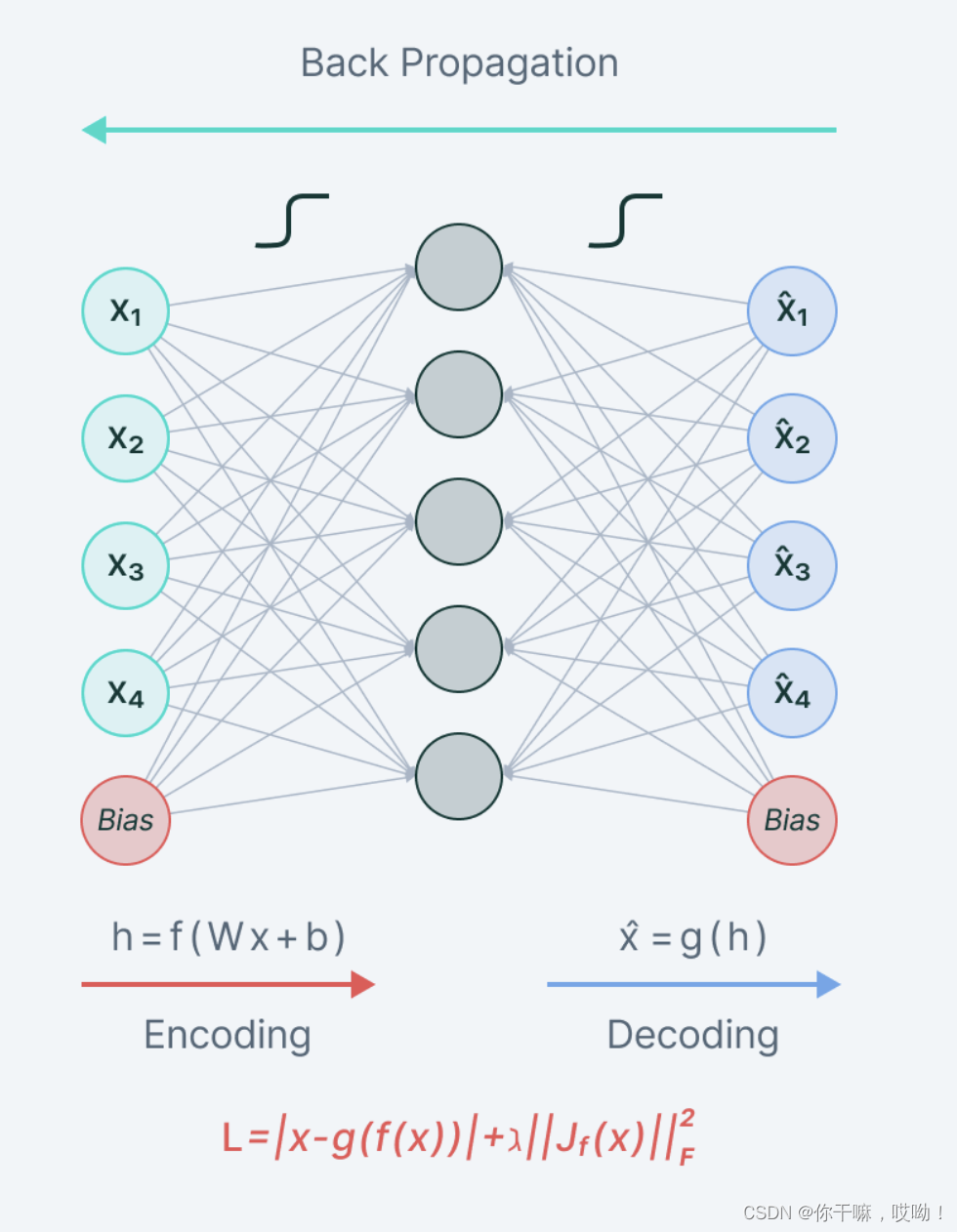
计算公式
设 WWW 为编码器中的权重参数,h(x)h(x)h(x) 为编码器的输出,JJJ 为 h(x)h(x)h(x) 对 xxx 的 Jacobian 矩阵,Frobenius 范数的计算公式为:
∣∣J∣∣F2=∑i,j(∂hj(x)∂xi)2||J||_F^2=\sum_{i,j}(\frac{\partial h_j(x)}{\partial x_i})^2∣∣J∣∣F2=i,j∑(∂xi∂hj(x))2
收缩式自动编码器的损失函数一般包含两部分,一部分是重构误差(reconstruction error),另一部分是对编码层的约束(contractive penalty),通常的表达式为:
L=1N∑i=1N∣∣xi−g(f(xi))∣∣22+λ∣∣J∣∣F2\mathcal{L}=\frac{1}{N}\sum_{i=1}^N||x_i-g(f(x_i))||_2^2+\lambda||J||_F^2L=N1i=1∑N∣∣xi−g(f(xi))∣∣22+λ∣∣J∣∣F2
其中 ggg 为解码器,fff 为编码器,xix_ixi 为输入数据,NNN 为样本数量,λ\lambdaλ 为约束系数,用于平衡重构误差和约束项。
想象一下你在学习如何绘画,但是你觉得你的画风缺少某些特定的元素。你决定参加一次训练营,学习如何更好地描绘人物面部特征。在开始训练之前,你需要了解如何描述这些特征以及如何将它们放在一起来描绘出一个完整的面孔。
这就像是一个收缩自动编码器,它从一幅图像中学习出最重要的特征,然后在压缩数据时只保留这些特征。通过这种方式,我们可以在压缩数据的同时保留重要的信息
4.去噪自动编码器
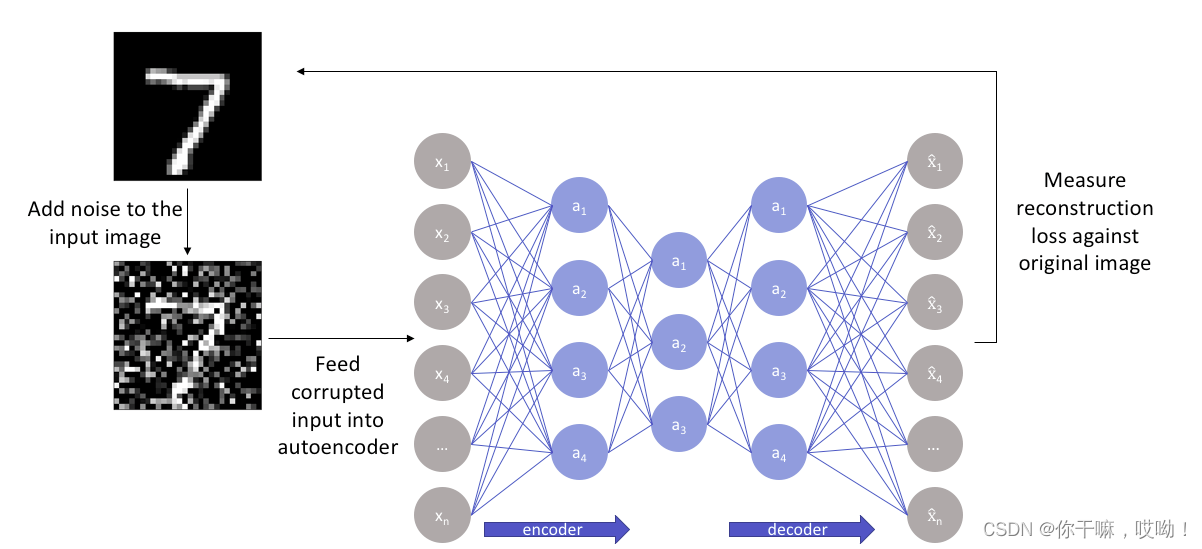
去噪自动编码器(Denoising Autoencoder)是一种能够通过去除噪声来提取数据特征的自动编码器。其出现是为了解决在真实环境下数据往往会受到噪声干扰的问题。
算法原理
去噪自动编码器与标准自动编码器的不同之处在于它们的训练数据是被添加了随机噪声的数据。去噪自动编码器在输入数据中添加随机噪声,然后将经过噪声处理后的数据作为输入,重构清晰数据。在这个过程中,它不仅仅要学习数据的特征,还要学习去除噪声的技巧,因此更加健壮。
计算公式
去噪自动编码器的计算公式与标准自动编码器的公式类似,只是多了一个去噪项。其公式如下:
Lθ=∑i=1n∣∣gθ(xi~)−xi∣∣2\mathcal{L}_{\theta}=\sum_{i=1}^n||g_\theta(\widetilde{\mathbf{x_i}})-\mathbf{x_i}||^2Lθ=i=1∑n∣∣gθ(xi)−xi∣∣2
其中,xi~\widetilde{\mathbf{x_i}}xi 是被添加了随机噪声的数据,gθg_{\boldsymbol{\theta}}gθ 是编码器和解码器的函数,LDAE\mathcal{L}_{DAE}LDAE 是训练损失函数。
拟人解释:去噪自动编码器就像是我们在嘈杂的环境中学习一件事情,我们会尽可能地去掉噪声,把一些关键信息留下来。例如,我们在嘈杂的音乐会上,虽然听不清每个音符,但我们仍然可以听到一首歌的主旋律。去噪自动编码器的原理也是一样的,它通过训练,可以从受噪声干扰的数据中提取出有用的信息,并去除噪声。
5.变分自动编码器VAE(用于生成模型)
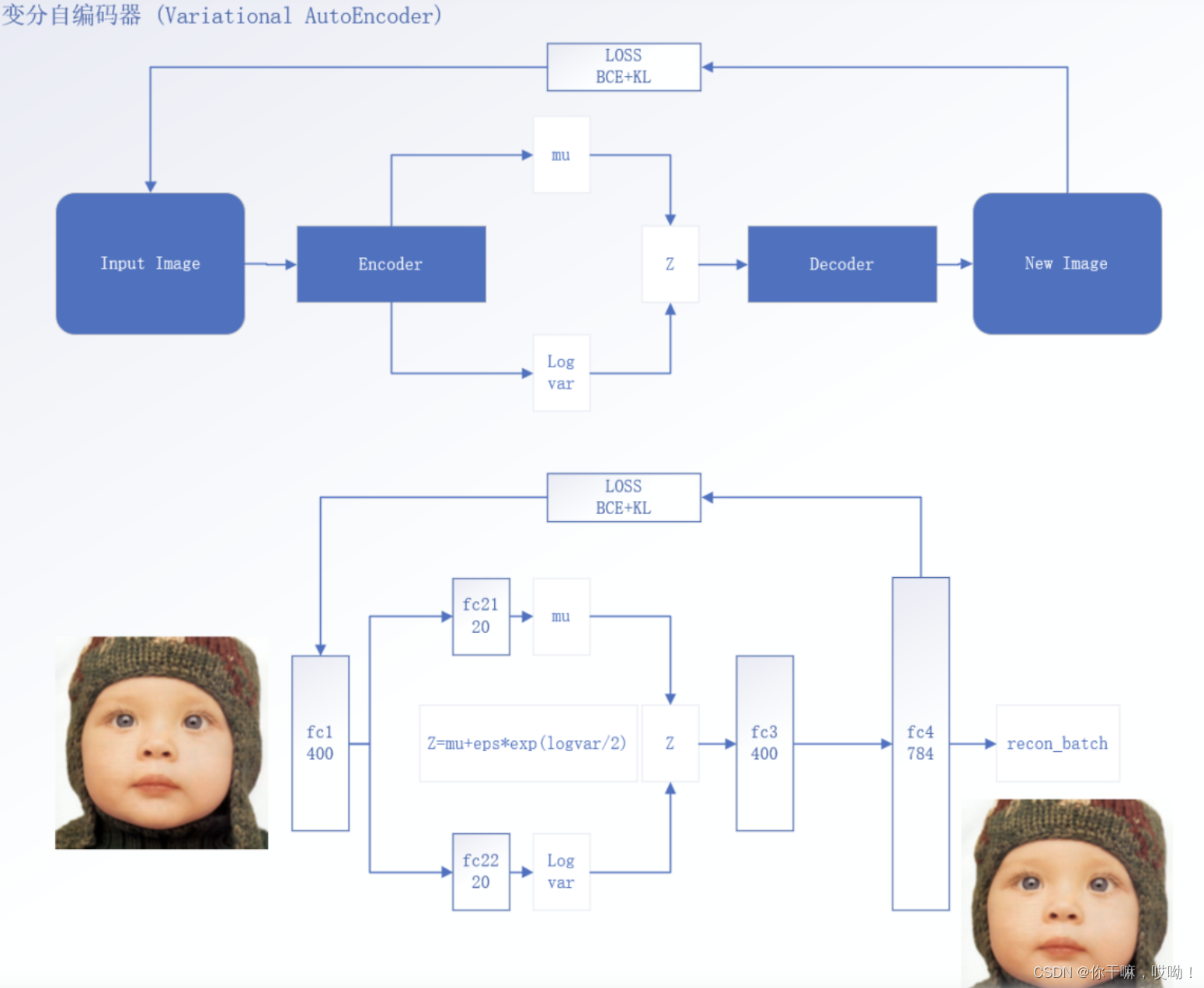
变分自动编码器(Variational Autoencoder,VAE)是一种基于神经网络的生成模型,其主要目的是学习数据的概率分布并能够生成新的数据样本。VAE最初由Diederik P. Kingma和Max Welling在2013年提出,是对传统自动编码器(Autoencoder,AE)的改进。
在传统的自动编码器中,编码器和解码器都是确定性的函数,通过最小化重构误差来训练模型。而VAE引入了一种基于概率的生成模型来描述输入数据的潜在分布。VAE将数据编码为一个潜在变量向量,并使用一个解码器将该向量映射回原始数据空间中。不同于传统自动编码器使用确定性的编码器和解码器,VAE使用随机的编码器将输入数据编码为潜在变量的分布,并通过采样来生成新的数据样本。
VAE的目标是最小化重构误差同时约束潜在变量的分布服从标准正态分布。这是通过最小化重构误差和KL散度来实现的,其中KL散度用于衡量潜在变量分布与标准正态分布之间的差异。这种方法使得VAE能够生成具有多样性和连续性的数据样本,且能够控制数据生成的多样性程度。
算法原理
VAE是一种生成模型,它可以用于学习数据分布的低维表示,以便用于数据的生成和重构。VAE基于自动编码器(Autoencoder,AE)的基本结构,但是使用了一种不同的训练策略,使其可以学习潜在空间中的连续分布。这种训练策略是基于变分推断(Variational Inference,VI)的。
VAE使用了一个编码器和一个解码器。编码器将输入数据xxx映射到潜在空间的隐变量zzz,解码器将隐变量zzz映射回重构数据x′x'x′。这样,VAE可以被看作是一个将输入数据xxx转换为潜在空间的隐变量zzz,然后再将隐变量zzz转换回重构数据x′x'x′的函数,即:
x′=fθ(z),z=gϕ(x)x'=f_\theta(z),z=g_\phi(x)x′=fθ(z),z=gϕ(x)
其中,fθf_{\theta}fθ表示解码器,gϕg_{\phi}gϕ表示编码器,θ\thetaθ和ϕ\phiϕ表示解码器和编码器的参数。
为了训练VAE,我们需要最大化对数似然函数logpθ(x)\log p_{\theta}(x)logpθ(x)。但是,直接计算对数似然函数是不可行的,因为它涉及到在所有可能的zzz值上的积分。因此,VAE使用了变分推断,将问题转化为最大化下界:
LVAE=Eqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))\mathcal{L}_{VAE}=E_{q_\phi(z|x)}[log p_\theta(x|z)]-KL(q_\phi(z|x)||p(z))LVAE=Eqϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))
其中,qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)表示给定xxx的情况下,zzz的后验概率分布,p(z)p(z)p(z)表示先验分布,KL(qϕ(z∣x)∣∣p(z))\text{KL}(q_{\phi}(z|x)||p(z))KL(qϕ(z∣x)∣∣p(z))表示后验分布qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)和先验分布p(z)p(z)p(z)之间的KL散度。
我们可以将这个下界分解为两个部分:重构误差和正则化项。重构误差衡量了解码器重构数据x′x'x′和原始数据xxx之间的差异,而正则化项鼓励后验分布qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)接近先验分布p(z)p(z)p(z)。
算法流程
下面是VAE训练过程的计算公式:
- 数据预处理
图像数据通常以像素矩阵的形式输入VAE模型,因此需要将图像数据进行预处理,例如将像素归一化为[0,1]之间的实数,或者将像素减去均值并除以标准差进行标准化等。
- 前向传播
使用编码器将输入数据xxx映射到潜在空间的隐变量zzz,其中编码器的输出是均值向量μ\muμ和方差向量σ\sigmaσ:
μ,logσ2=gϕ(x)\mu,log\sigma^2=g_\phi(x)μ,logσ2=gϕ(x)
其中,logσ2\log \sigma^2logσ2是为了确保方差是正的。这里使用logσ2\log \sigma^2logσ2是因为我们需要一个可训练的参数,并且这样可以避免负数的情况。
- 采样
从后验分布qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)中采样zzz
z=μ+ϵ⊙σ,ϵN(0,1)z=\mu+\epsilon \odot \sigma,\epsilon ~N(0,1)z=μ+ϵ⊙σ,ϵ N(0,1)
其中,ϵ\epsilonϵ是从标准正态分布中采样的噪声向量,⊙\odot⊙表示元素间的乘法
- 解码
使用解码器将隐变量zzz映射回重构数据x′x'x′:
x′=fθ(z)x'=f_\theta(z)x′=fθ(z)
- 计算重构误差
使用重构误差来衡量解码器重构数据x′x'x′和原始数据xxx之间的差异,这里假设数据是二元数据,使用交叉熵作为重构误差:
CE=−∑i=1Nxilogxi′+(1−xi)log(1−xi′)CE=-\sum_{i=1}^{N}x_ilogx'_i+(1-x_i)log(1-x'_i)CE=−i=1∑Nxilogxi′+(1−xi)log(1−xi′)
其中,NNN是数据的维度。
- 计算KL散度
计算后验分布qϕ(z∣x)q_{\phi}(z|x)qϕ(z∣x)和先验分布p(z)p(z)p(z)之间的KL散度:
KL(qϕ(z∣x)∣∣p(z))=−12∑j=1J(1+log(σj2)−μj2−σj2)KL(q_\phi(z|x)||p(z))=-\frac{1}{2}\sum_{j=1}^J(1+log(\sigma_j^2)-\mu_j^2-\sigma_j^2)KL(qϕ(z∣x)∣∣p(z))=−21j=1∑J(1+log(σj2)−μj2−σj2)
其中,JJJ是隐变量zzz的维度,μj\mu_jμj和σj2\sigma_j^2σj2是编码器输出的第jjj个隐变量的均值和方差。
- 计算损失函数
将重构误差和KL散度结合起来,得到VAE的损失函数:
L=CE+βKL(qϕ(z∣x)∣∣p(z))L=CE+\beta KL(q_\phi(z∣x)∣∣p(z))L=CE+βKL(qϕ(z∣x)∣∣p(z))
其中,β\betaβ是一个超参数,用于平衡重构误差和KL散度的权重。
- 反向传播
根据损失函数LLL对模型的参数ϕ\phiϕ和θ\thetaθ进行反向传播,更新参数:
θ←θ−α∂L∂θ\theta \leftarrow \theta-\alpha \frac{\partial L}{\partial \theta}θ←θ−α∂θ∂L
ϕ←ϕ−α∂L∂ϕ\phi \leftarrow\phi-\alpha \frac{\partial L}{\partial \phi}ϕ←ϕ−α∂ϕ∂L
其中,α\alphaα是学习率。重复上述步骤,直到损失函数收敛或达到预设的迭代次数。
自编码器代码实现
线性自编器实现
import torch
import torchvision
from torch import nn
from torch import optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import osif not os.path.exists('./vae_img'):os.mkdir('./vae_img')def to_img(x):x = x.clamp(0, 1)x = x.view(x.size(0), 1, 28, 28)return xnum_epochs = 100
batch_size = 128
learning_rate = 1e-3img_transform = transforms.Compose([transforms.ToTensor()# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])dataset = MNIST('../data', transform=img_transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)class VAE(nn.Module):def __init__(self):super(VAE, self).__init__()self.fc1 = nn.Linear(784, 400)self.fc21 = nn.Linear(400, 20)self.fc22 = nn.Linear(400, 20)self.fc3 = nn.Linear(20, 400)self.fc4 = nn.Linear(400, 784)def encode(self, x):h1 = F.relu(self.fc1(x))return self.fc21(h1), self.fc22(h1)def reparametrize(self, mu, logvar):std = logvar.mul(0.5).exp_()if torch.cuda.is_available():eps = torch.cuda.FloatTensor(std.size()).normal_()else:eps = torch.FloatTensor(std.size()).normal_()eps = Variable(eps)return eps.mul(std).add_(mu)def decode(self, z):h3 = F.relu(self.fc3(z))# return F.sigmoid(self.fc4(h3))return torch.sigmoid(self.fc4(h3))def forward(self, x):mu, logvar = self.encode(x)z = self.reparametrize(mu, logvar)return self.decode(z), mu, logvarmodel = VAE()
if torch.cuda.is_available():# model.cuda()print('cuda is OK!')model = model.to('cuda')
else:print('cuda is NO!')reconstruction_function = nn.MSELoss(size_average=False)
# reconstruction_function = nn.MSELoss(reduction=sum)def loss_function(recon_x, x, mu, logvar):"""recon_x: generating imagesx: origin imagesmu: latent meanlogvar: latent log variance"""BCE = reconstruction_function(recon_x, x) # mse loss# loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)KLD = torch.sum(KLD_element).mul_(-0.5)# KL divergencereturn BCE + KLDoptimizer = optim.Adam(model.parameters(), lr=1e-3)for epoch in range(num_epochs):model.train()train_loss = 0for batch_idx, data in enumerate(dataloader):img, _ = dataimg = img.view(img.size(0), -1)img = Variable(img)if torch.cuda.is_available():img = img.cuda()optimizer.zero_grad()recon_batch, mu, logvar = model(img)loss = loss_function(recon_batch, img, mu, logvar)loss.backward()# train_loss += loss.data[0]train_loss += loss.item()optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch,batch_idx * len(img),len(dataloader.dataset), 100. * batch_idx / len(dataloader),# loss.data[0] / len(img)))loss.item() / len(img)))print('====> Epoch: {} Average loss: {:.4f}'.format(epoch, train_loss / len(dataloader.dataset)))if epoch % 10 == 0:save = to_img(recon_batch.cpu().data)save_image(save, './vae_img/image_{}.png'.format(epoch))torch.save(model.state_dict(), './vae.pth')
卷积自编器实现
import os
import datetimeimport torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNISTif not os.path.exists('./dc_img'):os.mkdir('./dc_img')def to_img(x):x = 0.5 * (x + 1)x = x.clamp(0, 1)x = x.view(x.size(0), 1, 28, 28)return xnum_epochs = 100
batch_size = 128
learning_rate = 1e-3img_transform = transforms.Compose([transforms.ToTensor(),# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))transforms.Normalize([0.5], [0.5])
])dataset = MNIST('./data', transform=img_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)class autoencoder(nn.Module):def __init__(self):super(autoencoder, self).__init__()self.encoder = nn.Sequential(nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10nn.ReLU(True),nn.MaxPool2d(2, stride=2), # b, 16, 5, 5nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3nn.ReLU(True),nn.MaxPool2d(2, stride=1) # b, 8, 2, 2)self.decoder = nn.Sequential(nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5nn.ReLU(True),nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15nn.ReLU(True),nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28nn.Tanh())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return xmodel = autoencoder().cuda()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate,weight_decay=1e-5)
starttime = datetime.datetime.now()for epoch in range(num_epochs):for data in dataloader:img, label = dataimg = Variable(img).cuda()# ===================forward=====================output = model(img)loss = criterion(output, img)# ===================backward====================optimizer.zero_grad()loss.backward()optimizer.step()# ===================log========================endtime = datetime.datetime.now()print('epoch [{}/{}], loss:{:.4f}, time:{:.2f}s'.format(epoch+1, num_epochs, loss.item(), (endtime-starttime).seconds))# if epoch % 10 == 0:pic = to_img(output.cpu().data)save_image(pic, './dc_img/image_{}.png'.format(epoch))torch.save(model.state_dict(), './conv_autoencoder.pth')
变分自编器实现
import torch
import torchvision
from torch import nn
from torch import optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import os
import datetimeif not os.path.exists('./vae_img'):os.mkdir('./vae_img')def to_img(x):x = x.clamp(0, 1)x = x.view(x.size(0), 1, 28, 28)return xnum_epochs = 100
batch_size = 128
learning_rate = 1e-3img_transform = transforms.Compose([transforms.ToTensor()# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])dataset = MNIST('./data', transform=img_transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)class VAE(nn.Module):def __init__(self):super(VAE, self).__init__()self.fc1 = nn.Linear(784, 400)self.fc21 = nn.Linear(400, 20)self.fc22 = nn.Linear(400, 20)self.fc3 = nn.Linear(20, 400)self.fc4 = nn.Linear(400, 784)def encode(self, x):h1 = F.relu(self.fc1(x))return self.fc21(h1), self.fc22(h1)def reparametrize(self, mu, logvar):std = logvar.mul(0.5).exp_()if torch.cuda.is_available():eps = torch.cuda.FloatTensor(std.size()).normal_()else:eps = torch.FloatTensor(std.size()).normal_()eps = Variable(eps)return eps.mul(std).add_(mu)def decode(self, z):h3 = F.relu(self.fc3(z))# return F.sigmoid(self.fc4(h3))return torch.sigmoid(self.fc4(h3))def forward(self, x):mu, logvar = self.encode(x)z = self.reparametrize(mu, logvar)return self.decode(z), mu, logvarstrattime = datetime.datetime.now()
model = VAE()
if torch.cuda.is_available():# model.cuda()print('cuda is OK!')model = model.to('cuda')
else:print('cuda is NO!')reconstruction_function = nn.MSELoss(size_average=False)
# reconstruction_function = nn.MSELoss(reduction=sum)def loss_function(recon_x, x, mu, logvar):"""recon_x: generating imagesx: origin imagesmu: latent meanlogvar: latent log variance"""BCE = reconstruction_function(recon_x, x) # mse loss# loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)KLD = torch.sum(KLD_element).mul_(-0.5)# KL divergencereturn BCE + KLDoptimizer = optim.Adam(model.parameters(), lr=1e-3)for epoch in range(num_epochs):model.train()train_loss = 0for batch_idx, data in enumerate(dataloader):img, _ = dataimg = img.view(img.size(0), -1)img = Variable(img)img = (img.cuda() if torch.cuda.is_available() else img)optimizer.zero_grad()recon_batch, mu, logvar = model(img)loss = loss_function(recon_batch, img, mu, logvar)loss.backward()# train_loss += loss.data[0]train_loss += loss.item()optimizer.step()if batch_idx % 100 == 0:endtime = datetime.datetime.now()print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f} time:{:.2f}s'.format(epoch,batch_idx * len(img),len(dataloader.dataset), 100. * batch_idx / len(dataloader),loss.item() / len(img), (endtime-strattime).seconds))print('====> Epoch: {} Average loss: {:.4f}'.format(epoch, train_loss / len(dataloader.dataset)))if epoch % 10 == 0:save = to_img(recon_batch.cpu().data)save_image(save, './vae_img/image_{}.png'.format(epoch))torch.save(model.state_dict(), './vae.pth')