文章目录
- 1. 需求 / 现存问题
- 2. 总述
- 3. 实现
- 3.1 概述
1. 需求 / 现存问题
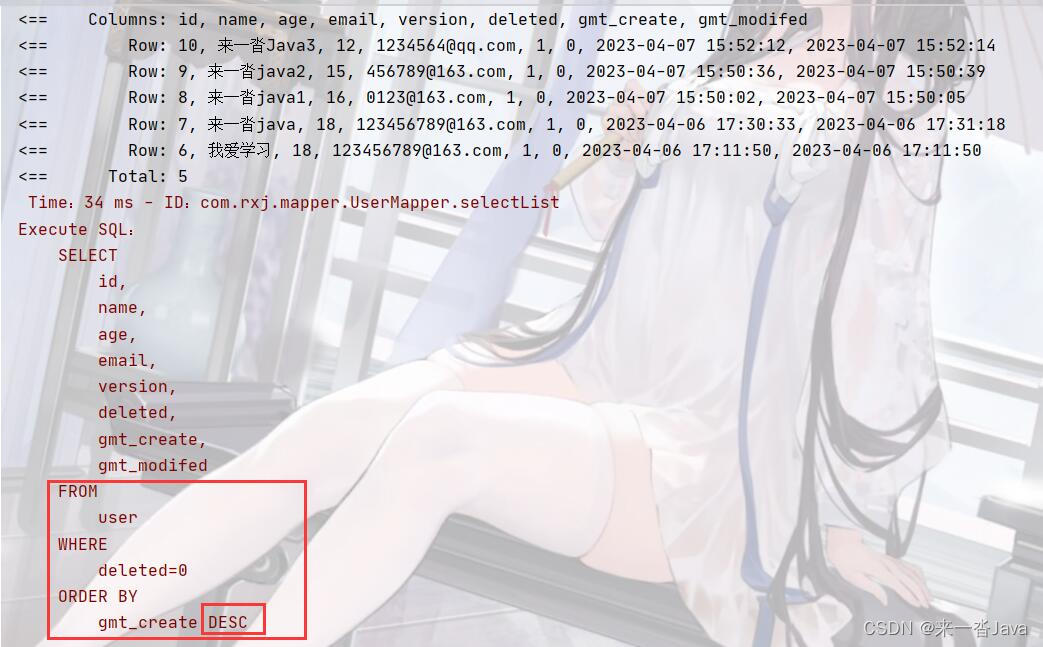
输入数据通常很大,为了在合理的时间内完成计算,必须将计算分布到数百或数千台机器上。
如何并行化计算、分发数据和处理故障等问题使得原本简单的计算变得晦涩难懂,需要大量复杂的代码来处理这些问题。
2. 总述
提出了一种新的抽象化方法,使我们能够表达我们试图执行的简单计算,同时隐藏了并行化、容错、数据分发和负载平衡等混乱的细节。
- 大多数的计算都涉及对输入中的每个逻辑“记录”应用一个map操作,以计算一组中间键/值对;
- 然后对所有共享相同键的值应用reduce操作,以适当地组合导出的数据。
- 使用基于函数式编程模型的用户指定map和reduce操作的方法,使我们能够轻松地并行化大型计算,并将重新执行作为容错的主要机制。
这篇文章最终提供了简单而强大的接口,用户可以实现这个接口来应用于自己的业务。
3. 实现
MapReduce接受一组输入键值对,并输出一组键值对。将其表示为两个函数:Map和Reduce,均由用户编写。
- Map:接收一个输入键/值对,并生成一组中间键/值对。MapReduce库将所有与相同中间键
I相关联的中间值组合在一起,并将它们传递给Reduce函数。 - Reduce:接受一个中间键
I和该键对应的一组值,并将这些值合并在一起以形成可能更小的一组值。通常,每次Reduce调用只会生成零个或一个输出值。中间值通过迭代器提供给用户的Reduce函数,这使得我们能够处理太大而无法放入内存的值列表。
举个例子——倒排索引:
- Map函数:解析每个文档,并发出一个
<单词序列,文档ID>对。 - Reduce函数:接受给定单词的所有对,对相应的文档ID进行排序,并发出一个
<word, list(文档ID)>对。
所有输出对的集合形成一个简单的倒排索引。很容易扩大这个计算来跟踪单词的位置。
3.1 概述
- Map调用:
- Map调用分布在多台机器上。
- 将输入数据自动划分为M个块,
- 输入的块可以由不同的机器并行处理。
- Reduce调用:是通过使用分区函数(例如,hash(key) mod R)将中间键空间划分为R块来分配的。分区的数量®和分区函数由用户指定。
MapReduce操作的总体流程如图:
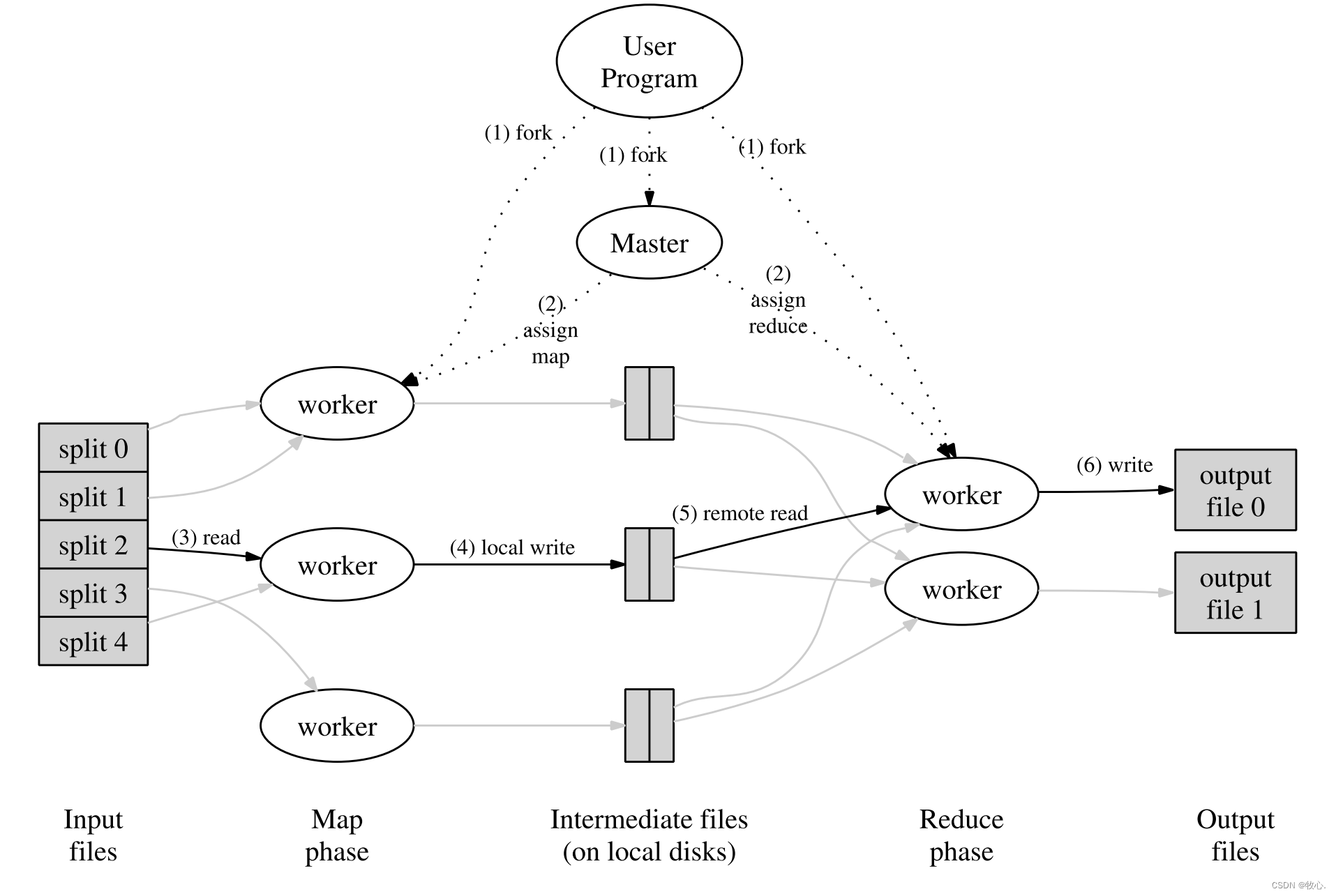
- (1)用户程序中的MapReduce库首先将输入文件分割成M块,通常为16MB到64MB(用户可以通过一个可选参数进行控制)。然后在一组机器上启动程序的许多副本。
- (2)程序的一个副本是特殊的——主副本(master)。其余的worker是由master分配任务的worker。有M个map任务和R个reduce任务需要分配。master会挑选空闲的worker,给每个worker分配一个map任务或者reduce任务。
- (3)被分配一个map任务的worker读取相应的输入块的内容。它从输入数据中解析键/值对,并将每个键/值对传递给用户定义的Map函数。Map函数产生的中间键/值对被缓冲在内存中。
- (4)周期性地将缓冲对写入本地磁盘,通过分区函数将缓冲对划分为R个区域。将这些缓冲对在本地磁盘上的位置传递回master,master负责将这些位置转发给reduce worker。
- (5)当master通知reduce worker这些位置时,它使用rpc(远程过程调用)从map worker的本地磁盘读取缓冲数据。当reduce worker读取了所有中间数据后,它会根据中间键对数据进行排序,这样 所有相同键的occurrences(这里的occurrences,博主认为可以是映射为相同的key的任何形式的数据)都会被分组到一起。并且这里的排序过程是有必要的,因为通常有许多不同的键映射到同一个reduce任务。如果中间数据的数量太大而无法装入内存,则使用外部排序。
- (6)reduce worker遍历排序的中间数据,对于遇到的每个唯一的中间键,它将键和相应的中间值集传递给用户的reduce函数。Reduce函数的输出被追加到这个Reduce分区的最终输出文件中。
- (7)当所有map任务和reduce任务完成后,master将唤醒用户程序。此时,用户程序中的MapReduce调用返回到用户代码。
成功完成后,MapReduce执行的输出存储在R文件中以供使用(每个reduce任务会有一个输出文件,文件名由用户指定)。通常,用户不需要将这些R输出文件合并到一个文件中——他们通常将这些文件作为输入传递给另一个MapReduce调用,或者从另一个分布式应用程序中使用它们(该应用程序能够处理划分为多个文件的输入)。
后续追更……