目录
Linux设备分类
字符设备驱动基础
字符设备驱动框架
虚拟串口设备
Linux设备分类
Linux系统根据驱动程序实现的模型框架将设备驱动分为下面三种。
(1)字符设备驱动:设备对数据的处理是按照字节流的形式进行的,可以支持随机访问,也可以不支持随机访问,因为数据流量通常不是很大,所以一般没有页高速缓存典型的字符设备有串口、键盘、帧缓存设备等。以串口为例,串口对收发的数据长度没有具体要求,可以是任意多个字节;串口也不支持 lseek操作,即不能定位到一个具体的位置进行读写,因为串口按顺序发送或接收数据;串口的数据通常保存在一个较小的FIFO中,并且不会重复利用FIFO中的数据。帧缓存设备(就是我们通常说的显卡)也是一个字符设备,但它可以进行随机访问,这样我们就能修改某个具体位置的帧缓存数据,从而改变屏幕上的某些确定像素点的颜色。
(2)块设备驱动:设备对数据的处理是按照若干个块进行的,一个块有其固定的大小,比如为4096 字节,那么每次读写的数据至少就是4096 字节。这类设备都支持随机访问,并且为了提高效率,可以将之前用到的数据缓存起来,以便下次使用。典型的块设备有硬盘、光盘、SD卡等。以硬盘为例,一个硬盘的最小访问单位是一个扇区,一个扇区通常是512 字节,那么块的大小至少就是512字节。我们可以访问硬盘中的任何一个扇区,也就是说,硬盘支持随机访问。因为硬盘的访问速度非常慢,如果每次都去礤盘上获取数据,那么效率会非常低,所以一般将之前从硬盘上得到的数据放在一个叫作页高速缓存的内存中,如果程序要访问的数据是之前访问过的,那么程序会直接从页高速缓存中获得数据,从而提高效率。
(3)网络设备驱动:顾名思义,它就是专门针对网络设备的一类驱动,其主要作用是进行网络数据的收发。
以上驱动程序的分类是按照驱动的模型框架进行的,在现实生活中,有的设备很难被严格界定是字符设备还是块设备。甚至有的设备同时具有两类驱动,如MTD(存储技术设备,如闪存)。一个设备的驱动属于上述三类中的哪一类,还要看具体的使用场合和最终的用途。
字符设备驱动基础
在正式学习字符设备驱动的编写之前,我们首先来看看相关的基础知识。在类UNIX系统中,有一个众所周知的说法,即“一切皆文件”,当然网络设备是一个例外。这就意味着设备最终也会体现为一个文件,应用程序要对设备进行访问,最终就会转化为对文件的访问,这样做的好处是统一了对上层的接口。设备文件通常位于/dev目录下,使用
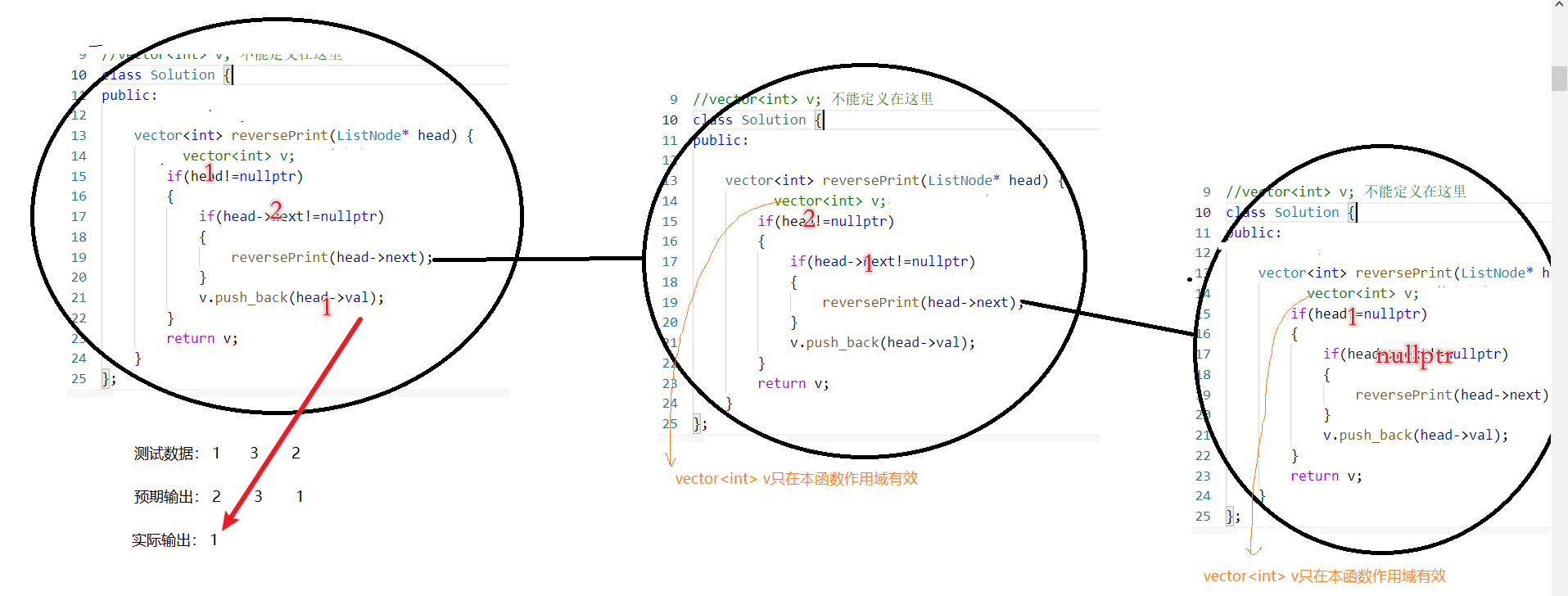
下面的命令可以看到很多设备文件及其相关的信息。
$ls -l /dev
我的ubuntu里面有很多的设备,要是新移植的内核则应该是很少
我收回,他更多。。。。。
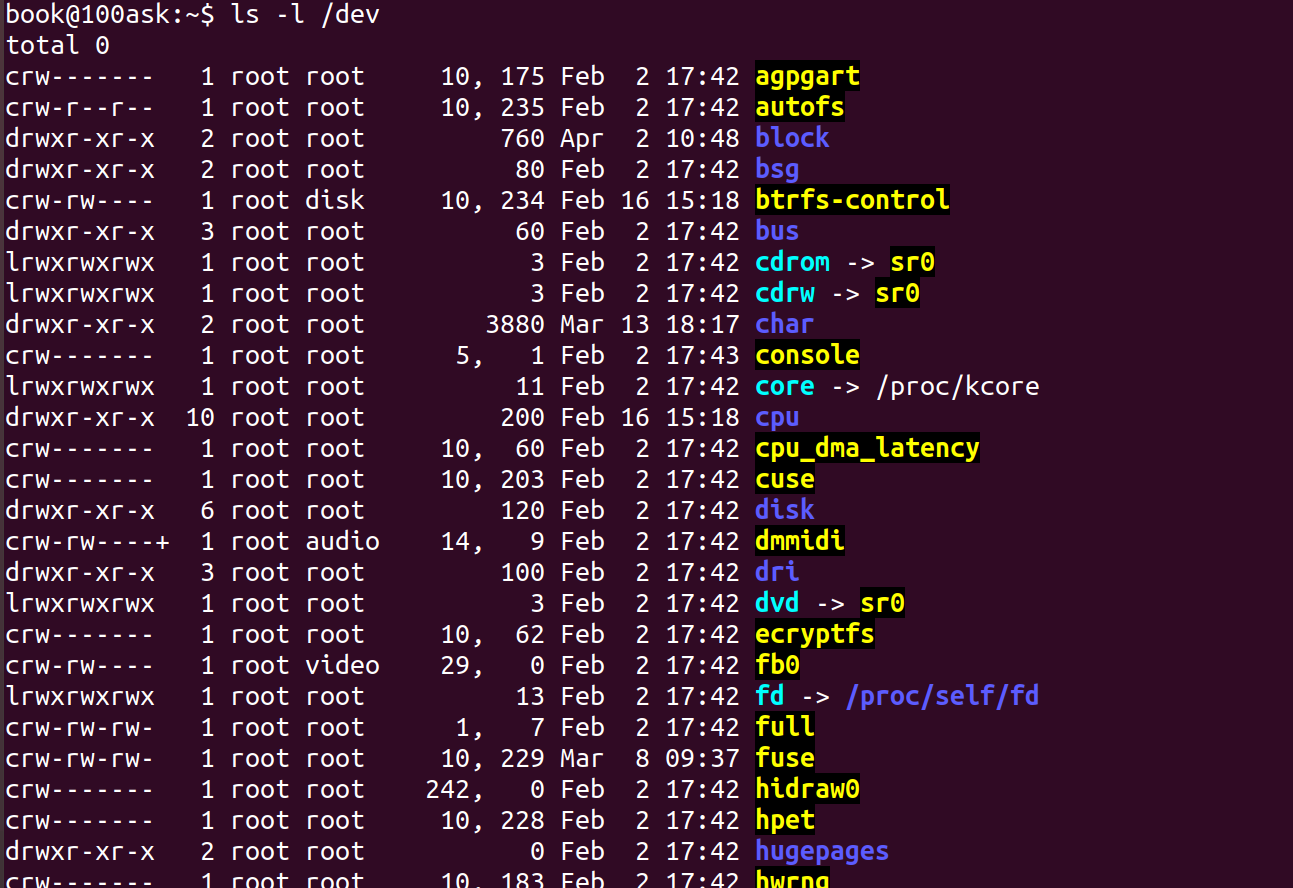

在上面列出的信息中,前面的字母“b”表示是块设备,“c”表示是字符设备。比如 sda、sdal、sda2、sda5 就是块设备,实际上这些设备是 Ubuntu主机上的一个硬盘和这个硬盘上的三个分区,其中 sda表示的是整个硬盘,而sda1、sda2、sda5分别是三个分区。tty0、tty1就是终端设备,shell 程序使用这些设备来同用户进行交互。从上面的打印信息来看,设备文件和普通文件有很多相似之处,都有相应的权限、所属的用户和组、修改时间和名字。但是设备文件会比普通文件多出两个数字,这两个数字分别是主设备号和次设备号。这两个号是设备在内核中的身份或标志,是内核区分不同设备的唯一信息。通常内核用主设备号区别一类设备,次设备号用于区分同一类设备的不同个体或不同分区。而路径名则是用户层用于区别设备信息的。
在现在的 Linux系统中,设备文件通常是自动创建的。即便如此,我们还是可以通过mknod命令来手动创建一个设备文件,如下所示。
mknod /dev/vser0 c256 0
ls -li /dev/vser0
126695 crw-r--r-- 1 root root 256, 0 Ju1 13 10:03 /dev/vsez0
我的是540

删除的话他是一个文件用文件的方式删掉就行
那么mknod 命令具体做了什么呢?mknod是make node的缩写,顾名思义就是创建了一个节点(所以设备文件有时又叫作设备节点)。在Linux系统中,一个节点代表一个文件,创建一个文件最主要的根本工作就是分配一个新的节点(注意,这是存在于磁盘上的节点,之后我们还会看到位于内存中的节点inode),包含节点号的分配(节点号在一个文件系统中是唯一的,可以以此来区别不同的文件。如上面ls命令的i选项就列出了/dev/vser0设备的节点号为126695),然后初始化好这个新节点(包含文件模式、访问时间、用户ID、组ID等元数据信息,如果是设备文件还要初始化好设备号),再将这个初始化好的节点写入磁盘。还需要在文件所在目录下添加一个目录项,目录项中包含了前面分配的节点号和文件的名字,然后写入磁盘。存在于磁盘上的这个节点用一个结构封装,下面以Linux 系统中最常见的 ext2文件系统为例进行说明。
/*fs/ext2/ext2.h */
294 /*
295 * Structure of an inode on the disk296·/
297 struct ext2_inode (
298 __le16 1_mode; /* File mode */
299 __le16 i_uid; /* Low 16 bits of Owner Uid */
300 __le32 i_size; /* Size in bytes */
301 __le32 i atime; /* Access time */
302 __le32 i_ctimei /* Creation time */
303 __le32 i mtime: /* Modification time */...
320 __le32 i_block(EXT2 N_BLOCKS)i/’ Pointers to blocks */
...
349};
ext2_inode 是最终会写在磁盘上的一个 inode,可以很清楚地看到,刚才所述的元数据信息包含在该结构中。另外,对于i_block成员来说,如果是普通文件,则这个数组存放的是真正的文件数据所在的块号(可以看成对文件数据块的索引,所以ext2照索引方式存储文件,其性能远远优于FAT格式);
现在已经优化到ext4了他们的区别如下:
文件系统之ext2,ext3和ext4
如果是设备文件,这个数组则被用来存放设备的主次设备号,可以从下面的代码得出结论。
/*fs/ext2/inode.c*
1435 static int __ext2_write_inode(struct inode *inode, int do_syne)14361
1443 struct ext2 inode * raw inode - ext2 get inode(sb, ino, &bh);
1456 raw_inode->i_mode - cpu_to_le16(inode->i_mode);
1513 if (s_ISCHR(inode->i_mode) I| s_ISBLK(inode->1_mode)) (
1514 if (old valid dev(inode->i_rdev)){
1515 raw inode->i block[0] ~
1516 cpu to 1e32(old encode dev(inode->i_rdev));
1517 raw inode->i block[1]- 0;
1518 ) else(
1519 raw inode->i block[0]-0;
1520 raw inode->i block[1]=
1521 cpu_to_le32 (new encode dev(inode->i rdev));
1522 raw inode->i block[2]-0;
1523}..
}
代码1443行获得了一个要写入磁盘的 ext2_inode结构,并初始化了部分成员,代码第1513行到1523行,判断了设备的类型,如果是字符设备或块设备,那么将设备号写入i_block的前2个或前3个元素,其中ionde的irdev成员就是设备号。而这里的inode是存在于内存中的节点,是涉及文件操作的一个非常关键的数据结构,关于该结构我们之后还要讨论,这里只需要知道写入磁盘中的ext2inode结构内的成员基本上都是靠存在于内存中的inode中对应的成员初始化的即可,其中就包含了这里讲的设备号。之前我们说过,设备号有主、次设备号之分,而这里的设备号只有一个。原因是主、次设备号的位宽有限制,可以将两个设备号合并,之后我们会看到相应的代码。在代码1456行我们可以看到,文件的类型也被保存在了 ext2 inode结构中,并且写在了磁盘上。
刚才还谈到了需要在文件所在目录下添加目录项,这又是怎么完成的呢?在Linux系统中,目录本身也是一个文件,其中保存的数据是若干个目录项,目录项的主要内容就是刚才分配的节点号和文件或子目录的名字,在 ext2 文作系统中,写入磁盘的目录项数据结构如下。
/.fs/ext2/ext2.h*/
574 /*
575 * structure of a directory entry576./577
578 struct ext2_dir_entry (
579 __le32 inode; /* Inode number */
580 __le16 rec_len;/* Directory entry length */
581 __le16 name_len;/* Name length */
582 char name[1]; /* File name, up to EXT2_NAME LEN */
583 };
上面的inode 成员是节点号,name成员就是文件或子目录的名字。具体的代码实现可以参考“fs/ext2/namei.c”的 ext2_mknod 函数,在此不再赘述。可以通过图 3.1来说明mknod 命令在 ext2文件系统上所完成的工作。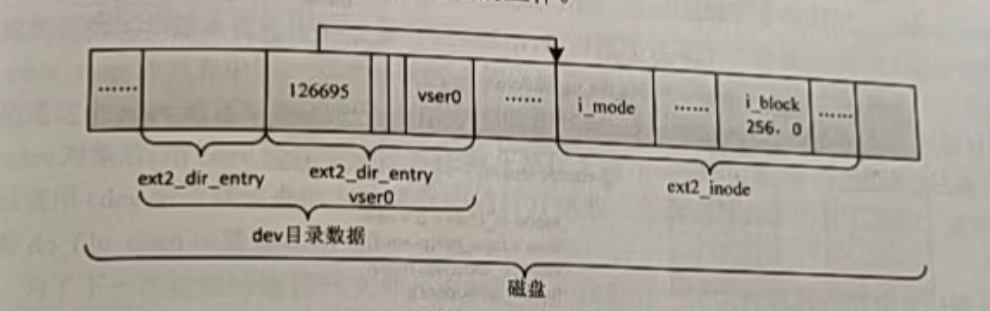
图3.1 创建设备文件示意图
上面的整个过程,一言以蔽之就是mknod 命令将文件名、文件类型和主、次设备号等信息保存在了磁盘上。
接下来我们来讨论如何打开一个文件,这是理解上层应用程序和底层驱动程序如何建立联系的关键,也是理解字符设备驱动编写方式的关键。整个过程非常烦琐,涉及的数据结构和相关的内核知识非常多。为了便于大家理解,下面将该过程进行大量简化,并以图 3.2和调用流程来进行说明。
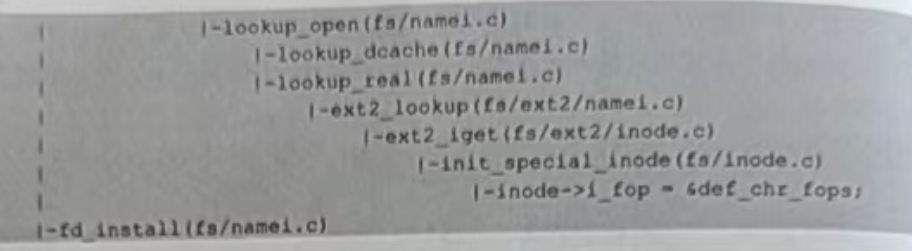
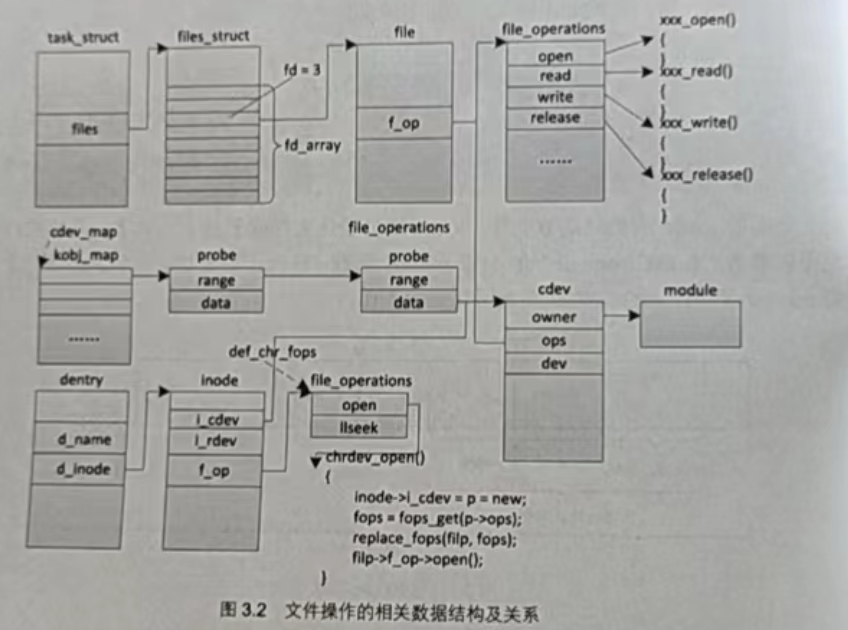
在内核中,一个进程用一个 task_struct 结构对象来表示,其中的 files 成员指向了一个files_struct结构变量,该结构中有一个fd_array的指针数组(用于维护打开文件的信息),数组的每一个元素是指向 file 结构的一个指针。open 系统调用函数在内核中对应的函数是sys_open,sys_open 调用了 do_sys_open,在do_sys_open 中首先调用了 getname 函数将文件名从用户空间复制到了内核空间。接着调用 get_unused_fd_flags 来获取一个未使用的文件描述符,要获得该描述符,其实就是搜索 files_struct 中的 fd_array 数组,查看哪一个元素没有被使用,然后返回其下标即可。接下来调用 do_filp_open 函数来构造一个 file结构,并初始化里面的成员。其中最重要的是将它的 f_op 成员指向和设备对应的驱动程序的操作方法集合的结构 file_operations,这个结构中的绝大多数成员都是函数指针,通过 file_operations 中的open 函数指针可以调用驱动中实现的特定于设备的打开函数,从而完成打开的操作。do_filp_open 函数执行成功后,调用 fd_install 函数,该函数将刚才得到的文件描述符作为访问 fd_array 数组的下标,让下标对应的元素指向新构造的 file 结构.最后系统调用返回到应用层,将刚才的数组下标作为打开文作的文件播送特返回。
do_filp_open 函数包含的内容很多,是这个过程中最复杂的一能分,下面进行一下非常简化的介绍。do_filp_open 函数调用 path_openat来进行实际的打开操作,path_openat调用get_empty_filp快速得到一个 file结构,再调用 link_path_walk 来处理文件路径中除最后一个分量的前面部分。举个例子来说,如果要打开/dev/vser0这个文件,那么link_path_walk 需要处理/dev 这部分,包合根目录和 dev 目录。接下来path_openat 调用do_last 来处理最后一个分量,do_last 首先调用 lookup_fast 在 RCU 模式下来尝试快速查找,如果第一次这么做会失败,所以继续调用lookup_open ,而lookup_open首先调用lookup_dcache 在目录项高速缓存中进行查找,第一次这么做也会失败,所以转而调用lookup_real,lookup_real 则在磁盘上真正开始查找最后一个分量所对应的节点,如果是ext2文件系统,则会调用 ext2_lookup,得到 inode 的编号后,ext2_lookup 又会调用ext2_iget 从磁盘上获取之前使用 mknod 保存的节点信息。对字符设备驱动来说,这里最重要的就是将文件类型和设备号取出并填充到了内存中的 inode 结构的相关成员中。另外,通过判断文件的类型,还将 inode 中的 f_op 指针指向了 def_chr_fops,这个结构中的open 函数指针指向了 chrdev_open,那么自然 chrdev_open 紧接着会被调用。chrdev_open完成的主要工作是:首先根据设备号找到添加在内核中代表字符设备的 cdev(cdev是放在 cdev_map 散列表中的,驱动加载时会构造相应的 cdev 并添加到这个散列表中,并且在构造这个 cdev 时还实现了一个操作方法集合,由 cdev 的 ops 成员指向它),找到对应的cdev 对象后,用 cdev 关联的操作方法集合替代之前构造的 file结构中的操作方法集合,然后调用cdev 所关联的操作方法集合中的打开函数,完成设备真正的打开操作,这也标志着 do_filp_open 函数基本结束。
为了下一次能够快速打开文件,内核在第一次打开一个文件或目录时都会创建一个dentry 的目录项,它保存了文件名和所对应的 inode 信息,所有的 dentry 使用散列的方式存储在目录项高速缓存中,内核在打开文件时会先在这个高速缓存中查找相应的 dentry,如果找到,则可以立即获取文件所对应的 inode,否则就会在磁盘上获取.
对于字符设备驱动来说,设备号、cdev 和操作方法集合至关重要,内核找到路径名所对应的 inode后,要和驱动建立连接,首先要做的就是根据 inode 中的设备号找到cdev然后根据cdev找到关联的操作方法集合,从而调用驱动所提供的操作方法来完成对设备的具体操作。可以说,字符设备驱动的框架就是围绕着设备号、cdev 和操作方法集合来实现的。
虽然设备的打开操作很烦琐,但是其他系统的调用过程就要简单很多。因为打开操作返回了一个文件描述符,其他系统调用时都会以这个文件描述符作为参数传递给内核,内核得到这个文件描述符后可以直接索引 fd_array,找到对应的 file 结构,然后调用相应的方法。
(cdev就是一个结构体)
字符设备驱动框架
通过上一节的分析我们知道,要实现一个字符设备驱动,最重要的事就是要构造个cdcv结构对象,并让cdev同设备号和设备的操作方法集合相关联,然后将该cdev结构对象添加到内核的cdevmap散列表中。下面我们步来实现这一过程,首先就是在照动中注册设备号,代码如下
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>#include <linux/fs.h>#define VSER_MAJOR 256
#define VSER_MINOR 0
#define VSER_DEV_CNT 1
#define VSER_DEV_NAME "vser"static int __init vser_init(void)
{int ret;dev_t dev;dev = MKDEV(VSER_MAJOR,VSER_MINOR);ret = register_chrdev_region(dev, VSER_DEV_CNT, VSER_DEV_NAME);if((ret)goto reg_err;return 0;
reg_err:return ret;
}static void __exit vser_exit(void)
{dev_t dev;dev = MKDEV(VSER_MAJOR,VSER_MINOR);unregister_chrdev_region(dev, VSER_DEV_CNT);
}module_init(vser_init);
module_exit(vser_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("name <E-mail>");
MODULE_DESCRIPTION("A simple module");
MODULE_ALIAS("virtual-serial");
在模块的初始化函数中,首先在代码第17使用KDEV宏将主设备号和次设备号。在3.14.25 版本的内核源码中,相关的宏定义如下。

不难发现,该宏的作用是将主设备号左移 20 和次设备号相或。在当前内核版本中,dev_t是一个无符号的32整数,很自然的,设备号占12位,次设备号占20位。另外还有两个宏为MAJOR 和 MINOR,它们分别是从设备号中取出主设备号和次设备号的两个宏。尽管我们知道设备号是怎样构成的,但是我们在代码中不应该自己来构造设备号,而是应该调用相应的宏,因为不能保证以后的内核会改变这一规则。
构造好设备号之后,代码第 18 行调用register_chrdev_region 将构造的设备号注册到内核中,该设备号已经被占用,如果有其他驱动随后要注册该设备号,将会失败。其函数原型如下。
int register chrdev region(dev t from, unsigned count, const char *name);
该函数一次可以注册多个连续的号,由 count 形参指定个数,由 from指定起始的设备号,name 名。该数成功则返回,不成功则返回负数,返回负数通常是因为要注册的设备号已经被其他的驱动抢先注册了。如果注册出错,则使用 goto语句转到错误处理代码处执行,否则初始化函数返回 0.使用 goto 函数进行集中错误处理在驱动中非常常见,也非常实用,虽然这和一般的C语言编程规则相悖。
在卸载模块时,已注册的号应该从内核中注销,否则再次加载该驱动时,注册设备号操作会失败。代码第 33 行调用了unregister_chrdev_region 函数,该函数只有两个形参和register_chrdev_region函数的前两个形参的意义一样。
上面的代码再一次印证了前面所说的内容,即在模块初始化函数中负责注册、分配内存等操作,而在模块清除函数中负责相反的操作,即注销、释放内存等操作。以上的代码可以编译并进行测试,在Ubuntu主机上测试的步骤如下(在ARM目标板上的测试和前面所讲的模块在ARM目标板上测试的过程类似)。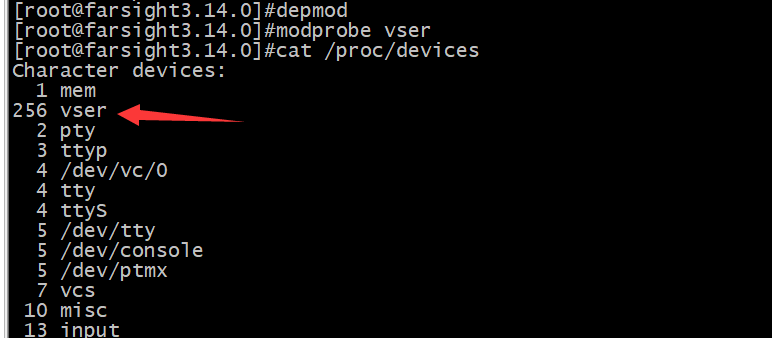
我比较懒写了个脚本拷贝。
使用register_chrdev_region注册设备号的方式为静态注册,该方式有一个明显的缺点,就是如果两个驱动都使用了同样的设备号,那么后加载的驱动将会失败,因为设备号冲突了。为了解决这个问题,可以使用动态分配设备号的函数,其原型如下。
int alloc chrdev region(devt *dev, unsigned baseminor, unsigned count,const char *name);
其中,count 和name 形参同register_chrdev_region数中相应的形参一致。baseminor是动态分配的设备号的起始次设备号,而dev是分配得到的第一个设备号。该函数成功则返回0,失败则回负数。这样就避免了各个驱动使用相同的设备号而带来的冲突,但是会存在另外一个问题,那就是不能事先知道主次设备号,在使用mknod命令创建设备节点时,必须先查看/proc/devices确设备号设备号在代码中确定),也就是要求mknod命后于驱动加载执行,这个问题在新的Linux已经得到了比较好的解决,设备节点会自动地创建和销毁,这在后面的章节会详细描述。
成功地注册了设备号,接下来应该构造并添加cdev结构对象,其代码如下
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>#include <linux/fs.h>
#include <linux/cdev.h>#define VSER_MAJOR 256
#define VSER_MINOR 0
#define VSER_DEV_CNT 1
#define VSER_DEV_NAME "vser"static struct cdev vsdev;static struct file_operations vser_ops = {.owner = THIS_MODULE,
};static int __init vser_init(void)
{int ret;dev_t dev;dev = MKDEV(VSER_MAJOR,VSER_MINOR);ret = register_chrdev_region(dev, VSER_DEV_CNT, VSER_DEV_NAME);if(ret)goto reg_err;cdev_init(&vsdev, &vser_ops);vsdev.owner = THIS_MODULE;ret = cdev_add(&vsdev, dev, VSER_DEV_CNT);if (ret)goto add_err;return 0;add_err:unregister_chrdev_region(dev, VSER_DEV_CNT);reg_err:return ret;
}static void __exit vser_exit(void)
{dev_t dev;dev = MKDEV(VSER_MAJOR,VSER_MINOR);cdev_del(&vsdev);unregister_chrdev_region(dev, VSER_DEV_CNT);
}module_init(vser_init);
module_exit(vser_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("name <E-mail>");
MODULE_DESCRIPTION("A simple module");
MODULE_ALIAS("virtual-serial");
在上面的代码中,第13行定义了一个structcdev类型的全局变量vsdev。代码第15行到第17行定义了一个 struct file_operations 类型的全局变量vser_ops。我们知道,这两个数据结构是实现字符设备驱动的关键。其中,vsdev代表了一个具体的字符设备,而 vser_ops 是操作该设备的一些方法。代码第 29 行调用 cdev_init函数初始化了 vsdev中的部分成员。另外一个最重要的操作就是将 vsdev中的ops 指针指向了 vser_ops,这样通过设备号找到vsdev对象后,就能找到相关的操作方法集合,并调用其中的方法。cdev init函数的原型如下,第一个参数是要初始化的 cdev地址,第二个参数是设备操作方法集合的结构地址。
void cdev init(struct cdev *cdev, const struct file operations *fops);
代码第16行和第30行都将一个owner成员赋值为THIS_MODULE,owner 是一个指向struct module类型变量的指针,THIS_MODULE 是包含驱动的模块中的 struct module类型对象的地址,类似于 C++中的 this 指针。这样就能通过 vsdev 或 vser_fops 找到对应的模块,在对前面两个对象进行访问时都要调用类似于try_module_get的函数增加模块的引用计数,因为在这两个对象使用的过程中,模块是不能被卸载的,模块被卸载的前提条件是引用计数为0。
cdev对象初始化以后,就应该添加到内核中的cdev_map散列表中,调用的函数cdev_add,其函数原型如下。
int cdev add(struct cdev *p, dev t dev, unsigned count);
根据前面的几个函数原型,不难得出该函数的各个形参的意义。cdev_add 函数的主要工作是将主设备号通过对255取余,将余数作为cdev_map数组的下标索引,然后构造一个probe 对象,并让data指向要添加的cdev结构地址,然后加入到链表当中(见图3.2)该函数的最后一个参数count 指定了被添加的cdev可以管理多少个设备。这里需要特别注意的是,参数p只指向一个 cdev 对象,但该对象可以同时管理多个设备,由 count 的值来决定具体有多少个设备,那么cdev和设备就不是一一对应的关系。这样,对于一个驱动支持多个设备的情况,我们可以采用两种方法来实现,第一种方法是为每一个设备分配一个cdev 对象,每次调用cdev_add添加一个 cdev对象,直到多个cdev对象全部被添加到内核中;第二种方法是只构造一个cdev对象,但在调用cdev_add时,指定添加的 cdev可以管理多个设备。这两种方法我们在后面的例子中都会看到。以上是简化的讨论,实际的实现要复杂一些,如果要详细了解,请参考 cdev_add的内核源码。
在初始化函数中添加了cdev对象,那么在清除函数中自然就应该删除该cdev对象代码第51行演示了这一操作,实现的函数是cdev_del,其函数原型如下。该函数的作用就是根据cdev找到散列表中的probe,并进行删除。
void cdev del(struct cdev *p);
在上述的示例代码中,cdev对象是静态定义的,我们也可以进行动态分配,对应的函数是cdev_alloc,其函数原型如下。
struct cdev *cdev alloc(void);
该函数成功则返回动态分配的cdev对象地址,失败则返回NULL
上面的代码基本上实现了一个字符设备驱动程序的框架,即使目前还没有任何实际意义,但是还是能够对之进行操作了,其相关的命令如下。
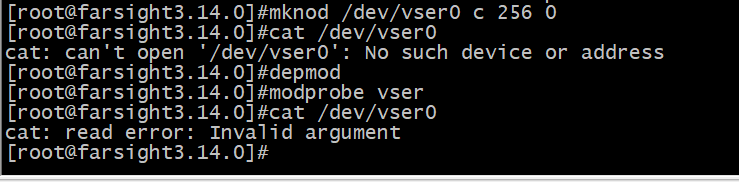
从上面的操作可以看到,在未加载驱动之前,使用 cat 命令读取/dev/vser0设备错误信息是设备找不到,这是因为找不到和设备号对应的 cdev对象。在加载驱动后cat 命令的错误信息变成了参数无效,说明驱动工作了,只是还未实现具体的设备操作的方法。
虚拟串口设备
在进一步实现字符设备驱动之前,我们先来讨论一
下本书中用到的一个虚拟串口设备。这个设备是驱动代码虚拟出来的,不能实现真正的串口数据收发,但是它能够接收用户想要发送的数据,并且将该数据原封不动地环回给串口的收端,使用户也能从该串口接收数据。也就是说,该虚拟串口设备是一个功能弱化之后的只具备内环回作用的串口,如图 3.3所示
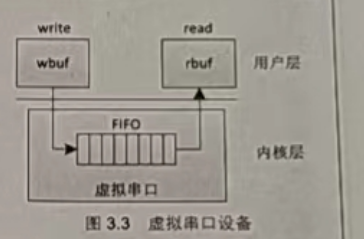
这一功能的实现,主要是在驱动中实现一个FIFO,驱动接收用户层传来的数据,然后将之放入FIFO,当应用层要获取数据时,驱动将 FIFO中的数据读出,然后复制给应用层。一个更贴近实际的形式应该是在驱动中有两个FIFO一个用于发送,一个用于接收,但是这并不是实现这个简单的虚拟串口设备驱动的关键,所以为了简单起见,这里只用了一个FIFO。
内核中已经有了一个关于FIFO 的数据结构 struct kfifo,相关的操作宏或函数的声明、定义都在“include/linux/kfifo.h”头文件中,下面将最常用的宏罗列如下。
DEFINE KFIFO(fifo, type, size)
kfifo_from_user(fifo, from, len, copied)kfifo to user(fifo, to, len, copied)
DEFINE_KFIFO 用于定义并初始化一个FIFO,这个变量的名字由 fifo 参数决定,type是FIFO 中成员的类型,size 则指定这个 FIFO 有多少个元素,但是元素的个数必须是2的幂。
kfifo_from_user 是将用户空间的数据(from)放入 FIFO 中,元素个数由 len 来指定,实际放入的元素个数由 copied 返回。
kfifo_to_user 则是将 FIFO 中的数据取出,复制到用户空间(to)。len和copied的含义同kfifo_from user中对应的参数。