深度学习-第R3周——天气预测
- 深度学习-第R3周——天气预测
- 一、前言
- 二、我的环境
- 三、导入数据集
- 三、探索式数据分析
- 1、数据相关性探索
- 2、是否会下雨
- 1、预测明天是否会下雨
- 2、预测今天是否会下雨
- 3、探索两个分类变量之间的关系。
- 4、 归一化处理,以生成百分比形式的数据。
- 4、绘图
- 3、地理位置与下雨的关系
- 4、湿度和压力对下雨的影响
- 5、气温对下雨的影响
- 四、数据集预处理
- 1、处理缺失值
- 1、计算每列中确实数据的百分比
- 2、在该列中随机选择数进行填充
- 3、寻找数据集中所有的 object 类型的列
- 4、填充
- 2、构建数据集
- 五、预测是否会下雨
- 1、搭建神经网络
- 2、模型训练
- 3、结果可视化
深度学习-第R3周——天气预测
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:Tensorflow
三、导入数据集
.head 用于显示数据集的前几行。
head() 方法接受一个整数参数 n(默认值为 5),指示要显示数据集的前 n 行。例如,如果使用 data.head(10) 则会显示数据集的前 10 行数据。
import numpy as np
import pandas as pd
import seaborn as sns
#Seaborn是基于matplotlib的Python可视化库。它提供了一个高级界面来绘制有吸引力的统计图形。
#Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,不需要经过大量的调整就能使你的图变得精致
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
from tensorflow.keras.callbacks import EarlyStoppingdata = pd.read_csv("weatherAUS.csv")
df = data.copy()
data.head()
Pandas 库中 DataFrame 对象的一个方法,用于计算每个数值列的基本描述统计信息。
.describe() 方法将数据集的各个统计量以表格形式展示出来,其中包括:
count:非缺失值的数量。
mean:平均值。
std:标准差。
min:最小值。
25%:第一四分位数。
50%:中位数(第二四分位数)。
75%:第三四分位数。
max:最大值。
默认情况下,.describe() 只会计算数值特征的描述性统计量,如果需要包括所有特征,可以使用 include=‘all’ 参数。还可以使用 exclude 参数排除某些特征的统计量
data.describe()
data.dtypes

to_datetime() 函数将数据集 data 中的 ‘Date’ 列转换为 Pandas 中的时间序列格式,即 datetime64。
datetime64 格式是一种高效的时间序列类型,可以存储具有纳秒级精度的时间戳,并支持向量化计算和时间序列操作。to_datetime() 函数会解析输入的字符串或数字类型的日期并将其转换为 datetime64 类型。
data['Date'] = pd.to_datetime(data['Date'])
data['Date']
'''
将转换后的时间序列赋值回 'Date' 列,以更新数据集的内容。这意味着我们现在可以使用 Pandas 库中的内置函数处理该时间序列,例如获取年份、月份、季度或星期几等信息,或绘制基于时间的折线图、柱状图等。最后,打印 'Date' 列时,会显示转换后的日期格式,因为 datetime64 类型在显示时会格式化为日期字符串。
'''

Pandas 库中的 dt 属性及其包含的 year、month 和 day 子属性将 data 数据集中的 ‘Date’ 列扩展为年、月和日三列。
.dt 属性提供了一种简单而有效的方式来访问 Pandas 时间序列类型的相关属性
data['year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['day'] = data['Date'].dt.day
data.head()
'''
在这里,我们使用 .dt.year、.dt.month 和 .dt.day 属性获取由 'Date' 列中的日期信息生成的年、月和日,然后将每个新列赋值给原始数据集。通过将时间列扩展到年、月和日,我们可以更轻松地对数据进行分组和聚合
'''
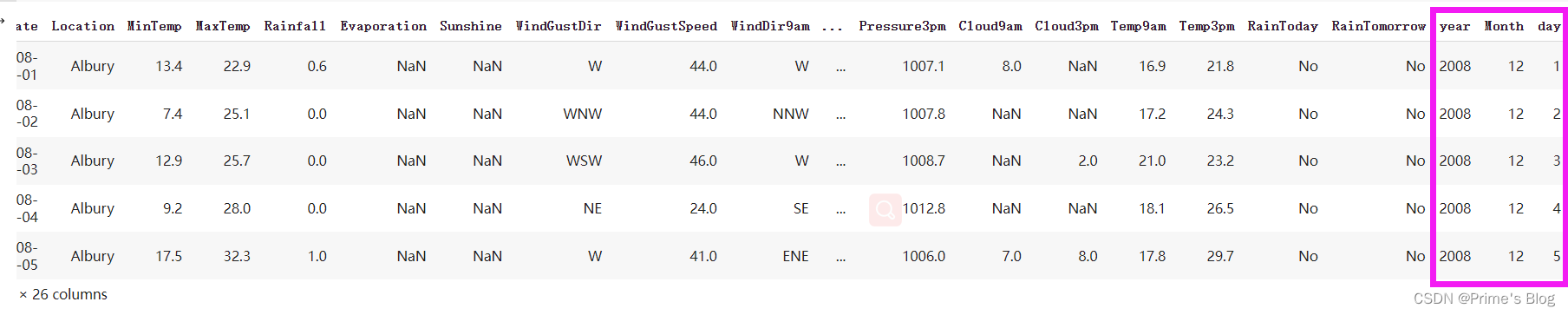
drop() 函数删除了 data 数据集中名为 ‘Date’ 的列,并将修改后的数据集存储回原始变量
data.drop('Date', axis = 1, inplace = True)
data.columns
#指定了 axis = 1 参数来表示我们要删除列(默认为行),并使用 inplace = True 参数来指示直接修改原始数据集而不是创建副本

三、探索式数据分析
1、数据相关性探索
data.corr() 该函数会自动遍历数据框中的每一对变量,并计算它们之间的相关系数,最终返回一个相关系数矩阵。矩阵中的每个元素都代表了两个变量间的相关程度,其值在 -1 到 1 之间,其中正值表示正相关,负值表示负相关,0表示无相关性。
plt.figure(figsize = (15, 13))
#data.corr()表示了data中的两个变量之间的相关性
ax = sns.heatmap(data.corr(), square = True, annot = True, fmt = '.2f')
'''
heatmap() 函数,并传入了相关系数矩阵 data.corr() 作为参数来生成热力图。
具体来说,设置 square 参数为 True 来让每个单元格都显示为正方形
设置 annot 参数为 True,以在每个单元格中显示相关系数的具体数值。
fmt 参数指定了数值的格式(保留小数点后两位)。
在生成热力图时,Seaborn 库还会自动根据不同的相关系数值将颜色进行映射。例如,当相关系数为正值时,颜色通常呈现为较浅的蓝色或绿色,而当相关系数为负值时,则呈现为较浅的红色或橙色。这样,我们便可以通过观察颜色的深浅程度来初步判断变量之间的相关性强度。
'''
ax.set_xticklabels(ax.get_xticklabels(), rotation = 90)
'''
通过 ax.get_xticklabels() 获取热力图 x 轴的刻度标签,这些标签通常是由相关变量的名称组成。
调用 ax.set_xticklabels() 方法来重新设置刻度标签,并将其旋转 90 度以避免它们之间的重叠。旋转角度可以自定,如这里的 90 度。需要注意的是,由于热力图的 x 轴上通常显示的是变量名称,因此在进行标签设置时,我们需要保证这些名称的可读性和清晰度,以避免混淆和误解
'''
plt.show()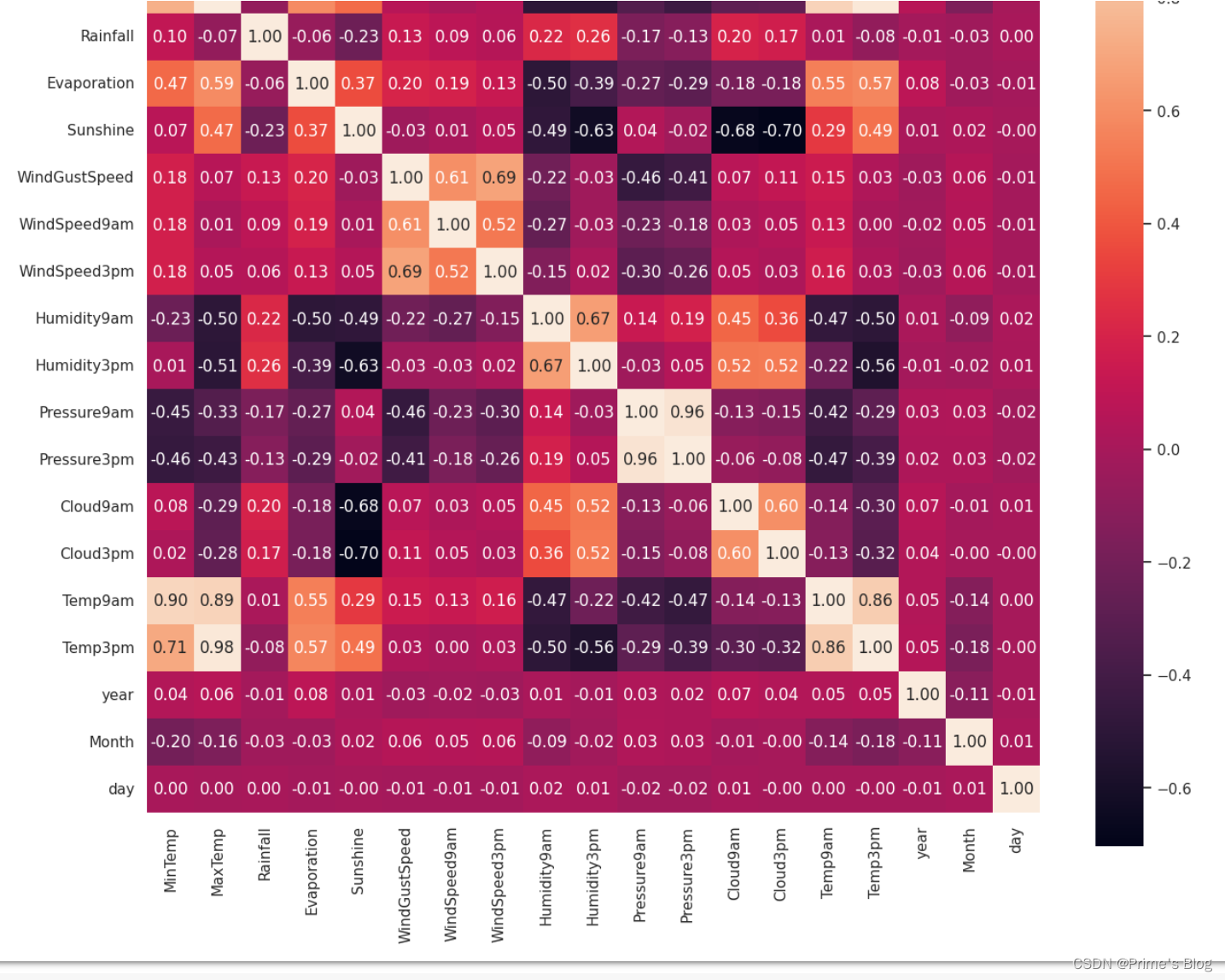
2、是否会下雨
1、预测明天是否会下雨
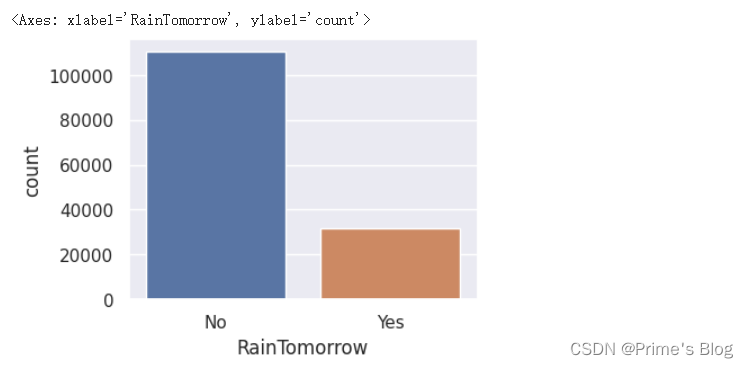
使用 Seaborn 库绘制柱形计数图。
首先,通过 sns.set() 方法来设置 seaborn 的绘图风格为 “darkgrid”,以增强可读性和美观性。
然后,我们创建一个大小为 (4, 3) 的新绘图区域,使用 sns.countplot() 函数来生成柱形计数图。具体来说,我们指定 x 参数为 “RainTomorrow”,并将数据集 data 作为 data 参数传递给该函数。
柱形计数图是一种经常用于探索分类变量中各个类别之间数量分布情况的可视化方法。
在这里, “RainTomorrow” 列作为分类变量,表示是否会下雨,然后根据数据集中的观测值数量将其分成两个类别,分别用蓝色和橙色柱子表示。因此,我们可以通过观察柱子的高度来初步判断哪个类别所占比例更大,进而预测明天是否会下雨.
sns.set(style = "darkgrid")
#https://www.iotword.com/6149.html
plt.figure(figsize = (4, 3))
sns.countplot(x = "RainTomorrow", data = data)
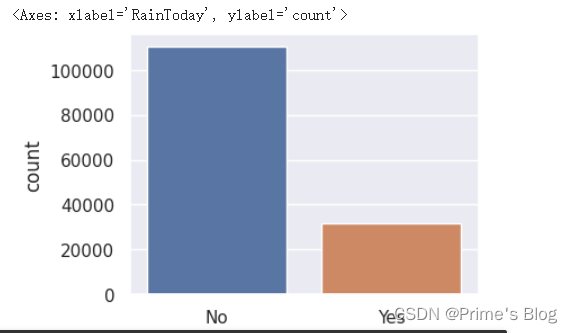
2、预测今天是否会下雨
plt.figure(figsize = (4, 3))
sns.countplot(x = "RainToday", data = data)
3、探索两个分类变量之间的关系。
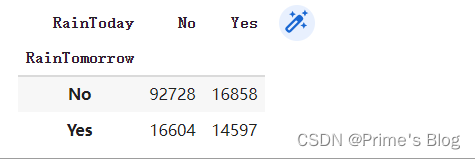
使用 Pandas 中的 crosstab() 函数来创建一个交叉制表,用于探索两个分类变量之间的关系。
具体来说,我们将 “RainTomorrow” 列和 “RainToday” 列作为参数传递给 crosstab() 函数,以生成一个新的数据框,其中包含这两个变量之间的计数值。这意味着,交叉制表的行表示 “RainTomorrow” 列中的类别,列表示 “RainToday” 列中的类别,交叉制表元素表示具有特定行和列组合的观测值数量。
通过创建交叉制表,我们可以快速了解这两个变量之间的关系,并发现它们之间是否存在任何相关性或模式。例如,如果我们发现 “RainToday” 为 “Yes” 的情况下,“RainTomorrow” 也经常为 “Yes”,则可以初步推断这两个变量存在某种形式的关联。
x = pd.crosstab(data['RainTomorrow'], data['RainToday'])
x
4、 归一化处理,以生成百分比形式的数据。
使用 NumPy 的reshape方法和矩阵计算,对交叉制表数据进行归一化处理,以生成百分比形式的数据。
具体来说,x 被除以通过 x 的转置与列总和矩阵相乘计算得出的新矩阵。这样操作后,我们可以在 y 中获得归一化后的百分比值。x 被转置为了确保列总和向量能够正确地与 x 相乘。最后, NumPy 的 reshape 方法被用于重新构造列总和矩阵,以便按照正确的维度与 x 相乘。
通过将数据归一化到百分比形式,我们可以更方便地比较和解释交叉制表中不同变量组合之间的关系。例如,在这里,我们可以看到每个类别在各自所属行或列的总数中所占的百分比,从而更清楚地了解两个变量之间的关联程度和重要性。
y = x / x.transpose().sum().values.reshape(2, 1) * 100
y
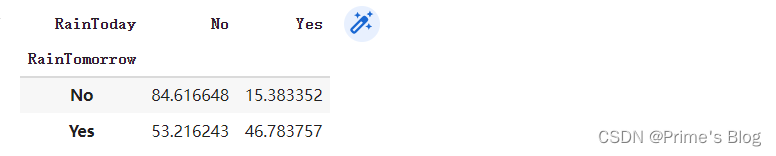 可以看到:
可以看到:
如果今天不下雨,那么明天下雨的机会= 15%
如果今天下雨明天下雨的机会= 46%
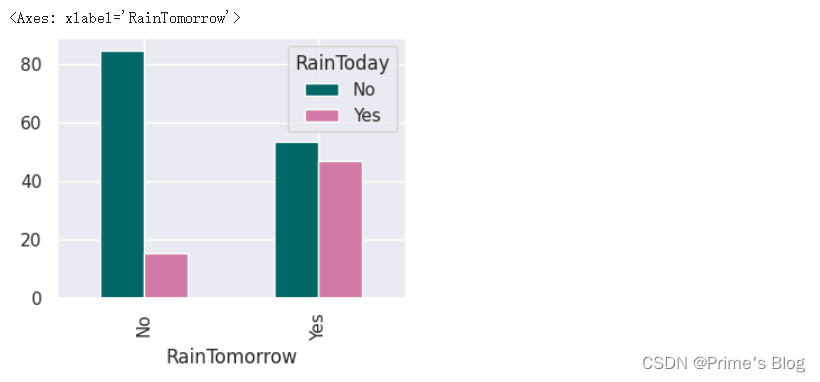
4、绘图
使用 Pandas 库中的 plot() 方法来生成归一化后的百分比数据的条形图。
y.plot(kind = "bar", figsize = (4, 3), color = ['#006666', '#d279a6'])
具体来说,我们使用 y.plot(kind=“bar”) 来指定绘图类型为条形图。然后,我们通过 figsize 参数指定了图形的大小为 (4, 3),并通过 color 参数来指定用于柱子颜色的列表。
在这里,由于我们已经将交叉制表数据归一化为百分比形式,因此生成的条形图可以很好地显示每个类别在各自所属行或列总数中占的百分比。例如,如果我们观察到某个变量组合的柱子高度特别高,那么我们就可以推断该组合在两个变量之间可能存在某种显著关联或差异。
3、地理位置与下雨的关系
使用 Pandas 库中的 crosstab() 函数创建一个交叉制表,然后将其转换为归一化后的百分比数据,并生成一个水平条形图。
x = pd.crosstab(data['Location'], data['RainToday'])y = x / x.transpose().sum().values.reshape((-1, 1)) * 100
y = y.sort_values(by = 'Yes', ascending = True)color = ['#cc6699', '#006699', '#006666', '#862d86', '#ff9966']
y.Yes.plot(kind = 'barh', figsize = (15, 20), color = color)
首先使用 crosstab() 函数对数据集中的 “Location” 和 “RainToday” 两个变量进行交叉制表,以便探索它们之间的关系。
接下来,我们对制表数据进行归一化处理,以将每个组合在各自所属行和列的总数中所占的百分比表示出来。
然后,我们使用 sort_values() 函数将数据按照 “Yes” 列进行排序,并将结果保存在 y 变量中。
最后,我们使用 Pandas 中的 plot() 方法绘制水平条形图。
在此过程中,我们通过 kind 参数指定了图形类型为水平条形图,通过 figsize 参数设定了图像大小,并使用 color 参数为每个柱子设置不同颜色。在这里,由于我们已经将数据归一化,因此能够更好地了解每个位置上的降雨情况,并找出可能存在的模式或趋势。
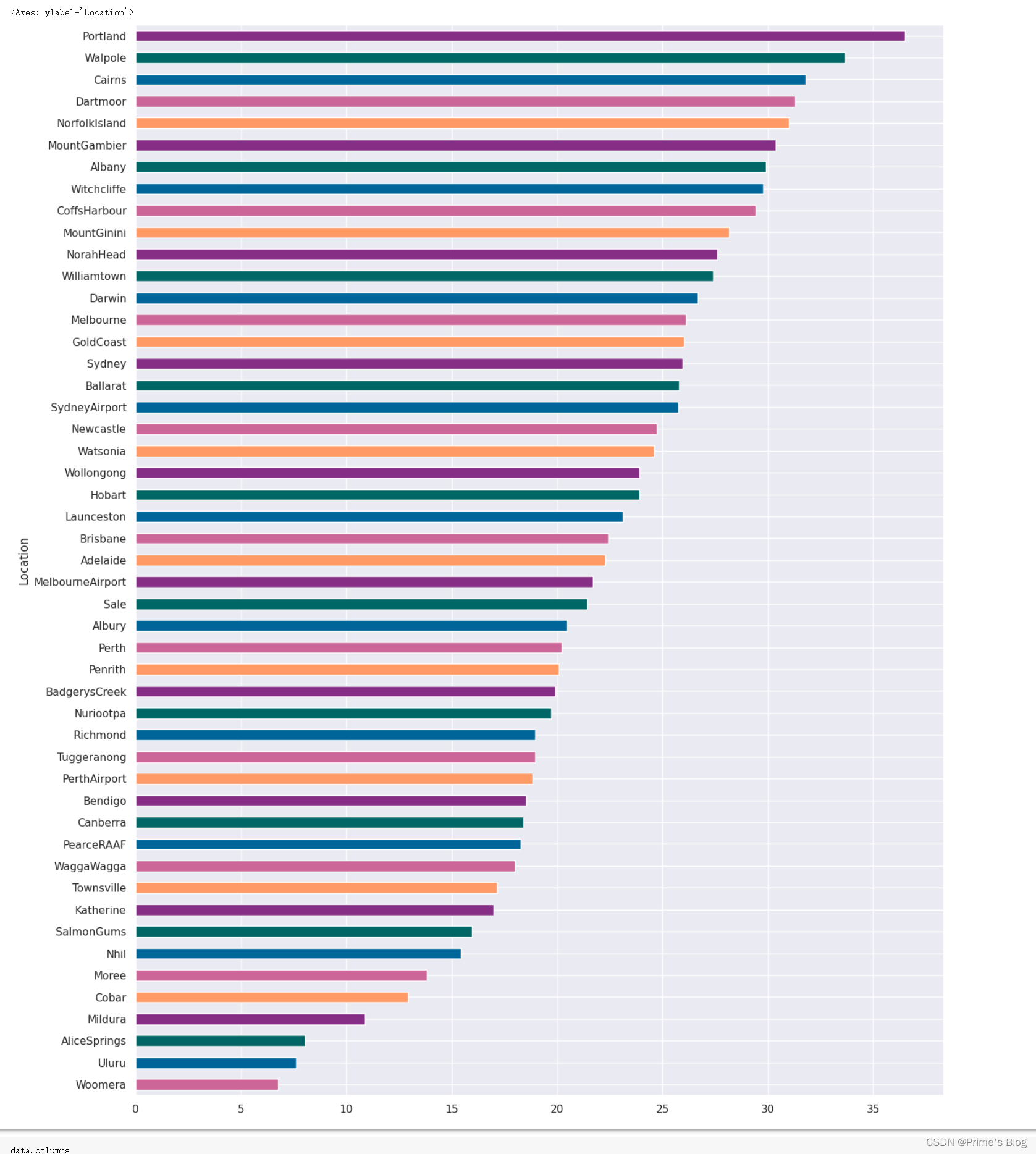 可以看到,位置影响下雨,对于Prtland来说,有36%的时间在下雨,而对于Woomers来说,只有6%的时间在下雨
可以看到,位置影响下雨,对于Prtland来说,有36%的时间在下雨,而对于Woomers来说,只有6%的时间在下雨
4、湿度和压力对下雨的影响
先看数据集中所有列的名称。
data.columns

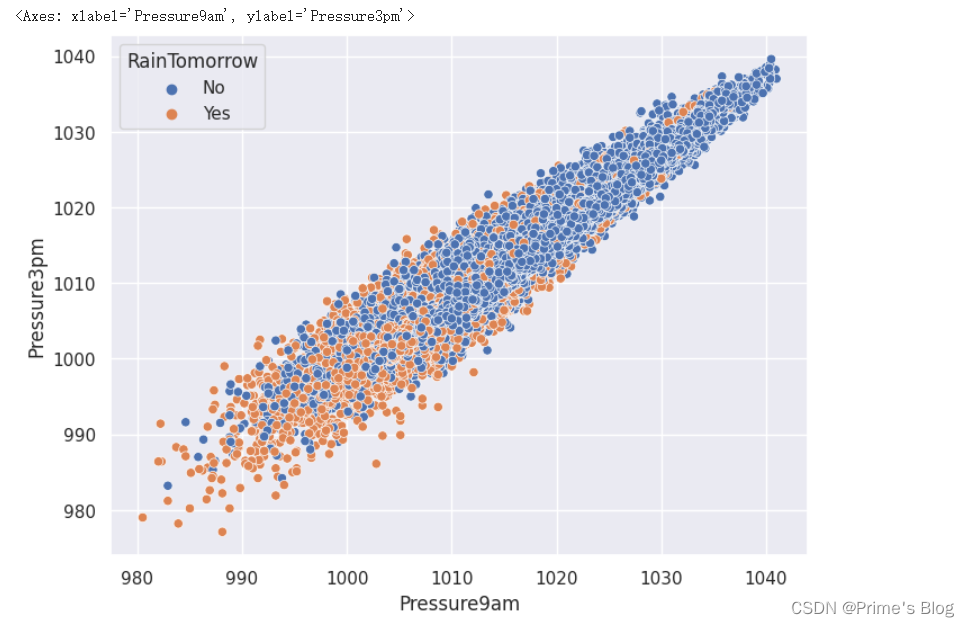
使用 Seaborn 库中的 scatterplot() 函数绘制压力变量在 9am 和 3pm 的散点图,并使用不同颜色表示明天是否有雨
plt.figure(figsize = (8,6))
sns.scatterplot(data = data, x = 'Pressure9am', y = 'Pressure3pm', hue = 'RainTomorrow')
首先使用 Matplotlib 库中的 figure() 函数指定图形的大小为 (8, 6)。
然后,使用 Seaborn 库中的 scatterplot() 函数绘制散点图,其中 x 轴和 y 轴分别表示压力变量在 9am 和 3pm 的值,hue 参数表示不同颜色将用于区分明天是否有雨。
在这里,通过散点图,我们可以更好地了解压力变量在不同时间点的取值情况,并可以看到明天是否有雨对压力变量的影响。如果我们发现明天有雨的数据点和没有雨的数据点在 x-y 平面中呈现出不同的分布模式,那么我们就可以研究这种模式与气象条件之间的关系,以更好地预测未来的天气
观察Humidity9am和Humidity3am两个变量之间的关系,并同时考察它们与是否会下雨的关系
plt.figure(figsize = (8,6))
sns.scatterplot(data = data, x = 'Humidity9am', y = 'Humidity3pm', hue = 'RainTomorrow')
#x参数指定Humidity9am作为x轴数据,y参数指定Humidity3am作为y轴数据,hue参数指定RainTomorrow作为分类变量,即每个RainTomorrow取值对应的点被标记为不同的颜色。#通过该代码绘制的散点图可以帮助我们观察Humidity9am和Humidity3am两个变量之间的关系,并同时考察它们与是否会下雨的关系
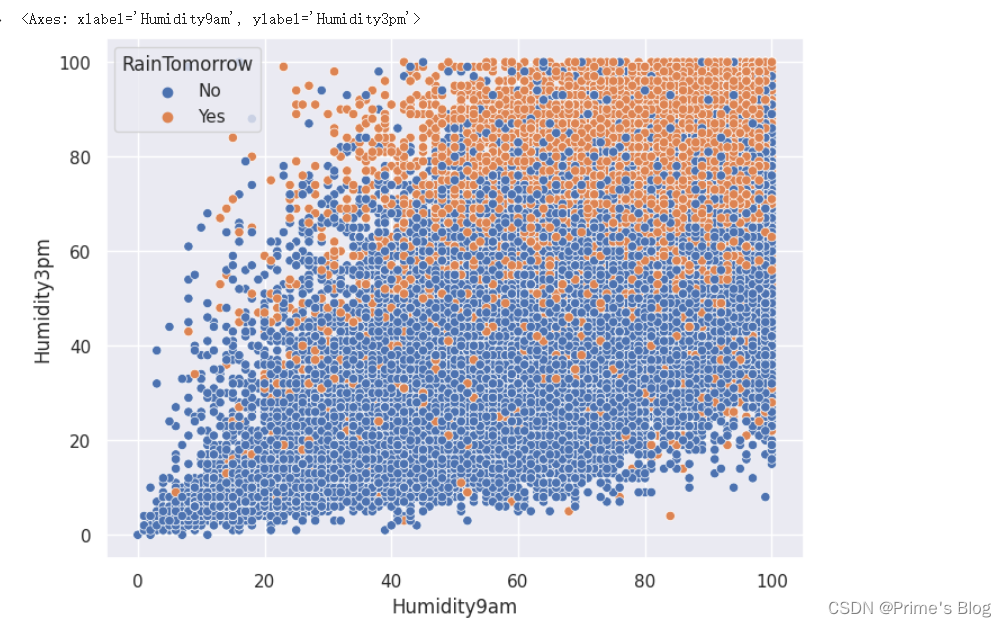 可以看到,低压与高湿度会增加第二天下雨的概率,尤其是下午3点的空气湿度。
可以看到,低压与高湿度会增加第二天下雨的概率,尤其是下午3点的空气湿度。
5、气温对下雨的影响
sns.scatterplot(data = data, x = 'MaxTemp', y = 'MinTemp', hue = 'RainTomorrow')
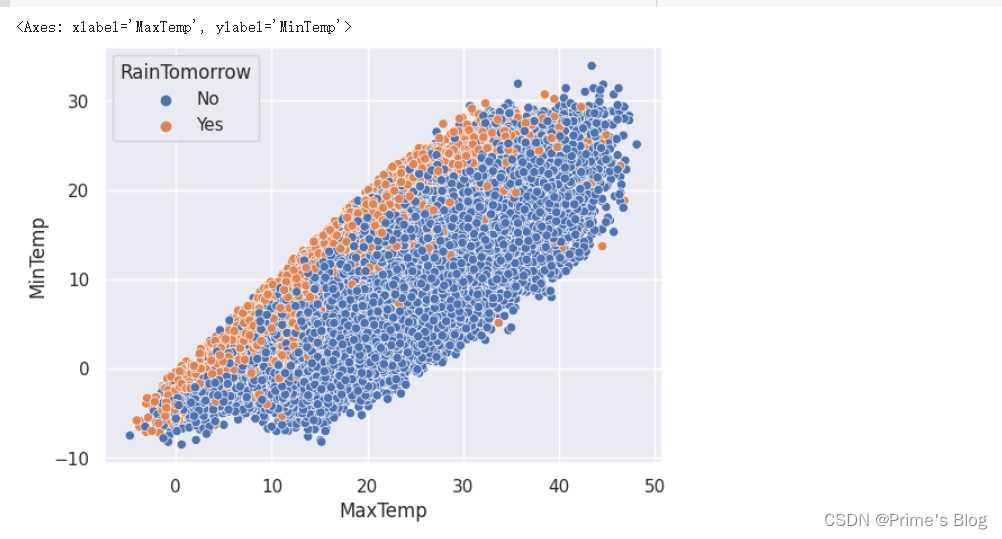
结论:当天的最高气温和最低气湿接近时,第二天下雨的概率会增加。
四、数据集预处理
1、处理缺失值
1、计算每列中确实数据的百分比
使用 Pandas 库中的 isnull() 函数和 sum() 函数统计数据集中每列缺失数据的数量,并计算其占列总数的百分比
#处理缺失值
#每列中缺失数据的百分比
data.isnull().sum()/data.shape[0] * 100
首先使用 isnull() 函数检测数据集中的缺失值,返回一个与原始数据集同形状的 DataFrame,其中 True 表示该位置为缺失值,False 表示该位置有数据。
然后,我们使用 Pandas 库中的 sum() 函数对 DataFrame 沿着行方向进行求和,即得到每个变量中缺失值的总数。
最后,我们将缺失值总数除以数据集的行总数,再乘以 100,即可得到每列中缺失数据的百分比。
这样做的目的是帮助我们更好地理解数据集中缺失值的分布情况,进而采取合适的处理策略。常用的处理方法包括删除缺失值、填充缺失值等
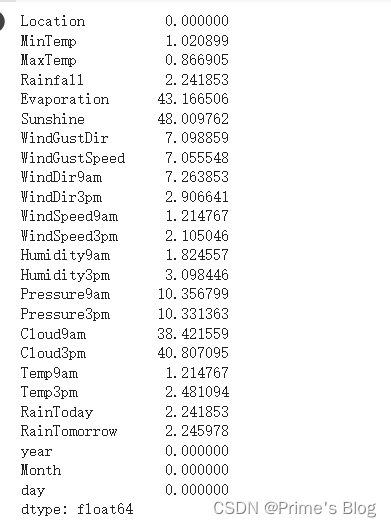
2、在该列中随机选择数进行填充
#在该列中随机选择数进行填充
lst = ['Evaporation', 'Sunshine', 'Cloud9am', 'Cloud3pm']
for col in lst:fill_list = data[col].dropna()data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list, size = len(data.index))))'''
fill_list = data[col].dropna() 表示将数据集data中指定列col中的所有缺失值去除,并将其余非空的值赋值给名为fill_list的列表。dropna()方法的作用是去除包含缺失值的行或列。当我们在处理数据时,经常会遇到某些行或列存在缺失值的情况。如果不对缺失值进行处理,将会影响后续分析和建模的结果。因此,我们需要使用该函数将缺失值去除或进行填充操作,以保证数据质量。例如,我们可以使用data[col].dropna()方法来筛选数据集中某一列中非空的数据,也可以使用该方法对整个数据集进行缺失值处理,如:data.dropna()(删除包含缺失值的行)或data.dropna(axis=1)(删除包含缺失值的列)。在进行缺失值处理时,dropna()方法是一个非常重要的工具。data[col] = data[col].fillna(pd.Series(np.random.choice(fill_list, size = len(data.index))))
该代码的作用是对数据集data中指定列col中的缺失值进行填充。具体来说,当data[col]中存在缺失值时,就使用fill_list中的随机值进行填充。解释如下:fillna()方法用于填充数据缺失值。在该代码中,我们将fillna()方法应用于data[col]这一列数据,以便找到其中所有的缺失值,并对它们进行填充。
pd.Series()方法用于将list、tuple、array等数据类型转换成pandas里的Series类型。在该代码中,我们将np.random.choice(fill_list, size = len(data.index))产生的 numpy ndarray 转换成了 pandas.Series。
np.random.choice()方法从一个一维数组中随机抽取指定个数的元素。在该代码中,我们从fill_list中随机选择与data[col]中缺失值数量相同的元素,将这些元素组成一个新的数组,并使用该数组的值进行填充。
因此,当我们执行这一行代码时,会将data[col]中的缺失值,使用fill_list中的随机值进行填充。这样可以快速有效地处理数据集中的缺失值,使得数据更加完整。
'''
3、寻找数据集中所有的 object 类型的列
s = (data.dtypes == "object")
object_cols = list(s[s].index)
object_cols'''
,该代码的作用是寻找数据集中所有的 object 类型的列,并将它们的列名存储到 object_cols 这个列表中。具体来说,这段代码包含以下几个步骤:s = (data.dtypes == "object"):使用 data.dtypes 属性获取数据集中每一列的数据类型,并将其与 "object" 进行比较。这会返回一个布尔类型的 Series 对象 s,其中每个元素表示相应的列是否为 object 类型。
object_cols = list(s[s].index):从 Series 对象 s 中选择值为 True 的元素索引,即 object 类型的列名,将其转化成列表 object_cols 并返回。这里使用了布尔索引(s[s]),将 s 中值为True的索引选出来,再使用.index方法返回对应的索引名称。
最终得到的 object_cols 就是数据集中所有的 object 类型的列名列表。
因此,执行这段代码后,我们可以得到一个包含所有 object 类型的列名的列表 object_cols,用于在数据分析/预处理时针对 object 类型的特征进行进一步操作和处理,例如进行编码转换(Category Encoding)、哑变量编码(One-Hot Encoding)等等。
'''
4、填充
该代码的作用是对数据集 data 中的所有 object 类型的列进行缺失值填充,采用众数(mode)进行填充。
for i in object_cols:data[i].fillna(data[i].mode()[0], inplace = True)print(data[i].mode())print("-")print(data[i].mode()[0])print("------")'''
其中 object_cols 是一个包含了数据集中所有 object 类型列名的列表。该代码的作用是对数据集 data 中的所有 object 类型的列进行缺失值填充,采用众数(mode)进行填充。具体来说,这段代码使用了 for 循环遍历 object_cols 中的每一个列名,再对该列中的缺失值进行填充。填充方法使用了众数(mode),即在该列中出现次数最多的值,将其作为缺失值的填充值。填充完成后,将填充结果直接存回原数据集 data 中。其中,data[i].mode() 表示求列 i 的众数,返回是一个 DataFrame,其中包含了众数及其个数信息,而 data[i].mode()[0] 则表示取众数 DataFrame 中的第一行(即众数)。最后的参数 inplace = True 表示直接在原数据集中进行填充,避免产生额外的中间过程数据,节省内存空间并提高代码运行效率。因此,执行这段代码后,数据集中所有 object 类型的列中的缺失值都会被众数所填充,从而使得数据更加完整,便于后续的数据分析和建模。
'''
中位数填充
t = (data.dtypes == "float64")
num_cols = list(t[t].index)
for i in num_cols:data[i].fillna(data[i].median(), inplace = True)查看缺失值情况
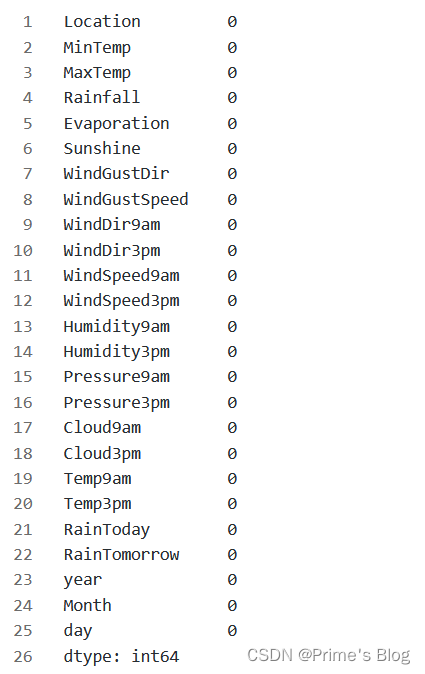
data.isnull().sum()
'''
isnull() 方法用于判断每个元素是否为缺失值(NaN),返回一个布尔类型的 DataFrame,True 表示缺失值,False 表示非缺失值;
而 sum() 方法则用于对 True 值进行求和,即统计缺失值的数量。因此,执行这段代码后,会返回一个 Series 对象,其中每个元素表示相应的变量中的缺失值数量。
'''
2、构建数据集
from sklearn.preprocessing import LabelEncoderlabel_encoder = LabelEncoder()
for i in object_cols:data[i] = label_encoder.fit_transform(data[i])
'''
其中 object_cols 是一个包含了数据集中所有 object 类型列名的列表,sklearn.preprocessing 中的LabelEncoder类被导入并命名为 label_encoder。
该代码的作用是对数据集 data 中的所有 object 类型的列进行标签编码(Label Encoding)。具体来说,这段代码使用了 for 循环遍历 object_cols 中的每一个列名,再通过调用 LabelEncoder().fit_transform() 方法将当前列数据进行标签编码。
该方法会将当前列中的每个不同值分配一个唯一的整数标签,因此在编码后,当前列中的值就变成了一系列整数值,而非原来的字符串或者分类变量。编码结果将覆盖原始数据集 data 中的相应列。在具体实现时,我们先创建了一个名为 label_encoder 的 LabelEncoder 实例,并使用其 fit_transform() 方法对每个 object 类型的列进行编码。
该方法首先根据当前列中出现的不同值计算出唯一的标签集合(即整数标签),并将标签集合映射到当前列中的每个值。这样,每个列中的值都被转换成唯一的整数标签,并存储在 data[i] 中。
需要注意的是,同一个标签集合会被用于每个列中的值,所以相同的值在不同的列中可能会被赋予不同的整数标签。
'''
X = data.drop(['RainTomorrow', 'day'], axis = 1).values
y = data['RainTomorrow'].values
'''
data 是一个数据集(pandas DataFrame),该代码的作用是将数据集中的特征和标签分别存储到变量 X 和 y 中。具体来说,这段代码首先调用了 pandas DataFrame 中的 drop() 方法,按列删除了数据集中的两列:'RainTomorrow' 和 'day'。
其中,'RainTomorrow' 列包含每天是否下雨的标签信息,而 'day' 列表示日期,这两列不是我们所需要的特征信息,因此被删除。删除列的操作通过传入参数 axis = 1 来实现,axis = 1 表示按列操作,即对列进行删除;而 axis = 0 则表示按行操作,即对行进行删除。接下来,使用 .values 方法将删除操作后的数据集转换成 NumPy 数组,并分别存储到变量 X 和 y 中。其中,y 数组保存了每日的下雨情况标签(1 表示下雨,0 表示不下雨),而 X 数组保存了其他所有特征的值(如温度、湿度等)。需要注意的是,数据集中的每一行均表示一天的数据。使用数组存储数据有助于在机器学习算法中进行处理和分析。通常情况下,我们会把原始数据集按照一定的比例切分成训练集和测试集,然后使用训练集来训练算法模型,使用测试集来验证模型的性能。
'''
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 101)
'''
X 和 y 分别表示经过处理后的特征和标签,该代码的作用是将数据集按照一定比例(一般是 75% 训练集和 25% 测试集)进行划分,并将划分后的数据集存储到 X_train, X_test, y_train, y_test 四个变量中。具体来说,这段代码使用了 scikit-learn 中的 train_test_split 方法,其中 X 和 y 分别表示需要划分的特征和标签,test_size 表示测试集所占的比例,random_state 是一个随机种子,用于控制每次划分的结果都相同。train_test_split() 方法的作用是将数据集随机划分成两部分:训练集和测试集。训练集用于训练模型,而测试集用于评估模型的性能。在实际应用中,我们通常会将数据集中的大部分数据用于训练模型,少部分数据用于测试模型。
一般情况下,训练集所占比例会更高,因为我们需要尽可能多地使用数据来训练模型,以提高模型的准确度。
'''
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
'''
scaler 是一个 MinMaxScaler 类型的对象,该代码的作用是对 X_train 和 X_test 进行归一化处理。具体来说,该代码使用了 scikit-learn 中的 MinMaxScaler 类来实现归一化操作。MinMaxScaler 是一种常用的数据预处理方法,主要用于将特征缩放到指定的范围内,以消除不同特征之间的量纲影响,从而提高模型的训练效果。
在该代码中,我们把归一化器 scaler 应用到训练集 X_train 上,并使用 fit() 方法对其进行拟合。这样可以得到训练集特征的最小值和最大值。
fit() 是 scikit-learn 中的一个方法,用于对机器学习模型进行训练(拟合)。在模型训练过程中,我们需要将训练数据传入模型,并根据训练数据自适应地调整模型的参数,使得模型能够更准确地预测测试数据或新的未知数据。
具体来说,fit() 方法的作用是通过传入训练集数据,拟合出一个特定的模型。在拟合过程中,模型会根据样本数据计算出一些内部参数,这些参数可以描述数据的某些特征,例如分类问题中的决策边界、回归问题中的系数等。然后,我们把训练集和测试集都使用 transform() 方法进行归一化操作。这就是训练集与测试集不能共用的原因。测试集的归一化需要使用训练集的最大值与最小值进行归一化。
如果使用训练集和测试集的最大值与最小值进行归一化,则会破坏测试集的信息,导致模型训练出现偏差。
transform() 是 scikit-learn 中常用的一个方法,通常用于对数据进行预处理、特征提取或降维等操作。在机器学习中,我们需要对原始数据进行一些处理,以便能够更好地运用到各种模型中。
具体来说,transform() 方法的作用是根据拟合后得到的统计参数对数据进行变换。例如,在数据归一化中,我们可以使用 MinMaxScaler 对数据进行 min-max 归一化,然后使用 transform() 方法将原始数据进行缩放。transform() 方法的主要作用是将训练集和测试集标准化为相同的比例经过以上操作后,X_train 和 X_test 中的所有特征都被缩放到了 [0,1] 的区间内,从而消除了不同特征之间的量纲影响。
这有助于提高机器学习算法的训练效果,因为大多数机器学习算法都是基于欧氏距离来度量样本之间的相似度,在特征量纲不一致时会受到影响。
'''
五、预测是否会下雨
1、搭建神经网络
from tensorflow.keras.optimizers import Adammodel = Sequential()
model.add(Dense(units = 24, activation = 'tanh'))
model.add(Dense(units = 18, activation = 'tanh'))
model.add(Dense(units = 23, activation = 'tanh'))
model.add(Dropout(0.5))
model.add(Dense(units = 12, activation = 'tanh'))
model.add(Dropout(0.2))
model.add(Dense(units = 1, activation = 'sigmoid'))optimizer = tf.keras.optimizers.Adam(learning_rate = 1e-4)model.compile(loss = 'binary_crossentropy', optimizer = optimizer, metrics = 'accuracy')2、模型训练
early_stop = EarlyStopping(monitor = 'val_loss',mode = 'min',min_delta = 0.001,verbose = 1,patience = 25,restore_best_weights = True)
'''
利用 Keras 中的 EarlyStopping 回调函数,实现在验证集上监控模型性能,并在性能停止提升时停止训练,从而避免过拟合。具体来说,EarlyStopping 回调函数接受一些参数,这些参数决定了在什么情况下停止训练:monitor:需要监控的指标。在这里,我们选取了验证集上的损失,即 'val_loss'。
mode:比较模式。由于我们希望在 val_loss 停止提升时停止训练,因此将 mode 设置为 'min'。
min_delta:最小变化量。如果新的指标值与前一个值之间的差异不足 min_delta,则被认为没有提升。在这里,我们将 min_delta 设置为 0.001。
verbose:详细程度。控制输出信息的详细程度,通常设置为 0 或 1。
patience:耐心。如果模型在经过 patience 轮迭代后仍未提升,则训练被停止。在这里,我们将 patience 设置为 25。
restore_best_weights:恢复最佳权重。如果为 True,则在停止时恢复具有最佳验证损失的模型权重。这可以确保我们在检查点中保存了最佳的模型权重。
'''model.fit(x = X_train, y = y_train,validation_data = (X_test, y_test), verbose = 1,callbacks = [early_stop],epochs = 10,batch_size = 32)
'''
x:输入数据。在这里,我们将训练集数据 X_train 作为输入。
y:标签数据。在这里,我们将训练集标签 y_train 作为标签。
validation_data:验证集数据和标签。在这里,我们将测试集数据 X_test 和测试集标签 y_test 组成的元组作为验证集数据。
verbose:详细程度。控制输出信息的详细程度,通常设置为 0、1 或 2。
callbacks:回调函数列表。我们在这里传入了 EarlyStopping 回调函数对象。
epochs:训练轮数。每次训练都会用整个数据集进行训练,一次训练完成后称为一个 epoch。
batch_size:批次大小。即每次训练时所选取的样本数量。
在训练过程中,模型将使用 Adam 优化器最小化损失函数(binary_crossentropy),同时监控和输出训练和验证的准确率。如果模型在验证集上的损失没有提升,则 EarlyStopping 回调函数将停止训练,并恢复具有最佳验证损失的模型权重(如果 restore_best_weights 设置为 True)
'''
3、结果可视化
import matplotlib.pyplot as pltacc = model.history.history['accuracy'']
val_acc = model.history.history['val_accuracy']loss = model.history.history['loss']
val_loss = model.history.history['val_loss']epochs_range = range(10)
plt.figure(figsize = (14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label = 'Training Accuracy')
plt.plot(epochs_range, val_acc, label = 'Validation Accuracy')
plt.legend()
plt.title("Training And Validation Accuracy")plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label = 'Training Loss')
plt.plot(epochs_range, val_loss, label = 'Validation Loss')
plt.legend()
plt.title("Training And Validation Loss")plt.show()'''
plt.legend() 是一个 Matplotlib 函数,可以用于在当前轴上添加图例。当 plt.legend() 没有参数时,它将尝试使用当前轴中的所有线条、误差线和区域来生成默认的图例。如果需要修改图例标签或属性,则可以传递一些可选参数给 plt.legend() 函数,例如:
labels:图例标签列表,应与数据序列数量匹配。例如 labels=['data1', 'data2', 'data3'] 表示三个数据序列的标签分别为 'data1'、'data2' 和 'data3'。
loc:图例位置。可以是一个字符串(例如 'upper left'、'lower right')或一个整数(例如 1、2、3、4),分别表示不同的位置。默认情况下,loc='best' 表示自动选择最优位置。
title:图例标题。可以是一个字符串,将作为图例顶部的文本。
fontsize:字体大小。
ncol:图例中的列数。默认值为 1。
'''
![[ 常用工具篇 ] 渗透神器 whatweb 安装使用详解](https://img-blog.csdnimg.cn/cdc2921201c94af5aecd788b60522628.png)
![[学习笔记] 1. 机器学习前置知识](https://img-blog.csdnimg.cn/56aaa1065a4a481fbb7d90a23b121ffb.png#pic_center)