网络爬虫——Xpath解析
- Xpath简介
- Xpath解析
- 节点选择
- 路径表达式
- 谓语
- 未知节点
- Xpath实战演示
- 豆果美食实战
- 获取数据
- 源代码
前言:
📝📝此专栏文章是专门针对Python零基础爬虫,欢迎免费订阅!
📝📝第一篇文章获得全站热搜第一,python领域热搜第一,
第四篇文章全站热搜第八,欢迎阅读!
🎈🎈欢迎大家一起学习,一起成长!!
💕💕:悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。


Xpath简介
XPath是一种用于在XML文档中定位节点的语言,它可以用于从XML文档中提取数据,以及在XML文档中进行搜索和过滤操作。它是W3C标准的一部分,被广泛应用于XML文档的处理和分析。
XPath使用路径表达式来描述节点的位置,这些路径表达式类似于文件系统中的路径。路径表达式由一个或多个步骤(step)组成,每个步骤描述了一个节点或一组节点。步骤可以使用关系运算符(如/和//)来连接,以便描述更复杂的节点位置。
XPath还提供了一些内置函数和运算符,可以对XML文档中的数据进行操作和计算。例如,可以使用XPath的数学函数来计算节点的数值,或使用字符串函数来处理节点的文本内容。
在Python中,XPath可以使用lxml库来实现。lxml提供了一个etree模块,该模块包含了XPath的实现,可以方便地对XML文档进行解析和操作,同时支持XPath语法。
Xpath解析
节点选择
XPath用于在XML文档中定位和选择节点,以下是XPath的一些常用用法:
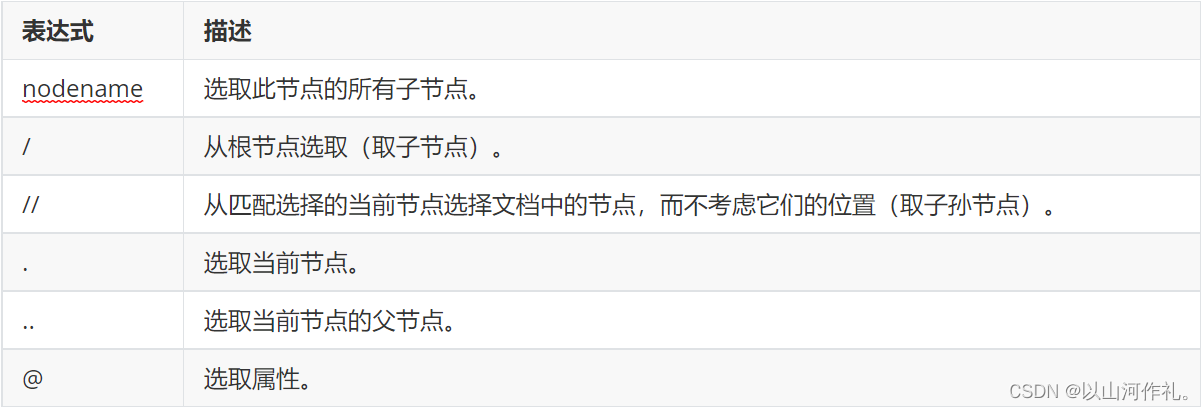
1. 选择所有节点:
使用双斜杠//选择文档中的所有节点,例如:
//node()
2. 按标签名选择节点:
使用标签名选择节点,例如:
//book
3. 按属性选择节点:
使用方括号[]和@符号选择具有特定属性值的节点,例如:
//book[@category="children"]
4. 选择父节点、子节点和兄弟节点:
使用父节点(…)、子节点(/)和兄弟节点(//)选择节点,例如:
//book/title/..、//book/author/following-sibling::title等
5. 使用通配符选择节点:
使用星号*选择任何节点,例如:
//book/*选择所有book节点的子节点
6. 使用逻辑运算符选择节点:
使用and、or、not等逻辑运算符选择节点,例如:
//book[price<10 and @category="children"]
7. 使用内置函数处理节点:
使用内置函数处理节点的文本和数值,例如:
//book[substring(title,1,3)="The"]选择标题以"The"开头的书籍
8. 使用轴选择节点:
使用轴选择节点,例如:
//book/ancestor::library选择book节点的library祖先节点
在Python中,使用lxml库的etree模块可以方便地使用XPath进行节点定位和选择。例如,可以使用etree.parse()函数解析XML文档,并使用xpath()方法执行XPath表达式,以便选择和操作XML文档中的节点。
路径表达式
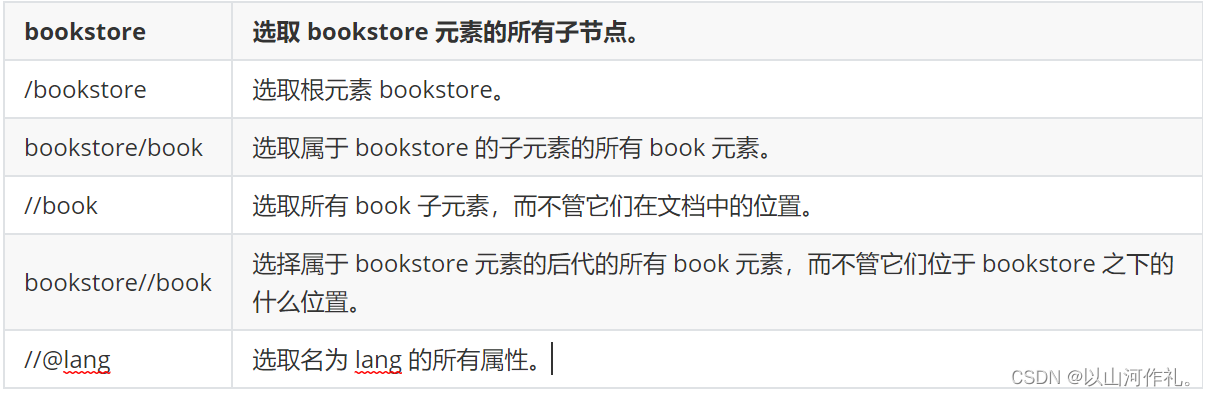
XPath路径表达式是一种用于在XML文档中定位节点的语法。它由一系列节点名、轴、谓词和运算符组成,可以构造出一个完整的路径,以定位到目标节点。
XPath路径表达式的基本语法如下:
/ : 从根节点开始,定位到目标节点
// : 从当前节点开始,递归查找所有符合条件的节点
. : 表示当前节点
.. : 表示当前节点的父节点
* : 匹配任意节点
@ : 表示属性节点
[] : 表示谓词,用于筛选符合条件的节点
例如,以下是一些XPath路径表达式的示例:
/ : 定位到根节点
/bookstore : 定位到根节点下的bookstore节点
/bookstore/book : 定位到bookstore节点下的所有book节点
//book : 递归查找所有book节点
//book[@category='web'] : 查找所有category属性值为web的book节点
XPath路径表达式是XPath语言的核心,它可以用于查询XML文档中的数据,并且在XPath语言中还有很多其他的功能,例如函数、运算符等,可以更加灵活地处理XML数据。
谓语
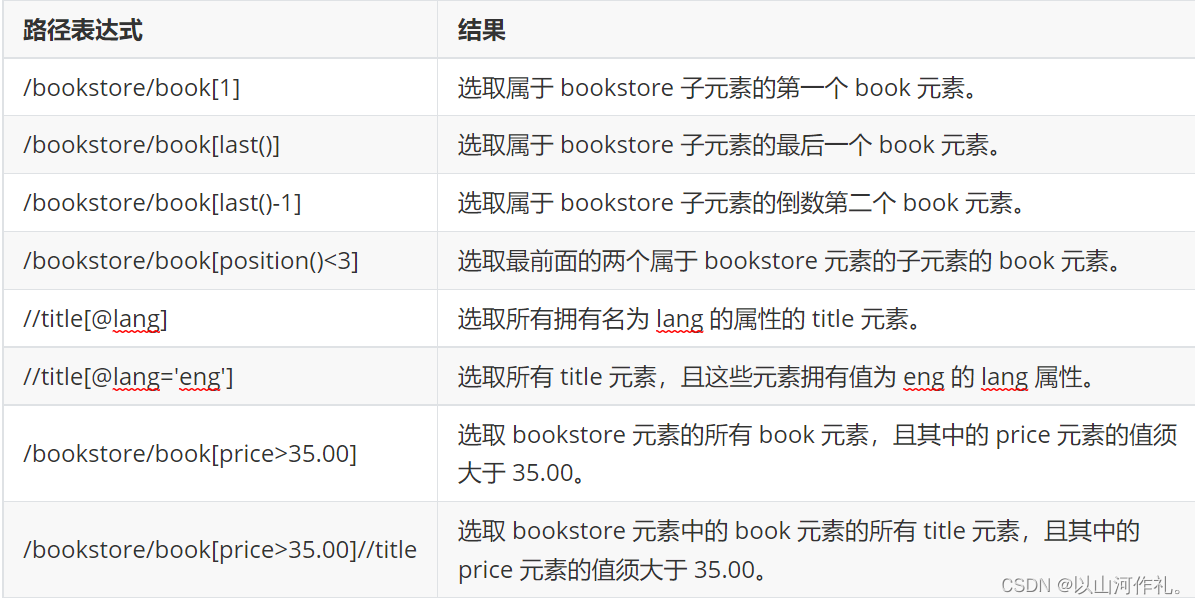
XPath谓语是一种用于筛选XML文档中特定节点的表达式,它可以在XPath路径中使用。谓语通常由方括号包围,并包括一个条件表达式。
例如,以下XPath路径选择所有名为“book”的元素:
/bookstore/book
如果我们想要选择所有具有价格大于10美元的书籍,我们可以使用以下XPath路径和谓语:
/bookstore/book[price > 10]
在这个例子中,谓语是“[price > 10]”,它指定了一个条件,它只选择价格大于10美元的书籍。
未知节点
当我们需要选择一个未知节点时,意味着我们无法确定节点的位置或名称,但我们知道节点具有某些特定属性或特征。在这种情况下,我们可以使用通配符、轴、谓词等技术来选择未知节点。
通配符(*)可以用来匹配任何节点,轴可以用来选择与当前节点相关的节点,谓词可以用来筛选符合条件的节点。使用这些技术,我们可以选择任何未知节点,使我们的XPath表达式更加灵活和通用。

Xpath语法较多,我不一一演示,但在后面实战演示中,会依次讲解,帮助大家理解学习。理论讲解完毕,我们进入实战!!! 💨💨
Xpath实战演示
所以今天实战内容是关于美食的,毕竟博主是一个吃货 。🍧 🍨 🍩 🍪 🎂 🍰🧀 🍖 🍗 🥩 🥓 🍔 🍟 🍕 🌭 🥪 🌮 🌯 🍜 🍝 🍠 🍢 🍣
豆果美食实战
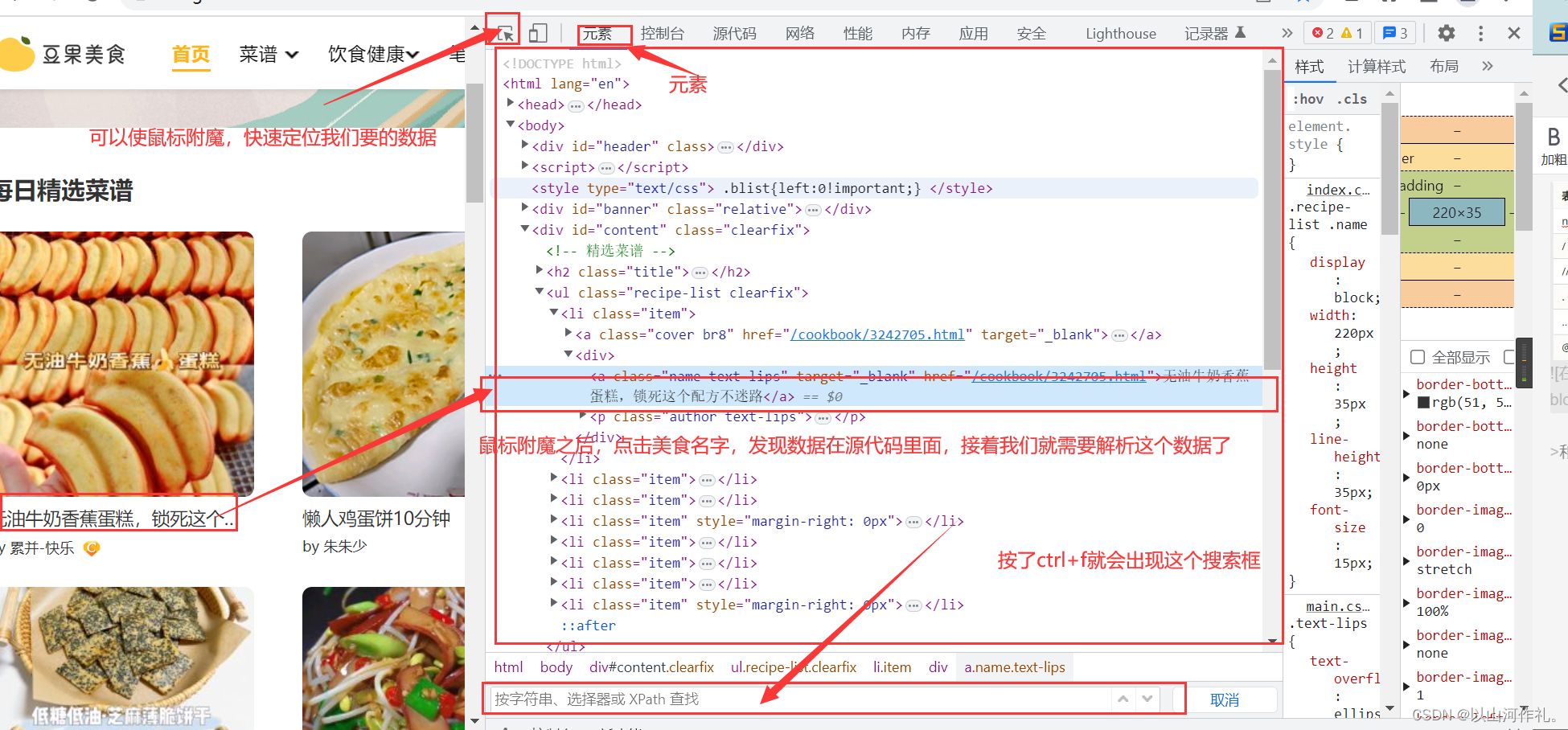
让我们欣赏一下主页吧!
我们今天不获取照片了,毕竟太吸引人了,哈哈哈。

>和之前一样,我们点击右键,选择检查,查看元素,接着按CTRL+F键
在XPath中,nodename指的是XML文档中的节点名称。节点名称可以是元素名称、属性名称、注释名称、处理指令名称等。
第一个是不是很简单,想找那个就输入那个,我们慢慢来。
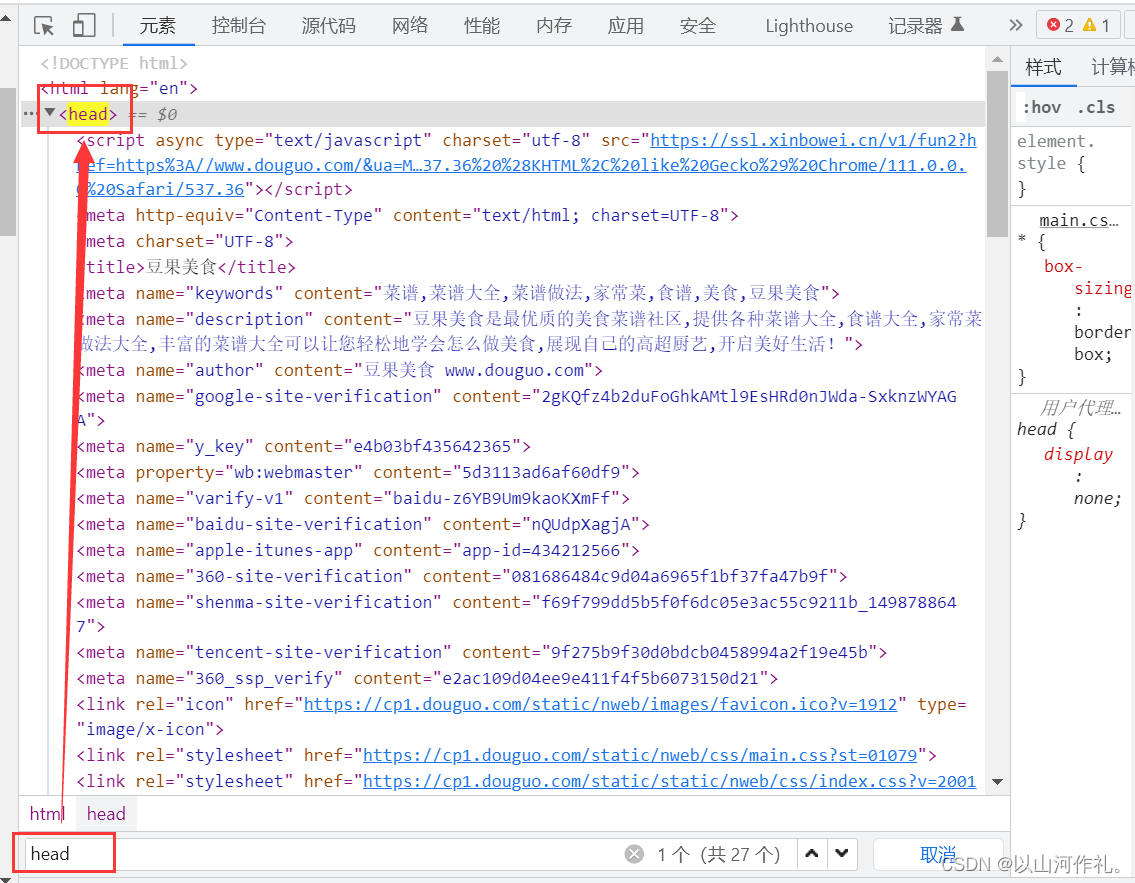
/从根节点选取(取子节点)。
url = 'https://www.douguo.com/'res = requests.get(url)print(res.text)
html = etree.HTML(res.text)
# /从根节点选取(取子节点)。
rest = html.xpath('/html/head/title') # 返回Element对象
print(rest)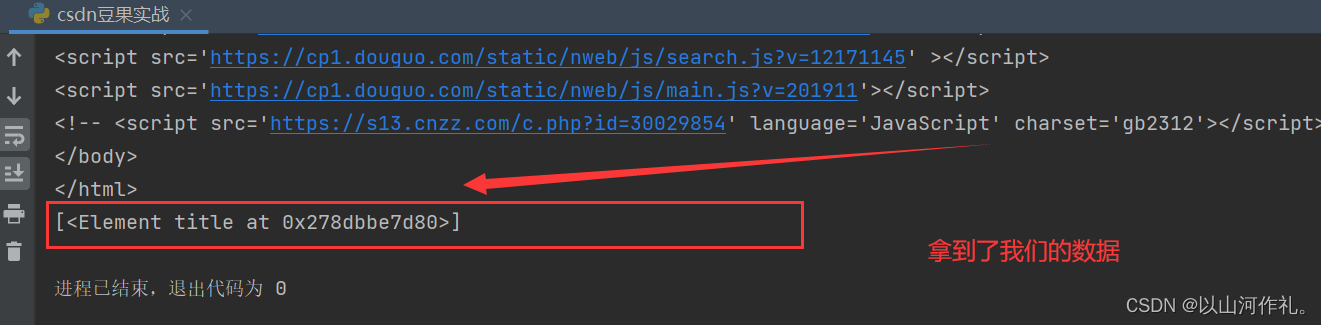
url = 'https://www.douguo.com/'res = requests.get(url)print(res.text)
html = etree.HTML(res.text)
# /从根节点选取(取子节点)。
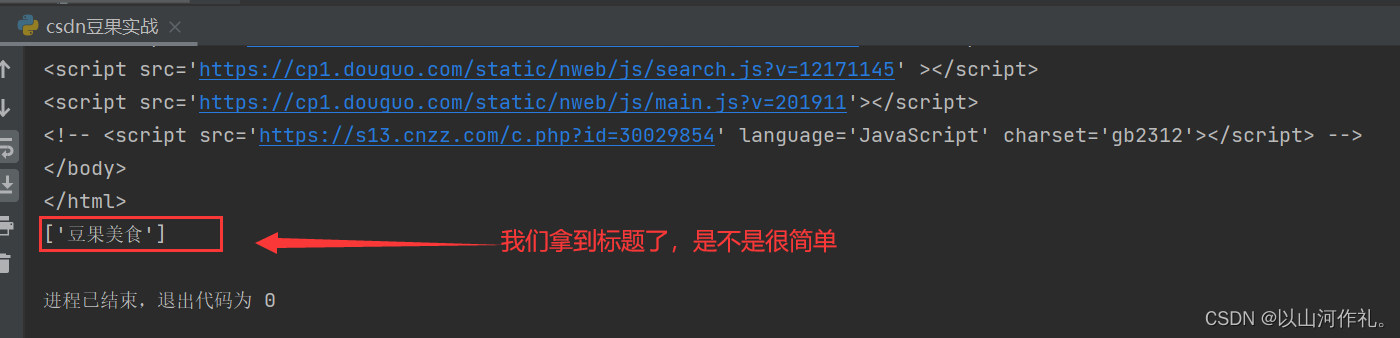
rest = html.xpath('/html/head/title/text()') # 返回Element对象
print(rest)
我们在xpath代码里面加入text(),/text() 获取Element对象的元素内容(元素文本)
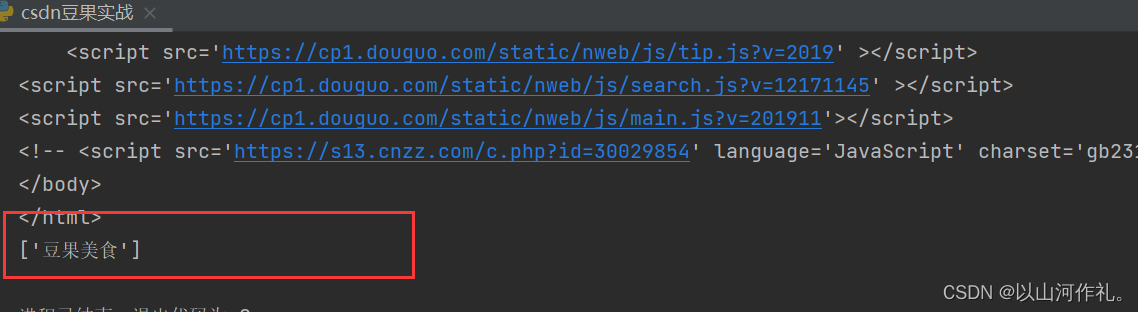
// 获取任何位置的数据,不从根路径出发
# // 获取任何位置的数据,不从根路径出发
title_text = html.xpath('//title/text()') # 一般会获取多个数据
print(title_text)
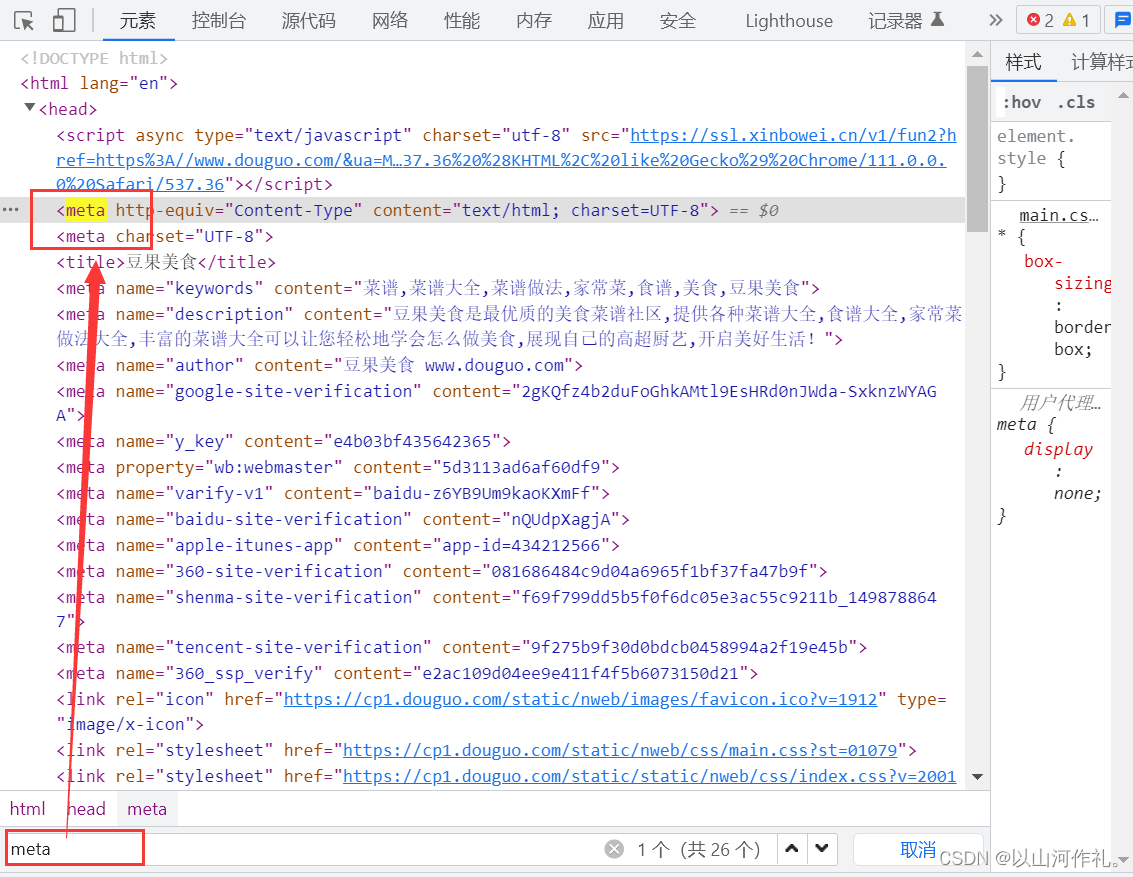
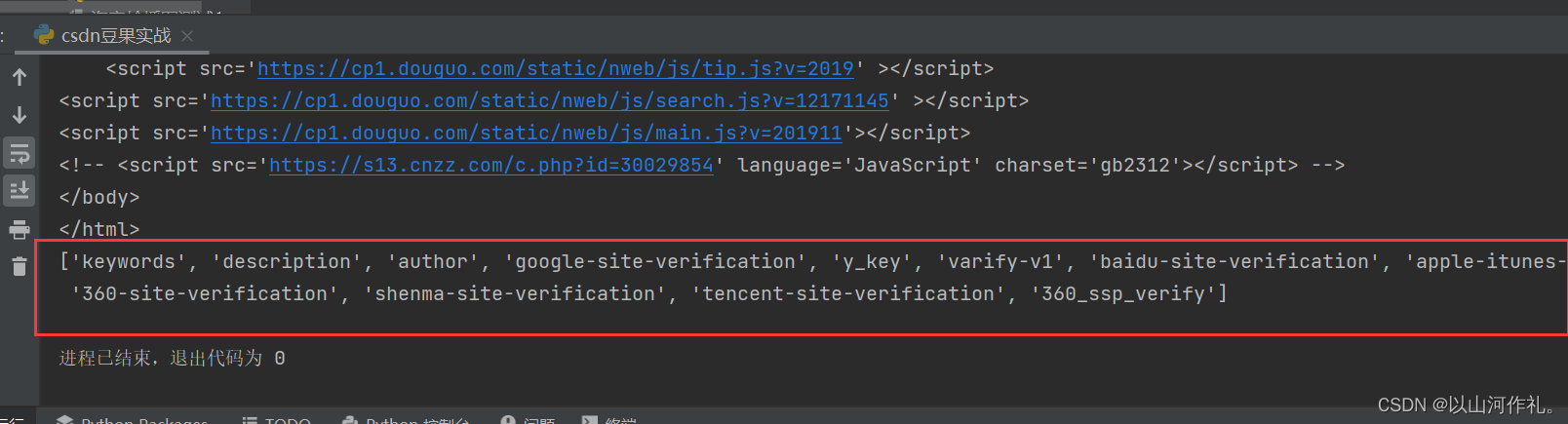
/@属性名 获取标签中的属性名的内容
# /@属性名 获取标签中的属性名的内容
attr = html.xpath('//meta/@name')
print(attr)
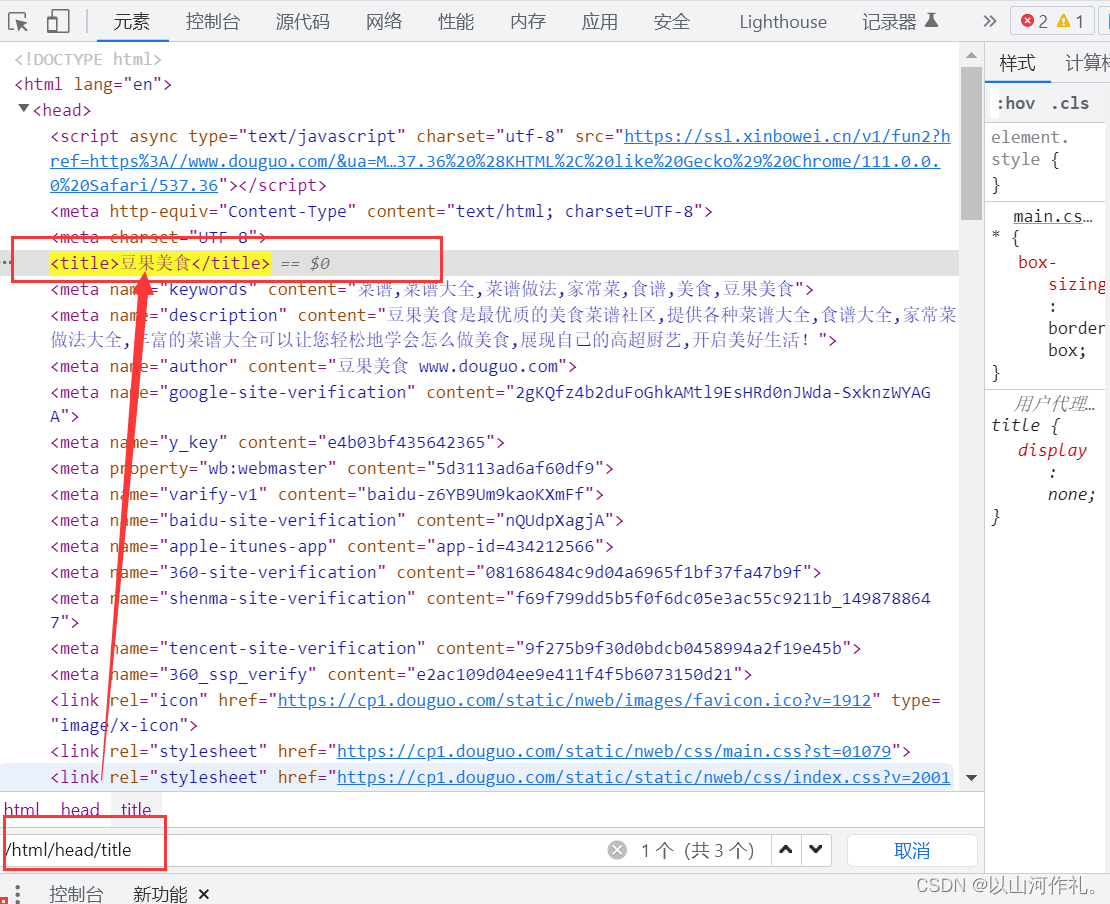
谓语 (相当于python里面的索引,条件) 选取数据中某部分数据
# 谓语 (相当于python里面的索引,条件)
# 选取数据中某部分数据
index = html.xpath('/html/head/meta[3]') # meta[3] 获取meta里面的第3个参数
print(index)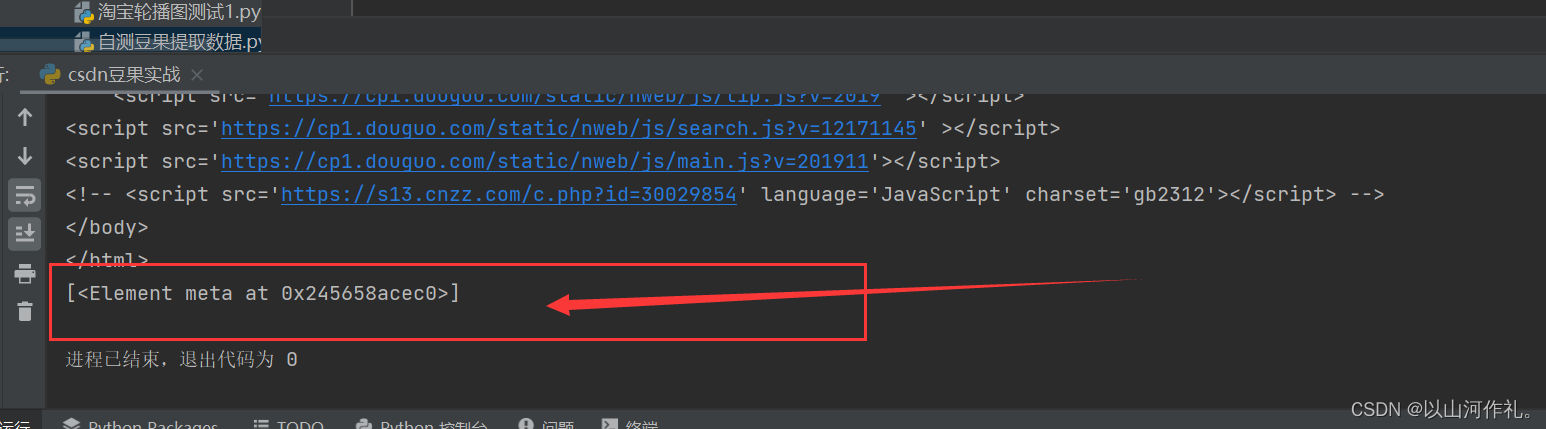
last() 获取最后面的数据
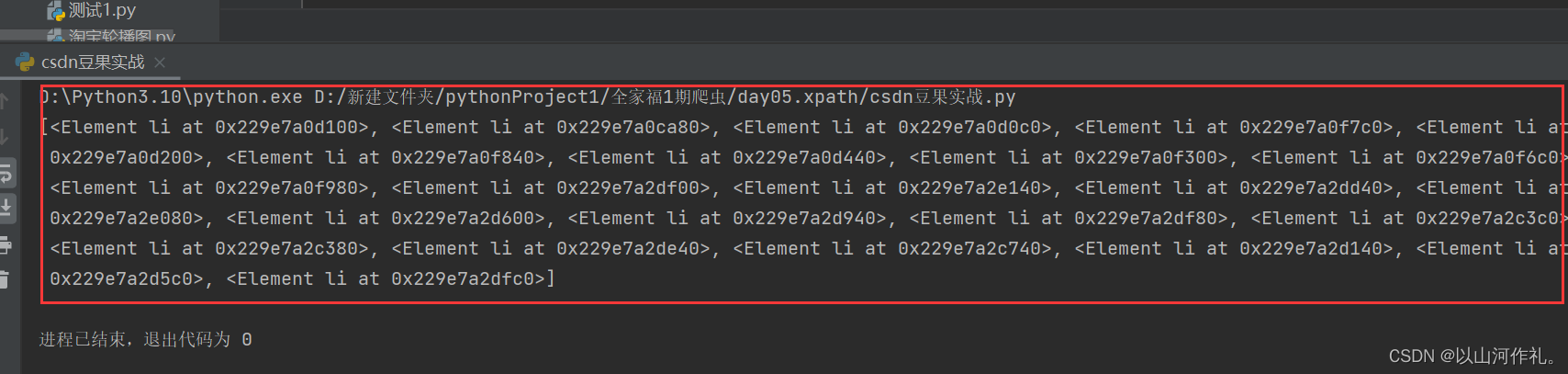
# last() 获取最后面的数据index = html.xpath('/html/body/div[1]/div/a[last()]') # meta[3] 获取meta里面的第3个参数
print(index)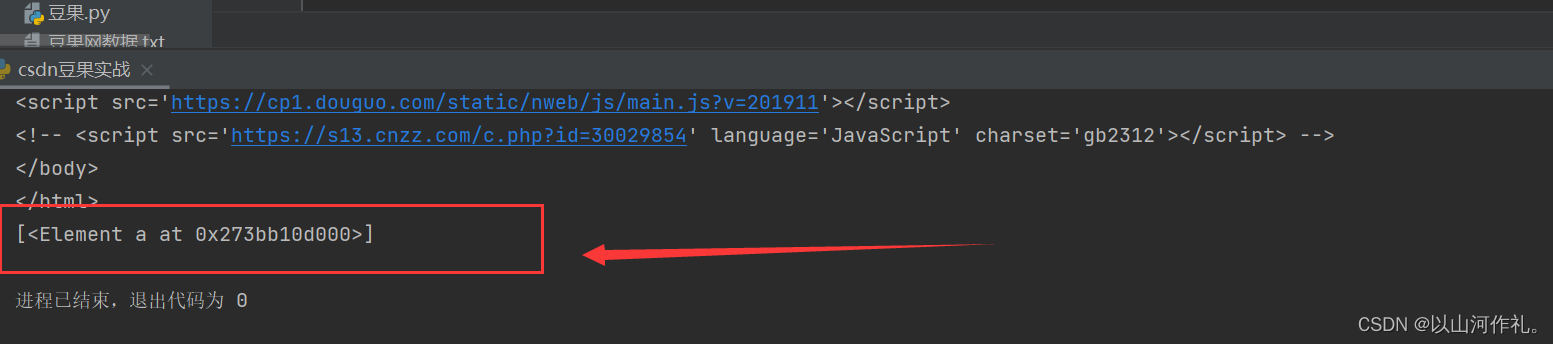
position()<3 获取索引小于3的数据
# position()<3 获取索引小于3的数据
index = html.xpath('/html/body/div[1]/div/a[position()<3]') # meta[3] 获取meta里面的第3个参数
print(index)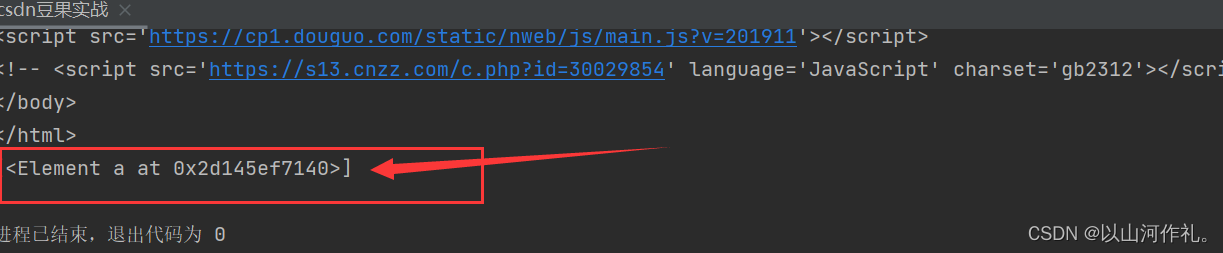
//meta[@charset] 根据标签名 和 属性名称进行数据筛选
# //meta[@charset] 根据标签名 和 属性名称进行数据筛选
index = html.xpath('//meta[@charset]') # meta[3] 获取meta里面的第3个参数
print(index)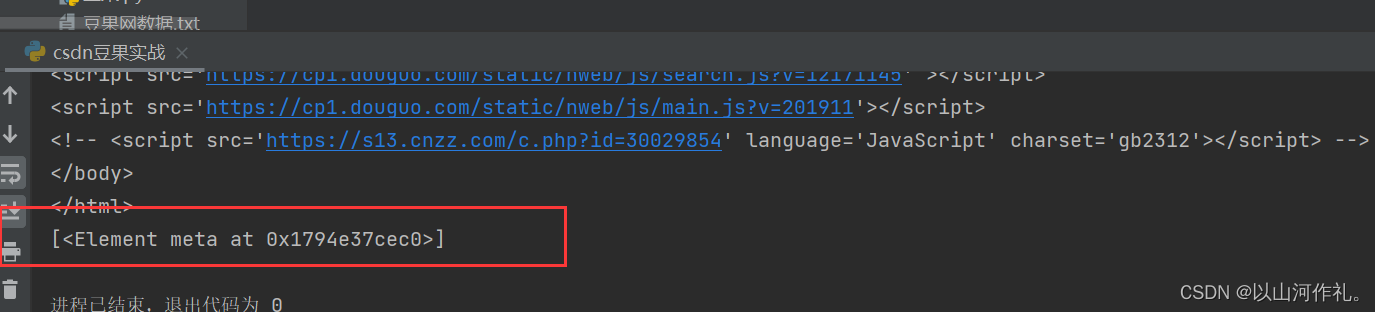
//meta[@name="meta1"] # 标签为meta 并且 里面的属性为name,属性的值为author
# //meta[@name="meta1"] # 标签为meta 并且 里面的属性为name,属性的值为author
index = html.xpath('//meta[@name="author"]')
print(index)
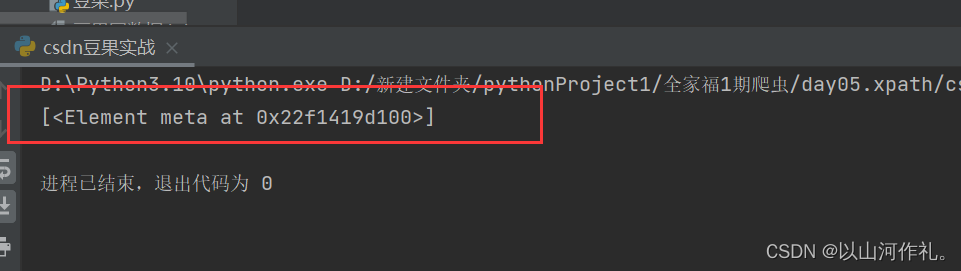
未知节点
不管是什么标签名 只要其中有class="meta1"就获取到
# 未知节点
index = html.xpath('//*[@class="item"]')
# 不管是什么标签名 只要其中有class="meta1"就获取到
print(index)
获取未知的属性
获取meta标签 并且里面有一个属性的值=keywords
# 获取未知的属性
# 获取meta标签 并且里面有一个属性的值=keywords
index = html.xpath('//meta[@*="keywords"]')
print(index)

获取数据
常用的用法基本上都讲了一遍,现在教大家怎么获取更多数据
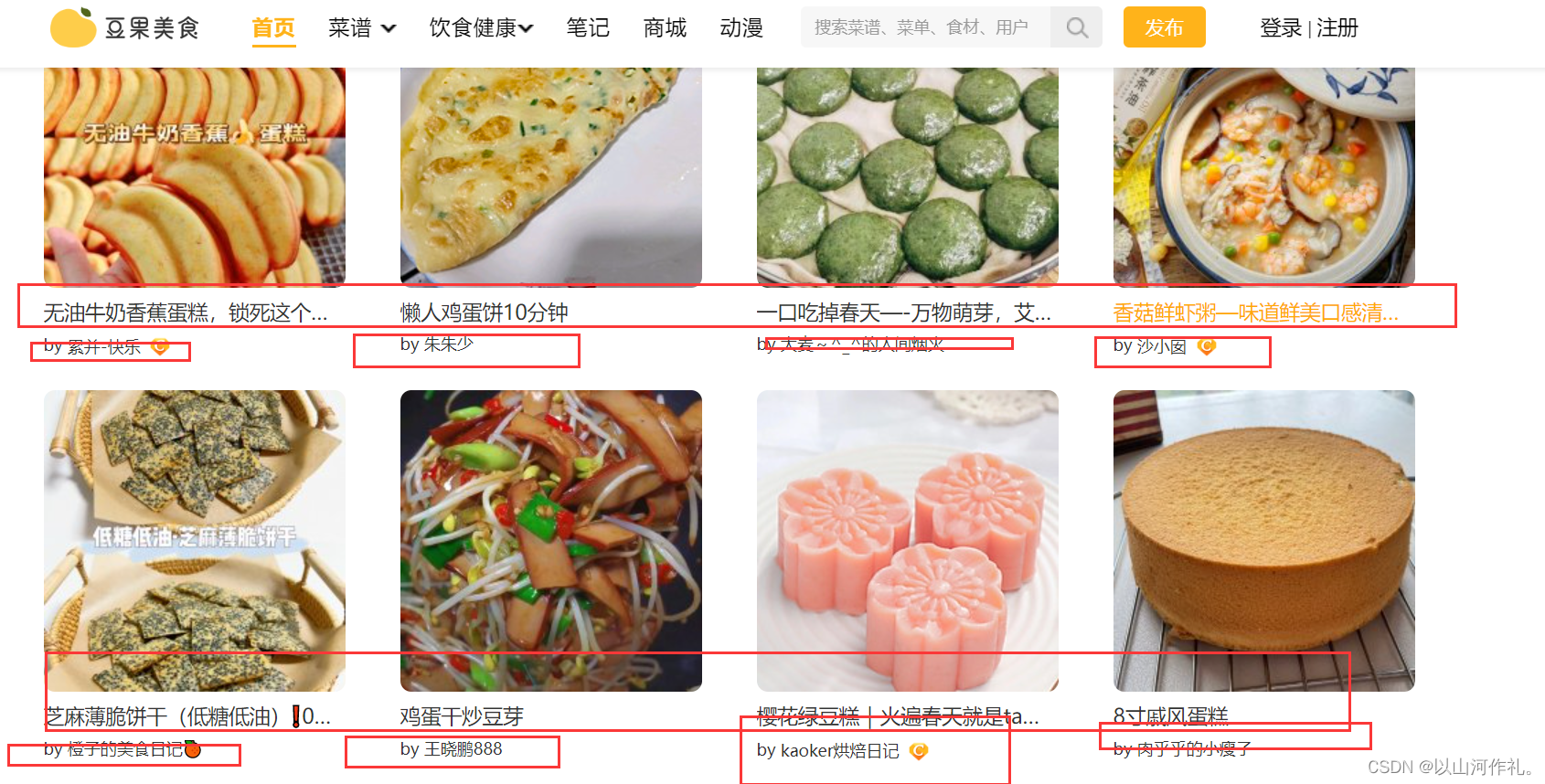
我们来获取这些菜谱的名字和作者的名字
首先,我们获取这个网页的源代码到我们本地,这个就不具体演示了,前面几章已经作了详细的讲解,如果有疑问,可以看我之前的文章。
直接展示:
import time
import requests
from lxml import etree
from tabulate import tabulateurl = 'https://www.douguo.com/'res = requests.get(url)print(res.text)
# html = etree.HTML(res.text)
是不是很简单,几行代码就得到了这些数据,接下来我们对源代码里面的数据用Xpath进行解析,来获取我们想要的数据。
首先我们需要认识一行代码
html = etree.HTML(res.text)这行代码的作用是将 HTTP 响应中的 HTML 文本解析为一个 Element 对象,以便后续对其进行操作,例如提取数据、修改内容、查找元素等等。其中,etree 是 Python 的一个第三方库,可以用来解析 XML 和 HTML 文本。HTML 是一种标记语言,用于构建网页和 Web 应用程序的用户界面。
我们在使用的时候,需要导入,代码如下:
from lxml import etree
进入正题,开始使用Xpath来解析数据:
html = etree.HTML(res.text)
name = html.xpath(f'//*[@id="content"]/ul[1]/li[1]/div/a/text()')
print(name)

很好,我们通过一行代码获取了第一个美食的名字,一共有八个美食,我们不可能写八行代码来获取名字吧,虽然可以,但太繁琐,不宜使用。我们可以使用循环,他们之间一定有内在的联系,通过解析发现,他们路径基本上相同,不同的
li[i]里面的值,我们通过循环来获取名字。
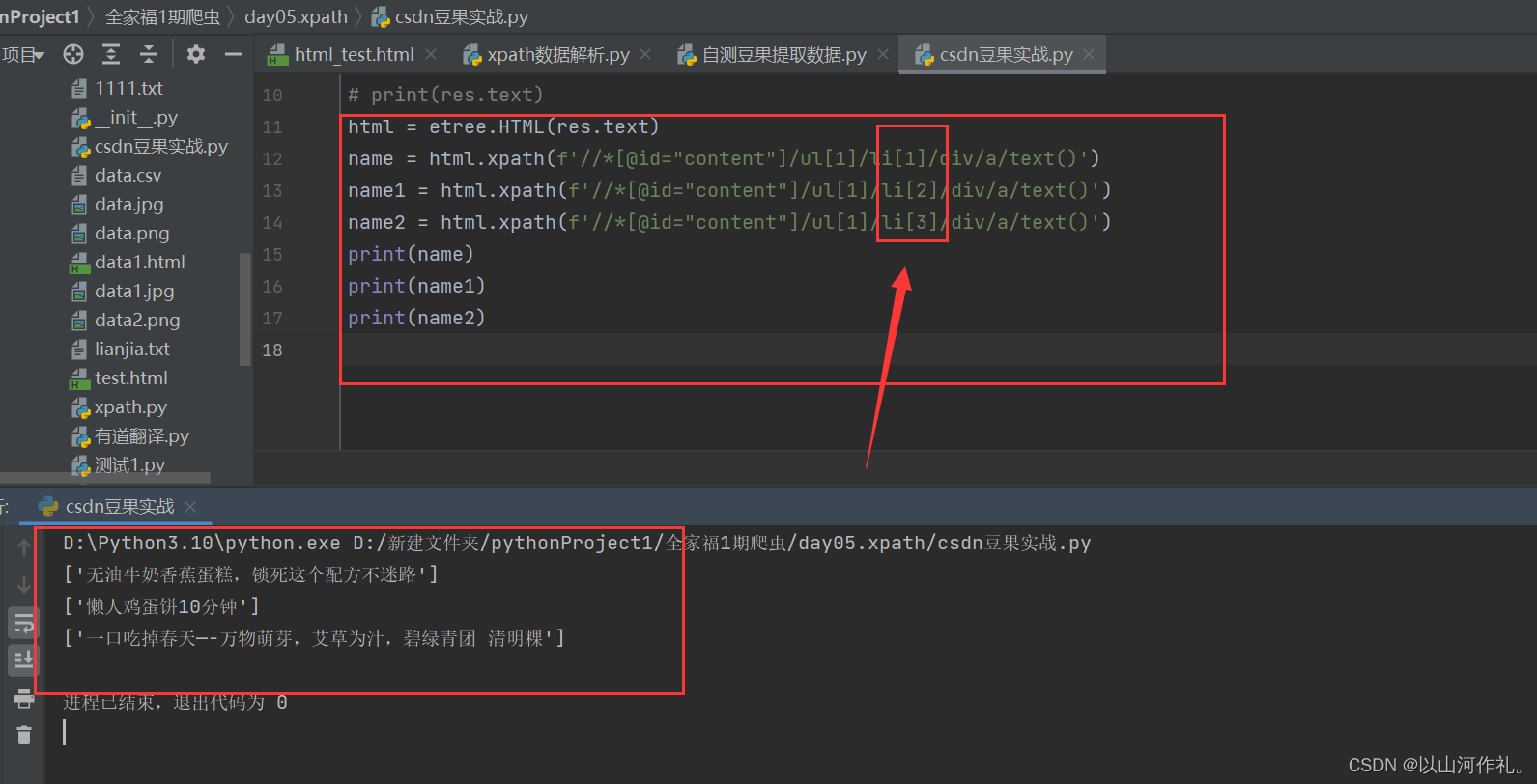
修改后的代码,三行就够了!!
html = etree.HTML(res.text)
for i in range(1, 9):name = html.xpath(f'//*[@id="content"]/ul[1]/li[{i}]/div/a/text()')
# name1 = html.xpath(f'//*[@id="content"]/ul[1]/li[2]/div/a/text()')
# name2 = html.xpath(f'//*[@id="content"]/ul[1]/li[3]/div/a/text()')print(name)
# print(name1)
# print(name2)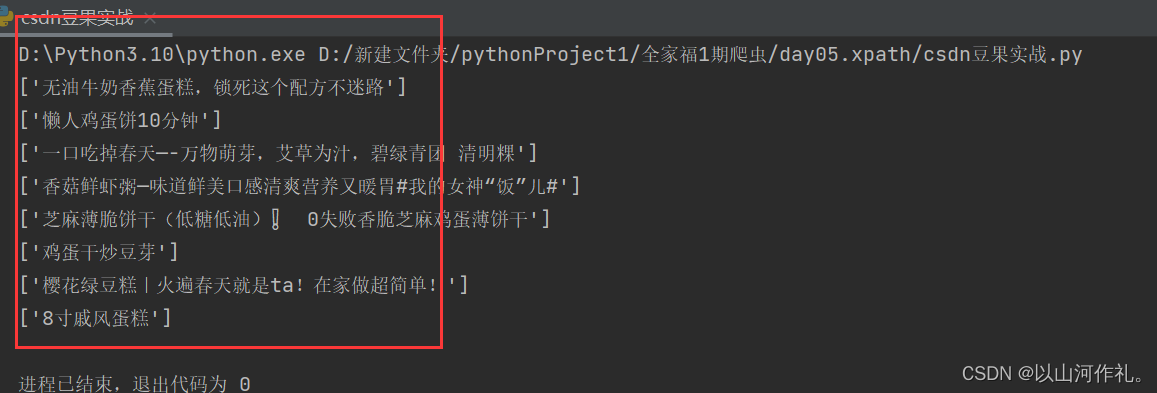
我们获取了前八个美食的名字,接下来我们获取前八个美食的作者名字,方法和前面一样,先找到一个作者的xpath路径,接着找规律,如何用循环写出来,如下:
res = requests.get(url)# print(res.text)
html = etree.HTML(res.text)
for i in range(1, 9):name = html.xpath(f'//*[@id="content"]/ul[1]/li[{i}]/div/a/text()')author = html.xpath(f'//*[@id="content"]/ul[1]/li[{i}]/div/p/a[1]/text()')print(name)print( author)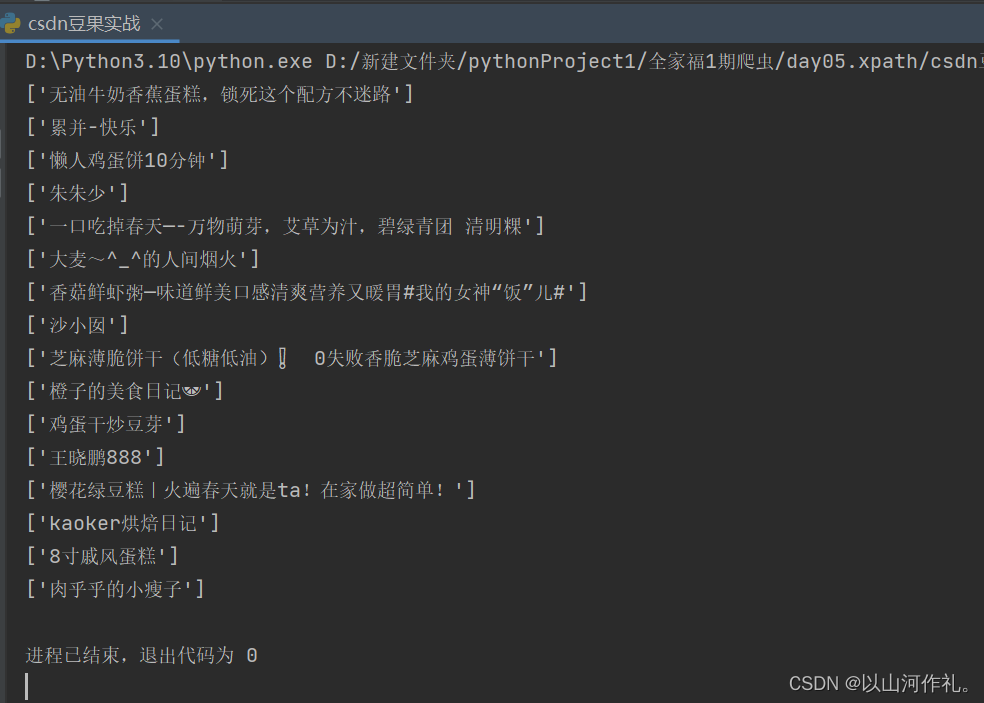
我们获取了想要的数据l,是不是很简单,其实我们还可以美化一下。
result = tabulate([[name, author]], headers=['Name', 'Author'], tablefmt='orgtbl')print(result)将名字和作者的数据以表格的形式输出。具体实现方式是使用tabulate库中的tabulate函数,将数据列表和表头传入函数中,设置输出格式为orgtbl,最后将输出结果打印出来。
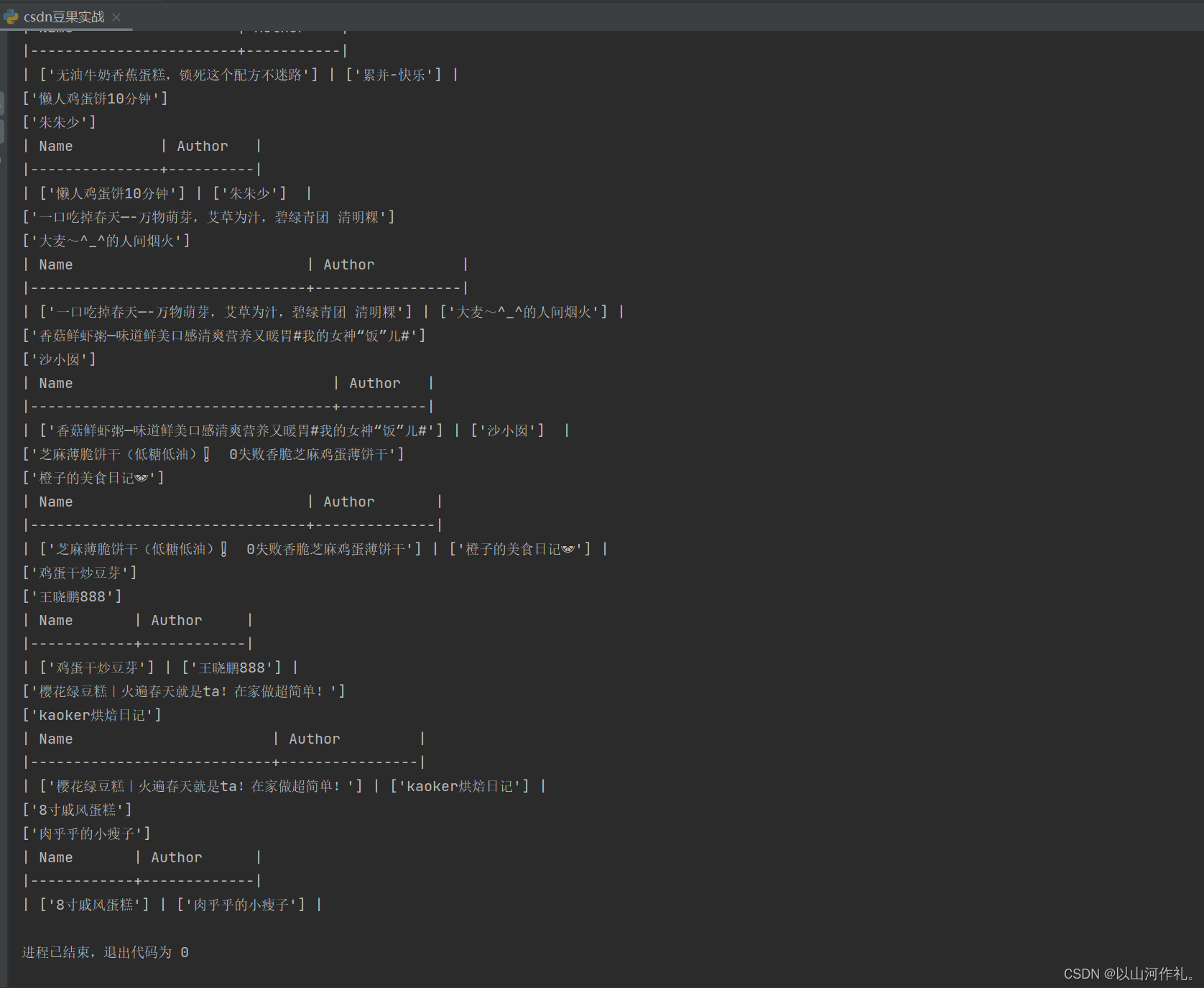
源代码
import time
import requests
from lxml import etree
from tabulate import tabulateurl = 'https://www.douguo.com/'res = requests.get(url)# print(res.text)
html = etree.HTML(res.text)
for i in range(1, 9):name = html.xpath(f'//*[@id="content"]/ul[1]/li[{i}]/div/a/text()')author = html.xpath(f'//*[@id="content"]/ul[1]/li[{i}]/div/p/a[1]/text()')print(name)print(author)result = tabulate([[name, author]], headers=['Name', 'Author'], tablefmt='orgtbl')print(result)🍀🍀写在最后:本篇文章总计
上万字,感谢你能阅读到这里,为你的学习点一个赞。为了写好这篇文章,我学习了三天的数据解析,写了四个小时的文章,一点一点的写出来,方便大家理解学习,如果觉得对你有帮助,点一个赞吧,你的赞是对我最大的鼓励,谢谢啦。🌸🌸🌸