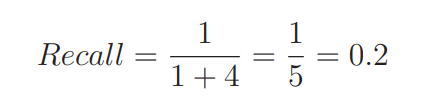目录
- 一、前言
- 二、CAM
- 1. CAM计算过程
- 2. 代码实现
- 3. 流程图
- 三、SAM
- 1. SAM计算过程
- 2. 代码实现
- 3. 流程图
- 四、YOLOv5中添加CBAM模块
- 参考文章
一、前言
由于卷积操作通过融合通道和空间信息来提取特征(通过N×NN×NN×N的卷积核与原特征图相乘,融合空间信息;通过不同通道的特征图加权求和,融合通道信息),论文提出的Convolutional Block Attention Module(CBAM)沿两个独立的维度(通道和空间)依次学习特征,然后与学习后的特征图与输入特征图相乘,进行自适应特征细化。

上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
二、CAM
1. CAM计算过程

输入特征图FFF首先经过两个并行的MaxPool层和AvgPool层,将特征图的维度从C×H×WC×H×WC×H×W变为C×1×1C×1×1C×1×1,然后经过Shared MLP模块。在该模块中,它先将通道数压缩为原来的1/r1/r1/r倍,再经过ReLU激活函数,然后扩张到原通道数。将这两个输出结果进行逐元素相加,再通过一个sigmoid激活函数得到Channel Attention的输出结果,然后将这个输出结果与原图相乘,变回C×H×WC×H×WC×H×W的大小。
上述过程的计算公式如下:
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))M_{c}(F)=\sigma (MLP(AvgPool(F))+MLP(MaxPool(F)))Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))=\sigma (W_{1}(W_{0}(F^{c}_{avg}))+W_{1}(W_{0}(F^{c}_{max})))=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))
其中,σ\sigmaσ代表sigmoid激活函数,W0∈RC/r×CW_{0}\in R^{C/r\times C}W0∈RC/r×C,W1∈RC×C/rW_{1}\in R^{C\times C/r}W1∈RC×C/r,且MLP的权重W0W_{0}W0和W1W_{1}W1对于输入来说是共享的,ReLU激活函数位于W0W_{0}W0之后,W1W_{1}W1之前。
2. 代码实现
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) # 上面公式中的W0self.relu = nn.ReLU()self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) # 上面公式中的W1self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))max_out = self.f2(self.relu(self.f1(self.max_pool(x))))out = self.sigmoid(avg_out + max_out)return torch.mul(x, out)
3. 流程图
CAM过程的详细流程如下图所示:
三、SAM
1. SAM计算过程

将Channel Attention的输出结果通过最大池化和平均池化得到两个1×H×W1×H×W1×H×W的特征图,然后经过Concat操作对两个特征图进行拼接,再通过7×77×77×7卷积将特征图的通道数变为111(实验证明7×77×77×7效果比3×33×33×3好),再经过一个sigmoid得到Spatial Attention的特征图,最后将输出结果与原输入特征图相乘,变回CHW大小。
上述过程的计算公式如下:
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))M_{s}(F)=\sigma (f^{7\times 7}([AvgPool(F);MaxPool(F)])) Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
=σ(f7×7([Favgs;Fmaxs]))=\sigma (f^{7\times 7}([F^{s}_{avg};F^{s}_{max}]))=σ(f7×7([Favgs;Fmaxs]))
其中,σ\sigmaσ代表sigmoid激活函数,f7×7f^{7\times 7}f7×7代表卷积核大小为7×77×77×7的卷积过程。
2. 代码实现
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.sigmoid(self.conv(out))return torch.mul(x, out)
3. 流程图
SAM过程的详细流程如下图所示:

四、YOLOv5中添加CBAM模块
- 修改common.py
在common.py中添加下列代码:
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu = nn.ReLU()self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))max_out = self.f2(self.relu(self.f1(self.max_pool(x))))out = self.sigmoid(avg_out + max_out)return torch.mul(x, out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.sigmoid(self.conv(out))return torch.mul(x, out)class CBAMC3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(CBAMC3, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])self.channel_attention = ChannelAttention(c2, 16)self.spatial_attention = SpatialAttention(7)def forward(self, x):# 将最后的标准卷积模块改为了注意力机制提取特征return self.spatial_attention(self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
- 修改yolo.py
在yolo.py的if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR,......]中添加CBAMC3,即修改后的代码为:
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,C3, C3TR, ASPP, CBAMC3]:c1, c2 = ch[f], args[0] if c2 != no: c2 = make_divisible(c2 * gw, 8) args = [c1, c2, *args[1:]]
- 修改yolov5s.yaml
修改后的yolov5s.yaml如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, CBAMC3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, CBAMC3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, CBAMC3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, CBAMC3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
参考文章
CBAM——即插即用的注意力模块(附代码)