Introduction to Multi-Armed Bandits——05 Thompson Sampling[3]
参考资料
-
Russo D J, Van Roy B, Kazerouni A, et al. A tutorial on thompson sampling[J]. Foundations and Trends® in Machine Learning, 2018, 11(1): 1-96.
-
ts_tutorial
项目代码地址: https://github.com/yijunquan-afk/bandit-learning.git
到目前为止,我们所考虑的 Bernoulli bandit 和最短路径例子中的共轭性质有利于简单和计算效率高的贝叶斯推理。 计算效率制定模型时的一个重要考虑。 然而,很多情况下我们需要更复杂的模型,而精确的贝叶斯推理在计算上是难以实现的。 幸运的是,我们有一些准确的方法可以用来对后验分布进行近似采样。(Approximations)
在本节中,我们将讨论四种近似后验取样的方法。Gibbs sampling、Langevin Monte Carlo、从Laplace approximation中抽样和bootstrap。 作为一个例子,我们考虑在线最短路径问题的一个变体。
一、Binary Feedback
在之前最短路的基础上。假设图代表了 MMM 阶的 binomial bridge,让每个 θe\theta_eθe 独立分布,且是 gamma分布的,E[θe]=1\mathbb{E}[\theta_e] = 1E[θe]=1, E[θe2]=1.5\mathbb{E}[\theta_e^2] = 1.5E[θe2]=1.5,观察值根据如下公式产生:
yt∣θ∼{1with probability 11+exp(∑e∈xtθe−M)0otherwise.\begin{equation*} y_t | \theta \sim \begin{cases} 1 \qquad & \text{with probability } \frac{1}{1 + \exp\left(\sum_{e \in x_t} \theta_e - M\right)} \\ 0 \qquad & \text{otherwise.} \end{cases} \end{equation*} yt∣θ∼{10with probability 1+exp(∑e∈xtθe−M)1otherwise.
我们将奖励看作评级,rt=ytr_t = y_trt=yt。例如,一个Internet路线推荐服务。每天,系统推荐一条路线 xtx_txt ,并收到司机的反馈 yty_tyt ,表示该路线是否可取。当实现的遍历时间 ∑e∈xt\sum_{e \in x_t}∑e∈xt 低于先前的期望值 MMM ,反馈往往是积极的(1),反之亦然(0)。
这个新的模型不具有在第四节中利用的共轭性质,也不适合于有效的精确贝叶斯推理。 不过,这个问题可以通过近似的方法来解决。 为了说明这一点,下图显示了三个近似版本的TS应用于twenty-stage binomial bridge 的在线最短路问题的结果。这些算法利用了Langevin Monte Carlo、Laplace近似和bootstrap这三种方法。 作为比较的基线,还绘制了贪心算法的应用结果。
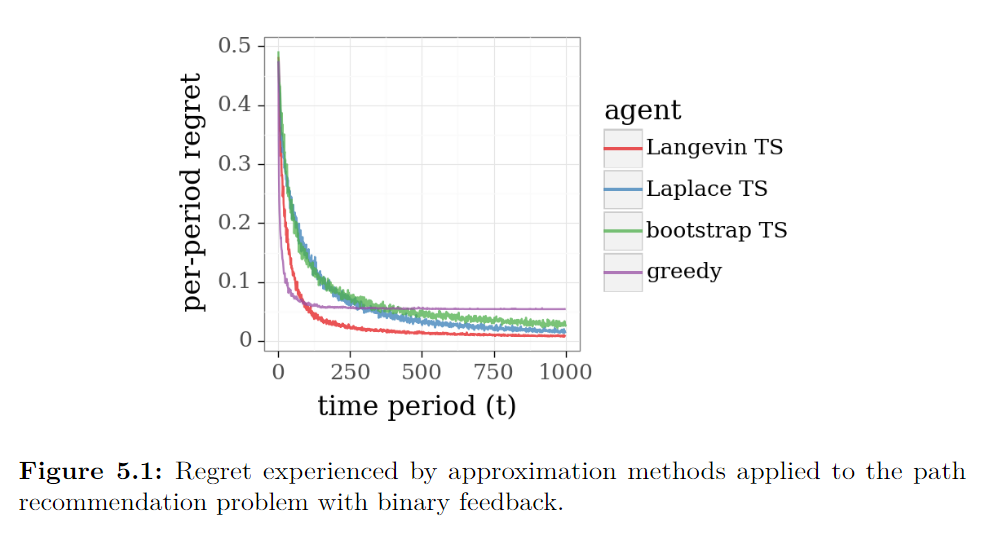
在本节中,我们让 ft−1f_{t-1}ft−1 代表在历史为 Ht−1=((x1,y1),…,(xt−1,yt−1))\mathbb{H}_{t-1} = ((x_1, y_1),\ldots,(x_{t-1},y_{t-1}))Ht−1=((x1,y1),…,(xt−1,yt−1)) 的条件下 θ\thetaθ 的后验密度。TS算法通过从 ft−1f_{t-1}ft−1 中抽取参数向量 θ^\hat{\theta}θ^ 并求解 θ^\hat{\theta}θ^ 下的最优路径来生成动作 xtx_txt 。我们所描述的方法产生了一个样本 θ^\hat{\theta}θ^ ,其分布近似于后验 f^t−1\hat{f}_{t-1}f^t−1,当精确的后验抽样不可行时,可以近似地实现TS的功能。
二、Gibbs Sampling
可以阅读这篇文章:机器学习中的MC、MCMC、Gibbs采样
Gibbs抽样是一种通用马尔可夫链蒙特卡罗(MCMC)算法,用于从多元概率分布中提取近似样本。它产生了一个采样参数序列 (θ^n:n=0,1,2,…)(\hat{\theta}^{n} : n =0,1,2, \ldots)(θ^n:n=0,1,2,…),形成了一个稳定分布的马尔可夫链 ft−1f_{t-1}ft−1 。在合理的技术条件下,该马尔可夫链的极限分布为其平稳分布,θ^n\hat{\theta}^nθ^n 的分布收敛于 ft−1f_{t-1}ft−1。
Gibbs抽样从最初的猜测 θ^0\hat{\theta}^{0}θ^0 开始,迭代遍历n=1,…,Nn=1,\ldots,Nn=1,…,N,对于第n次扫描,该算法迭代分量 k=1,…,Kk=1,\ldots,Kk=1,…,K,对于每个 kkk 生成一维边际分布:
ft−1n,k(θk)∝ft−1((θ^1n,…,θ^k−1n,θk,θ^k+1n−1,…,θ^Kn−1))f^{n,k}_{t-1}(\theta_k) \propto f_{t-1}((\hat{\theta}^n_1, \ldots, \hat{\theta}^n_{k-1}, \theta_k, \hat{\theta}^{n-1}_{k+1}, \ldots, \hat{\theta}^{n-1}_K))ft−1n,k(θk)∝ft−1((θ^1n,…,θ^k−1n,θk,θ^k+1n−1,…,θ^Kn−1))
按照 θ^kn∼ft−1n,k\hat{\theta}^n_k \sim f^{n,k}_{t-1}θ^kn∼ft−1n,k 对第k个分量进行采样。经过 NNN 次的扫描,向量 θ^N\hat{\theta}^{N}θ^N 被认为是近似的后验样本。
Gibbs抽样适用于广泛的问题,即使在从 ft−1f_{t-1}ft−1 抽样时,在计算上也往往是可行的。这是因为从一维分布中取样比较简单。 也就是说,对于复杂的问题,Gibbs抽样在计算上仍有一定要求。 例如我们的二元反馈的路径推荐问题。在这种情况下,很容易实现Gibbs抽样的一个版本,它可以在一分钟内产生一个接近于后验样本的结果。然而, 在数百个时间段内运行数千次模拟是相当耗时的,需要更有效的近似方法。
三、Laplace Approximation
可以参考贝叶斯推断之拉普拉斯近似、拉普拉斯近似法。
我们现在讨论一种方法,用高斯分布来逼近潜在的复杂后验分布。然后,来自这个较简单的高斯分布的样本可以作为感兴趣的后验分布的近似样本。 Chapelle和Li 提出了这种方法,用广告点击率的逻辑回归模型来近似显示广告问题中的TS。
设 ggg 表示 RK\R^KRK 上的概率密度函数,我们希望从中抽样。如果 ggg 是单峰的(unimodal),它的对数密度 ln(g(ϕ))\ln(g(\phi))ln(g(ϕ)) 在其模 ϕ‾\overline{\phi}ϕ 上是严格凹的,g(ϕ)=eln(g(ϕ))g(\phi)= e^{\ln(g(\phi))}g(ϕ)=eln(g(ϕ))在 ϕ‾\overline{\phi}ϕ 周围急剧地达到顶峰。考虑围绕其模进行全局近似是很自然的。对数密度的二阶泰勒近似给出如下:
ln(g(ϕ))≈ln(g(ϕ‾))−12(ϕ−ϕ‾)⊤C(ϕ−ϕ‾),\ln(g(\phi)) \approx \ln(g(\overline{\phi})) - \frac{1}{2} (\phi - \overline{\phi})^\top C (\phi - \overline{\phi}),ln(g(ϕ))≈ln(g(ϕ))−21(ϕ−ϕ)⊤C(ϕ−ϕ),
其中C=−∇2ln(g(ϕ‾)).C = -\nabla^2 \ln(g(\overline{\phi})).C=−∇2ln(g(ϕ)).
我们可以使用
g~(ϕ)∝e−12(ϕ−ϕ‾)⊤C(ϕ−ϕ‾).\tilde{g}(\phi) \propto e^{-\frac{1}{2} (\phi - \overline{\phi})^\top C (\phi - \overline{\phi})}.g~(ϕ)∝e−21(ϕ−ϕ)⊤C(ϕ−ϕ).
作为 ggg 的近似值。这与具有均值 ϕ‾\overline{\phi}ϕ 和协方差 C−1C^{-1}C−1 的高斯分布密度成正比,因此
g~(ϕ)=∣C/2π∣e−12(ϕ−ϕ‾)⊤C(ϕ−ϕ‾).\tilde{g}(\phi) = \sqrt{|C/2\pi|} e^{-\frac{1}{2} (\phi - \overline{\phi})^\top C (\phi - \overline{\phi})}.g~(ϕ)=∣C/2π∣e−21(ϕ−ϕ)⊤C(ϕ−ϕ).
我们称之为 ggg 的 Laplace Approximation. 由于有高效的算法来生成高斯分布的样本,这为从 ggg 中近似取样提供了一种可行的方法。
作为一个例子,让我们考虑拉普拉斯近似在例子binary feedback中的应用。贝叶斯规则表明 ft−1f_{t-1}ft−1 的后验密度 θθθ 满足:
ft−1(θ)∝f0(θ)∏τ=1t−1(11+exp(∑e∈xτθe−M))yτ(exp(∑e∈xτθe−M)1+exp(∑e∈xτθe−M))1−yτf_{t-1}(\theta) \propto f_0(\theta) \prod_{\tau=1}^{t-1} \left(\frac{1}{1 + \exp\left(\sum_{e \in x_\tau} \theta_e - M\right)}\right)^{y_\tau} \left(\frac{\exp\left(\sum_{e \in x_\tau} \theta_e - M\right)}{1 + \exp\left(\sum_{e \in x_\tau} \theta_e - M\right)}\right)^{1-y_\tau} ft−1(θ)∝f0(θ)τ=1∏t−1(1+exp(∑e∈xτθe−M)1)yτ(1+exp(∑e∈xτθe−M)exp(∑e∈xτθe−M))1−yτ
众数(mode) θ‾\overline{\theta}θ 可以通过最大化 ft−1f_{t-1}ft−1 来有效计算,ft−1f_{t-1}ft−1 是对数凹的。然后从高斯分布中抽取一个近似的后验样本 θ^\hat{\theta}θ^,其平均值为 θ‾\overline{\theta}θ,协方差矩阵为 (−∇2ln(ft−1(θ‾)))−1(- \nabla^2 \ln(f_{t-1}(\overline{\theta})))^{-1}(−∇2ln(ft−1(θ)))−1
拉普拉斯近似法非常适合于binray feedback,因为对数后验密度是严格内凹的,其梯度和Hessian矩阵可以有效计算。
我们采用了牛顿方法和回溯线搜索法,使 ln(ft−1)\ln(f_{t-1)}ln(ft−1) 达到最大。 遗憾会衰减,最终应该消失。在我们的例子中,拉普拉斯近似法的表现不如Langevin Monte Carlo。这可能是由于后验分布不够接近高斯。而在TS的实际应用中,拉普拉斯近似是一种流行的方法。
四、Langevin Monte Carlo
我们现在描述一种替代性的马尔科夫链蒙特卡罗(MCMC)方法,它使用目标分布的梯度信息。 让 g(ϕ)g(\phi)g(ϕ) 表示在 RK\mathbb{R}^{K}RK 上的一个对数凹的概率密度函数,我们希望从中取样。假设 ln(g(ϕ))\ln(g(\phi))ln(g(ϕ)) 是可微的,其梯度是可有效计算的。 Langevin dynamics 首先出现在物理学中,指的是扩散过程
dϕt=∇ln(g(ϕt))dt+2dBt(5.1)d\phi_t = \nabla \ln(g(\phi_t)) dt + \sqrt{2} dB_t \tag{5.1} dϕt=∇ln(g(ϕt))dt+2dBt(5.1)
其中 BtB_tBt 是一个标准布朗运动过程,这个过程有 ggg 作为其唯一的静止分布,在合理的技术条件下, ϕt\phi_tϕt $的分布会迅速收敛到这个静止分布。因此,模拟(5.1)提供了一种从 ggg 中近似取样的方法。
通常情况下,我们可以用欧拉离散化来代替这个随机微分方程:
ϕn+1=ϕn+ϵ∇ln(g(ϕn))+2ϵWnn∈N(5.2)\phi_{n+1}= \phi_{n} + \epsilon \nabla \ln(g(\phi_n)) + \sqrt{2\epsilon} W_n \qquad n \in \mathbb{N}\tag{5.2} ϕn+1=ϕn+ϵ∇ln(g(ϕn))+2ϵWnn∈N(5.2)
其中 W1,W2,…W_1, W_2,\ldotsW1,W2,… 是独立同分布的标准高斯随机变量, ϵ>0\epsilon>0ϵ>0 是一个小的步长。与梯度上升法一样,在这种方法下,ϕn\phi_nϕn 倾向于向密度 g(ϕn)g(\phi_n)g(ϕn) 增加的方向漂移。然而,每一步都会注入随机的高斯噪声 WnW_nWn ,因此,对于大的 nnn ,ϕn\phi_nϕn 的位置是随机的。
我们对这个方法做了两个标准的修改以提高计算效率。
-
首先,根据最近的工作,我们实现了stochasticgradientstochastic\ gradientstochastic gradient。Langevin Monte Carlo,它使用采样的小批数据来计算近似梯度而不是精确梯度。我们的实现使用了100个mini-batch的规模。当观测值少于100个时,我们遵循Markov链(5.2),进行精确梯度计算。当收集到超过100个观测值时,我们遵循(5.2),但在每一步使用基于100个数据点的随机子样本的估计梯度 ∇ln(g^n(ϕn))\nabla \ln(\hat{g}_n(\phi_n))∇ln(g^n(ϕn)) 。
-
我们的第二个修改涉及到使用一个预处理矩阵来提高马尔科夫链(5.2)的混合率。对于
binary feedback中的路径推荐问题,我们发现对数后验密度在后期变得病态的。由于这个原因,梯度上升法收敛到后验众数(mode)的速度非常慢。有效的优化方法应该利用二阶信息。同样,由于条件较差,我们可能需要选择一个极小的步长 ϵ\epsilonϵ ,导致(5.2)中的Markov链混合缓慢。Langevin MCMC可以通过模拟马尔科夫链,用对称正定预处理矩阵 AAA 实现
ϕn+1=ϕn+ϵA∇ln(g(ϕn))+2ϵA1/2Wnn∈N\phi_{n+1}= \phi_{n} + \epsilon A \nabla \ln(g(\phi_n)) + \sqrt{2\epsilon} A^{1/2} W_n \qquad n \in \mathbb{N} ϕn+1=ϕn+ϵA∇ln(g(ϕn))+2ϵA1/2Wnn∈N
其中 A1/2A^{1/2}A1/2 表示 AAA 的矩阵平方根。我们采取 ϕ0=argmaxϕln(g(ϕ))\phi_0 = \text{argmax}_{\phi} \ln(g(\phi))ϕ0=argmaxϕln(g(ϕ)),所以链的初始化是在后验众数(mode)。并采取预处理矩阵 A=−(∇2ln(g(ϕ))∣ϕ=ϕ0)−1A= -(\nabla^2 \ln(g(\phi)) \rvert_{\phi=\phi_0})^{-1}A=−(∇2ln(g(ϕ))∣ϕ=ϕ0)−1 为该点的负逆Hessian。
五、Bootstrapping
bootstrap的解释可以看这个:用 Bootstrap 进行参数估计大有可为
作为一种替代方法,我们讨论了一种基于 statistical bootstrap 的方法,它甚至可以容纳非常复杂的密度。 我们介绍一个适用于我们在本教程中涉及的例子。
与拉普拉斯近似法一样,我们的bootstrap法也假定θ\thetaθ 是从欧几里得空间 RKR^KRK中抽取。首先考虑一个标准的bootstrap法,用于评估 θ\thetaθ 的最大似然估计的抽样分布。该方法产生了一个假设的历史 Ht−1^=((x^1,y^1),…,(x^t−1,y^t−1))\hat{\mathbb{H}_{t-1}} = ((\hat{x}_1,\hat{y}_1), \ldots, (\hat{x}_{t-1}, \hat{y}_{t-1}))Ht−1^=((x^1,y^1),…,(x^t−1,y^t−1)) ,它由 t−1t-1t−1 action−observationaction-observationaction−observation 对组成,每个人都从 Ht−1\mathbb{H}_{t-1}Ht−1 均匀采样并替换。然后,我们在假设的历史下最大化 θ\thetaθ 的可能性,对于我们的最短路径推荐问题来说,这个可能性是这样的:
L^t−1(θ)=∏τ=1t−1(11+exp(∑e∈x^τθe−M))y^τ(exp(∑e∈x^τθe−M)1+exp(∑e∈x^τθe−M))1−y^τ\hat{L}_{t-1}(\theta) = \prod_{\tau=1}^{t-1} \left(\frac{1}{1 + \exp\left(\sum_{e \in \hat{x}_\tau} \theta_e - M\right)}\right)^{\hat{y}_\tau} \left(\frac{\exp\left(\sum_{e \in \hat{x}_\tau} \theta_e - M\right)}{1 + \exp\left(\sum_{e \in \hat{x}_\tau} \theta_e - M\right)}\right)^{1-\hat{y}_\tau} L^t−1(θ)=τ=1∏t−1(1+exp(∑e∈x^τθe−M)1)y^τ(1+exp(∑e∈x^τθe−M)exp(∑e∈x^τθe−M))1−y^τ
最大化器中的随机性 L^t−1\hat{L}_{t-1}L^t−1 反映了最大似然估计的抽样分布的随机性。不幸的是,这种方法并没有考虑到代理人的先验。一个更严重的问题是,它严重低估了智能体在初始时期的真实不确定性。我们将以一种简单的方式克服这些缺点。
该方法的步骤如下。首先,像以前一样,我们抽取一个假设的历史 Ht−1^=((x^1,y^1),…,(x^t−1,y^t−1))\hat{\mathbb{H}_{t-1}} = ((\hat{x}_1,\hat{y}_1), \ldots, (\hat{x}_{t-1}, \hat{y}_{t-1}))Ht−1^=((x^1,y^1),…,(x^t−1,y^t−1)),它由t−1t-1t−1 action−observationaction-observationaction−observation 对组成,每个人都从 Ht−1\mathbb{H}_{t-1}Ht−1 均匀采样并替换。接下来,我们从先验分布 f0f_0f0 中抽取一个样本 θ0\theta^0θ0。让 Σ\SigmaΣ 表示先验 f0f_0f0 的协方差矩阵。最后,我们解决最大化问题
θ^=argmaxθ∈Rke−(θ−θ0)⊤Σ(θ−θ0)L^t−1(θ)\hat{\theta} = \text{argmax}_{\theta \in \mathbb{R}^k} \,\, e^{-(\theta-\theta^0)^\top \Sigma (\theta - \theta^0)} \hat{L}_{t-1}(\theta) θ^=argmaxθ∈Rke−(θ−θ0)⊤Σ(θ−θ0)L^t−1(θ)
并将 θ^\hat{\theta}θ^ 视为近似的后验样本。这可以看作是对后验密度的随机近似 f^t−1\hat{f}_{t-1}f^t−1 的最大化,其中 f^t−1(θ)∝e−(θ−θ0)⊤Σ(θ−θ0)L^t−1(θ)\hat{f}_{t-1}(\theta) \propto e^{-(\theta-\theta^0)^\top \Sigma (\theta - \theta^0)} \hat{L}_{t-1}(\theta)f^t−1(θ)∝e−(θ−θ0)⊤Σ(θ−θ0)L^t−1(θ) 是指如果先验是均值为 θ0\theta^0θ0、协方差矩阵为 Σ\SigmaΣ 的高斯分布,而观察的历史是 H^t−1\hat{\mathbb{H}}_{t-1}H^t−1,后验密度会是什么。当收集到的数据很少时,样本中的随机性大多源于先验样本 θ0\theta_0θ0 的随机性。这种随机的先验样本鼓励智能体在早期阶段进行探索。当 ttt 很大时,已经收集了大量的数据,可能性通常压倒了先验样本,样本中的随机性主要来自于对历史 H^t−1\hat{\mathbb{H}}_{t-1}H^t−1 的随机选择。
在最短路径推荐问题中,f^t−1(θ)\hat{f}_{t-1}(\theta)f^t−1(θ) 是对数凹的,因此可以有效地实现最大化。 同样,为了得出图中报告的计算结果,我们采用了牛顿方法和回溯线搜索来最大化 ln(f^t−1)\ln(\hat{f}_{t-1})ln(f^t−1)。
从图中可以看出,对于我们的例子,bootstrap法的表现与拉普拉斯近似法差不多。 bootstrap法的一个优点是它是非参数性的,无论后验分布的函数形式如何,它都可以合理地工作,而拉普拉斯近似法则依赖于高斯近似法,Langevin Monte Carlo 法则依赖于log-concavity和其他规则性假设。
六、健全性检查
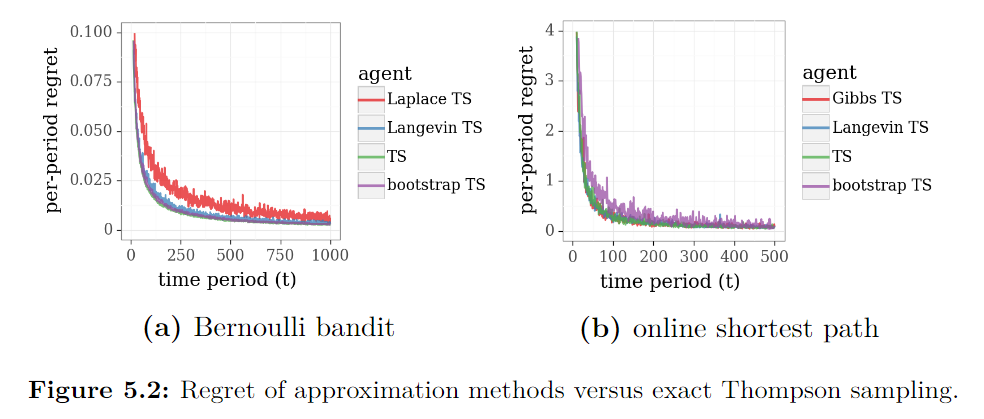
图5.1展示了Laplace approximation、Langevin Monte Carlo和bootstrap方法在应用于路径推荐问题时,从二项反馈中学习,以随着时间的推移提高性能。然而,这可能会让人疑惑,确切的TS是否会提供更好的性能。由于我们没有可处理的方法来执行该问题的精确TS,因此在本节中,我们将我们的近似方法应用于精确TS可处理的问题。这使得可以比较精确方法和近似方法的性能。
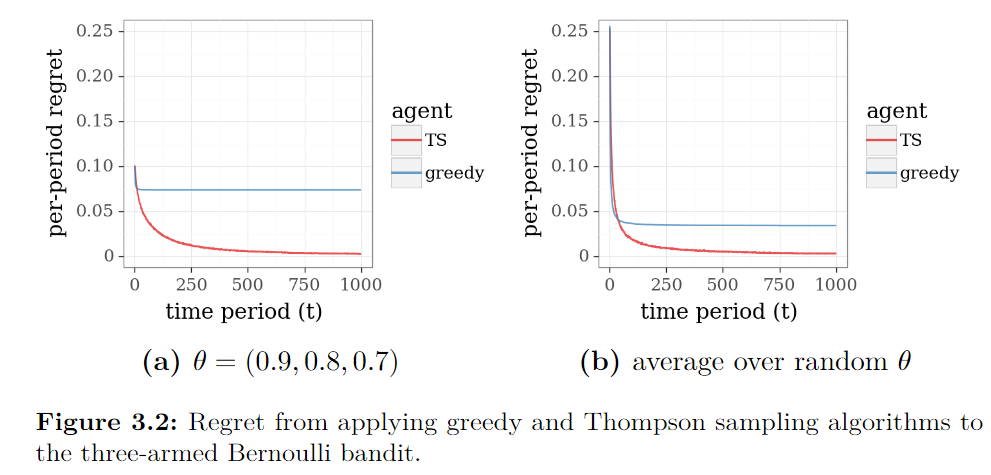
回顾一下三臂beta-Bernoulli强盗问题,其贪心算法和TS算法的结果如上图所示。对于这个问题,θ\thetaθ 的各分量在后验分布下是独立的。因此,Gibbs抽样可以得到精确的后验样本。 因此,使用Gibbs抽样的近似版本的性能将与精确的TS完全相同。下图中的a绘制了应用Laplace approximation、Langevin Monte Carlo和bootstrap方法的结果。对于这个问题,我们的近似方法提供的性能与精确的TS在质量上相似,拉普拉斯近似法的表现比其他方法略差。
接下来,考虑具有correlated边延迟的在线最短路径问题。如图b所示。应用拉普拉斯近似方法与适当的变量替换达到了与精确TS相同的结果。 图中将这些结果与Gibbs sampling、Langevin Monte Carlo和bootstrap方法所产生的结果进行了比较。同样,近似方法产生了有竞争力的结果,bootstrap的效果略逊于其他方法。