不会涉及到Optimizers 的数学证明!
文章目录
- Some Notations
- Different Optimizers
- SGD
- SGD with Momentum(SGDM)
- Adagrad
- RMSProp
- Adam
- Optimizers: Real Application
- Adam vs SGDM
- Towards Improving Adam
- AMSGrad
- AdaBound
- Towards Improving SGDM
- LR range test
- Cyclical LR
- SGDR
- One-cycle LR
- 基于warm-up改进的RAdam
- RAdam vs SWATS
- k step forward, 1 step back
- Lookahead
- Can we look into the future?
- Nesterov accelerated gradient (NAG)
- Adam in the future:Nadam&SGDM
- Do you really know your optimizer?
- A story of L2 regularization…
- AdamW & SGDW with momentum
- Something helps optimization…
- learned &Advices
Some Notations
- θt:\theta_t:θt:时间步长t的模型参数
- ▽L(θt)orgt:\triangledown L(\theta_t)or \ g_t:▽L(θt)or gt:θt\theta_tθt处的梯度(loss),用于计算θt+1\theta_{t+1}θt+1
- mt+1:m_{t+1}:mt+1:从第0步累计到第t步的动量(压缩),用于计算θt+1\theta_{t+1}θt+1
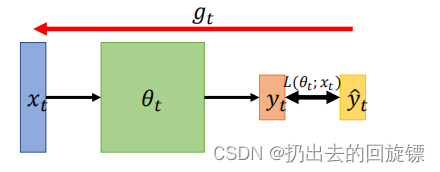
神经网络架构:On-line
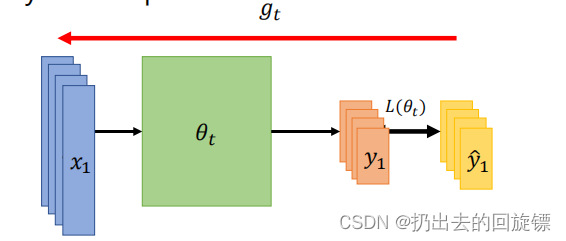
神经网络架构:Off-line
Different Optimizers
SGD
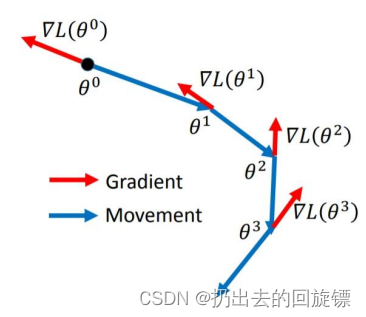
首先计算θ0\theta_{0}θ0的gradient,由于要最小的L,所以是往反方向走,依次重复这个步骤直到t时刻▽L(θt)\triangledown L(\theta_t)▽L(θt)计算达到设定阈值
SGD with Momentum(SGDM)
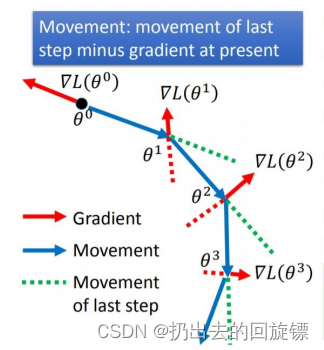
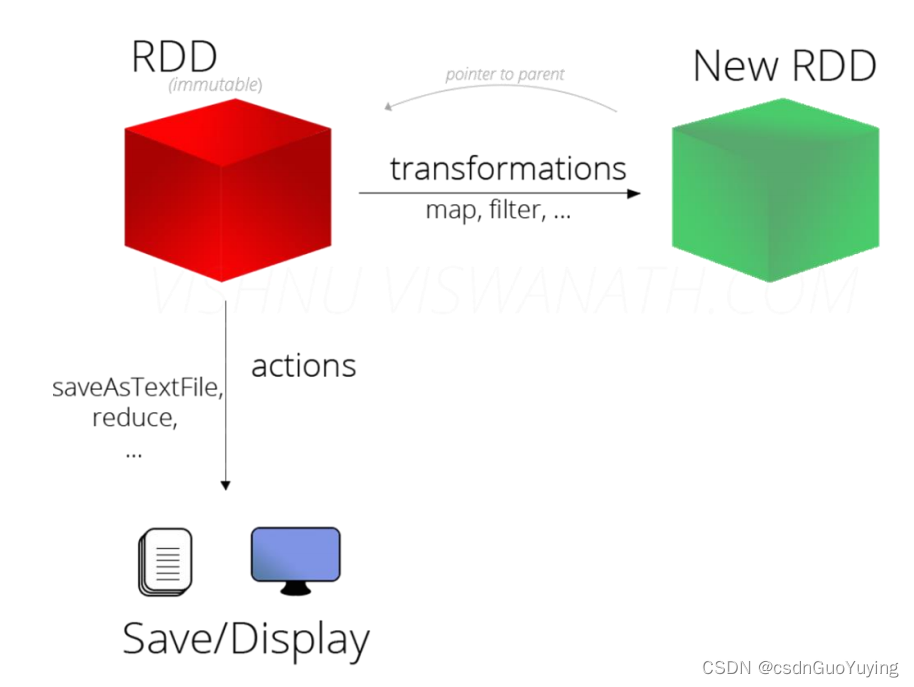
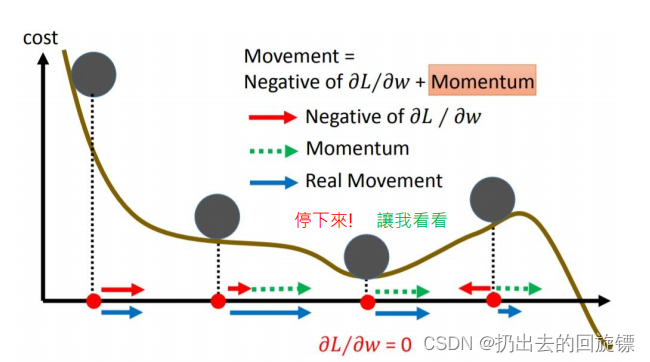
引入动量Momentum后,每次除了计算当前点的梯度外,还要将上一次移动的方向考虑进来,这样可以学习接触的范围更大,不一定会卡在局部最低点,形象图表示如下:
Adagrad
wt+1←wt−ηtσtgtw^{t+1}\leftarrow w^t-\frac{\eta^t}{\sigma^t}g^twt+1←wt−σtηtgt
其中,ηt\eta^tηt一般选择ηt+1\frac{\eta}{\sqrt{t+1}}t+1η,σt\sigma^tσt表示参数w之前偏导数(gig^igi)的均方根,所以可以化简:
wt+1←wt−ηt+11t+1∑i=0t(gi)2gt=wt−η∑i=0t(gi)2gtw^{t+1}\leftarrow w^t-\frac{\frac{\eta}{\sqrt {t+1}}}{\sqrt{\frac{1}{t+1}\sum_{i=0}^{t}(g^i)^2}}g^t\\ =w^t-\frac{\eta}{\sqrt{\sum_{i=0}^{t}(g^i)^2}}g^twt+1←wt−t+11∑i=0t(gi)2t+1ηgt=wt−∑i=0t(gi)2ηgt
这里两位老师对算法的说法有一点点区别,这里说明一下:
- 李宏毅老师上节课用二次函数的最佳间隔分子应该是二次微分举例,让分子为∑i=0t(gi)2\sqrt{\sum_{i=0}^{t}(g^i)^2}∑i=0t(gi)2是在不改变计算量的情况下作为二次微分的估计提高效率
- 这节课的老师表达的是,当之前的偏导计算小的时候增强增加效率,计算大的时候削弱防止错过
RMSProp
wt+1←wt−ηvtgtw^{t+1}\leftarrow w^t-\frac{\eta}{\sqrt v_t}g^twt+1←wt−vtηgt
其中,v1=g02v_1=g_0^2v1=g02,vt=αvt−1+(1−α)(gt−1)2v_t=\alpha v_{t-1}+(1-\alpha)(g_{t-1})^2vt=αvt−1+(1−α)(gt−1)2。目的是解决Adagrad算法中如果开始求的微分很大导致计算特别缓慢的问题
Adam
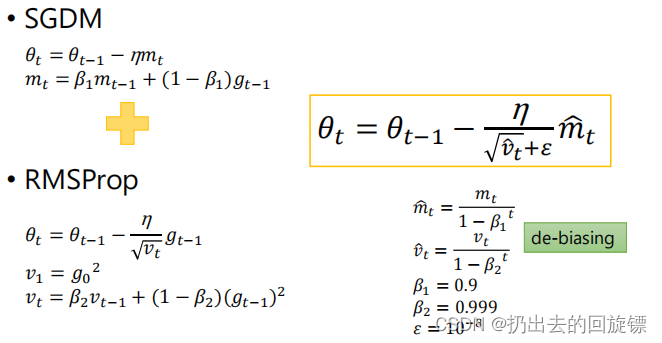
mt1−β1t\frac {m_t}{1-\beta_1^t}1−β1tmt和vt1−β2t\frac {v_t}{1-\beta_2^t}1−β2tvt的计算是为了de-biasing
Optimizers: Real Application
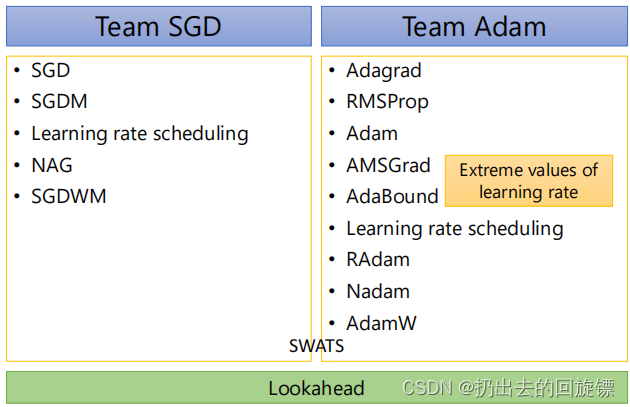
市面上几乎所有的模型都被ADAM和SGDM占有了,具体的有
- ADAM:Tacotron、Transformer、BER、Big-Gan、MAML…
- SGDM:Mask R-CNN、YOLO、ResNe…
实际上,自从2014年Adam问世之后,几乎没有更加优秀的Optimizers出现,市场也可以体现这个问题,接下来就重点关注这两个算法!
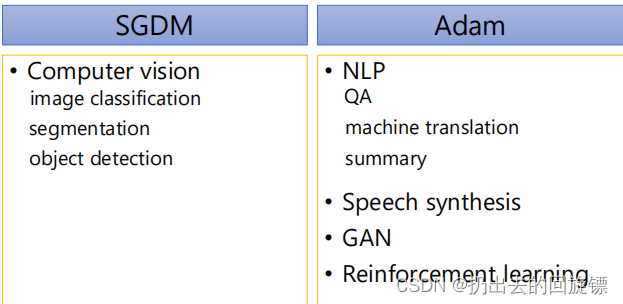
Adam vs SGDM
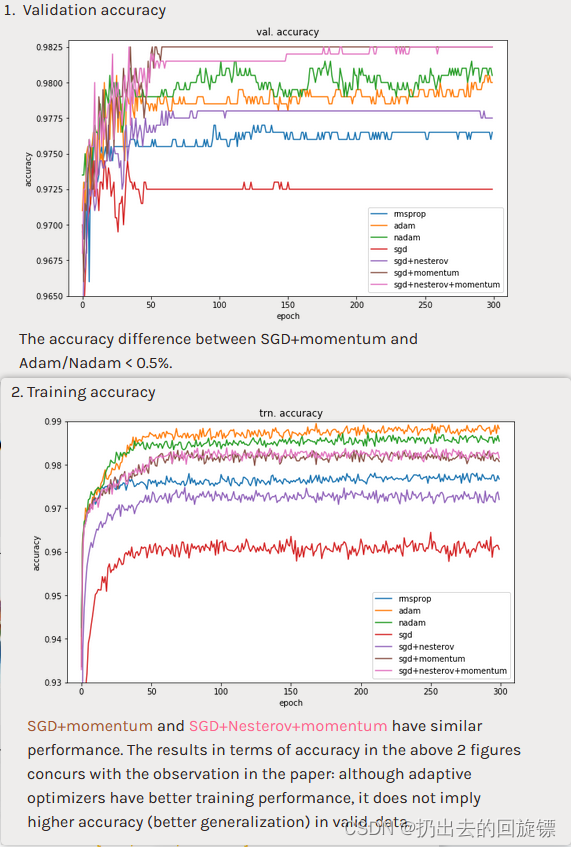
在这篇文章中通过实验证明SGDM并不逊色Adam,通常认为二者特点如下:
- Adam:fast training, large generalization gap, unstable
- SGDM:stable, little generalization gap, better convergence
当然,有人尝试先使用收敛快的Adam再切换成稳定的SGDM,称作SWATS算法,简单示意图如下
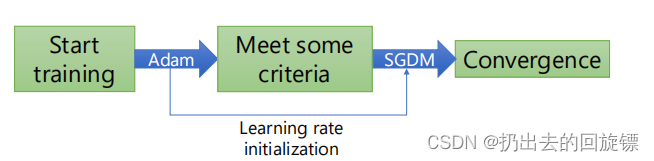
但是作者并没有清楚的解释实际优化多少,但也是不错的尝试
Towards Improving Adam
从它的公式中β2\beta_2β2=0.999与梯度相乘可以得出,vtv_tvt的记忆可以持续1000步。所以如果训练的某个阶段大多数梯度计算都较小,如果突然出现较大的梯度会导致从移动的不够快。基于这个问题有两个改进的算法:
AMSGrad
θt=θt−1−ηv^t+εmtv^t=max(v^t−1,vt)\theta_t=\theta_{t-1}-\frac{\eta}{\sqrt {\hat v_t}+\varepsilon}m_t \\ \hat v_t=max(\hat v_{t-1},v_t)θt=θt−1−v^t+εηmtv^t=max(v^t−1,vt)
特点:
- 减少非信息梯度的影响
- 学习率单调递减
- 只解决了large learning rates 的问题
AdaBound
θt=θt−1−Clip(ηv^t+ε)m^tClip(x)=Clip(x,0.1−0.1(1−β2)t+1,0.1+0.1(1−β2)t)\theta_t=\theta_{t-1}-Clip(\frac{\eta}{\sqrt {\hat v_t+\varepsilon}})\hat m_t \\ Clip(x)=Clip(x,0.1-\frac{0.1}{(1-\beta_2)t+1},0.1+\frac{0.1}{(1-\beta_2)t})θt=θt−1−Clip(v^t+εη)m^tClip(x)=Clip(x,0.1−(1−β2)t+10.1,0.1+(1−β2)t0.1)
特点:
- 工程向,不够优美
- 抽象难懂
Towards Improving SGDM
对它的改进就是加速它收敛的速率,下面介绍几种改进方式:
LR range test
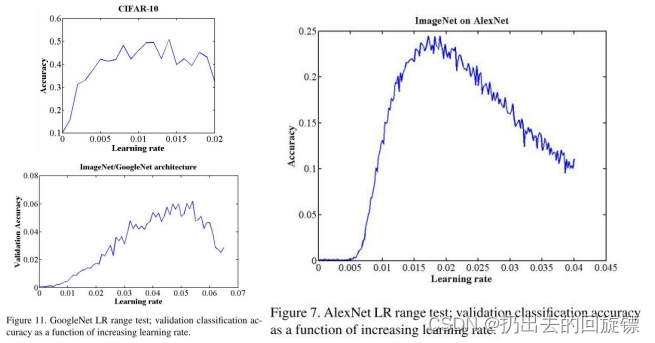
简单的说就是调整learning rate
Cyclical LR
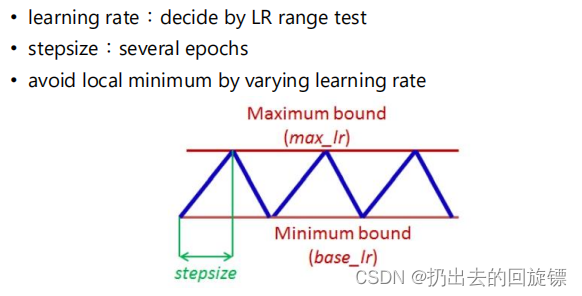
周期性的改变learning rate
SGDR

同上,但是变法略不同
One-cycle LR
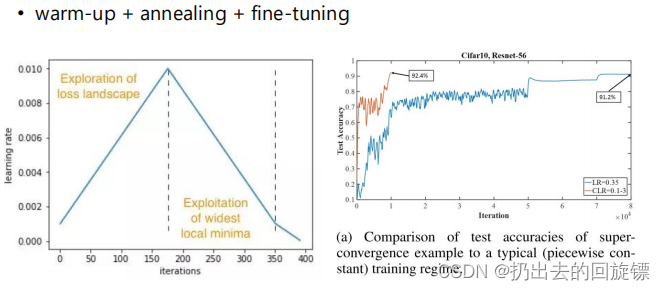
learning rate的变化只有一个cycle,分三个阶段
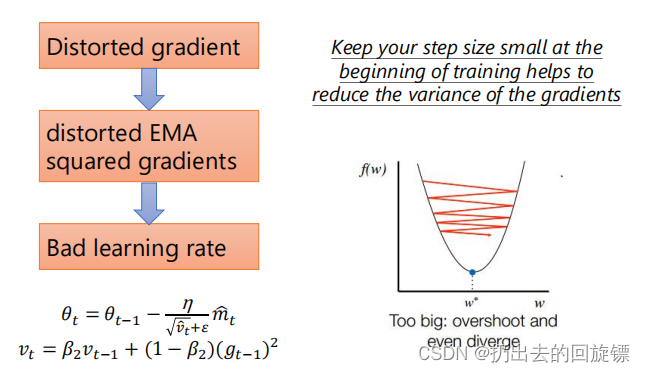
warm-up的影响
实验表明,开始的10步没有warm-up会受到较大的扰乱。形象图表示如下:
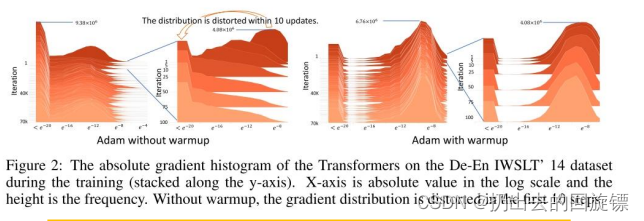
基于warm-up改进的RAdam

训练初期的时候,切换到SGD + Momentum进行预热
RAdam vs SWATS

k step forward, 1 step back
Lookahead
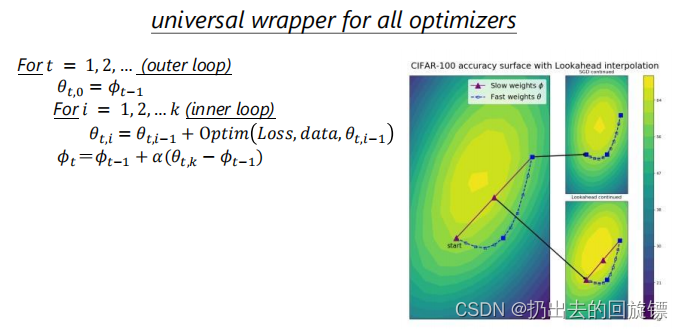
可以使用 Lookahead 加强已有最优化方法的性能,Lookahead 首先使用内部循环中的 SGD 等标准优化器,更新 k 次「Fast weights」,然后以最后一个 Fast weights 的方向更新「slow weights」
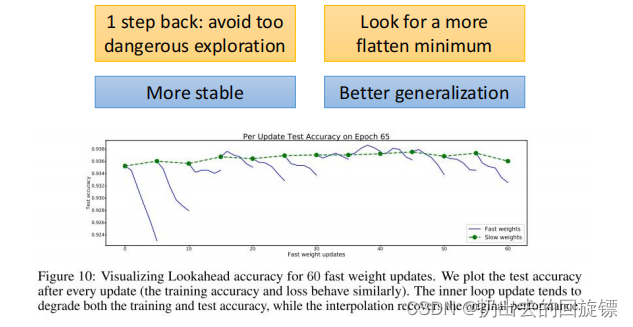
- Lookahead 向高曲率方向振荡时,fast weights 更新在低曲率方向上快速前进,slow weights 则通过参数插值使振荡平滑
- fast weights 和 slow weights 的结合改进了高曲率方向上的学习,降低了方差,使得 Lookahead 在实践中实现更快的收敛
- Lookahead 提升收敛效果。当 fast weights 在极小值周围慢慢探索时,slow weight 更新促使 Lookahead 激进地探索更优的新区域,从而使测试准确率得到提升
Can we look into the future?
Nesterov accelerated gradient (NAG)
计算“超前梯度”更新冲量项

Adam in the future:Nadam&SGDM

Do you really know your optimizer?
A story of L2 regularization…
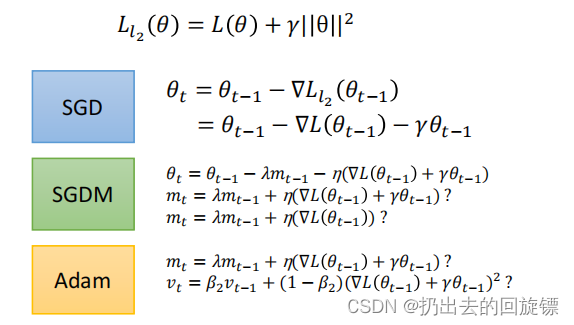
是否需要最后面的正则项?
AdamW & SGDW with momentum
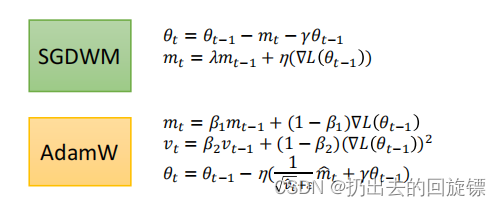
实验证实去掉后效果更好
Something helps optimization…
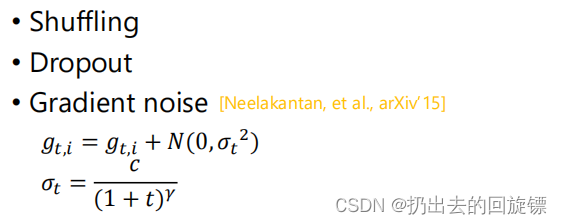

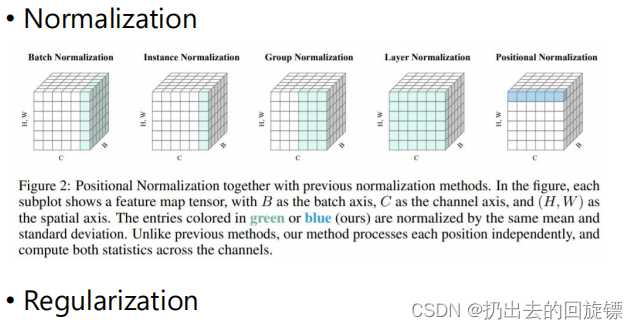
learned &Advices