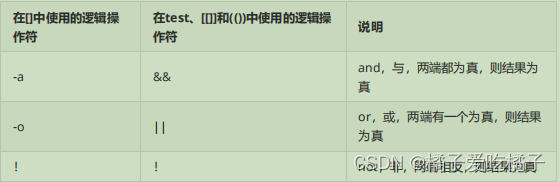
数据挖掘,计算机网络、操作系统刷题笔记47
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
【45】数据挖掘,计算机网络、操作系统刷题笔记45
【46】数据挖掘,计算机网络、操作系统刷题笔记46
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记47
- @[TOC](文章目录)
- 数据挖掘分析应用:朴素贝叶斯
- 生成模型和判别模型
- 决策树
- graphviz:图表可视化软件,画决策树的模型图
- 我们现在用的网络模式大多是以太网.那么,它的标准是( )
- 下面关于以太网的描述正确的是( )。
- 区分局域网(LAN)和广域网(WAN)的依据是______。
- 进程从等待状态进入就绪状态可能是由于()。
- 下面有关线程的说法错误的是()
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记47
- @[TOC](文章目录)
- 数据挖掘分析应用:朴素贝叶斯
- 生成模型和判别模型
- 决策树
- graphviz:图表可视化软件,画决策树的模型图
- 我们现在用的网络模式大多是以太网.那么,它的标准是( )
- 下面关于以太网的描述正确的是( )。
- 区分局域网(LAN)和广域网(WAN)的依据是______。
- 进程从等待状态进入就绪状态可能是由于()。
- 下面有关线程的说法错误的是()
- 总结
数据挖掘分析应用:朴素贝叶斯
概率知识

联合就是共同发生的概率
概率和为1


easy
如果AB是独立的
条件概率就等于A本身的概率
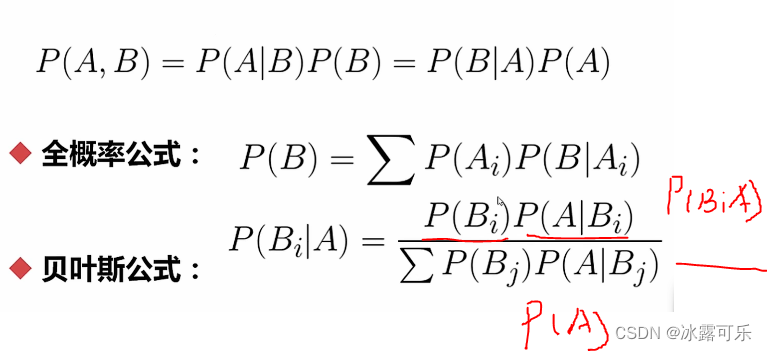
得到了贝叶斯公式

到此你可以不用往下看这些例子了,你就随便看看就行

第一次抽到2种情况,在这两种情况下,第二次抽到红球的概率——全概率公式


请问
判断这个账户是真实的还是虚假的???

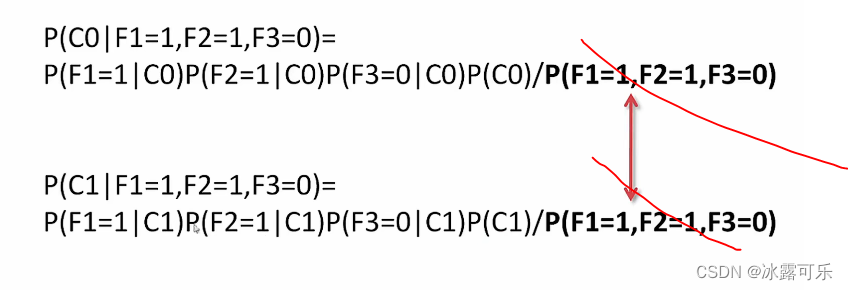

大概率是真实账户
这么多你也不要看了,反正了解一下即可

讲课搞这么复杂作甚??????????
直接看代码

上一篇文章的代码,我们集成一下
自动化程度高
方便以后加别的机器学习模型
# 集成化模型训练代码
# 模型
def hr_modeling_all(features, label):from sklearn.model_selection import train_test_split# 切分函数#DataFramefeature_val = featureslabel_val = labeltrain_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集print(len(train_data), len(valid_data), len(test_data))# KNN分类from sklearn.neighbors import NearestNeighbors, KNeighborsClassifierfrom sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价models = []knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖for modelName, model in models:print(modelName)model.fit(train_data, y_train) # 指定训练集# 又集成化数据集data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]for i in range(len(data)):print(i)y_input = data[i][0]y_label = data[i][1] # 输入输出预测y_pred = model.predict(y_input)print("acc:", accuracy_score(y_label, y_pred))print("recall:", recall_score(y_label, y_pred))print("F1:", f1_score(y_label, y_pred))# 不考虑存储,你看看这个模型就会输出仨结果if __name__ == '__main__':features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,lower_d=True, ld_n=3)# print(df, label)# 灌入模型hr_modeling_all(features, label)8999 3000 3000
KNN
0
acc: 0.9595510612290254
recall: 0.9290681502086231
F1: 0.9167429094236048
1
acc: 0.928
recall: 0.8497191011235955
F1: 0.8485273492286115
2
acc: 0.9216666666666666
recall: 0.8547008547008547
F1: 0.8362369337979094Process finished with exit code 0现在我们搞贝叶斯模型分类
就是给你提供不同字段状态,属于离职率高的用户,让你做一个分类
贝叶斯回去统计这些概率啥的,贼复杂,你只需要会用就行
# 集成化模型训练代码
# 模型
def hr_modeling_all(features, label):from sklearn.model_selection import train_test_split# 切分函数#DataFramefeature_val = featureslabel_val = labeltrain_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集print(len(train_data), len(valid_data), len(test_data))# KNN分类from sklearn.neighbors import NearestNeighbors, KNeighborsClassifierfrom sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好models = []knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类bys_clf = GaussianNB()bnl_clf = BernoulliNB()models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖for modelName, model in models:print(modelName)model.fit(train_data, y_train) # 指定训练集# 又集成化数据集data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]for i in range(len(data)):print(i)y_input = data[i][0]y_label = data[i][1] # 输入输出预测y_pred = model.predict(y_input)print("acc:", accuracy_score(y_label, y_pred))print("recall:", recall_score(y_label, y_pred))print("F1:", f1_score(y_label, y_pred))print("\n")# 不考虑存储,你看看这个模型就会输出仨结果if __name__ == '__main__':features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,lower_d=True, ld_n=3)# print(df, label)# 灌入模型hr_modeling_all(features, label)8999 3000 3000
KNN
0
acc: 0.9609956661851317
recall: 0.9373271889400921
F1: 0.9205702647657841
1
acc: 0.921
recall: 0.8587896253602305
F1: 0.8341497550734779
2
acc: 0.9223333333333333
recall: 0.8514851485148515
F1: 0.8378566457898399GaussianNB
0
acc: 0.8806534059339927
recall: 0.6493087557603686
F1: 0.7240493319630011
1
acc: 0.888
recall: 0.6657060518731989
F1: 0.7333333333333334
2
acc: 0.8766666666666667
recall: 0.6562942008486563
F1: 0.7149460708782743BernoulliNB
0
acc: 0.7588620957884209
recall: 0.0
F1: 0.0
1
acc: 0.7686666666666667
recall: 0.0
F1: 0.0
2
acc: 0.7643333333333333
recall: 0.0
F1: 0.0Process finished with exit code 0高斯贝叶斯比伯努利好
但是也比KNN差劲
反正贝叶斯一般般吧感觉
生成模型和判别模型
生成:求联合概率,再求分类概率——复杂
判别:不通过联合概率分布,直接输出分类概率

朴素贝叶斯就是生成模型
决策树
一步步按照特招判断,划分
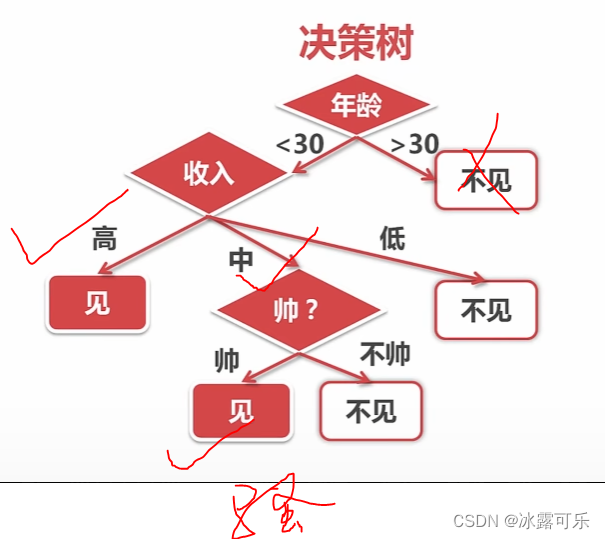
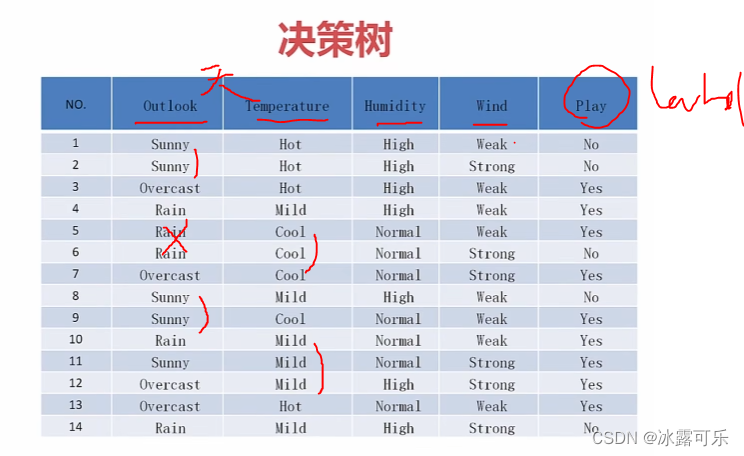
怎么决策??
熵
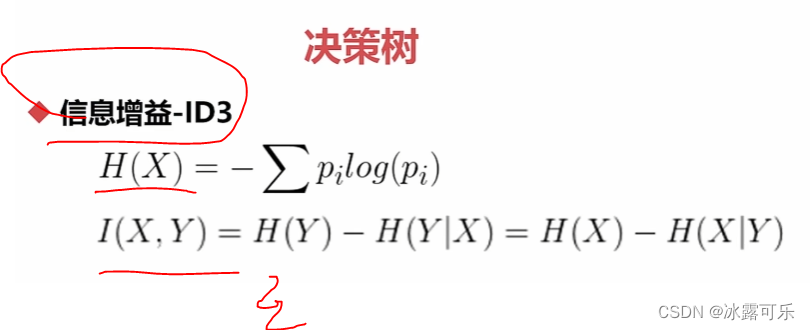
知道了条件熵,信息就算曝光了

wind两种条件下,打球的熵
这样的话,计算出来就好说了
这样就是根据风
这个特征进行切分的熵增益
别的字段呢???

因为天气的增益最大,所以咱们能第一次切分就用天气这个字段
显然天气下雨没法玩啊
信息增益率:
互信息不对称
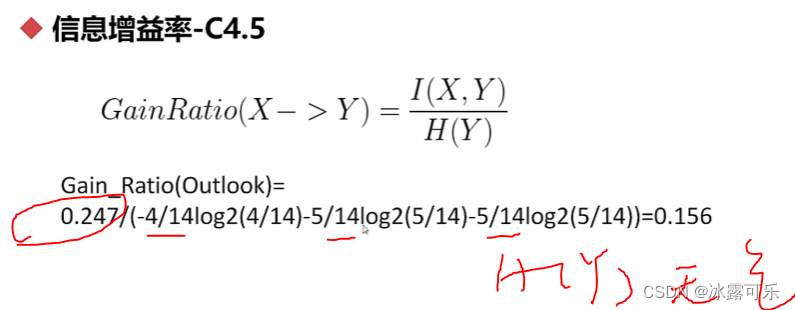
基尼系数:取最小的基尼系数,才是我们要的切分字段
不纯度
CART决策树经常用哦
humidity有3取值
high有7个,打球不打球各3 4个
mid
low
类似统计
去算基尼系数

连续值咋搞?分段呗
规则很多,那就整体投票
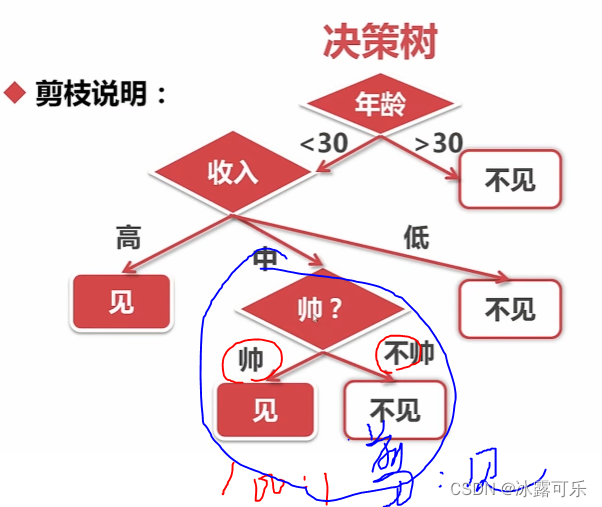
解决过拟合的方法可能是剪枝啥的
收入中的人中,都是帅的,那剪枝,直接见面,别分支了
看代码
决策树的效果不错哦
# 集成化模型训练代码
# 模型
def hr_modeling_all(features, label):from sklearn.model_selection import train_test_split# 切分函数#DataFramefeature_val = featureslabel_val = labeltrain_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集print(len(train_data), len(valid_data), len(test_data))# KNN分类from sklearn.neighbors import NearestNeighbors, KNeighborsClassifierfrom sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好from sklearn.tree import DecisionTreeClassifier # 决策树models = [] # 申请模型,挨个验证好坏knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类bys_clf = GaussianNB()bnl_clf = BernoulliNB()DT_clf = DecisionTreeClassifier()models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖# 不同的模型,依次验证for modelName, model in models:print(modelName)model.fit(train_data, y_train) # 指定训练集# 又集成化数据集data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]for i in range(len(data)):print(i)y_input = data[i][0]y_label = data[i][1] # 输入输出预测y_pred = model.predict(y_input)print("acc:", accuracy_score(y_label, y_pred))print("recall:", recall_score(y_label, y_pred))print("F1:", f1_score(y_label, y_pred))print("\n")# 不考虑存储,你看看这个模型就会输出仨结果if __name__ == '__main__':features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,lower_d=True, ld_n=3)# print(df, label)# 灌入模型hr_modeling_all(features, label)
8999 3000 3000
KNN
0
acc: 0.9594399377708634
recall: 0.9254716981132075
F1: 0.9148985777570529
1
acc: 0.918
recall: 0.853185595567867
F1: 0.8335588633288227
2
acc: 0.92
recall: 0.877914951989026
F1: 0.8421052631578947GaussianNB
0
acc: 0.8820980108900989
recall: 0.6400943396226415
F1: 0.7189403973509934
1
acc: 0.881
recall: 0.6426592797783933
F1: 0.7221789883268482
2
acc: 0.8756666666666667
recall: 0.6488340192043895
F1: 0.7172100075815012BernoulliNB
0
acc: 0.7644182686965219
recall: 0.0
F1: 0.0
1
acc: 0.7593333333333333
recall: 0.0
F1: 0.0
2
acc: 0.757
recall: 0.0
F1: 0.0Decision Tree
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9383333333333334
recall: 0.9016620498614959
F1: 0.8755884330867518
2
acc: 0.929
recall: 0.8984910836762688
F1: 0.8601444517399869Process finished with exit code 0决策树在测试集上的表现很完美
训练集上基本都是完美的100%
看来决策树贼牛逼啊
graphviz:图表可视化软件,画决策树的模型图
将其加入环境变量
去官网下载
然后在代码中将我们的模型想办法保存到pdf文件中
# 集成化模型训练代码——保存模型DT
# 模型
def hr_modeling_all_saveDT(features, label):from sklearn.model_selection import train_test_split# 切分函数#DataFramefeature_val = features.valueslabel_val = label# 特征段feature_name = features.columnstrain_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集print(len(train_data), len(valid_data), len(test_data))# KNN分类from sklearn.neighbors import NearestNeighbors, KNeighborsClassifierfrom sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树from io import StringIOimport pydotplusimport osos.environ["PATH"] += os.pathsep+r"D:\Program Files\Graphviz\bin"models = [] # 申请模型,挨个验证好坏knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类bys_clf = GaussianNB()bnl_clf = BernoulliNB()DT_clf = DecisionTreeClassifier()# models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖# models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖# models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖# 不同的模型,依次验证for modelName, model in models:print(modelName)model.fit(train_data, y_train) # 指定训练集# 又集成化数据集data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]for i in range(len(data)):print(i)y_input = data[i][0]y_label = data[i][1] # 输入输出预测y_pred = model.predict(y_input)print("acc:", accuracy_score(y_label, y_pred))print("recall:", recall_score(y_label, y_pred))print("F1:", f1_score(y_label, y_pred))print("\n")# 保存模型DT为pdfdot_data = export_graphviz(decision_tree=model,out_file=None,feature_names=feature_name,class_names=["Nl", "left"],filled=True,rounded=True,special_characters=True)graph = pydotplus.graph_from_dot_data(dot_data)graph.write_pdf("dt_tree.pdf")# 不考虑存储,你看看这个模型就会输出仨结果if __name__ == '__main__':features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,lower_d=True, ld_n=3)# print(df, label)# 灌入模型hr_modeling_all_saveDT(features, label)
安装好之后,一直没有成功,gg
暂时就看不了了
gg
我们现在用的网络模式大多是以太网.那么,它的标准是( )
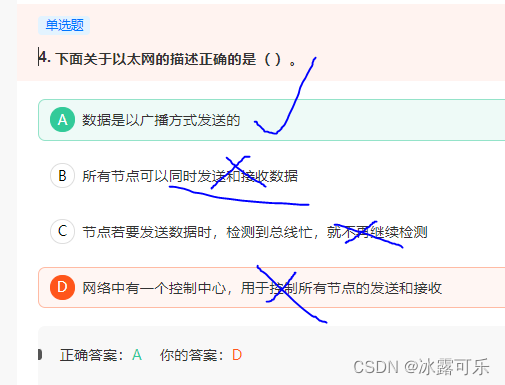
下面关于以太网的描述正确的是( )。
区分局域网(LAN)和广域网(WAN)的依据是______。

现在课程里教的是根据采用的技术区分啊,根据范围的已经过时了。。。采用广域网技术即使距离近也是广域网
可恶
进程从等待状态进入就绪状态可能是由于()。

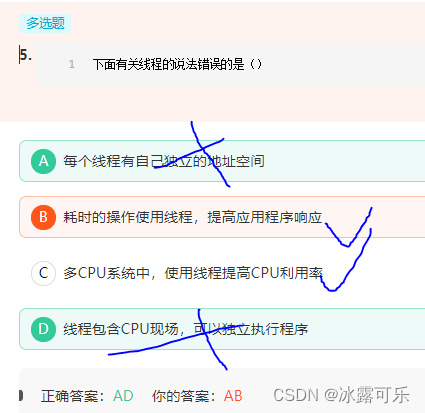
下面有关线程的说法错误的是()
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。