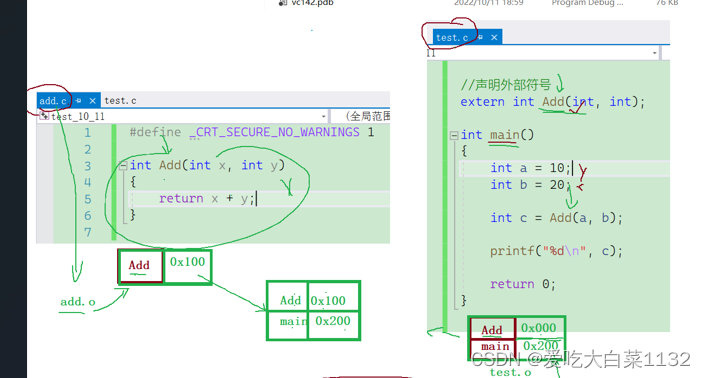
talk
这篇文章还是有可读的必要性。 关注点: 1. 丢弃边 丢弃节点的 视图增强方法。 2. 不同于原来的 dgi gmi mvgrl 采用 JS散度 或者 Infomax的目标函数,本文采用 infonce。 3. Pubmed数据集引发的 对 评价指标 和 评价方法的 讨论
缺点: 可扩展性差,PubMed就需要 12G
有最大的一个问题,这个算法 的 评价指标 和之前的 dgi gmi(LR也采用了 early stop) mvgrl 的不一样
1.实验
1.1 Cora
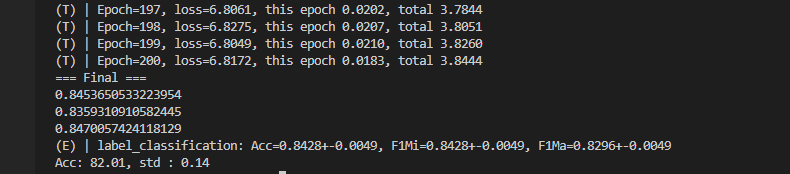
1.2 CiteSeer
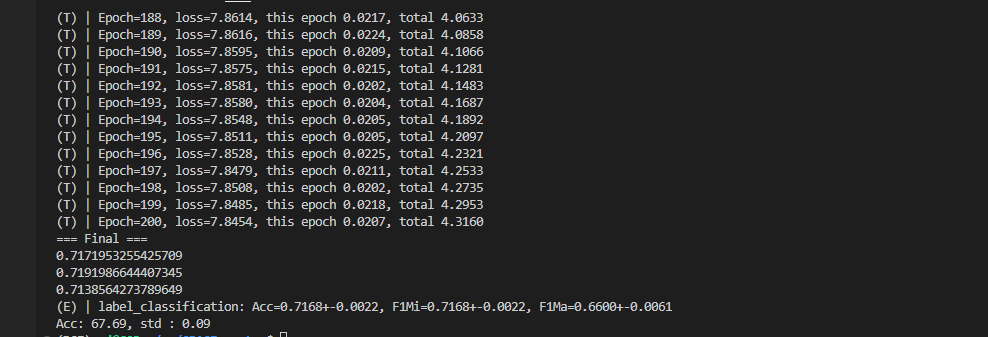

1.3 PubMed
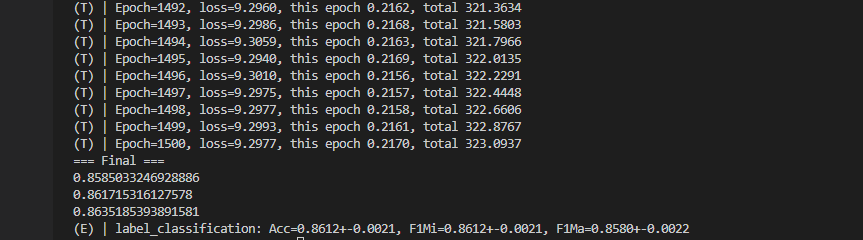
GPU内存占的 还是比较多的

这里修改了 训练:测试 = 0.05:0.95 变成标准的 半监督节点分类,原本以为会 drop, 可是效果出奇的好!! 但是 是不是 这个 评价有问题呢?
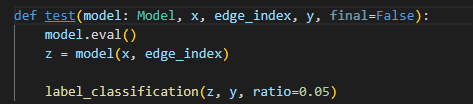

这里 重新又 对 GRACE 采用了 DGI等的 评价方法,发现结果不一致
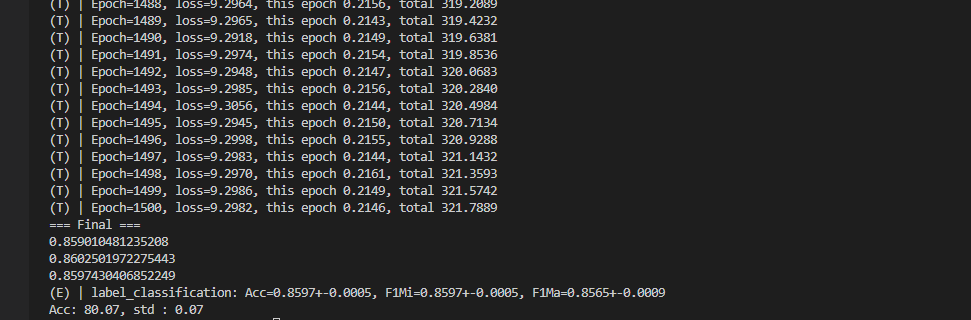
2. 三个关注点
2.1 视图增强 drop_edge + drop_feature
代码还是比较简单,送入x edge_index. 生成视图,计算损失
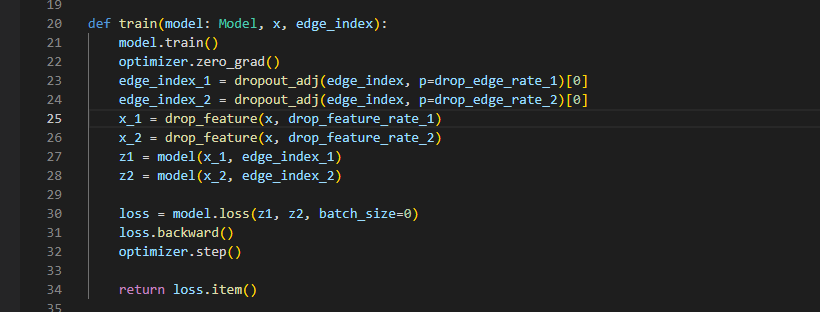
drop_edge
这里采用是 PyG的 库函数
以p的概率从伯努利分布中进行丢边,默认参数 无向图=False,即单方向丢弃边,mask是 掩码,通过filter_adj 进行边的丢弃。拼接之后返回新edge_index。
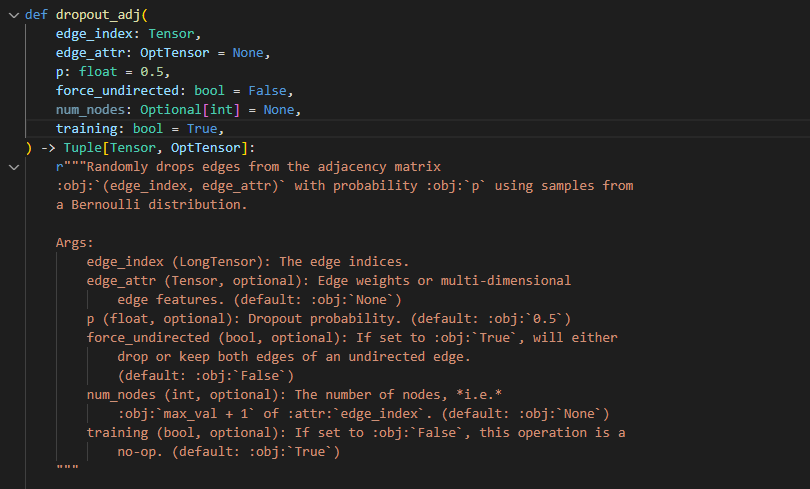
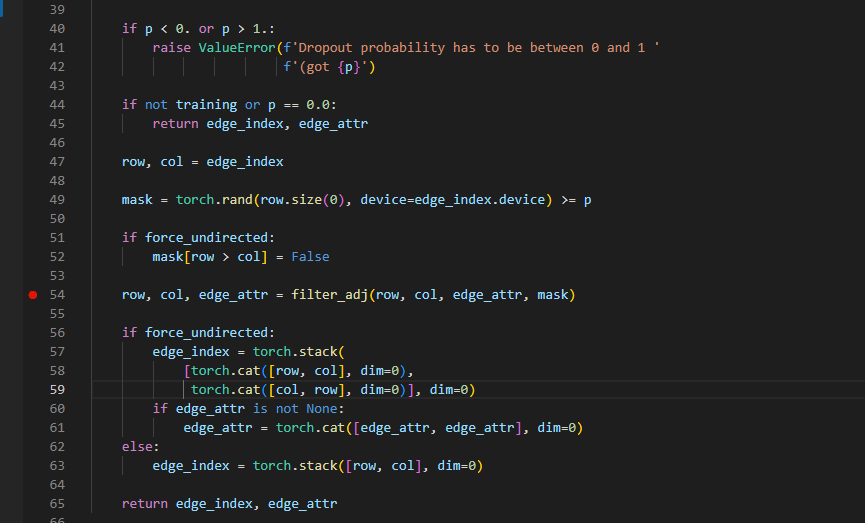
这里 mask = True处 的元素就会保留,mask的长度 是边 的个数。

drop_feature
传入参数:x矩阵和 drop p
操作:对x中的每一个维度进行丢弃。 意味着 所有节点 的 某一个属性就都没有了。 如果这里的mask是 每个节点的每个维度和X大小相同,则意味着 每个 节点 丢失的 维度 都不一样 随机的。
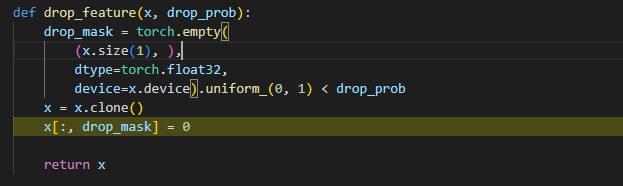
通过 torch.empty((size))创建空矩阵。 torch.tensor.uniform_是通过均匀分布 对tensor填值,进行判断,生成mask,进行mask。
2.2 损失计算
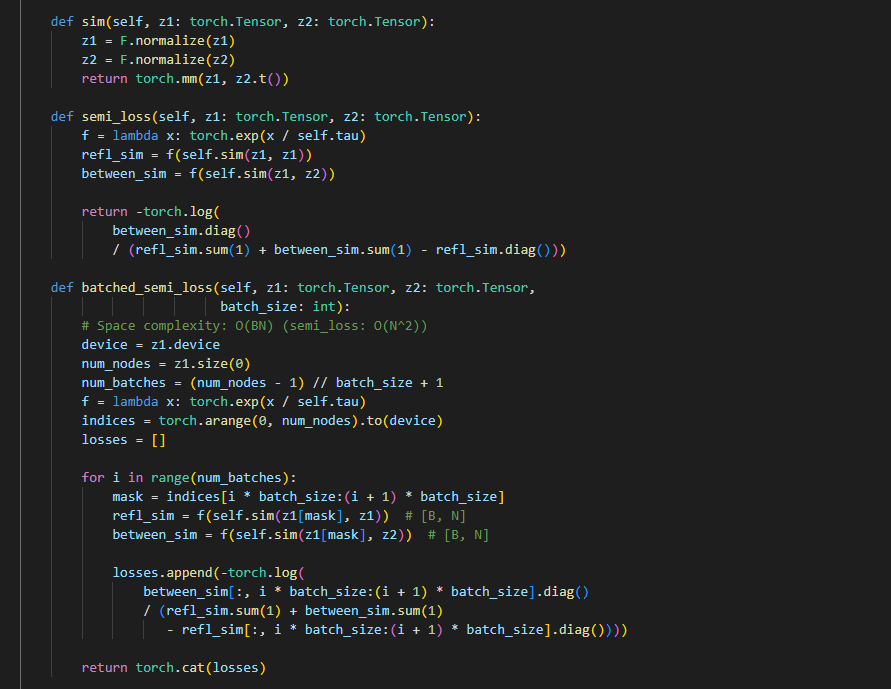
这里有两个版本的损失 计算, 第一个 full-batch 通过 两个矩阵内积,通过指数e和维度tao对应 原论文里的公式 infonce, 损失 -log (ii/ii+ij) 。 这里不是很直观,找个 栗子~
2.2.1 example
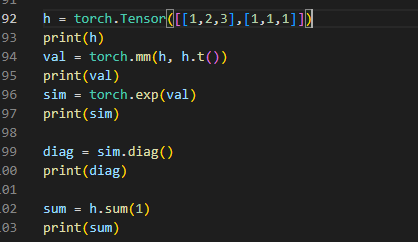

因此 上面的 损失 就是 内积的 矩阵 n*n 分子 取 对角元素 (一维向量)即是 论文里面的 uv 第几个元素就是 uivi
分母 第2项 就是 论文 分母的前面两项 分母 第一和第三项 是 论文里面的 第三项(k≠i)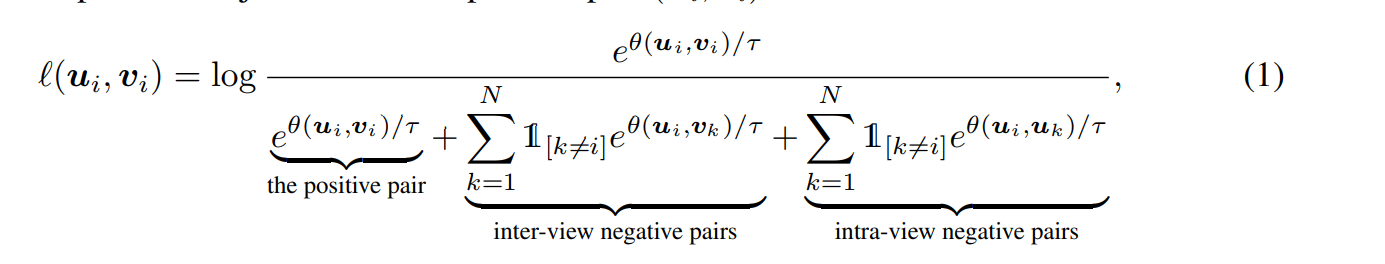
返回的损失l1 就是 一个向量 长度为节点总数,分别是 每个节点的 infonce损失, 采用mean() 来得出 loss
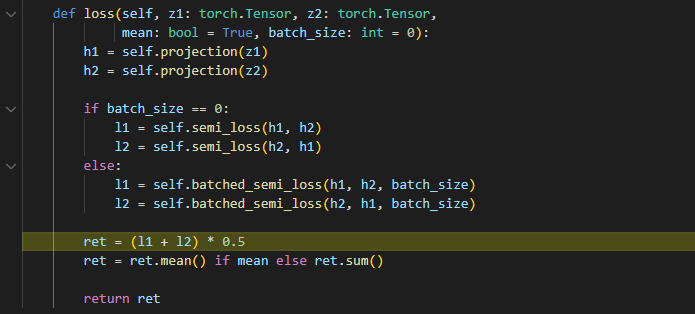
这里有另外 sample-batch的 infonce损失,即 bacthed 。 通过节点总数/batch_size 进行 多次batch计算, 但这样 不是越小batch 越好,Pubmed 2w节点,采4000-5000 可以到9G, 但是 采用 50 直接24G都爆了。
2.3 评价指标问题
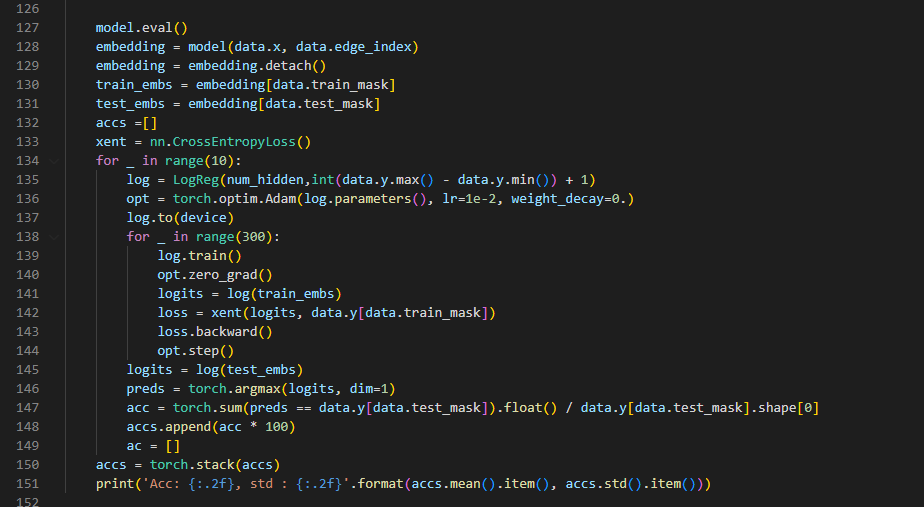
作者自己写的 评价指标,这里也是采用LogReg ,精度计算出来很高
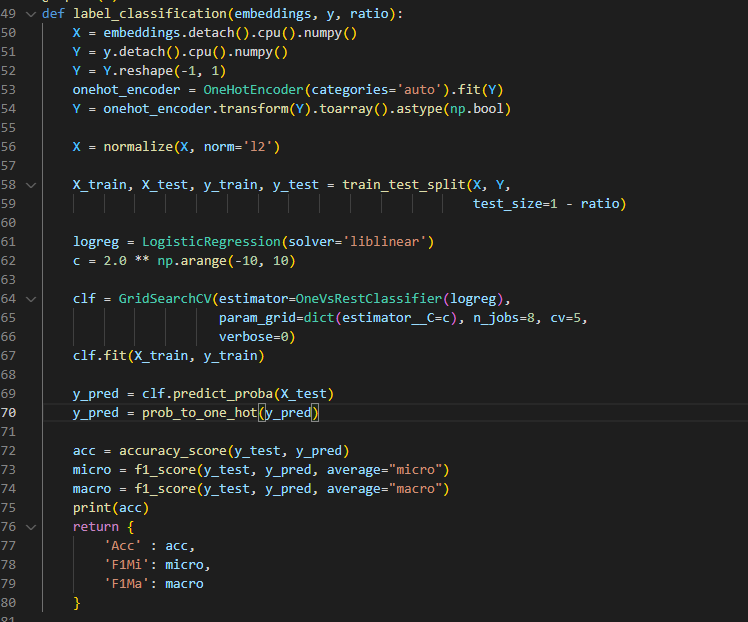
但如果采用 下面 DGI版本的LR 的精度就不是很高,上面实验cora citeseer pubmed 最后一行就是采用DGI式,每个数据集都远远低于作者的,这个现象在 PyG实现的 infomax_transductive 例子里面也有,PyG的例子评测也是调用 from sklearn.linear_model import LogisticRegression 最终也是比DGI这样 评测要好的。 有明白的同学 希望相互讨论~






![API接口名称(item_search - 按关键字搜索淘宝商品)[item_search,item_get,item_search_shop等]](https://img-blog.csdnimg.cn/5deef5a52808438590a87bac73b57b68.jpeg)