目录
一.引言
二.GBDT 理论
1.集成学习
2.分类 & 回归问题
3.梯度提升
4.GBDT 生成
三.GBDT 实战
1.数据准备
2.构建 GBDT Pipeline
3.预测与评估
四.总结
一.引言
关于决策树前面已经介绍了常规决策树与随机森林两种类型的知识,本文主要介绍梯度提升树 Gradient Boosting Decision Tree 即常说的 GBDT,其实一种使用决策树集成的流行分类和回归方法。梯度提升算法的思想类似于随机梯度下降。该算法中模型由若干个 F(x) 即基学习器构成,每个 F(x) 都拥有一个权重 Weight,初始化时各个权重相同,之后不断地将模型计算结果与真实结果进行比较,如果出错则增加错误样本的权重并基于新权重样本,让模型朝着损失减少最快的负梯度方法进行优化。其整体可以看做是 Bossting 方法,主要思想是每一次建立模型都是在之前建立模型损失函数的梯度下降方向,即"每次沿着当前位置最陡峭,损失下降最快的方向移动"。

二.GBDT 理论
决策树相对来说很直观形象,同学们也很好理解,但是到了梯度提升树,负梯度、最小化残差等概念的出现容易找不到方向,其次为什么0-1分类问题也有梯度等等疑问也随之而来,在使用 Spark 3.0 ML 介绍梯度提升树的使用之前,我们先熟悉一些 GBDT 的基础数学概念,做到理论实践相结合。
1.集成学习
上一文随机森林就是一种集成学习的方法,其一般都有一个基学习器 Tk,对于随机森林、梯度提升树而言,基学习器 Tk 就是我们常规的 DT 决策树。针对常见的分类与回归问题,我们的问题都可以转化为下述数学语言,构造一个函数 y = f(x),训练模型使得 f(x) 尽量与真实值相同:
而实际运行中,我们的模型很难做到百发百中的精准预测,往往预测值与真实值之前存在一定偏差:
这个 residual error 就是我们常说的残差,即 y - f(x) 的差值即真实值与预测值之前的差异。实践场景下我们一般对残差进行如下度量:
A.偏差 - 与真实值分布的偏差大小,体现模型的预测能力,越小模型预测越准
B.方差 - 与真实值分布的偏差均值方差,体现模型的预测稳定性,越小模型越稳定
集成学习中,基学习器一般为简单的算法模型、例如 LR、DT,因此其单一学习器的预测能力有限,从而通过集成学习将多个基学期的组合,针对残差进行拟合,进而降低模型的偏差与方差,提高模型整体的预测能力与稳定性,达到 "N个臭皮匠 Tk,能顶一个诸葛亮" 的思想。虽然 RF 和 GBDT 都是基于树的集成学习,但是二者亦有不同,前者 Tk 可以并行生成,是典型的 bagging,而 GBDT 的 Tk 是串行生成,类似于 Adaboost。
2.分类 & 回归问题
回归问题我们在 LR 中就遇到过,下面简单复述下,给定数据集 X:
其中 x 为 K 维特征 (K >=1):
其中 y 为真实输出值,分类任务对应 0-1,回归任务对应预测值,我们的目的就是构建一个模型:
去尽可能的逼近每一个真实值 y。
A.分类问题损失函数:(常见的指数损失函数)
B.回归问题损失函数:(常见的 MSE 均方误差损失函数)
3.梯度提升
Gradient Boosting Decision Tree,简单分词可以得到两个主体,分别为 Gradient Boosting 与 Decision Tree,所以我们把这两个东西搞差不多,GBDT 我们也就搞差不多了,DT 可以参考 决策树原理与实战。此时基学习器 Tk 为 DT 决策树,假设当前:
前 K 个基学习器的预测值为 Fk(x),可以看到 GBDT 是一种加法模型,它把所有基础模型的预测值累加起来作为最终的预测值。由于 GBDT 采用串行的生成方式生成新的基学习器,所以我们将上面的公式修改为递推形式:
在训练第 K 个 T(x) 时,我们需要最小化如下目标函数:
此处我们需要使用梯度下降的方法,让目标函数的取值朝着最快的下降方向前进。以 MSE 交叉熵损失函数为例:
对 F(x) 求导可得:
后面得到的结果就是我们集成学习部分提到的负残差。由随机梯度下降更新公式可知,这里可以参考简易的 牛顿法参数更新,其中 α 为学习率:
后面的求导结果为负残差,所以移项可得 (此处忽略 α):
所以可以看到每次新增的基学习器 Tk 都用于拟合之前所有 Ti 与当前真实值之间的残差时,导数梯度下降最快,从而模型拟合效果更好。
4.GBDT 生成
GBDT 串行生成,假设我们的第一个基学习器是:
此时对应残差为,第二个学习器 T2 负责拟合 T1 与 y 之间的残差:
根据残差拟合 T2 并串行增加到 T1 后面,得到最新的 GBDT 模型:
依次类推,不断在新函数的基础上求得残差,并通过残差拟合新的 Tk,直到达到我们预定的精度要求或者树要求,即代表 GBDT 模型生成完毕:
实际操作中,有时还会根据上一轮的误差修改新一轮样本 X 的权重,从而使得新增的 Tk 对于之前集成学习器分类错误的样本能够拥有更好的分类结果,从而提升整体集成学习器的预测能力。
三.GBDT 实战
1.数据准备
spark.read.format 对 LIBSVM 数据进行读取加载
LabelIndexer 对预测值进行重新编码映射
featureIndexer 对特征进行离散与连续的区分
randomSplit 将数据按比例分为训练、测试数据
val spark = SparkSession.builder//创建spark会话.master("local").appName("GradientBoostedTreeClassifierExample")//设置名称.getOrCreate() //创建会话变量// 读取文件,装载数据到spark dataframe 格式中val data = spark.read.format("libsvm").load("/Users/xudong11/sparkV3/src/main/scala/org/example/RandomForest/sample_libsvm_data.txt")// 搜索标签,添加元数据到标签列// 对整个数据集包括索引的全部标签都要适应拟合val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(data)// 自动识别分类特征,并对其进行索引// 设置MaxCategories以便大于4个不同值的特性被视为连续的。val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(data)// 按照7:3的比例进行拆分数据,70%作为训练集,30%作为测试集val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))Tips:
样本为 libsvm 格式,特征维度 692,标签为二分类

2.构建 GBDT Pipeline
gbt 构造 GBDT 分类器
labelConverter 将上述标签转换的标签再映射回来
pipeline 将上述 Stage 拼接得到最终的 Estimator
pipeline.fit 训练模型,获取预测的 transformer
// 建立一个决策树分类器,并设置MaxIter最大迭代次数为10val gbt = new GBTClassifier().setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures").setMaxIter(10).setFeatureSubsetStrategy("auto")// 将索引标签转换回原始标签val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labelsArray(0))// 把索引和决策树链接(组合)到一个管道(工作流)之中val pipeline = new Pipeline().setStages(Array(labelIndexer, featureIndexer, gbt, labelConverter))// 载入训练集数据正式训练模型val model = pipeline.fit(trainingData)Tips:
这里 FeatureSubsetStrategy 是属性在每个节点中计算的数目,即用作在每个树节点进行分割的候选特征数量,该数字被指定为总特征数量的分数或函数。减少这个数字会加快训练速度,但是太低的话会影响性能,这里建议使用 auto 参数让 ML 内核自动决定每个节点的属性数。
3.预测与评估
model.transform 用上一步得到的 transformer 对测试集数据预测
evaluator 计算预测样本的 Accuracy
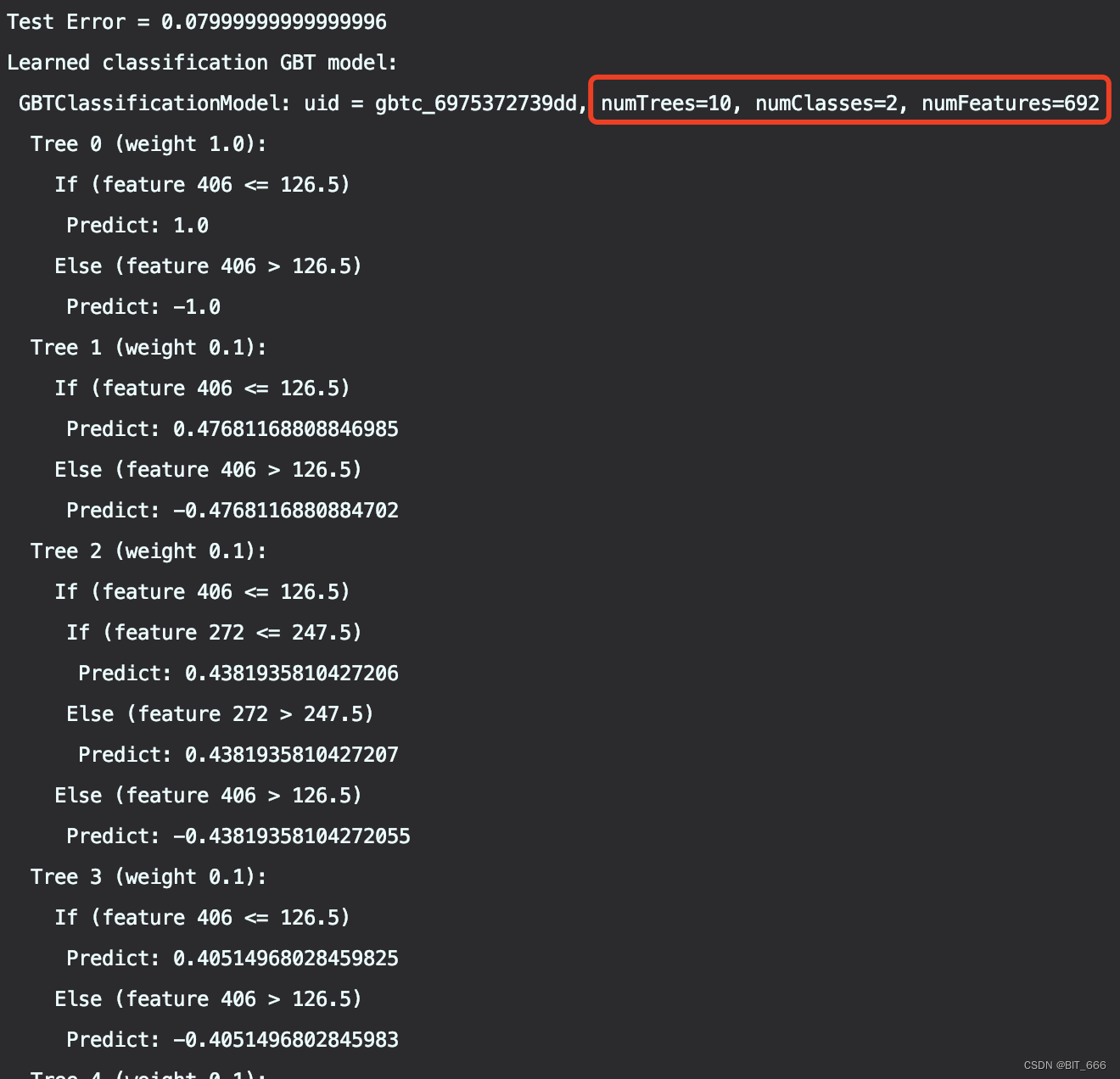
toDebugString 获取本次训练的 GBDT 树的简介
// 使用测试集作预测val predictions = model.transform(testData)// 选择一些样例进行显示predictions.select("predictedLabel", "label", "features").show(5)// 计算测试误差val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("accuracy")val accuracy = evaluator.evaluate(predictions)println(s"Test Error = ${1.0 - accuracy}")val gbtModel = model.stages(2).asInstanceOf[GBTClassificationModel]println(s"Learned classification GBT model:\n ${gbtModel.toDebugString}")spark.stop()Tips:
由于篇幅长度,这里我们只展示前 4 棵树,我们的模型共拥有 10 棵树,对应问题为 2 分类问题,全部特征为 692 维度。将全部预测值与权重加权求和,再经过 sigmoid 函数即可得到对应标签类型,如果是回归问题,则不需要 sigmoid 函数。这里 GBDT 处理二分类也借鉴了 LR,通过 sigmoid 函数将分类的非线性问题转化到 y = wx + b 的线性函数。
四.总结
GBDT 增加学习器意在让模型的损失函数持续下降,其中最好的方式就是让损失函数在梯度方向下降,此时优化速度最快。Boosting 算法是一种继承学习方法,每一轮训练样本都是固定的,改变的是每个样本的权重,根据错误率调整样本权重,错误率越大的样本权重越大。各个预测函数只能顺序生成,因为后一个模型需要用到上一个模型的结果。通过加法模型不断减小训练产生的残差,实现数据的分类与回归。在 Gradient Boosting 中,每个新基学习器的建立都是为了使之前的模型残差往梯度方向减少。啰嗦了这么多,下面我们简单总结一下:
A.训练阶段,GBDT 的基学习器只能串行生成,但是预测阶段可以通过并行计算提高效率
B.GBDT 分类问题支持 LogLoss,回归问题支持 MSE、MAE,SPARK ML 默认为 L2 MSE。
C.Iter 参数为迭代次数,每增加1都会新增一棵树,预测的准确性也随之增加
D.适量的增加树可以提高模型准确能力,但也会带来过拟合风险,可以添加 Reg 正则化参数
E.GBDT 可以自动筛选重要特征,可以与其他模型配合使用,例如最常见的 GBDT + LR





![[Android移动安全渗透基础教程] 易受攻击的移动应用程序](https://img-blog.csdnimg.cn/f56539491100458584f43795e10a3427.png)