redis cluster 集群安装
redis集群方案
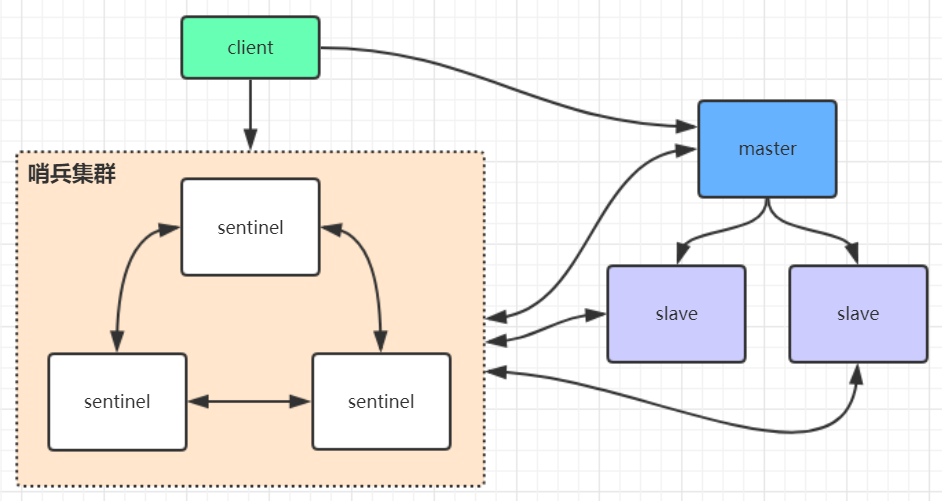
哨兵集群
如图,实际上还是一个节点对外提供服务,所以虽然是三台机器,但是还是一台机器的并发量,而且master挂了之后,整个集群不能对外提供服务
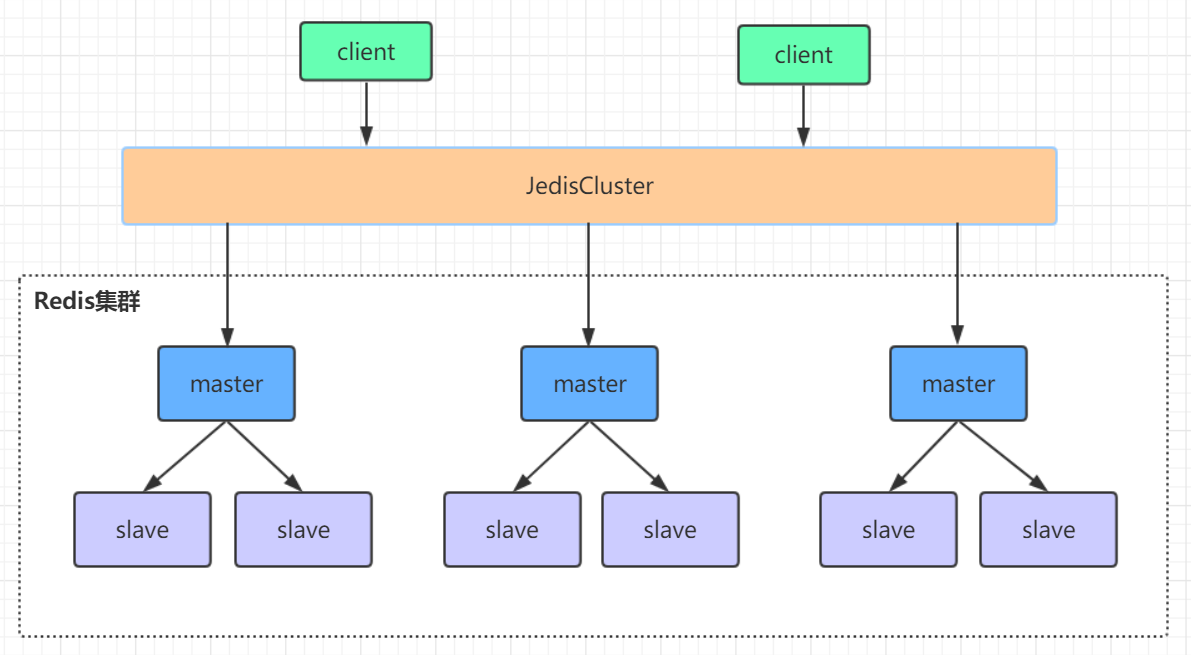
cluster集群
多个主从集群节点对外提供服务,支持横向扩展,主节点挂了之后,不需要哨兵也可以实现故障转移。其中一组主从节点挂了,不会影响其他节点继续提供服务
单机版部署
官方下载地址 : https://redis.io/download/
当前已经到了7.0版本,这里安装6.2.7版本
window版本下载地址:https://github.com/microsoftarchive/redis/releases
编译安装包
# 上传jar,解压
tar xvf redis-6.2.7.tar.gz # 进入到解压好
的redis解压目录下,进行编译,一般没啥问题
make# 全局执行
ln /app/redis/redis-6.2.7/src/redis-server /usr/local/bin/# 验证安装成功
redis-server -v
修改配置项
redis.conf,修改前注意备份
表示官方注释密密麻麻,—
非本机连接需要修改
# bind用于绑定本机的网络接口(网卡),redis只接受来自绑定网络接口的请求。 bind 127.0.0.1 -::1表示只允许本机的Ip4 和ip6 进行访问,所以如果你想允许所有ip进行访问,此处注释即可,或者配置本机特定网卡ip,多个网卡用空格分开
# bind 127.0.0.1 -::1# yes 表示只有本机才能访问,默认是yes
protected-mode no# 后台启动,默认no
daemonize yes可选修改项
日志和pid文件
# 日志默认输出到空,可指定
logfile ""
# 默认会写入启动后的进程id到这个文件,注意需要有权限
pidfile /var/run/redis_6379.pid
# 持久化数据存放目录
dir ./密码
acl是redis6新增的特性,优先级更高,有需要的了解一下,这里只需要通过requirepass 设置密码即可
# aclfile /etc/redis/users.acl# 开启密码认证,并设置密码
requirepass sry
启动和停止
# 指定配置文件启动,安装目录下
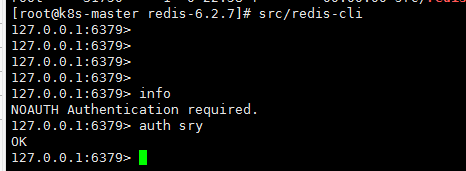
src/redis-server ./redis.conf 指定配置文件# 验证是否启动ps -ef | grep redis# 连接后quit退出
src/redis-cli -h 127.0.0.1 -p 6379 -a sry# 退出redis服务:
(1)pkill redis‐server
(2)kill 进程号
(3)src/redis‐cli shutdown
权限控制
ACL 机制支持配置用户密码,和其权限
https://www.cnblogs.com/weihanli/p/redis-acl-intro.html
info命令
Info:查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
- Server 服务器运行的环境参数
- Clients 客户端相关信息
- Memory 服务器运行内存统计数据
- Persistence 持久化信息
- Stats 通用统计数据
- Replication 主从复制相关信息
- CPU CPU 使用情况
- Cluster 集群信息
- KeySpace 键值对统计数量信息
> info
# Server
redis_version:6.2.7
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:ca59b36af8ac92d0
redis_mode:standalone
os:Linux 3.10.0-1160.71.1.el7.x86_64 x86_64
arch_bits:64
monotonic_clock:POSIX clock_gettime
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:4.8.5
process_id:31750
process_supervised:no
run_id:24af465e6e3653c343f028521c73d9e83f0f993a
tcp_port:6379
server_time_usec:1668049183685417
uptime_in_seconds:43303
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:7104799
executable:/app/redis/redis-6.2.7/src/redis-server
config_file:/app/redis/redis-6.2.7/./redis.conf
io_threads_active:0# Clients
connected_clients:3
cluster_connections:0
maxclients:10000
client_recent_max_input_buffer:32
client_recent_max_output_buffer:0
blocked_clients:0
tracking_clients:0
clients_in_timeout_table:0# Memory
used_memory:918040
used_memory_human:896.52K
used_memory_rss:2904064
used_memory_rss_human:2.77M
used_memory_peak:957208
used_memory_peak_human:934.77K
used_memory_peak_perc:95.91%
used_memory_overhead:873616
used_memory_startup:812032
used_memory_dataset:44424
used_memory_dataset_perc:41.91%
allocator_allocated:1029336
allocator_active:1335296
allocator_resident:3850240
total_system_memory:8101208064
total_system_memory_human:7.54G
used_memory_lua:32768
used_memory_lua_human:32.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.30
allocator_frag_bytes:305960
allocator_rss_ratio:2.88
allocator_rss_bytes:2514944
rss_overhead_ratio:0.75
rss_overhead_bytes:-946176
mem_fragmentation_ratio:3.32
mem_fragmentation_bytes:2028776
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61512
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
lazyfreed_objects:0# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1668047703
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:196608
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0# Stats
total_connections_received:16
total_commands_processed:176
instantaneous_ops_per_sec:0
total_net_input_bytes:4176
total_net_output_bytes:421960
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:538
evicted_keys:0
keyspace_hits:25
keyspace_misses:2
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:319
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:8
dump_payload_sanitizations:0
total_reads_processed:195
total_writes_processed:181
io_threaded_reads_processed:0
io_threaded_writes_processed:0# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:fe2597c9a1b5734776d1754f6dff1c97bb62c336
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0# CPU
used_cpu_sys:11.761245
used_cpu_user:19.821572
used_cpu_sys_children:0.000954
used_cpu_user_children:0.000954
used_cpu_sys_main_thread:11.760119
used_cpu_user_main_thread:19.816153# Modules# Errorstats
errorstat_ERR:count=3
errorstat_NOAUTH:count=5# Cluster
cluster_enabled:0# Keyspace
db0:keys=1,expires=0,avg_ttl=0
connected_clients:2 # 正在连接的客户端数量
instantaneous_ops_per_sec:789 # 每秒执行多少次指令
used_memory:929864 # Redis分配的内存总量(byte),包含redis进程内部的开销和数据占用的内
存
used_memory_human:908.07K # Redis分配的内存总量(Kb,human会展示出单位)
used_memory_rss_human:2.28M # 向操作系统申请的内存大小(Mb)(这个值一般是大于used_memor
y的,因为Redis的内存分配策略会产生内存碎片)
used_memory_peak:929864 # redis的内存消耗峰值(byte)
used_memory_peak_human:908.07K # redis的内存消耗峰值(KB)maxmemory:0 # 配置中设置的最大可使用内存值(byte),默认0,不限制
maxmemory_human:0B # 配置中设置的最大可使用内存值
maxmemory_policy:noeviction # 当达到maxmemory时的淘汰策略
主从集群
持久化
rdb的数据是存在内存中的,为了机器停机或故障之后数据还可以恢复,就有了持久化到磁盘的数据。
RDB
默认是持久化到一个rdb文件,会定义默认的持久化策略,策略全部注释表示关闭rdb持久化,就redis6而言,默认的配置文件是关闭rdb持久化的
dbfilename dump.rdb
dir ./
#save 900 1 # 在900秒内有一个key有变动就会进行一次持久化
#save 300 10
#save 60 10000
bgsave的写时复制(COW)机制
Redis 借助操作系统提供的写时复制技术(Copy-On-Write, COW),在生成快照的同时,依然可以正常处理写命令。简单来说,bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
save与bgsave对比:
| 命令 | save | bgsave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子进程执行调用fork函数时会有短暂阻塞) |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子进程,消耗内存 |
配置自动生成rdb文件后台使用的是bgsave方式。
AOF
(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化,将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间fsync到磁盘)
appendonly no
appendfilename "appendonly.aof"# appendfsync always # 每次操作都持久化到磁盘
appendfsync everysec # 一秒钟同步到磁盘一次 ,是aof的默认策略,如果故障,也只会丢失1秒的数据
# appendfsync no # 从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择大致是命令执行的顺序,将命令追加到aof文件中,当然并不是原始的明林,比如还包含了key的过期时间时间戳。
我们通过appendonly yes 来开启aof持久化,显然,reids6中使用的并不是aof持久化
# aof重写参数, 默认no,aof既然是命令的追加,那么就自然冗余,所以当aof文件过大时会进行重写,bgrewriteaof机制,在一个子进程中进行aof的重写,从而不阻塞主进程对其余命令的处理,同时解决了aof文件过大问题。既然操作磁盘,那就可能影响到主进程,这个参数为yes 是先将数据写入到缓冲区
no-appendfsync-on-rewrite no # 超过上一次文件的%分比后,进行重写,默认是一倍
auto-aof-rewrite-percentage 100
# aof文件超过64m 之后才重写
auto-aof-rewrite-min-size 64mb
混合持久化
当我们需要恢复数据是,只要将我们的rdb或aof文件放置到redis的数据目录下即可,由于rdb是二进制文件,显然在数据量较大的情况下,使用rdb文件恢复数据到内存中的速度更快
RDB 和 AOF ,我应该用哪一个?
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 容易丢数据 | 根据策略决定 |
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更全一点。
在reids4版本支持混合持久化,开启混合持久化命令如下,显然redis6默认的策略就是混合持久化
aof-use-rdb-preamble yes
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF 全量文件重放,因此重启效率大幅得到提升。
文件结构如图
<img src=“https://cdn.jsdelivr.net/gh/cloudinwinter/myimage@master/blogImg/20221108/1202211101203442.png” alt=“image-20221110120324650” style=“zoom: 50%;” /"/>
配置修改
如果是同一台机器部署,还需要修改pid文件存放位置,和日志文件存放位置,端口等,为了区分,最后重新命名配置文件
以下配置是在单机配置的基础上修改
# replicaof <masterip> <masterport> 配置从哪里同步数据,这里配置主节点的ip和端口
replicaof k8s-master 6379# replica 是复制品的意思,如果master设置了密码保护,从节点需要设置连接主节点的密码
# masterauth <master-password>
masterauth sry# 当连接挂掉之后,或者主从复制进行时,从节点数据可能不是最新的, 此参数设置为yes,表示从节点还是会响应客户端的数据,设置成no,则返回 SYNC with master in progress 的错误。默认yesreplica-serve-stale-data yes# 配置从节点只读 ,默认开启
replica‐read‐only yes
启动测试
启动和连接命令同单机

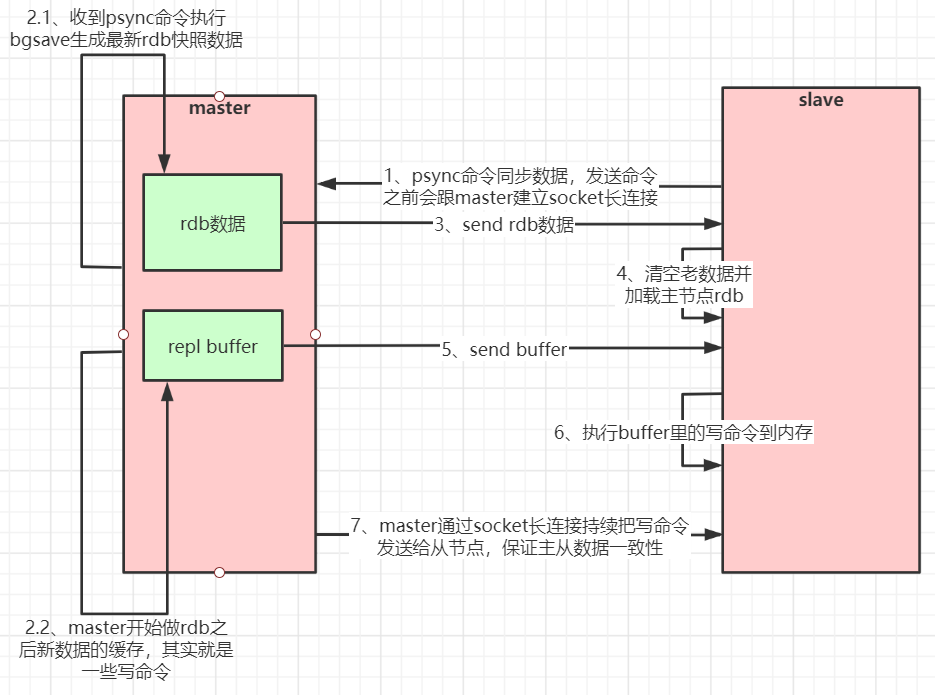
Redis主从工作原理
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave。
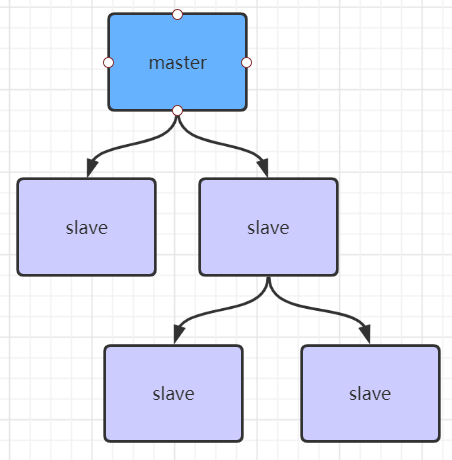
主从复制风暴
就是很多个从节点都从主节点获取数据,导致主节点压力过大,解决的话,如下图,似乎没了用,弄这么多从节点应该不太可能
哨兵集群
redis安装包中本身就有哨兵的配置文件,src下也有哨兵的操作命令,以下操作是粘贴过来的,仅做记录,大致是启动3个哨兵维持高可用,一个哨兵也是可以的,不过一个节点的哨兵挂了之后主从节点没法自动切换,
如果是三个哨兵,三个redis,那么哨兵会选举出leader(master挂了之后,而且每次挂了都会再次选举),由于需要半数以上的节点投票,所以哨兵最少三个才能保证高可用,选举出leader之后,再由leader将从节点切换成主节点。所以似乎不是必须一主两从,可以一主一从。master再次上线后,会作为从节点继续提供服务。
<img src=“https://cdn.jsdelivr.net/gh/cloudinwinter/myimage@master/blogImg/20221108/1202211101351821.png” alt=“image-20221110135155401” style=“zoom: 80%;” /"/>
1、复制一份sentinel.conf文件
cp sentinel.conf sentinel-26379.conf2、将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis-5.0.3/data"
# sentinel monitor <master-redis-name> <master-redis-ip> <master-redis-port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
sentinel monitor mymaster 192.168.0.60 6379 2 # mymaster这个名字随便取,客户端访问时会用到3、启动sentinel哨兵实例
src/redis-sentinel sentinel-26379.conf4、查看sentinel的info信息
src/redis-cli -p 26379
127.0.0.1:26379>info
可以看到Sentinel的info里已经识别出了redis的主从5、可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改
哨兵选举机制:https://blog.csdn.net/zh_nanfang/article/details/126401058
启动成功后每个哨兵的配置文件都会包含redis主从节点的信息,并且每次故障转移后,这些信息都会更新(追加的方式,以最后一条为准)
cluster集群
由于没有哨兵,需要redis的master节点来提供选举,同样是半数以上的机制,所以需要三组主从节点
机器不够,部分节点部署在同一台机器上
k8s部署相关地址:https://developer.aliyun.com/article/953884
配置
关键配置
首先不需要直接配置节点间主从关系,所以请不要开启replicaof的配置,部分访问的配置参考单机部署
# 开启集群模式
cluster-enabled yes# 集群启动成功后会保存集群的节点信息,这里指定文件的名称,以端口号区分,部署在同一台机器上的话注意修改
cluster-config-file nodes-6379.conf# 集群节点超时时间,超过会认为故障 默认5000
cluster-node-timeout 15000# 开启密码认证,并设置密码
requirepass sry# replica 是复制品的意思,如果master设置了密码保护,从节点需要设置连接主节点的密码。由于故障后涉及到主从切换,所以此处避免麻烦都设成一样的吧
# masterauth <master-password>
masterauth sry
其他集群参数配置全部走默认
次要配置
如果位于不同机器上此处可以不修改
主要是pid文件,数据持久化存放位置,端口号
以下仅做示例,每一个节点都应不同
# 默认会写入启动后的进程id到这个文件,注意需要有权限
pidfile /var/run/redis_6379.pid
# 持久化数据存放目录
dir /app/redis/cluster/data/6379/
#
port 6379
最终我的配置文件如下,由于我只有两台机器可以 部署,所以一个节点部署三个redis

启动集群
一次启动6台redis
redis-server /app/redis/cluster/conf/redis-cluster-6379.conf
redis-server /app/redis/cluster/conf/redis-cluster-6380.conf
redis-server /app/redis/cluster/conf/redis-cluster-6381.conf
端口放通
除了放通redis客户端连接端口外,cluster集群节点之间信息同步gossip通信端口16379(默认是在redis端口号上加1W)
创建集群
# --cluster-replicas 表示每一组节点从节点的数量,-a 表示集群节点密码
src/redis-cli -a sry --cluster create --cluster-replicas 1 43.143.136.203:6379 43.143.136.203:6380 43.143.136.203:6381 61.171.5.6:6379 61.171.5.6:6380 61.171.5.6:6381
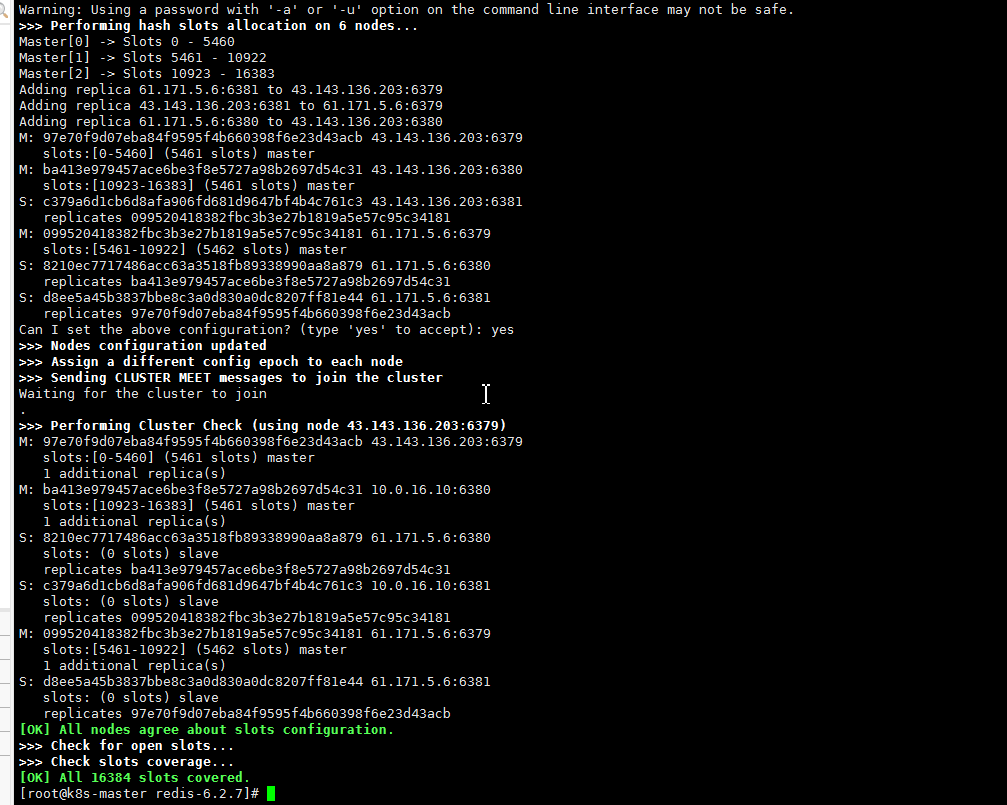
验证
# 连接集群中任意一个redis -c表示指定集群模式,不加的话进入客户端指定命令可能报错
src/redis-cli -h 127.0.0.1 -p 6379 -a sry -c进行验证:
(1) cluster info(查看集群信息)、cluster nodes(查看节点列表)
(2)进行数据操作验证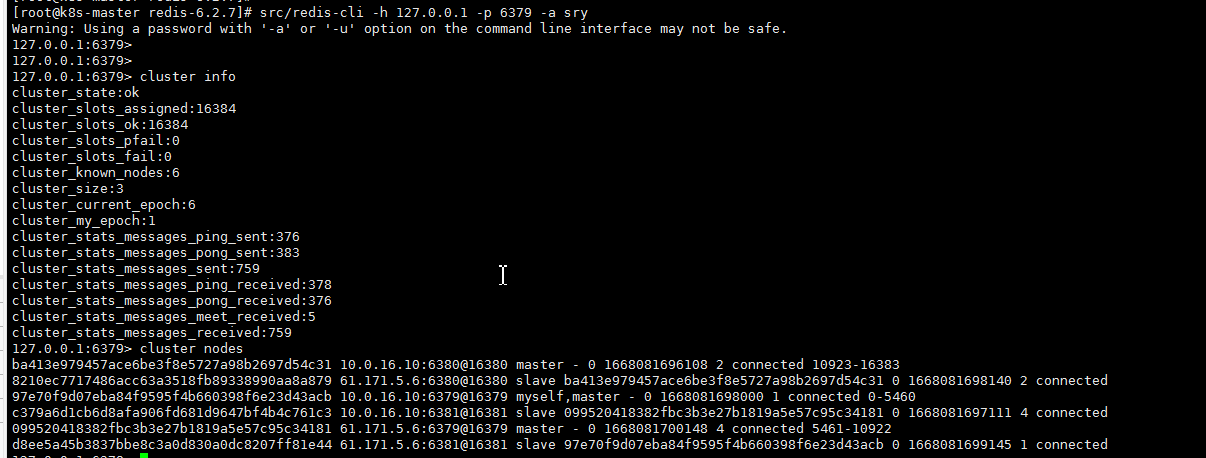
关闭集群
# 关闭集群则需要逐个进行关闭,使用命令:
src/redis-cli -a sry -c -h 127.0.0.1 -p 6379 shutdown
cluster扩容和缩容
仅做记录,未实际操作,且命令中的参数和我实际数据对应不上
首先集群最少三个,否则无法完成故障转移
配置文件
同上
操作
# 查看帮助
src/redis-cli --cluster help
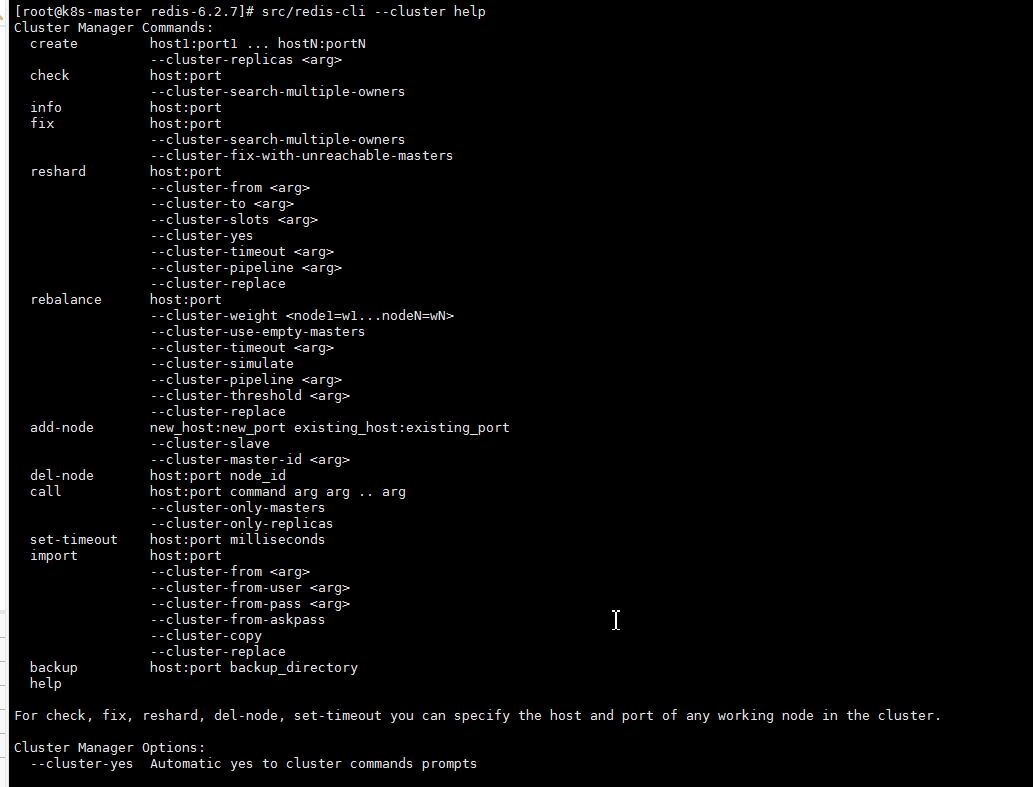
- 1.create:创建一个集群环境host1:port1 … hostN:portN
- 2.call:可以执行redis命令
- 3.add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
- 4.del-node:移除一个节点
- 5.reshard:重新分片
- 6.check:检查集群状态
添加节点
src/redis-cli -a zhuge --cluster add-node 192.168.0.61:8007 192.168.0.61:8001
查看集群状态
src/redis-cli -h 127.0.0.1 -p 6379 -a sry -c
cluster info
注意:当添加节点成功以后,新增的节点不会有任何数据,因为它还没有分配任何的slot(hash槽),我们需要为新节点手工分配hash槽
分配solt
随意连接上集群中的一个节点即可,需要注意的是分配solt需要主节点的id,这个在cluster info信息里可以看到
src/redis-cli -a zhuge --cluster reshard 192.168.0.61:8001

设置从节点
# 我们需要执行replicate命令来指定当前节点(从节点)的主节点id为哪个,首先需要连接新加的8008节点的客户端,然后使用集群命令进行操作,把当前的8008(slave)节点指定到一个主节点下(这里使用之前创建的8007主节点)
src/redis-cli -a zhuge -c -h 192.168.0.61 -p 8008
192.168.0.61:8008> cluster replicate 2728a594a0498e98e4b83a537e19f9a0a3790f38 #后面这串id为8007的节点id
删除节点
从节点删除
# 用del-node删除从节点8008,指定删除节点ip和端口,以及节点id(红色为8008节点id)
src/redis-cli -a zhuge --cluster del-node 192.168.0.61:8008 a1cfe35722d151cf70585cee21275565393c0956
主节点删除
主节点删除需要从新分配这个节点上的hash槽
src/redis-cli -a zhuge --cluster reshard 192.168.0.61:8007

# 再通过cluster info查看hash槽是否已经移除,然后删除主节点即可
src/redis-cli -a zhuge --cluster del-node 192.168.0.61:8007 2728a594a0498e98e4b83a537e19f9a0a3790f38cluster集群原理和问题
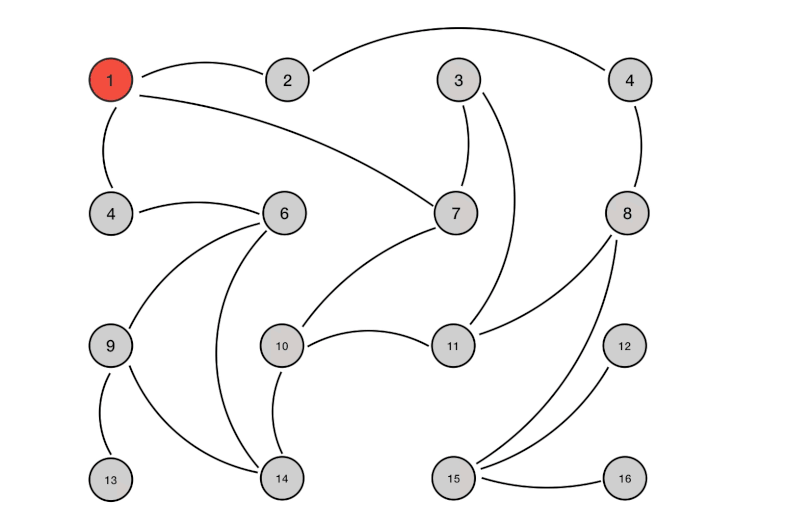
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) mod 16384
跳转重定位
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽位映射表。
以下图片中忘记了加-c 参数,所以报错了,正常不是这样的

客户端连接参数
Redis集群节点间的通信机制
redis cluster节点间采取gossip协议进行通信
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
- meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信;
- ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
- pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
- fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
- gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
gossip通信的10000端口
每个节点都有一个专门用于节点间gossip通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口。 每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping消息之后返回pong消息。
网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
Redis集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
- slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- slave广播Pong消息通知其他集群节点。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
•延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
集群脑裂数据丢失问题
网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复,会将其中一个主节点变为从节点,这时会有大量数据丢失。
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制):
# //写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,比如集群总共三个节点,每个节点一主一从,可以配置1,加上leader就是2,超过了半数
# min-replicas-to-write 3
# 数据复制和同步的延迟不能超过10秒,否则master拒绝写请求
# min-replicas-max-lag 10
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
Redis集群对批量操作命令的支持
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去,示例如下:
mset {user1}:1:name zhuge {user1}:1:age 18
假设name和age计算的hash slot值不一样,但是这条命令在集群下执行,redis只会用大括号里的 user1 做hash slot计算,所以算出来的slot值肯定相同,最后都能落在同一slot。
可视化工具
Redis Desktop Manager
下载需要收费,不过下载之后的安装包可以随意,之前一直用的这个,不过只能连接单机的redis
redis-insight
可以连接集群和单机,有桌面版和网页版,功能更全面,免费(其许可证上说明了非商用),至少Redis Desktop Manager 不支持发布订阅,指标监控
官方网址:https://redis.com/redis-enterprise/redis-insight/
其官方界面还提供免费的redis数据库
安装
这里下载linux版本的安装包
RedisInsight-v2-linux-x86_64.AppImage,不太好使,我直接k8s安装了
apiVersion: v1
kind: Namespace
metadata:name: redis---apiVersion: apps/v1
kind: Deployment
metadata:name: redisinsightnamespace: redislabels:app: redisinsight
spec:replicas: 1selector:matchLabels:app: redisinsighttemplate:metadata:labels:app: redisinsightspec:containers:- name: redisinsightimage: redislabs/redisinsight:1.13.1imagePullPolicy: IfNotPresentsecurityContext:runAsUser: 0volumeMounts:- name: dbmountPath: /dbports:- containerPort: 8001protocol: TCPvolumes:- name: dbhostPath:# 确保文件所在目录成功创建。path: /app/redis/redisinsight/datatype: DirectoryOrCreate
---apiVersion: v1
kind: Service
metadata:name: redisinsight-servicenamespace: redis
spec:type: NodePortselector:app: redisinsightports:- port: 8001targetPort: 8001nodePort: 31801,直接点连接单个节点即可,注意不是走redis enterprise cluster这个入口设置连接,而是走普通入口,我这里是网页版的连接集群成功的截图
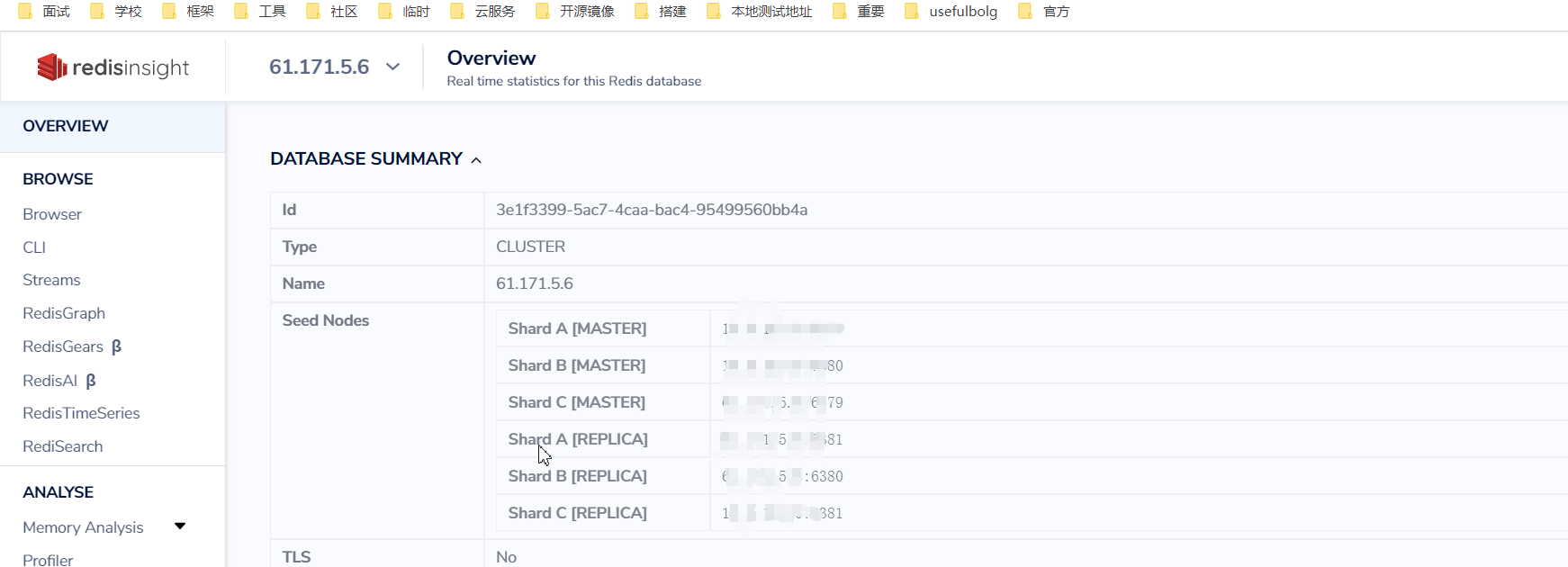
但是我本地使用window版的RedisInsight去访问集群似乎有问题,待定https://www.codenong.com/cs106207921/
程序或命令操作
java使用redis :https://developer.redis.com/develop/java/
中文命令在线:https://www.redis.net.cn/order
官方命令:https://redis.io/commands/
关联信息
- 关联的主题:
- 上一篇:
- 下一篇:
- image: 20221021/1
- 转载自: