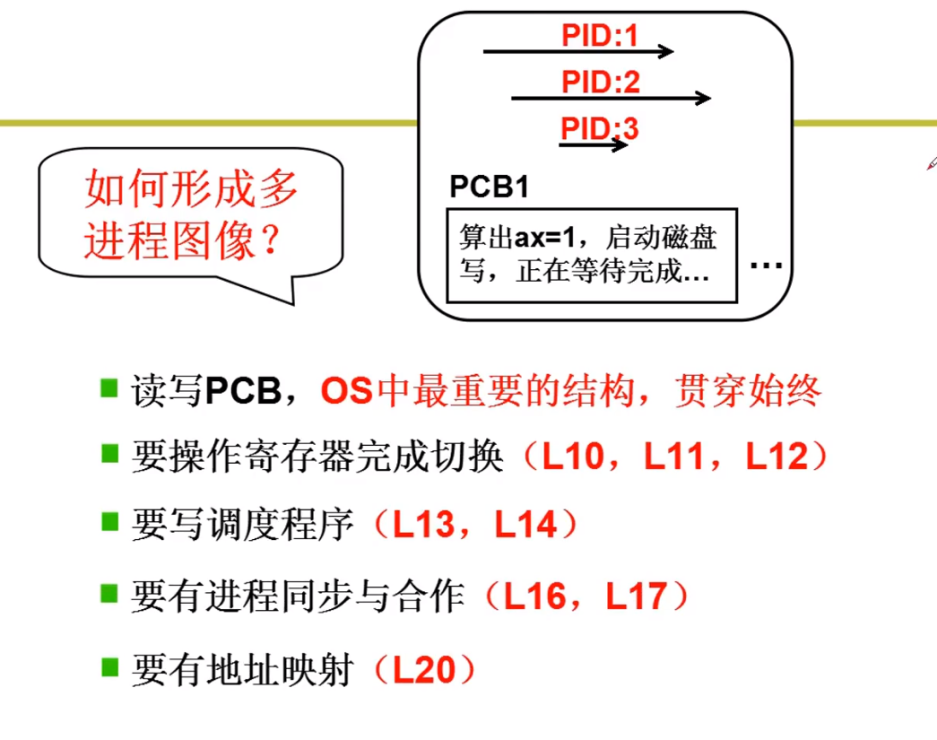
管理和自定义crushmap
定义pg到osd的映射关系
通过crush算法使三副本映射到理想的主机或者机架
更改故障域提高可靠性
pg到osd映射由crush实现

下载时需要将对象从osd搜索到,组成文件,那么对象多了就会效率变低,那么从pg组里面搜索。提高效率
对象放在pg要通过hash算法 95个pg / 100 取余 对象放在第95个pg里
pg属于存储池
默认池有32个pg
pg映射到osd,这个就属于crush算法
三种存储(rbd cephfs rgw)底层都是一样的
文件切分,是在客户端完成的
客户端被告知映射视图
然后开始存osd

crush的作用,就是根据pg id 得一个osd列表

crush map 的解译 编译 更新
导出一个二进制crush文件
[root@clienta ~]# cephadm shell
[ceph: root@clienta /]# ceph osd getcrushmap -o crushmap.bin
20
[ceph: root@clienta /]# ls
bin crushmap.bin etc lib lost+found mnt proc run srv tmp var
boot dev home lib64 media opt root sbin sys usr
[ceph: root@clienta /]#
将二进制转换为文本文件
[ceph: root@clienta /]# crushtool -d crushmap.bin -o crushmap.txt
[ceph: root@clienta /]# cat crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root# buckets
host serverc {id -3 # do not change unnecessarilyid -4 class hdd # do not change unnecessarily# weight 0.029alg straw2hash 0 # rjenkins1item osd.0 weight 0.010item osd.1 weight 0.010item osd.2 weight 0.010
}
host serverd {id -5 # do not change unnecessarilyid -6 class hdd # do not change unnecessarily# weight 0.029alg straw2hash 0 # rjenkins1item osd.3 weight 0.010item osd.5 weight 0.010item osd.7 weight 0.010
}
host servere {id -7 # do not change unnecessarilyid -8 class hdd # do not change unnecessarily# weight 0.029alg straw2hash 0 # rjenkins1item osd.4 weight 0.010item osd.6 weight 0.010item osd.8 weight 0.010
}
root default {id -1 # do not change unnecessarilyid -2 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item serverc weight 0.029item serverd weight 0.029item servere weight 0.029
}# rules
rule replicated_rule {id 0type replicatedmin_size 1max_size 10step take defaultstep chooseleaf firstn 0 type hoststep emit
}# end crush map
devices 会识别你的硬盘是ssd还是hdd
有时候会识别错误,但是可以人为干预
types 为故障域
三副本情况下
osd,找所有osd找三个 (三个osd在一个主机上,这样就容易丢数据)
host,所有主机找三个
rack,机架级别的
room、datacenter 房间,数据中心(也是故障域)
osd只能识别到host级别
其他级别就得自定义

放在同一个根下面就会有关系
三副本,要是你用这个图的数据中心级别,那么两个数据中心是不够的
默认故障域关系
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08817 root default #root
-3 0.02939 host serverc
0 hdd 0.00980 osd.0 up 1.00000 1.00000
1 hdd 0.00980 osd.1 up 1.00000 1.00000
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-5 0.02939 host serverd
3 hdd 0.00980 osd.3 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
7 hdd 0.00980 osd.7 up 1.00000 1.00000
-7 0.02939 host servere
4 hdd 0.00980 osd.4 up 1.00000 1.00000
6 hdd 0.00980 osd.6 up 1.00000 1.00000
8 hdd 0.00980 osd.8 up 1.00000 1.00000
[ceph: root@clienta /]# # buckets
host serverc {id -3 # do not change unnecessarilyid -4 class hdd # do not change unnecessarily# weight 0.029alg straw2hash 0 # rjenkins1item osd.0 weight 0.010item osd.1 weight 0.010item osd.2 weight 0.010
}
我们能改变的只是怎么去分布就好了。他这个自动已经通过算法识别好了,没必要改
权重1Tb为1 我一个osd 10G,主机权重为osd的和
root default {id -1 # do not change unnecessarilyid -2 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item serverc weight 0.029item serverd weight 0.029item servere weight 0.029
}
写一个rack级别
三个节点在不同机架
rack rack1 {id -9 # do not change unnecessarilyid -10 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item serverc weight 0.029
}rack rack2 {id -11 # do not change unnecessarilyid -12 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item serverd weight 0.029
}rack rack3 {id -13 # do not change unnecessarilyid -14 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item servere weight 0.029
}[ceph: root@clienta /]# cp crushmap.txt crushmap-new.txt
增加到new里面并且反编译[ceph: root@clienta /]# crushtool -c crushmap-new.txt -o crushmap-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i crushmap-new.bin
21
更新之后20变21 + 1 数据变了就知道更新了[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-13 0.02899 rack rack3
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
1 hdd 0.00999 osd.1 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-11 0.02899 rack rack2
-3 0.02899 host serverd
0 hdd 0.00999 osd.3 up 1.00000 1.00000
1 hdd 0.00999 osd.5 up 1.00000 1.00000
2 hdd 0.00999 osd.7 up 1.00000 1.00000
-9 0.02899 rack rack1
-3 0.02899 host servere
0 hdd 0.00999 osd.4 up 1.00000 1.00000
1 hdd 0.00999 osd.6 up 1.00000 1.00000
2 hdd 0.00999 osd.8 up 1.00000 1.00000
-1 0.08698 root default
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
1 hdd 0.00999 osd.1 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
5 hdd 0.00999 osd.5 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
6 hdd 0.00999 osd.6 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
[ceph: root@clienta /]# 无根节点,就是三个rack不在一起。一定要有根节点。
创建存储池可以选择根节点。好多个根节点,就得指定

dc如果是根,那它就到头了。不过不是,那还可以向上延伸。多个根之间没有任何关系。
root dc1 {id -15 # do not change unnecessarilyid -16 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item rack1 weight 0.029
}root dc2 {id -17 # do not change unnecessarilyid -18 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item rack2 weight 0.029item rack3 weight 0.029
}root dc3 {id -19 # do not change unnecessarilyid -20 class hdd # do not change unnecessarily# weight 0.088alg straw2hash 0 # rjenkins1item rack1 weight 0.029item rack2 weight 0.029item rack3 weight 0.029}
增加三个根节点dc
一个机架一个主机,所以一个主机权重就是机架权重
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-19 0.08698 root dc3
-9 0.02899 rack rack1
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
1 hdd 0.00999 osd.1 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-11 0.02899 rack rack2
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
5 hdd 0.00999 osd.5 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-13 0.02899 rack rack3
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
6 hdd 0.00999 osd.6 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
-17 0.05798 root dc2
-11 0.02899 rack rack2
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
5 hdd 0.00999 osd.5 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-13 0.02899 rack rack3
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
6 hdd 0.00999 osd.6 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
-15 0.02899 root dc1
-9 0.02899 rack rack1
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
1 hdd 0.00999 osd.1 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-1 0.08698 root default
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
1 hdd 0.00999 osd.1 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
5 hdd 0.00999 osd.5 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
6 hdd 0.00999 osd.6 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000

对应架构图
无法引用,没有设置规则
pool 6 'pool1' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 208 flags hashpspool stripe_width 0
创建一个pool1 他的规则仍然是crush_rule 0,没有任何改变
[ceph: root@clienta /]# ceph osd crush rule ls
replicated_rule# rules
rule replicated_rule {id 0type replicated #类型min_size 1 #副本数在1-10之间,副本超过11这个规则用不了max_size 10step take default # 这个规则引用了default根 并没用我的dc根step chooseleaf firstn 0 type host # 叶子节点就是rack那个 他这为host(默认),故障域(机架的 主机的 osd的)step emit
}
自己做一个rule
# rules
rule replicated_rule1 {id 1type replicatedmin_size 1max_size 10step take dc3 #根节点step chooseleaf firstn 0 type rack #故障域 step emit
}
应用它
[ceph: root@clienta /]# vi crushmap-new.txt
[ceph: root@clienta /]#
[ceph: root@clienta /]# crushtool -c crushmap-new.txt -o crushmap-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i crushmap-new.bin
24
[ceph: root@clienta /]# ceph osd crush rule ls
replicated_rule
replicated_rule1[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^8
dumped pgs_brief
8.4 active+clean [6,5,1] 6 [6,5,1] 6
8.7 active+clean [1,5,4] 1 [1,5,4] 1
8.6 active+clean [6,2,7] 6 [6,2,7] 6
8.1 active+clean [3,1,8] 3 [3,1,8] 3
8.0 active+clean [1,7,4] 1 [1,7,4] 1
8.3 active+clean [8,3,2] 8 [8,3,2] 8
8.2 active+clean [5,8,1] 5 [5,8,1] 5
8.d active+clean [2,7,6] 2 [2,7,6] 2
8.c active+clean [0,5,4] 0 [0,5,4] 0
8.f active+clean [4,5,1] 4 [4,5,1] 4
8.a active+clean [5,4,1] 5 [5,4,1] 5
8.9 active+clean [6,3,0] 6 [6,3,0] 6
8.b active+clean [0,8,5] 0 [0,8,5] 0
8.8 active+clean [1,3,6] 1 [1,3,6] 1
8.e active+clean [5,2,4] 5 [5,2,4] 5
8.5 active+clean [6,2,7] 6 [6,2,7] 6
8.1a active+clean [0,7,4] 0 [0,7,4] 0
8.1b active+clean [5,4,0] 5 [5,4,0] 5
8.18 active+clean [4,2,7] 4 [4,2,7] 4
8.19 active+clean [8,5,1] 8 [8,5,1] 8
8.1e active+clean [1,7,6] 1 [1,7,6] 1
8.1f active+clean [7,6,1] 7 [7,6,1] 7
8.1c active+clean [2,8,7] 2 [2,8,7] 2
8.1d active+clean [6,7,2] 6 [6,7,2] 6
8.12 active+clean [8,7,0] 8 [8,7,0] 8
8.13 active+clean [3,4,1] 3 [3,4,1] 3
8.10 active+clean [0,4,3] 0 [0,4,3] 0
8.11 active+clean [2,8,3] 2 [2,8,3] 2
8.16 active+clean [5,4,0] 5 [5,4,0] 5
8.17 active+clean [8,2,5] 8 [8,2,5] 8
8.14 active+clean [4,2,7] 4 [4,2,7] 4
8.15 active+clean [3,8,1] 3 [3,8,1] 3
[ceph: root@clienta /]#
分布在了三个rack上
# rules
rule replicated_rule1 {id 1type replicatedmin_size 1max_size 10step take dc3step chooseleaf firstn 0 type osdstep emit
}
更改规则为osd,可以发现0,1,5 0,1属于一个host,rack
[ceph: root@clienta /]# vi crushmap-new.txt
[ceph: root@clienta /]# crushtool -c crushmap-new.txt -o crushmap-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i crushmap-new.bin
26
[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^8
dumped pgs_brief
8.4 active+clean [6,5,3] 6 [6,5,3] 6
8.7 active+clean [1,5,3] 1 [1,5,3] 1
8.6 active+clean [6,2,8] 6 [6,2,8] 6
8.1 active+clean [3,7,1] 3 [3,7,1] 3
8.0 active+clean [1,0,7] 1 [1,0,7] 1
8.3 active+clean [8,4,3] 8 [8,4,3] 8
8.2 active+clean [5,8,7] 5 [5,8,7] 5
8.d active+clean [2,7,6] 2 [2,7,6] 2
8.c active+clean [0,5,1] 0 [0,5,1] 0
8.f active+clean [4,5,1] 4 [4,5,1] 4
8.a active+clean [5,4,6] 5 [5,4,6] 5
8.9 active+clean [6,3,5] 6 [6,3,5] 6
8.b active+clean [0,8,2] 0 [0,8,2] 0
8.8 active+clean [1,3,6] 1 [1,3,6] 1
8.e active+clean [5,2,1] 5 [5,2,1] 5
8.5 active+clean [6,2,7] 6 [6,2,7] 6
8.1a active+clean [0,7,4] 0 [0,7,4] 0
8.1b active+clean [5,4,0] 5 [5,4,0] 5
8.18 active+clean [4,2,7] 4 [4,2,7] 4
8.19 active+clean [8,4,5] 8 [8,4,5] 8
8.1e active+clean [1,7,6] 1 [1,7,6] 1
8.1f active+clean [7,5,6] 7 [7,5,6] 7
8.1c active+clean [2,8,7] 2 [2,8,7] 2
8.1d active+clean [6,7,2] 6 [6,7,2] 6
8.12 active+clean [8,7,0] 8 [8,7,0] 8
8.13 active+clean [3,4,1] 3 [3,4,1] 3
8.10 active+clean [0,4,1] 0 [0,4,1] 0
8.11 active+clean [2,8,6] 2 [2,8,6] 2
8.16 active+clean [5,4,8] 5 [5,4,8] 5
8.17 active+clean [8,6,2] 8 [8,6,2] 8
8.14 active+clean [4,2,7] 4 [4,2,7] 4
8.15 active+clean [3,8,1] 3 [3,8,1] 3
[ceph: root@clienta /]#
冲突案例
# rules
rule replicated_rule2 {id 1type replicatedmin_size 1max_size 10step take dc2 #根节点 (class ssd)step chooseleaf firstn 0 type rack #firstn0 你有三副本就选择三个rackstep emit
}
这个是池是三副本默认值,但是dc2是只有两个机架(两个主机,我一个机架一个主机)。那么firstn0他硬要选择三副本,所以会引发冲突
将replicated_rule2加入配置文件
[ceph: root@clienta /]# crushtool -c crushmap-new.txt -o crushmap-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i crushmap-new.bin
27
[ceph: root@clienta /]# ceph osd pool create pool4 replicated_rule2
pool 'pool4' created
[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^9
dumped pgs_brief
9.5 active+undersized [5,6] 5 [5,6] 5
9.6 active+undersized [4,5] 4 [4,5] 4
9.7 active+undersized [6,3] 6 [6,3] 6
9.0 active+undersized [5,4] 5 [5,4] 5
9.1 active+undersized [3,4] 3 [3,4] 3
9.2 active+undersized [8,5] 8 [8,5] 8
9.3 active+undersized [7,4] 7 [7,4] 7
9.c active+undersized [3,4] 3 [3,4] 3
9.d active+undersized [3,4] 3 [3,4] 3
9.e active+undersized [7,4] 7 [7,4] 7
9.b active+undersized [5,4] 5 [5,4] 5
9.8 active+undersized [8,3] 8 [8,3] 8
9.a active+undersized [3,4] 3 [3,4] 3
9.9 active+undersized [5,8] 5 [5,8] 5
9.f active+undersized [4,5] 4 [4,5] 4
9.4 active+undersized [8,3] 8 [8,3] 8
9.1b active+undersized [5,4] 5 [5,4] 5
9.1a active+undersized [8,7] 8 [8,7] 8
9.19 active+undersized [6,3] 6 [6,3] 6
9.18 active+undersized [5,4] 5 [5,4] 5
9.1f active+undersized [6,7] 6 [6,7] 6
9.1e active+undersized [7,8] 7 [7,8] 7
9.1d active+undersized [6,3] 6 [6,3] 6
9.1c active+undersized [5,4] 5 [5,4] 5
9.13 active+undersized [8,5] 8 [8,5] 8
9.12 active+undersized [5,8] 5 [5,8] 5
9.11 active+undersized [8,3] 8 [8,3] 8
9.10 active+undersized [5,4] 5 [5,4] 5
9.17 active+undersized [8,7] 8 [8,7] 8
9.16 active+undersized [5,4] 5 [5,4] 5
9.15 active+undersized [7,4] 7 [7,4] 7
9.14 active+undersized [4,3] 4 [4,3] 4
[ceph: root@clienta /]#
undersized超出了,不是很健康
[ceph: root@clienta /]# ceph -s
cluster:id: 2ae6d05a-229a-11ec-925e-52540000fa0chealth: HEALTH_WARNDegraded data redundancy: 32 pgs undersizedservices:mon: 4 daemons, quorum serverc.lab.example.com,clienta,serverd,servere (age 3h)mgr: serverc.lab.example.com.aiqepd(active, since 3h), standbys: clienta.nncugs, servere.kjwyko, serverd.klrkciosd: 9 osds: 9 up (since 3h), 9 in (since 9M)rgw: 2 daemons active (2 hosts, 1 zones)data:pools: 9 pools, 233 pgsobjects: 221 objects, 4.9 KiBusage: 245 MiB used, 90 GiB / 90 GiB availpgs: 201 active+clean32 active+undersizedio:client: 71 KiB/s rd, 0 B/s wr, 71 op/s rd, 47 op/s wr
ceph -s 警告了
pg属于降级状态,未达到规定副本数

修复状态
更改配置文件
# rules
rule replicated_rule2 {id 2type replicatedmin_size 1max_size 10step take dc2step chooseleaf firstn 2 type rack #定义2副本step emitstep take dc1 step chooseleaf firstn 1 type rack #定义剩下的1个副本step emit
} [ceph: root@clienta /]# vi crushmap-new.txt
[ceph: root@clienta /]# crushtool -c crushmap-new.txt -o crushmap-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i crushmap-new.bin
28[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^9
dumped pgs_brief
9.5 active+clean [5,6,0] 5 [5,6,0] 5
9.6 activating [4,5,2] 4 [4,5,2] 4
9.7 activating [6,3,2] 6 [6,3,2] 6
9.0 activating [5,4,1] 5 [5,4,1] 5
9.1 active+clean [3,4,0] 3 [3,4,0] 3
9.2 activating [8,5,1] 8 [8,5,1] 8
9.3 active+clean [7,4,0] 7 [7,4,0] 7
9.c activating [3,4,2] 3 [3,4,2] 3
9.d active+clean [3,4,0] 3 [3,4,0] 3
9.e activating [7,4,2] 7 [7,4,2] 7
9.b active+clean [5,4,0] 5 [5,4,0] 5
9.8 activating [8,3,2] 8 [8,3,2] 8
firstn = 0 则是在根节点下寻找3个叶子(副本数)节点存放
firstn > 0 则在根节点寻找2个叶子节点存放副本(三副本),剩余副本则使用下面的规则
firstn -1 < 0 则是在根节点下寻找副本数减去其绝对值个叶子节点存放副本 (负数?这真的有必要吗?)

把上面做的还原
创建基于ssd的存储池
元数据 检索要求磁盘较快(ssd)
删掉原有磁盘类型
手动改类型
[ceph: root@clienta /]# ceph osd crush rm-device-class osd.1
done removing class of osd(s): 1
[ceph: root@clienta /]# ceph osd crush rm-device-class osd.5
done removing class of osd(s): 5
[ceph: root@clienta /]# ceph osd crush rm-device-class osd.6
done removing class of osd(s): 6
[ceph: root@clienta /]# [ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08698 root default
-3 0.02899 host serverc
1 0.00999 osd.1 up 1.00000 1.00000
0 hdd 0.00999 osd.0 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
-5 0.02899 host serverd
5 0.00999 osd.5 up 1.00000 1.00000
3 hdd 0.00999 osd.3 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
-7 0.02899 host servere
6 0.00999 osd.6 up 1.00000 1.00000
4 hdd 0.00999 osd.4 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
[ceph: root@clienta /]#
更改为ssd
[ceph: root@clienta /]# for i in 1 5 6;do ceph osd crush set-device-class ssd osd.$i; done[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08698 root default
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
5 ssd 0.00999 osd.5 up 1.00000 1.00000
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
6 ssd 0.00999 osd.6 up 1.00000 1.00000
[ceph: root@clienta /]# [ceph: root@clienta /]# ceph osd crush class ls
["hdd","ssd"
]
[ceph: root@clienta /]#
命令行创建规则
[ceph: root@clienta /]# ceph osd crush rule create-replicated ssd_rule default host ssd
[ceph: root@clienta /]# ceph osd crush rule ls
replicated_rule
ssd_rule
[ceph: root@clienta /]#
创建存储池
[ceph: root@clienta /]# ceph osd crush rule create-replicated ssd_rule default host ssd
[ceph: root@clienta /]# ceph osd crush rule ls
replicated_rule
ssd_rule
[ceph: root@clienta /]# ceph osd pool create pool1 ssd_rule
pool 'pool1' created[ceph: root@clienta /]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 249 flags hashpspool stripe_width 0 pg_num_min 1 application mgr_devicehealth
pool 2 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 48 flags hashpspool stripe_width 0 application rgw
pool 3 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 50 flags hashpspool stripe_width 0 application rgw
pool 4 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 52 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.meta' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 184 lfor 0/184/182 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 8 application rgw
pool 10 'pool1' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 266 flags hashpspool stripe_width 0[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^10
dumped pgs_brief
10.6 active+clean [6,1,5] 6 [6,1,5] 6
10.5 active+clean [1,5,6] 1 [1,5,6] 1
10.4 active+clean [5,1,6] 5 [5,1,6] 5
10.3 active+clean [5,6,1] 5 [5,6,1] 5
10.2 active+clean [6,5,1] 6 [6,5,1] 6
10.1 active+clean [1,5,6] 1 [1,5,6] 1
10.0 active+clean [6,5,1] 6 [6,5,1] 6
10.f active+clean [6,1,5] 6 [6,1,5] 6
10.e active+clean [1,5,6] 1 [1,5,6] 1
10.d active+clean [6,5,1] 6 [6,5,1] 6
10.8 active+clean [1,5,6] 1 [1,5,6] 1
10.b active+clean [6,5,1] 6 [6,5,1] 6
10.9 active+clean [1,5,6] 1 [1,5,6] 1
10.a active+clean [5,1,6] 5 [5,1,6] 5
10.c active+clean [1,5,6] 1 [1,5,6] 1
10.7 active+clean [5,6,1] 5 [5,6,1] 5
10.18 active+clean [1,5,6] 1 [1,5,6] 1
10.19 active+clean [1,6,5] 1 [1,6,5] 1
10.1a active+clean [6,1,5] 6 [6,1,5] 6
10.1b active+clean [6,5,1] 6 [6,5,1] 6
10.1c active+clean [5,1,6] 5 [5,1,6] 5
10.1d active+clean [6,1,5] 6 [6,1,5] 6
10.1e active+clean [1,5,6] 1 [1,5,6] 1
10.1f active+clean [6,1,5] 6 [6,1,5] 6
10.10 active+clean [1,6,5] 1 [1,6,5] 1
10.11 active+clean [5,6,1] 5 [5,6,1] 5
10.12 active+clean [6,5,1] 6 [6,5,1] 6
10.13 active+clean [5,1,6] 5 [5,1,6] 5
10.14 active+clean [1,6,5] 1 [1,6,5] 1
10.15 active+clean [6,1,5] 6 [6,1,5] 6
10.16 active+clean [6,1,5] 6 [6,1,5] 6
10.17 active+clean [1,6,5] 1 [1,6,5] 1
[ceph: root@clienta /]#
全部在指定磁盘上
可以整一个性能较好的池(都是ssd盘)
命令行在配置文件里做了这些操作
[ceph: root@clienta /]# ceph osd getcrushmap -o crushmap.bin
44
[ceph: root@clienta /]# crushtool -d crushmap.bin -o crushmap.txt
[ceph: root@clienta /]# vi crushmap.txt rule ssd_rule {id 1type replicatedmin_size 1max_size 10step take default class ssdstep chooseleaf firstn 0 type hoststep emit
}
# devices
device 0 osd.0 class hdd
device 1 osd.1 class ssd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class ssd
device 6 osd.6 class ssd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
执行lab命令(会报错,改变devices标签的时候,选择手动改标签)
lab start map-crush
[ceph: root@clienta /]# ceph osd crush add-bucket cl260 root
added bucket cl260 type root to crush map
[ceph: root@clienta /]# ceph osd crush add-bucket rack1 rack
added bucket rack1 type rack to crush map
[ceph: root@clienta /]# ceph osd crush add-bucket rack2 rack
added bucket rack2 type rack to crush map
[ceph: root@clienta /]# ceph osd crush add-bucket rack3 rack
added bucket rack3 type rack to crush map
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-16 0 rack rack3
-15 0 rack rack2
-14 0 rack rack1
-13 0 root cl260
-1 0.08698 root default
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
5 ssd 0.00999 osd.5 up 1.00000 1.00000
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
6 ssd 0.00999 osd.6 up 1.00000 1.00000
[ceph: root@clienta /]# [ceph: root@clienta /]# ceph osd crush add-bucket hostc host
added bucket hostc type host to crush map
[ceph: root@clienta /]# ceph osd crush add-bucket hostd host
added bucket hostd type host to crush map
[ceph: root@clienta /]# ceph osd crush add-bucket hoste host
added bucket hoste type host to crush map
[ceph: root@clienta /]# ceph osd crush move rack1 root=cl260
moved item id -14 name 'rack1' to location {root=cl260} in crush map
[ceph: root@clienta /]# ceph osd crush move rack2 root=cl260
moved item id -15 name 'rack2' to location {root=cl260} in crush map
[ceph: root@clienta /]# ceph osd crush move rack3 root=cl260
moved item id -16 name 'rack3' to location {root=cl260} in crush map
[ceph: root@clienta /]# ceph osd crush move hostc rack=rack1
moved item id -17 name 'hostc' to location {rack=rack1} in crush map
[ceph: root@clienta /]# ceph osd crush move hostd rack=rack2
moved item id -18 name 'hostd' to location {rack=rack2} in crush map
[ceph: root@clienta /]# ceph osd crush move hoste rack=rack3
moved item id -19 name 'hoste' to location {rack=rack3} in crush map
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-13 0 root cl260
-14 0 rack rack1
-17 0 host hostc
-15 0 rack rack2
-18 0 host hostd
-16 0 rack rack3
-19 0 host hoste
-1 0.08698 root default
-3 0.02899 host serverc
0 hdd 0.00999 osd.0 up 1.00000 1.00000
2 hdd 0.00999 osd.2 up 1.00000 1.00000
1 ssd 0.00999 osd.1 up 1.00000 1.00000
-5 0.02899 host serverd
3 hdd 0.00999 osd.3 up 1.00000 1.00000
7 hdd 0.00999 osd.7 up 1.00000 1.00000
5 ssd 0.00999 osd.5 up 1.00000 1.00000
-7 0.02899 host servere
4 hdd 0.00999 osd.4 up 1.00000 1.00000
8 hdd 0.00999 osd.8 up 1.00000 1.00000
6 ssd 0.00999 osd.6 up 1.00000 1.00000
[ceph: root@clienta /]# [ceph: root@clienta /]# ceph osd crush set osd.1 1.0 root=cl260 rack=rack1 host=hostc
set item id 1 name 'osd.1' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.5 1.0 root=cl260 rack=rack1 host=hostc
set item id 5 name 'osd.5' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.6 1.0 root=cl260 rack=rack1 host=hostc
set item id 6 name 'osd.6' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]#
权重1.0,大小都一样所以1.0[ceph: root@clienta /]# ceph osd crush set osd.1 1.0 root=cl260 rack=rack1 host=hostc
set item id 1 name 'osd.1' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.5 1.0 root=cl260 rack=rack1 host=hostc
set item id 5 name 'osd.5' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.6 1.0 root=cl260 rack=rack1 host=hostc
set item id 6 name 'osd.6' weight 1 at location {host=hostc,rack=rack1,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.0 1.0 root=cl260 rack=rack2 host=hostd
set item id 0 name 'osd.0' weight 1 at location {host=hostd,rack=rack2,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.3 1.0 root=cl260 rack=rack2 host=hostd
set item id 3 name 'osd.3' weight 1 at location {host=hostd,rack=rack2,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.4 1.0 root=cl260 rack=rack2 host=hostd
set item id 4 name 'osd.4' weight 1 at location {host=hostd,rack=rack2,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.2 1.0 root=cl260 rack=rack3 host=hoste
set item id 2 name 'osd.2' weight 1 at location {host=hoste,rack=rack3,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.7 1.0 root=cl260 rack=rack3 host=hoste
set item id 7 name 'osd.7' weight 1 at location {host=hoste,rack=rack3,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd crush set osd.8 1.0 root=cl260 rack=rack3 host=hoste
set item id 8 name 'osd.8' weight 1 at location {host=hoste,rack=rack3,root=cl260} to crush map
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-13 9.00000 root cl260
-14 3.00000 rack rack1
-17 3.00000 host hostc
1 ssd 1.00000 osd.1 up 1.00000 1.00000
5 ssd 1.00000 osd.5 up 1.00000 1.00000
6 ssd 1.00000 osd.6 up 1.00000 1.00000
-15 3.00000 rack rack2
-18 3.00000 host hostd
0 hdd 1.00000 osd.0 up 1.00000 1.00000
3 hdd 1.00000 osd.3 up 1.00000 1.00000
4 hdd 1.00000 osd.4 up 1.00000 1.00000
-16 3.00000 rack rack3
-19 3.00000 host hoste
2 hdd 1.00000 osd.2 up 1.00000 1.00000
7 hdd 1.00000 osd.7 up 1.00000 1.00000
8 hdd 1.00000 osd.8 up 1.00000 1.00000
-1 0 root default
-3 0 host serverc
-5 0 host serverd
-7 0 host servere
[ceph: root@clienta /]#
改配置文件
[ceph: root@clienta /]# ceph osd getcrushmap -o cm-org.bin
66
[ceph: root@clienta /]# crushtool -d cm-org.bin -o cm-org.txt
[ceph: root@clienta /]# cp cm-org.txt cm-new.txt
[ceph: root@clienta /]# vi cm-new.txt
[ceph: root@clienta /]# rule ssd_first {id 2type replicatedmin_size 1max_size 10step take rack1 class ssdstep chooseleaf firstn 1 type hoststep emitstep take cl260 class hddstep chooseleaf firstn -1 type rackstep emit}
第一个副本为主osd,给他放到ssd上
剩下的副本在不同的rack(hdd)里选择一个osd
[ceph: root@clienta /]# crushtool -c cm-new.txt -o cm-new.bin
[ceph: root@clienta /]# ceph osd setcrushmap -i cm-new.bin
ceph 67
[ceph: root@clienta /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-13 9.00000 root cl260
-14 3.00000 rack rack1
-17 3.00000 host hostc
1 ssd 1.00000 osd.1 up 1.00000 1.00000
5 ssd 1.00000 osd.5 up 1.00000 1.00000
6 ssd 1.00000 osd.6 up 1.00000 1.00000
-15 3.00000 rack rack2
-18 3.00000 host hostd
0 hdd 1.00000 osd.0 up 1.00000 1.00000
3 hdd 1.00000 osd.3 up 1.00000 1.00000
4 hdd 1.00000 osd.4 up 1.00000 1.00000
-16 3.00000 rack rack3
-19 3.00000 host hoste
2 hdd 1.00000 osd.2 up 1.00000 1.00000
7 hdd 1.00000 osd.7 up 1.00000 1.00000
8 hdd 1.00000 osd.8 up 1.00000 1.00000
-1 0 root default
-3 0 host serverc
-5 0 host serverd
-7 0 host servere
[ceph: root@clienta /]# ceph osd crush rule ls
replicated_rule
ssd_rule
ssd_first
[ceph: root@clienta /]#
创建存储池查看效果
[ceph: root@clienta /]# ceph osd pool create ssdpool ssd_first
pool 'ssdpool' created
[ceph: root@clienta /]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 249 flags hashpspool stripe_width 0 pg_num_min 1 application mgr_devicehealth
pool 2 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 48 flags hashpspool stripe_width 0 application rgw
pool 3 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 50 flags hashpspool stripe_width 0 application rgw
pool 4 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 52 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.meta' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 8 pgp_num 8 autoscale_mode on last_change 184 lfor 0/184/182 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 8 application rgw
pool 10 'pool1' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 266 flags hashpspool stripe_width 0
pool 11 'ssdpool' replicated size 3 min_size 2 crush_rule 2 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 338 flags hashpspool stripe_width 0[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^11
dumped pgs_brief
11.7 active+clean [1,7,4] 1 [1,7,4] 1
11.4 active+clean [5,0,8] 5 [5,0,8] 5
11.5 active+clean [1,8,3] 1 [1,8,3] 1
11.2 active+clean [5,8,3] 5 [5,8,3] 5
11.3 active+clean [6,7,3] 6 [6,7,3] 6
11.0 active+clean [1,2,0] 1 [1,2,0] 1
11.1 active+clean [6,0,2] 6 [6,0,2] 6
11.e active+clean [5,4,7] 5 [5,4,7] 5
11.f active+clean [6,0,7] 6 [6,0,7] 6
11.c active+clean [1,4,8] 1 [1,4,8] 1
11.9 active+clean [1,8,3] 1 [1,8,3] 1
11.a active+clean [5,7,3] 5 [5,7,3] 5
11.8 active+clean [6,8,4] 6 [6,8,4] 6
11.b active+clean [6,2,4] 6 [6,2,4] 6
11.d active+clean [6,7,3] 6 [6,7,3] 6
11.6 active+clean [1,8,3] 1 [1,8,3] 1
11.19 active+clean [1,8,3] 1 [1,8,3] 1
11.18 active+clean [6,2,4] 6 [6,2,4] 6
11.1b active+clean [6,2,4] 6 [6,2,4] 6
11.1a active+clean [5,3,7] 5 [5,3,7] 5
11.1d active+clean [1,7,4] 1 [1,7,4] 1
11.1c active+clean [6,2,4] 6 [6,2,4] 6
11.1f active+clean [6,4,8] 6 [6,4,8] 6
11.1e active+clean [5,3,7] 5 [5,3,7] 5
11.11 active+clean [1,0,7] 1 [1,0,7] 1
11.10 active+clean [5,2,3] 5 [5,2,3] 5
11.13 active+clean [5,0,8] 5 [5,0,8] 5
11.12 active+clean [5,2,0] 5 [5,2,0] 5
11.15 active+clean [5,0,2] 5 [5,0,2] 5
11.14 active+clean [6,3,2] 6 [6,3,2] 6
11.17 active+clean [5,0,8] 5 [5,0,8] 5
11.16 active+clean [1,0,7] 1 [1,0,7] 1
[ceph: root@clienta /]#
提升读效率,对外提供服务会好
写的时候第一个快了。主osd写完,后复制到另外两hdd
纠删码池和复制池是通用定义域,但是规则会有区别,各用各的
关于纠删码池的规则
ceph osd erasure-code-profile set myprofile k=3 m=2 crush-root=DC2 crush-failure-domain=rack crush-device-class=ssd
ceph osd pool create myecpool 50 50 erasure myprofile
ceph osd crush rule ls[ceph: root@clienta /]# ceph osd erasure-code-profile set myprofile2 crush-root=cl260 crush-failure-domain=osd
[ceph: root@clienta /]# ceph osd pool create myecpool2 erasure myprofile2
pool 'myecpool2' created
[ceph: root@clienta /]# ceph pg dump pgs_brief | grep ^13
dumped pgs_brief
13.1 creating+peering [8,4,5,7] 8 [8,4,5,7] 8
13.2 creating+peering [8,0,5,4] 8 [8,0,5,4] 8
13.3 creating+peering [2,6,0,4] 2 [2,6,0,4] 2
手动改映射
[ceph: root@clienta /]# ceph pg map 11.7
osdmap e338 pg 11.7 (11.7) -> up [1,7,4] acting [1,7,4]
[ceph: root@clienta /]# ceph osd pg-upmap-items 11.7 7 8
set 11.7 pg_upmap_items mapping to [7->8]
[ceph: root@clienta /]# ceph pg map 11.7
osdmap e340 pg 11.7 (11.7) -> up [1,8,4] acting [1,8,4]
[ceph: root@clienta /]#
命令概括
1. 假设每台主机的最后一个osd为ssd
for i in 0 3 6;do ceph osd crush rm-device-class osd.$i;done
for i in 0 3 6;do ceph osd crush set-device-class ssd osd.$i;done
ceph osd crush class ls
ceph osd crush rule create-replicated ssd_rule default host ssd
ceph osd crush rule ls
1. 创建基于ssd_rule规则的存储池
ceph osd pool create cache 64 64 ssd_rule
1. 将一个现有的池迁移至ssd的osd上
ceph osd pool set cephfs_metadata crush_rule ssd_rule
1. 写入数据,测试数据分布
rados -p cache put test test.txt
ceph osd map cache test3.命令行管理crushmap
1.移除osd.1 osd.5 osd.6的设备类型
ceph osd crush rm-device-class osd.1
ceph osd crush rm-device-class osd.5
ceph osd crush rm-device-class osd.62.设置osd.1 osd.5 osd.6的设备类型
ceph osd crush set-device-class ssd osd.1
ceph osd crush set-device-class ssd osd.5
ceph osd crush set-device-class ssd osd.63.添加root节点
ceph osd crush add-bucket cl260 root4.添加rack节点
ceph osd crush add-bucket rack1 rack
ceph osd crush add-bucket rack2 rack
ceph osd crush add-bucket rack3 rack5.添加主机节点
ceph osd crush add-bucket hostc host
ceph osd crush add-bucket hostd host
ceph osd crush add-bucket hoste host6.将rack移动到root节点下
ceph osd crush move rack1 root=cl260
ceph osd crush move rack2 root=cl260
ceph osd crush move rack3 root=cl2607.将host移动到rack下
ceph osd crush move hostc rack=rack1
ceph osd crush move hostd rack=rack2
ceph osd crush move hoste rack=rack38.将osd移动到host下
ceph osd crush set osd.1 1.0 root=cl260 rack=rack1 host=hostc
ceph osd crush set osd.5 1.0 root=cl260 rack=rack1 host=hostc
ceph osd crush set osd.6 1.0 root=cl260 rack=rack1 host=hostc
ceph osd crush set osd.0 1.0 root=cl260 rack=rack1 host=hostd
ceph osd crush set osd.3 1.0 root=cl260 rack=rack1 host=hostd
ceph osd crush set osd.4 1.0 root=cl260 rack=rack1 host=hostd
ceph osd crush set osd.2 1.0 root=cl260 rack=rack1 host=hoste
ceph osd crush set osd.7 1.0 root=cl260 rack=rack1 host=hoste
ceph osd crush set osd.8 1.0 root=cl260 rack=rack1 host=hoste9添加规则
ceph osd getcrushmap -o cm-org.bin
crushtool -d cm-org.bin -o cm-org.txt
cp cm-org.txt cm-new.txt
vi cm-new.txt
rule ssd_first {id 2type replicatedmin_size 1max_size 10step take rack1step chooseleaf firstn 1 type host # 第1个副本在rack1上step emitstep take cl260 class hddstep chooseleaf firstn -1 type rack # 剩余副本在cl260根下的hdd上step emit
}crushtool -c cm-new.txt -o cm-new.bin
ceph osd setcrushmap -i cm-new.bin
ceph osd tree
ceph osd crush ls
ceph osd crush rule ls
ceph osd pool create ssdpool ssd_firstceph pg dump pgs_brief | grep ^10