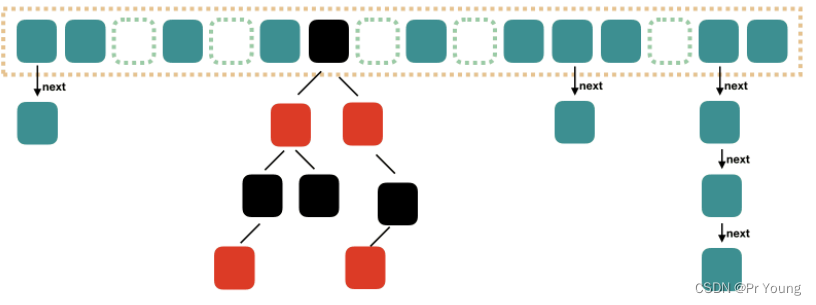
HashMap的底层结构是数组+链表
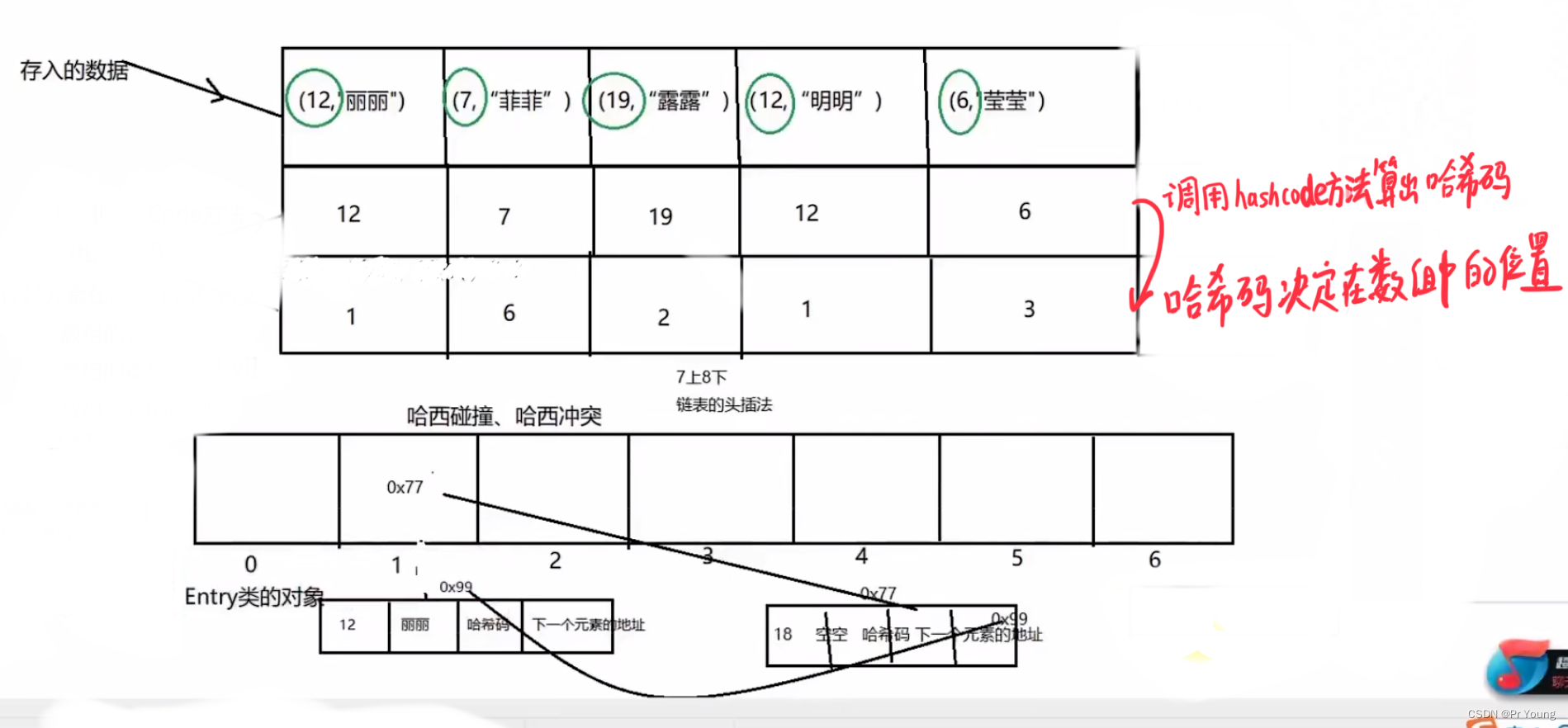
没有哈希冲突的元素放在数组里面, 哈希冲突的元素用链表串起来
初始数组长度是16,对应源码:
static final int DEFAULT_INITIAL_CAPACITY=1;最大的容量为2的30次方,一个很大很大很大的数
还定义了一个负载因子下(加载因子):0.75
static final float DEFAULT_LOAD_FACTOR=0.75;
当数组内元素数量超过 “数组容量*加载因子”时,进行扩容
(1)为什么加载因子为0.75?
加载因子为0.5时,虽然不容易产生碰撞,因此不容易产生链表,所以查询的次数也更少,查询效率高,但是需要频繁进行扩容,空间利用率太低了
装填因子为1的话,会容易产生碰撞,所以很容易产生链表,这样要查询的次数就更多,所以查询的效率很低
因此折中一下,取平均值
(2)为什么扩容后数组的长度时2的n次方?
jdk1.8 hashmap的数据结构就变成数组+链表+红黑树
1.7 数组+链表时,顺着链表一个一个查的时间复杂度为O(n)
1.8,当链表中的元素达到了 8 个时,会将链表转换为红黑树,查找的时间复杂度降为O(logN)