原创文章第116篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
北京疫情似乎还没有到拐点,但这三天结束后应该会到来。
今天重点说说,机器学习模型整合到我们的回测框架中,并与backtrader连接起来回测。
我们前面已经完成了数据标注,特征工程,数据集划分,模型准备,训练与评估等等。在测试集上生成pred_score用于排序即可。
01 排序算子
排序算子,就是在候选池或者已选择的标的池里,按某一个因子顺序选择前K个,比如动量从大到小选前2支,或者按机器模型预估的分数值,选前面K支。这个算法类似qlib里的TopK,qlib的更复杂一些,它是针对全市场选股,为了保证流动性,会强调淘汰排名靠后的后5支,但原理是类似的。
class SelectTopK:def __init__(self, K=1, order_by='order_by', b_ascending=False):self.K = Kself.order_by = order_byself.b_ascending = b_ascendingdef __call__(self, context):stra = context['strategy']features = context['features']if self.order_by not in features.columns:logger.error('排序字段{}未计算'.format(self.order_by))returnbar = get_current_bar(context)if bar is None:logger.error('取不到bar')return Truebar.sort_values(self.order_by, ascending=self.b_ascending, inplace=True)selected = []pre_selected = Noneif 'selected' in context:pre_selected = context['selected']del context['selected']# 当前全候选集# 按顺序往下选K个for code in list(bar.code):if pre_selected:if code in pre_selected:selected.append(code)else:selected.append(code)if len(selected) >= self.K:breakcontext['selected'] = selected
主要逻辑的__call__函数中,即每次调用时计算。
1、检查确保order_by这段在数据中。
2、取当前日期的bar,对order_by字段进行排序(默认是升级,可以指定为降序)。
3、若是之前已有筛选子集,则使用这个子集;否则使用整体资产候选池子。
从前往后选K个即止。
02 机器学习计算pred_score
我们的引擎主体有add_features函数,
1、添加给backtrader的大脑。
2、由dataloader自动进行数据特征工程与数据标注。
def add_features(self, symbols, names, fields):# 1.添加数据集,即资产候选集for s in symbols:self.add_data(s)# 2.特征工程self.features = self.loader.load_one_df(symbols, names, fields)
3、我们下一步,进行数据预估。
def add_model(self, model, split_date, feature_names):self.dataset = Dataset(dataloader=self.loader, split_date=split_date, feature_names=feature_names)model.fit(self.dataset)self.features['pred_score'] = model.predict(self.dataset)print(self.features['pred_score'])
使用dataset对dataloader进行包装,可以自动划分时间序列数据集,使用model对数据集进行训练并评分。然后对数据进行预测,生成pred_score列。
后续的训练流程就是一样的了:
e.add_model(SklearnModel(RandomForestRegressor()), split_date='2020-01-01', feature_names=feature_names)

训练集上得分很高,但测试集上分是负的。(明显过拟合了)
使用SelectTopK算子,order_by='pred_score'进行排序。
e.run_algo_strategy([SelectTopK(K=1, order_by='pred_score',b_ascending=False), WeightEqually()]) e.analysis(pyfolio=False)
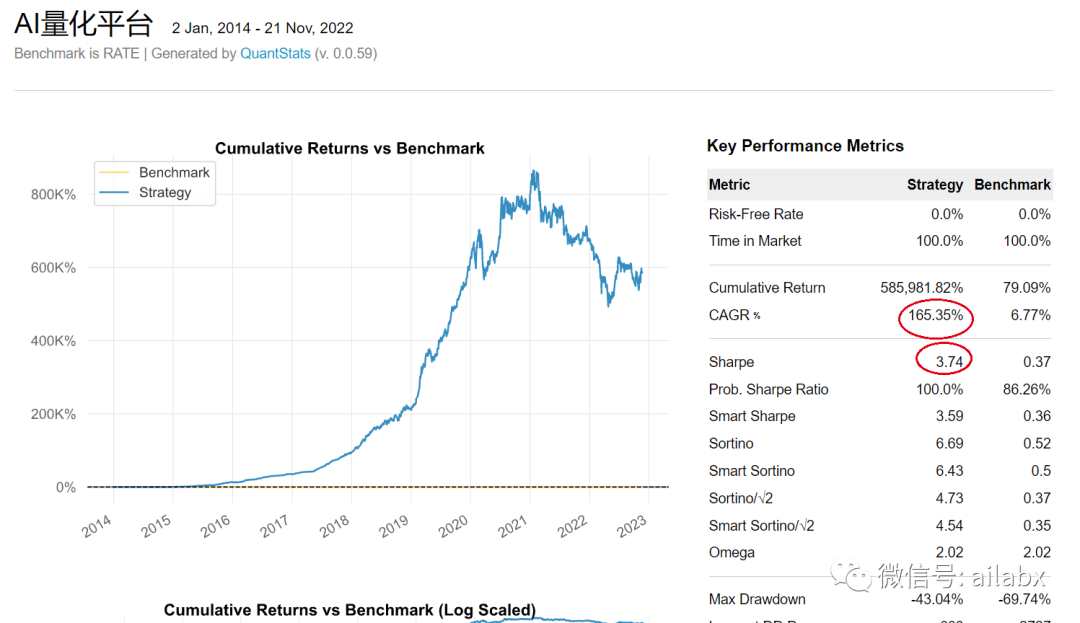
小结:今天把框架流程走通,明天继续优化。
代码与数据已经同步到星球-量化专栏。
ETF轮动+RSRS择时,加上卡曼滤波:年化48.41%,夏普比1.89
金融机器学习:数据集划分与baseline模型
etf动量轮动+大盘择时:年化30%的策略