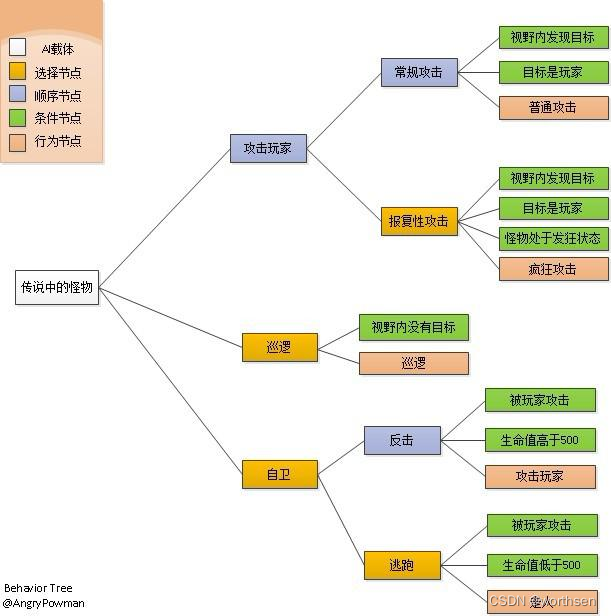
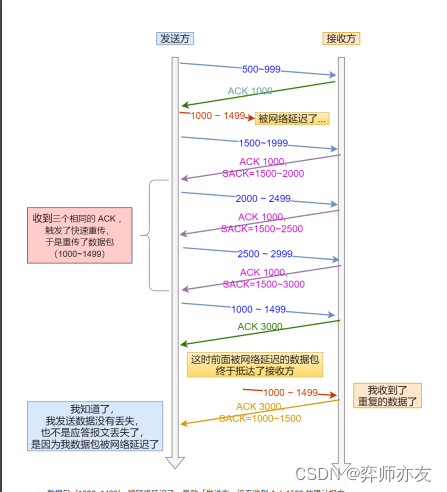
本章学习节点嵌入。这些方法的目标是将节点编码为低维向量,以表示它们的图位置和局部图邻域的结构。换句话说,我们希望将节点投影到一个潜在空间中,其中这个潜在空间中的几何关系对应于原始图或网络中的关系。
几篇文章,强烈建议观看
本章讲的简单图,下一章讲多维度图
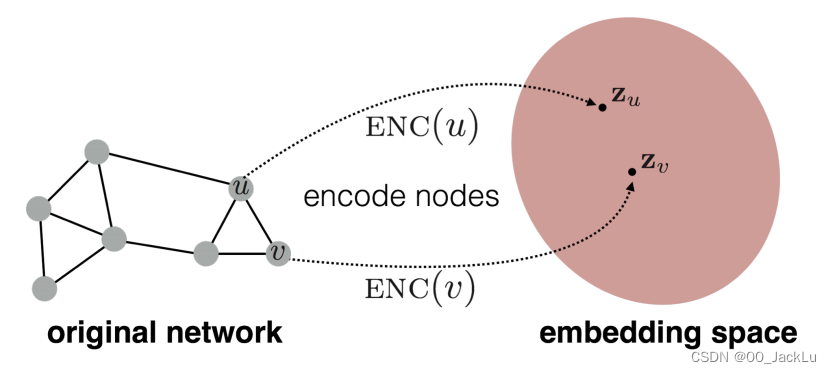
3.1 An Encoder-Decoder Perspective
编码器模型将图中的每个节点映射到一个低维向量或嵌入模型中
解码器模型采用低维节点嵌入,并利用它们来重构原始图中每个节点的邻域信息
3.1.1 The Encoder
编码器是一个函数,把节点映射成向量。
大多是浅嵌入方法(shallow embedding),将节点ID作为输入来产生节点嵌入的方法,它只是一个基于节点ID的简单的嵌入查找。
enc(v)=Z[v]enc(v) = Z[v] enc(v)=Z[v]
Z是矩阵,节点v对应的是Z[v]这一行。
编码器使用节点特征或节点周围的局部图结构作为输入来生成嵌入。这些广义的编码器架构——通常被称为图神经网络(GNNs)——将是本书第二部分的主要焦点
3.1.2 The Decoder
解码器是由编码器生成的节点嵌入进行图的重构。例如,给定一个节点u嵌入节点zu,解码器可能会尝试预测u的邻域集N (u)或图邻接矩阵中的行A[u]。
标准做法是定义成对解码器(pairwise decoder),它可以预测节点间的相似性。将其应用于嵌入数据,可以重建节点u和节点v间的关系,并且最小化损失。
我们假设S[u,v]是一种基于图的节点间的相似性度量。例如,预测两个节点是否是邻居,那么
3.1.3 Optimizing an Encoder-Decoder Model
为了实现重建,需要最小化损失,我们定义了损失和损失函数。
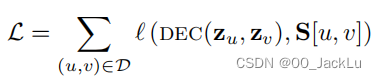
总体目标是训练编码器和解码器,大多数是采用随机梯度下降法,也有其他的方法。
3.1.4 Overview of the Encoder-Decoder Approach

上表是几种著名的节点嵌入方法,这些方法都使用了浅层的编码方法。
编码器-解码器框架的好处是可以让人从以下3点进行模型比较:
- 解码器函数
- 基于图的相似性度量
- 损失函数
3.2 Factorization-based approaches
从节点嵌入中解码局部邻域结构的挑战,与重构图邻接矩阵中的项密切相关。因此,基于因子分解(矩阵分解)的方法主要思想是:使用矩阵分解来学习节点节点相似度矩阵S的低维近似。
(着实看不懂了,继续往后读)
Laplacian eigenmaps
最早也最具有影响力的因子分解方法–拉普拉斯特征映射,在这种方法中,我们根据节点嵌入之间的l2-距离(欧式距离)来定义解码器:
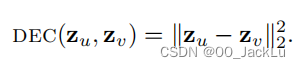
损失函数根据节点在图中的相似性对节点对进行加权:
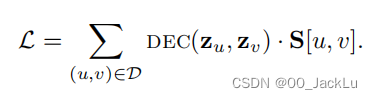
当非常相似的节点有相距很远的嵌入时,损失函数会惩罚模型。
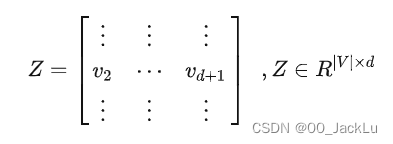
如果构造S矩阵,使其满足Laplacian矩阵的性质,那么,如果zu是d维的,最优解就是图拉普拉斯矩阵最小的d个特征值所对应的特征向量(排除最小的那一个v1),即:
Inner-product methods
内积法,基于内积的解码器(内积一般就是我们所谓的向量点乘 ):
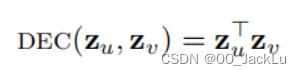
这里假设两个节点之间的相似性——例如,它们的局部邻域之间的重叠——与它们的嵌入的点积成正比。
GF、GraRep和HOPE模型都使用了内积,和均方误差:


不同点在于如何定义节点相似度或邻域重叠S[u,v]S[u, v]S[u,v]
- GF方法使用邻接矩阵并且设S[u,v]=S[u, v]=S[u,v]=A[u,v]A[u, v]A[u,v]
- GraRep:S[u,v]=Ak[u,v]S[u,v]=Ak[u,v]S[u,v]=Ak[u,v]
- HOPE算法支持一般的邻域重叠度量
以上被称为矩阵-因子分解方法,因为它们的损失函数可以用因子分解算法来最小化,如奇异值分解(SVD)。
这一类方法之所以成为因子分解方法,是因为它们的损失函数都可以使用因子分解(SVD等)算法进行最小化。
到底重构了哪一部分呢?就是重构的邻接矩阵A~=ZZT。
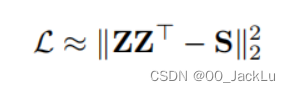
重构的目标也可以重写为矩阵的形式。
直观地说,这些方法的目标是学习每个节点的嵌入,使得学习到的嵌入向量之间的内积可以模拟某种确定的节点相似性度量。
图神经网络由浅入深:基于随机游走的方法(建议观看)
3.3 Random walk embeddings
上一节讨论的内积法确定了节点的相似性度量,它们通常定义为邻接矩阵的多项式函数。随机游走法使用邻域重叠的随机度量改进内积法。此类方法的关键创新在于优化节点嵌入——如果两个节点倾向于在图上的短随机游动(序列)中同时出现,那么这两个节点应该具有相似的嵌入。
DeepWalk and node2vec
Deepwalk和node2vec 也是浅嵌入和内积解码器。这些方法的关键在于它们如何定义节点相似度和邻域重构。和之前的方法不同,这两种是通过优化节点嵌入,来编码随机游走的统计特性的。
学习嵌入以便大致保持:
DEC(zu,zv)≜ezuτzv∑vk∈ezuτzkDEC(z_u,z_v ) \triangleq \frac {e^{z_u\tau z_v}} {\sum_{v_k \in {e^{z_u \tau z_k}}}}DEC(zu,zv)≜∑vk∈ezuτzkezuτzv
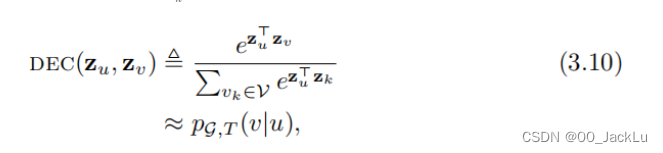
其中,pG,T(v∣u)pG,T(v|u)pG,T(v∣u)是在从u开始的长度-T随机游动上访问v的概率,T通常被定义为在T∈2,...,10T∈{2,...,10}T∈2,...,10的范围内。同样,上式和基于因子分解的方法之间的一个关键区别是,上式中的相似性度量是随机的和不对称的。

D表示随机游走的训练集,从每个节点开始采样随机游走生成的。
如何优化?
直接计算会很昂贵,我们可以发现,最左侧的求和操作是针对全部的节点进行的,而softmax参数化的分母也是针对全部的节点进行的,那就意味着整个式子的计算是∗O(∣D∣∣V∣)∗*O(|D||V|)*∗O(∣D∣∣V∣)∗级别的复杂度,这在图规模较大的情况下是不可接受的。能不能优化呢?首先,最左侧的求和是不可或缺的,因为我们至少得对所有的节点更新一次参数,那么softmax参数化的标准化分母可以优化一下吗?
DeepWalk采用分层softmax来近似方程,用二叉树来加速计算。node2vec用了噪声对比,其中归一化因子以以下方法使用负样本来近似:
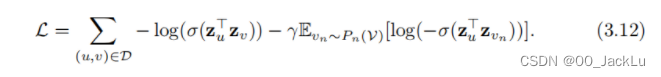
加了后面那一串东西,Pn(V)Pn (V)Pn(V)表示节点V集合上的分布,我们假设γ>0γ > 0γ>0是一个超参数。在实践中,Pn(V)Pn (V)Pn(V)通常被定义为均匀分布,并且期望使用蒙特卡罗抽样来近似。
式子3.12解释
先来看看在一个大规模的,比较均匀的图网络中,假设我们随机选定了一个节点u,那么实际上能够跟这个节点产生关联性的节点其实并不多(即正样本不多),这就意味着拟合过程中的负样本数目极其庞大,而在事实上我们也并没有必要去考虑所有的这些无关联节点,因此,我们就可以通过这些节点进行采样,仅使用一部分负样本来达到我们学习目的,即负采样。
其中,σ\sigmaσ为sigmod函数,nin_ini为从所有节点中采样的随机分布,为什么是所有节点?因为与给定节点实际有关联的节点并不多,所以直接进行随机采样大概率采样到的都是负样本)。至此,我们就通过负采样解决了优化目标的性能问题,能够高效的进行拟合操作了。
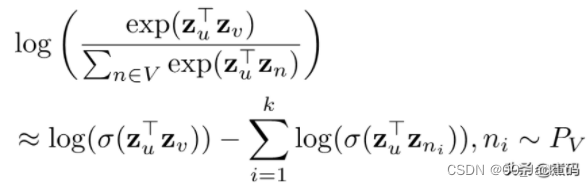
node2vec方法区别于早期的DeepWalk算法,更灵活地定义随机行走。当DeepWalk简单地使用均匀随机行走定义pG,T(v∣u)pG,T(v|u)pG,T(v∣u),node2vec方法引入了超参数,node2vec方法引入了超参数,允许随机行走的概率更接近于图上bfs或dfs的平滑插值。
Large-scale information network embeddings (LINE)
LINE没有明确地利用随机游走,但是它与deepwalk、node2vec共享概念动机。它是结合两个编码器-解码器目标。第一个是编码一阶邻接信息,并使用以下解码器:
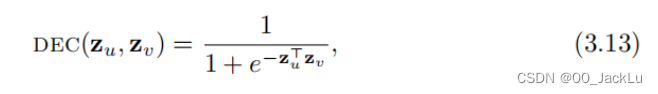
第二个目标是使用KL散度来编码两跳(二阶)邻接信息,和3.10一样的decoder。LINE在概念上与node2vec、DeepWalk相关。它使用了一个概率解码器和概率损失函数(基于kl散度)。和采样随机游走不同的是,它显示的重构了一阶和二阶邻居信息。
Additional variants of the random-walk idea
随机游走的一个优点是它可以通过偏置(bias)或修改随机游走,来进行扩展和修正。“跳过”节点的随机游走,生成类似GraRep。
3.3.1 Random walk methods and matrix factorization
随机游走方法实际上与矩阵分解方法密切相关。
通过DeepWalk学习到的嵌入实际上与本书第一部分中讨论的光谱聚类嵌入密切相关。关键的区别在于,DeepWalk嵌入通过T控制不同特征值的影响,即随机游走的长度。
3.4 Limitations of Shallow Embeddings
浅嵌入方法以前很火,现在大家发现了一些缺陷:
- 浅层嵌入方法在编码器中的节点之间不共享任何参数,导致学习的效率底。缺乏参数共享意味着浅嵌入方法的参数数量必然随着O(|V|)而增加,这在大量图中是难处理。
- 没有利用编码器中的节点特性,会缺失掉很多有用的潜在信息。
- 浅嵌入方法具有内在传导性,只能对训练时就有的节点编码,之后新生成的不行。
为了减轻这些限制,浅层编码器可以被更复杂的编码器所取代,这些编码器更普遍地依赖于图的结构和属性。