yolo系列文章目录
学习视频: YOLOV7改进-添加注意力机制_哔哩哔哩_bilibili
文章目录
- yolo系列文章目录
- 一、SE注意力机制是什么?
- 二、yolov7改进添加SE注意力机制
- 1.首先从github粘贴SE.py
- 2.复制109行的conv
- 3.在sppc加注意力机制
- 三、添加注意力机制在Concat里面
- 总结
yolov7各网络模型的结构图详解:yolov7各网络模型的结构图详解
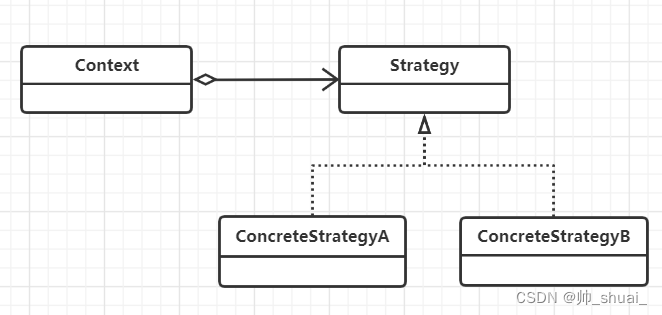
一、SE注意力机制是什么?
简介
SENet是2017年ImageNet比赛的冠军,2018年CVPR引用量第一。论文链接:SENet
较早的将attention引入到CNN中,模块化化设计。
SE模块的目的是想通过一个权重矩阵,从通道域的角度赋予图像不同位置不同的权重,得到更重要的特征信息。
SE模块的主要操作:挤压(Squeeze)、激励(Excitation)
算法流程图:
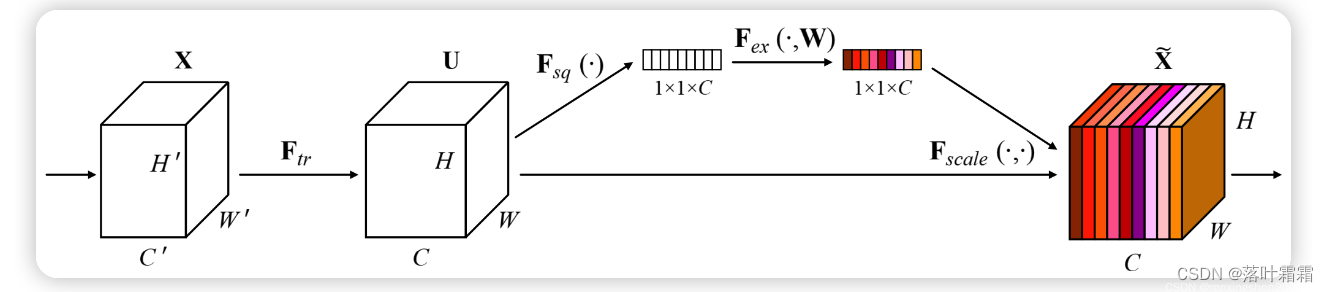
添加注意力机制在卷积里面
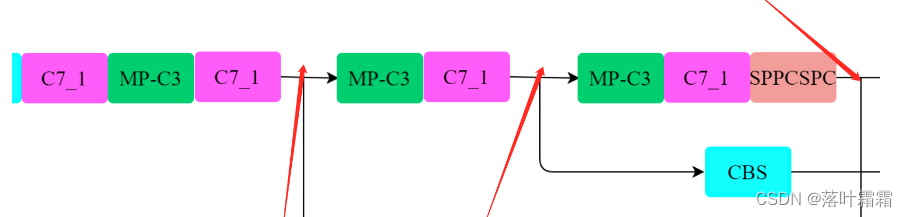
二、yolov7改进添加SE注意力机制
1.首先从github粘贴SE.py
在models里面新建SE.py,粘贴以下代码
import numpy as np
import torch
from torch import nn
from torch.nn import initclass SEAttention(nn.Module):def __init__(self, channel=512,reduction=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
2.复制109行的conv
class Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper(Conv, self).__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))def fuseforward(self, x):return self.act(self.conv(x))
粘贴如下
from models.SE import SEAttention
class Conv_ATT(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper(Conv_ATT, self).__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())self.att =SEAttention(c2)def forward(self, x):return self.att(self.act(self.bn(self.conv(x))))def fuseforward(self, x):return self.att(self.act(self.conv(x)))
然后在
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
添加定义的con_att
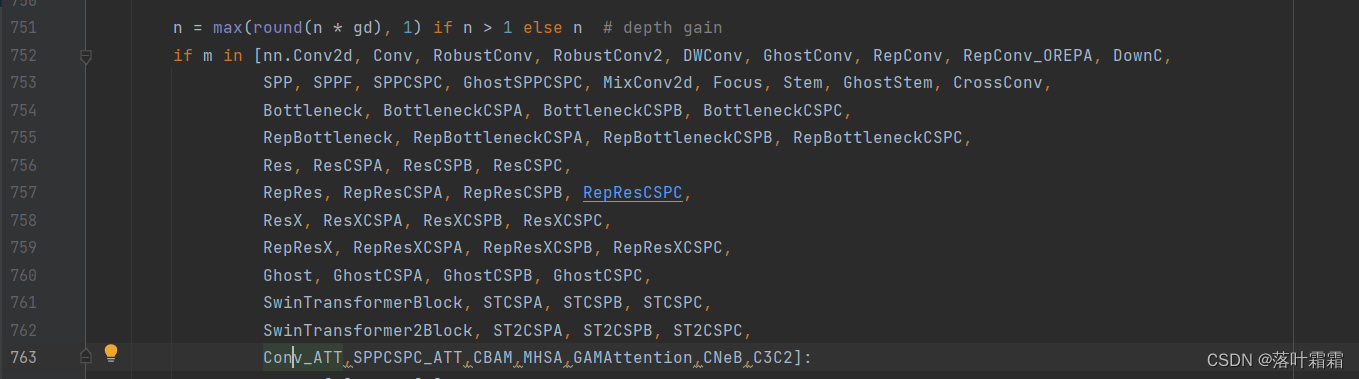
然后就是yaml配置文件,
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2 [-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, Conv, [64, 1, 1]],[-2, 1, Conv, [64, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 11[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8 [-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv_ATT, [512, 1, 1]], # 24[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]], # 29-P4/16 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv_ATT, [1024, 1, 1]], # 37[-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]], # 42-P5/32 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 50]# yolov7 head
head:[[-1, 1, SPPCSPC, [512]], # 51[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, Conv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, Conv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[75, 1, RepConv, [256, 3, 1]],[88, 1, RepConv, [512, 3, 1]],[101, 1, RepConv, [1024, 3, 1]],[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]3.在sppc加注意力机制
需要在models里面的common.py
按住ctrl+f,搜索sppcspc,
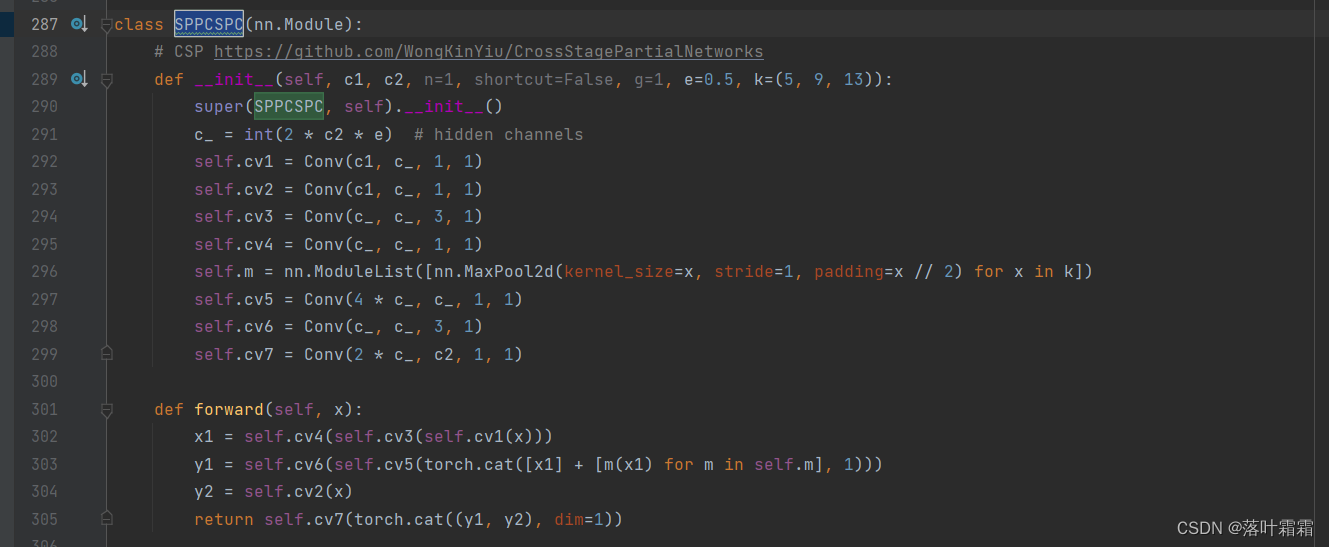
复制粘贴如下:
class SPPCSPC_ATT(nn.Module):# CSP https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):super(SPPCSPC_ATT, self).__init__()c_ = int(2 * c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(c_, c_, 3, 1)self.cv4 = Conv(c_, c_, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])self.cv5 = Conv(4 * c_, c_, 1, 1)self.cv6 = Conv(c_, c_, 3, 1)self.cv7 = Conv(2 * c_, c2, 1, 1)self.att = SEAttention(c2)def forward(self, x):x1 = self.cv4(self.cv3(self.cv1(x)))y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))y2 = self.cv2(x)return self.att(self.cv7(torch.cat((y1, y2), dim=1)))
这里self.att = SEAttention(c2),c2是通道数,如果是SimAM这种不需要通道数的,就用空括号,不写c2,各个注意力机制的通道数链接:各个注意力机制的通道数
同理在加入sppcspc_att,
修改配置文件
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2 [-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, Conv, [64, 1, 1]],[-2, 1, Conv, [64, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 11[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8 [-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv_ATT, [512, 1, 1]], # 24[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]], # 29-P4/16 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv_ATT, [1024, 1, 1]], # 37[-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]], # 42-P5/32 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 50]# yolov7 head
head:[[-1, 1, SPPCSPC_ATT, [512]], # 51[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, Conv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, Conv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[75, 1, RepConv, [256, 3, 1]],[88, 1, RepConv, [512, 3, 1]],[101, 1, RepConv, [1024, 3, 1]],[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]三、添加注意力机制在Concat里面
同样的道理,与添加1的前面步骤一样。
复制代码前40行,在models文件夹下新建SE.py文件,粘贴进去。
对models文件夹下的common.py文件进行修改,在前面导入SE。
在modles文件夹中找到common.py文件的class Concat类,
在这类下面加上如下代码
class Concat_ATT(nn.Module):def __init__(self, channel, dimension=1):super(Concat_ATT, self).__init__()self.d = dimensionself.att = SEAttention(channel)def forward(self, x):return self.att(torch.cat(x, self.d))
后在models文件夹下的yolo.py文件中找到elif m is Concat:
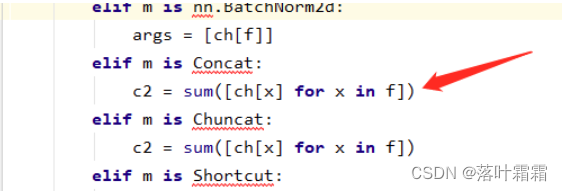
在箭头所指这行下面 加入
elif m is Concat_ATT:c2 = sum([ch[x] for x in f])args = [c2]
然后修改yolov7.yaml文件中的头部,将四个Concat都改成Concat_ATT,就可以进行训练。
总结
根据自己的需要修改对应的yaml文件即可验证实现不同的注意力机制效果。