文章目录
- 批作业调度算法
- 调度的基本准则与方式
- 基本准则
- 方式
- 常用的作业调度算法:
- 先来先服务FCF
- 最短作业优先SJFS
- 高相应比优先HRRF
- 时间片轮转
- 多级反馈队列
批作业调度算法
调度的基本准则与方式
基本准则
- CPU 利用率
- 系统吞吐量
- (★★★)周转时间
- 周转时间=作业完成时间−提交时间作业完成时间-提交时间作业完成时间−提交时间
- 平均周转时间=作业1周转时间+⋯+作业n周转时间n\frac{作业1周转时间+⋯+作业n周转时间}{n}n作业1周转时间+⋯+作业n周转时间
- 带权周转时间=作业周转时间作业实际运行时间\frac{作业周转时间作业}{实际运行时间}实际运行时间作业周转时间作业
- 平均带权周转时间=作业1带权周转时间+⋯+作业n带权周转时间n\frac{作业1带权周转时间+⋯+作业n带权周转时间}{n}n作业1带权周转时间+⋯+作业n带权周转时间
- 等待时间
- 响应时间
方式
- 非剥夺调度方式(非抢占式)
- 剥夺调度方式(抢占式)
常用的作业调度算法:
作业周转时间 = 完成时间 - 提交时间
作业的带权周转时间 = 作业的周转时间 / 运行时间
平均周转时间 = 各作业的带权周转时间之和 / 作业数目
先来先服务FCF
-
先来先服务算法(First Come Serve , FCFS)
是按作业进入系统的先后次序进行调度,即每次调度都在后备作业队列选择一个最先进入队列的作业
特点:实现简单,有利于长作业,不利于短作业,有利于 CPU 繁忙型作业,不利于 I/O 繁忙型作业
示例:
起始:
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | ||||
| J2 | 8:50 | 30 | ||||
| J3 | 9:00 | 12 | ||||
| J4 | 9:10 | 6 |
第一轮:
-
先选择先来的,即先提交的 J1 :8:00 ,将其作为第一个开始的,由于他前面没有等待队列,所以它的开始时间为:
8:00。 -
结束时间为开始时间加上运行时间:
8:00 + 60min = 9:00 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:00-8:00= 60min -
带权周转时间 : 作业的周转时间 / 运行时间 =
60/60= 1
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | ||||
| J3 | 9:00 | 12 | ||||
| J4 | 9:10 | 6 |
第二轮:
-
由于按照先来先选择的算法,选l择第二的, J1 :8:50 ,将其作为第二,由于他还需要等待他前面的完成了才到他,所以它的开始时间为:
9:00。 -
结束时间为:开始时间 + 运行时间 =
9:00 + 30min = 9:30 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:30-8:50= 40min -
带权周转时间 : 作业的周转时间 / 运行时间 =
40/30= 4/3
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:30 | 40 | 4/3 |
| J3 | 9:00 | 12 | ||||
| J4 | 9:10 | 6 |
剩下的以此类推。。。
最终为:
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:30 | 40 | 4/3 |
| J3 | 9:00 | 12 | 9:30 | 9:42 | 42 | 21/6 |
| J4 | 9:10 | 6 | 9:42 | 9:48 | 38 | 19/3 |
平均周转时间 = 各作业的带权周转时间之和 / 作业数目
= (1+4/3+21/6+19/)/4 ≈ 3.0417
最短作业优先SJFS
-
最短作业优先(Shortest Job First SJF)
从后备队列中选择估计运行时间最短的作业
特点:克服了FCFS 偏爱长作业的缺点,易于实现,会使系统平局周转时间最短,系统吞吐量大;
缺点是:
**1)需要预先知道作业所需的CPU时间 **
**2)对长作业不利,忽视了作业等待时间,容易出现饥饿现象 **
**3)未考虑作业的紧迫程度 **
示例:
起始:
作业 提交时间 运行时间(min) 开始时间 结束时间 周转时间 Ti /min 带权周转时间 Wi /min J1 8:00 60 J2 8:50 30 J3 9:00 12 J4 9:10 6
第一轮:
-
由于J1是最先来的,此时没有别的等待队列,故先进行J1 ,所以它的开始时间为:
8:00。 -
结束时间为:开始时间 + 运行时间 =
8:00 + 60min = 9:00 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:00-8:00= 60min -
带权周转时间 : 作业的周转时间 / 运行时间 =
60/60= 1
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | ||||
| J3 | 9:00 | 12 | ||||
| J4 | 9:10 | 6 |
第二轮:
-
选取在第一轮执行结束之后的时间之前
9:00提前的作业中运行时间最低段的作为第二轮作业,即:在J2:8:50与J3:9:00中选取运行时间最短的,即J3.所以第二轮的开始时间为:9:00。 -
结束时间为:开始时间 + 运行时间 =
9:00 + 12min = 9:12 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:12-9:00= 12min -
带权周转时间 : 作业的周转时间 / 运行时间 =
12/12= 1
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:12 | 12 | 1 |
| J3 | 9:00 | 12 | ||||
| J4 | 9:10 | 6 |
第三轮:
-
选取在第二轮执行结束之后的时间之前
9:12提前的作业中运行时间最低段的作为第二轮作业,即:在J2:8:50与J4:9:10中选取运行时间最短的,即J4.所以第二轮的开始时间为:9:12。 -
结束时间为:开始时间 + 运行时间 =
9:12 + 6min = 9:18 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:18-9:10= 8min -
带权周转时间 : 作业的周转时间 / 运行时间 =
8/6= 4/3
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | ||||
| J3 | 9:00 | 12 | 9:00 | 9:12 | 12 | 1 |
| J4 | 9:10 | 6 | 9:12 | 9:18 | 8 | 4/3 |
同理可得第四轮结果为:
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 1 |
| J2 | 8:50 | 30 | 9:18 | 9:48 | 58 | 29/15 |
| J3 | 9:00 | 12 | 9:00 | 9:12 | 12 | 1 |
| J4 | 9:10 | 6 | 9:12 | 9:18 | 8 | 4/3 |
平均周转时间 = 各作业的带权周转时间之和 / 作业数目
= (1+29/15+1+4/3)/4 ≈ 1.3167
高相应比优先HRRF
-
响应比高者优先算法(Highest Response Ratio First ,HRRF)
计算后备作业队列中每个作业的响应比,然后挑选响应比最高者,保证紧迫性作业优先
其中响应比计算公式为:作业的响应时间作业的运行时间\frac {作业的响应时间}{作业的运行时间}作业的运行时间作业的响应时间 = 作业的等待时间+作业的运行时间作业的运行时间\frac {作业的等待时间+作业的运行时间}{作业的运行时间}作业的运行时间作业的等待时间+作业的运行时间= 1+ 作业的等待时间作业的运行时间\frac {作业的等待时间}{作业的运行时间}作业的运行时间作业的等待时间
特点:
- 作业等待时间相同,要求服务时间越短,响应比越高,有利于短作业
- 要求服务时间相同,作业的响应比由其等待时间确定,等待时间越长,其响应比越高。因而实现了先来先服务
- 对于长作业,作业的响应比随等待时间的增加而提高,等待时间足够长时,响应比便可升到很高,从而也可获得处理机。因此,克服了饥饿状态,兼顾了长作业。
示例:
起始:
作业 提交时间 运行时间(min) 开始时间 结束时间 周转时间 Ti /min 带权周转时间 Wi /min J1 8:00 60 J2 8:50 30 J3 9:00 12 J4 9:10 6 第一轮:
-
首先还是一样的先执行第一个提交的作业J1,所以提交时间时间即为运行时间:
8:00, -
结束时间为:开始时间 + 运行时间 =
8:00 + 60min = 9:00
-
周转时间为:完成时间(结束时间) - 提交时间 =
9:00-8:00= 60min -
带权周转时间 : 作业的周转时间 / 运行时间 =
60/60= 1 -
更新第一轮结束时间之前提交的作业的等待时间。
显然,满足条件(在结束时间9:00之前提交作业的)有J2,J3
等待时间为:
上个作业结束时间-该作业提交时间 显然,J1 = 0
J2 = 9:00 - 8:50 = 10
J3 = 9:00 - 9:00 = 0
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 等待时间/min | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 0 | 60 | 1 |
| J2 | 8:50 | 30 | 10 | ||||
| J3 | 9:00 | 12 | 0 | ||||
| J4 | 9:10 | 6 |
第二轮:
-
首先在满足条件(在第一轮完成时间之前提交的作业)中选取响应比最大的作为第二轮作业任务
- J2 = 1 + 10/30
- J3 = 1 + 0/12
显然,响应比:J2 > J3
因此选取J2作为第二轮的任务,其开始时间为
第一轮结束时间:9:00 -
结束时间为:开始时间 + 运行时间 =
9:00 + 30min = 9:30 -
周转时间为:完成时间(结束时间) - 提交时间 =
8:50-9:30= 40min -
带权周转时间 : 作业的周转时间 / 运行时间 =
40/30= 4/3 -
更新第二轮结束时间之前提交的作业的等待时间。
显然,满足条件(在结束时间9:30之前提交作业的)有J3,J4
等待时间为:
上个作业结束时间-该作业提交时间 J3 = 9:30 - 9:00 = 30
J4 = 9:30 - 9:10 = 20
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 等待时间/min | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 0 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:30 | 10 | 40 | 4/3 |
| J3 | 9:00 | 12 | 30 | ||||
| J4 | 9:10 | 6 | 20 |
第三轮:
-
首先在满足条件(在第二轮完成时间之前提交的作业)中选取响应比最大的作为第二轮作业任务
- J3 = 1 + 30/12
- J4 = 1 + 20/6
显然,响应比:J4 > J3
因此选取J4作为第三轮的任务,其开始时间为
第二轮结束时间:9:30 -
结束时间为:开始时间 + 运行时间 =
9:30 + 6min = 9:36 -
周转时间为:完成时间(结束时间) - 提交时间 =
9:36-9:10= 26min -
带权周转时间 : 作业的周转时间 / 运行时间 =
26/6= 13/3 -
更新第二轮结束时间之前提交的作业的等待时间。
显然,满足条件(在结束时间9:36之前提交作业的)有J3
等待时间为:
上个作业结束时间-该作业提交时间 J3 = 9:36 - 9:00 = 36
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 等待时间/min | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 0 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:30 | 10 | 40 | 4/3 |
| J3 | 9:00 | 12 | 36 | ||||
| J4 | 9:10 | 6 | 9:30 | 9:36 | 20 | 26 | 13/3 |
同理可得第四轮结果:
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 等待时间/min | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:00 | 0 | 60 | 1 |
| J2 | 8:50 | 30 | 9:00 | 9:30 | 10 | 40 | 4/3 |
| J3 | 9:00 | 12 | 9:36 | 9:48 | 36 | 48 | 4 |
| J4 | 9:10 | 6 | 9:30 | 9:36 | 20 | 26 | 13/3 |
平均周转时间 = 各作业的带权周转时间之和 / 作业数目
= (1+4/3+4+13/3)/4 ≈ 2.6667
并且不难看出,响应比高者优先算法的效率是介于最短作业优先,来先服务算法
时间片轮转
- 时间片轮转算法: 先来先服务,但仅能运行一个时间片。
特点:若一个时间片未完成,剥夺该进程处理机,并将这个进程挂到就绪队列末尾,将处理机分配给当前就绪队列的第一个进程。
示例:
起始
| 作业 | 提交时间 | 运行时间(min) | 开始时间 | 结束时间 | 周转时间 Ti /min | 带权周转时间 Wi /min |
|---|---|---|---|---|---|---|
| J1 | 8:00 | 60 | 8:00 | 9:10 | 70 | 7/6 |
| J2 | 8:50 | 30 | 8:50 | 9:48 | 58 | 29/15 |
| J3 | 9:00 | 12 | 9:10 | 9:38 | 38 | 19/6 |
| J4 | 9:10 | 6 | 9:30 | 9:36 | 26 | 13/3 |
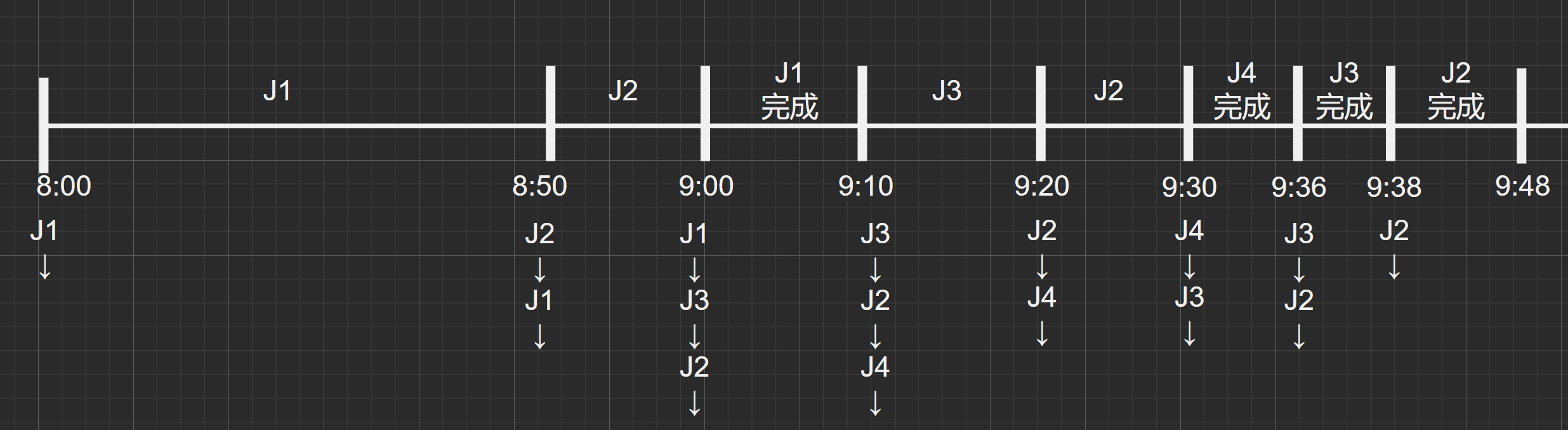
第一轮:因为刚开始8:00时刻后备队列中只有J1作业因此选择J1,且到之后的J2入队列时的8:50之前都在运行J1。因此J1的开始时间为8:00,J2的开始时间为8:50
第二轮:当J2从8:50运行完一个时间片之后,到了9:00J3进入后备队列队尾,然后J2运行完也插入队尾(这里假设若当进程运行完一个时间同时有新作业提交则新作业先插入队尾)。此时队列从头到尾的顺序依次为J1->J3->J2 ,选取队头元素J1继续运行一个时间片。
第三轮:当J1执行完一个时间片之后,作业便执行结束,时间为9:10 然后J4作业插入后被队列队尾,此时后备队列顺序为J3->J2->J4 ,选取队头元素J3继续运行一个时间片。。
后续分析如法炮制。。
多级反馈队列
- 多级反馈队列:时间片轮转和优先级调度,多个队列,优先级不同,时间片也不同。
特点:
- 总的来说,优先级越高的队列越先执行,但其时间片越短。
- 一个时间片未完成,降优先级
- 一个优先级队列都运行完后,才能运行下一个
- 若有高优先级来,则抢占资源
融合了前几种算法的优点