文章目录
- 1.Canal简介
- 1.1 MySQL主备复制原理
- 1.2 canal工作原理
- 2.开启MySQL Binlog
- 3.安装Canal
- 3.1 下载Canal
- 3.2 修改配置文件
- 3.3 启动和关闭
- 4.SpringCloud集成Canal
- 4.1 Canal数据结构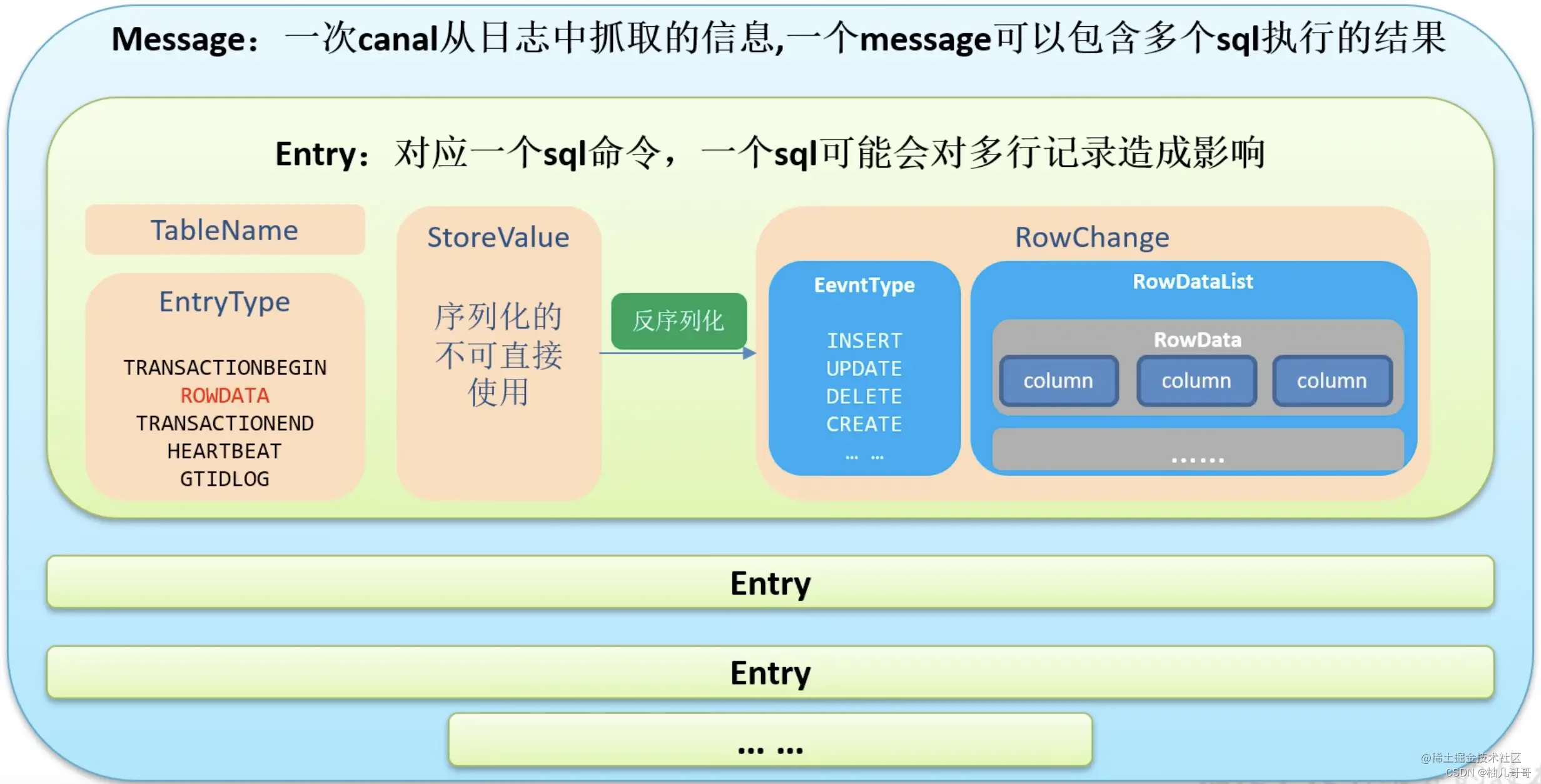
- 4.2 引入依赖
- 4.3 配置多个数据同步的目的地
- 4.4 application.yml
- 4.5 监听配置
- 4.5 监听配置
- 4.5.1 监听测试类
- 4.5.2 redis数据同步
- 4.5.3 Elasticsearch数据同步
- 4.5.4 Es Api 封装业务类 EsApiService
- 4.6 canal日志
- 4.7 第二种方案(解决数据库存在下划线,用上述方法,某些字段会为空)
- 4.7.1 引入依赖
- 4.7.2 创建监听
- 4.7.3 实体类
- 4.8 canal整合异常问题排查思路
- 4.8.1 无法正常启动
- 4.8.2 使用canal监听数据 启动成功了 没有报错 不过一直监听不到消息
1.Canal简介
官网
https://github.com/alibaba/canal
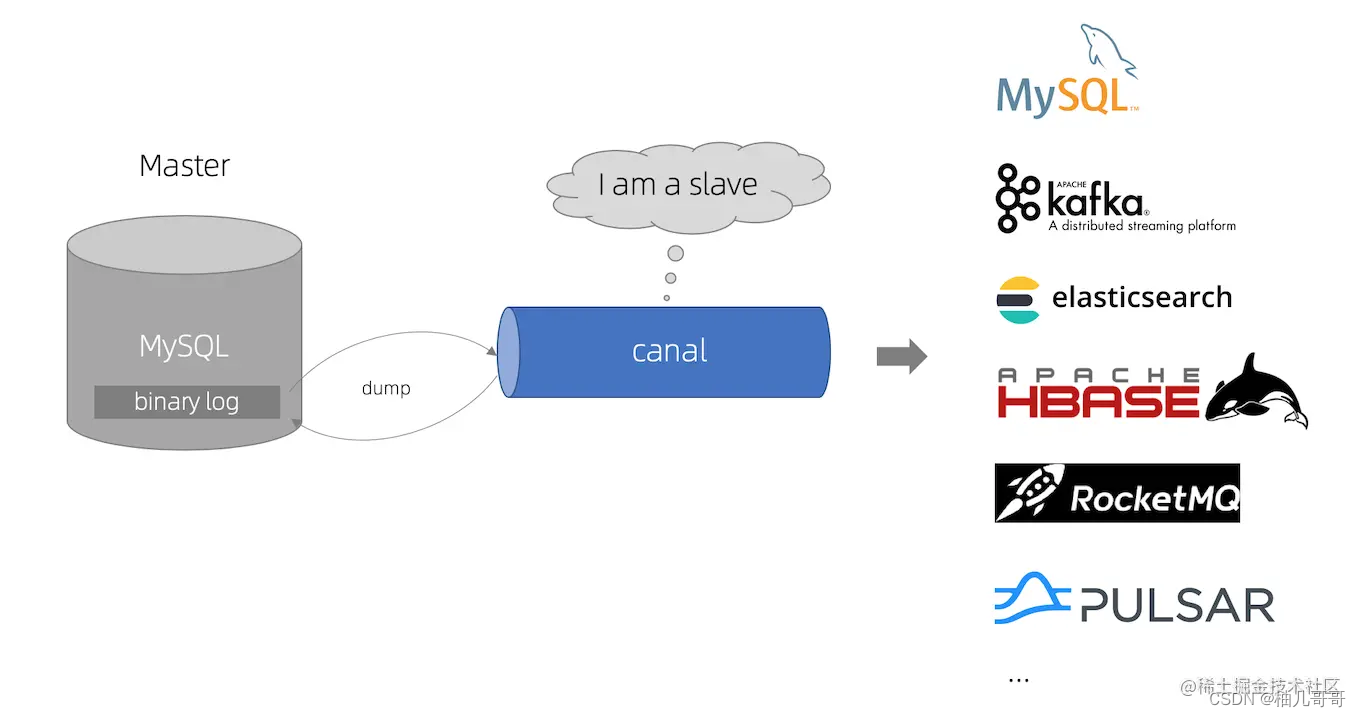

canal [kə’næl] ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.1 MySQL主备复制原理
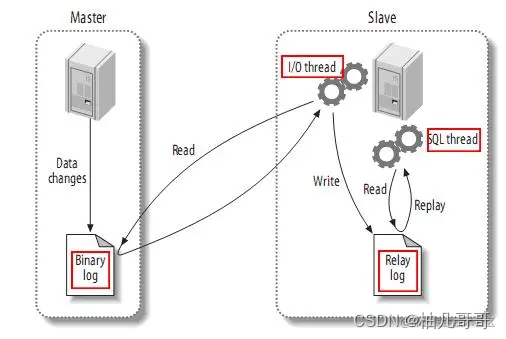
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
1.2 canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
2.开启MySQL Binlog
对于自建 MySQL , 需要先开启 Binlog 写入功能,
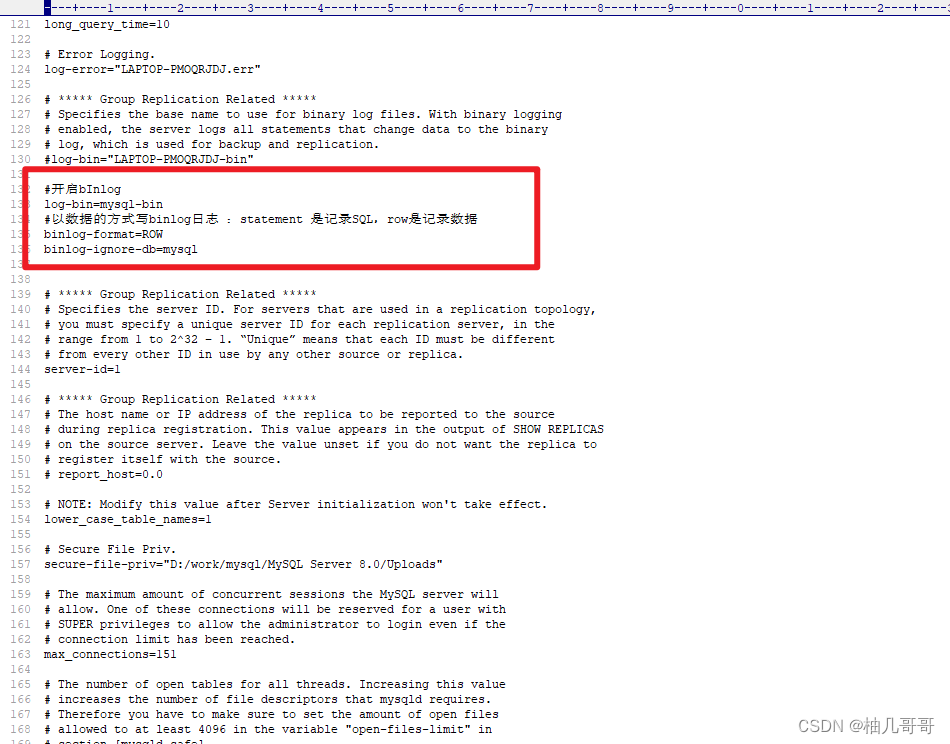
配置 binlog-format 为 ROW 模式,这里以mysql8.0.27为例,my.cnf 中配置如下
#开启bInlog
log-bin=mysql-bin
#以数据的方式写binlog日志 :statement 是记录SQL,row是记录数据
binlog-format=ROW
binlog-ignore-db=mysql
修改后,重启mysql服务。
- 创建cannal
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限,
flush privileges;
#创建用户cannal
CREATE USER canal IDENTIFIED BY 'canal';
#把所有权限赋予canal,密码也是canal
GRANT ALL PRIVILEGES ON canaldb.user TO 'canal'@'%' identified by "canal";
//GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' identified by "canal";
#刷新权限
flush privileges;如果已有账户可直接 grant
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; #更新一下用户密码
FLUSH PRIVILEGES; #刷新权限
通过以下命令,可以查看mysql用户信息
#查看所有数据库
show databases;
#使用mysql数据库
use mysql;
#查看当前库下所有表
show tables;
#查看user表
select Host, User from user;
3.安装Canal
3.1 下载Canal
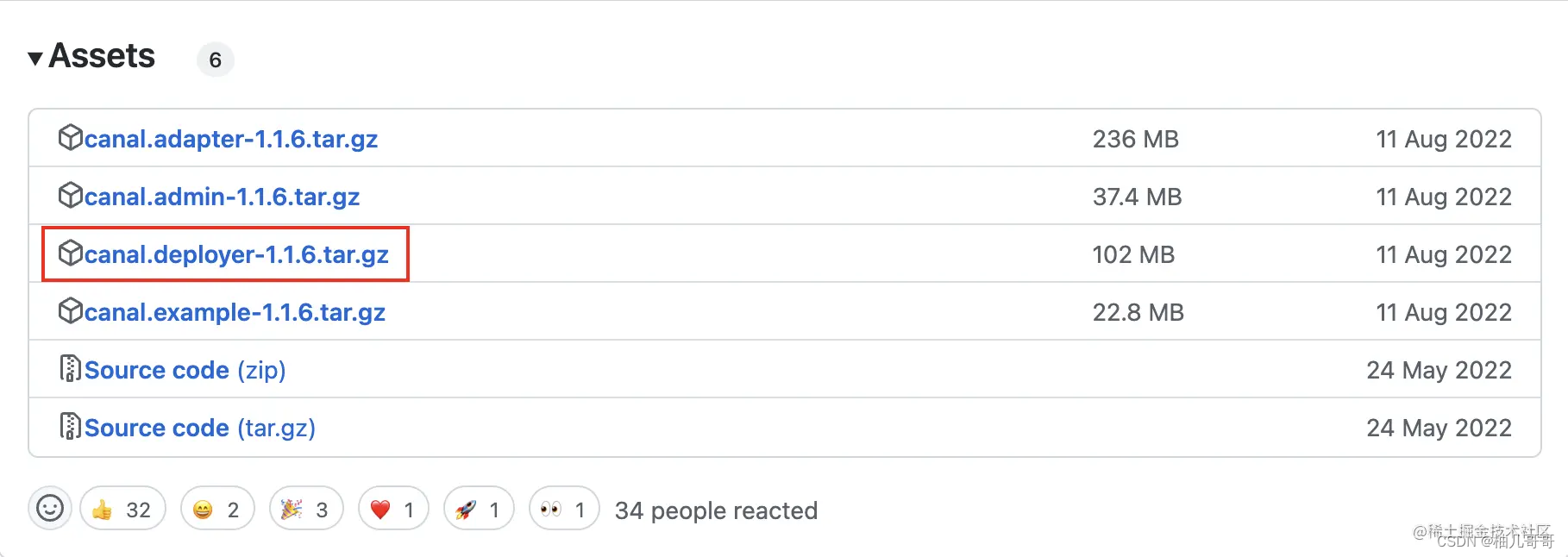
点击下载地址,选择版本后点击canal.deployer文件下载
https://github.com/alibaba/canal/releases
3.2 修改配置文件
打开目录下conf/example/instance.properties文件,主要修改以下内容
## mysql serverId,不要和 mysql 的 server_id 重复
canal.instance.mysql.slaveId = 10
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
#username/password,需要改成自己的数据库信息,与刚才添加的用户保持一致
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
复制代码
3.3 启动和关闭
#进入文件目录下的bin文件夹
#Linux启动
sh startup.sh
##Linux关闭
sh stop.sh
#Windows启动
双击 startup.bat
4.SpringCloud集成Canal
4.1 Canal数据结构
4.2 引入依赖
父工程规定版本,子工程引用
<!-- 统一管理jar包版本 --><properties><canal.version>1.2.1-RELEASE</canal.version></properties><!-- 子模块继承之后,提供作用:锁定版本+了modlue不用写groupId和version --><dependencyManagement><dependencies><!--Canal 依赖--><dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>${canal.version}</version></dependency></dependencies></dependencyManagement>
4.3 配置多个数据同步的目的地
由于我们这里是多个服务对应同一个canal端,则需要配置多个数据同步的目的地
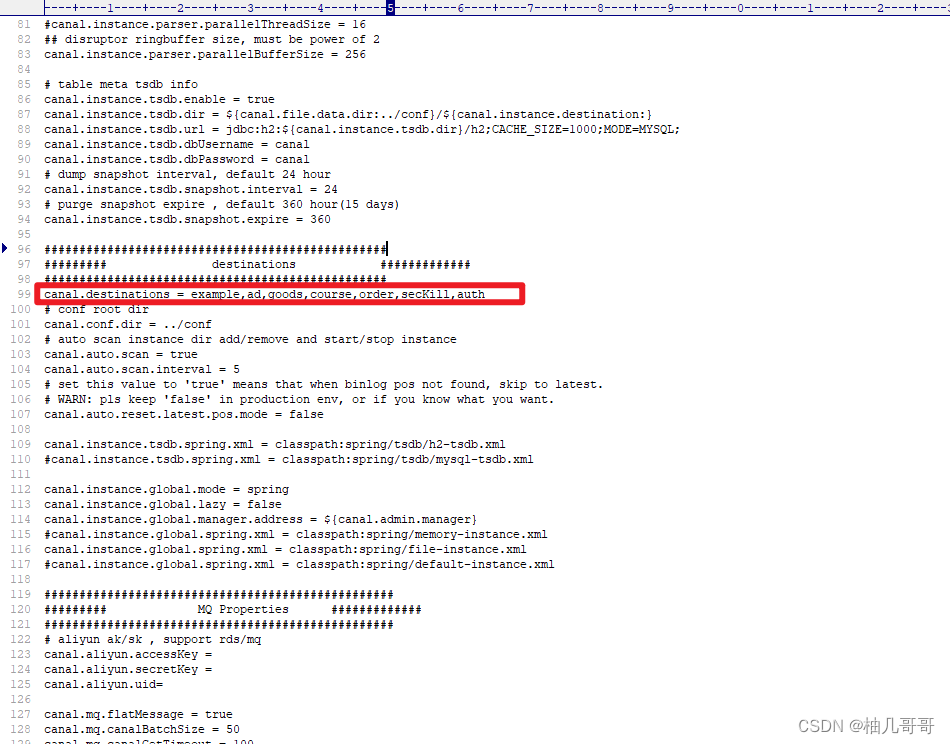
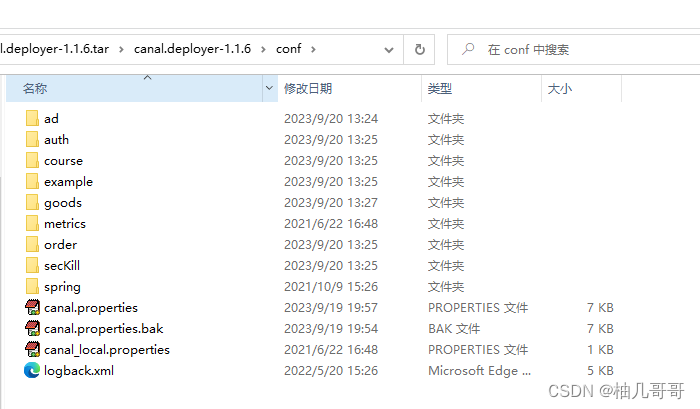
在canal的安装目录下打开canal.deployer-1.1.6\conf\canal.properties文件
在canal.destinations = example后面添加多个数据目录,用逗号分割,一个服务对应一个目录,这里默认只有一个example
#################################################
######### destinations #############
#################################################
canal.destinations = example,ad,goods,course,order,secKill,auth
配置好后,重启canal服务
之后会看到会看到canal/conf目录下新增了这些数据目录的文件夹
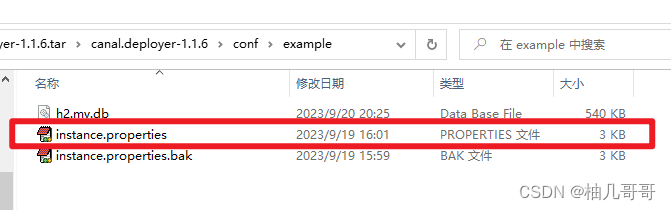
我们需要将默认的example文件夹中的instance.properties配置文件复制到新创建的自定义数据目录中
4.4 application.yml
canal:#canal的地址server: 127.0.0.1:11111 #数据同步的目的地destination: goods
4.5 监听配置
去实现EntryHandler接口,添加自己的业务逻辑,比如缓存的删除更新插入,实现对增删改查的逻辑重写。
4.5 监听配置
去实现EntryHandler接口,添加自己的业务逻辑,比如缓存的删除更新插入,实现对增删改查的逻辑重写。
canal-client提供了EntryHandler,该handler中提供了insert,delete,update方法,当监听到某张表的相关操作后,会回调对应的方法把数据传递进来,我们就可以拿到数据往Redis同步了。
- @CanalTable(“employee”) :监听的表
EntryHandler<Employee>: 拿到employee表的改变后的数据之后,会封装为Employee实体 投递给我们
4.5.1 监听测试类
@CanalTable("test")
@Component
@Slf4j
public class TestHandler implements EntryHandler<Test> {@Resourceprivate RedisService redisService;@Overridepublic void insert(Test test) {log.info("新增Test:"+test);}@Overridepublic void delete(Test test) {log.debug("删除Test:"+test);}@Overridepublic void update(Test before, Test after) {log.info("修改前Test:"+before);log.info("修改后Test:"+after);}}
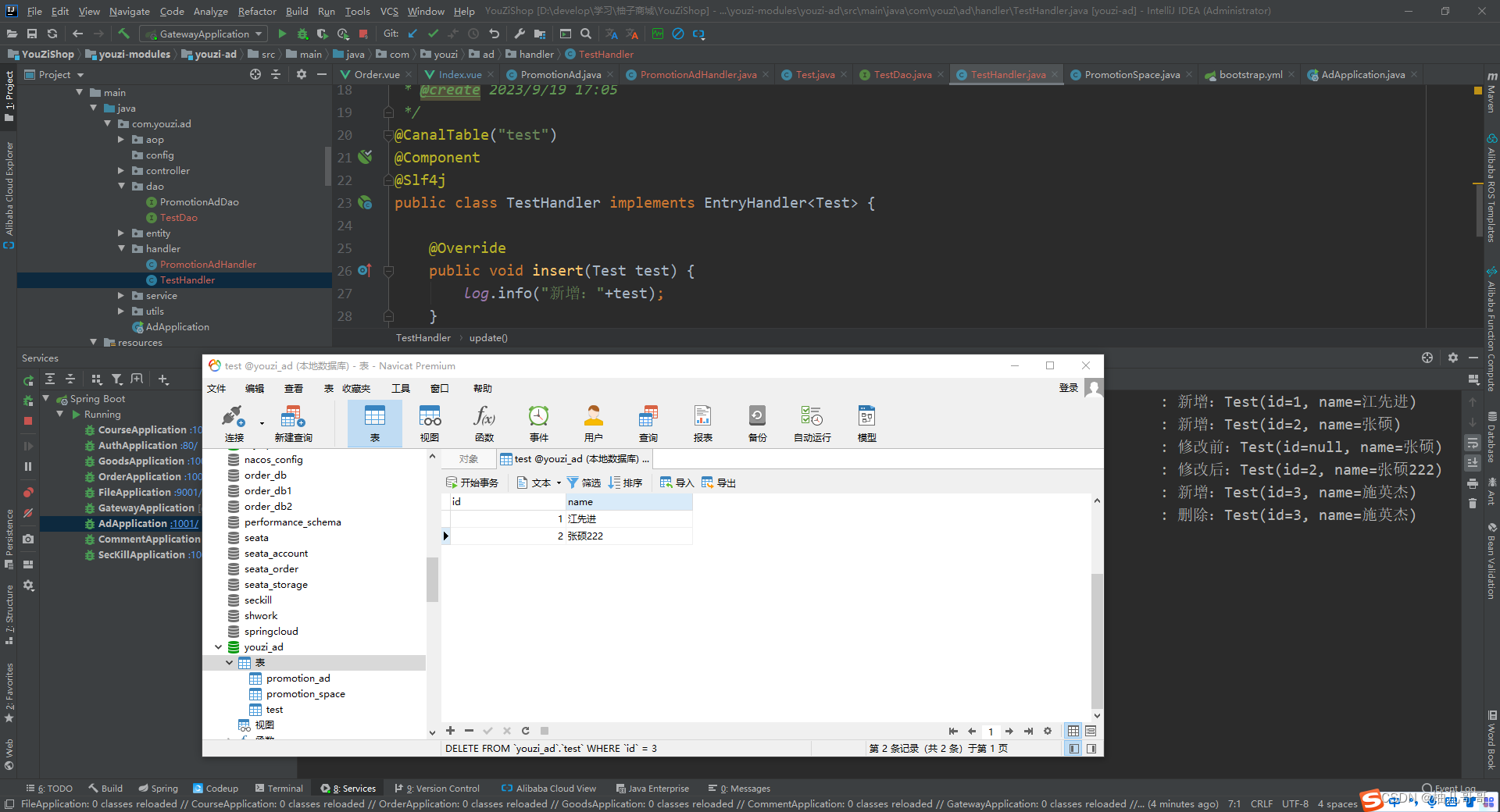
通过日志可以看到我们在navicat中对test这张表的增删改操作均被监听到了
4.5.2 redis数据同步
@CanalTable("employee")
@Component
@Slf4j
public class EmployeeHandler implements EntryHandler<Employee> {//把数据往Redis同步@Autowiredprivate RedisTemplate<Object,Object> redisTemplate;@Overridepublic void insert(Employee employee) {redisTemplate.opsForValue().set("EMP:"+employee.getId(),employee);}@Overridepublic void delete(Employee employee) {redisTemplate.delete("EMP:"+employee.getId());}@Overridepublic void update(Employee before, Employee after) {redisTemplate.opsForValue().set("EMP:"+after.getId(),after);}
}4.5.3 Elasticsearch数据同步
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;@CanalTable("t_goods")
@Component
@Slf4j
public class GoodsHanlder implements EntryHandler<Goods> {@Resourceprivate EsApiService esApiService;@Resourceprivate GoodsService goodsService;/*** 新增商品后同步es* @param goods*/@SneakyThrows@Overridepublic void insert(Goods goods) {log.info("新增:" + goods);goods = goodsService.getById(goods.getId());//同步至estry {esApiService.bulkRequest(EsConst.GOODS,goods);}catch (Exception e){log.error("同步es失败:"+e.getMessage());}}/*** 更新商品后同步es* @param before* @param after*/@SneakyThrows@Overridepublic void update(Goods before, Goods after) {log.info("修改前:" + before);log.info("修改后:" + after);after = goodsService.getById(after.getId());//同步至esesApiService.updateDocument(EsConst.GOODS,String.valueOf(after.getId()),after);}/*** 删除商品后同步es* @param goods*/@SneakyThrows@Overridepublic void delete(Goods goods) {log.info("删除:" + goods);//同步至esesApiService.deleteDocument(EsConst.GOODS,String.valueOf(goods.getId()));}
}4.5.4 Es Api 封装业务类 EsApiService
package com.youzi.elasticsearch.service;import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;import java.io.IOException;
import java.util.List;/*** EsService : es API封装类** @author zyw* @create 2023/9/19 17:31*/
@Component
@Slf4j
public class EsApiService {@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;/*** 更新文档信息* @param index 索引名称* @param id id* @param data 更新的对象* @return* @throws IOException*/public boolean updateDocument(String index, String id,Object data) throws IOException {UpdateRequest request = new UpdateRequest(index, id);request.id("1");request.timeout(TimeValue.timeValueSeconds(1));request.doc(JSON.toJSONString(data), XContentType.JSON);UpdateResponse update = client.update(request, RequestOptions.DEFAULT);log.info("更新文档信息:" + update);return true;}/*** 插入单个** @param index 索引名称* @param data 批量新增的对象* @return* @throws IOException*/public boolean bulkRequest(String index, Object data) throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");//批处理请求bulkRequest.add(new IndexRequest(index).source(JSON.toJSONString(data), XContentType.JSON));BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);return bulk.hasFailures();}/*** 批量插入** @param index 索引名称* @param list 批量新增的对象集合* @return* @throws IOException*/public boolean bulkRequest(String index, List<Object> list) throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");//批处理请求for (int i = 0; i < list.size(); i++) {//批量更新和批量删除,就在这里修改对应的请求就可以了bulkRequest.add(new IndexRequest(index).source(JSON.toJSONString(list.get(i)), XContentType.JSON));}BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);return bulk.hasFailures();}/*** 删除文档信息** @param index 索引名称* @param id id* @throws IOException*/public boolean deleteDocument(String index, String id) throws IOException {DeleteRequest request = new DeleteRequest(index, id);request.timeout(TimeValue.timeValueSeconds(1));DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);log.info("删除文档信息:" + delete);return true;}
}4.6 canal日志
如果不想让控制台一直打印某些信息,可以配置如下配置屏蔽AbstractCanalClient类process()一直打印this.log.info(“获取消息 {}”, message)。
logging:level:#禁止AbstractCanalClient 打印常規日志 获取消息 {}top.javatool.canal.client: warn
4.7 第二种方案(解决数据库存在下划线,用上述方法,某些字段会为空)
上面的方式只适合数据库字段和实体类字段,属性完全一致的情况;当数据库字段含有下划线的适合,因为我们直接去监听的binlog日志,里面的字段是数据库字段,因为跟实体类字段不匹配,所以会出现字段为空的情况,这个适合需要去获取列的字段,对字段进行属性转换,实现方法如下:
4.7.1 引入依赖
<dependency><groupId>com.xpand</groupId><artifactId>starter-canal</artifactId><version>0.0.1-SNAPSHOT</version></dependency>
4.7.2 创建监听
@CanalEventListener
@Slf4j
public class KafkaListener {@Autowiredprivate RedisTemplate redisTemplate;/*** @param eventType 当前操作数据库的类型* @param rowData 当前操作数据库的数据*/@ListenPoint(schema = "maruko", table = "kafka_test")public void listenKafkaTest(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {KafkaTest kafkaTestBefore = new KafkaTest();KafkaTest kafkaTestAfter = new KafkaTest();//遍历数据获取k-vList<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();getEntity(beforeColumnsList, kafkaTestBefore);log.warn("获取到提交前的对象为:" + kafkaTestBefore);getEntity(afterColumnsList, kafkaTestAfter);log.warn("获取到提交后的对象为:" + kafkaTestAfter);//判断是新增还是更新还是删除switch (eventType.getNumber()) {case CanalEntry.EventType.INSERT_VALUE:case CanalEntry.EventType.UPDATE_VALUE:redisTemplate.opsForValue().set("kafka_test" + kafkaTestAfter.getId(), kafkaTestAfter);break;case CanalEntry.EventType.DELETE_VALUE:redisTemplate.delete("kafka_test" + kafkaTestBefore.getId());break;}}/*** 遍历获取属性转换为实体类** @param columnsList* @param kafkaTest*/private void getEntity(List<CanalEntry.Column> columnsList, KafkaTest kafkaTest) {SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");for (CanalEntry.Column column : columnsList) {String name = column.getName();String value = column.getValue();switch (name) {case KafkaTest.ID:if (StringUtils.hasLength(value)) {kafkaTest.setId(Integer.parseInt(value));}break;case KafkaTest.CONTENT:if (StringUtils.hasLength(value)) {kafkaTest.setContent(value);}break;case KafkaTest.PRODUCER_STATUS:if (StringUtils.hasLength(value)) {kafkaTest.setProducerStatus(Integer.parseInt(value));}break;case KafkaTest.CONSUMER_STATUS:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerStatus(Integer.parseInt(value));}break;case KafkaTest.UPDATE_TIME:if (StringUtils.hasLength(value)) {try {kafkaTest.setUpdateTime(format.parse(value));} catch (ParseException p) {log.error(p.getMessage());}}break;case KafkaTest.TOPIC:if (StringUtils.hasLength(value)) {kafkaTest.setTopic(value);}break;case KafkaTest.CONSUMER_ID:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerId(value);}break;case KafkaTest.GROUP_ID:if (StringUtils.hasLength(value)) {kafkaTest.setGroupId(value);}break;case KafkaTest.PARTITION_ID:if (StringUtils.hasLength(value)) {kafkaTest.setPartitionId(Integer.parseInt(value));}break;case KafkaTest.PRODUCER_OFFSET:if (StringUtils.hasLength(value)) {kafkaTest.setProducerOffset(Long.parseLong(value));}break;case KafkaTest.CONSUMER_OFFSET:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerOffset(Long.parseLong(value));}break;case KafkaTest.TEST:if (StringUtils.hasLength(value)) {kafkaTest.setTest(value);}break;}}}
}
4.7.3 实体类
@Data
@TableName("kafka_test")
public class KafkaTest {public static final String ID = "id";public static final String CONTENT = "content";public static final String PRODUCER_STATUS = "producer_status";public static final String CONSUMER_STATUS = "consumer_status";public static final String UPDATE_TIME = "update_time";public static final String TOPIC = "topic";public static final String CONSUMER_ID = "consumer_id";public static final String GROUP_ID = "group_id";public static final String PARTITION_ID = "partition_id";public static final String PRODUCER_OFFSET = "consumer_offset";public static final String CONSUMER_OFFSET = "producer_offset";public static final String TEST = "test";@TableId(type = IdType.AUTO)private Integer id;@TableField("content")private String content;@TableField("producer_status")private Integer producerStatus;@TableField("consumer_status")private Integer consumerStatus;@TableField("update_time")private Date updateTime;@TableField("topic")private String topic;@TableField("consumer_id")private String consumerId;@TableField("group_id")private String groupId;@TableField("partition_id")private int partitionId;@TableField("consumer_offset")private Long consumerOffset;@TableField("producer_offset")private Long producerOffset;@TableField("test")private String test;
}4.8 canal整合异常问题排查思路
4.8.1 无法正常启动
canal配置文件中mysql连接方式是否有效,
是否已为canal单独配置mysql账号,并赋予权限
服务对应的自定义数据存储目的地中配置文件是否完整,初始配置文件需要与默认的exmple中配置文件一致
更改配置文件之后如果自定义的数据目录还是无法连接,则将对应目录下的meta.dat文件删除之后再重启
4.8.2 使用canal监听数据 启动成功了 没有报错 不过一直监听不到消息
- 检查canal的配置,确保配置正确,特别是数据库的连接信息;
- 检查canal的日志,确保没有报错;
- 检查数据库的binlog是否开启,确保binlog格式为row;
- 检查数据库的binlog是否有变更,确保有变更;
- 检查canal的过滤规则,确保过滤规则正确;
- 检查canal的版本,确保版本与数据库版本兼容;
- 检查canal的运行环境,确保环境正确;
- 检查canal的配置文件,确保配置文件正确;
- 检查canal的运行状态,确保运行正常;
- 检查canal的监听端口,确保端口没有被占用。