导读:随着 OCR 系统识别能力的提升,专业对抗 OCR 的黑产也越来越多,这个过程中 AI 如何抵御黑产攻击类的文字图像?本文通过分享相似性特征训练的常见算法,并选择了其中一些有代表性的工作进行介绍,希望能给读者一些思路与方法。
文|邓芮 网易易盾高级计算机视觉算法工程师
一、背景
在互联网信息中,文字是重要的信息媒介,通过传递微信、电话号码等信息,黑产能够完成对广告、色情等引流。为了阻断这些垃圾信息的传播,在内容安全审核领域,OCR 文字识别系统是重要的一环,它通过对图像中文字内容进行自动识别,发现异常的文字,拦截过滤有害内容。
随着 OCR 系统识别能力的提升,专业对抗 OCR 的黑产也越来越多,典型的黑产会通过拆字、加遮挡、扭曲等方式,破坏图像特征,从而达到模型难以自动识别的目的。一旦他们造出来当前系统难以识别的文字,就会批量生成,进行刷量传播,在这个过程中,为了躲避系统追击,还常常伴随着恶意变种。另外我们也发现,同一种对抗攻击类型,会跨时间、跨客户的反复出现。
那么我们要如何来解决这个问题呢?考虑已有的方案,一个是更强的 OCR 识别系统,另一个是相似图片识别。前者的问题在于如果文字特征被严重破坏,OCR 系统就失去了识别的基础,也难以召回。而后者常用于图像整体的相似性识别,包括图像中人物、文字、背景等,当文字区域占比较小,背景更换时(如更换了不同的美女帅哥背景),整体图像相似度识别往往容易失效。

近期出现的一种攻击案例(攻击强度越来越大)
网易易盾算法团队在经过深入的问题分析和技术实践后,建立了一套以文字特征分析为核心的新一代垃圾图像识别服务,并在线上成功落地。这套服务包含图中文字属性分析、显著性区域特征提取、特征相似性比对分析等模块,对相似类型的变种(遮挡、压缩、旋转、背景变换等)具有良好的鲁棒性,结合易盾多因子识别能力,做到了垃圾图片的精准治理。上图中的垃圾图片变化多端,新服务经过少量样本迭代,对新型变种的机器召回率可达 95%+。
结合大规模无监督学习,易盾算法团队建立了多个高精度高召回的特征分析模型,实现了对特征相似性地精准判断。这篇文章主要分享相似性特征训练的常见算法, 并选择其中一些有代表性的工作进行介绍。
二、算法分享
相似性学习本质上是一个对比学习任务,通过模型学习一些不变形特征,将图片信息压缩到一个高维的特征空间。主要的学习方法有两类,自监督学习(Self-Supervised Learning )和度量学习(Deep Metric Learning)。前者的优势是能够利用大量的无标签数据,零标注成本,但是只能学”自己“,对变种的拒绝率高。而度量学习会学习一类物体的相似度,在图像检索领域有广泛应用,但是物体的类别需要人工进行标注,标注速度慢且成本较高。下面对两类方法分别进行介绍。
Moco 系列
Moco[1] 是一种流行的自监督学习算法,目标是通过自身的对比来学习一个泛化性强的预训练特征。
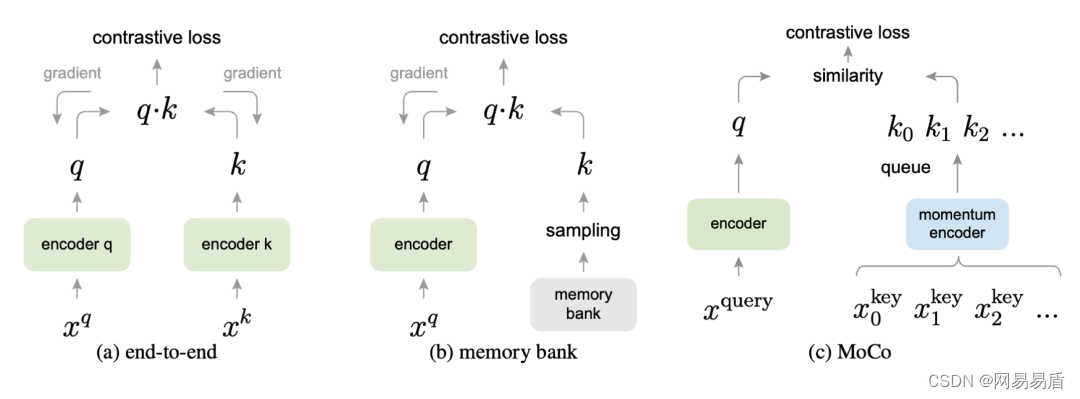
在 MoCo 之前,一种常见对比学习框架如下图(a)所示,是一种 end-to-end 的框架,这个框架相对简单,将一个样本的两种增强,一个作为 query,一个作为 key,都用同一个 encoder 进行编码,然后用 constrative loss 进行学习。然而在实际使用时,这种框架通常收敛较慢,同时由于 batchsize 受限于显卡的显存,最终收敛的效果也相对较差。
于是有了改进版本下图(b),这种方式维护了一个很大的 memory-bank 作为训练的负样本,memory-bank 存储了一系列之前 iteration 编码好的特征,通过采样可以直接用来做对比,同时 memory-bank 中的样本是不进行梯度传播的。memory-bank 的出现提高了对比学习的收敛速度和收敛效果,以至于在后期很多论文中都有使用这个模块。
而 MoCo 与前两种方法的差异,在于提出了动量编码器(momentum encoder)和一个动态的字典队列,如图(c)所示。key 特征通过动量编码器后存储到一个字典队列中,而动量编码器是一个单独的编码器,它通过动量更新保持了特征的一致性,也就是相较于 memory-bank 的方法,MoCo 中动态字典特征更稳定和具有一致性,效果也会更好,实验中也证明了这一点,同等队列尺寸下,MoCo 比 memory bank 效果好 2.6% 以上。
SwAV
SwAV[2],全称 Swapping Assignments between multiple Views of the same image,即通过交换不同视图中的标签分配来完成自监督式学习,是独立于 MoCo 和 SimCLR[3] 这种基于 pairwise 对比的一种新颖的自监督学习方式。结合文章中提出的 MultiCrop 的数据增强方式,达到了当时最好的结果。
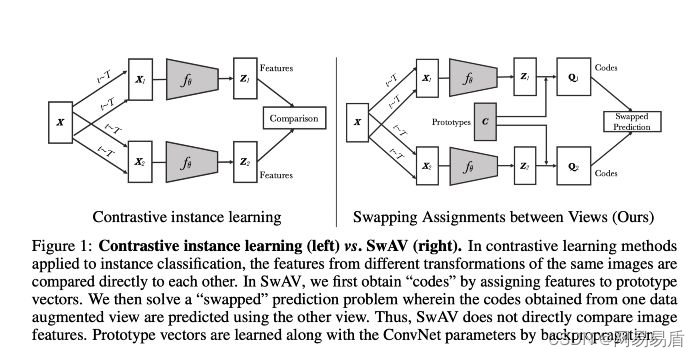
左:基于 pairwise 对比的自监督学习方式。右:SwAW 学习方式
SwAV 中学习的标签来自于聚类,它维护了一个有 K 个 prototype 的向量组,这 K 个 prototype 向量可以看做是数据的中心(参考 kmeans 的中心),样本经过 encoder 编码后,再计算与这 K 个中心的距离,就可以得到一个 soft 编码,作为这个样本的标签。在训练时,一个样本通过数据增强变成两个增强后的样本,再经过编码器分别获得自己的标签,再把自己的标签给对方,即完成了一次交换的过程,交换后的标签可以用 KL-Loss 来进行学习。
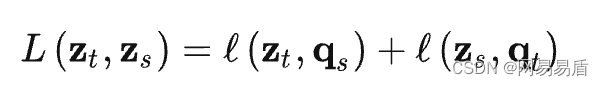
我们知道,模型学习的效果跟标签质量有很大的关系,标签质量越高,模型能学习得越好。那么 SwAV 中是如何获取高质量的 prototype 的呢?答案是 Online Cluster, SwAV 中的 prototype 也是不断训练的,始终代表着模型在当前 dataset 上的中心向量。一般来说,求 dataset 的中心向量,常规的是离线使用 Kmeans 算法(OfflineTraining),在整个 dataset 上进行计算,这种思路走下去类似于 DeepClusterV2[4]。而 SwAV 则是使用一个队列维护了少量样本队列,然后通过 Sinkhorn 算法强制将队里中的样本均匀地分配到每个中心上,这个优化过程可以表示为,给定一个特征队列 Z=[z1, z2,…zb], 将它们映射到 prototypesC=[c1, c2, …ck],这个映射关系可以表示为一个矩阵 Q=[q1, q2,…,qb], Q 的优化目标是特征和 prototype 的相似性最大,这个过程用 sinkhorn 算法来求迭代近似解,就是下面的公式。因为特征队列 Z 的长度不大,通常为几千,所以整个求解过程也很快,训练的额外开销相对较小。
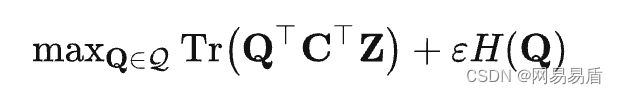
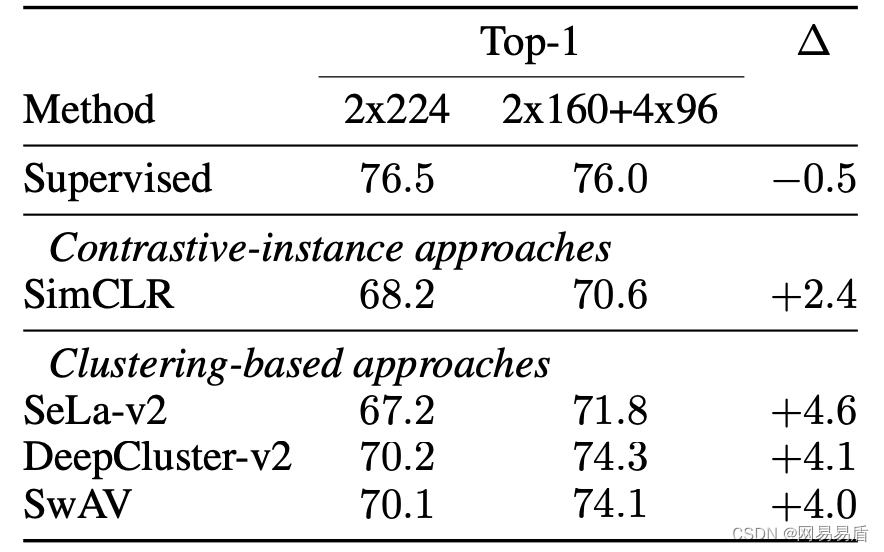
实验结果,SwAW 跟有监督训练的效果已经非常接近,优于 SimCLR 类的对比方法。另外,在标签分配的方法上,其实 SwAV 的 OnlineTraining 跟 DeepClusterV2 的 OfflineTraining 是差不多的,结果都非常好,双双印证了这种标签交换方法的有效性。
MultiSimilarity-Loss
在深度度量学习(Deep Metric Learning)中,有一系列的 pairwise 的 Loss 被提出,如 contrastive loss,triplet loss 等,在 MultiSimilarity Loss 这篇文章中提出了一个统一的框架去解释这些 Loss,文中称为GPW(General Pair Weighting),将这些 Loss 统一成对 Pair 相似性进行加权的问题,在这个框架下,作者进而提出了 3 种形式的 similarity,即 self-similarity、positive-relative-similarity 和 negative-relative-similarity,其中第一种是自相似性,只与自身有关,而后两种属于相对相似性,与其他样本相关。而 Multi-Similarity 就是同时考虑了这 3 种相似性的 Loss。
那么这 3 种相似性究竟是什么呢?用一张图来总结。
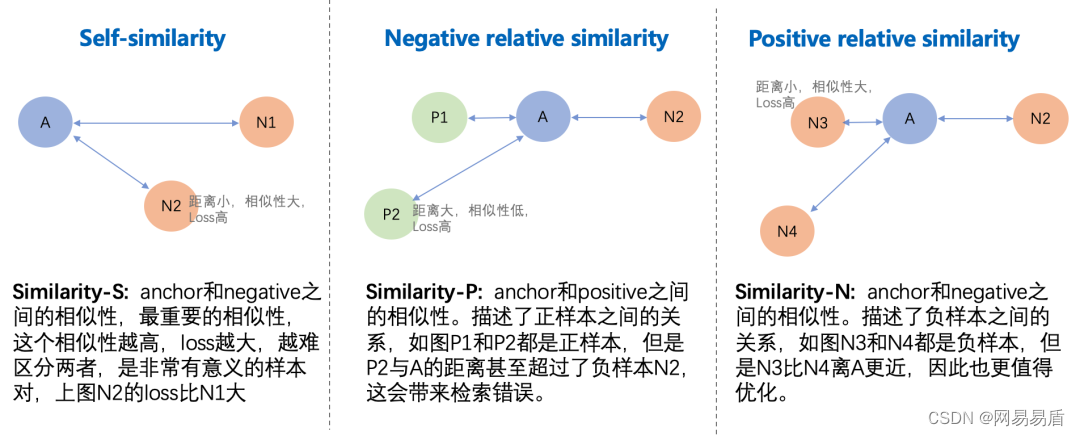
表:不同 Loss 中包含的相似性。之前的方法都只包含部分相似性。
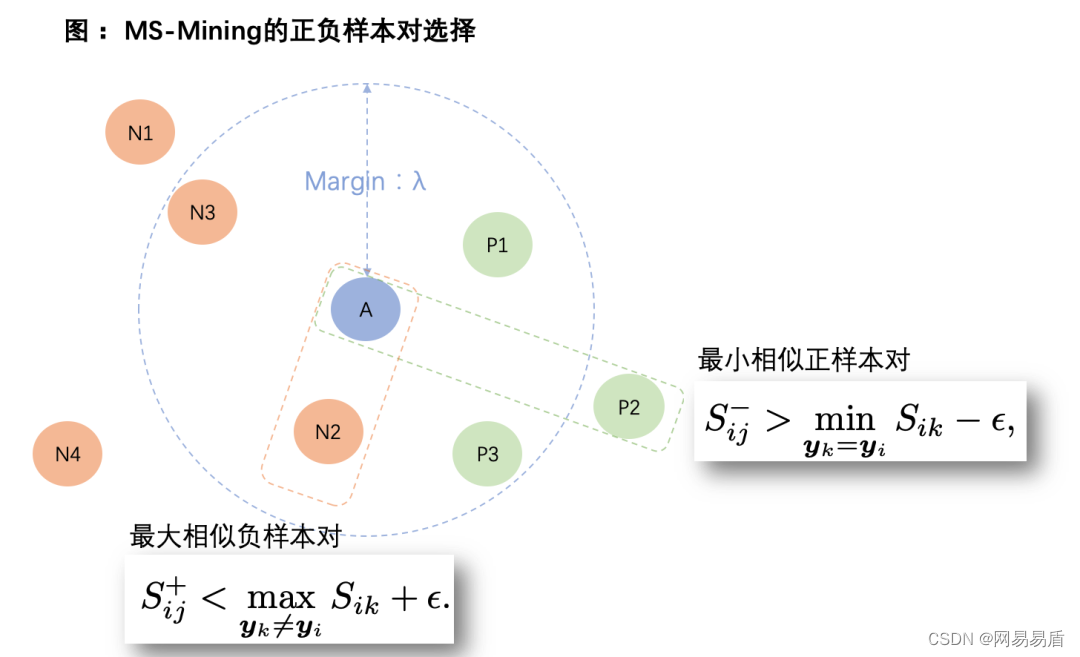
MultiSimilarLoss 的多种相似性不仅体现在 Loss 上,还体现在对训练样本的挖掘上。通过迭代去挖掘(Mining)和加权(Weighting),不断挑选出信息量高的 pair 进行训练,达到了非常好的效果。Mining 的过程是根据两个原则挑选出最优信息量的正负样本对。Weighting 是根据相似性赋予不同的样本对不同的权重。
MS Loss 的最终表达形式:
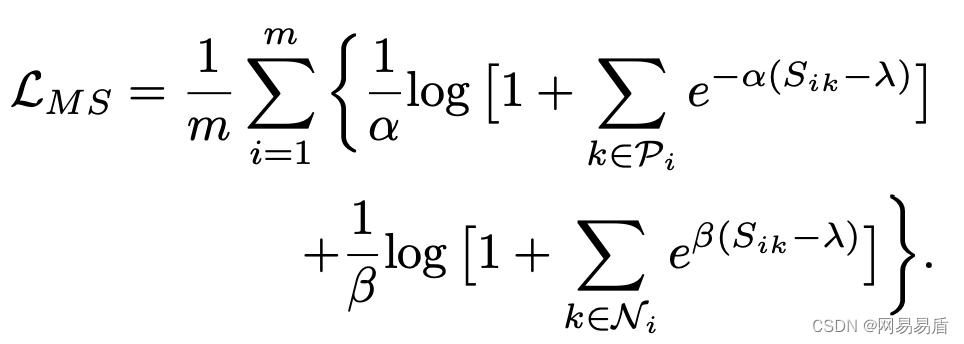
三、总结
大规模相似性特征的训练离不开自监督学习,自监督学习能以较低的成本学习到一个效果优越特征模型。但仅靠自监督学习也让模型局限在自我(self)的世界里,潜在地降低模型的泛化性,反应到线上实际应用中,会存在召回率低的问题。如何解决这个问题又是另一个新的课题,目前易盾探索了一条结合主动标注和度量学习的算法方案,逐步引导模型学习潜在的邻近关系,并取得了一定的效果。未来易盾会持续跟进业界和学界的最新方法,为这类对抗垃圾治理提供更多的解决方案。
参考资料
[1] MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
[2] Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
[3] A Simple Framework for Contrastive Learning of Visual Representations
[4] Multi-Similarity Loss with General Pair Weightingfor Deep Metric Learning
作者简介:邓芮,网易易盾高级计算机视觉算法工程师,负责 OCR 和音视频算法在内容安全领域的研发和落地。