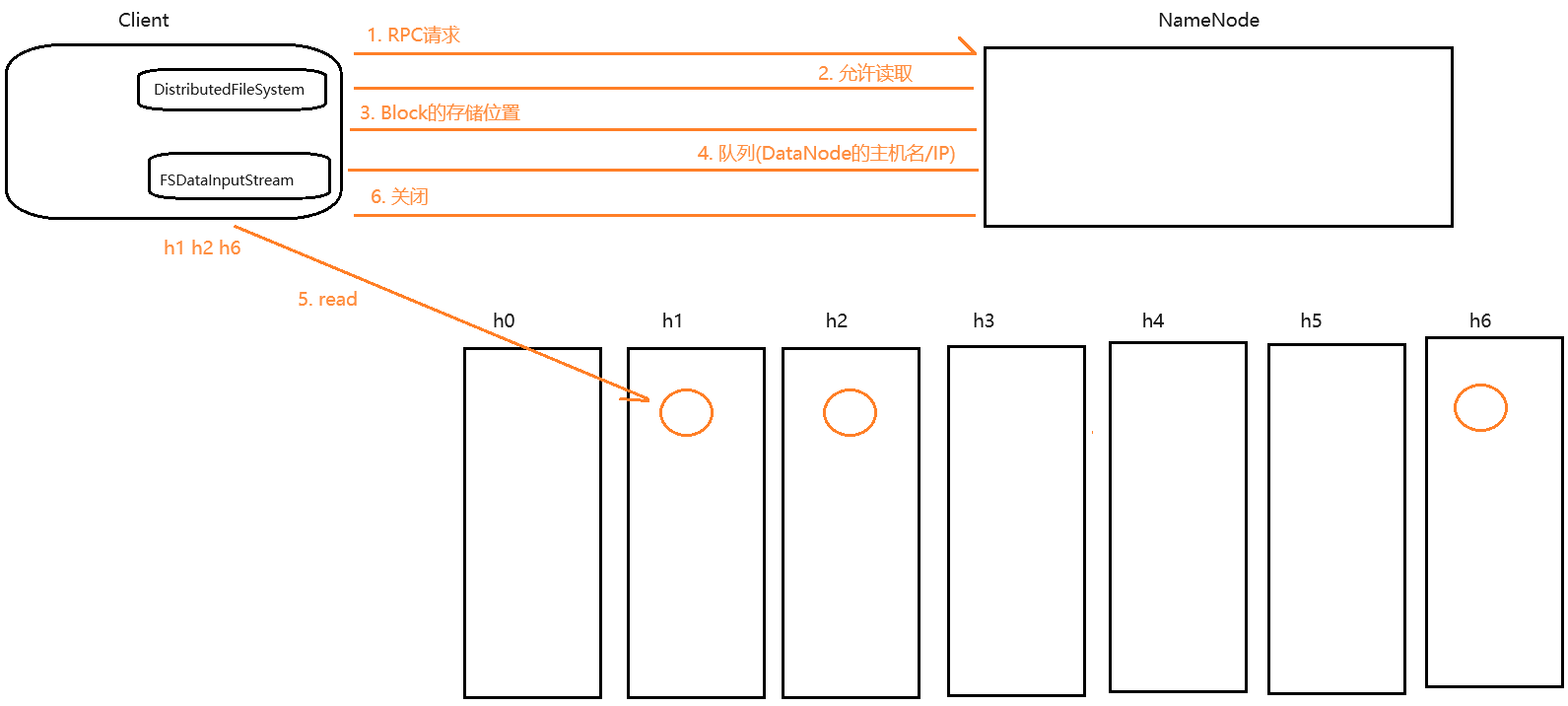
OLAP和OLTP不同的是,表中单条记录本身并不是查询所关心的,比较典型的特点包括有聚合类算子、涉及多表Join,查询所用谓语/条件没有索引。由于这些操作都非常耗计算资源,而且数据仓库相比数据库在数据量上大很多,因此,OLAP类查询经常表现为cpu-bound而不是io-bound。
按照建模类型划分:
- MOLAP
- ROLAP
- HOLAP
MOLAP
这应该算最传统的数仓了,1993年olap概念提出来时,指的就是MOLAP数仓,M即表示多维。大多数MOLAP产品均对原始数据进行预计算得到用户可能需要的所有结果,将其存储到优化过的多维数组中,也就是常听到的 数据立方体。
由于所有可能结果均已计算出来并持久化存储,查询时无需进行复杂计算,且以数组形式可以进行高效的免索引数据访问,因此用户发起的查询均能够稳定地快速响应。这些结果集是高度结构化的,可以进行压缩/编码来减少存储占用空间。
但高性能并不是没有代价的。首先,MOLAP需要进行预计算,这会花去很多时间。如果每次写入增量数据后均要进行全量预计算,显然是低效率的,因此支持仅对增量数据进行迭代计算非常重要。其次,如果业务发生需求变更,需要进行预定模型之外新的查询操作,现有的MOLAP实例就无能为力了,只能重新进行建模和预计算。
在开源软件中,由eBay开发并贡献给Apache基金会的Kylin即属于这