简介
概述
Flume本身是由Cloudera公司开发的后来贡献给了Apache的一套针对日志进行收集(collecting)、汇聚(aggregating)和传输(moving)的分布式机制。

图-1 Flume图标
Flume本身提供了较为简易的流式结构,使得开发者能够较为简易和方便的搭建Flume的流动模型。
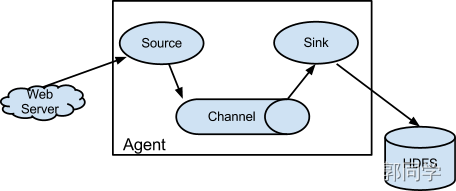
图-2 Flume流动模型图
目前,Flume提供了两大版本:Flume0.x和Flume1.x版本:
1)Flume0.X:又称之为Flume-og版本,依赖于Zookeeper,结构配置相对复杂,现在在市面上已经不怎么常见了。
2)Flume1.X:又称之为Flume-ng版本,不依赖于Zookeeper,结构配置相对简单,是现在比较常用的版本。
截止到目前为止(2023年7月20日),Flume的最新版本是Flume1.11.0版本。
基本概念
在Flume中,有两个基本的概念:Event和Agent。
Event
在Flume中,会将收集到的每一条日志都封装成一个Event对象,所以一个Event就是一条日志。
Event本质上是一个json串,固定的包含两部分:headers和body。即Flume会将收集到的每一条日志封装成一个json,这个json就是一个Event。
{"headers":{},"body":""}
Agent
Agent是Flume流动模型的基本组成部分,固定的包含三个部分:
1)Source:从数据源采集数据(collecting);
2)Channel:将数据进行临时的存储(aggregating);
3)Sink:将数据进行传输(moving)。
流动模型/拓扑结构
Flume中,通过Agent之间相互组合,可以构成复杂的流动模型,包括:单级流动,多级流动,扇入流动,扇出流动以及复杂流动。
单级流动(Agent Flow),顾名思义,即只有1个Agent组成,数据经过Source采集,通过Sink写入目的地,经过一次流动即可。
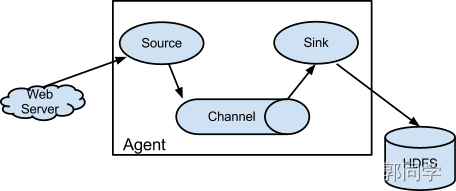
图-3 单级流动
多级流动(Multi-agent Flow),又叫串联流动,是由2个及以上的Agent串联组成,数据需要流经多个Agent才能写到目的地。

图-4 多级流动
扇入流动(Consolidation),又叫聚集流动,是将多个Agent的结果汇聚到一个Agent中,最终写入目的地。

图-5 扇入流动
扇出流动(Multiplexing the flow),又叫复用流动,是将数据分别传输给多个Agent,写入多个目的地。
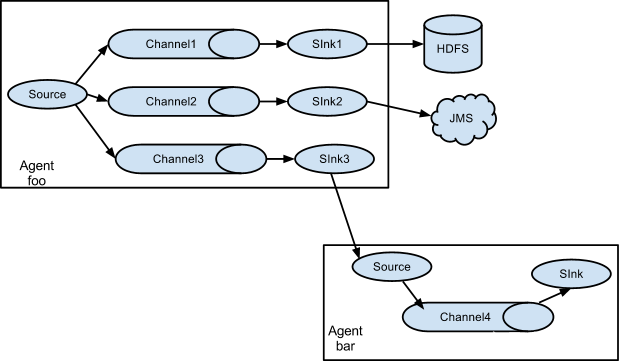
图-6 扇出流动
复杂流动(Flexible Flow),按照项目需求,将上述流动模型进行组合,构成的就是复杂流动。
编译和安装
编译
1)进入源码存放目录,上传或者下载Flume的源码包:
# 进入目录 cd /opt/presoftware/
# 官网下载地址
wget https://archive.apache.org/dist/flume/1.11.0/apache-flume-1.11.0-src.tar.gz
2)解压:
tar -xvf apache-flume-1.11.0-src.tar.gz -C /opt/source/
3)进入Flume源码目录:
cd /opt/source/apache-flume-1.11.0-src/
4)编译:
mvn -X package -Pdist,nativeN,docs -DskipTests -Dtar -Dmaven.skip.test=true -Dmaven.javadoc.skip=true -Denforcer.skip=true
5)编译好的安装包在flume-ng-dist/target目录下。
编译错误处理
如果编译过程中提示缺少了eigenbase,那么上传jar包之后,执行:
mvn install:install-file \
-Dfile=DynamoDBLocal-1.11.86.jar \
-DgroupId=com.amazonaws \
-DartifactId=DynamoDBLocal \
-Dversion=1.11.86 \
-Dpackaging=jar
缺少net.hydromatic:linq4j:jar:0.4:
mvn install:install-file \
-Dfile=linq4j-0.4.jar \
-DgroupId=net.hydromatic \
-DartifactId=linq4j \
-Dversion=0.4 \
-Dpackaging=jar
缺少net.hydromatic:quidem:jar:0.1:
mvn install:install-file \
-Dfile=quidem-0.1.1.jar \
-DgroupId=net.hydromatic \
-DartifactId=quidem \
-Dversion=0.1.1 \
-Dpackaging=jar
缺少org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde:
mvn install:install-file \
-Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar \
-DgroupId=org.pentaho \
-DartifactId=pentaho-aggdesigner-algorithm \
-Dversion=5.1.5-jhyde \
-Dpackaging=jar
安装
Flume本身是使用Java开发的,所以要求服务器上首先安装了JDK1.8。
1)进入软件预安装目录,上传或者下载安装包:
# 进入预安装目录
cd /opt/presoftware/
# 官网下载地址
wget --no-check-certificate https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz
2)解压安装包:
tar -xvf apache-flume-1.11.0-bin.tar.gz -C /opt/software/
3)进入Flume安装目录:
cd /opt/software/
4)重命名目录:
mv apache-flume-1.11.0-bin/ flume-1.11.0
5)配置环境变量:
# 编辑文件
vim /etc/profile.d/flumehome.sh
# 在文件中添加
export FLUME_HOME=/opt/software/flume-1.11.0
export PATH=$PATH:$FLUME_HOME/bin
# 保存退出,生效
source /etc/profile.d/flumehome.sh
# 测试
flume-ng version
6)解决Flume的连接池包和Hadoop的连接池包不一致问题:
# 进入Flume的lib目录
cd flume-1.11.0/lib/
# 删除原来的连接池包
rm -rf guava-11.0.2.jar
# 复制Hadoop的连接池包
cp /opt/software/hadoop-3.2.4/share/hadoop/common/lib/guava-27.0-jre.jar ./
入门案例
1)进入Flume中,创建数据目录,用于存放格式文件:
# 进入Flume的安装目录
cd /opt/software/flume-1.11.0/
# 创建数据目录
mkdir data
# 进入目录
cd data
2)创建格式文件:
vim basic.properties
添加内容:
# 指定Agent的名字
# 指定Source的名字
# 如果要配置多个Source,那么Source之间用空格间隔
a1.sources = s1
# 指定Channel的名字
# 如果要配置多个Channel,那么Channel之间用空格间隔
a1.channels = c1
# 指定Sink的名字
# 如果要配置多个Sink,那么Sink之间用空格间隔
a1.sinks = k1
# 配置Source
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
# 配置Channel
a1.channels.c1.type = memory
# 配置Sink
a1.sinks.k1.type = logger
# 绑定Source和Channel
a1.sources.s1.channels = c1
# 绑定Sink和Channel
a1.sinks.k1.channel = c1
3)启动Flume:
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file basic.properties -Dflume.root.logger=INFO,console
上述命令可以简化为:
flume-ng agent -n a1 -c $FLUME_HOME/conf -f basic.properties -Dflume.root.logger=INFO,console
4)复制窗口,在新窗口中输入:
nc hadoop01 8090
# 回车之后发送数据
5)停掉Flume之后,会发现在当前的data目录下生成了一个新文件flume.log,而我们输入的数据被封装成了Event形式写入到了这个新文件中。
控制台打印
需要注意的是,从Flume1.10.0版本开始,使用log4j2.x替换log4j1.x,使用log4j2.xml替换了log4j.properties,因此使用Logger Sink不再输出到控制台上,而是将结果输出到了flume.log文件中。如果想要将数据打印到控制台上,操作如下:
1)进入Flume的配置文件目录:
cd /opt/software/flume-1.11.0/conf/
2)编辑文件:
vim log4j2.xml
修改文件内容如下:
<Loggers><Logger name="org.apache.flume.lifecycle" level="info"/><Logger name="org.jboss" level="WARN"/><Logger name="org.apache.avro.ipc.netty.NettyTransceiver" level="WARN"/><Logger name="org.apache.hadoop" level="INFO"/><Logger name="org.apache.hadoop.hive" level="ERROR"/><Root level="INFO"><AppenderRef ref="Console"/><AppenderRef ref="LogFile" /></Root></Loggers>3)回到数据目录下:
cd ../data
4)重新启动Flume,发送数据,会发现数据已经打印到了控制台上。
参数解释
Flume启动过程中,需要用到多个参数,这多个参数的解释如下:
表-1 参数解释
| 完整写法 | 简写 | 解释 |
| flume-ng | Flume启动命令 | |
| agent | 表示启动Flume的Agent组件 | |
| --name | -n | 指定要启动的Agent的名字,和格式文件中Agent的名字对应 |
| --conf | -c | 指定Flume的配置文件所在的位置,注意,这儿的配置文件是Flume自己的配置文件,而不是我们自己编写的格式文件/数据文件!默认情况下,Flume的配置文件在Flume安装目录的conf目录下 |
| --conf-file | -f | 指定要执行的格式文件的位置 |
| -D | 指定其他运行的参数 | |
| flume.root.logger | 指定日志的打印级别和打印位置,可以指定级别包含INFO,WARN和ERROR,可以指定的打印位置包含console和logfile |
Source
AVRO Source
AVRO Source会监听指定的端口,接收其他节点传过来的被AVRO序列化之后的数据。AVRO Source结合AVRO Sink可以实现更多的流动模型/拓扑结构,例如多级流动、扇入流动、扇出流动等。
AVRO Source中配置的选项有:
表-2 配置选项
| 选项 | 备注 | 解释 |
| type | required | Source的类型,此处必须是avro |
| bind | required | 要监听的服务器的主机名或者IP |
| port | required | 要监听的端口 |
| channels | required | Source需要绑定的Channel |
案例:
1)编辑文件:
vim avrosource.properties
添加如下配置:
a1.sources = s1a1.channels = c1a1.sinks = k1# 配置AVRO Source# 类型必须是avroa1.sources.s1.type = avro# 绑定要监听的主机a1.sources.s1.bind = 0.0.0.0# 绑定要监听的端口a1.sources.s1.port = 8090a1.channels.c1.type = memorya1.sinks.k1.type = loggera1.sources.s1.channels = c1a1.sinks.k1.channel = c12)启动Flume:
flume-ng agent -n a1 -c $FLUME_HOME/conf -f avrosource.properties -Dflume.root.logger=INFO,console
3)在新窗口中,创建一个文件,添加内容。
4)启动Flume的avro-client组件,将文件进行AVO序列化之后发送给Avro Source:
flume-ng avro-client -H hadoop01 -p 8090 -F a.txt
avro-client组件中的参数解释:
表-3 参数解释
| 完整写法 | 简写 | 解释 |
| avro-client | 指定启动Flume的avro-client组件 | |
| --host | -H | 指定数据要发送的主机名或者IP |
| --port | -p | 指定数据要发送的端口 |
| --filename | -F | 指定要发送的文件 |
Exec Source
Exec Source会运行指定的命令,然后收集这个命令的执行结果。可以利用这个Source来完成部分场景的监控,例如对方是否有返回,文件是否有新增等。
Exec Source中配置的选项有:
表-4 配置选项
| 选项 | 备注 | 解释 |
| type | required | Source的类型,此处必须是command |
| command | required | 要执行的命令 |
| channels | required | Source需要绑定的Channel |
| shell | optional | 指定命令的类型,最好指定这个属性 |
案例:监听指定的文件,如果文件中新添了数据,那么自动收集新添的数据。
1)编辑文件:
vim execsource.properties
添加如下内容:
a1.sources = s1a1.channels = c1a1.sinks = k1# 配置Exec Source# 类型必须是execa1.sources.s1.type = exec# 指定命令a1.sources.s1.command = tail -F /opt/software/flume-1.11.0/data/a.txt# 指定Shell类型a1.sources.s1.shell = /bin/bash -ca1.channels.c1.type = memorya1.sinks.k1.type = loggera1.sources.s1.channels = c1a1.sinks.k1.channel = c12)启动Flume:
flume-ng agent -n a1 -c $FLUME_HOME/conf -f execsource.properties -Dflume.root.logger=INFO,console
3)新窗口中,向文件中追加数据:
echo 'append' >> /opt/software/flume-1.11.0/data/a.txt
echo 'exec' >> /opt/software/flume-1.11.0/data/a.txt
回到Flume界面,发现新添加的数据被Flume自动收集了。
Spooling Directory Source
Spooling Directory Source用于监听指定的目录,如果目录中有新的文件,那么会自动收集新文件中的数据。注意,被收集过的文件会自动的添加一个后缀。
Spooling Directory Source配置的选项包含:
表-5 配置选项
| 选项 | 备注 | 解释 |
| type | required | Source的类型,此处必须是spooldir |
| spoolDir | required | 要监听的目录 |
| channels | required | Source需要绑定的Channel |
| fileSuffix | optional | 被收集过的文件添加的后缀,默认是.COMPLETED |
案例:监听指定的目录,自动收集新文件的内容。
1)编辑文件:
vim spoolsource.properties
添加如下配置: