写了几篇网络爬虫的博文后,有网友留言问Python爬虫如何入门?今天就来了解一下什么是爬虫,如何快速的上手Python爬虫。
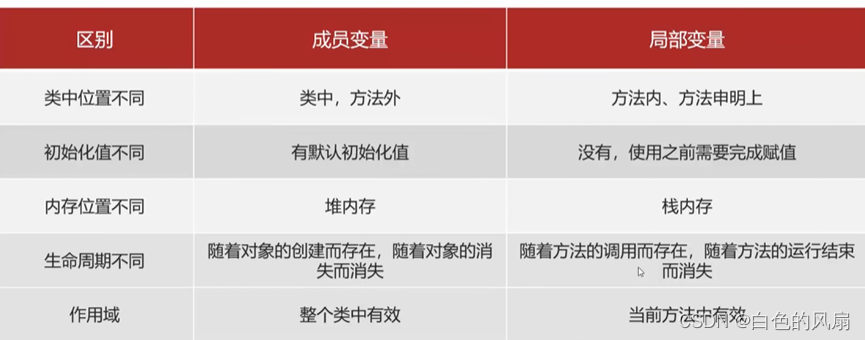
一、什么是网络爬虫
网络爬虫,英文名称为Web Crawler或Spider,是一种通过程序在互联网上自动获取信息的技术。它根据指定的规则,从互联网上下载网页、图片、视频等内容,并抽取其中的有用信息进行处理。简单来说,网络爬虫可以看作是在互联网上自动“爬行”的程序,它们从某个或某些初始网页开始,读取网页内容,找到其中的链接地址,然后通过这些链接地址寻找下一个网页,这样不断循环,直到按照某种策略抓取完所需的网页为止。
网络爬虫的应用场景非常广泛,包括搜索引擎中的网页抓取、数据挖掘、网站监测等领域。例如,搜索引擎通过爬虫技术抓取互联网上的网页信息,建立索引数据库,以便用户进行关键词搜索时能够快速找到相关信息。同时,网络爬虫也需要注意遵守相关法律法规和网站的使用协议,避免对网站造成不必要的负担或侵犯用户隐私。
二、网络爬虫的工作原理
网络爬虫(Web Crawler)是一种自动化程序,用于在互联网上按照一定规则和算法自动获取网页信息。网络爬虫通过访问网站的URL,并根据预设的规则抓取页面内容,然后将抓取到的数据保存、分析或用于其他用途。
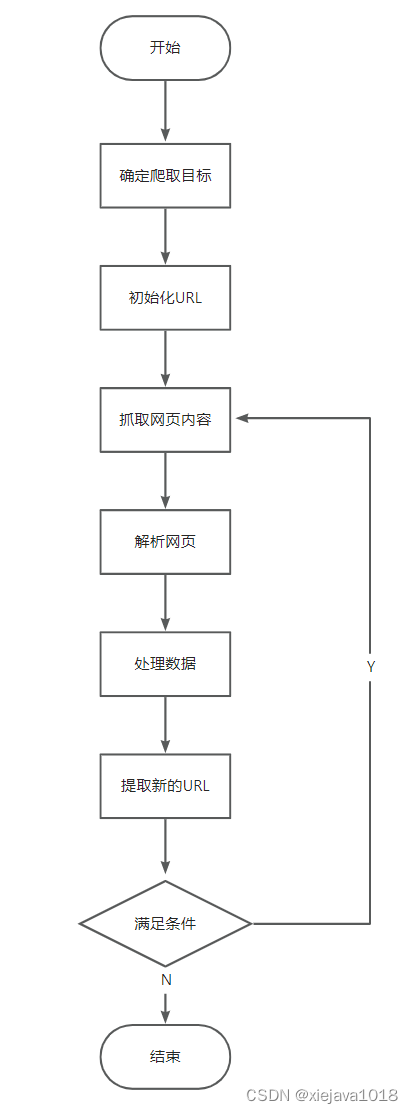
网络爬虫的主要工作步骤包括以下几个方面:
确定爬取目标–>抓取网页内容–>解析网页–>处理数据
- 确定爬取目标:网络爬虫会从一个或多个起始URL开始,然后根据链接关系逐步发现更多的网页。它可以通过遍历网页的超链接、Sitemap、RSS订阅等方式来发现新的网页。
- 抓取网页内容:一旦网络爬虫发现了目标网页,它会向服务器发送HTTP请求,获取网页的HTML代码或其他相关资源(如图片、视频等)。获取到的网页内容将会被保存到本地或内存中。
- 解析网页:网络爬虫通常会对抓取到的网页进行解析,提取其中的结构化数据,例如标题、正文、链接、图片等内容。这通常需要使用HTML解析器来处理网页内容。
- 处理数据:抓取到的数据可以被进一步处理、分析、过滤、清洗或存储。这些数据可以用于搜索引擎的索引、数据分析、信息检索、机器学习等各种用途。
三、学习爬虫需要哪些前置知识
了解到网络爬虫的工作原理后,就知道了爬虫需要哪些前置知识了。
- 需要具备基础的网络基础知识
需要理解HTTP请求与响应的基本原理,包括请求方法(GET、POST等)、请求头、请求体以及响应状态码等。 - 需要了解熟悉HTML和CSS基础知识
需要了解HTML的基本结构和常用标签,如标题、段落、链接、图片等
需要熟悉CSS选择器的基本语法和用法,以便在解析网页时能够定位并提取所需内容。 - 最好需要熟悉正则表达式
学习正则表达式的语法和用法,以便在爬虫中用于匹配和提取特定格式的文本信息。 - 了解基本的数据库知识
因为最终爬取的数据需要存储到数据库中,那么需要了解一些基本的数据库知识如常用的关系型数据库mysql或非关系型数据库MongoDB
四、Python实现网络爬虫有什么优势
要实现网络爬虫需要编写代码来实现,Python实现网络爬虫具有许多优势,使其成为首选的爬虫开发语言之一。
- 易学易用:Python具有简洁、清晰的语法,易于学习和上手。它的语法类似于伪代码,使得编写爬虫代码变得简单直观。
- 丰富的爬虫库和工具:Python拥有丰富的第三方爬虫库和工具,如Beautiful Soup、Scrapy、Requests、Selenium等,这些库提供了丰富的功能和灵活的选项,可以满足不同场景下的爬虫需求。
- 强大的数据处理能力:Python在数据处理和分析方面有着强大的支持,如Pandas、NumPy、Matplotlib等库,可以轻松地对爬取到的数据进行处理、分析和可视化。
- 活跃的社区支持:Python拥有庞大而活跃的社区,你可以轻松地找到大量的教程、文档、示例代码以及问答社区,解决遇到的问题并不断提升技能。
- 跨平台性:Python是一种跨平台的语言,可以在Windows、Linux、Mac等操作系统上运行,因此可以轻松地部署和运行爬虫程序。
- 广泛的应用领域:Python不仅在网络爬虫领域广泛应用,还在数据科学、人工智能、Web开发等领域有着广泛的应用。因此学习Python不仅有助于网络爬虫开发,还能为未来的职业发展打下良好基础。
Python实现网络爬虫具有易学易用、丰富的库和工具、强大的数据处理能力、活跃的社区支持、跨平台性和广泛的应用领域等优势,使其成为开发网络爬虫的首选语言之一。
五、如何快速入门Python爬虫
以下是一些建议的步骤和资源,帮助开始Python爬虫的学习之旅:
- 学习Python基础:
● 如果你还没有学习Python,首先需要掌握Python的基础知识,包括变量、数据类型、控制流、函数、模块等。
● 推荐资源:官方Python教程、菜鸟教程、W3Schools等。 - 了解网络基础知识:
● 学习HTTP协议、URL结构、请求方法(GET、POST等)和响应状态码等网络基础知识。
● 推荐资源:W3Schools等。 - 使用requests库发送HTTP请求:
● requests是Python中非常流行的HTTP库,用于发送HTTP请求。requests 库提供了便捷的方式来发送HTTP请求,处理响应内容,包括cookies、headers等细节。
● 安装:pip install requests
● 学习如何发送GET和POST请求,处理响应,以及设置请求头等。 - 解析网页内容:
● 学习使用BeautifulSoup或lxml等库来解析HTML内容,提取所需数据。BeautifulSoup, lxml 等库提供了强大的网页解析功能,能够轻松解析HTML和XML文档结构。
● 安装:pip install beautifulsoup4 和 pip install lxml
● 掌握选择器语法,如CSS选择器和XPath。
● 学习基础的正则表达式。参考《Python与正则表达式》 - 处理JavaScript动态加载的内容:
● 有些网页内容是通过JavaScript动态加载的,直接请求HTML可能无法获取到完整内容。
● 学习使用Selenium库来模拟浏览器行为,获取动态加载的内容。Selenium 可以用来驱动真实的浏览器进行动态页面的爬取和交互。
● 安装:pip install selenium,并下载对应的浏览器驱动。参考《selenium安装与配置》 - 使用代理和应对反爬虫机制:
● 学习如何使用代理IP来避免被封禁,以及如何应对常见的反爬虫机制,如验证码、用户登录等。
● 学习和使用mitmproxy代理工具来抓包进行数据爬取。参考《mitmproxy安装与配置》 - 存储和处理数据:
● 学习将数据存储到文件(如CSV、JSON等)或数据库(如MySQL、MongoDB等)中。
● 掌握使用Python进行数据清洗和处理的技巧。pandas是做数据清洗、处理、分析的利器,可以参考《pandas快速入门指南》 - 高效与可扩展:
● 学习Scrapy框架,Scrapy框架支持分布式爬虫,允许大规模数据采集。可以参考《Scrapy爬虫框架实战》 - 实践项目:
● 通过实践项目来巩固所学知识,例如爬取某个网站的新闻、商品信息等。
可以参考《Python爬虫获取电子书资源实战》、《Selenium实战-模拟登录淘宝并爬取商品信息》、《mitmproxy实战-通过mitmdump爬取京东金榜排行数据》、《Python爬取京东商品评价信息实战》、《Python爬取淘宝商品评价信息实战》 - 学习资源和社区:
● 推荐资源:官方文档、博客文章、GitHub上的开源项目等。
● 加入Python和爬虫相关的社区和论坛,与其他开发者交流学习经验。
最后,请注意在爬虫开发过程中要遵守法律法规和道德准则,不要对目标网站造成不必要的负担或侵犯他人隐私。
博客地址:http://xiejava.ishareread.com/