目录
摘要
ABSTRACT
1 论文信息
1.1 论文标题
1.2 论文模型
1.2.1 数据处理
1.2.2 门控图神经网络
1.2.3 掩码操作
2 相关知识
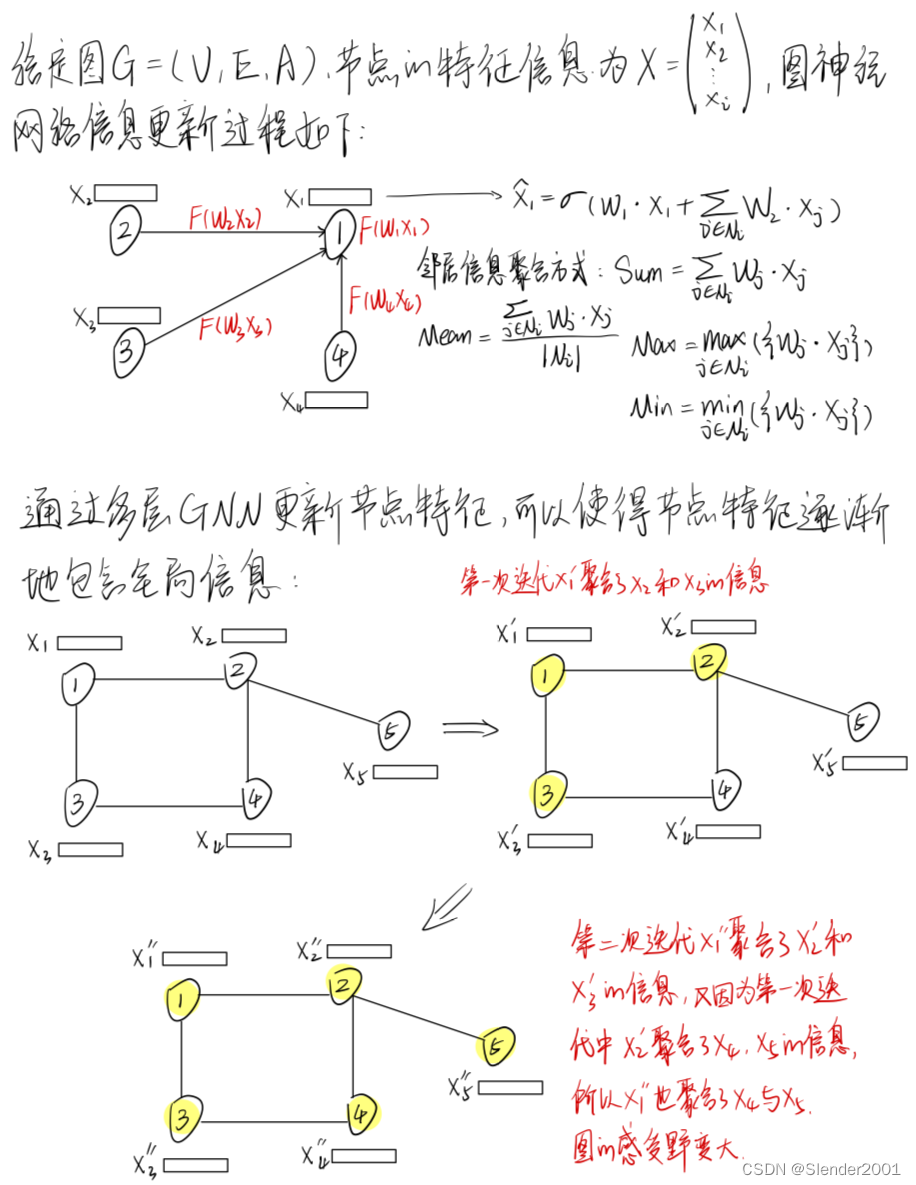
2.1 图神经网络(GNN)
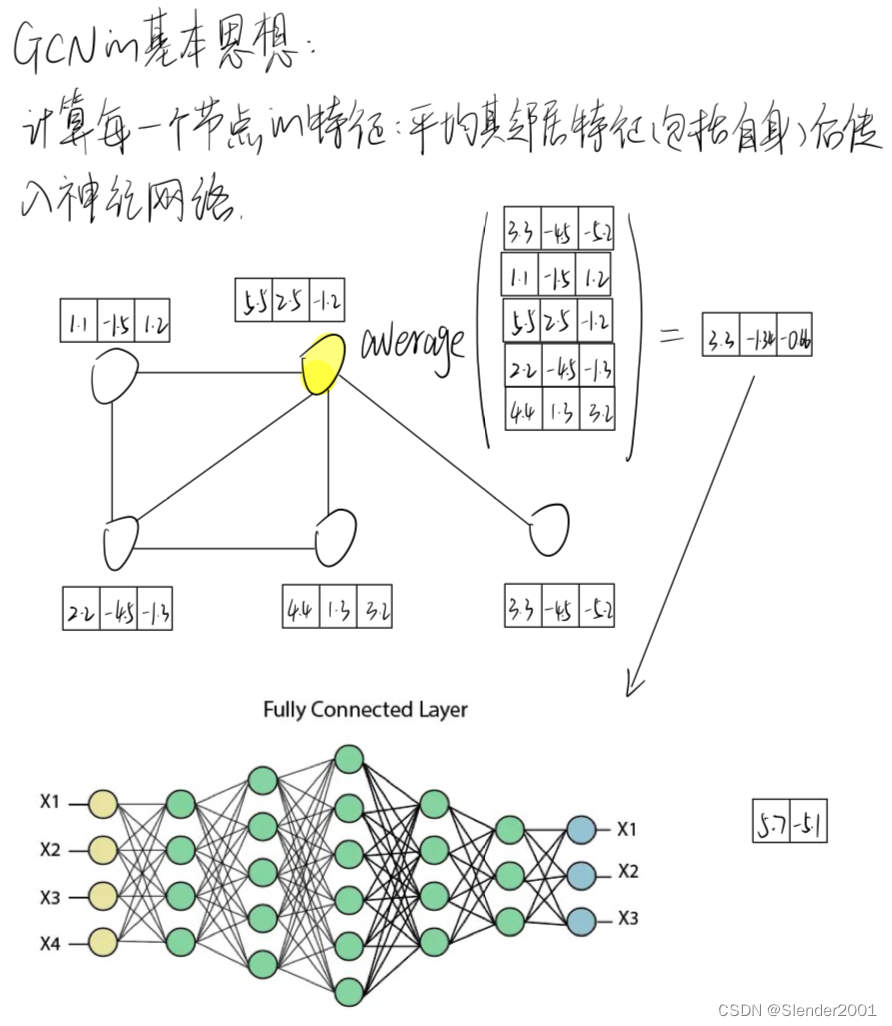
2.2 图卷积神经网络(GCN)
3 相关代码
摘要
本周阅读了一篇利用图神经网络(GNN)与门控循环单元(GRU)进行配水网络(WDN)水质预测的论文。论文模型(GGNN)实现了扩展图邻接矩阵在有向图中加入双向信息流,从而增强了模型的双向学习能力。同时模型还利用掩码操作模拟了站点故障导致数据缺失的情况,根据正常站点数据也能对故障站点进行预测,并且还能解决模型过拟合或者欠拟合的问题。
ABSTRACT
This week, We read a paper on water quality prediction in water distribution networks (WDNs) using Graph Neural Networks (GNN) and Gated Recurrent Units (GRU). The paper introduces a model called GGNN, which extends the graph adjacency matrix to incorporate bidirectional information flow in directed graphs, thus enhancing the model's bidirectional learning capability. Additionally, the model utilizes masking operations to simulate data missing due to station failures, enabling the prediction of faulty stations based on normal station data. Moreover, it addresses the issues of model overfitting or underfitting.
1 论文信息
1.1 论文标题
Real-time water quality prediction in water distribution networks using graph neural networks with sparse monitoring data
1.2 论文模型
论文模型(GGNN)旨在利用门控图神经网络(GGNN)处理网络拓扑结构、流向以及水质监测站的历史氯浓度测量数据来预测配水网络(WDN)中的实时水质。该模型由两个主要部分组成:(1)对供水网络信息进行数据处理,输入到图神经网络中;(2)利用收集到的数据构建模型。
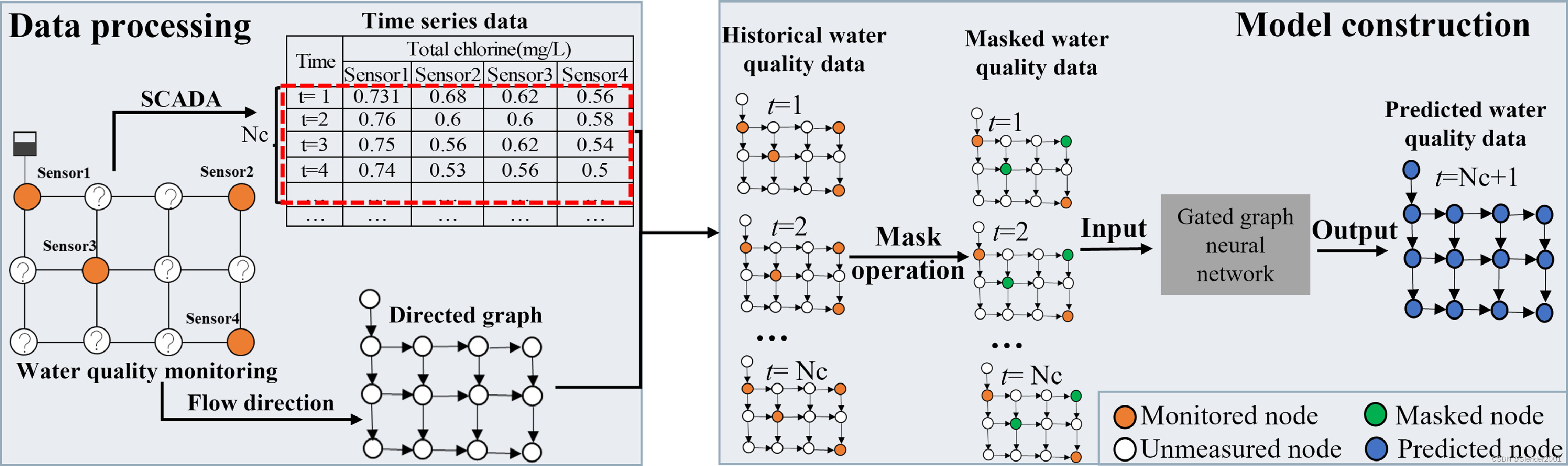
1.2.1 数据处理
GGNN模型需要两类数据:传感器监测站的WDN拓扑结构和历史水质监测数据。假设一个WDN由n个节点和m条管道组成,配备个传感器站监测水质。网络拓扑由图
表示,其中V表示由水库、储罐和连接点组成的节点集,E表示由管道、阀门和泵组成的边集。网络的流向信息和空间拓扑细节通常可以从EPANET等水力模型中获得。利用这些数据构建有向图的邻接矩阵
,其中每个元素
表示水是否从节点i流向节点j (
)或不流向 (
)。论文仅在边的权重相等时考虑水流方向。更进一步还可以同时考虑流量的动态变化和加权边。
通过在WDN中实现的监控和数据采集(SCADA)系统,可以获得各监测站的历史水质数据。该数据采集过程包括在指定的时间窗口内采集水质测量数据,记为,也表示采集历史数据的周期时间。然后将采集到的数据作为数据集中被监测节点的节点属性,对于未被监测节点,将空值替换为0,得到节点属性
。
表示数据采集周期
内获得的水质测量次数,对应于指定时间窗口内的时间步数。它是预测下一时刻水质所需数据大小的指标。
1.2.2 门控图神经网络
为了解决WDN的非欧氏图域带来的挑战,将GGNN架构用于水质预测。GGNN是一种图神经网络,用于处理复杂的图结构数据,如WDN拓扑。它扩展了通常定义在欧氏域上的传统神经网络,使其能够直接处理非欧氏图数据。GGNN模型根据相邻节点和边之间传递的消息为每个节点计算状态向量
。状态向量
表示节点学习到的特征表示,编码了关于图的局部和全局信息。它可以被认为是节点的隐藏状态,从其邻域和整个图中捕获相关信息。最终,状态向量可用于水质预测。GGNN的整体工作流程如Fig.2所示。

首先,通过扩展邻接矩阵,在有向图中加入双向信息流来作为输入。主要通过将邻接矩阵
与其转置连接起来,形成一个扩展的邻接矩阵
来实现的,这样可以同时考虑输入边和输出边。
捕获了节点之间的复杂关系和消息传播方向,从而增强了GGNN的双向学习能力。
然后,通过标准线性组合与修正线性单元(rectified linear unit, ReLU)激活函数将节点的节点属性
从原始空间
映射到新空间
的原始隐藏状态
。这种映射过程有效地扩大了节点属性的大小,使GGNN能够捕获节点属性之间潜在的重要非线性关系。隐藏状态的大小用
表示,是一个决定模型容量的超参数。然而,至关重要的是要与
取得平衡,以防止过拟合并控制训练期间的计算复杂性。
GGNN以扩展的邻接矩阵和映射的节点属性
为输入,在固定的
步上递归计算节点状态以产生最终的状态矩阵
。在聚合阶段,利用扩展邻接矩阵
计算聚合向量
,
表示节点
和相邻节点状态的聚合,聚合向量的计算公式如下:
(1)
其中,上标表示时间步长,
是块
中对应节点
的两列,
是偏移向量。在聚合阶段之后,传播阶段采用门控循环单元(gated recurrent units, GRU)机制更新节点状态。GRU传播方程描述如下:
(2)
(3)
(4)
(5)
其中和
是重置门和更新门;
和
是每层的权重和偏差;
为sigmoid激活函数;
是元素点积运算。
GGNN中的聚合和传播步骤允许模型迭代更新和细化节点状态,合并来自节点先前的特征及其邻近节点的特征信息。这个迭代过程捕获了图结构内的动态和交互规则,使GGNN能够学习和表示节点之间的复杂关系和依赖关系。传播步长(也即GNN层数)决定了GGNN中信息传播的深度。当
时,每个节点只能从其近邻节点学习。随着
的增加,GGNN可以从距离
步的节点捕获信息,包括它们的间接连接。
的选择影响模型的学习能力和效率。较高的
值会导致训练较慢以及增加内存需求,而较低的
值会限制每个节点可以学习的依赖关系的数量。因此,
的选择应该在模型性能和计算效率之间取得平衡。
在使用GRU模块更新节点状态后,使用线性层将更新后的状态转换为表示每个节点预测状态的
。在本研究中,节点属性为历史水质浓度数据,其预测状态表示模型对每个节点下一时间步水质浓度的预测。这种转换允许模型根据其更新的表示和从邻近节点传播的信息在每个节点生成对水质的预测。
1.2.3 掩码操作
虽然之前的研究主要采用掩码操作(Maskng Operation)来模拟传感器故障,特别是在不利条件下测试模型的鲁棒性,但本文方法在训练阶段利用掩码操作来增强模型对未监测节点的预测能力。在训练过程中,结合掩码操作对解决两个重大挑战至关重要。首先,现有研究通常假设传感器节点的输入,并根据模拟的网络中所有节点的值来计算损失,这在现实世界中是不切实际的,因为获取非传感器节点的测量数据很困难。论文使用模拟模型的合成数据,这样数据虽然完整,但作者并没有使用所有网络节点的所有数据进行训练。相反,只使用了一小部分节点数据。其次,如果模型仅基于传感器节点的输入进行训练,并基于这些节点计算损失,可能会导致过拟合,阻碍模型预测未监测节点的水质的能力。为了克服这些挑战,在训练过程中引入了掩码操作。随机选择指定比例(例如20%)的传感器节点,并通过在每个训练批次中将其输入替换为零进行掩盖。这个屏蔽操作有两个目的。首先,在训练过程中模拟非传感器节点数据的不可用性,使模型能够在观测到的传感器数据之外进行泛化,并学习预测无监测节点的值;其次,它作为正则化技术,防止模型仅依赖有限的传感器输入。通过鼓励模型捕捉传感器节点和非监测节点之间的关系,提高模型的泛化能力,降低过拟合的可能性。需要研究掩码节点的比例,因为它可以平衡模型性能和过拟合。更高的比率会减少可用的信息,增加欠拟合的风险。较低的速率可以提供更多的信息,但可能会导致过拟合。因此,掩码率也是一个十分重要的超参数。
2 相关知识
2.1 图神经网络(GNN)
2.2 图卷积神经网络(GCN)



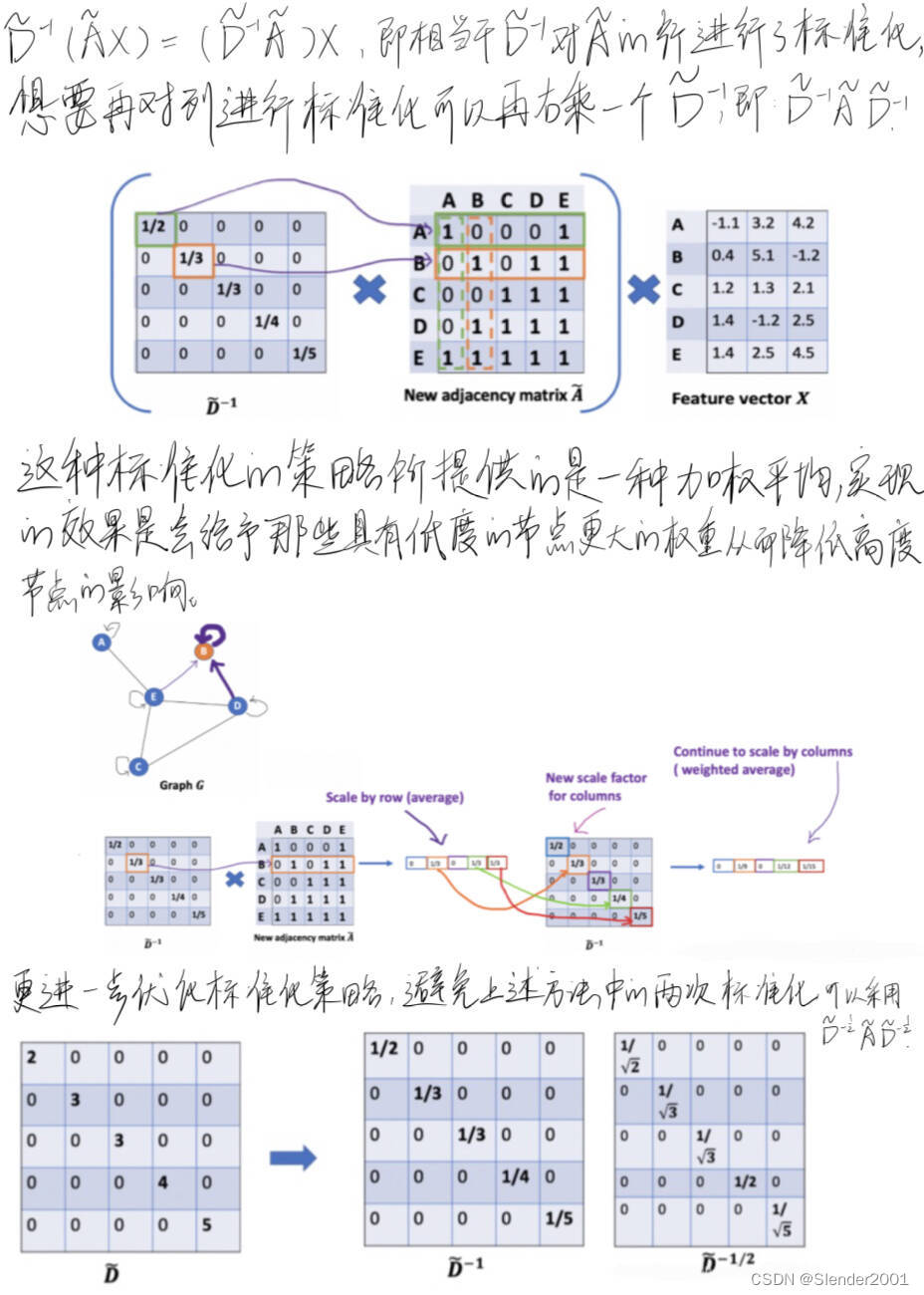
需要注意的是,常规任务情境下不会需要节点的信息传播太远。经过6~7个hops,基本上就可以使节点的信息传播到整个网络,这也使得聚合不那么有意义。实验结果也表明,2~3层的网络应该是比较好的,当GCN达到7层时,效果已经变得较差,但是通过在隐藏层间加上残差连接(Residual Connections)可以使效果变好。

3 相关代码
GCN模型定义与图结构数据定义:
import torch
import torch.nn as nn
import networkx as nx
import matplotlib.pyplot as plt
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import KarateClub
from torch_geometric.utils import to_networkxclass GCN(nn.Module):def __init__(self):super().__init__()torch.manual_seed(1234)self.conv1 = GCNConv(dataset.num_features, 4)self.conv2 = GCNConv(4, 4)self.conv3 = GCNConv(4, 2)self.classifier = nn.Linear(2, dataset.num_classes)def forward(self, x, edge_index):h = self.conv1(x, edge_index) # 输入特征与邻接矩阵h = h.tanh()h = self.conv2(h, edge_index)h = h.tanh()h = self.conv3(h, edge_index)h = h.tanh()out = self.classifier(h)return out, hdef visualize_graph(G, color):plt.figure(figsize=(7, 7))plt.xticks([])plt.yticks([])nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels=False, node_color=color, cmap="Set2")plt.show()def visualize_embedding(h, color, epoch=None, loss=None):plt.figure(figsize=(7, 7))plt.xticks([])plt.yticks([])h = h.detach().cpu().numpy()plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")if epoch is not None and loss is not None:plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)plt.show()dataset = KarateClub()
print(f'Dataset: {dataset}')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0]
# x:[34, 34](M*F,M:样本数,F:特征维度)
# edge_index:[2, 156](两个数组,第一个为source,第二个为target,156条边)
# y:[34](标签)
# train_mask:[34](指定节点是否有标签,通过此数组可以选择哪些节点计算损失,元素类型为bool)
print(data)
print(dataset.edge_index)G = to_networkx(data, to_undirected=True)
visualize_graph(G, color=data.y)
数据集KarateClub的图结构: