Python初学小知识(十四):数据分析处理库Pandas
- 十八 Pandas
- 1 文件读取
- 1.1 读取csv
- 1.2 读取txt
- 1.3 读取excel(xlsx)
- 2 内容读取
- 2.1 读取行
- 2.2 读取列
- 3 数据处理
- 3.1 加减乘除
- 3.1.1 列 与 元素
- 3.1.2 列 与 列
- 3.2 最值、总和、归一化
- 3.3 `.sort_values()`排序
- 3.4 缺失值处理
- 4 常用函数
- 4.1 pivot_table 找出特定索引对应的特定值
- 4.2 删去缺失值多的那列或行
- 4.3 定位
- 4.4 自定义函数apply
- 5 Series 结构
- 5.1 从表格中提取 Series 结构
- 5.2 自己造一个 Series 结构
来源于这里。
很多情况下用的是pandas而不是numpy,因为前者是在后者的基础上又封装了一些操作,相当于做了函数简化。pandas主要是数据预处理用的比较多。
十八 Pandas
1 文件读取
1.1 读取csv
任意一种格式,只要是以,为分隔符,就可以用read_csv读取:
import pandas as pd
excel = pd.read_csv('excel.csv')
先把文件打印出来看看结果:
print(excel)
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN e NaN
6 9.0 NaN j NaN
7 8.0 NaN i NaN
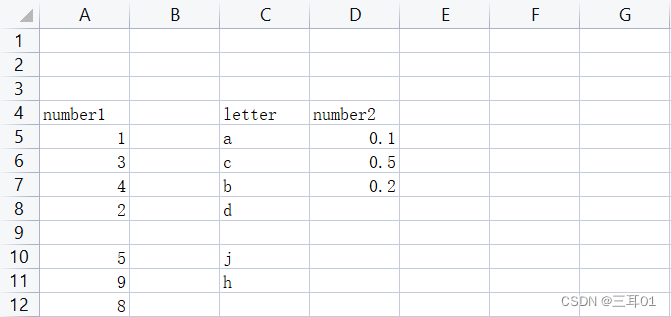
结果是和表格一致的,而且打印出来的在表格左侧加上了行号。而没有内容的地方用NaN表示。忽略了前面的空行,但是内部的空行不忽略。
接着我们看看这个文件的格式:
print(type(excel))
>>> <class 'pandas.core.frame.DataFrame'>
pandas的格式是DataFrame,数据流。通过read_csv之后,就是数据流格式,这是pandas里面最为核心也是最常用的格式。这个格式跟矩阵是差不多的,也是由行和列来组成。
我们再看看文件内部的格式:
print(excel.dtypes)
>>> number1 float64Unnamed: 1 float64letter objectnumber2 float64dtype: object
可以看到,基本是由int、float、object组成的。
值得一提的是,文件number1这一列存在浮点数(NaN被认为是浮点数),则类型就是float64。
1.2 读取txt
1.1说过了:任意一种格式,只要是以,为分隔符,就可以用read_csv读取。因此用逗号分隔的txt格式也是一样的方法:

import pandas as pd
excel = pd.read_csv('word_new.txt')
print(excel)>>> number word
0 1 my
1 2 name NaN
2 3 is
3 4\tnxy NaN
4 5 \t?print(type(excel))
>>> <class 'pandas.core.frame.DataFrame'>print(excel.dtypes)
>>> number objectword objectdtype: object
- 最前面的空行同样被忽略了→
csv和txt都是用pd.read_csv()读取,用逗号来分隔,所以这两个文件都忽略了前面的空行,但是内容中间的空行不能忽略。- 第一行有内容的行被认为是表头
number,word和1,my行都是被,分隔的,所以很顺利的占据两列2 name没有逗号,认为是一列的,所以在后面补NaN3, is里面is左右各有两个空格,所以可以看到结果里面is没有和同一列其它元素一样向右对齐- 最后两行是用了
tab
1.3 读取excel(xlsx)
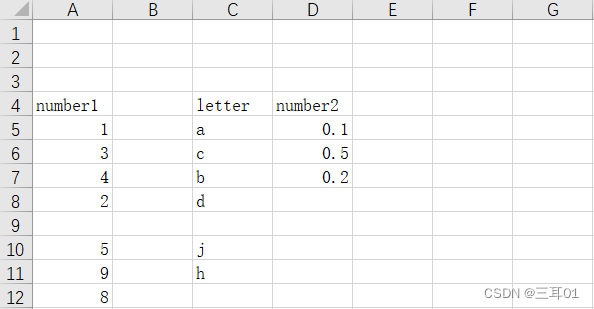
pandas里面同样包含读取最普遍的 excel 的xlsx格式的方式:
import pandas as pd
excel = pd.read_excel('excel.xlsx')
print(excel)
>>> Unnamed: 0 Unnamed: 1 Unnamed: 2 Unnamed: 3
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 number1 NaN letter number2
3 1 NaN a 0.1
4 3 NaN c 0.5
5 4 NaN b 0.2
6 2 NaN d NaN
7 NaN NaN NaN NaN
8 5 NaN j NaN
9 9 NaN h NaN
10 8 NaN NaN NaNprint(type(excel))
>>> <class 'pandas.core.frame.DataFrame'>print(excel.dtypes)
>>> Unnamed: 0 objectUnnamed: 1 float64Unnamed: 2 objectUnnamed: 3 objectdtype: object
这里就没有忽略前面的空行。
\quad
2 内容读取
这里的excel代表的是'excel.csv':
number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN e NaN
6 9.0 NaN j NaN
7 8.0 NaN i NaN
2.1 读取行
.head()读取前面几行:
print(excel.head(3))
>>> number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2print(excel.head()) # 默认5行
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
.tail()读取后面几行:
print(excel.tail())
>>>number1 Unnamed: 1 letter number2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN j NaN
6 9.0 NaN h NaN
7 8.0 NaN NaN NaN
.loc[]读取特定行:
print(excel.loc[3])
>>> number1 2.0Unnamed: 1 NaNletter dnumber2 NaNName: 3, dtype: objectprint(excel.loc[3:6])
>>>number1 Unnamed: 1 letter number2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN j NaN
6 9.0 NaN h NaNprint(excel.loc[[2,4,7]])
>>>number1 Unnamed: 1 letter number2
2 4.0 NaN b 0.2
4 NaN NaN NaN NaN
7 8.0 NaN NaN NaN
2.2 读取列
直接文件名+列名:
print(excel['number1'])
>>> 0 1.01 3.02 4.03 2.04 NaN5 5.06 9.07 8.0Name: number1, dtype: float64'''读取多列要再加一个[]'''
print(excel[['number1', 'letter']].head())
>>>number1 letter
0 1.0 a
1 3.0 c
2 4.0 b
3 2.0 d
4 NaN NaN
如果要读取列的表头:
print(excel.columns)
>>> Index(['number1', 'Unnamed: 1', 'letter', 'number2'], dtype='object')
这样出来的是名称和类型,但是有时候只想要列表模式的名称就行,所以在上面的代码还要再加上.tolist():
columns_names = excel.columns.tolist()
print(columns_names)
>>> ['number1', 'Unnamed: 1', 'letter', 'number2']
这时候其实可以针对列名来筛选列,比如筛选数字列:
new = []
for i in columns_names:if 'number' in i:new.append(i)print(new) # 这就是筛选出的列名
>>> ['number1', 'number2']print(excel[new].head())
>>>number1 number2
0 1.0 0.1
1 3.0 0.5
2 4.0 0.2
3 2.0 NaN
4 NaN NaN
或者筛选末尾有特定字符的列名(比如末尾都有某种计量单位),在这里筛选末尾都是1的列:
new = []
for i in columns_names:if i.endswith('1'):new.append(i)print(new) # 这就是筛选出的列名
>>> ['number1', 'Unnamed: 1']print(excel[new].head())
>>>number1 Unnamed: 1
0 1.0 NaN
1 3.0 NaN
2 4.0 NaN
3 2.0 NaN
4 NaN NaN
3 数据处理
3.1 加减乘除
要保证运算的是相同元素!!!
3.1.1 列 与 元素
- 对于全为
NaN的空列,不管怎么运算,结果都还是NaN,且类型为float:
print(excel['Unnamed: 1'].head() + 10)
print(excel['Unnamed: 1'].head() - 10)
print(excel['Unnamed: 1'].head() * 10)
print(excel['Unnamed: 1'].head() / 10)print(excel['Unnamed: 1'].head() + '10ab')
print(excel['Unnamed: 1'].head() - '10ab')
print(excel['Unnamed: 1'].head() * '10ab')
print(excel['Unnamed: 1'].head() / '10ab')'''结果全都一样'''
>>> 0 NaN1 NaN2 NaN3 NaN4 NaNName: Unnamed: 1, dtype: float64
float、int、str+ 元素:
print(excel['number1'].head() + 10) # 数字+数字
>>> 0 11.01 13.02 14.03 12.04 NaNName: number1, dtype: float64print(excel['letter'].head() + '012ab') # 字符串+字符串
>>> 0 a012ab1 b012ab2 c012ab3 d012ab4 NaNName: letter, dtype: object
float、int、str- 元素:
print(excel[['number1', 'number2']].head() - 10) # 数字-数字
>>> number1 number2
0 -9.0 -9.9
1 -7.0 -9.5
2 -6.0 -9.8
3 -8.0 NaN
4 NaN NaN
float、int、str×、÷ 元素:
×、÷里面的元素只能是数字!
print(excel[['number1', 'letter']] * 10)
>>>number1 letter
0 10.0 aaaaaaaaaa
1 30.0 cccccccccc
2 40.0 bbbbbbbbbb
3 20.0 dddddddddd
4 NaN NaN
5 50.0 jjjjjjjjjj
6 90.0 hhhhhhhhhh
7 80.0 NaNprint(excel[['number1']] / 10)
>>> number1
0 0.1
1 0.3
2 0.4
3 0.2
4 NaN
5 0.5
6 0.9
7 0.8
3.1.2 列 与 列
列 与 列 的运算中,哪一列的行更多,结果的行就取决于哪一列。
- 对于全为
NaN的空列,不管怎么运算,结果都还是NaN,但是类型会变:
print(excel['number1'].head() + excel['Unnamed: 1'].head())
print(excel['number1'].head() - excel['Unnamed: 1'].head())
print(excel['number1'].head() * excel['Unnamed: 1'].head())
print(excel['number1'].head() / excel['Unnamed: 1'].head())
>>> 0 NaN1 NaN2 NaN3 NaN4 NaNdtype: float64print(excel['letter'].head() + excel['Unnamed: 1'].head())
print(excel['letter'].head() - excel['Unnamed: 1'].head())
print(excel['letter'].head() * excel['Unnamed: 1'].head())
print(excel['letter'].head() / excel['Unnamed: 1'].head())
>>> 0 NaN1 NaN2 NaN3 NaN4 NaNdtype: object
类型取决于与Unnamed列运算的那一列。
\quad
float、int加减乘除float、int:
'''与自己运算,就会给出列名和类型'''
print(excel['number1'].head() + excel['number1'])
>>> 0 2.01 6.02 8.03 4.04 NaNName: number1, dtype: float64'''与别人运算,只会给类型'''
print(excel['number1'].head() - excel['number2'])
>>> 0 0.91 2.52 3.83 NaN4 NaN5 NaN6 NaN7 NaNdtype: float64'''总行数取决于行数最多的那个'''
print(excel['number1'].head() * excel['number2'])
>>> 0 0.11 1.52 0.83 NaN4 NaN5 NaN6 NaN7 NaNdtype: float64print(excel['number1'].head() / excel['number2'].head())
>>> 0 10.01 6.02 20.03 NaN4 NaNdtype: float64
\quad
float、int与str的列不能运算str+str(只有这一种)
print(excel['letter'].head() + excel['letter'].head())
>>> 0 aa1 cc2 bb3 dd4 NaNName: letter, dtype: object
3.2 最值、总和、归一化
print(excel['number1'].max(), excel['number1'].min(), excel['number1'].sum())
>>> 9.0 1.0 32.0
归一化:除以最大值
print(excel['number1'] / excel['number1'].max())>>> 0 0.1111111 0.3333332 0.4444443 0.2222224 NaN5 0.5555566 1.0000007 0.888889Name: number1, dtype: float64
3.3 .sort_values()排序
用法:DataFrame.sort_values(by='##',axis=0,ascending=True, inplace=False, na_position='last')
by='':针对列:指定列名by='number1'(一般为了偷懒都直接写列名)
针对行:指定索引by=1axis=0:若axis=0或'index',则按列排序;
若axis=1或'columns',则按指定索引行排序ascending=True:排列顺序,默认升序排列
inplace=False:是否用排序后的数据集替换原来的数据,默认不替换na_position='last':{'first','last'},设定缺失值的显示位置(开始还是末尾)
'number1',按列排序,升序排列,不替换,缺失值末尾显示
print(excel.sort_values('number1'))
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
3 2.0 NaN d NaN
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
5 5.0 NaN j NaN
7 8.0 NaN NaN NaN
6 9.0 NaN h NaN
4 NaN NaN NaN NaN
可以看到,行与行之间按照排序重新换了位置。
此时索引发生了变化,我们可以重新安排索引:
sorted_excel = excel.sort_values('number1') # 排序后的
sorted_excel_reindexed = sorted_excel.reset_index(drop=True) # 把之前的index给drop掉
print(sorted_excel_reindexed)
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 2.0 NaN d NaN
2 3.0 NaN c 0.5
3 4.0 NaN b 0.2
4 5.0 NaN j NaN
5 8.0 NaN NaN NaN
6 9.0 NaN h NaN
7 NaN NaN NaN NaN
'letter',按列排序,降序排列,不替换,缺失值显示在开始
print(excel.sort_values('letter', ascending=False, na_position='first'))
>>>number1 Unnamed: 1 letter number2
4 NaN NaN NaN NaN
7 8.0 NaN NaN NaN
5 5.0 NaN j NaN
6 9.0 NaN h NaN
3 2.0 NaN d NaN
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
0 1.0 NaN a 0.1
- 按第7行排序,升序排列,不替换,缺失值显示在开头
print(excel.sort_values(by=7, axis='columns', na_position='first'))
>>>Unnamed: 1 letter number2 number1
0 NaN a 0.1 1.0
1 NaN c 0.5 3.0
2 NaN b 0.2 4.0
3 NaN d NaN 2.0
4 NaN NaN NaN NaN
5 NaN j NaN 5.0
6 NaN h NaN 9.0
7 NaN NaN NaN 8.0
这里是按照最后一行排序,可以看到,所有列都随着第七行变化了顺序。
3.4 缺失值处理
首先要找到缺失值:
number1 = excel['number1']
number1_isnull = pd.isnull(number1) # 判断是否NaN
print(number1_isnull) # 布尔类型
>>> 0 False1 False2 False3 False4 True5 False6 False7 FalseName: number1, dtype: boolprint(number1[number1_isnull]) # 输出True的
>>> 4 NaNName: number1, dtype: float64
然后找出好的值:
good_number1 = number1[number1_isnull==False]
print(good_number1) # 输出不为缺失值的,也就是好的
>>> 0 1.01 3.02 4.03 2.05 5.06 9.07 8.0Name: number1, dtype: float64print(sum(good_number1) / len(good_number1)) # 均值
>>> 4.571428571428571
上面是求均值,其实已经有函数直接解决了:
print(excel['number1'].mean())
>>> 4.571428571428571
4 常用函数
4.1 pivot_table 找出特定索引对应的特定值
换一个表格:
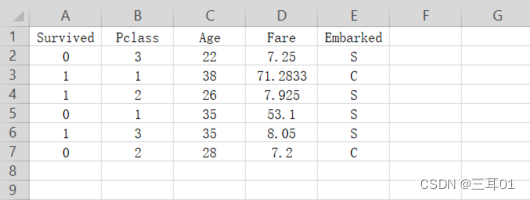
import pandas as pd
excel = pd.read_csv('new.csv')
print(excel)
>>>Survived Pclass Age Fare Embarked
0 0 3 22 7.2500 S
1 1 1 38 71.2833 C
2 1 2 26 7.9250 S
3 0 1 35 53.1000 S
4 1 3 35 8.0500 S
5 0 2 28 7.2000 C
找出特定索引对应的特定值:
# 统计各个等级的船舱(Pclass)中,获救的几率,按平均值计算
passenger_survival = excel.pivot_table(index='Pclass', values='Survived', aggfunc=np.mean)
print(passenger_survival)
>>>Survived
Pclass
1 0.5
2 0.5
3 0.5
# 统计各个船舱中乘客的年龄
passenger_age = excel.pivot_table(index='Pclass', values='Age') # aggfunc没写,就是默认mean
print(passenger_age)
>>>
Pclass
1 36.5
2 27.0
3 28.5
# 统计不同登船地点(C、S)的价格和存活人数
port_stats = excel.pivot_table(index='Embarked', values=['Fare', 'Survived'], aggfunc=np.sum)
print(port_stats)
>>>Fare Survived
Embarked
C 78.4833 1
S 76.3250 2
4.2 删去缺失值多的那列或行
原始表格:
import pandas as pd
import numpy as np
excel = pd.read_csv('excel.csv')
print(excel)
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN j NaN
6 9.0 NaN h NaN
7 8.0 NaN NaN NaN
删除列中含有 NaN 值较多的列:
# thresh 参数表示一个列中至少要有多少个非 NaN 值,否则该列将被删除。
# 上面代码中的 thresh=len(df)*0.8 表示一个列中非 NaN 值数量至少要占该列总数量的 80% 才会保留,这可以根据实际情况进行调整。
drop1_excel = excel.dropna(thresh=len(excel)*0.7, axis='columns')
print(drop1_excel)
>>>number1 letter
0 1.0 a
1 3.0 c
2 4.0 b
3 2.0 d
4 NaN NaN
5 5.0 j
6 9.0 h
7 8.0 NaN
删掉指定列中,含有NaN的行:
drop1_excel = excel.dropna(axis=0, subset = ['letter', 'number2'])
print(drop1_excel)
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
4.3 定位
# 定位第7号样本的number1是什么内容
location = excel.loc[7, 'number1']
print(location) # 8.0
4.4 自定义函数apply
# 自定义一个想实现的功能的函数
def find(x): # 寻找第3行的样本a = x.loc[3]return amy = excel.apply(find)
print(my)
>>>
number1 2.0
Unnamed: 1 NaN
letter d
number2 NaN
dtype: object
def not_null_count(x): # 统计每一列的缺失值y = pd.isnull(x) # 函数用于判断一个 DataFrame 或 Series 中每个元素是否为空值,返回一个由 True/False 构成的布尔型 DataFrame/Seriesnull = x[y] # 取出为 True 的元素return len(null)print(excel.apply(not_null_count)) # 打印出每个列有多少个缺失值
>>>
number1 1
Unnamed: 1 8
letter 2
number2 5
dtype: int64
def is_adult(x): # 判断是否是成年人,表格是newif x['Age'] > 18:return Trueelse:return Falseprint(excel.apply(is_adult, axis=1))
>>>
0 True
1 True
2 True
3 True
4 True
5 True
dtype: bool
5 Series 结构
参考:Pandas库中的Series结构
Series对象可以理解为由一列索引和一列值,共两列数据组成的结构。而DataFrame就是由一列索引和多列值组成的结构,其中,在DataFrame中的每一列都是一个Series对象。
Series(collection of values)
DataFrame(collection of Series objects)
5.1 从表格中提取 Series 结构
import pandas as pd
excel = pd.read_csv('excel.csv')
print(excel)
>>>number1 Unnamed: 1 letter number2
0 1.0 NaN a 0.1
1 3.0 NaN c 0.5
2 4.0 NaN b 0.2
3 2.0 NaN d NaN
4 NaN NaN NaN NaN
5 5.0 NaN j NaN
6 9.0 NaN h NaN
7 8.0 NaN NaN NaNseries_letter = excel['letter']
print(type(series_letter))
>>> <class 'pandas.core.series.Series'># 作为 Series 结构直接提取
print(series_letter[0:5])
>>>
0 a
1 c
2 b
3 d
4 NaN
Name: letter, dtype: object# 也可以作为 DataFrame 结构
print(series_letter.loc[2])
>>> b
5.2 自己造一个 Series 结构
from pandas import Series
series_letter = excel['letter'].values
series_number1 = excel['number1'].valuesseries_new = Series(series_number1, index=series_letter) # 索引是number1,值是letter
print(series_new)
>>>
a 1.0
c 3.0
b 4.0
d 2.0
NaN NaN
j 5.0
h 9.0
NaN 8.0
dtype: float64print(series_new[['b', 'j']]) # 相当于额外造了一个索引,之前的索引一样能用
>>>
b 4.0
j 5.0
dtype: float64print(series_new[0:5])
>>>
a 1.0
c 3.0
b 4.0
d 2.0
NaN NaN
dtype: float64
照样可以进行排序等操作,参考Pandas库中的Series结构就行。