opencv场景识别
文章目录
- opencv场景识别
- 一、需求
- 1、现状
- 2、设想
- 二、模型使用
- 1、opencv dnn支持的功能
- 2、ANN_MLP相关知识
- 3、图像分类模型训练学习
- 4、目标检测模型
- 5、opencv调用darknet物体识别模型
- 三、模型训练
- 1、现状
- 2、步骤-模型编译
- 3、步骤-模型训练
一、需求
1、现状
现在有一个ppt插入软件,可以根据图片的名字,将对应的图片插入到ppt中去。
但是,既然都简化了,拍完的照片还需要挑选然后重命名,实际上也是一个麻烦且琐碎的活,于是试图简化这一步骤。
2、设想
将拍好的图片分类重命名
二、模型使用
1、opencv dnn支持的功能
Opencv Dnn可以对图像和视频完成基于深度学习的计算机视觉推理。opencv DNN支持的功能:
- 图像分类
- 目标检测
- 图像分割
- 文字检测和识别
- 姿态估计
- 深度估计
- 人脸验证和检测
- 人体重新识别
2、ANN_MLP相关知识
-
介绍
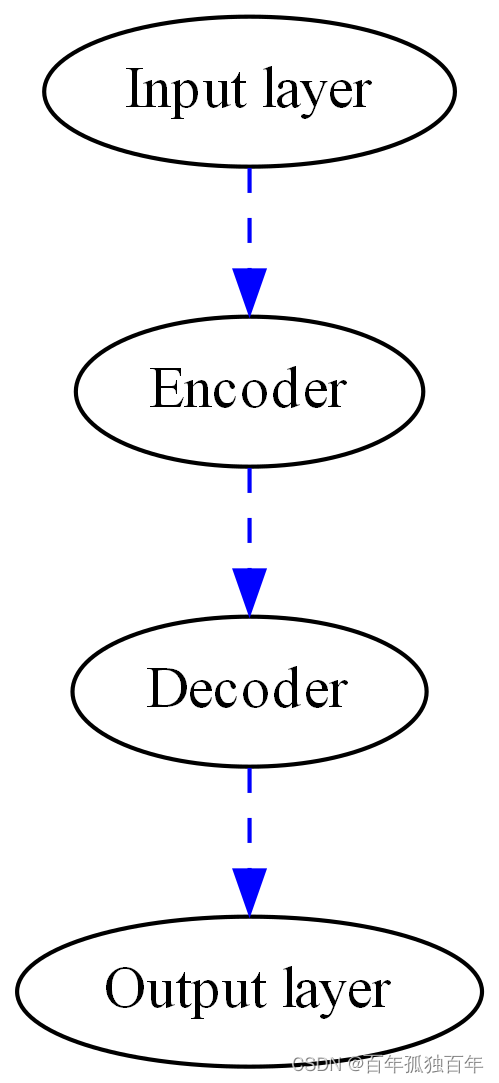
人工神经网络——多层感知器
先创建一个model,所有的权重都设置为0。
网络训练层使用一层输入和输出的向量,训练过程可以重复重复不止一次,权重可以基于新的训练数据调整权重
-
一些函数
-
create():创建一个model
-
setLayerSizes():指定每层中神经元的数量,包括输入和输出层。第一个元素指定输入图层中的元素数。最后一个元素-输出图层中的元素数
例子的数量要和标签的数量相同。第一项为图片的像素数,最后一项 为训练的种类数
Mat layerSizes = (Mat_<int>(1, 4) << image_rows*image_cols, int(image_rows*image_cols / 2), int(image_rows*image_cols / 2), class_num);bp->setLayerSizes(layerSizes); -
setActivationFunction():设置激活函数
setActivationFunction(int type, double param1 = 0, double param2 = 0)type 含义 IDENTITY f ( x ) = x f(x) = x f(x)=x SIGMOID_SYM f ( x ) = β ∗ 1 − e α x 1 + e − α x f(x) = \beta * \frac{1 - e^{\alpha x}}{1+e^{-\alpha x}} f(x)=β∗1+e−αx1−eαx GAUSSIAN f ( x ) = β e − α x ∗ x f(x) = \beta e^{-\alpha x*x} f(x)=βe−αx∗x RELU f ( x ) = m a x ( 0 , x ) f(x) = max(0,x) f(x)=max(0,x) LEAKYRELU 对于x>0, f ( x ) = x f(x) = x f(x)=x;对于x<0, f ( x ) = α x f(x) = \alpha x f(x)=αx bp->setActivationFunction(ANN_MLP::SIGMOID_SYM, 1, 1); -
setTrainMethod()
训练方式/传播方式
cv::ml::ANN_MLP::setTrainMethod(int method,double param1 = 0,double param2 = 0 )method 函数 BACKPROP 反向传播算法 RPROP 弹性反向传播 ANNEAL 模拟退火算法 -
setTermCriteria
设置迭代算法终止的判断条件
TermCriteria:迭代算法终止的判断条件
class CV_EXPORTS TermCriteria { public:enum Type{COUNT = 1;MAX_ITER=COUNT;EPS=2;}TermCriteria(int type, int maxCount, double epsilon);int type;int maxCount;double epsilon; }类变量有三个参数:类型、迭代的 最大次数、特定的阈值
-
加载分类器
Ptr<ANN_MLP> bp = StatModel::load<ANN_MLP>("*.xml"); Ptr<ANN_MLP> bp = ANN_MLP::load<ANN_MLP>("*.xml"); Ptr<ANN_MLP> bp = Algorithm::load<ANN_MLP>("*.xml"); -
predict函数
float predict( InputArray samples, OutputArray results=noArray(), int flags=0 )最终的预测结果 应该是第二个参数OutputArray results
-
3、图像分类模型训练学习
没试过相关的模型训练,先尝试一下,参考:https://blog.csdn.net/qq_15985873/article/details/125087166
#include <iostream>
#include <opencv2/opencv.hpp>
#include <vector>
using namespace std;
using namespace cv;
using namespace ml;#define ROW 45
#define COL 30
#define TYPE_NUM 5
#define SUM 100
// string fruits[5] = {"apple", "cabbage", "carrot", "cucumber", "pear"};
string fruits[5] = {"apple", "cabbage", "carrot", "banana", "pear"};
Mat Label = Mat::eye(5, 5, CV_32FC1);void fruitAnnPrePro(Mat &src, Mat &dst) {src.convertTo(src, CV_32FC1);resize(src, src, Size(ROW, COL));dst.push_back(src.reshape(0,1));
}void trainChar(string &root_path, string &model_path) {vector<string> dir_path;for(string s : fruits)dir_path.push_back(root_path + s +"\\");Mat trainDataMat,trainLabelMat;vector<vector<string>> files(TYPE_NUM, vector<string>());for(int i = 0; i < dir_path.size(); i++) {glob(dir_path[i], files[i], false);}for(int i = 0; i < dir_path.size(); i++) {printf("%d size %d\n", i, files[i].size() );}for(int i = 0; i < files.size(); i++) {for(int j = 0; j < files[i].size(); j++) {Mat src = imread(files[i][j], IMREAD_GRAYSCALE);if(src.empty()){break;}fruitAnnPrePro(src, trainDataMat);trainLabelMat.push_back(Label.row(i));}}imshow("trainData", trainDataMat);waitKey(0);cout << trainDataMat.size() << endl;cout << trainLabelMat.size() << endl;Ptr<ANN_MLP> model = ANN_MLP::create();Mat labelSizes = (Mat_<int>(1,5) << 1350, 1350, 1350, 10, TYPE_NUM);model->setLayerSizes(labelSizes);model->setActivationFunction(ANN_MLP::SIGMOID_SYM, 1, 1);model->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER + TermCriteria::EPS, 300,0.95));model->setTrainMethod(ANN_MLP::BACKPROP, 0, 1);Ptr<TrainData> trainData = TrainData::create(trainDataMat, ROW_SAMPLE, trainLabelMat);printf("开始训练!\n");model->train(trainData);// //保存模型model->save(model_path);printf("+++++++++++++++++++++++++++训练完成+++++++++++++++++++++++++++\n\n");
}void useModel(string imgPath, string &model_path) {Mat src = imread(imgPath, IMREAD_GRAYSCALE);Mat testDataMat;fruitAnnPrePro(src, testDataMat);Ptr<ANN_MLP> model = ANN_MLP::create();model = Algorithm::load<ANN_MLP>(model_path);Mat res;double maxVal;Point maxLoc;for(int i = 0; i < testDataMat.rows; i++) {model->predict(testDataMat.row(i), res);cout << format(res, Formatter::FMT_NUMPY) << endl;minMaxLoc(res, NULL, &maxVal, NULL, &maxLoc);printf("测试结果:%s 置信度: %f% \n", fruits[maxLoc.x].c_str(), maxVal * 100);}
}int main() {// string rootpath = "cpp\\opencv\\fruitClassify\\img\\";string rootpath = "C:\\Users\\CaCu999\\Pictures\\img\\";string modelpath = "cpp\\opencv\\fruitClassify\\model\\fruitModel.xml";trainChar(rootpath, modelpath);// string imgpath = "cpp\\opencv\\fruitClassify\\img\\apple\\r1_304.jpg";string imgpath = "C:\\Users\\CaCu999\\Pictures\\img\\banana\\10.jpg";useModel(imgpath, modelpath);return 0;
}
4、目标检测模型
-
知识了解
仔细想想,我需要的不是图像的分类,而是内部的物体的识别。所以需要的是目标检测
https://blog.csdn.net/virobotics/article/details/124008160
-
物体识别的概念
需要解决的问题是目标在哪里以及其状态
秒检测用的比较多的主要是RCNN,spp-net,fast-rcnn;yolo系列(yolov3和yolov4);还有SSD,ResNet等
-
YOLO算法概述
对出入的图片,将图片分为mxm个方格。当某个物体的中心点落在了某个方格中,该方格负责预测该物体。每个方格会被预测物体产生n个候选框并生成每个框的置信度。最后选区置信度比较高的方框作为结果
5、opencv调用darknet物体识别模型
-
darknet模型获取
-
文件
- cfg文件:模型描述文件
- weights文件:模型权重文件
-
yolov3
https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
https://pjreddie.com/media/files/yolov3.weightshttps://github.com/pjreddie/darknet/blob/master/data/coco.names
-
yolov4
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.cfg
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
-
-
python代码
直接粘贴的
import cv2 cv=cv2 import numpy as np import time#读取模型 net = cv2.dnn.readNetFromDarknet("cpp\\opencv\\ObjectDetection\\model\\yolov3.cfg", "cpp\\opencv\\ObjectDetection\\model\\yolov3.weights") #gpu计算之类的…… # net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA) # net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA) #阈值 confThreshold = 0.5 #Confidence threshold nmsThreshold = 0.4 #Non-maximum suppression threshold #读取图片 frame=cv2.imread("cpp\\opencv\\ObjectDetection\\img\\20221122_110416.jpg") #等比例缩小 frame = cv2.resize(frame,((int)(frame.shape[1]/10),(int)(frame.shape[0]/10))) print(frame.shape[0] * frame.shape[1] / 100) #标签文件并读取所有的标签 classesFile = "cpp\\opencv\\ObjectDetection\\model\\coco.names"; classes = None with open(classesFile, 'rt') as f:classes = f.read().rstrip('\n').split('\n')#读取网络名字 def getOutputsNames(net):# Get the names of all the layers in the networklayersNames = net.getLayerNames()# Get the names of the output layers, i.e. the layers with unconnected outputsreturn [layersNames[i - 1] for i in net.getUnconnectedOutLayers()] print(getOutputsNames(net)) # Remove the bounding boxes with low confidence using non-maxima suppressiondef postprocess(frame, outs):frameHeight = frame.shape[0]frameWidth = frame.shape[1]# Scan through all the bounding boxes output from the network and keep only the# ones with high confidence scores. Assign the box's class label as the class with the highest score.classIds = []confidences = []boxes = []# 解析结果for out in outs:print(out.shape)for detection in out:scores = detection[5:]classId = np.argmax(scores)confidence = scores[classId]if confidence > confThreshold:center_x = int(detection[0] * frameWidth)center_y = int(detection[1] * frameHeight)width = int(detection[2] * frameWidth)height = int(detection[3] * frameHeight)left = int(center_x - width / 2)top = int(center_y - height / 2)classIds.append(classId)confidences.append(float(confidence))boxes.append([left, top, width, height])# Perform non maximum suppression to eliminate redundant overlapping boxes with# lower confidences.print(boxes)print(confidences) indices = cv2.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold) for i in indices:#print(i)#i = i[0]box = boxes[i]left = box[0]top = box[1]width = box[2]height = box[3]drawPred(classIds[i], confidences[i], left, top, left + width, top + height)# Draw the predicted bounding box def drawPred(classId, conf, left, top, right, bottom):# Draw a bounding box.cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255))label = '%.2f' % conf # Get the label for the class name and its confidenceif classes:assert(classId < len(classes))label = '%s:%s' % (classes[classId], label)#Display the label at the top of the bounding boxlabelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)top = max(top, labelSize[1])cv2.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255)) #读取图片,改为416*416的大小 blob = cv2.dnn.blobFromImage(frame, 1/255, (416, 416), [0,0,0], 1, crop=False) t1=time.time() #设置输入的图片获取结果 net.setInput(blob) #使用模型 outs = net.forward(getOutputsNames(net)) print(time.time()-t1) postprocess(frame, outs) t, _ = net.getPerfProfile() label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency()) cv2.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255)) print(frame.shape) cv2.imshow("result",frame) cv2.waitKey(0) -
遇到的一些问题
-
blobFromImage(frame, (double)1/255, Size(416, 416),Scalar(0,0,0), true);需要注意这里的收缩比例以及需要转为double
-
net.forward的输出结果
一共80个label,输出结果为n*85。第1和2个是方框中心点(x,y)的位置的比例。第3和4个是宽和高的比例。第五个不知道。后面的80个是这个区域的每个标签的可能性
所以针对这个结果,需要做的是:从后面80个结果里面获取最大值和索引。这个索引也就是label的索引。如果这个最大值大于置信度的阈值,就获取前面的选框区域
-
-
c++代码
#include <iostream> #include <opencv2/opencv.hpp> #include <fstream>using namespace std; using namespace cv; using namespace dnn;void readClasses(vector<string> &classes, string classFile) {ifstream readFile;readFile.open(classFile);if(readFile.is_open()) {// printf("文件打开成功!\n开始读取内容……\n");string label;while(getline(readFile, label)) {// printf("%s\n", label.c_str());classes.push_back(label);}// printf("读取结束,一共%d个标签\n", classes.size());} else {cerr << "文件打开失败" << endl;}readFile.close(); }vector<string> getOutputsNames(Net net) {vector<string> layers = net.getLayerNames();cout << layers.size()<< endl;//获得末端连接神经网络名字,用于指定forward输出层的名字auto idx = net.getUnconnectedOutLayers();vector<string> res;for(int i = 0; i < idx.size(); i++) {res.push_back(layers[idx[i] - 1]);}for(int i = 0; i < res.size(); i++) {cout << res[i] << endl;}return res; }void readAndGetRes(string imgPath,Mat &frame, vector<Mat> &outs) {Net net = readNetFromDarknet("cpp\\opencv\\ObjectDetection\\model\\yolov3.cfg", "cpp\\opencv\\ObjectDetection\\model\\yolov3.weights");frame = imread(imgPath);resize(frame, frame, Size(frame.cols / 10, frame.rows / 10));string classFile = "cpp\\opencv\\ObjectDetection\\model\\coco.names";Mat blob = blobFromImage(frame, (double)1/255, Size(416, 416),Scalar(0,0,0), true);time_t startTime;time(&startTime);net.setInput(blob);net.forward(outs, getOutputsNames(net)); }void postProcess(Mat &frame,vector<Mat> probs) {vector<string> classes;readClasses(classes, "cpp\\opencv\\ObjectDetection\\model\\coco.names");int w = frame.cols;int h = frame.rows;float confThreshold = 0.5;float nmxThreshold = 0.4;vector<int> classIds;vector<float> confidences;vector<Rect> boxes;for(auto prob: probs) {cout << prob.size() << endl;for(int i = 0; i < prob.rows; i++) {//获取该选框的所有label的可能性Mat scores = prob.row(i).colRange(5, prob.cols);//获取选框的位置vector<float> detect = prob.row(i).colRange(0, 4);Point maxLoc;double confidence;//获取最大可能的可能性以及它的索引minMaxLoc(scores, 0, &confidence, 0, &maxLoc);if(confidence > confThreshold) {printf("confidence %0.2f, loc %s, %0.2f %0.2f %0.2f %0.2f %0.2f\n",confidence, classes[maxLoc.x].c_str(), detect[0], detect[1], detect[2], detect[3], detect[4]);int center_x = detect[0] * w;int center_y = detect[1] * h;int width = detect[2] * w;int height = detect[3] * h;Rect box = Rect(center_x - width / 2, center_y - height / 2, width, height);boxes.push_back(box);confidences.push_back(confidence);classIds.push_back(maxLoc.x);}}}vector<int> indices;NMSBoxes(boxes, confidences, confThreshold, nmxThreshold, indices);cout << "the res " << indices.size() << endl;for(int i:indices) {cout << i << endl;rectangle(frame, boxes[i], Scalar(0, 0, 255));string label = format("%s:%0.2f%", classes[classIds[i]].c_str(), confidences[i]*100);cout << label << endl;putText(frame, label, Point(boxes[i].x,boxes[i].y), FONT_HERSHEY_SIMPLEX,0.5,Scalar(255,255,255));cout << label << endl;}cout << "this is end" << endl;imshow("label frame",frame);waitKey(0); }int main() {vector<Mat> res;Mat img;readAndGetRes("cpp\\opencv\\ObjectDetection\\img\\20221122_110416.jpg", img, res);postProcess(img, res);return 0; }上述部分参考自:https://blog.csdn.net/virobotics/article/details/124008160
三、模型训练
1、现状
之前尝试了使用yolo3进行了图像的识别,但是里面的label跟我说需要的不匹配,尝试针对自己的需求进行模型训练
2、步骤-模型编译
-
下载代码
git clone https://github.com/pjreddie/darknet.git -
源码编译-环境准备
https://blog.csdn.net/m0_52571715/article/details/109713440
-
环境准备
-
GitBash运行make命令,提示bash: make: command not found
说明我现有的环境变量里面不包含make.exe
我现有的环境已经有c++的套件,去mingw/bin目录下看了一下,确实没有make.exe
于是去网上下了一个make.exe复制进去了http://www.equation.com/servlet/equation.cmd?fa=make
-
尝试编译的时候发现,没有cuda库
https://blog.csdn.net/weixin_43848614/article/details/117221384
-
下载:https://developer.nvidia.com/cuda-toolkit-archive
-
安装


-
环境变量
添加刚刚安装的位置NVIDIA GPU Computing Toolkit的那个
-
测试
打开cmd
> nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2020 NVIDIA Corporation Built on Tue_Sep_15_19:12:04_Pacific_Daylight_Time_2020 Cuda compilation tools, release 11.1, V11.1.74 Build cuda_11.1.relgpu_drvr455TC455_06.29069683_0
-
-
windows编译和解编译问题-失败了所以重来
-
Makefile:修改GPU=1
GPU=1 CUDNN=0 OPENCV=0 OPENMP=0 DEBUG=0 -
Makefile:修改/usr/local/cuda/include/改成自己的路径
-
include/darknet.h:780:11: error: unknown type name ‘clock_t’;
-
改成clockid_t
include/darknet.h:780:11: error: unknown type name 'clock_t'; did you mean 'clockid_t'?float sec(clock_t clocks);^~~~~~~clockid_t compilation terminated due to -Wfatal-errors. -
直接注释了
修改了类型以后冲突了,直接把这个头文件里面的注释了试试看
./src/utils.h:48:7: error: conflicting types for 'sec'float sec(clock_t clocks);^~~ compilation terminated due to -Wfatal-errors. make: *** [makefile:89: obj/gemm.o] Error 1
-
-
nvcc fatal : Unsupported gpu architecture ‘compute_30’
compute_30已经被cuda11放弃使用了,修改Makefile
ARCH= -gencode arch=compute_30,code=sm_30 \-gencode arch=compute_35,code=sm_35 \-gencode arch=compute_50,code=[sm_50,compute_50] \-gencode arch=compute_52,code=[sm_52,compute_52]ARCH= -gencode arch=compute_35,code=sm_35 \-gencode arch=compute_50,code=[sm_50,compute_50] \-gencode arch=compute_52,code=[sm_52,compute_52] -
nvcc fatal : Cannot find compiler ‘cl.exe’ in PATH
懒得再装了,印象里好像在别的地方安装过。去搜了一下,在
./Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.35.32215/bin/Hostx86/x86/cl.exe找到了先试试看直接把文件复制到cuda目录下面,似乎可以了
-
nvcc fatal : Failed to preprocess host compiler properties
配置cudnn

-
-
卸载并重新安装visual studio
后面在尝试的过程中,出现了visual studio版本不对的通知,建议为2015-2019。本来直接跳过的,但是后面报错编译不过了QAQ
-
卸载vs

-
下载2019
https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/

-
安装



-
-
重新下载代码编译
-
下载:
git clone https://github.com/AlexeyAB/darknet -
打开PowerShell 管理员,输入
Set-ExecutionPolicy RemoteSigned
-
进入darknet目录执行:
.\build.ps1
从过程里面看
-
下载了vcpkg

-
确认VS

-
确认CUDA

-
编译命令及版本确认

-
cmake版本不对于是重新下

-
powershell版本不对又下

……后面太多了,懒得一一看了
-
-
-
-
3、步骤-模型训练
https://blog.csdn.net/qq_38915710/article/details/97112788
-
准备数据集
根目录新建myData文件夹,在myData文件夹下再新建三个文件夹,分别为annotations、ImageSets、JPEGImages,其中annotations文件下存放xml文件,ImageSets下新建main文件夹,其中建一个train.txt,其中放图片名称(不要带.jpg,只是单独的图片名称),JPEGImages下放要训练的图片。
-
读取所有文件名
#include <io.h> #include <vector>void readImageFile(string filePath) {struct _finddata_t fileinfo;intptr_t file_ptr;file_ptr = _findfirst(filePath.c_str(), &fileinfo);vector<string> files;if(file_ptr != -1) {do {cout << fileinfo.name << " ";string name = fileinfo.name;int idx = name.find_last_of('.');if (idx == -1) continue; string type = name.substr(idx);if(type == ".jpg" || type == ".jpeg" || type == ".png") {cout << name.substr(0, idx) << endl;files.push_back(name.substr(0, idx));}} while ((_findnext(file_ptr, &fileinfo)) == 0);_findclose(file_ptr);}ofstream outfile;outfile.open("D:\\Project\\OpencvProject\\darknet\\myData\\ImageSets\\main\\train.txt");if (!outfile.is_open()) {cerr << "open file failed" << endl;}for (string name : files) {outfile << name << endl;}outfile.close(); }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-334444qg-1681956764395)(opencv场景识别.assets/image-20230418144352893.png)]
-
准备标签
-
下载labelimg:
pip install labelimg后面下载了labelimg的代码,然后压成exe文件
pyinstaller.exe --hidden-import=xml --hidden-import=xml.etree --hidden-import=xml.etree.ElementTree --hidden-import=lxml.etree -D -F -n labelImg -c "../labelImg.py" -p ../libs -p ../
-
启动


-
加标签

-
转换标签
python的(复制来的)
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import joinsets=[('myData', 'train')] #元组数组classes = ['screen'] # each category's namedef convert(size, box):dw = 1./(size[0])dh = 1./(size[1])x = (box[0] + box[1])/2.0 - 1y = (box[2] + box[3])/2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)def convert_annotation(wd, year, image_id):#读取xml,输出为txt文件in_file = open(wd + './Annotations/%s.xml'%(image_id))out_file = open(wd + './labels/%s.txt'%(image_id), 'w')#读取xml内容tree=ET.parse(in_file)root = tree.getroot() #这两行表示从xml文件中读取内容size = root.find('size') #从读取到的xml内容中发现sizew = int(size.find('width').text) #取宽度h = int(size.find('height').text) #取高度for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textcls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))try:bb = convert((w,h), b)except:print(image_id)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')if __name__ == '__main__':wd = getcwd() #返回当前工作目录wd += '/darknet/myData/' #定位到数据目录classes = open(wd + './Annotations/classes.txt').read().strip().split()print(classes)for year, image_set in sets:#判断并创建labels目录if not os.path.exists(wd + './labels/'): #os.path.exists("")表示如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False。os.makedirs(wd + './labels/') #创建目录#读取train.txt下所有的图片名字image_ids = open(wd + './ImageSets/main/%s.txt'%(image_set)).read().strip().split() #打开该文件,并一次性读取该文件所有内容,再去掉文本中句子开头与结尾的符号的print(wd + './%s_%s.txt'%(year, image_set))# 在myData目录下创建myData_train文件list_file = open(wd + './%s_%s.txt'%(year, image_set), 'w') #打开myData_train该文件for image_id in image_ids:#在myData_train目录下写入图片的绝对路径-(有些问题,可能后缀不是jpg)list_file.write('%s/JPEGImages/%s.jpg\n'%(wd, image_id)) #在myData_train.txt里面写入图片地址+名称convert_annotation(wd, year, image_id)list_file.close()c++
本来想转为c++的实现的,但是后面发现,转化出来的结果与yonglabelImage的时候直接选择yolo格式一致=。=,只有精度有点区别。用c++先来一波复制
#include <iostream> #include <io.h> #include <vector> #include <fstream> using namespace std;void readImageFile(string root) {string filePath = root + ".\\JPEGImages\\*";struct _finddata_t fileinfo;intptr_t file_ptr;file_ptr = _findfirst(filePath.c_str(), &fileinfo);filePath = filePath.substr(0, filePath.size()-1);vector<string> files;vector<string> absfiles;if(file_ptr != -1) {do {// cout << filePath + fileinfo.name << " ";string name = fileinfo.name;int idx = name.find_last_of('.');if (idx == -1) continue; string type = name.substr(idx);if(type == ".jpg" || type == ".jpeg" || type == ".png") {// cout << name.substr(0, idx) << endl;//保存文件名和绝对路径files.push_back(name.substr(0, idx));absfiles.push_back(filePath + name);}} while ((_findnext(file_ptr, &fileinfo)) == 0);_findclose(file_ptr);}//写入文件名和绝对路径ofstream outfile;ofstream trainfile;outfile.open(root + ".\\ImageSets\\main\\train.txt");trainfile.open(root + ".\\myData_train.txt");if (!outfile.is_open() || !trainfile.is_open()) {cerr << "open file failed" << endl;}for (int i = 0; i < files.size(); i++) {outfile << files[i] << endl;trainfile << absfiles[i] << endl;}outfile.close();trainfile.close();//调用cmd命令创建label文件夹string labelspath = root + "labels\\";string cmd = "mkdir " + labelspath;system(cmd.c_str());cmd = "copy " + root + ".\\Annotations\\*.txt " + labelspath;system(cmd.c_str()); }int main() {string root = "D:\\Project\\OpencvProject\\darknet\\myData\\";readImageFile(root);return 0; }
-
-
-
训练数据
-
准备文件
-
ImgDetect.data
#类数 classes= 23 #训练数据集 train = myData/myData_train.txt #测试数据集 valid = myData/myData_train.txt #类名 names = myData/labels/classes.txt #结果 backup = myData/ -
yolo.cfg
[net]
batch为一次可训练的图片数量
subdivision是分割一次训练数量的值(使用该参数可以让显卡较差的电脑也能够使用高batch进行训练)。其两者的关系就是batch÷subdivision=实际上一次训练图片数量
width和height是输入图片的尺寸,这个无需改变,只要是16的倍数即可
max_batches是总共训练的轮数(官方推荐是:种类量2000,但最少6000。即如果你训练一个种类。则填6000,若训练4个种类则填8000)
steps的值设置为0.6max_batches和0.8*max_batches即可https://blog.csdn.net/weixin_52939176/article/details/122554179

[convolutional]和[yolo]
主要修改,如上图所示的【convolutional】和【yolo】组(在yolo-tiny算法中共两组,yolo算法中三组)
修改filters为:(种类数+5)*3,即种类数8,(8+5)*3=39
修改classes为种类数
-
yolov3.weights
需要和.cfg文件对应,直接去网上找
-
-
开始训练
darknet.exe detector train cfg_myData/ImgDetect.data cfg_myData/yolov3.cfg cfg_myData/yolov3.weights
!可能是数据太少了,结果很差。重新来一下QAQ
csdn的图片也太难传了,居然要一张张图片往里贴
-