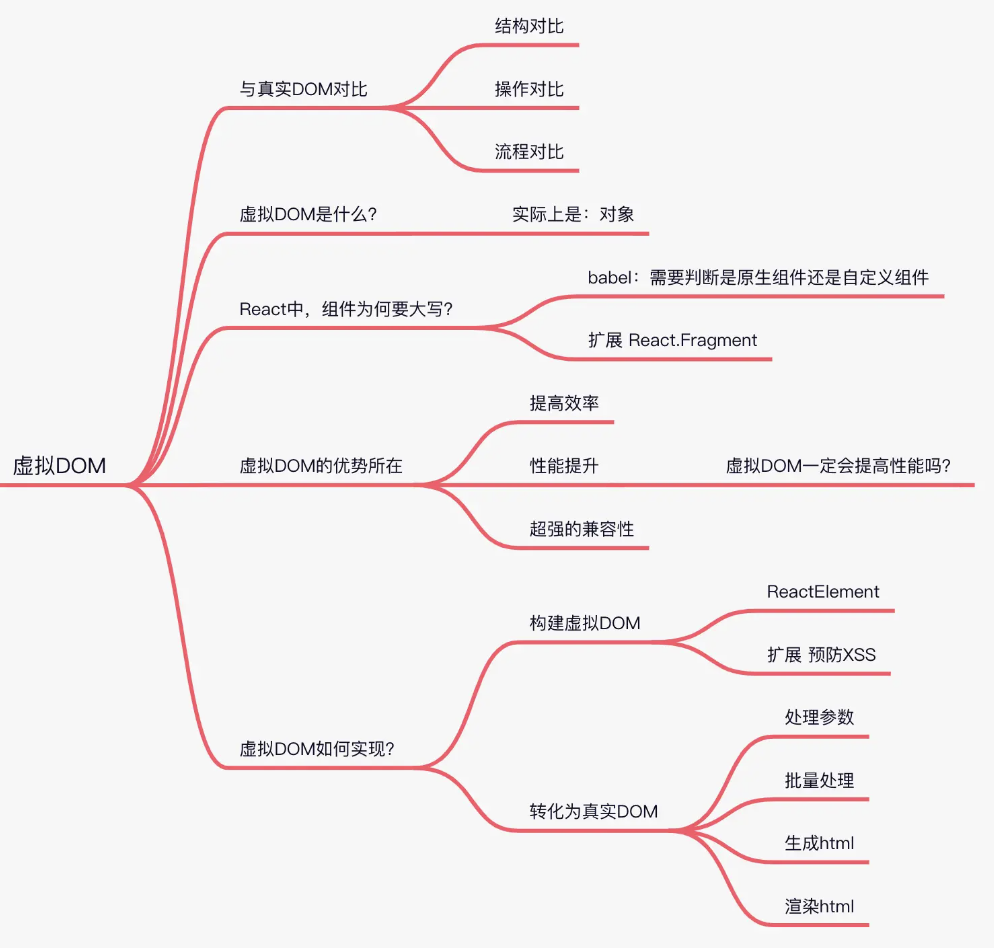
Apscheduler 介绍
四大组件
- triggers:触发器,用于设定触发任务的条件
- job stores:作业存储器,用于存放任务,可以存放在数据库或内存,默认内存
- executors:执行器,用于执行任务,可以设定执行默认为单线程或线程池
- schedulers:调度器,将上述三个组件作为参数,通过创建调度器实例来执行
触发器 triggers
每个任务都有自己的触发器,它可以决定任务触发的条件,触发器默认是无状态的。
作业存储器 job stores
默认存储在内存中,若存储到数据库中会有个序列化和反序列化的过程,同时修改和搜索任务的功能也是由它实现。
一个作业存储器不要共享给多个调度器,不然会造成状态混乱
执行器 executors
将任务放入线程或线程池中执行,执行完毕通知调度器
调度器 schedulers
调度器提供接口,可以将触发器、作业存储器和执行器整合起来,从而实现对任务的操作。
调度器组件
- BlockingScheduler 阻塞式调度器:适用于只跑调度器的程序。
- BackgroundScheduler 后台调度器:适用于非阻塞的情况,调度器会在后台独立运行。
- AsyncIOScheduler AsyncIO调度器,适用于应用使用AsnycIO的情况。
- GeventScheduler Gevent调度器,适用于应用通过Gevent的情况。
- TornadoScheduler Tornado调度器,适用于构建Tornado应用。
- TwistedScheduler Twisted调度器,适用于构建Twisted应用。
- QtScheduler Qt调度器,适用于构建Qt应用。
选择正确的调度器、作业存储器、触发器和执行器
1、作业存储器
- 作业不需要持久化:默认的
MemoryJobStore - 作业需要持久化:作业在调度程序重启或应用程序奔溃后继续存在,推荐采用:
SQLAlchemyJobStore + PostgreSQL
2、执行器
- 默认
ThreadPoolExecutor线程池足以满足大多数场景 - CPU 密集型操作:应考虑
ProcessPoolExecutor进程池,来充分利用多核算力。也可以将ProcessPoolExecutor作为第二执行器,混合使用两种不同的执行器。
触发器详解
一个任务可以设定多种触发器,如全部条件满足触发、满足其一触发以及复合触发等:
可参考:https://apscheduler.readthedocs.io/en/latest/modules/triggers/combining.html#module-apscheduler.triggers.combining
内置的三种触发器类型
date:在特定时间仅允许一次作业interval:固定时间间隔允许作业cron:一天中特定时间定期允许作业
指定时间任务 date
三种类型:date/datetime/字符串,不加时间则立即执行:
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job(text):print(text)sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text'])
sched.add_job(my_job, 'date', run_date=datetime(2020, 1, 7, 14, 35, 2), args=['text'])
sched.add_job(my_job, 'date', run_date='2009-11-06 16:30:05', args=['text'])
sched.add_job(my_job, args=['text'])sched.start()
参考:apscheduler.triggers.date
间隔任务 interval
from datetime import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
import osdef tick():print('当前时间:', datetime.now())if __name__ == '__main__':scheduler = BlockingScheduler() # 默认调度器,存入在内存中scheduler.add_job(tick, 'interval', seconds=3) # 添加到作业中print('按 Ctrl+{0} 终端任务'.format('Break' if os.name == 'nt' else 'c '))try:scheduler.start()except (KeyboardInterrupt, SystemError):pass
运行结果如下:
按 Ctrl+Break 终端任务
当前时间: 2020-01-07 13:55:37.540614
当前时间: 2020-01-07 13:55:40.540879
当前时间: 2020-01-07 13:55:43.542759
当前时间: 2020-01-07 13:55:46.542512
当前时间: 2020-01-07 13:55:49.541907
当前时间: 2020-01-07 13:55:52.541845
当前时间: 2020-01-07 13:55:55.542011
当前时间: 2020-01-07 13:55:58.542533
指定开始、结束时间:
# 指定开始、结束时间
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())sched.add_job(my_job, 'interval', seconds=3, start_date='2020-01-07 14:45:20', end_date='2020-01-07 14:46:20')sched.start()
装饰器:
@sched.scheduled_job('interval', id='job_id', seconds=3)
def my_job():print('当前时间:', datetime.now())
jitter 振动参数,给每次触发添加一个随机浮动秒数,一般适用于多服务器,避免同时运行造成服务拥堵。
# 每小时(上下浮动120秒区间内)运行`job_function`
sched.add_job(job_function, 'interval', hours=1, jitter=120)
参考:apscheduler.triggers.interval
crontab表达式 cron
参数
pscheduler.triggers.cron.CronTrigger(year = None,month = None,day = None,week = None,day_of_week = None,hour = None,minutes = None,second = None,start_date = None,end_date = None,timezone = None,jitter = None )
参数详解
- year (int|str) – 4-digit year
- month (int|str) – month (1-12)
- day (int|str) – day of the (1-31)
- week (int|str) – ISO week (1-53)
- day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun)
- hour (int|str) – hour (0-23)
- minute (int|str) – minute (0-59)
- second (int|str) – second (0-59)
- start_date (datetime|str) :开始触发事件
- end_date (datetime|str) :结束时间
- timezone (datetime.tzinfo|str) 用于日期、时间计算的时区,默认为调度程序时区
- jitter (int|None) :作业最多延迟多久执行
表达式类型
| 表达式 | 参数类型 | 描述 |
|---|
- | 所有 | 通配符,minute=* 即每分钟触发一次
*/a | 所有 | 可被 a 整除的通配符
a-b | 所有 | 范围 a -b 触发
a-b/c | 所有 | 范围 a-b,且可被 c 整除时触发
xth y | 日 | 第几个星期几触发,x 为第几个,y 为星期几
last x | 日 | 一个月中,最后那个星期几触发
last | 日 | 一个月中最后一天触发
x,y,z | 所有 | 组合表达式,可组合确定值或上方表达式
示例一
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())# 6/7/8 和 11/12 月的第三个周五的 0/1/2/3 点触发
sched.add_job(my_job, 'cron', month='6-8, 11-12', day='3rd fri', hour='0-3')sched.start()
示例二:指定时间范围
# 周一到周日,每天 15::9 触发,截止时间:2020-01-08
sched.add_job(my_job, 'cron', day_of_week='0-6', hour=15, minute=29, end_date='2020-01-08')
示例三:装饰器
# 每个月的最后一个星期日触发
@sched.scheduled_job('cron', id='job_id', day='last 6')
def my_job():print('当前时间:', datetime.now())
示例四:标准 crontab 表达式
sched.add_job(my_job, CronTrigger.from_crontab('0 0 1-15 may-aug *'))
添加 jitter 随机执行,适用于多台服务器在不同时间执行:
# 每小时上下浮动120秒触发
sched.add_job(my_job, 'cron', hour='*', jitter=120)
夏令时问题
有些时区可能因为夏令时问题,导致时区切换时,任务不执行或执行两次,这不是错误,要避免这个问题,可使用 UTC 时间,或提前规避,以下写法可能会导致错误:
# 在Europe/Helsinki时区, 在三月最后一个周一就不会触发;在十月最后一个周一会触发两次
sched.add_job(job_function, 'cron', hour=3, minute=30)
参考:apscheduler.triggers.cron
配置调度器
可通过直接传字典、传参或实例一个调度器对象,再添加配置信息的形式来配置调度器。
创建一个默认作业存储器和执行器:
from apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler()
- 调度器:
default的MemoryJonStore(内存任务存储器) - 执行器:
default,最大线程数为 10 的ThreadPoolExecutor线程池执行器
示例
应用场景:
两个作业存储器搭配两个执行器,同时又要修改作业的默认参数,还有修改时区。
- 名为 mongo 的 MemoryDBJobStore
- 名为 default 的 SQLAlchemyJobStore
- 名为 TreadPoolExecutor 的 ThreadPoolExecutor,最大线程 20
- 名为 processpool 的 ProcessPoolExecutor,最大进程 5
- UTC 时区作为默认调度器时区
- 默认为新任务关闭合并模式
- 设置新任务的默认最大实例数为 3
1、方法一:
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor# 作业存储器
jobstores = {'mongo': MongoDBJobStore(),'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}# 执行器
executors = {'default': ThreadPoolExecutor(20),'processpool': ProcessPoolExecutor(5)
}job_defaults = {'coalesce': False, # 关闭作业合并'max_instances': 3
}scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
2、方法二:
from apscheduler.schedulers.background import BackgroundScheduler# The "apscheduler." prefix is hard coded
scheduler = BackgroundScheduler({'apscheduler.jobstores.mongo': {'type': 'mongodb'},'apscheduler.jobstores.default': {'type': 'sqlalchemy','url': 'sqlite:///jobs.sqlite'},'apscheduler.executors.default': {'class': 'apscheduler.executors.pool:ThreadPoolExecutor','max_workers': '20'},'apscheduler.executors.processpool': {'type': 'processpool','max_workers': '5'},'apscheduler.job_defaults.coalesce': 'false','apscheduler.job_defaults.max_instances': '3','apscheduler.timezone': 'UTC',
})
3、方法三:
from pytz import utcfrom apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutorjobstores = {'mongo': {'type': 'mongodb'},'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {'default': {'type': 'threadpool', 'max_workers': 20},'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {'coalesce': False,'max_instances': 3
}
scheduler = BackgroundScheduler()# .. do something else here, maybe add jobs etc.scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
启用调度
调用 start() 即可启用调度,对于非阻塞的会立即返回,对于 BlockingScheduler 会阻塞的 start 位置,因此运行其他代码要写在 start 之前。
调度器启动后,就不能修改配置了。
添加任务
add_job():返回一个实例对象,通过对象可以修改、删除任务- 装饰器:
scheduled_job():运行时不能修改任务
任何时候都可添加任务,若调度器未启动,那么任务会处于一个暂存状态。当调度器启动时,才会计算下次运行时间。
若执行器和作业存储器是要序列化的任务的,那么必须满足
- 回调函数必须全局可用
- 回调函数参数必须可用被序列化
内置任务储存器中,只有MemoryJobStore不会序列化任务;内置执行器中,只有ProcessPoolExecutor会序列化任务。
另外若程序初始化时,从数据库读取任务,则必须为每个任务定义一个 ID,并使用 replace_existing=True,否则每次重启程序,都会得到一个新的任务拷贝,即前一个任务状态不会被保存。
Tips:立即执行任务,可在添加任务时省略 trigger 参数
移除任务
从调度器移除任务,也必须移除作业存储器中的任务。
remove_job(任务 ID):参数为任务 ID 或作业存储器名称- 调用
job=add_job()、job.remove()移除
对于通过 scheduled_job() 创建的任务,只能选择第一种方式。
示例:
job = sched.add_job(func, 'interval', minutes=2)
job.remove()sched.add_job(func, 'interval', minute=2, id='job_id')
sched.remove_job('job_id')
暂停恢复任务
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'cron', id='job_id', month='6-8, 11-12', day='3rd fri', hour='0-3')# 暂停作业
job.pause()
sched.pause_job('job_id')# 恢复作业
job.resume()
sched.remove_job('job_id')sched.start()
获取任务列表
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'cron', id='job_id', month='6-8, 11-12', day='3rd fri', hour='0-3')print('当前任务', sched.get_job('job_id'))
print('任务列表', sched.get_jobs())
print('格式化作业列表', sched.print_jobs())sched.start()
运行结果如下:
当前任务 my_job (trigger: cron[month='6-8,11-12', day='3rd fri', hour='0-3'], pending)
任务列表 [<Job (id=job_id name=my_job)>]
Pending jobs:my_job (trigger: cron[month='6-8,11-12', day='3rd fri', hour='0-3'], pending)
格式化作业列表 None
print_jobs() 可以快速打印格式化的任务列表,包含触发器,下次运行时间等信息。
修改任务
# 可修改除 ID 以外其他任务属性
job.modify(max_instances=6, name='Alternate name')
sched.modify_job(max_instances=6, name='Alternate name')# 修改触发器
# job.reschedule('job_id', trigger='cron', minute='*/5')
sched.reschedule_job('job_id', trigger='interval', minutes=4)
示例:
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())job = sched.add_job(my_job, 'interval', id='job_id', minutes=3)print('当前任务', sched.get_job('job_id'))# job.reschedule('job_id', trigger='cron', minute='*/5')
sched.reschedule_job('job_id', trigger='interval', minutes=4)
print('修改后的任务:', sched.get_job('job_id'))sched.start()
运行结果如下:
当前任务 my_job (trigger: interval[0:03:00], pending)
修改后的任务: my_job (trigger: interval[0:04:00], next run at: 2020-01-07 16:44:45 CST)
关闭调度
sched.shutdown()
sched.shutdown(wait=False) # 不等待正在运行的任务
限制作业并发执行实例数量
默认情况下,在同一时间,一个任务只允许一个执行中的实例在运行。比如说,一个任务是每5秒执行一次,但是这个任务在第一次执行的时候花了6秒,也就是说前一次任务还没执行完,后一次任务又触发了,由于默认一次只允许一个实例执行,所以第二次就丢失了。为了杜绝这种情况,可以在添加任务时,设置 max_instances 参数,为指定任务设置最大实例并行数。
丢失任务的执行与合并
有时,任务会由于一些问题没有被执行。最常见的情况就是,在数据库里的任务到了该执行的时间,但调度器被关闭了,那么这个任务就成了“哑弹任务”。错过执行时间后,调度器才打开了。这时,调度器会检查每个任务的 misfire_grace_time 参数 int 值,即哑弹上限,来确定是否还执行哑弹任务(这个参数可以全局设定的或者是为每个任务单独设定)。此时,一个哑弹任务,就可能会被连续执行多次。
但这就可能导致一个问题,有些哑弹任务实际上并不需要被执行多次。 coalescing 合并参数就能把一个多次的哑弹任务揉成一个一次的哑弹任务。也就是说,coalescing 为 True 能把多个排队执行的同一个哑弹任务,变成一个,而不会触发哑弹事件。
注!如果是由于线程池/进程池满了导致的任务延迟,执行器就会跳过执行。要避免这个问题,可以添加进程或线程数来实现或把 misfire_grace_time 值调高。
调度事件监听
任务执行时有可能会出现错误,那么如何第一时间指定在哪发生错误呢? apscheduler
给我们提供了事件监听来解决这个问题。
from datetime import date, datetimefrom apscheduler.schedulers.blocking import BlockingSchedulersched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())print(1/0)
上述代码每 5 秒钟执行一次,每次都会发生错误。我们给其添加一个回调函数和日志记录来监听:
from datetime import date, datetime
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
import logginglogging.basicConfig(level=logging.INFO,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%Y-%m-%d %H:%M:%S',filename='log.txt',filemode='a')sched = BlockingScheduler()def my_job():print('当前时间:', datetime.now())print(1 / 0)def test_job():print('正常任务!', datetime.now())def my_listener(event):if event.exception:print('任务运行出错!', datetime.now())else:print('任务正常运行!', datetime.now())job = sched.add_job(my_job, 'cron', second='*/5')
job1 = sched.add_job(test_job, 'interval', seconds=3)
sched.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
sched._logger = loggingsched.start()
事件类型
| Constant | Description | Event class |
|---|---|---|
| EVENT_SCHEDULER_STARTED | The scheduler was started SchedulerEvent | |
| EVENT_SCHEDULER_SHUTDOWN | The scheduler was shut down SchedulerEvent | |
| EVENT_SCHEDULER_PAUSED | Job processing in the scheduler was paused SchedulerEvent | |
| EVENT_SCHEDULER_RESUMED | Job processing in the scheduler was resumed SchedulerEvent | |
| EVENT_EXECUTOR_ADDED | An executor was added to the scheduler SchedulerEvent | |
| EVENT_EXECUTOR_REMOVED | An executor was removed to the scheduler SchedulerEvent | |
| EVENT_JOBSTORE_ADDED | A job store was added to the scheduler SchedulerEvent | |
| EVENT_JOBSTORE_REMOVED | A job store was removed from the scheduler SchedulerEvent | |
| EVENT_ALL_JOBS_REMOVED | All jobs were removed from either all job stores or one particular job store SchedulerEvent | |
| EVENT_JOB_ADDED | A job was added to a job store JobEvent | |
| EVENT_JOB_REMOVED | A job was removed from a job store JobEvent | |
| EVENT_JOB_MODIFIED | A job was modified from outside the scheduler JobEvent | |
| EVENT_JOB_SUBMITTED | A job was submitted to its executor to be run JobSubmissionEvent | |
| EVENT_JOB_MAX_INSTANCES | A job being submitted to its executor was not accepted by the executor because the job has already reached its maximum concurrently executing instances JobSubmissionEvent | |
| EVENT_JOB_EXECUTED | A job was executed successfully JobExecutionEvent | |
| EVENT_JOB_ERROR | A job raised an exception during execution JobExecutionEvent | |
| EVENT_JOB_MISSED | A job’s execution was missed JobExecutionEvent | |
| EVENT_ALL | A catch-all mask that includes every event type N/A |
日志
import logginglogging.basicConfig()
logging.getLogger('apscheduler').setLevel(logging.DEBUG)