2023年蜂巢科技最新面试题
bio与nio的区别
-
bio同步阻塞io:在此种⽅式下,⽤户进程在发起⼀个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,⽤户进程才能运⾏。JAVA传统的IO模型属于此种⽅式!
-
nio同步⾮阻塞式I/O;java NIO采⽤了双向通道进⾏数据传输,在通道上我们可以注册我们感兴趣的事件:连接事件、读写事件;NIO主要有三⼤核⼼部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进⾏操作,⽽NIO基于Channel和Buffer(缓冲区)进⾏操作,数据总是从通道读取到缓冲区中,或者从缓冲区写⼊到通道中。Selector(选择区)⽤于监听多个通道的事件(⽐如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
-
BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写⼊必须阻塞在⼀个线程内等待其完成。这⾥使⽤那个经典的烧开⽔例⼦,这⾥假设⼀个烧开⽔的场景,有⼀排⽔壶在烧开⽔,BIO的⼯作模式就是, 叫⼀个线程停留在⼀个⽔壶那,直到这个⽔壶烧开,才去处理下⼀个⽔壶。但是实际上线程在等待⽔壶烧开的时间段什么都没有做。
-
NIO (New I/O):同时⽀持阻塞与⾮阻塞模式,但这⾥我们以其同步⾮阻塞I/O模式来说明,那么什么叫做同步⾮阻塞?如果还拿烧开⽔来说,NIO的做法是叫⼀个线程不断的轮询每个⽔壶的状态,看看是否有⽔壶的状态发⽣了改变,从 ⽽进⾏下⼀步的操作。
-
AIO ( Asynchronous I/O):异步⾮阻塞I/O模型。异步⾮阻塞与同步⾮阻塞的区别在哪⾥?异步⾮阻塞⽆需⼀个线程 去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开⽔中就是,为每个⽔壶上⾯装了⼀个开关,⽔烧开之后,⽔壶会⾃动通知我⽔烧开了。
-
select与poll的区别
-
io多路复⽤:
-
概念:IO多路复⽤是指内核⼀旦发现进程指定的⼀个或者多个IO条件准备读取,它就通知该进程。
-
优势:与多进程和多线程技术相⽐,I/O多路复⽤技术的最⼤优势是系统开销⼩,系统不必创建进程/线程,也不必维护这些进程/线程,从⽽⼤⼤减⼩了系统的开销。
-
系统:⽬前⽀持I/O多路复⽤的系统调⽤有 select,pselect,poll,epoll。
-
-
select:select⽬前⼏乎在所有的平台上⽀持,其良好跨平台⽀持也是它的⼀个优点。select的⼀个缺点在于单个进程能够监视的⽂件描述符的数量存在最⼤限制,在Linux上⼀般为1024,可以通过修改宏定义甚⾄重新编译内核的⽅式提升这⼀限制,但是这样也会造成效率的降低。
-
poll:它没有最⼤连接数的限制,原因是它是基于链表来存储的,但是同样有⼀个缺点:
-
⼤量的fd的数组被整体复制于⽤户态和内核地址空间之间,⽽不管这样的复制是不是有意义。
-
poll还有⼀个特点是“⽔平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
-
epoll跟select都能提供多路I/O复⽤的解决⽅案。在现在的Linux内核⾥有都能够⽀持,其中epoll是Linux所特有,⽽select则应该是POSIX所规定,⼀般操作系统均有实现。
-
zookeeper的⼯作原理
-
定义:zookeeper是⼀种为分布式应⽤所设计的⾼可⽤、⾼性能且⼀致的开源协调服务,它提供了⼀项基本服务:分布式锁服务。后来摸索出了其他使⽤⽅法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
-
特点:
-
能够⽤在⼤型分布式系统中;
-
具有⼀致性、可⽤性、容错性,不会因为⼀个节点的错误⽽崩溃;
-
-
⽤途:⽤户⼤型分布式系统,作协调服务⻆⾊;
-
分布式锁应⽤:通过对集群进⾏master选举,来解决分布式系统中的单点故障(⼀主n从,主挂全挂)。
-
协调服务;
-
注册中⼼;
-
-
原理:
-
术语:
-
数据结构Znode:zookeeper数据采⽤树形层次结构,和标准⽂件系统⾮常相似,树中每个节点被称为Znode;
-
通知机制Watcher:zookeeper可以为所有的读操作(exists()、getChilden()及getData())设置watch,watch事件是⼀次性出发器,当watch的对象状态发⽣改变时,将会触发次对象上watch所对应的事件。watch事件将被异步的发送给客户端,并且zookeeper为watch机制提供了有序的⼀致性保证。
-
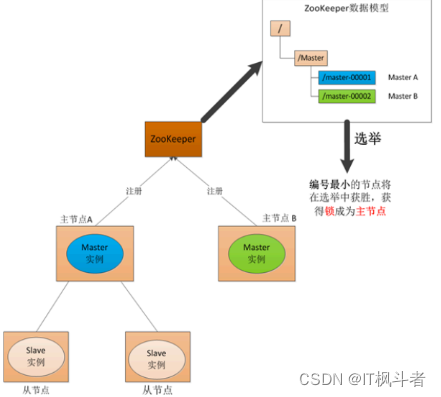
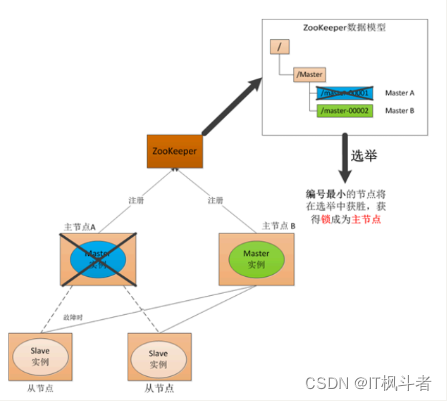
基本流程:分布式锁应⽤场景
-
传统的⼀主n从分布式系统,容易发⽣单点故障,传统解决⽅式是增加⼀个备⽤节点,定期给主节点发送Ping包,主节
点回复ack,但是如果⽹络原因ack丢失,那么会出现两个主节点,造成数据混乱。
zookeeper的引⼊可以管理两个主节点,其中挂了⼀个,会将另外⼀个作为新的主节点,挂的节点回来时担任备⽤节点
-
-

-
cap理论
-
概念:⼀个分布式系统最多只能同时满⾜⼀致性(Consistency)、可⽤性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
-
⼀致性:更新操作成功并返回客户端完成后,所有节点在同⼀时间的数据完全⼀致,所以,⼀致性,说的就是数据⼀ 致性。
-
可⽤性:服务⼀直可⽤,⽽且是正常响应时间。
-
分区容错性:分布式系统在遇到某节点或⽹络分区故障的时候,仍然能够对外提供满⾜⼀致性和可⽤性的服务。
⼆段式满⾜cap理论的哪两个理论
-
两阶段提交协议在正常情况下能保证系统的强⼀致性,但是在出现异常情况下,当前处理的操作处于错误状态,需要管理员⼈⼯⼲预解决,因此可⽤性不够好,这也符合CAP协议的⼀致性和可⽤性不能兼得的原理。
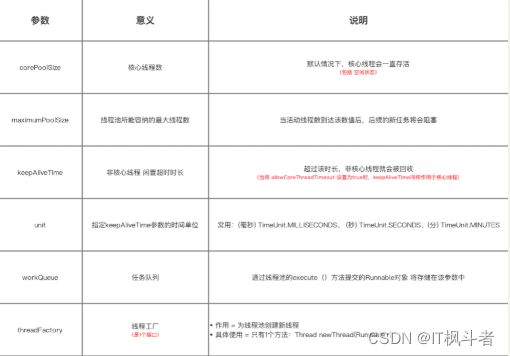
线程池的参数配置,为什么java官⽅提供⼯⼚⽅法给线程池
-
线程池简介:
-

-
核⼼参数:
-
-
⼯⼚⽅法作⽤:ThreadPoolExecutor类就是Executor的实现类,但ThreadPoolExecutor在使⽤上并不是那么⽅便,在实例化时需要传⼊很多歌参数,还要考虑线程的并发数等与线程池运⾏效率有关的参数,所以官⽅建议使⽤Executors⼯程类来创建线程池对象。
分布式框架dubbo的好处,不⽤dubbo可不可以。为什么要使⽤分布式
-
dubbo好处:
-
远程通讯: 提供对多种基于⻓连接的NIO框架抽象封装, 包括多种线程模型,序列化,以及“请求-响应”模式的信息交换⽅式。
-
软负载均衡及容错机制: 提供基于接⼝⽅法的透明远程过程调⽤,包括多协议⽀持,以及软负载均衡,失败容错,地址路由,动态配置等集群⽀持。可在内⽹替代F5等硬件负载均衡器,降低成本,减少单点。
-
服务⾃动注册与发现: 基于注册中⼼⽬录服务,使服务消费⽅能动态的查找服务提供⽅,使地址透明,使服务提供⽅可以平滑增加或减少机器 。
-
提供完善的管理控制台dubbo-admin与简单的控制中⼼dubbo-monitor
-
Dubbo提供了伸缩性很好的插件模型,很⽅便进⾏扩展(ExtensionLoader)
-
-
不⽤dubbo可不可以:可以,使⽤springcloud。
-
分布式作⽤:
-
系统之间的耦合度⼤⼤降低,可以独⽴开发、独⽴部署、独⽴测试,系统与系统之间的边界⾮常明确,排错也变得相当容易,开发效率⼤⼤提升。
-
系统之间的耦合度降低,从⽽系统更易于扩展。我们可以针对性地扩展某些服务。假设这个商城要搞⼀次⼤促,下单量可能会⼤⼤提升,因此我们可以针对性地提升订单系统、产品系统的节点数量,⽽对于后台管理系统、数据分析系统⽽⾔,节点数量维持原有⽔平即可。
-
服务的复⽤性更⾼。⽐如,当我们将⽤户系统作为单独的服务后,该公司所有的产品都可以使⽤该系统作为⽤户系统,⽆需重复开发。
-
七个垃圾回收器之间如何搭配使⽤
-
Serial New收集器是针对新⽣代的收集器,采⽤的是复制算法;
-
Parallel New(并⾏)收集器,新⽣代采⽤复制算法,⽼年代采⽤标记整理;
-
Parallel Scavenge(并⾏)收集器,针对新⽣代,采⽤复制收集算法;
-
Serial Old(串⾏)收集器,新⽣代采⽤复制,⽼年代采⽤标记清理;
-
Parallel Old(并⾏)收集器,针对⽼年代,标记整理;
-
CMS收集器,基于标记清理;7. G1收集器(JDK):整体上是基于标记清理,局部采⽤复制;
-
综上:新⽣代基本采⽤复制算法,⽼年代采⽤标记整理算法。cms采⽤标记清理;
接⼝限流⽅案
-
限制 总并发数(⽐如 数据库连接池、线程池)
-
限制 瞬时并发数(如 nginx 的 limit_conn 模块,⽤来限制 瞬时并发连接数)
-
限制 时间窗⼝内的平均速率(如 Guava 的 RateLimiter、nginx 的 limit_req 模块,限制每秒的平均速率)
-
限制 远程接⼝ 调⽤速率
-
限制 MQ 的消费速率
-
可以根据 ⽹络连接数、⽹络流量、CPU 或 内存负载 等来限流
ConcurrentHashMap使⽤原理
-
⼯作机制(分⽚思想):它引⼊了⼀个“分段锁”的概念,具体可以理解为把⼀个⼤的Map拆分成N个⼩的segment,根据key.hashCode()来决定把key放到哪个HashTable中。可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
-
应⽤:当读>写时使⽤,适合做缓存,在程序启动时初始化,之后可以被多个线程访问;
-
hash冲突:
-
简介:HashMap中调⽤hashCode()⽅法来计算hashCode。由于在Java中两个不同的对象可能有⼀样的hashCode,所以不同的键可能有⼀样hashCode,从⽽导致冲突的产⽣。
-
hash冲突解决:使⽤平衡树来代替链表,当同⼀hash中的元素数量超过特定的值便会由链表切换到平衡树
-
-
⽆锁读:ConcurrentHashMap之所以有较好的并发性是因为ConcurrentHashMap是⽆锁读和加锁写,并且利⽤了分段锁(不是在所有的entry上加锁,⽽是在⼀部分entry上加锁);
-

-
读之前会先判断count(jdk1.6),其中的count是被volatile修饰的(当变量被volatile修饰后,每次更改该变量的时候会将更改结果写到系统主内存中,利⽤多处理器的缓存⼀致性,其他处理器会发现⾃⼰的缓存⾏对应的内存地址被修改,就会将⾃⼰处理器的缓 存⾏设置为失效,并强制从系统主内存获取最新的数据。),故可以实现⽆锁读。
解决map的并发问题⽅案
-
HashMap不是线程安全的;Hashtable线程安全,但效率低,因为是Hashtable是使⽤synchronized的,所有线程竞争同⼀把锁;⽽ConcurrentHashMap不仅线程安全⽽且效率⾼,因为它包含⼀个segment数组,将数据分段存储,给每⼀段数据配⼀把锁,也就是所谓的锁分段技术。
什么是协程,以及实现要点
-
⽣产者/消费者模式不是⾼性能的实现:
-
涉及到同步锁。
-
涉及到线程阻塞状态和可运⾏状态之间的切换。
-
涉及到线程上下⽂的切换
-
-
协成定义:协程,英⽂Coroutines,是⼀种⽐线程更加轻量级的存在。正如⼀个进程可以拥有多个线程⼀样,⼀个线 程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,⽽完全是由程序所控制(也就是在⽤户态执⾏),这样带来的好处就是性能得到了很⼤的提升,不会像线程切换那样消耗资源
-
-
协成优点:协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进⾏切换。因此,协程的开销远远⼩于线程的开销。
-
实现:
-
Lua语⾔ :Lua从5.0版本开始使⽤协程,通过扩展库coroutine来实现。
-
Python语⾔ :正如刚才所写的代码示例,python可以通过 yield/send 的⽅式实现协程。在python 3.5以后, async/await 成为了更好的替代⽅案。
-
Go语⾔ :Go语⾔对协程的实现⾮常强⼤⽽简洁,可以轻松创建成百上千个协程并发执⾏。
-
Java语⾔ :Java语⾔并没有对协程的原⽣⽀持,但是某些开源框架模拟出了协程的功能
-
lru cache 使⽤hash map 的实现(算法)
-
概念:其实解释起来很简单,LRU就是Least Recently Used的缩写,翻译过来就是“最近最少使⽤”。也就是说LRU算法会将最近最少⽤的缓存移除,让给最新使⽤的缓存。⽽往往最常读取的,也就是读取次数最多的,所以利⽤好LRU算法,我们能够提供对热点数据的缓存效率,能够提⾼缓存服务的内存使⽤率。
-
实现:
-
思路:
-
限制缓存⼤⼩
-
查询出最近最晚⽤的缓存
-
给最近最少⽤的缓存做⼀个标识
-
-
代码:
-
import java.util.LinkedHashMap; import java.util.Map; /** * 简单⽤LinkedHashMap来实现的LRU算法的缓存 */public class LRUCache<K, V> extends LinkedHashMap<K, V> {private int cacheSize;public LRUCache(int cacheSize) {super(16, (float) 0.75, true);this.cacheSize = cacheSize;}protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > cacheSize;}}
-
-
图的深度遍历和⼴度遍历(算法)
-
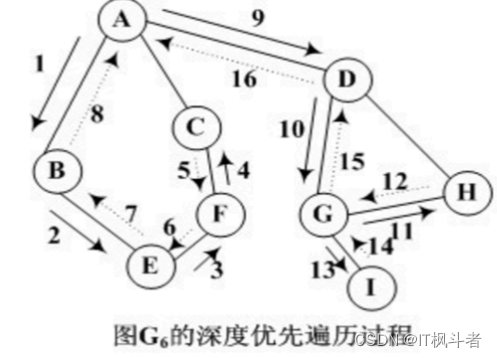
深度优先遍历:
-
-
深度优先遍历结果是: A B E F C D G H I
-
⼴度优先遍历:
-

-
⼴度优先遍历结果是: A B C D E F G H I
基本排序(算法)
-
快速排序:
-
原理:快速排序采⽤的是⼀种分治的思想,它先找⼀个基准数,然后将⽐这个基准数⼩的数字都放到它的左边,然后再递归调⽤,分别对左右两边快速排序,直到每⼀边只有⼀个数字.整个排序就完成了.
-
复杂度:O(n)
-
特点:快速排序是我们平常最常使⽤的⼀种排序算法,因为它速度快,效率⾼,是最优秀的⼀种排序算法.
-
-
冒泡排序:
-
原理:冒泡排序其实就是逐⼀⽐较交换,进⾏⾥外两次循环,外层循环为遍历所有数字,逐个确定每个位置,⾥层循环为确定了位置后,遍历所有后⾯没有确定位置的数字,与该位置的数字进⾏⽐较,只要⽐该位置的数字⼩,就和该位置的数字进⾏交换.
-
复杂度:O(n^2),最佳时间复杂度为O(n)
-
特点:冒泡排序在我们实际开发中,使⽤的还是⽐较少的.它更加适合数据规模⽐较少的时候,因为它的效率是⽐较低的,但是优点是逻辑简单,容易让我们记得.
-
-
直接插⼊排序:
-
原理:直接插⼊排序是将从第⼆个数字开始,逐个拿出来,插⼊到之前排好序的数列⾥.
-
复杂度:O(n^2),最佳时间复杂度为O(n)
-
特点:
-
-
直接选择排序:
-
原理:直接选择排序是从第⼀个位置开始遍历位置,找到剩余未排序的数据⾥最⼩的,找到最⼩的后,再做交换
-
复杂度:O(n^2)
-
特点:和冒泡排序⼀样,逻辑简单,但是效率不⾼,适合少量的数据排序
-
设计模式的使⽤
java 8 流式使⽤

java的对象⼀致性
操作系统的读写屏障
java 域的概念
-
field,域是⼀种属性,可以是⼀个类变量,⼀个对象变量,⼀个对象⽅法变量或者是⼀个函数的参数。
分布式设计领域的概念
-
分布式系统设计的两⼤思路:中⼼化和去中⼼化
-
中⼼化:中⼼化的设计思想在⾃然界和⼈类⽣活中是如此的普遍和⾃然,它的设计思想也很简单,分布式集群中的 节点按照⻆⾊分⼯,可以分为两种⻆⾊--“领导”和“⼲活的”,中⼼化的⼀个思路就是“领导”通常分发任务并监督“⼲ 活的”,谁空闲了就给它安排任务,谁病倒了就⼀脚踢出去,然后把它的任务分给其他⼈;中⼼化的另⼀个思路是领 导只负责⽣成任务⽽不再指派任务,由每个“⼲活的”⾃发去领任务。
-
去中⼼化:全球IP互联⽹就是⼀个典型的去中⼼化的分布式控制架构,联⽹的任意设备宕机都只会影响很⼩范围的 功能。去中⼼化设计通常没有“领导”和“⼲活的”,⻆⾊⼀样,地位平等,因此不存在单点故障。实际上,完全意义的 去中⼼化分布式系统并不多⻅,很多看起来是去中⼼化但⼯作机制采⽤了中⼼化设计思想的分布式系统正在不断涌 现,在这种架构下,集群中的领导是动态选择出来的,⽽不是⼈为预先指定的,⽽且在集群发⽣故障的情况下,集群的成员会⾃发举⾏会议选举新的领导。典型案例如:zookeeper、以及Go语⾔实现的Etcd。
-
-
分布式系统的⼀致性原理
-
在说明⼀致性原理之前,可以先了解⼀下cap理论和base理论,具体⻅《事务与柔性事务》中的说明。
-
对于多副本的⼀致性处理,通常有⼏种⽅法:同步更新--即写操作需要等待两个节点都更新成功才返回,这样的话如果⼀旦发⽣⽹络分区故障,写操作便不可⽤,牺牲了A。异步更新--即写操作直接返回,不需要等待节点更新成功,节点异步地去更新数据,这种⽅式,牺牲了C来保证A。折衷--只要保证集群中超过半数的节点正常并达到⼀致性 即可满⾜要求,此时读操作只要⽐较副本集数据的修改时间或者版本号即可选出最新的,所以系统是强⼀致性的。如果允许“数据⼀致性存在延迟时间”,则是最终⼀致性。
-
如Cassandra中的折衷型⽅案QUORUM,只要超过半数的节点更新成功便返回,读取时返回多数副本的⼀致的值。然后,对于不⼀致的副本,可以通过read repair的⽅式解决。read repair:读取某条数据时,查询所有副本中的这条 数据,⽐较数据与⼤多数副本的最新数据是否⼀致,若否,则进⾏⼀致性修复。此种情况是强⼀致性的。
-
⼜如Redis的master-slave模式,更新成功⼀个节点即返回,其他节点异步地去备份数据。这种⽅式只保证了最终⼀ 致性。最终⼀致性:相⽐于数据时刻保持⼀致的强⼀致性,最终⼀致性允许某段时间内数据不⼀致。但是随着时间的增⻓,数据最终会到达⼀致的状态。此种情况只能保证最终⼀致性。著名的DNS也是最终⼀致性的成功例⼦。强⼀致性算法:1989年就诞⽣了著名的Paxos经典算法(zookeeper就采⽤了Paxos算法的近亲兄弟Zab算法),但由于Paxos算法难以理解、实现和排错,所以不断有⼈尝试优化算法,2013年终于有了重⼤突破:Raft算法的出现, 其中Go语⾔实现的Raft算法就是Etcd,功能类似于zookeeper。
-
Base的思想:基本可⽤、柔性状态、最终⼀致性,主要针对数据库领域的数据拆分,通过数据分⽚(如Mycat、 Amodeba等)来提升系统的可⽤性。由于分⽚拆分后会涉及分布式事务,所以接下来看⼀下如何⽤最终⼀致性的思路来实现分布式事务,也就是柔性事务。
-
-
柔性事务:具体⻅https://blog.csdn.net/Andrew_Chenwq/article/details/129212779?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22129212779%22%2C%22source%22%3A%22Andrew_Chenwq%22%7D。
-
分布式系统的关键Zookeeper
-
⽬标是解决分布式系统的⼏个问题:集群集中化配置,集群节点动态发现机制,简单可靠的节点Leader选举机制,分布式锁。
-
ZNode有⼀个ACL访问权限控制列表,提供对节点增删改查的API,提供监听ZNode变化的实时通知接⼝--Watch接⼝。
-
ZNode类型:持久节点(可以实现配置中⼼)、临时节点(和创建这个节点的客户端会话绑定,可实现集群节点动态发现,可以实现服务注册中⼼)、时序节点(创建节点时会加上数字后缀,通过选择编号最⼩的ZNode可以实现Leader选举机制)、临时性时序节点(同时具备临时节点和时序节点的特性,主要⽤于分布式锁的实现)。
-
如何实现双11的购物限流(redis实现⽅案)
-
限流策略:
-
Nginx接⼊层限流
-
按照⼀定的规则如帐号、IP、系统调⽤逻辑等在Nginx层⾯做限流
-
-
业务应⽤系统限流
-
通过业务代码控制流量这个流量可以被称为信号量,可以理解成是⼀种锁,它可以限制⼀项资源最多能同时被多少进程访问。
-
mysql调优
-
选择最合适的字段属性:类型、⻓度、是否允许NULL等;尽量把字段设为not null,⼀⾯查询时对⽐是否为null;
-
要尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索引。
-
应尽量避免在 where ⼦句中对字段进⾏ null 值判断、使⽤!= 或 <> 操作符,否则将导致引擎放弃使⽤索引⽽进⾏全表扫描
-
应尽量避免在 where ⼦句中使⽤ or 来连接条件,如果⼀个字段有索引,⼀个字段没有索引,将导致引擎放弃使⽤索引⽽进⾏全表扫描
-
in 和 not in 也要慎⽤,否则会导致全表扫描
-
模糊查询也将导致全表扫描,若要提⾼效率,可以考虑字段建⽴前置索引或⽤全⽂检索;
-
如果在 where ⼦句中使⽤参数,也会导致全表扫描。因为SQL只有在运⾏时才会解析局部变量,但优化程序不能将访问计划的选 择推迟到运⾏时;它必须在编译时进⾏选择。然 ⽽,如果在编译时建⽴访问计划,变量的值还是未知的,因⽽⽆法作为索引选择的输⼊ 项。
-
应尽量避免在where⼦句中对字段进⾏函数操作,这将导致引擎放弃使⽤索引⽽进⾏全表扫描。
-
不要在 where ⼦句中的“=”左边进⾏函数、算术运算或其他表达式运算,否则系统将可能⽆法正确使⽤索引。
-
在使⽤索引字段作为条件时,如果该索引是复合索引,那么必须使⽤到该索引中的第⼀个字段作为条件时才能保证系统使⽤该索引,否则该索引将不会被使⽤,并且应尽可能的让字段顺序与索引顺序相⼀致。
-
不要写⼀些没有意义的查询,如需要⽣成⼀个空表结构:
-
Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调⽤会引起明显的性能消耗,同时带来⼤量⽇志。
-
对于多张⼤数据量(这⾥⼏百条就算⼤了)的表JOIN,要先分⻚再JOIN,否则逻辑读会很⾼,性能很差。
-
select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是⼀定要杜绝的。
-
索引并不是越多越好,索引固然可以提⾼相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况⽽定。⼀个表的索引数最好不要超过6个,若太多 则应考虑⼀些不常使⽤到的列上建的索引是否有 必要。
-
应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,⼀旦该列值 改变将导致整个表记录的顺序的调整,会耗费相当⼤的资源。若应⽤系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将 该索引建为 clustered 索引。
-
尽量使⽤数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个⽐较字符串中每⼀个字符,⽽对于数字型⽽⾔只需要⽐较⼀次就够了。
-
尽可能的使⽤ varchar/nvarchar 代替 char/nchar ,因为⾸先变⻓字段存储空间⼩,可以节省存储空间,其次对于查询 来说,在⼀个相对较⼩的字段内搜索效率显然要⾼些。
-
任何地⽅都不要使⽤ select * from t ,⽤具体的字段列表代替“*”,不要返回⽤不到的任何字段。
-
尽量使⽤表变量来代替临时表。如果表变量包含⼤量数据,请注意索引⾮常有限(只有主键索引)。
-
避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使⽤,适当地使⽤它们可以使某些例程更有效,例如,当需要重复引⽤⼤型表或常⽤表中的某个数据集时。但是,对于⼀次性事件, 最好使⽤导出表。
-
在新建临时表时,如果⼀次性插⼊数据量很⼤,那么可以使⽤ select into 代替 create table,避免造成⼤量 log , 以提⾼速度;如果数据量不⼤,为了缓和系统表的资源,应先create table,然后insert。
-
如果使⽤到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较⻓时间锁定。
-
尽量避免使⽤游标,因为游标的效率较差,如果游标操作的数据超过1万⾏,那么就应该考虑改写。
-
使⽤基于游标的⽅法或临时表⽅法之前,应先寻找基于集的解决⽅案来解决问题,基于集的⽅法通常更有效。
-
与临时表⼀样,游标并不是不可使⽤。对⼩型数据集使⽤ FAST_FORWARD 游标通常要优于其他逐⾏处理⽅法,尤其是在必须引⽤⼏个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要⽐使⽤游标执⾏的速度快。如果开发时 间允许,基于游标的⽅法和基于集的⽅法都可以尝试⼀下,看哪⼀种⽅法的效果更好。
-
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。⽆需在执⾏存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
-
尽量避免⼤事务操作,提⾼系统并发能⼒。
-
尽量避免向客户端返回⼤数据量,若数据量过⼤,应该考虑相应需求是否合理。
cdn(异地多活)
-
异地多活:异地多活指分布在异地的多个站点同时对外提供服务的业务场景。异地多活是⾼可⽤架构设计的⼀种,与传统的灾备设计的最主要区别在于“多活”,即所有站点都是同时在对外提供服务的。
-
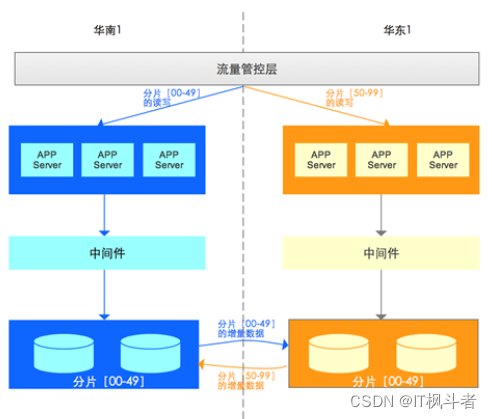
两地容灾切换⽅案: 容灾是异地多活中最核⼼的⼀环, 以两个城市异地多活部署架构图为例:
-
-
在两个城市(城市1位于华南1地域、城市2位于华东1地域)均部署⼀套完整的业务系统。下单业务按照“user_id”% 100 进⾏分⽚,在正常情况下:
-
[00~49]分⽚所有的读写都在城市1的数据库实例主库。
-
[50~99]分⽚所有的读写都在城市2的数据库实例主库。
-
“城市1的数据库实例主库”和 “城市2的数据库实例主库”建⽴DTS双向复制。
-
当出现异常时,需要进⾏容灾切换。可能出现的场景有以下4种:
-
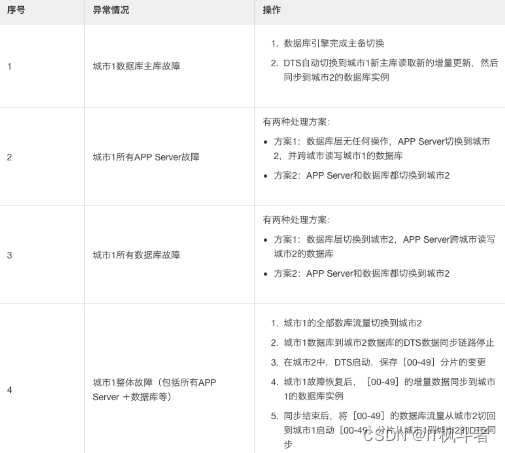
-
将第2种、第3种异常情况,全部采⽤第2种⽅案进⾏处理,那么不管是所有的APP Server异常、所有的数据库异常、整个城市异常,就直接按照城市级容灾⽅案处理,直接将APP Server、数据库切换到到另⼀个城市。
-
多城异地多活: 多城市异地多活模式指的是3个或者3个以上城市间部署异地多活。该模式下存在中⼼节点和单元节点:
-
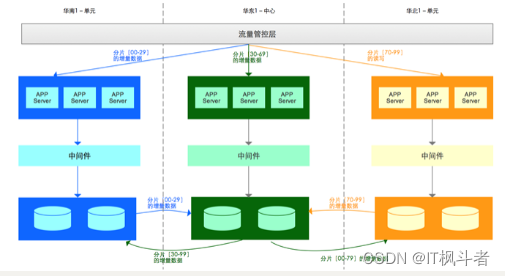
-
中⼼节点:指单元节点的增量数据都需要实时的同步到中⼼节点,同时中⼼节点将所有分⽚的增量数据同步到其他单元节点
-
单元节点:即对应分⽚读写的节点,该节点需要将该分⽚的增量同步到中⼼节点,并且接收来⾃于中⼼节点的其他分⽚的增量数据。
进程之间的通信⽅式
-
匿名管道通信:
-
⽗进程创建管道,得到两个⽂件描述符指向管道的两端
-
⽗进程fork出⼦进程,⼦进程也有两个⽂件描述符指向同⼀管道。
-
⽗进程关闭fd[0],⼦进程关闭fd[1],即⽗进程关闭管道读端,⼦进程关闭管道写端(因为管道只⽀持单向通信)。⽗进程可以往管道⾥写,⼦进程可以从管道⾥读,管道是⽤环形队列实现的,数据从写端流⼊从读端流出,这样就实现了进程间通信。
-
-
⾼级管道通信:将另⼀个程序当做⼀个新的进程在当前程序进程中启动,则它算是当前程序的⼦进程,这种⽅式我们成为⾼级管道⽅式。
-
有名管道通信:有名管道也是半双⼯的通信⽅式,但是它允许⽆亲缘关系进程间的通信。
-
消息队列通信:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息 少、管道只能承载⽆格式字节流以及缓冲区⼤⼩受限等缺点。
-
信号量通信:
-
信号通信:
-
共享内存通信:
-
套接字通信:
tcp/ip协议、http协议
⼆级交换器传输协议
spring 事务的传播
分布式下down机的处理⽅案(⼼跳检测)
-
dubbo:服务器宕机,zk临时被删除;
-
springcloud:每30s发送⼼跳检测重新进⾏租约,如果客户端不能多次更新租约,它将在90s内从服务器注册中⼼移 除。
-
apm监控:
分布式弱⼀致性下down机的处理⽅案
dubbo与zookeeper 两者作为注册中⼼的区别,假如注册中⼼挂了,消费者还能调⽤服务吗,⽤什么调⽤的
-
注册中⼼对等集群,任意⼀台宕掉后,会⾃动切换到另⼀台
-
注册中⼼全部宕掉,服务提供者和消费者仍可以通过本地缓存通讯
-
服务提供者⽆状态,任⼀台 宕机后,不影响使⽤
-
服务提供者全部宕机,服务消费者会⽆法使⽤,并⽆限次重连等待服务者恢复