作者:王同学 来源:投稿
编辑:学姐
模型评估作为机器学习领域一项不可分割的部分,却常常被大家忽略,其实在机器学习领域中重要的不仅仅是模型结构和参数量,对模型的评估也是至关重要的,只有选择那些与应用场景匹配的评估方法才能更好的解决实际问题。
我们平时接触的模型评估一般分成离线评估和在线评估两个阶段,针对不同的机器学习问题,我们选择的评价指标也是不同的。
所以了解不同评价指标的意义,从而针对自己的问题选择不同的评价指标是至关重要的,这也是一位优秀的工程师必须掌握的技能,接下来我会通过两个案例来让大家了解评价指标的重要性,同时也会带大家把常见的几个评价指标展开讨论一下。
案例1
某奢侈品广告主们希望把自家广告定向投放给奢侈品用户。他们先是通过第三方的数据管理平台(DataManagementPlatform,DMP)拿到了一部分奢侈品用户的数据,并以此数据作为训练集和测试集,训练了一个奢侈品用户的分类模型。
该模型的分类准确率超过了95%,但在实际广告投放过程中,该模型还是把大部分广告投给了非奢侈品用户,那么这是什么原因造成的呢?
这是凸显评价指标作用的一个典型案例,在回答问题之前我们首先要清楚一个概念。即我们经常听到的准确率,准确率是指分类正确的样本数量占总样本数量的比例,即:
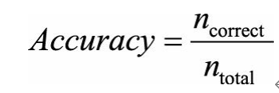
准确率虽然是分类问题中最简单最直观的评价指标,但存在明显的缺陷。
比如,当负样本占比99%时,分类器就算把所有样本都预测为负样本,那也可以获得99%的准确率。所以,当正负样本的比例非常不均衡时,准确率这个评价指标对评价模型好坏是没有多大的参考意义的。
继续回到案例1这个问题,奢侈品用户只占据全体用户的一小部分,虽然模型在整体数据上的准确率很高,但是这并不代表仅对奢侈品用户的准确率也达到了相应的高度。那么这就要求我们对评价指标的选择进行进一步的考量。
当然,我这里仅仅是通过这个案例说明一下评价指标的重要性,影响模型好坏的原因有很多,比如该案例中训练集和验证集的划分可能不太合理,也可能模型在训练过程中出现了过拟合的情况,很多因素都会对最终的结果产生影响。
案例2
Youtube提供视频模糊搜索功能,搜索模型返回的Top5准确率非常高,但是用户在实际的使用过程中却还是经常出现找不到自己目标视频的情况。
针对这个问题,我还是要引出俩个概念,即「精确率和召回率」。
「精确率」是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
「召回率」是指分类正确的正样本个数占真正的正样本个数的比例。
在排序问题中,通常没有一个确定的阈值把得到的结果直接判定为正样本或负样本,而是采用Top N的形式返回结果的Precision值和Recall值来衡量模型的性能,即认为模型返回的Top N的结果就是模型判定的正样本,然后计算前N个位置上的准确率Precision N和前N个位置上的召回率Recall N。
精确率和召回率是既矛盾又统一的两个个体,一方增加必定导致另一方减少,继续回到案例2,模型返回的Precision 5的质量很高。但在实际应用过程中,用户为了找一些冷门的视频,往往会寻找排在较靠后位置的结果。那么也就是说用户还是经常找不到想要的视频,这说明模型没有把相关的视频都找出来呈现给用户。
显然,问题出在召回率上。如果相关结果有100个,即使Precision 5达到了 100%,那么Recall 5也仅仅有5%。
通过这个案例我想让大家明白的是,在模型评估时,我们应该同时关注Precision值 和Recall值,不能一味的为了提高某一个指标而忽略了其它的指标,那么这里就需要我们找到一个能同时反应模型精确率和召回率的指标,到这里就要引出今天的主角了「P-R曲线(Precision- Recall)」。
「P-R曲线的横轴是召回率,纵轴是精确率」。
对于一个排序模型来说,其P-R曲线上的一个点代表着:在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
整条P-R曲线是通过将阈值从高到低移动而生成的。下图就是P-R曲线样例图,其中实线代表模型A的P-R曲线,虚线代表模型B的P-R曲线。原点附近代表当阈值最大时模型的精确率和召回率。
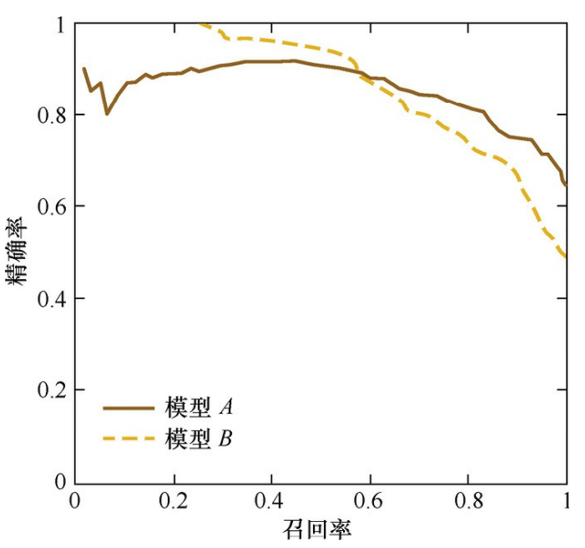
从上图我们可以看到,当召回率接近于0时,模型A的精确率为0.9,模型B的精确率是1, 这说明模型B得分前几位的样本全部是真正的正样本,而模型A即使得分最高的几个样本也存在预测错误的情况。并且,随着召回率的增加,精确率整体呈下降趋势。
但是,当召回率为1时,模型A的精确率反而超过了模型B。这充分说明,只用某个点对应的精确率和召回率是不能全面地衡量模型的性能的,只有通过P-R曲线的整体表现,才能够对模型进行更为全面的评估。
总结
当然,评价指标有很多,这里我没有展开讨论太多,这篇文章我只想让大家明白模型评估的重要性,每项评估指标都有其存在的意义,我们在解决实际问题时绝不能只考虑单一片面的指标,这样的得到的结果是没有多大参考意义的,只有选择那些合适的评价指标才能更好的解决实际场景中的问题。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“机器学习”
领取机器学习实战导学资料合集
码字不易,欢迎大家点赞评论收藏!