与PTB数据集相比,WikiText-2数据集保留了原来的标点符号、大小写和数字,并且比PTB数据集大了两倍多。
我们可以任意访问从WikiText-2语料库中的一对句子生成的预训练(遮蔽语言模型和下一句预测)样本。
原始的BERT有两个版本,其中基本模型有1.1亿个参数,大模型有3.4亿个参数。
在预训练BERT之后,我们可以用它来表示单个文本、文本对或其中的任何词元。
在实验中,同一个词元在不同的上下文中具有不同的BERT表示。这支持BERT表示是上下文敏感的。
目录
1.用于预训练BERT的数据集
1.1为预训练任务定义辅助函数
1.1.1生成下一句预测任务的数据
1.1.2生成遮蔽语言模型任务的数据
1.2将文本转换为预训练数据集
2.预训练BERT
2.1预训练BERT
2.2用BERT表示文本
1.用于预训练BERT的数据集
为了预训练来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中实现的BERT模型,我们需要以理想的格式生成数据集,以便于两个预训练任务:遮蔽语言模型和下一句预测。一方面,最初的BERT模型是在两个庞大的图书语料库和英语维基百科的合集上预训练的,但它很难吸引这本书的大多数读者。另一方面,现成的预训练BERT模型可能不适合医学等特定领域的应用。因此,在定制的数据集上对BERT进行预训练变得越来越流行。为了方便BERT预训练的演示,我们使用了较小的语料库WikiText-2 (Merity et al., 2016)。
与预训练word2vec,代码_流萤数点的博客-CSDN博客_word2vec代码中用于预训练word2vec的PTB数据集相比,WikiText-2(1)保留了原来的标点符号,适合于下一句预测;(2)保留了原来的大小写和数字;(3)大了一倍以上。
pip install mxnet==1.7.0.post1pip install d2l==0.17.0import os
import random
from mxnet import gluon, np, npx
from d2l import mxnet as d2lnpx.set_np()在WikiText-2数据集中,每行代表一个段落,其中在任意标点符号及其前面的词元之间插入空格。保留至少有两句话的段落。为了简单起见,我们仅使用句号作为分隔符来拆分句子。我们将更复杂的句子拆分技术的讨论留在本节末尾的练习中。
#@save
d2l.DATA_HUB['wikitext-2'] = ('https://s3.amazonaws.com/research.metamind.io/wikitext/''wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')#@save
def _read_wiki(data_dir):file_name = os.path.join(data_dir, 'wiki.train.tokens')with open(file_name, 'r') as f:lines = f.readlines()# 大写字母转换为小写字母paragraphs = [line.strip().lower().split(' . ')for line in lines if len(line.split(' . ')) >= 2]random.shuffle(paragraphs)return paragraphs1.1为预训练任务定义辅助函数
在下文中,我们首先为BERT的两个预训练任务实现辅助函数。这些辅助函数将在稍后将原始文本语料库转换为理想格式的数据集时调用,以预训练BERT。
1.1.1生成下一句预测任务的数据
根据来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客的描述,_get_next_sentence函数生成二分类任务的训练样本。
#@save
def _get_next_sentence(sentence, next_sentence, paragraphs):if random.random() < 0.5:is_next = Trueelse:# paragraphs是三重列表的嵌套next_sentence = random.choice(random.choice(paragraphs))is_next = Falsereturn sentence, next_sentence, is_next下面的函数通过调用_get_next_sentence函数从输入paragraph生成用于下一句预测的训练样本。这里paragraph是句子列表,其中每个句子都是词元列表。自变量max_len指定预训练期间的BERT输入序列的最大长度。
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):nsp_data_from_paragraph = []for i in range(len(paragraph) - 1):tokens_a, tokens_b, is_next = _get_next_sentence(paragraph[i], paragraph[i + 1], paragraphs)# 考虑1个'<cls>'词元和2个'<sep>'词元if len(tokens_a) + len(tokens_b) + 3 > max_len:continuetokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)nsp_data_from_paragraph.append((tokens, segments, is_next))return nsp_data_from_paragraph1.1.2生成遮蔽语言模型任务的数据
为了从BERT输入序列生成遮蔽语言模型的训练样本,我们定义了以下_replace_mlm_tokens函数。在其输入中,tokens是表示BERT输入序列的词元的列表,candidate_pred_positions是不包括特殊词元的BERT输入序列的词元索引的列表(特殊词元在遮蔽语言模型任务中不被预测),以及num_mlm_preds指示预测的数量(选择15%要预测的随机词元)。在来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中定义遮蔽语言模型任务之后,在每个预测位置,输入可以由特殊的“掩码”词元或随机词元替换,或者保持不变。最后,该函数返回可能替换后的输入词元、发生预测的词元索引和这些预测的标签。
#@save
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,vocab):# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元mlm_input_tokens = [token for token in tokens]pred_positions_and_labels = []# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测random.shuffle(candidate_pred_positions)for mlm_pred_position in candidate_pred_positions:if len(pred_positions_and_labels) >= num_mlm_preds:breakmasked_token = None# 80%的时间:将词替换为“<mask>”词元if random.random() < 0.8:masked_token = '<mask>'else:# 10%的时间:保持词不变if random.random() < 0.5:masked_token = tokens[mlm_pred_position]# 10%的时间:用随机词替换该词else:masked_token = random.choice(vocab.idx_to_token)mlm_input_tokens[mlm_pred_position] = masked_tokenpred_positions_and_labels.append((mlm_pred_position, tokens[mlm_pred_position]))return mlm_input_tokens, pred_positions_and_labels通过调用前述的_replace_mlm_tokens函数,以下函数将BERT输入序列(tokens)作为输入,并返回输入词元的索引(在来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客 5.1中描述的可能的词元替换之后)、发生预测的词元索引以及这些预测的标签索引。
#@save
def _get_mlm_data_from_tokens(tokens, vocab):candidate_pred_positions = []# tokens是一个字符串列表for i, token in enumerate(tokens):# 在遮蔽语言模型任务中不会预测特殊词元if token in ['<cls>', '<sep>']:continuecandidate_pred_positions.append(i)# 遮蔽语言模型任务中预测15%的随机词元num_mlm_preds = max(1, round(len(tokens) * 0.15))mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab)pred_positions_and_labels = sorted(pred_positions_and_labels,key=lambda x: x[0])pred_positions = [v[0] for v in pred_positions_and_labels]mlm_pred_labels = [v[1] for v in pred_positions_and_labels]return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]1.2将文本转换为预训练数据集
现在我们几乎准备好为BERT预训练定制一个Dataset类。在此之前,我们仍然需要定义辅助函数_pad_bert_inputs来将特殊的“<mask>”词元附加到输入。它的参数examples包含来自两个预训练任务的辅助函数_get_nsp_data_from_paragraph和_get_mlm_data_from_tokens的输出。
#@save
def _pad_bert_inputs(examples, max_len, vocab):max_num_mlm_preds = round(max_len * 0.15)all_token_ids, all_segments, valid_lens, = [], [], []all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []nsp_labels = []for (token_ids, pred_positions, mlm_pred_label_ids, segments,is_next) in examples:all_token_ids.append(np.array(token_ids + [vocab['<pad>']] * (max_len - len(token_ids)), dtype='int32'))all_segments.append(np.array(segments + [0] * (max_len - len(segments)), dtype='int32'))# valid_lens不包括'<pad>'的计数valid_lens.append(np.array(len(token_ids), dtype='float32'))all_pred_positions.append(np.array(pred_positions + [0] * (max_num_mlm_preds - len(pred_positions)), dtype='int32'))# 填充词元的预测将通过乘以0权重在损失中过滤掉all_mlm_weights.append(np.array([1.0] * len(mlm_pred_label_ids) + [0.0] * (max_num_mlm_preds - len(pred_positions)), dtype='float32'))all_mlm_labels.append(np.array(mlm_pred_label_ids + [0] * (max_num_mlm_preds - len(mlm_pred_label_ids)), dtype='int32'))nsp_labels.append(np.array(is_next))return (all_token_ids, all_segments, valid_lens, all_pred_positions,all_mlm_weights, all_mlm_labels, nsp_labels)将用于生成两个预训练任务的训练样本的辅助函数和用于填充输入的辅助函数放在一起,我们定义以下_WikiTextDataset类为用于预训练BERT的WikiText-2数据集。通过实现__getitem__函数,我们可以任意访问WikiText-2语料库的一对句子生成的预训练样本(遮蔽语言模型和下一句预测)样本。
最初的BERT模型使用词表大小为30000的WordPiece嵌入 (Wu et al., 2016)。WordPiece的词元化方法是对 子词嵌入,词的相似性和类比任务_流萤数点的博客-CSDN博客中原有的字节对编码算法稍作修改。为简单起见,我们使用d2l.tokenize函数进行词元化。出现次数少于5次的不频繁词元将被过滤掉。
#@save
class _WikiTextDataset(gluon.data.Dataset):def __init__(self, paragraphs, max_len):# 输入paragraphs[i]是代表段落的句子字符串列表;# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表paragraphs = [d2l.tokenize(paragraph, token='word') for paragraph in paragraphs]sentences = [sentence for paragraph in paragraphsfor sentence in paragraph]self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=['<pad>', '<mask>', '<cls>', '<sep>'])# 获取下一句子预测任务的数据examples = []for paragraph in paragraphs:examples.extend(_get_nsp_data_from_paragraph(paragraph, paragraphs, self.vocab, max_len))# 获取遮蔽语言模型任务的数据examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)+ (segments, is_next))for tokens, segments, is_next in examples]# 填充输入(self.all_token_ids, self.all_segments, self.valid_lens,self.all_pred_positions, self.all_mlm_weights,self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(examples, max_len, self.vocab)def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx], self.all_pred_positions[idx],self.all_mlm_weights[idx], self.all_mlm_labels[idx],self.nsp_labels[idx])def __len__(self):return len(self.all_token_ids)通过使用_read_wiki函数和_WikiTextDataset类,我们定义了下面的load_data_wiki来下载并生成WikiText-2数据集,并从中生成预训练样本。
#@save
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')paragraphs = _read_wiki(data_dir)train_set = _WikiTextDataset(paragraphs, max_len)train_iter = gluon.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)return train_iter, train_set.vocab将批量大小设置为512,将BERT输入序列的最大长度设置为64,我们打印出小批量的BERT预训练样本的形状。注意,在每个BERT输入序列中,为遮蔽语言模型任务预测10(64×0.15)个位置。
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,mlm_Y, nsp_y) in train_iter:print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,nsp_y.shape)breakDownloading ../data/wikitext-2-v1.zip from https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip... (512, 64) (512, 64) (512,) (512, 10) (512, 10) (512, 10) (512,)
最后,我们来看一下词量。即使在过滤掉不频繁的词元之后,它仍然比PTB数据集的大两倍以上。
len(vocab)20256
2.预训练BERT
利用来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中实现的BERT模型和第一节中从WikiText-2数据集生成的预训练样本,我们将在本节中在WikiText-2数据集上对BERT进行预训练。
from mxnet import autograd, gluon, init, np, npx
from d2l import mxnet as d2lnpx.set_np()首先,我们加载WikiText-2数据集作为小批量的预训练样本,用于遮蔽语言模型和下一句预测。批量大小是512,BERT输入序列的最大长度是64。注意,在原始BERT模型中,最大长度是512。
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)2.1预训练BERT
原始BERT (Devlin et al., 2018)有两个不同模型尺寸的版本。基本模型(BERTBASE)使用12层(Transformer编码器块),768个隐藏单元(隐藏大小)和12个自注意头。大模型(BERTLARGE)使用24层,1024个隐藏单元和16个自注意头。值得注意的是,前者有1.1亿个参数,后者有3.4亿个参数。为了便于演示,我们定义了一个小的BERT,使用了2层、128个隐藏单元和2个自注意头。
net = d2l.BERTModel(len(vocab), num_hiddens=128, ffn_num_hiddens=256,num_heads=2, num_layers=2, dropout=0.2)
devices = d2l.try_all_gpus()
net.initialize(init.Xavier(), ctx=devices)
loss = gluon.loss.SoftmaxCELoss()在定义训练代码实现之前,我们定义了一个辅助函数_get_batch_loss_bert。给定训练样本,该函数计算遮蔽语言模型和下一句子预测任务的损失。请注意,BERT预训练的最终损失是遮蔽语言模型损失和下一句预测损失的和。
#@save
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X_shards,segments_X_shards, valid_lens_x_shards,pred_positions_X_shards, mlm_weights_X_shards,mlm_Y_shards, nsp_y_shards):mlm_ls, nsp_ls, ls = [], [], []for (tokens_X_shard, segments_X_shard, valid_lens_x_shard,pred_positions_X_shard, mlm_weights_X_shard, mlm_Y_shard,nsp_y_shard) in zip(tokens_X_shards, segments_X_shards, valid_lens_x_shards,pred_positions_X_shards, mlm_weights_X_shards, mlm_Y_shards,nsp_y_shards):# 前向传播_, mlm_Y_hat, nsp_Y_hat = net(tokens_X_shard, segments_X_shard, valid_lens_x_shard.reshape(-1),pred_positions_X_shard)# 计算遮蔽语言模型损失mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y_shard.reshape(-1),mlm_weights_X_shard.reshape((-1, 1)))mlm_l = mlm_l.sum() / (mlm_weights_X_shard.sum() + 1e-8)# 计算下一句子预测任务的损失nsp_l = loss(nsp_Y_hat, nsp_y_shard)nsp_l = nsp_l.mean()mlm_ls.append(mlm_l)nsp_ls.append(nsp_l)ls.append(mlm_l + nsp_l)npx.waitall()return mlm_ls, nsp_ls, ls通过调用上述两个辅助函数,下面的train_bert函数定义了在WikiText-2(train_iter)数据集上预训练BERT(net)的过程。训练BERT可能需要很长时间。以下函数的输入num_steps指定了训练的迭代步数,而不是像train_ch13函数那样指定训练的轮数。
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):trainer = gluon.Trainer(net.collect_params(), 'adam',{'learning_rate': 0.01})step, timer = 0, d2l.Timer()animator = d2l.Animator(xlabel='step', ylabel='loss',xlim=[1, num_steps], legend=['mlm', 'nsp'])# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数metric = d2l.Accumulator(4)num_steps_reached = Falsewhile step < num_steps and not num_steps_reached:for batch in train_iter:(tokens_X_shards, segments_X_shards, valid_lens_x_shards,pred_positions_X_shards, mlm_weights_X_shards,mlm_Y_shards, nsp_y_shards) = [gluon.utils.split_and_load(elem, devices, even_split=False) for elem in batch]timer.start()with autograd.record():mlm_ls, nsp_ls, ls = _get_batch_loss_bert(net, loss, vocab_size, tokens_X_shards, segments_X_shards,valid_lens_x_shards, pred_positions_X_shards,mlm_weights_X_shards, mlm_Y_shards, nsp_y_shards)for l in ls:l.backward()trainer.step(1)mlm_l_mean = sum([float(l) for l in mlm_ls]) / len(mlm_ls)nsp_l_mean = sum([float(l) for l in nsp_ls]) / len(nsp_ls)metric.add(mlm_l_mean, nsp_l_mean, batch[0].shape[0], 1)timer.stop()animator.add(step + 1,(metric[0] / metric[3], metric[1] / metric[3]))step += 1if step == num_steps:num_steps_reached = Truebreakprint(f'MLM loss {metric[0] / metric[3]:.3f}, 'f'NSP loss {metric[1] / metric[3]:.3f}')print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on 'f'{str(devices)}')在预训练过程中,我们可以绘制出遮蔽语言模型损失和下一句预测损失。
train_bert(train_iter, net, loss, len(vocab), devices, 50)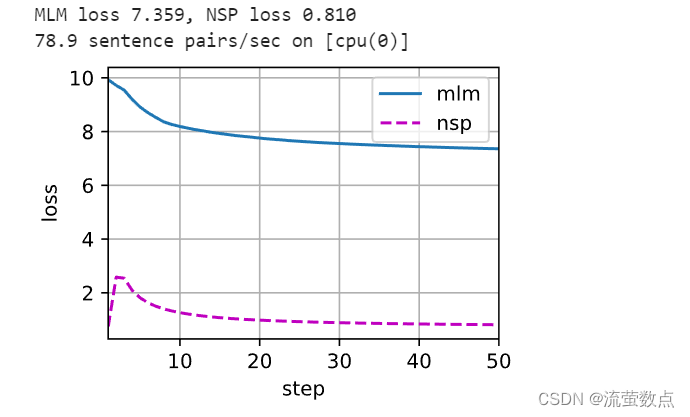
2.2用BERT表示文本
在预训练BERT之后,我们可以用它来表示单个文本、文本对或其中的任何词元。下面的函数返回tokens_a和tokens_b中所有词元的BERT(net)表示。
def get_bert_encoding(net, tokens_a, tokens_b=None):tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)token_ids = np.expand_dims(np.array(vocab[tokens], ctx=devices[0]),axis=0)segments = np.expand_dims(np.array(segments, ctx=devices[0]), axis=0)valid_len = np.expand_dims(np.array(len(tokens), ctx=devices[0]), axis=0)encoded_X, _, _ = net(token_ids, segments, valid_len)return encoded_X考虑“a crane is flying”这句话。回想一下来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中讨论的BERT的输入表示。插入特殊标记“<cls>”(用于分类)和“<sep>”(用于分隔)后,BERT输入序列的长度为6。因为零是“<cls>”词元,encoded_text[:, 0, :]是整个输入语句的BERT表示。为了评估一词多义词元“crane”,我们还打印出了该词元的BERT表示的前三个元素。
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]((1, 6, 128), (1, 128), array([-0.10092681, 0.61367166, -2.2546144 ]))
现在考虑一个句子“a crane driver came”和“he just left”。类似地,encoded_pair[:, 0, :]是来自预训练BERT的整个句子对的编码结果。注意,多义词元“crane”的前三个元素与上下文不同时的元素不同。这支持了BERT表示是上下文敏感的。
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]((1, 10, 128), (1, 128), array([-0.10034682, 0.6146434 , -2.25434 ]))