开源大数据编年史
- 大数据发展的各阶段
- 大数据诞生初期
- 大数据百花齐放的发展之路
- 追求性能的大数据成熟期
大数据发展的各阶段
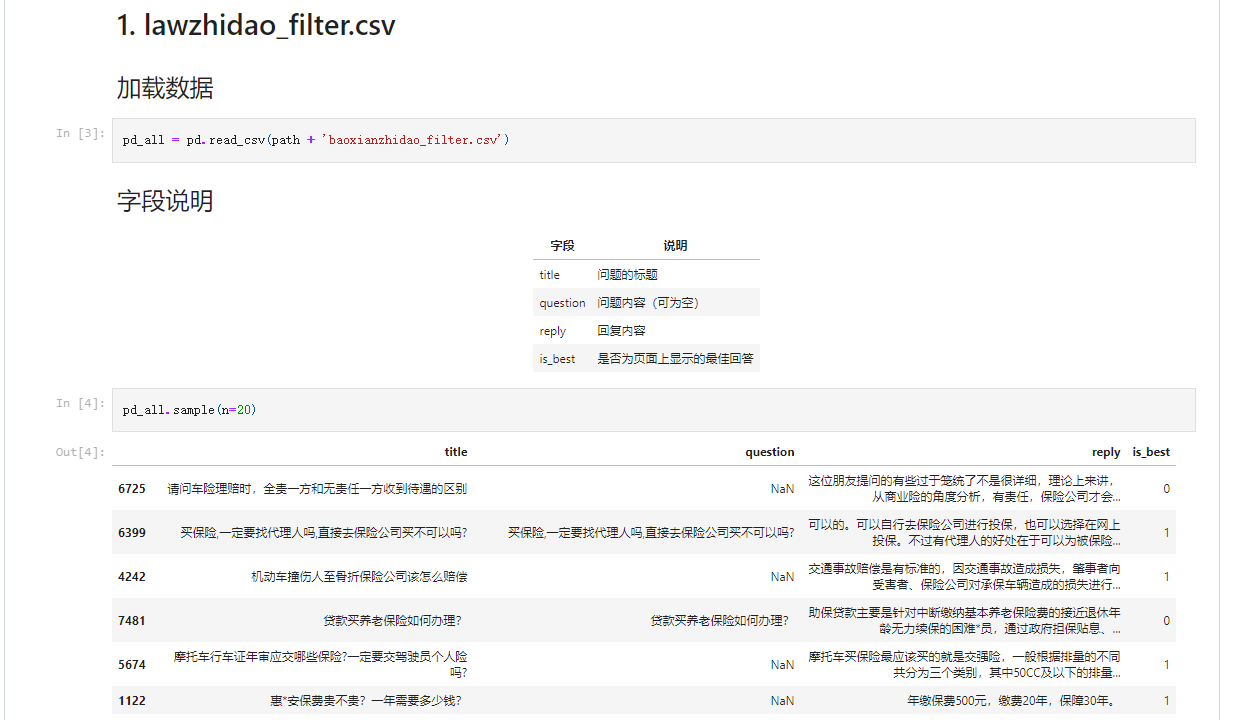
开源大数据的编年史的话,实际上分为三个阶段。一般来说它分为初期、发展期、成熟期。
初期就是大数据刚开始萌芽的一个阶段,它从谷歌的三篇论文开始诞生,并慢慢的成长起来。
在发展期,就是百花齐放。各个场景的一些组件开始丰富起来,大数据生态圈开始扩充。

从2014年之后,属于成熟期,就是大数据产品开始向着追求更高的性能,追求更好的易用性。开始向这样的一个方面进行靠拢。
大数据诞生初期
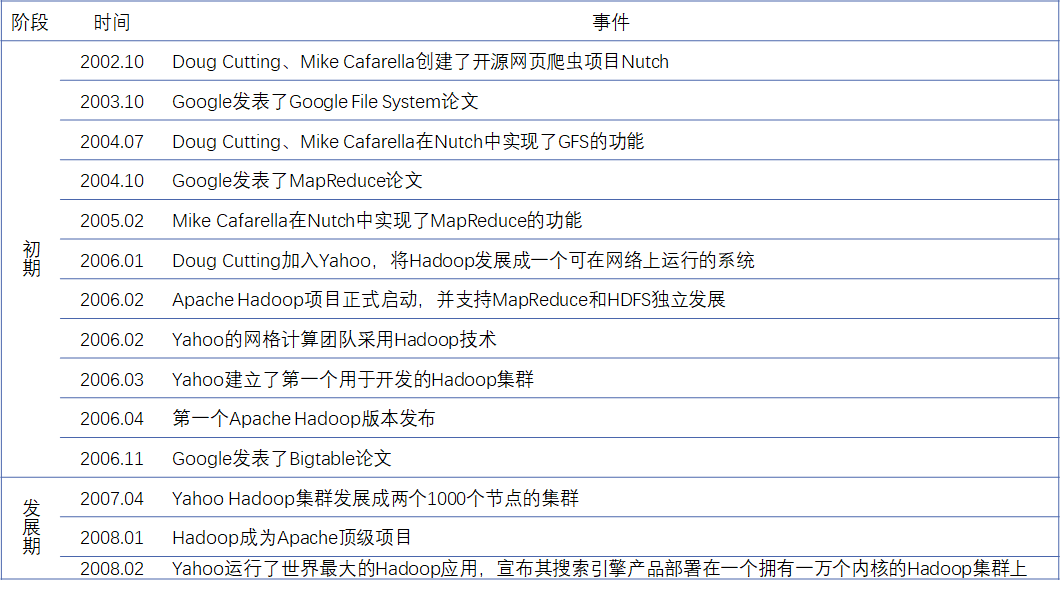
首先的话是02年这个时间点,有两个技术大神,Doug Cutting、Make Cafarella。他们创建了一个开源的爬虫项目叫Nutch。那爬虫项目大家知道,它是源源不断的在爬取数据的,爬取回来的数据,发现数据量太大,没地方存储了。存在单机节点一定是有存储上限的。
于是他们就开始寻找,这种能存储海量数据的技术解决方案。恰好第二年,谷歌发表了Google File System这篇论文,现在的话我们一般简称为GFS。它就是用来解决海量数据存储这样一个问题的。
于是他俩就在04年的时候,在Nutch这个爬虫中把GFS的功能就给实现了。这样的话海量数据就可以进行存储了,GFS它就是现在HDFS的前身。
它的一个数据存储方案,就是分布式多节点去存储。把一个文件拆分成好多份,大概每一份是128M(当时是64M)。拆分成很多份之后,再把这些拆出来的数据块均匀的放到各个服务器节点里面进行一个存储。
数据存起来之后,接下来要做什么?数据存起来肯定要做计算。
于是04年10月份,谷歌又发表了一篇论文叫MapReduce。这个论文就是用来解决海量数据的一个计算问题。
它用到的思想就是我们前面讲到的移动计算而非移动数据。你数据不要动,我的计算任务移动过去。
所以你看它命名上来说,MapReduce由两个单词组成。Map就是我把计算任务分发到各数据节点,每个数据节点进行计算后得到一个部分结果,这叫Map。
得到部分结果之后,这些部分结果肯定要进行一个汇总,汇总成最终的结果。而Reduce就是用来进行部分结果汇总的,得到最终结果之后,将最终结果做一个输出。
MapReduce这篇论文发表之后,在05年,也就是第二年。两个人又在Nutch中把MapReduce的功能也实现了。
到此为止,实际上大数据的雏形基本上就有了。因为我们想一下,对数据的一个存储包括计算都满足了。
就已经麻雀虽小五脏俱全了,接下来就要让它接受生产上的考验了。
于是06年两个创始人之一,Doug Cutting加入雅虎。你看雅虎开始把它发展成了一个可以在网络上运行的系统,这个系统它改名为Hadoop。
这个时候Hadoop就包含了两个组件,一个是我们前面GFS的实现叫HDFS,另外一个就是做计算的MapReduce。Hadoop就发展成了一个可以在网络上运行的系统。
2月份的时候大家看到,Apache的Hadoop项目就正式启动了。Apache是一个基金会,它孵化了很多的一些开源项目,06年2月份的时候Hadoop这样一个项目就推到了Apache进行了一个孵化。
它在孵化的时候,支持MapReduce和HDFS独立发展。
在06年之后,你发现雅虎慢慢的开始使用Hadoop,在这个生产上去进行试用。雅虎的网格计算团队采用Hadoop技术,建立了第一个用于开发的Hadoop集群。
当然的话中间有个时间是Apache第一个Hadoop版本发布。
06年11月份的时候,又有一个重要的时间点出现了,谷歌发表了BigTable论文。
谷歌之前发布了两篇论文,完全推动了开源大数据这一块的一个诞生。然后06年10月份又发表了一篇论文,叫BigTable,这个时候也就意味着谷歌的三驾马车(GFS、MapReduce、BigTable论文)全部推出来了。
Big Table是一个NoSQL数据库(开源实现是HBase),因为我们之前的数据是存在HDFS里面。
HDFS是个文件系统,文件系统一般对我们生产来说不好用。我们生产上没有见过说直接把数据存到文件系统里面,然后让我们程序去调用的。
我们生产一般是把数据存在数据库,虽然说这个数据库也是建立在文件系统之上,但它更加易用。
Bigtable也是这样的NoSQL数据库,基于HDFS这个文件系统搭建的。但是它是一个数据库,数据存进来之后可以对数据进行很快速的一些增删改查,这个是它更擅长的,而且它的并发读性能也很好。对生产上来说更易用一些。
于是谷歌发表了Big table论文之后,谷歌三驾马车全部推出来对大数据这一块起到了极大的推动作用。
大数据百花齐放的发展之路
接下来07年之后是大数据的发展期,你发现雅虎开始大规模的商用。开始的时候只是试水,但是07年之后大规模的在生产中推广与使用。Hadoop发展成了两个1000节点的集群,运行了世界上最大的Hadoop应用,把它的搜索引擎部署在了拥有1万个内核的Hadoop集群上。
雅虎敢这么用,意味着Hadoop已经在生产上经过锤炼,而且已经比较成熟了。
中间08年的时候,Hadoop成为Apache的顶级项目。之前它们是独立发展的,现在的话它们收到Hadoop这样一个顶级项目下,然后Hadoop里面有两个子项目一个HDFS,一个MapReduce。
之后的时间线,大数据产品开始百花齐放。Hive诞生、Pig诞生、HBase出现、Zookeeper、Yarn这些产品开始遍地开花。基于Hadoop产品,它的生态开始逐渐的扩展起来。
而且的话中间有一个重要的时间线,是什么呢?
08年8月份的时候,第一个Hadoop的商业化公司Cloudera成立了,目前是非常老牌的大数据公司。08年成立之后,在09年3月份,它就推出了世界上首个Hadoop发行版CDH,并完全开放源码。现在很多同学学习用的就是CDH这个版本。
商业化公司产生意味着,大数据被资本这一块所认可。意味着大数据是很有前景的。
这是整个一个发展期,百花齐放的过程中,商业化公司成立。
追求性能的大数据成熟期
大数据的成熟期在14年之后,它的一个标志时间是14年2月份Spark的诞生。Spark代替MapReduce成为Hadoop的缺省计算引擎。
什么叫缺省计算引擎?
Hadoop里面做计算的是MapReduce,但是MapReduce有一个问题在于计算效率低。
MapReduce是05年实现的,05年那个时候硬件成本还很高,内存其实很昂贵。于是mapreduce实现的一个想法在于尽量去节约内存,节省内存也就意味着,它会大量与磁盘进行交互。所以它实际上性能并不高。
时间一晃来到2014年,这个时候,硬件成本已经很廉价了。所以没必要再煞费苦心的去节省内存了,会导致效率降低。
于是spark这样的一个框架诞生的目的就是说,时代变了,已经不需要那样去节省内存。在计算时可以把所有数据全部加载到内存中进行计算。如果内存放不下,它才会把最早的数据溢写磁盘进行保存。
在内存里面进行计算,它的效率是非常高的。在Spark官网首页,你可以看到,Spark声称它的效率要比Hadoop快100倍。虽然说有点夸张,但是也侧面体现出它的效率确实是ok的。
于是在14年Spark诞生之后,Spark就可以成为Hadoop的一个缺省计算引擎。就是你可以选MapReduce也可以选Spark做大数据计算。
而且目前公司选型的话,一般选Spark是最多的。因为它效率很高,并且包含了很多易用的场景框架。
这是spark的一个诞生。而且在spark诞生之后,大数据产品开始追求效率,追求速度,追求易用性。
然后15年的时候,诞生了一个基于Hadoop的原生存储替代方案Kudu。Kudu也是把数据先加载到内存,热数据存储在内存中,这样会导致查询包括处理的性能有进一步的提升。
之后诞生的大数据产品都越来越追求速度和易用,性能也越来越出色。
这是整个大数据的一个编年史,这一节就和大家聊到这里,我们下期再会!配套视频可在B站观看,传送门:从编年史角度看大数据兴起