第 2 章 栈、队列、链表
目录
第 2 章 栈、队列、链表
队列:
解密回文——栈
纸牌游戏:
链表
模拟链表

队列:
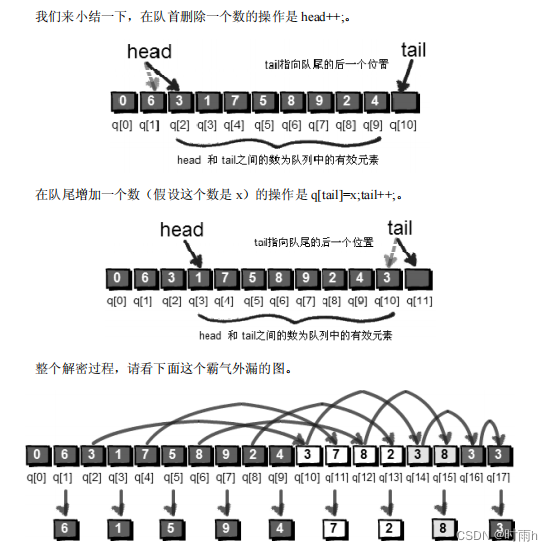
首先将第 1 个数删除,紧接着将第 2 个数放到这串数的末尾,再将第 3 个数删除并将第 4 个数放到这串数的末尾,再将第 5 个数删除……直到剩下最后一个数,将最后一个数也删除。按照刚才删除的顺序,把这些删除的数连在一起就是小哈的 号码啦。现在你来帮帮小哼吧。小哈给小哼加密过的一串数是“6 3 1 7 5 8 9 2 4”。
要去用程序来解决的话:
#include <stdio.h>
int main()
{ int q[102]={0,6,3,1,7,5,8,9,2,4},head,tail; int i; //初始化队列head=1; tail=10; //队列中已经有9个元素了,tail指向队尾的后一个位置 while(head<tail) //当队列不为空的时候执行循环{ //打印队首并将队首出队printf("%d ",q[head]); head++; //先将新队首的数添加到队尾q[tail]=q[head]; tail++; //再将队首出队head++; } getchar();getchar(); return 0;
}队列的概念:
队列是一种特殊的线性结构,它只允许在队列的首部(head)进行删除操作,这称为“出队”,而在队列的尾部(tail)进行插入操作,这称为“入队”。当队列中没有元素时(即 head==tail),称为空队列。
队列将是我们今后学习广度优先搜索以及队列优化的 Bellman-Ford 最短路算法的核心
数据结构。所以现在将队列的三个基本元素(一个数组,两个变量)封装为一个结构体类型,
如下。
struct queue
{ int data[100];//队列的主体,用来存储内容int head;//队首int tail;//队尾
};可以这么理解:我们定义了一个新的数据类型,这个新类型非常强大,用这个新类型定义出的每一个变量可以同时存储一个整型数组和两个整数。
使用结构体来实现的队列操作
#include <stdio.h>
struct queue
{ int data[100];//队列的主体,用来存储内容int head;//队首int tail;//队尾
};
int main()
{ struct queue q; int i; //初始化队列q.head=1; q.tail=1; for(i=1;i<=9;i++) { //依次向队列插入9个数scanf("%d",&q.data[q.tail]); q.tail++; } while(q.head<q.tail) //当队列不为空的时候执行循环{ //打印队首并将队首出队printf("%d ",q.data[q.head]); q.head++; //先将新队首的数添加到队尾q.data[q.tail]=q.data[q.head]; q.tail++; //再将队首出队q.head++; } getchar();getchar(); return 0;
}解密回文——栈
原书中对栈的说明:
栈究竟有哪些作用呢?我们来看一个例子。“xyzyx”是一个回文字符串,所谓回文字符串就是指正读反读均相同的字符序列,如“aha”和“ahaha”均是回文,但“ahah”不是回文。通过栈这个数据结构我们将很容易判断一个字符串是否为回文。首先我们需要读取这行字符串,并求出这个字符串的长度。char a[101];int len;gets(a);len=strlen(a);如果一个字符串是回文的话,那么它必须是中间对称的,我们需要求中点,即:mid=len/2-1;接下来就轮到栈出场了。我们先将 mid 之前的字符全部入栈。因为这里的栈是用来存储字符的,所以这里用来实现栈的数组类型是字符数组即 char s[101];,初始化栈很简单,top=0;就可以了。入栈的操作是top++; s[top]=x; (假设需要入栈的字符暂存在字符变量x中),其实可以简写为s[++top]=x;。现在我们就来将 mid 之前的字符依次全部入栈。for(i=0;i<=mid;i++){s[++top]=a[i];}接下来进入判断回文的关键步骤。将当前栈中的字符依次出栈,看看是否能与 mid 之后的字符一一匹配,如果都能匹配则说明这个字符串是回文字符串,否则这个字符串就不是回文字符串。for(i=mid+1;i<=len-1;i++) { if (a[i]!=s[top]) { break; } top--; } if(top==0) printf("YES"); else printf("NO"); 最后如果 top 的值为 0,就说明栈内所有的字符都被一一匹配了,那么这个字符串就是 回文字符串。完整的代码如下。 #include <stdio.h> #include <string.h> int main() { char a[101],s[101]; int i,len,mid,next,top;gets(a); //读入一行字符串 len=strlen(a); //求字符串的长度 mid=len/2-1; //求字符串的中点top=0;//栈的初始化 //将mid前的字符依次入栈 for(i=0;i<=mid;i++) s[++top]=a[i];//判断字符串的长度是奇数还是偶数,并找出需要进行字符匹配的起始下标 if(len%2==0) next=mid+1; else next=mid+2;//开始匹配 for(i=next;i<=len-1;i++) 第 2 章 栈、队列、链表 { if(a[i]!=s[top]) break; top--; }//如果top的值为0,则说明栈内所有的字符都被一一匹配了 if(top==0) printf("YES"); else printf("NO"); getchar();getchar(); return 0; }
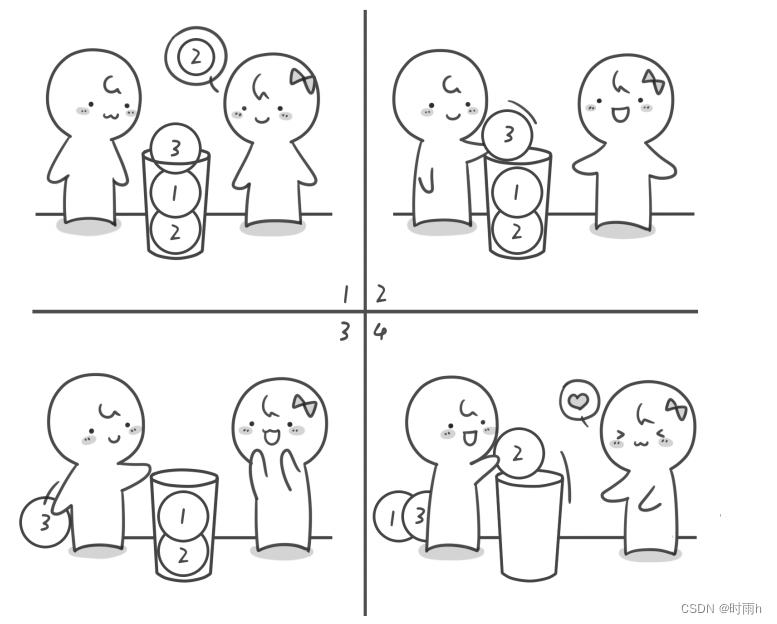
纸牌游戏:
星期天小哼和小哈约在一起玩桌游,他们正在玩一个非常古怪的扑克游戏——“小猫钓鱼”。游戏的规则是这样的:将一副扑克牌平均分成两份,每人拿一份。小哼先拿出手中的第一张扑克牌放在桌上,然后小哈也拿出手中的第一张扑克牌,并放在小哼刚打出的扑克牌的上面,就像这样两人交替出牌。出牌时,如果某人打出的牌与桌上某张牌的牌面相同,即可将两张相同的牌及其中间所夹的牌全部取走,并依次放到自己手中牌的末尾。当任意一人手中的牌全部出完时,游戏结束,对手获胜。假如游戏开始时,小哼手中有 6 张牌,顺序为 2 4 1 2 5 6,小哈手中也有 6 张牌,顺序为 3 1 3 5 6 4,最终谁会获胜呢?现在你可以拿出纸牌来试一试。接下来请你写一个程序来自动判断谁将获胜。这里我们做一个约定,小哼和小哈手中牌的牌面只有 1~9
完整代码实现
#include <stdio.h>
struct queue
{ int data[1000]; int head; int tail;
};
第 2 章 栈、队列、链表
struct stack
{ int data[10]; int top;
};
int main()
{ struct queue q1,q2; struct stack s; int book[10]; int i,t; //初始化队列q1.head=1; q1.tail=1; q2.head=1; q2.tail=1; //初始化栈s.top=0; //初始化用来标记的数组,用来标记哪些牌已经在桌上for(i=1;i<=9;i++) book[i]=0; //依次向队列插入6个数//小哼手上的6张牌for(i=1;i<=6;i++) { scanf("%d",&q1.data[q1.tail]); q1.tail++; } //小哈手上的6张牌for(i=1;i<=6;i++) { scanf("%d",&q2.data[q2.tail]); q2.tail++; } while(q1.head<q1.tail && q2.head<q2.tail ) //当队列不为空的时候执行循环{ t=q1.data[q1.head];//小哼出一张牌//判断小哼当前打出的牌是否能赢牌if(book[t]==0) //表明桌上没有牌面为t的牌
41
混混藏书阁:http://book-life.blog.163.com
啊哈!算法
42 { //小哼此轮没有赢牌q1.head++; //小哼已经打出一张牌,所以要把打出的牌出队s.top++; s.data[s.top]=t; //再把打出的牌放到桌上,即入栈book[t]=1; //标记桌上现在已经有牌面为t的牌} else { //小哼此轮可以赢牌q1.head++;//小哼已经打出一张牌,所以要把打出的牌出队q1.data[q1.tail]=t;//紧接着把打出的牌放到手中牌的末尾q1.tail++; while(s.data[s.top]!=t) //把桌上可以赢得的牌依次放到手中牌的末尾{ book[s.data[s.top]]=0;//取消标记q1.data[q1.tail]=s.data[s.top];//依次放入队尾q1.tail++; s.top--; //栈中少了一张牌,所以栈顶要减1 } } t=q2.data[q2.head]; //小哈出一张牌//判断小哈当前打出的牌是否能赢牌if(book[t]==0) //表明桌上没有牌面为t的牌{ //小哈此轮没有赢牌q2.head++; //小哈已经打出一张牌,所以要把打出的牌出队s.top++; s.data[s.top]=t; //再把打出的牌放到桌上,即入栈book[t]=1; //标记桌上现在已经有牌面为t的牌 } else { //小哈此轮可以赢牌q2.head++;//小哈已经打出一张牌,所以要把打出的牌出队q2.data[q2.tail]=t;//紧接着把打出的牌放到手中牌的末尾q2.tail++; while(s.data[s.top]!=t) //把桌上可以赢得的牌依次放到手中牌的末尾{ book[s.data[s.top]]=0;//取消标记
第 2 章 栈、队列、链表q2.data[q2.tail]=s.data[s.top];//依次放入队尾q2.tail++; s.top--; } } } if(q2.head==q2.tail) { printf("小哼win\n"); printf("小哼当前手中的牌是"); for(i=q1.head;i<=q1.tail-1;i++) printf(" %d",q1.data[i]); if(s.top>0) //如果桌上有牌则依次输出桌上的牌{ printf("\n桌上的牌是"); for(i=1;i<=s.top;i++) printf(" %d",s.data[i]); } else printf("\n桌上已经没有牌了"); } else { printf("小哈win\n"); printf("小哈当前手中的牌是"); for(i=q2.head;i<=q2.tail-1;i++) printf(" %d",q2.data[i]); if(s.top>0) //如果桌上有牌则依次输出桌上的牌{ printf("\n桌上的牌是"); for(i=1;i<=s.top;i++) printf(" %d",s.data[i]); } else printf("\n桌上已经没有牌了"); } getchar();getchar(); return 0;
}链表
#include <stdio.h>
#include <stdlib.h>
int main()
{ int *p; //定义一个指针p p=(int *)malloc(sizeof(int)); //指针p获取动态分配的内存空间地址*p=10; //向指针p所指向的内存空间中存入10 printf("%d",*p); //输出指针p所指向的内存中的值getchar();getchar(); return 0;
}书上关于链表的介绍:
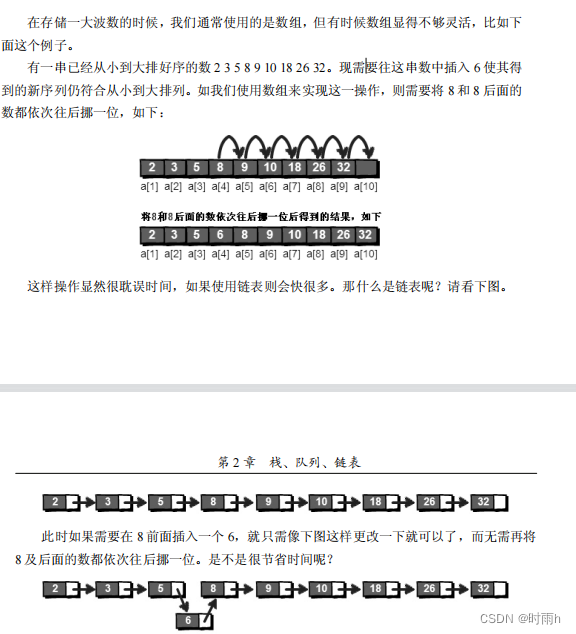
到这里你可能要问:为什么要用这么复杂的办法来存储数据呢?因为之前的方法,我们必须预先准确地知道所需变量的个数,也就是说我们必须定义出所有的变量。比如我们定义了 100 个整型变量,那么程序就只能存储 100 个整数,如果现在的实际情况是需要存储 101个,那必须修改程序才可以。如果有一天你写的软件已经发布或者交付使用,却发现要存储1000 个数才行,那就不得不再次修改程序,重新编译程序,发布一个新版本来代替原来的。而有了 malloc 函数我们便可以在程序运行的过程中根据实际情况来申请空间。
例子:
#include <stdio.h>
#include <stdlib.h>
//这里创建一个结构体用来表示链表的结点类型
struct node
{ int data; struct node *next;
};
int main()
{ struct node *head,*p,*q,*t; int i,n,a; scanf("%d",&n); head = NULL;//头指针初始为空for(i=1;i<=n;i++)//循环读入n个数{ scanf("%d",&a); //动态申请一个空间,用来存放一个结点,并用临时指针p指向这个结点p=(struct node *)malloc(sizeof(struct node)); p->data=a;//将数据存储到当前结点的data域中p->next=NULL;//设置当前结点的后继指针指向空,也就是当前结点的下一个结点为空if(head==NULL) head=p;//如果这是第一个创建的结点,则将头指针指向这个结点else q->next=p;//如果不是第一个创建的结点,则将上一个结点的后继指针指向当前结点q=p;//指针q也指向当前结点} //输出链表中的所有数t=head; while(t!=NULL) {
第 2 章 栈、队列、链表printf("%d ",t->data); t=t->next;//继续下一个结点} getchar();getchar(); return 0;
}容易造成内存泄漏!上面这段代码没有释放动态申请的空间,虽然没有错误,但是这样会很不安全,有兴趣的朋友可以去了解一下 free 命令。
#include <stdio.h>
#include <stdlib.h>
//这里创建一个结构体用来表示链表的结点类型
struct node
{ int data; struct node *next;
};
int main()
{ struct node *head,*p,*q,*t; int i,n,a; scanf("%d",&n); head = NULL;//头指针初始为空for(i=1;i<=n;i++)//循环读入n个数{ scanf("%d",&a); //动态申请一个空间,用来存放一个结点,并用临时指针p指向这个结点p=(struct node *)malloc(sizeof(struct node)); p->data=a;//将数据存储到当前结点的data域中p->next=NULL;//设置当前结点的后继指针指向空,也就是当前结点的下一个结点为空if(head==NULL) head=p;//如果这是第一个创建的结点,则将头指针指向这个结点else q->next=p;//如果不是第一个创建的结点,则将上一个结点的后继指针指向当前结点
第 2 章 栈、队列、链表q=p;//指针q也指向当前结点} scanf("%d",&a);//读入待插入的数t=head;//从链表头部开始遍历while(t!=NULL)//当没有到达链表尾部的时候循环{ if(t->next->data > a)//如果当前结点下一个结点的值大于待插入数,将数插入到中间{ p=(struct node *)malloc(sizeof(struct node));//动态申请一个空间,
用来存放新增结点p->data=a; p->next=t->next;//新增结点的后继指针指向当前结点的后继指针所指向的结点t->next=p;//当前结点的后继指针指向新增结点break;//插入完毕退出循环} t=t->next;//继续下一个结点} //输出链表中的所有数t=head; while(t!=NULL) { printf("%d ",t->data); t=t->next;//继续下一个结点} getchar();getchar(); return 0;
}模拟链表
链表可以用指针(上面的)和使用数组来实现的方式(叫做模拟链表)

#include <stdio.h>
int main()
{ int data[101],right[101]; int i,n,t,len; //读入已有的数 scanf("%d",&n); for(i=1;i<=n;i++) scanf("%d",&data[i]); len=n; //初始化数组right for(i=1;i<=n;i++) { if(i!=n) right[i]=i+1; else right[i]=0; } //直接在数组data的末尾增加一个数 len++; scanf("%d",&data[len]); //从链表的头部开始遍历 t=1; while(t!=0) { if(data[right[t]]>data[len])//如果当前结点下一个结点的值大于待插入数,将
数插入到中间 { right[len]=right[t];//新插入数的下一个结点标号等于当前结点的下一个结
点编号 right[t]=len;//当前结点的下一个结点编号就是新插入数的编号 break;//插入完成跳出循环 } t=right[t]; } //输出链表中所有的数 t=1; while(t!=0) { printf("%d ",data[t]); t=right[t]; } getchar(); getchar(); return 0;
}使用模拟链表也可以实现双向链表和循环链表