文章目录
- 一、链表基础
- 1.1 无序表(UnorderedList)
- 1.1.2 双向链表
- 1.1.3 循环链表
- 1.2 链表的基本操作
- 1.2.1 定义链表结构
- 1.2.2 建立线性链表
- 1.2.3 求线性链表的长度
- 1.2.4 查找元素
- 1.2.5 插入元素
- 1.2.6 改变元素
- 1.2.7 删除元素
- 1.3 有序表OrderedList
- 1.4 链表总结
- 二、 链表基础题目
- 2.1 设计链表(707)
- 2.1.1单链表
- 2.1.2 双链表
- 2.2 移除链表元素(203)
- 2.3 删除排序链表中的重复元素(83)
- 2.4 删除排序链表中的重复元素 (82)
- 2.5 反转链表
- 2.5.1 迭代
- 2.5.2 递归
- 2.6 反转链表二(92)
- 2.6.1 迭代
- 2.6.2 头插法,一次遍历(官方题解)
- 2.7 回文链表
- 三、链表双指针
- 3.1 双指针简介
- 3.2 起点不一致的快慢指针
- 3.2.1 算法简介
- 3.2.2 删除链表的倒数第 N 个结点
- 3.3 步长不一致的快慢指针
- 3.3.1 算法原理
- 3.3.2 求链表的中间结点
- 3.3.2.1 单指针
- 3.3.2.2 快慢指针
- 3.3.3 判断链表中是否含有环
- 3.3.3.1 哈希表
- 3.3.3.2 快慢指针(Floyd 判圈算法)
- 3.3.4 求环形链表入环位置
- 3.3.4.1 哈希表
- 3.3.4.2 快慢指针(Floyd 判圈算法)
- 3.4 分离双指针
- 3.4.1 算法原理
- 3.4.2 合并两个有序链表
- 3.4.3 相交链表
- 3.4.3.1 哈希表
- 3.4.3.2 分离双指针
- 四、链表排序
- 4.1 基础知识
- 4.2 链表插入排序
- 4.3 链表归并排序
- 4.4 链表排序题目
- 4.4.1 排序链表
- 4.4.2 合并K个升序链表
- 4.4.2.1 顺序合并
- 4.4.2.2 分治合并
本文主要参考《算法通关手册》链表篇
一、链表基础
1.1 无序表(UnorderedList)
链表(Linked List):一种线性表数据结构。它使用一组任意的存储单元(可以是连续的,也可以是不连续的),来存储一组具有相同类型的数据。简单来说,「链表」 是实现线性表链式存储结构的基础。
虽然列表数据结构要求保持数据项的前后相对位置,但这种前后位置的保持,并不要求数据项依次存放在连续的存储空间。如下图,数据项存放位置并没有规则,但如果在数据项之间建立链接指向,就可以保持其前后相对位置。第一个和最后一个数据项需要显示标记出来,一个是队首,一个是队尾,后面再无数据了。
- 插入删除元素时需要移动表中元素,而不是修改指针,顺序表也是随机存取数据。

如上图所示,链表通过将一组任意的存储单元串联在一起。其中,每个数据元素占用若干存储单元的组合称为一个链节点。每个节点包含两个部分:
- 元素值
- 后继指针
next:指出直接后继元素所在链节点的地址。
在链表中,数据元素之间的逻辑关系是通过指针来间接反映的。逻辑上相邻的数据元素在物理地址上可能相邻,可也能不相邻。其在物理地址上的表现是随机的。
我们先来简单介绍一下链表结构的优缺点:
-
优点:存储空间不必事先分配,在需要存储空间的时候可以临时申请,不会造成空间的浪费;一些操作的时间效率远比数组高(插入、移动、删除元素等)。
-
缺点:不仅数据元素本身的数据信息要占用存储空间,指针也需要占用存储空间,链表结构比数组结构的空间开销大。
接下来先来介绍一下除了单链表之外,链表的其他几种类型。
1.1.2 双向链表
双向链表(Doubly Linked List):链表的一种,也叫做双链表。它的每个链节点中有两个指针,分别指向直接后继和直接前驱。
从双链表的任意一个节点开始,都可以很方便的访问它的前驱节点和后继节点。
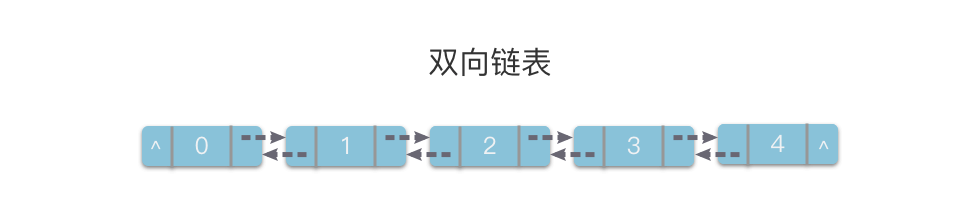
1.1.3 循环链表
循环链表(Circular linked list):链表的一种。它的最后一个链节点指向头节点,形成一个环。
从循环链表的任何一个节点出发都能找到任何其他节点。
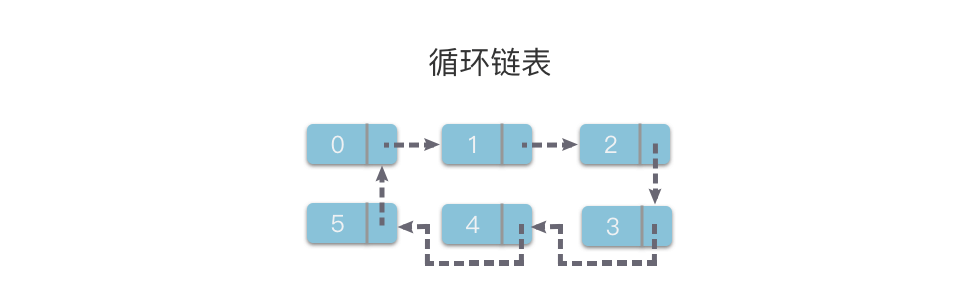
接下来我们以单链表为例,介绍一下链表的基本操作。
1.2 链表的基本操作
数据结构的操作一般涉及到增、删、改、查 4 种情况,链表的操作也基本上是这 4 种情况。我们一起来看一下链表的基本操作。
1.2.1 定义链表结构
ListNode类:链节点类。链表是由链节点通过next链接而构成的,所以ListNode类可使用成员变量val表示数据元素的值,使用指针变量next表示后继指针。LinkedList类:链表类 。ListkedList类中只有一个链节点变量head用来表示链表的头节点。我们在创建空链表时,只需要把相应的链表头节点变量设置为空链接(None)即可。
上述代码如下:
# 链节点类
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = next# 链表类
class LinkedList:def __init__(self):self.head = None
1.2.2 建立线性链表
建立线性链表的过程是:据线性表的数据元素动态生成链节点,并依次将其连接到链表中。其做法如下:
- 从所给线性表的第
1个数据元素开始依次获取表中的数据元素。 - 每获取一个数据元素,就为该数据元素生成一个新节点,将新节点插入到链表的尾部。
- 插入完毕之后返回第
1个链节点的地址。
建立一个线性链表的时间复杂度为 O(n)O(n)O(n),代码如下:
# 根据 data 初始化一个新链表
def create(self, data):self.head = ListNode(0)cur = self.headfor i in range(len(data)):node = ListNode(data[i])cur.next = nodecur = cur.next
1.2.3 求线性链表的长度
使用一个可以顺着链表指针移动的指针变量 cur 和一个计数器 count, cur 从头开始遍历链表直至为空,此时计数器的数值就是链表的长度。此操作时间复杂度为 O(n)O(n)O(n),代码如下:
# 获取链表长度
def length(self):count = 0cur = self.headwhile cur:count += 1cur = cur.next return count
1.2.4 查找元素
在链表中查找值为 val 的位置:链表不能像数组那样进行随机访问,只能从头节点 head 开始,沿着链表一个一个节点逐一进行查找。如果查找成功,返回被查找节点的地址。否则返回 None。所以查找元素操作的问时间复杂度也是 O(n)O(n)O(n),其代码如下:
# 查找元素
def find(self, val):cur = self.headwhile cur:if val == cur.val:return curcur = cur.nextreturn None
1.2.5 插入元素
链表中插入元素操作分为三种:
- 链表头部插入元素:在链表第
1个链节点之前插入值为val的链节点。 - 链表尾部插入元素:在链表最后
1个链节点之后插入值为val的链节点。 - 链表中间插入元素:在链表第
i个链节点之前插入值为val的链节点。
接下来我们分别讲解一下。
1. 链表头部插入元素
- 先创建一个值为
val的链节点node。 - 然后将
node的next指针指向链表的头节点head。 - 再将链表的头节点
head指向node。
这里后面两步顺序不能反了,否则原先的链表就会丢失。
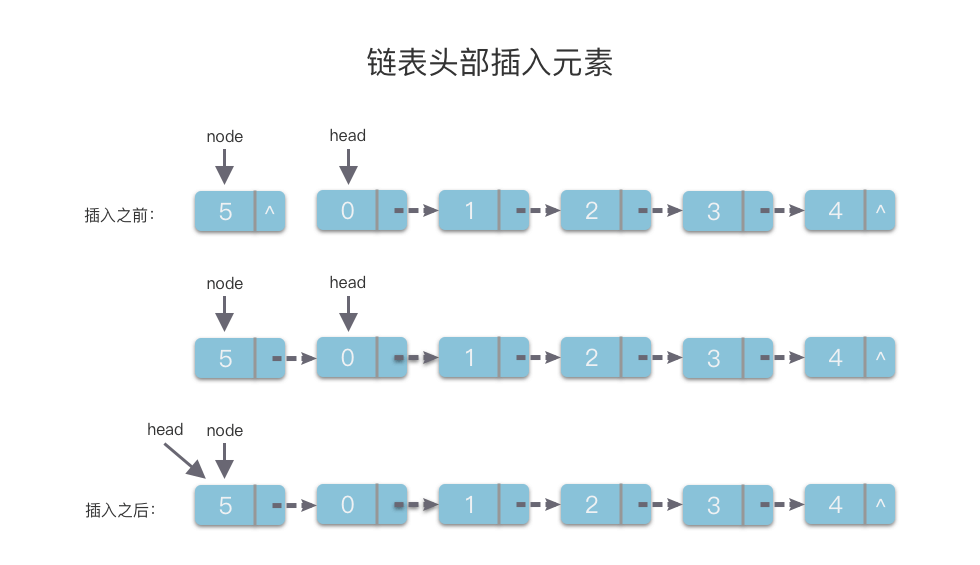
因为在链表头部插入链节点与链表的长度无关,所以该算法的时间复杂度为 O(1)O(1)O(1)。其代码如下:
# 头部插入元素
def insertFront(self, val):node = ListNode(val)node.next = self.headself.head = node
2. 尾部插入元素
- 先创建一个值为
val的链节点node。 - 使用指针
cur指向链表的头节点head。 - 通过链节点的
next指针移动cur指针,从而遍历链表,直到cur.next == None。 - 令
cur.next指向将新的链节点node。
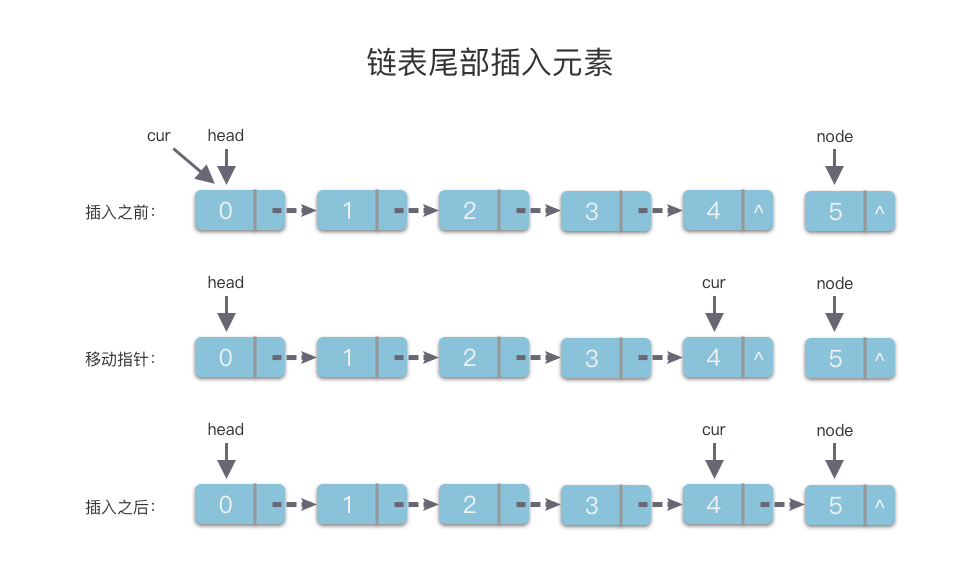
该算法的时间复杂度是 O(n)O(n)O(n),代码如下:
# 尾部插入元素
def insertRear(self, val):node = ListNode(val)cur = self.headwhile cur.next:cur = cur.nextcur.next = node
3. 中间插入元素
- 使用指针变量
cur和一个计数器count。令cur指向链表的头节点,count初始值赋值为0。 - 沿着链节点的
next指针遍历链表,指针变量cur每指向一个链节点,计数器就做一次计数。 - 当
count == index - 1时,说明遍历到了第index - 1个链节点,此时停止遍历。 - 创建一个值为
val的链节点node。 - 将
node.next指向cur.next。 - 然后令
cur.next指向node。
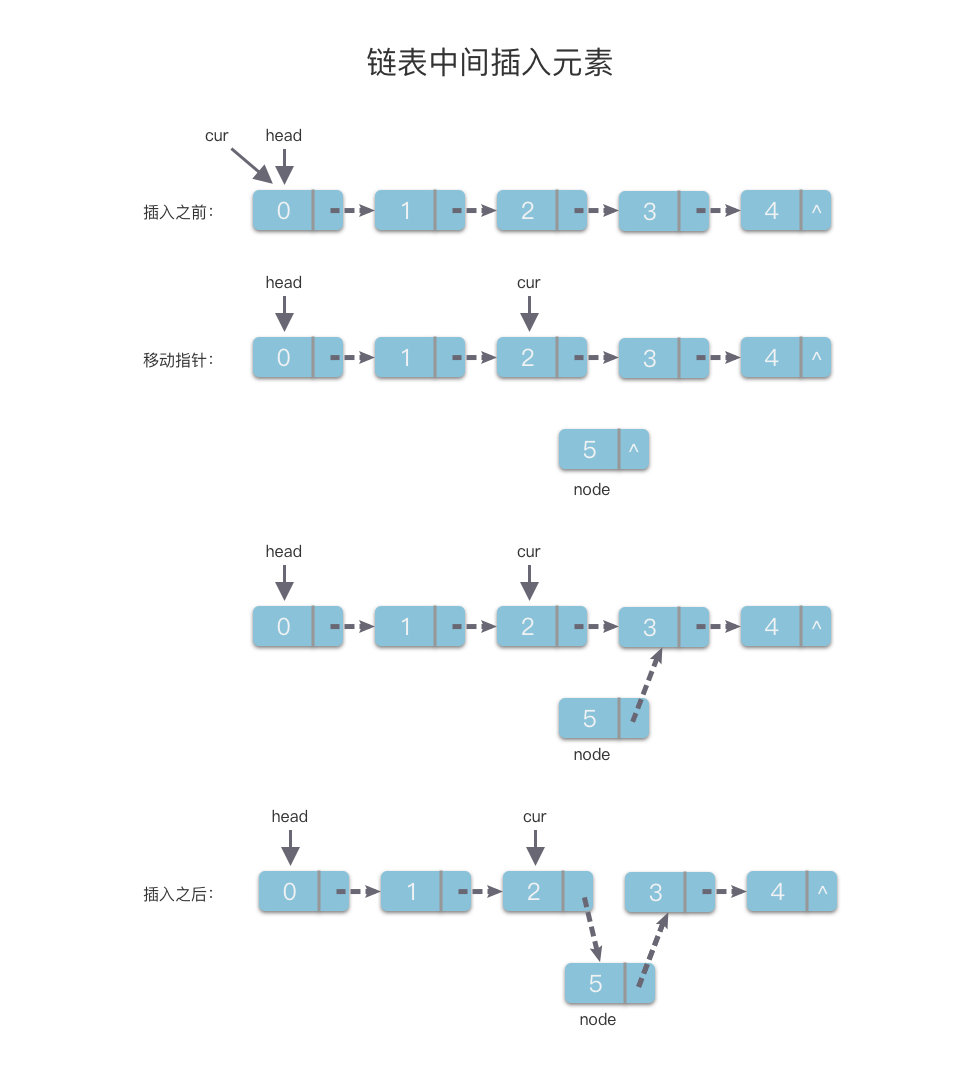
该算法的时间复杂度是 O(n)O(n)O(n),代码如下:
# 中间插入元素
def insertInside(self, index, val):count = 0cur = self.headwhile cur and count < index - 1:count += 1cur = cur.nextif not cur:return 'Error'node = ListNode(val)node.next = cur.nextcur.next = node
1.2.6 改变元素
将链表中第 i 个元素值改为 val:首先要先遍历到第 i 个链节点,然后直接更改第 i 个链节点的元素值。具体做法如下:
- 使用指针变量
cur和一个计数器count。令cur指向链表的头节点,count初始值赋值为0。 - 沿着链节点的
next指针遍历链表,指针变量cur每指向一个链节点,计数器就做一次计数。 - 当
count == index时,说明遍历到了第index个链节点,此时停止遍历。 - 直接更改
cur的值val。
该算法的时间复杂度是 O(n)O(n)O(n), 代码如下:
# 改变元素
def change(self, index, val):count = 0cur = self.headwhile cur and count < index:count += 1cur = cur.nextif not cur:return 'Error'cur.val = val
1.2.7 删除元素
链表的删除元素操作同样分为三种情况:
- 链表头部删除元素:删除链表的第
1个链节点。 - 链表尾部删除元素:删除链表末尾最后
1个链节点。 - 链表中间删除元素:删除链表第
i个链节点。
接下来我们分别讲解一下。
1. 链表头部删除元素
直接将 self.head 沿着 next 指针向右移动一步即可。
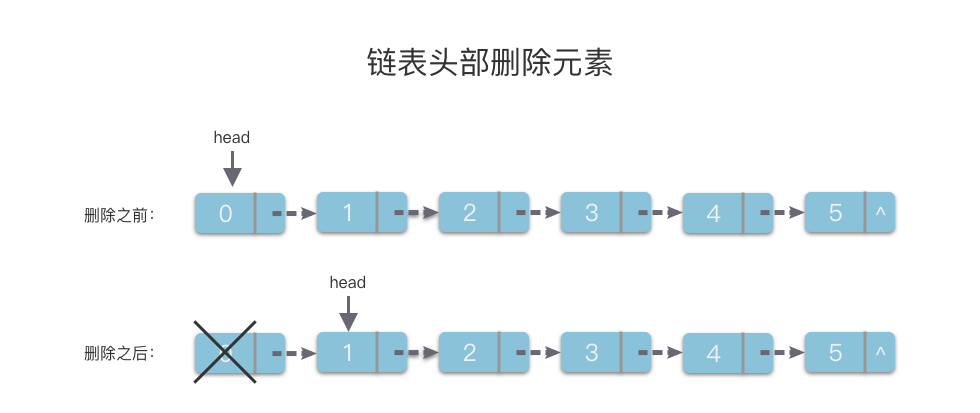
算法的时间复杂度为 O(1)O(1)O(1),代码如下:
# 链表头部删除元素
def removeFront(self):if self.head:self.head = self.head.next
2. 链表尾部删除元素
- 先使用指针变量
cur沿着next指针移动到倒数第2个链节点。 - 然后将此节点的
next指针指向None即可。
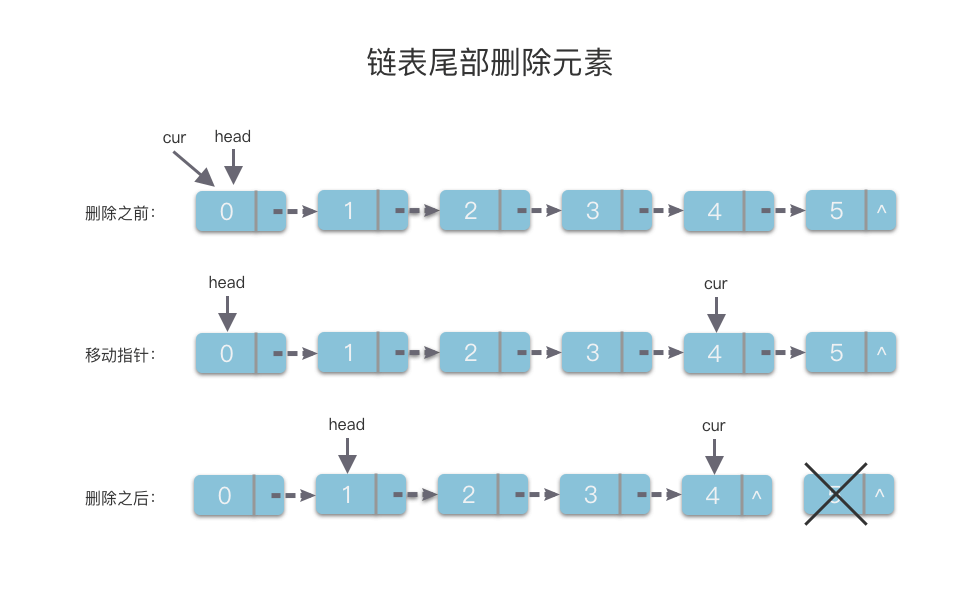
该算法的时间复杂度为 O(n)O(n)O(n),代码如下:
# 链表尾部删除元素
def removeRear(self):if not self.head.next:return 'Error'cur = self.headwhile cur.next.next:cur = cur.nextcur.next = None
3. 链表中间删除元素
删除链表中第 i 个元素的算法具体步骤如下:
- 先使用指针变量
cur移动到第i - 1个位置的链节点。 - 然后将
cur的next指针,指向要第i个元素的下一个节点即可。
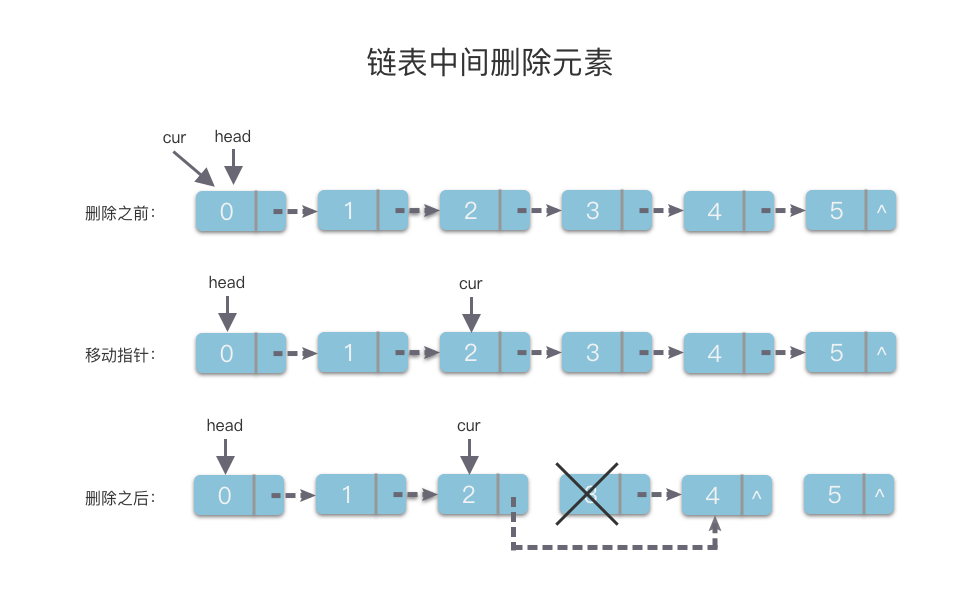
该算法的时间复杂度为 O(n)O(n)O(n),代码如下:
# 链表中间删除元素
def removeInside(self, index):count = 0cur = self.headwhile cur.next and count < index - 1:count += 1cur = cur.nextif not cur:return 'Error'del_node = cur.nextcur.next = del_node.next
到这里,有关链表的基础知识就介绍完了。下面进行一下总结。
1.3 有序表OrderedList

- 在实现有序表时,需要记住数据项的相对位置,取决于他们之间的“大小”比较,Node定义相同,OrderedList也设置一个head来保存链表表头的引用。
- 对于isEmpty(),size(),remove()方法与节点次序无关,其实现与UnorderedList相同。
- search和add方法需要修改。无序表中,需要search的数据项不存在,则需要搜索整个链表。而有序表中,可以利用链表有序排列的特点,节省搜索时间。
有序表实现:search方法
- 在无序表的search中,如果需要查找的数据项不存在,则会搜遍整个链表,直到表尾。
- 对于有序表来说,可以利用链表节点有序排列的特性,来为search节省不存在数据项的查找时间。一旦当前节点的数据项大于所要查找的数据项,则说明链表后面已经不可能再有要查找的数据项,可以直接返回False。
有序表实现:add方法
- add方法必须保证加入的数据项添加在合适的位置,以维护整个链表的有序性。
- 从头找到第一个比添加项大的数据项,将添加项插到该数据项前面。
- 跟remove方法类似,引入一个previous,跟随当前节点current。
代码实现:
class Node:def __init__(self,initdata):self.data = initdataself.next = Nonedef getData(self):return self.datadef getNext(self):return self.nextdef setData(self,newdata):self.data = newdatadef setNext(self,newnext):self.next = newnextclass OrderedList:def __init__(self):self.head = Nonedef search(self,item):current = self.headfound = Falsestop = Falsewhile current != None and not found and not stop:if current.getData() == item:found = Trueelse:if current.getData() > item:stop = Trueelse:current = current.getNext()return founddef add(self,item):current = self.headprevious = Nonestop = Falsewhile current != None and not stop:if current.getData() > item: # 发现插入位置stop = Trueelse:previous = currentcurrent = current.getNext()temp = Node(item)if previous == None: # 表头插入temp.setNext(self.head)self.head = tempelse: # 表中插入temp.setNext(current)previous.setNext(temp)
1.4 链表总结
「链表」 是实现线性表的链式存储结构的基础。它使用一组任意的存储单元(可以是连续的,也可以是不连续的),来存储一组具有相同类型的数据。
链表最大的优点在于可以灵活的添加和删除元素。链表进行访问元素、改变元素操作的时间复杂度为 O(n)O(n)O(n),进行头部插入、头部删除元素操作的时间复杂度是 O(1)O(1)O(1),进行尾部插入、尾部删除操作的时间复杂度是 O(n)O(n)O(n)。普通情况下进行插入、删除元素操作的时间复杂度为 O(n)O(n)O(n)。
Python内置的list数据类型,是基于顺序存储实现的,并进行了优化,其基本操作复杂度如下:

二、 链表基础题目
| 题号 | 标题 | 题解 | 标签 | 难度 |
|---|---|---|---|---|
| 0707 | 设计链表 | Python | 链表 | 中等 |
| 0083 | 删除排序链表中的重复元素 | Python | 链表 | 简单 |
| 0082 | 删除排序链表中的重复元素 II | Python | 链表、双指针 | 中等 |
| 0206 | 反转链表 | Python | 链表 | 简单 |
| 0092 | 反转链表 II | Python | 链表 | 中等 |
| 0025 | K 个一组翻转链表 | Python | 递归、链表 | 困难 |
| 0203 | 移除链表元素 | Python | 链表 | 简单 |
| 0328 | 奇偶链表 | Python | 链表 | 中等 |
| 0234 | 回文链表 | Python | 链表、双指针 | 简单 |
| 0430 | 扁平化多级双向链表 | Python | 链表 | 中等 |
| 0138 | 复制带随机指针的链表 | Python | 链表、哈希表 | 中等 |
| 0061 | 旋转链表 | Python | 链表、双指针 | 中等 |
2.1 设计链表(707)
要求:设计实现一个链表,需要支持以下操作:
get(index):获取链表中第index个节点的值。如果索引无效,则返回-1。addAtHead(val):在链表的第一个元素之前添加一个值为val的节点。插入后,新节点将成为链表的第一个节点。addAtTail(val):将值为val的节点追加到链表的最后一个元素。addAtIndex(index, val):在链表中的第index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。deleteAtIndex(index):如果索引index有效,则删除链表中的第index个节点。
说明:
- 所有
val值都在 [1,1000][1, 1000][1,1000] 之内。 - 操作次数将在 [1,1000][1, 1000][1,1000] 之内。
- 请不要使用内置的
LinkedList库。
示例:
- 示例 1:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); // 链表变为 1 -> 2 -> 3
linkedList.get(1); // 返回 2
linkedList.deleteAtIndex(1); // 现在链表是 1-> 3
linkedList.get(1); // 返回 3
2.1.1单链表
新建一个带有 val 值 和 next 指针的链表节点类, 然后按照要求对节点进行操作。
class ListNode:def __init__(self, x):self.val = xself.next = Noneclass MyLinkedList:def __init__(self):"""Initialize your data structure here."""self.size = 0self.head = ListNode(0)def get(self, index: int) -> int:"""Get the value of the index-th node in the linked list. If the index is invalid, return -1."""if index < 0 or index >= self.size:return -1curr = self.headfor _ in range(index + 1):curr = curr.nextreturn curr.valdef addAtHead(self, val: int) -> None:"""Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list."""self.addAtIndex(0, val)def addAtTail(self, val: int) -> None:"""Append a node of value val to the last element of the linked list."""self.addAtIndex(self.size, val)def addAtIndex(self, index: int, val: int) -> None:"""Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted."""if index > self.size:returnif index < 0:index = 0self.size += 1pre = self.headfor _ in range(index):pre = pre.nextadd_node = ListNode(val)add_node.next = pre.nextpre.next = add_nodedef deleteAtIndex(self, index: int) -> None:"""Delete the index-th node in the linked list, if the index is valid."""if index < 0 or index >= self.size:returnself.size -= 1pre = self.headfor _ in range(index):pre = pre.nextpre.next = pre.next.next
-
时间复杂度:
addAtHead(val):O(1)O(1)O(1)。get(index)、addAtTail(val)、del eteAtIndex(index):O(k)O(k)O(k)。kkk 指的是元素的索引。addAtIndex(index, val):O(n)O(n)O(n)。nnn 指的是链表的元素个数。
-
空间复杂度:O(1)O(1)O(1)。
2.1.2 双链表
新建一个带有 val 值和 next 指针、prev 指针的链表节点类,然后按照要求对节点进行操作。
class ListNode:def __init__(self, x):self.val = xself.next = Noneself.prev = Noneclass MyLinkedList:def __init__(self):"""Initialize your data structure here."""self.size = 0self.head = ListNode(0)self.tail = ListNode(0)self.head.next = self.tailself.tail.prev = self.headdef get(self, index: int) -> int:"""Get the value of the index-th node in the linked list. If the index is invalid, return -1."""if index < 0 or index >= self.size:return -1if index + 1 < self.size - index:curr = self.headfor _ in range(index + 1):curr = curr.nextelse:curr = self.tailfor _ in range(self.size - index):curr = curr.prevreturn curr.valdef addAtHead(self, val: int) -> None:"""Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list."""self.addAtIndex(0, val)def addAtTail(self, val: int) -> None:"""Append a node of value val to the last element of the linked list."""self.addAtIndex(self.size, val)def addAtIndex(self, index: int, val: int) -> None:"""Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted."""if index > self.size:returnif index < 0:index = 0if index < self.size - index:prev = self.headfor _ in range(index):prev = prev.nextnext = prev.nextelse:next = self.tailfor _ in range(self.size - index):next = next.prevprev = next.prevself.size += 1add_node = ListNode(val)add_node.prev = prevadd_node.next = nextprev.next = add_nodenext.prev = add_nodedef deleteAtIndex(self, index: int) -> None:"""Delete the index-th node in the linked list, if the index is valid."""if index < 0 or index >= self.size:returnif index < self.size - index:prev = self.headfor _ in range(index):prev = prev.nextnext = prev.next.nextelse:next = self.tailfor _ in range(self.size - index - 1):next = next.prevprev = next.prev.prevself.size -= 1prev.next = nextnext.prev = prev
- 时间复杂度:
addAtHead(val)、addAtTail(val):O(1)O(1)O(1)。get(index)、addAtIndex(index, val)、del eteAtIndex(index):O(min(k,n−k))O(min(k, n - k))O(min(k,n−k))。nnn 指的是链表的元素个数,kkk 指的是元素的索引。
- 空间复杂度:O(1)O(1)O(1)。
2.2 移除链表元素(203)
给定一个链表的头节点 head 和一个值 val,删除链表中值为 val 的节点,并返回新的链表头节点。
- 列表中的节点数目在范围 [0,104][0, 10^4][0,104] 内
示例:
- 输入:head = [1,2,6,3,4,5,6], val = 6
- 输出:[1,2,3,4,5]

解题思路:
- 使用两个指针
pre和cur。pre指向前一节点,cur指向当前节点。 - 从前向后遍历链表,遇到值为
val的节点时,将pre的next指针指向当前节点的下一个节点,继续递归遍历。没有遇到则将pre指针向后移动一步。 - 向右移动
cur,继续遍历。
需要注意的是:因为要删除的节点可能包含了头节点,我们可以考虑在遍历之前,新建一个头节点,让其指向原来的头节点。这样,最终如果删除的是头节点,则直接删除原头节点,然后最后返回新建头节点的下一个节点即可。
class Solution:def removeElements(self, head: ListNode, val: int) -> ListNode:newHead = ListNode(0, head)newHead.next = headpre, cur = newHead, headwhile cur:if cur.val == val:pre.next = cur.nextelse:pre = curcur = cur.nextreturn newHead.next或者是:
class Solution:def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:newHead = ListNode(0)newHead.next = head cur=newHeadwhile cur.next:# 如果cur下一个节点值为val,就将其跳过下一节点,否则cur右移if cur.next.val==val:cur.next=cur.next.nextelse:cur=cur.nextreturn newHead.next
2.3 删除排序链表中的重复元素(83)
给定一个已排序的链表的头 head,要求删除所有重复的元素,使每个元素只出现一次。返回已排序的链表。
- 链表中节点数目在范围 [0,300][0, 300][0,300] 内。
- −100≤Node.val≤100-100 \le Node.val \le 100−100≤Node.val≤100。
- 题目数据保证链表已经按升序排列。
示例:
- 输入:head = [1,1,2,3,3]
- 输出:[1,2,3]
解题思路
- 使用指针
cur遍历链表,如果cur节点和其下一个节点元素值相等,就跳过下一个节点(cur.next = cur.next.next)。否则,让cur继续向后遍历。 - 遍历完之后返回头节点
head。
class Solution:def deleteDuplicates(self, head: ListNode) -> ListNode:if head == None:return headcur = headwhile cur.next:if cur.val == cur.next.val:cur.next = cur.next.nextelse:cur = cur.nextreturn head
2.4 删除排序链表中的重复元素 (82)
给定一个已排序的链表的头 head,要求删除原始链表中所有重复数字的节点,只留下不同的数字。返回已排序的链表。
- 链表中节点数目在范围 [0,300][0, 300][0,300] 内。
- −100≤Node.val≤100-100 \le Node.val \le 100−100≤Node.val≤100。
- 题目数据保证链表已经按升序排列。
示例:
- 输入:head = [1,1,2,3,3,4,4,5]
- 输出:[2,5]
解题思路:
- 先使用哑节点
dummy_head构造一个指向head的指针,使得可以防止从head开始就是重复元素。 - 然后使用指针
cur表示链表中当前元素,从哑节点开始遍历。 - 当指针
cur的下一个元素和下下一个元素存在时:- 如果下一个元素值和下下一个元素值相同,则我们使用指针
temp保存下一个元素,并使用temp向后遍历,跳过所有重复元素,然后令cur的下一个元素指向temp的下一个元素,继续向后遍历。 - 如果下一个元素值和下下一个元素值不同,则令
cur向右移动一位,继续向后遍历。
- 如果下一个元素值和下下一个元素值相同,则我们使用指针
- 当指针
cur的下一个元素或者下下一个元素不存在时,说明已经遍历完,则返回哑节点dummy_head的下一个节点作为头节点。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def deleteDuplicates(self, head: ListNode) -> ListNode:dummy_head = ListNode(-1)dummy_head.next = headcur = dummy_headwhile cur.next and cur.next.next:if cur.next.val == cur.next.next.val:temp = cur.nextwhile temp and temp.next and temp.val == temp.next.val:temp = temp.nextcur.next = temp.nextelse:cur = cur.nextreturn dummy_head.next
2.5 反转链表
给定一个单链表的头节点 head。将该单链表进行反转。可以迭代或递归地反转链表。
- 链表中节点的数目范围是 [0,5000][0, 5000][0,5000]。
- −5000≤Node.val≤5000-5000 \le Node.val \le 5000−5000≤Node.val≤5000。
示例:
- 输入:head = [1,2,3,4,5]
- 输出:[5,4,3,2,1]
- 解释:翻转前 1->2->3->4->5->NULL,反转后 5->4->3->2->1->NULL
2.5.1 迭代
-
使用两个指针
cur和pre进行迭代。pre指向cur前一个节点位置。初始时,pre指向None,cur指向head。 -
将
pre和cur的前后指针进行交换,指针更替顺序为:- 使用
next指针保存当前节点cur的后一个节点,即next = cur.next; - 断开当前节点
cur的后一节点链接,将cur的next指针指向前一节点pre,即cur.next = pre; pre向前移动一步,移动到cur位置,即pre = cur;cur向前移动一步,移动到之前next指针保存的位置,即cur = next。
- 使用
-
继续执行第 2 步中的 1、2、3、4。
-
最后等到
cur遍历到链表末尾,即cur == None,时,pre所在位置就是反转后链表的头节点,返回新的头节点pre。
使用迭代法反转链表的示意图如下所示:

class Solution:def reverseList(self, head: ListNode) -> ListNode:pre = Nonecur = headwhile cur != None:next = cur.nextcur.next = prepre = curcur = nextreturn pre
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
2.5.2 递归
- 首先定义递归函数含义为:将链表反转,并返回反转后的头节点。
- 然后从
head.next的位置开始调用递归函数,即将head.next为头节点的链表进行反转,并返回该链表的头节点。 - 递归到链表的最后一个节点,将其作为最终的头节点,即为
new_head。 - 在每次递归函数返回的过程中,改变
head和head.next的指向关系。也就是将head.next的next指针先指向当前节点head,即head.next.next = head。 - 然后让当前节点
head的next指针指向None,从而实现从链表尾部开始的局部反转。 - 当递归从末尾开始顺着递归栈的退出,从而将整个链表进行反转。
- 最后返回反转后的链表头节点
new_head。
使用递归法反转链表的示意图如下所示:

class Solution:def reverseList(self, head: ListNode) -> ListNode:if head == None or head.next == None:return headnew_head = self.reverseList(head.next)head.next.next = headhead.next = Nonereturn new_head
- 时间复杂度:O(n)O(n)O(n)
- 空间复杂度:O(n)O(n)O(n)。最多需要 nnn 层栈空间。
2.6 反转链表二(92)
给定单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right。要求反转从位置 left 到位置 right 的链表节点,返回反转后的链表 。
- 链表中节点数目为
n,且1≤n≤5001 \le n \le 5001≤n≤500。 - −500≤Node.val≤500-500 \le Node.val \le 500−500≤Node.val≤500。
- 1≤left≤right≤n1 \le left \le right \le n1≤left≤right≤n。
示例:
- 输入:head = [1,2,3,4,5], left = 2, right = 4
- 输出:[1,4,3,2,5]
2.6.1 迭代
在「0206. 反转链表」中我们可以通过迭代、递归两种方法将整个链表反转。而这道题要求对链表的部分区间进行反转。我们可以先遍历到需要反转的链表区间的前一个节点,然后对需要反转的链表区间进行迭代反转。最后再返回头节点即可。
但是需要注意一点,如果需要反转的区间包含了链表的第一个节点,那么我们可以事先创建一个哑节点作为链表初始位置开始遍历,这样就能避免找不到需要反转的链表区间的前一个节点。具体解题步骤如下:
- 先使用哑节点
dummy_head构造一个指向head的指针,使得可以从head开始遍历。使用index记录当前元素的序号。 - 我们使用一个指针
start,初始赋值为dummy_head。然后向右逐步移动到需要反转的区间的前一个节点。 - 然后再使用两个指针
cur和pre进行迭代。pre指向cur前一个节点位置,即pre指向需要反转节点的前一个节点,cur指向需要反转的节点。初始时,pre指向start,cur指向pre.next。 - 当当前节点
cur不为空,且index在反转区间内时,将pre和cur的前后指针进行交换,指针更替顺序为:- 使用
next指针保存当前节点cur的后一个节点,即next = cur.next; - 断开当前节点
cur的后一节点链接,将cur的next指针指向前一节点pre,即cur.next = pre; pre向前移动一步,移动到cur位置,即pre = cur;cur向前移动一步,移动到之前next指针保存的位置,即cur = next。- 然后令
index加1。
- 使用
- 继续执行第
4步中的1、2、3、4、5步。 - 最后等到
cur遍历到链表末尾(即cur == None)或者遍历到需要反转区间的末尾时(即index > right) 时,将反转区间的头尾节点分别与之前保存的需要反转的区间的前一个节点reverse_start相连,即start.next.next = cur,start.next = pre。 - 最后返回新的头节点
dummy_head.next。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def reverseBetween(self, head: Optional[ListNode], left: int, right: int) -> Optional[ListNode]:dummy_head=ListNode(-1)dummy_head.next=head# 使用一指针start,初始赋值为 dummy_head。向右遍历到left前一个节点start=dummy_headindex=0while start.next and index<=left-2:start=start.nextindex+=1#print(start.val)#使用两个指针 cur 和 pre分别指向left和left前一个节点,开始反转链表pre,cur=start,start.nextwhile cur and index<right:next=cur.nextcur.next=prepre=curcur=nextindex+=1# 此时pre是反转后的链表头结点,cur是right下一个节点#print(pre.val,cur.val) # 如果right是最后一个节点,cur指向None,其没有val属性,print报错start.next.next=curstart.next=prereturn dummy_head.next
2.6.2 头插法,一次遍历(官方题解)
方法一的缺点是:如果 left 和 right 的区域很大,恰好是链表的头节点和尾节点时,找到 left 和 right 需要遍历一次,反转它们之间的链表还需要遍历一次,虽然总的时间复杂度为 O(n)O(n)O(n),但遍历了链表 2 次,可不可以只遍历一次呢?答案是可以的,如下图所示:

整体思想是:在需要反转的区间里,每遍历到一个节点,让这个新节点来到反转部分的起始位置。下面的图展示了整个流程。

具体来说,可以使用三个指针变量 pre、curr、next 来记录反转的过程中需要的变量,它们的意义如下:
- curr:指向待反转区域的第一个节点 left;
- next:永远指向 curr 的下一个节点,循环过程中,curr 变化以后 next 会变化;
- pre:永远指向待反转区域的第一个节点 left 的前一个节点,在循环过程中不变。
- 反转链表(同206题)
- 先将 curr 的下一个节点记录为 next;
- 执行操作 ①:把 curr 的下一个节点指向 next 的下一个节点;
- 执行操作 ②:把 next 的下一个节点指向 pre 的下一个节点;
- 执行操作 ③:把 pre 的下一个节点指向 next。

反转后效果如下:

2. 继续穿针引线


第三步同上:


class Solution:def reverseBetween(self, head: ListNode, left: int, right: int) -> ListNode:# 设置 dummyNode 是这一类问题的一般做法dummy_node = ListNode(-1)dummy_node.next = headpre = dummy_nodefor _ in range(left - 1):pre = pre.nextcur = pre.nextfor _ in range(right - left):next = cur.nextcur.next = next.nextnext.next = pre.nextpre.next = nextreturn dummy_node.next
2.7 回文链表
给定一个链表的头节点 head,判断该链表是否为回文链表。
示例:
- 输入:head = [1,2,2,1]
- 输出:True
利用数组,将链表元素值依次存入,然后判断最终的数组是否是回文数。
class Solution:def isPalindrome(self, head: ListNode) -> bool:nodes = []p1 = headwhile p1:nodes.append(p1.val)p1 = p1.nextreturn nodes == nodes[::-1]
三、链表双指针
3.1 双指针简介
在数组双指针中我们已经学习过了双指针的概念。这里再来复习一下。
双指针(Two Pointers):指的是在遍历元素的过程中,使用两个指针进行访问,从而达到相应的目的。如果两个指针方向相反,则称为「对撞时针」。如果两个指针方向相同,则称为「快慢指针」。如果两个指针分别属于不同的数组 / 链表,则称为「分离双指针」。
而在单链表中,因为遍历节点只能顺着 next 指针方向进行,所以对于链表而言,一般只会用到「快慢指针」和「分离双指针」。其中链表的「快慢指针」又分为「起点不一致的快慢指针」和「步长不一致的快慢指针」。这几种类型的双指针所解决的问题也各不相同,下面我们一一进行讲解。
| 题号 | 标题 | 题解 | 标签 | 难度 |
|---|---|---|---|---|
| 0141 | 环形链表 | Python | 链表、双指针 | 简单 |
| 0142 | 环形链表 II | Python | 链表、双指针 | 中等 |
| 0160 | 相交链表 | Python | 链表、双指针 | 简单 |
| 0019 | 删除链表的倒数第 N 个结点 | Python | 链表、双指针 | 中等 |
| 0876 | 链表的中间结点 | Python | 链表、指针 | 简单 |
| 剑指 Offer 22 | 链表中倒数第k个节点 | Python | 链表、双指针 | 简单 |
| 0143 | 重排链表 | Python | 栈、递归、链表、双指针 | 中等 |
| 0002 | 两数相加 | Python | 递归、链表、数学 | 中等 |
| 0445 | 两数相加 II | Python | 栈、链表、数学 | 中等 |
3.2 起点不一致的快慢指针
3.2.1 算法简介
两个指针从同一侧开始遍历链表,但是两个指针的起点不一样。 快指针 fast 比慢指针 slow 先走 n 步,直到快指针移动到链表尾端时为止。
求解步骤
- 使用两个指针
slow、fast。slow、fast都指向链表的头节点,即:slow = head,fast = head。 - 先将快指针向右移动
n步。然后再同时向右移动快、慢指针。 - 等到快指针移动到链表尾部(即
fast == None)时跳出循环体。
伪代码
slow,fast = head,headwhile n:fast = fast.nextn -= 1while fast:fast = fast.nextslow = slow.next
适用范围:主要用于找到链表中倒数第 k 个节点、删除链表倒数第 N 个节点等。
3.2.2 删除链表的倒数第 N 个结点
题目链接:19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode)
给定一个链表的头节点 head,要求删除链表的倒数第 n 个节点,并且返回链表的头节点。
- 要求使用一次遍历实现。
- 链表中结点的数目为
sz,其中 1≤sz≤301 \le sz \le 301≤sz≤30。 - 0≤Node.val≤1000 \le Node.val \le 1000≤Node.val≤100。
- 1≤n≤sz1 \le n \le sz1≤n≤sz。
示例:
- 输入:head = [1,2,3,4,5], n = 2
- 输出:[1,2,3,5]

解题思路:快慢指针
- 常规思路是遍历一遍链表,求出链表长度,再遍历一遍到对应位置,删除该位置上的节点。
- 使用快慢指针可以实现一次遍历得到结果。思路就是让快指针先走
n步,然后快慢指针同时右移,这样等快指针遍历到链表尾部的时候,慢指针就刚好遍历到了倒数第n个节点位置。将该位置上的节点删除即可。 - 要删除的节点可能包含了头节点。我们可以考虑在遍历之前,新建一个头节点,让其指向原来的头节点。这样,最终如果删除的是头节点,则删除原头节点即可。返回结果的时候,可以直接返回新建头节点的下一位节点。
class Solution:def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:newHead = ListNode(0, head) # val=0,next=headfast = headslow = newHeadwhile n:fast = fast.nextn -= 1while fast:fast = fast.nextslow = slow.nextslow.next = slow.next.nextreturn newHead.next
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.3 步长不一致的快慢指针
3.3.1 算法原理
两个指针从同一侧开始遍历链表,两个指针的起点一样,但是步长不一致。例如,慢指针 slow 每次走 1 步,快指针 fast 每次走两步。直到快指针移动到链表尾端时为止。
求解步骤
- 使用两个指针
slow、fast。slow、fast都指向链表的头节点。 - 在循环体中将快、慢指针同时向右移动,但是快、慢指针的移动步长不一致。比如将慢指针每次移动
1步,即slow = slow.next。快指针每次移动2步,即fast = fast.next.next。 - 等到快指针移动到链表尾部(即
fast == None)时跳出循环体。
伪代码
fast = head
slow = headwhile fast and fast.next:slow = slow.nextfast = fast.next.next
适用范围:此算法适合寻找链表的中点、判断和检测链表是否有环、找到两个链表的交点等问题。
3.3.2 求链表的中间结点
3.4.1 题目链接: 876. 链表的中间结点 - 力扣(LeetCode)
给定一个单链表的头节点 head,返回链表的中间节点。如果有两个中间节点,则返回第二个中间节点。
- 给定链表的结点数介于
1和100之间。
示例1:
- 输入:[1,2,3,4,5]
- 输出:此列表中的结点 3 (序列化形式:[3,4,5])
- 解释:返回的结点值为 3 。
- 注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例2:
- 输入:[1,2,3,4,5,6]
- 输出:此列表中的结点 4 (序列化形式:[4,5,6])
- 解释:由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
3.3.2.1 单指针
先遍历一遍链表,统计一下节点个数为 n,再遍历到 n / 2 的位置,返回中间节点。其代码如下:
class Solution:def middleNode(self, head: ListNode) -> ListNode:n = 0curr = headwhile curr:n += 1curr = curr.nextk = 0curr = headwhile k < n // 2:k += 1curr = curr.nextreturn curr
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.3.2.2 快慢指针
使用步长不一致的快慢指针进行一次遍历找到链表的中间节点。具体做法如下:
- 使用两个指针
slow、fast。slow、fast都指向链表的头节点。 - 在循环体中将快、慢指针同时向右移动。其中慢指针每次移动
1步,即slow = slow.next。快指针每次移动2步,即fast = fast.next.next。 - 等到快指针移动到链表尾部(即
fast == Node)时跳出循环体,此时slow指向链表中间位置。 - 返回
slow指针。
class Solution:def middleNode(self, head: ListNode) -> ListNode:fast = headslow = headwhile fast and fast.next:slow = slow.nextfast = fast.next.nextreturn slow
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.3.3 判断链表中是否含有环
题目链接: 141. 环形链表 - 力扣(LeetCode)
给定一个链表的头节点 head,判断链表中是否有环。如果有环则返回 True,否则返回 False。
- 链表中节点的数目范围是 [0,104][0, 10^4][0,104]。
- −105≤Node.val≤105-10^5 \le Node.val \le 10^5−105≤Node.val≤105。
pos为-1或者链表中的一个有效索引。
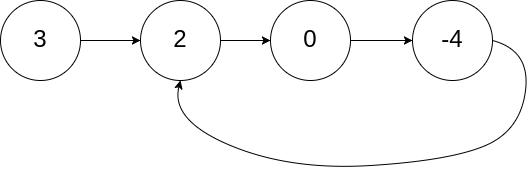
示例:
- 输入:head = [3,2,0,-4], pos = 1
- 输出:True
- 解释:链表中有一个环,其尾部连接到第二个节点。
3.3.3.1 哈希表
最简单的思路是遍历所有节点,每次遍历节点之前,使用哈希表判断该节点是否被访问过。如果过就说明存在环,如果没访问过则将该节点添加到哈希表中,继续遍历判断。
class Solution:def hasCycle(self, head: ListNode) -> bool:nodeset = set()while head:if head in nodeset:return Truenodeset.add(head)head = head.nextreturn False
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(n)O(n)O(n)。
3.3.3.2 快慢指针(Floyd 判圈算法)
这种方法类似于在操场跑道跑步。两个人从同一位置同时出发,如果跑道有环(环形跑道),那么快的一方总能追上慢的一方。
基于上边的想法,Floyd 用两个指针,一个慢指针(龟)每次前进一步,快指针(兔)指针每次前进两步(两步或多步效果是等价的)。如果两个指针在链表头节点以外的某一节点相遇(即相等)了,那么说明链表有环,否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环。
class Solution:def hasCycle(self, head: ListNode) -> bool:if head == None or head.next == None:return Falseslow = headfast = head.nextwhile slow != fast:if fast == None or fast.next == None:return Falseslow = slow.nextfast = fast.next.nextreturn True
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.3.4 求环形链表入环位置
题目链接::142 环形链表 II
给定一个链表的头节点 head,判断链表中是否有环,如果有环则返回入环的第一个节点,无环则返回 None。
- 链表中节点的数目范围在范围 [0,104][0, 10^4][0,104] 内。
- −105≤Node.val≤105-10^5 \le Node.val \le 10^5−105≤Node.val≤105。
pos的值为-1或者链表中的一个有效索引。
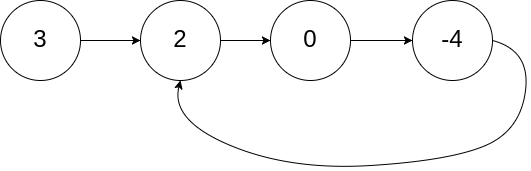
示例:
- 输入:head = [3,2,0,-4], pos = 1
- 输出:返回索引为 1 的链表节点
- 解释:链表中有一个环,其尾部连接到第二个节点。
3.3.4.1 哈希表
遍历链表中的每个节点,并将它记录下来;一旦遇到了此前遍历过的节点,就可以判定链表中存在环。借助哈希表可以很方便地实现。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:se=set()cur=headwhile cur:if cur not in se:se.add(cur)cur=cur.nextelse:return curreturn None
3.3.4.2 快慢指针(Floyd 判圈算法)
- 利用两个指针,一个慢指针
slow每次前进一步,快指针fast每次前进两步(两步或多步效果是等价的)。 - 如果两个指针在链表头节点以外的某一节点相遇(即相等)了,那么说明链表有环。
- 否则,如果(快指针)到达了某个没有后继指针的节点时,那么说明没环。
- 如果有环,则再定义一个指针
ans,和慢指针一起每次移动一步,两个指针相遇的位置即为入口节点。
这是因为:
-
假设入环位置为
A,快慢指针在B点相遇,则相遇时慢指针走了 a+ba + ba+b 步,快指针走了 a+n(b+c)+ba + n(b+c) + ba+n(b+c)+b 步。 -
因为快指针总共走的步数是慢指针走的步数的两倍,即 2(a+b)=a+n(b+c)+b2(a + b) = a + n(b + c) + b2(a+b)=a+n(b+c)+b,所以可以推出:a=c+(n−1)(b+c)a = c + (n-1)(b + c)a=c+(n−1)(b+c)。
-
我们可以发现:从相遇点到入环点的距离 ccc 加上 n−1n-1n−1 圈的环长 b+cb + cb+c 刚好等于从链表头部到入环点的距离。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]: if head==None or head.next==None:return Noneelse: slow,fast=head,head while fast and fast.next: slow=slow.nextfast=fast.next.nextif fast==slow: ans=headwhile ans!=slow:ans,slow=ans.next,slow.nextreturn slowreturn None
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.4 分离双指针
3.4.1 算法原理
分离双指针:两个指针分别属于不同的链表,两个指针分别在两个链表中移动。
求解步骤
- 使用两个指针
left_1、left_2。分别指向两个链表的头节点,即:left_1 = list1,left_2 = list2。 - 当满足一定条件时,两个指针同时右移,即
left_1 = left_1.next、left_2 = left_2.next。 - 当满足另外一定条件时,将
left_1指针右移,即left_1 = left_1.next。 - 当满足其他一定条件时,将
left_2指针右移,即left_2 = left_2.next。 - 当其中一个链表遍历完时或者满足其他特殊条件时跳出循环体。
伪代码模板
left_1 = list1
left_2 = list2while left_1 and left_2:if 一定条件 1:left_1 = left_1.nextleft_2 = left_2.nextelif 一定条件 2:left_1 = left_1.nextelif 一定条件 3:left_2 = left_2.next
适用范围:分离双指针一般用于有序链表合并等问题。
3.4.2 合并两个有序链表
题目链接: 21. 合并两个有序链表 - 力扣(LeetCode)
给定两个升序链表的头节点 list1 和 list2,要求将其合并为一个升序链表。
- 两个链表的节点数目范围是 [0,50][0, 50][0,50]。
- −100≤Node.val≤100-100 \le Node.val \le 100−100≤Node.val≤100。
list1和list2均按 非递减顺序 排列
示例:
- 输入:list1 = [1,2,4], list2 = [1,3,4]
- 输出:[1,1,2,3,4,4]

利用分离双指针,具体步骤如下:
- 使用哑节点
dummy_head构造一个头节点,并使用cur指向dummy_head用于遍历。 - 然后判断
list1和list2头节点的值,将较小的头节点加入到合并后的链表中。并向后移动该链表的头节点指针。 - 然后重复上一步操作,直到两个链表中出现链表为空的情况。
- 将剩余链表链接到合并后的链表中。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为合并后有序链表的头节点返回。
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:dummy_head = ListNode(-1)cur = dummy_headwhile list1 and list2:if list1.val <= list2.val:cur.next = list1list1 = list1.nextelse:cur.next = list2list2 = list2.nextcur = cur.next# 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可cur.next = list1 if list1 is not None else list2return dummy_head.next
- 时间复杂度:O(n)O(n)O(n)。
- 空间复杂度:O(1)O(1)O(1)。
3.4.3 相交链表
题目链接: 160. 相交链表- 力扣(LeetCode)
给定两个链表 listA、listB。判断两个链表是否相交,相交则返回起始点,不相交则返回 None。
示例:
- 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
- 输出:Intersected at ‘8’
- 解释:
- 相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
- 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
- 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。

3.4.3.1 哈希表
判断两个链表是否相交,可以使用哈希集合存储链表节点。
-
遍历链表 headA,并将其中的每个节点加入哈希集合中。
-
遍历链表 headB,对于遍历到的每个节点,判断该节点是否在哈希集合中:
- 如果当前节点不在哈希集合中,则继续遍历下一个节点;
- 如果当前节点在哈希集合中,则后面的节点都在哈希集合中,即从当前节点开始的所有节点都在两个链表的相交部分,因此在链表 headB 中遍历到的第一个在哈希集合中的节点就是两个链表相交的节点,返回该节点。
- 如果链表 headB 中的所有节点都不在哈希集合中,则两个链表不相交,返回
null
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:se=set()cur1=headAcur2=headBwhile cur1:se.add(cur1)cur1=cur1.nextwhile cur2:if cur2 in se:return cur cur2=cur2.nextreturn None
3.4.3.2 分离双指针
使用双指针的方法,可以将空间复杂度降至 O(1)O(1)O(1) :
- 使用两个指针
pA、pB,分别从链表listA、链表listB的头节点开始遍历。 - 直到
pA为空,将其指向listB的头结点,继续遍历 - 直到
pB为空,将其指向listA的头结点,继续遍历 - 当指针
pA和pB指向同一个节点或者都为空时,返回它们指向的节点或者null。
当两个链表相交时:

class Solution:def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:if headA == None or headB == None:return NonepA = headApB = headBwhile pA != pB :pA = pA.next if pA != None else headBpB = pB.next if pB != None else headAreturn pA
四、链表排序
此部分内容请参考《算法通关手册》 链表排序篇。
4.1 基础知识
在数组排序中,常见的排序算法有:冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序、基数排序等。
而对于链表排序而言,因为链表不支持随机访问,访问链表后面的节点只能依靠 next 指针从头部顺序遍历,所以相对于数组排序问题来说,链表排序问题会更加复杂一点。
- 适合链表的排序算法:冒泡排序、选择排序、插入排序、归并排序、快速排序、计数排序、桶排序、基数排序。
- 重点掌握:链表插入排序、链表归并排序 。
- 不适合链表的排序算法:希尔排序。
- 可以用于链表排序但不建议使用的排序算法:堆排序。
希尔排序为什么不适合链表排序?
希尔排序:希尔排序中经常涉及到对序列中第i + gap的元素进行操作,其中gap是希尔排序中当前的步长。而链表不支持随机访问的特性,导致这种操作不适合链表,因而希尔排序算法不适合进行链表排序。
为什么不建议使用堆排序?
堆排序:堆排序所使用的最大堆 / 最小堆结构本质上是一棵完全二叉树。而完全二叉树适合采用顺序存储结构(数组)。因为数组存储的完全二叉树可以很方便的通过下标序号来确定父亲节点和孩子节点,并且可以极大限度的节省存储空间。
而链表用在存储完全二叉树的时候,因为不支持随机访问的特性,导致其寻找子节点和父亲节点会比较耗时,如果增加指向父亲节点的变量,又会浪费大量存储空间。所以堆排序算法不适合进行链表排序。
如果一定要对链表进行堆排序,则可以使用额外的数组空间表示堆结构。然后将链表中各个节点的值依次添加入堆结构中,对数组进行堆排序。排序后,再按照堆中元素顺序,依次建立链表节点,构建新的链表并返回新链表头节点。
链表插入排序
4.2 链表插入排序
1. 算法步骤:
-
先使用哑节点
dummy_head构造一个指向head的指针,使得可以从head开始遍历。 -
维护
sorted_list为链表的已排序部分的最后一个节点,初始时,sorted_list = head。 -
维护
prev为插入元素位置的前一个节点,维护cur为待插入元素。初始时,prev = head,cur = head.next。 -
比较
sorted_list和cur的节点值。- 如果
sorted_list.val <= cur.val,说明cur应该插入到sorted_list之后,则将sorted_list后移一位。 - 如果
sorted_list.val > cur.val,说明cur应该插入到head与sorted_list之间。则使用prev从head开始遍历,直到找到插入cur的位置的前一个节点位置。然后将cur插入。
- 如果
-
令
cur = sorted_list.next,此时cur为下一个待插入元素。 -
重复 4、5 步骤,直到
cur遍历结束为空。返回dummy_head的下一个节点。
2. 实现代码
class Solution:def insertionSort(self, head: ListNode):if not head or not head.next:return headdummy_head = ListNode(-1)dummy_head.next = headsorted_list = headcur = head.next while cur:if sorted_list.val <= cur.val:# 将 cur 插入到 sorted_list 之后sorted_list = sorted_list.next else:prev = dummy_headwhile prev.next.val <= cur.val:prev = prev.next# 将 cur 到链表中间sorted_list.next = cur.nextcur.next = prev.nextprev.next = curcur = sorted_list.next return dummy_head.nextdef sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:return self.insertionSort(head)
- 时间复杂度:O(n2)O(n^2)O(n2)。
- 空间复杂度:O(1)O(1)O(1)。
4.3 链表归并排序
1. 算法步骤
- 分割环节:找到链表中心链节点,从中心节点将链表断开,并递归进行分割。
- 使用快慢指针
fast = head.next、slow = head,让fast每次移动2步,slow移动1步,移动到链表末尾,从而找到链表中心链节点,即slow。 - 从中心位置将链表从中心位置分为左右两个链表
left_head和right_head,并从中心位置将其断开,即slow.next = None。 - 对左右两个链表分别进行递归分割,直到每个链表中只包含一个链节点。
- 使用快慢指针
- 归并环节:将递归后的链表进行两两归并,完成一遍后每个子链表长度加倍。重复进行归并操作,直到得到完整的链表。
- 使用哑节点
dummy_head构造一个头节点,并使用cur指向dummy_head用于遍历。 - 比较两个链表头节点
left和right的值大小。将较小的头节点加入到合并后的链表中,并向后移动该链表的头节点指针。 - 然后重复上一步操作,直到两个链表中出现链表为空的情况。
- 将剩余链表插入到合并后的链表中。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为合并后的头节点返回。
- 使用哑节点
2. 实现代码
class Solution:def merge(self, left, right):# 归并环节dummy_head = ListNode(-1)cur = dummy_headwhile left and right:if left.val <= right.val:cur.next = leftleft = left.nextelse:cur.next = rightright = right.nextcur = cur.nextif left:cur.next = leftelif right:cur.next = rightreturn dummy_head.nextdef mergeSort(self, head: ListNode):# 分割环节if not head or not head.next:return head# 快慢指针找到中心链节点slow, fast = head, head.nextwhile fast and fast.next:slow = slow.next fast = fast.next.next # 断开左右链节点left_head, right_head = head, slow.next slow.next = None# 归并操作return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:return self.mergeSort(head)
- 时间复杂度:O(n×log2n)O(n \times \log_2n)O(n×log2n)。
- 空间复杂度:O(1)O(1)O(1)。
4.4 链表排序题目
| 题号 | 标题 | 题解 | 标签 | 难度 |
|---|---|---|---|---|
| 0148 | 排序链表 | Python | 链表、双指针、分治、排序、归并排序 | 中等 |
| 0021 | 合并两个有序链表 | Python | 递归、链表 | 简单 |
| 0023 | 合并K个升序链表 | Python | 链表、分治、堆(优先队列)、归并排序 | 困难 |
| 0147 | 对链表进行插入排序 | Python | 链表、排序 | 中等 |
4.4.1 排序链表
题目链接:0148. 排序链表
给定链表的头节点 head,请按照升序排列并返回排序后的链表。
- 链表中节点的数目在范围 [0,5∗104][0, 5 * 10^4][0,5∗104] 内。
- −105≤Node.val≤105-10^5 \le Node.val \le 10^5−105≤Node.val≤105。
本题使用链表的冒泡排序、选择排序、插入排序、快速排序都会超时。使用桶排序、归并排序、计数排序则可以通过,基数排序只适用于非负数的情况。归并排序代码上面已给出,其它排序算法请参考《算法通关手册》
4.4.2 合并K个升序链表
题目链接: 023 合并K个升序链表
给定一个链表数组,每个链表都已经按照升序排列。要求将所有链表合并到一个升序链表中,返回合并后的链表。
首先,何在 O(n)O(n)O(n) 的时间代价以及 O(1)O(1)O(1) 的空间代价里完成两个有序链表的合并?为了达到空间代价是 O(1)O(1)O(1),我们的宗旨是「原地调整链表元素的next指针完成合并」,具体参考本文的《3.4.2 合并两个有序链表》。
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:dummy_head = ListNode(-1)cur = dummy_headwhile list1 and list2:if list1.val <= list2.val:cur.next = list1list1 = list1.nextelse:cur.next = list2list2 = list2.nextcur = cur.next# 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可cur.next = list1 if list1 is not None else list2return dummy_head.next
4.4.2.1 顺序合并
我们可以想到一种最朴素的方法:用一个变量 ans来维护以及合并链表,第 i 次循环把第 i 个链表和 ans合并,答案保存到 ans中。

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:if len(lists)==0:return None else:ans=lists[0]for i in lists[1:]:ans=self.mergeTwoLists(ans,i)return ansdef mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:dummy_head = ListNode(-1)cur = dummy_headwhile list1 and list2:if list1.val <= list2.val:cur.next = list1list1 = list1.nextelse:cur.next = list2list2 = list2.nextcur = cur.next# 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可cur.next = list1 if list1 is not None else list2return dummy_head.next
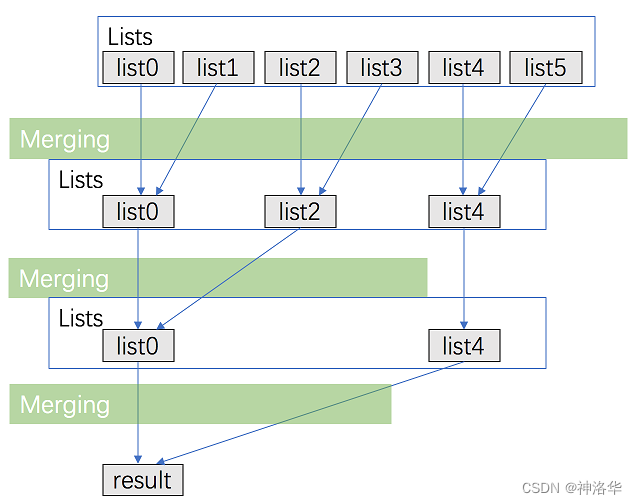
4.4.2.2 分治合并
分而治之的思想。将链表数组不断二分,转为规模为二分之一的子问题,然后再进行归并排序。
class Solution:def merge_sort(self, lists: List[ListNode], left: int, right: int) -> ListNode:if left == right:return lists[left]mid = left + (right - left) // 2node_left = self.merge_sort(lists, left, mid)node_right = self.merge_sort(lists, mid + 1, right)return self.merge(node_left, node_right)def merge(self, a: ListNode, b: ListNode) -> ListNode:root = ListNode(-1)cur = rootwhile a and b:if a.val < b.val:cur.next = aa = a.nextelse:cur.next = bb = b.nextcur = cur.nextif a:cur.next = aif b:cur.next = breturn root.nextdef mergeKLists(self, lists: List[ListNode]) -> ListNode:if not lists:return Nonesize = len(lists)return self.merge_sort(lists, 0, size - 1)