Java知识点总结:想看的可以从这里进入
目录
- 2、MySQL特性介绍
- 2.1、MySQL简介
- 2.2、存储引擎
- 2.3、表、字段、数据
2、MySQL特性介绍
2.1、MySQL简介
MySQL 是一个关系型数据库管理系统(RDBMS),于2009年被 Oracle 公司收购。它是一种关联数据库结构,将数据保存在不同的表中,而不是将所有数据放在一起,从而增加了速度并提高了灵活性。
在MySQL6开始MySQL分为两个版本:社区版(免费)和商业版(收费)。
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,可以修改源码来开发自己的 MySQL 系统。
- MySQL体积小、速度快、成本低、开源这些特点,导致越来越多的中小公司选择使用MySQL(Twitter、YouTube、美团等等)
其中 MySQL8有两个重要的版本,分别是:2015年发布的MySQL5.7 和2016年发布的MySQL8.0。尤其是8.0版本做了很多的增强,在源码上进行了重构,大大提高了其性能。
2.2、存储引擎
mysql有两种存储引擎:InnoDB、MyISAM。默认的为InnoDB。以读写插入为主的博客系统、新闻系统等使用MyISAM,增删改查都高,需要保证数据的完整性,并发量高,支持事务和外键的使用InnoDB
-
InnoDB(mysql5.5后默认使用的)
- 数据存储格式:.frm文件存储表结构、.idb文件存储索引和数据
- 锁:支持表锁和行锁,有四种隔离级别
- 可重复读:可解决脏读、不可重复读,不能解决幻读
- 读未提交(一个事务可以读取另一个未提交事务的数据):脏读、不可重复读,幻读均不能解决
- 读已提交:解决脏读,不能解决不可重复读,幻读
- 串行化:都可以解决
- 事务和外键:支持事务、支持外键
- begin:开始事务
- rollback:回滚事务
- commit:提交事务
- 主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值。因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引。最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
- 内存:需要较大的内存,会建立专门的缓冲池用于高速缓冲数据和索引。
- 数据保存顺序:按主键大小保存
-
MyISAM:
- 数据存储格式:.frm文件存储表结构、.MYD存储表数据、.MYIs存储索引数据
- 锁:只支持表锁,读取时加共享锁,写入时加排他锁。
- 事务和外键:不支持事务、不支持外键
- 采用非聚簇索引
- 内存:可被压缩,存储空间较小
- 数据保存顺序:按数据插入的顺序
-
对比
MYISAM INNODB 事务支持 不支持 支持 数据行锁定 不支持(为表锁) 支持 外键约束 不支持 支持 全文索引 支持 新版本支持 表的空间大小 较小 大,约为2倍 物理空间的存储 .frm表结构定义文件
.MYD 数据文件
.MYI 索引文件数据库表中有一个*.frm文件
及其上级目录下的ibdata文件
InnoDB 四大特性:
插入缓冲(insert buffer)
索引是存储在磁盘上的,所以对于索引的操作需要涉及磁盘操作。如果我们使用自增主键,在插入主键索引时,不需要磁盘的随机 I/O。如果我们使用的是普通索引,大概率是无序的,此时就涉及到磁盘的随机 I/O,而随机I/O的性能是比较差的(磁盘顺序I/O的性能是磁盘随机I/O的4000~5000倍)。
因此,InnoDB 存储引擎设计了 Insert Buffer ,对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池(Buffer pool)中,若在,则直接插入;若不在,则先放入到一个 Insert Buffer 对象中,然后再以一定的频率和情况进行 Insert Buffer 和辅助索引页子节点的合并操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
插入缓冲的使用需要满足以下两个条件:1)索引是辅助索引;2)索引不是唯一的。
因为在插入缓冲时,数据库不会去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有随机读取的情况发生,从而导致 Insert Buffer 失去了意义。
二次写(double write)
InnoDB 的的叶子节点一般是16kb,而操作系统写文件是以4kb作为单位,所以操作系统需要写4个块。如果数据在分块写的时候发生了某些异常,导致数据只要部分是写入成功的,这时会出现数据不完整的问题,而且这种问题无法通过日志进行恢复。
这时就需要使用二次写。它两部分组成,一部分为内存中的 doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间中连续的128个页,即2个区(extent),大小也是2M。
先将脏数据复制到内存中的 doublewrite buffer,之后通过 doublewrite buffer 再分2次,每次1MB写入到共享表空间的磁盘上(顺序写,性能很高),完成后马上调用 fsync 函数,将doublewrite buffer中的脏页数据写入实际的各个表空间文件(离散写)。如果操作系统在将页写入磁盘的过程中发生崩溃,InnoDB 再次启动后,发现了一个 page 数据已经损坏,InnoDB 存储引擎可以从共享表空间的 doublewrite 中找到该页的一个最近的副本,用于进行数据恢复。
预读(read ahead)
当 InnoDB 预计某些 page 可能很快就会需要用到时,它会异步地将这些 page 提前读取到缓冲池(buffer pool)中。InnoDB线性预读(linear read-ahead)(随机预读被废弃)
线性预读:线性预读以 extent块为单位(1个 extent 等于64个 page),将下一个extent 提前读取到 buffer pool 中。它通过innodb_read_ahead_threshold控制执行预读操作的触发阈值,如果一个 extent 中的被顺序读取的 page 超过或者等于该参数变量时,Innodb将会异步的将下一个 extent 读取到 buffer pool中。
随机预读:以 extent 中的 page 为单位,将当前 extent 中的剩余的 page 提前读取到 buffer pool 中。当同一个 extent 中的一些 page 在 buffer pool 中发现时,Innodb 会将该 extent 中的剩余 page 一并读到 buffer pool中,
自适应哈希索引
哈希索引一般情况下查找的时间复杂度为 O(1),但是它不支持范围索引,所以InnoDB只是在热点数据等场景长自适应哈希索引。
InnoDB 会监控对表上索引的查找,如果观察到某些索引被频繁访问,变认为这些索是热数据,则对其建立哈希索引,自适应哈希索引通过缓冲池的 B+ 树构造而来,建立的速度很快,InnoDB 会自动根据访问的频率和模式来为某些页建立哈希索引。
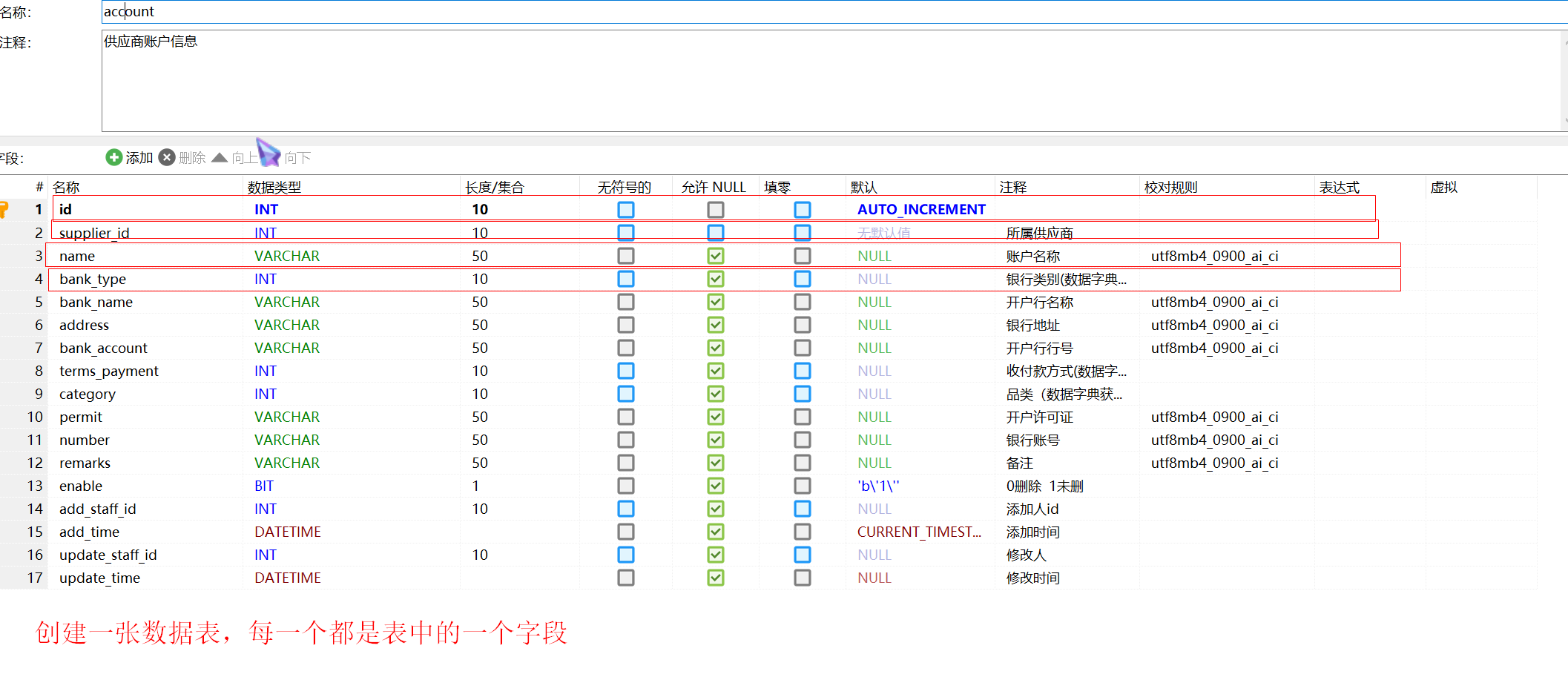
2.3、表、字段、数据
关系型数据,都是由一张张的表组成的,而表中的每一行都是一条数据,每一列对应一个字段。每张表都有一个名字,用来标识自己,表名具有唯一性。
把数据库结构对应到Java中:
每一张表都对应Java中的一个类每一个字段都对应了Java中的一个属性每一行的数据都对应一个实体对象。