第六章 定时器扩展(EID #0x54494D45"TIME")
这个定时器扩展取代了遗留定时器扩展(EID #0x00),并遵循 v0.2 中定义的调用规约。
6.1 函数:设置定时器(FID #0)
struct sbiret sbi_set_timer(uint64_t stime_value)描述和遗留扩展描述同。
6.2 函数列表

第七章 IPI 扩展(EID #0x735049)
取代了遗留的 IPI,不再赘述。
第八章 RFENCE 扩展(EID #0x52464E43)
取代了遗留的 RFENCE,不再赘述。
第九章 hart 状态管理扩展(EID #0x48534D)
hart 状态管理扩展 HSM 介绍了一系列的 hart 状态和一组函数给 S 模式软件来请求 hart 状态的改变。下表描述了一些可能的 HSM 状态以及每个状态的唯一 ID。
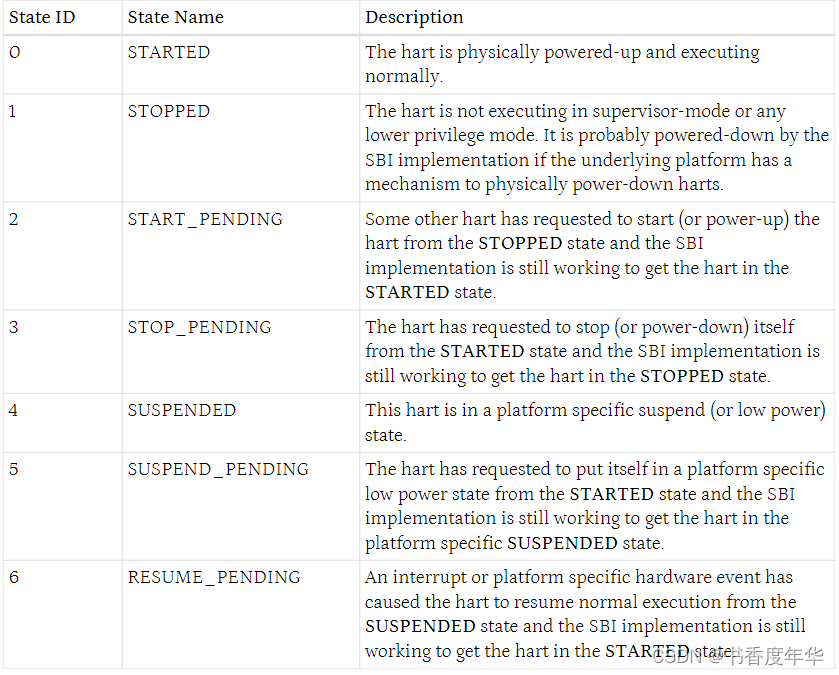
任何时间,一个 hart 应该只能处于上述状态中的一种,SBI 实现的 hart 状态应该遵循图3中的状态机转换。
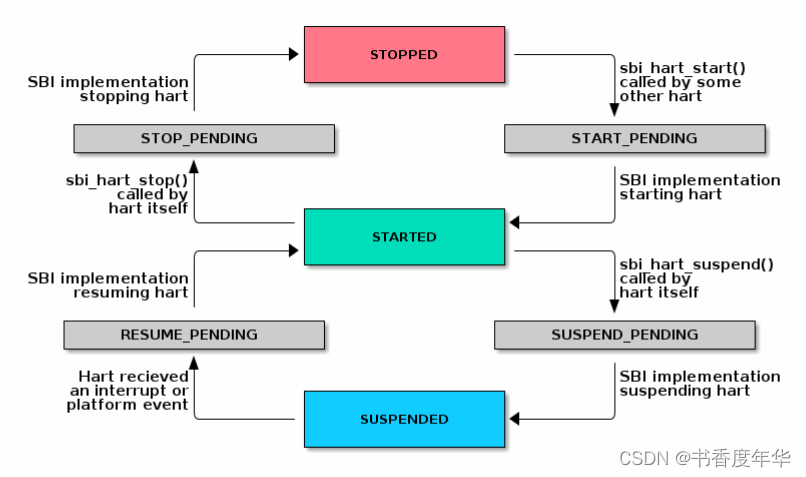
一个平台可以有多个 hart,这些 hart 可以被分为分层拓扑组(比如 core,cluster,nodes 等),每个分组都具有独立的低功耗状态。分层拓扑组中的这些平台相关的低功耗状态可以表示 suspend 状态,一个 SBI 实现可以使用下面方法来利用更高层拓扑组的 suspend 状态:
- 平台协调
这种方法中,当一个 hart 空闲时,S 模式电源管理软件会请求这个 hart 和 更高一层组进入最深度 suspend 状态。一个 SBI 实现应该为高层组选择一个 suspend 状态:a. 不比指定 suspend 状态更深 b.唤醒延时不能比指定的 suspend 延时高
- OS 发起
这种方法中,S 模式中的电源管理软件会在最后一个 hart 空闲时,直接请求高拓扑组进入 suspend 状态。当一个 hart 空闲,S 模式电源管理软件总是为自己选择一个 suspend 状态,只有自己是组内最后一个 suspend 的 hart 时,会请求高层拓扑组进入 suspend 状态。一个 SBI 实现应该:a.永远给高层拓扑组选择一个和指定 suspend 状态相同的状态 b.总是倾向于选择最近请求高层拓扑组的 suspend 状态。
9.1 函数: HART 开始(FID #0)
struct sbiret sbi_hart_start(unsigned long hartid, unsigned long start_addr, unsigned long opaque)请求 SBI 实现来在 S 模式下、指定地址、指定寄存器数值、开始执行目标 hart,描述如下:
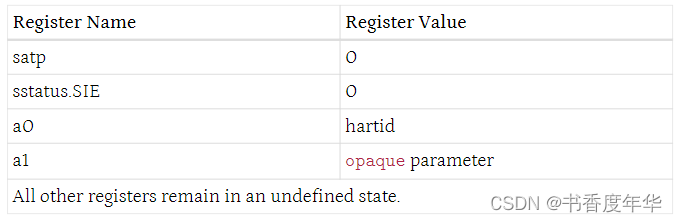
这个调用是异步的,更具体的,这个函数会在目标 hart 开始执行前返回,SBI 实现能够保证返回码的准确性。如果 SBI 实现是一个执行在 M 模式下的平台运行时固件,那么它必须在将控制权交给 S 模式前,配置 PMP 以及其他 M 模式下的状态。
hartid 参数指定了待启动的目标 hart;
start_addr 参数指定了运行时的物理地址,目标 hart 能够在 S 模式下在该地址开始运行;
opaque 参数是一个 XLEN-bit 长度的数值,当 hart 开始执行时会设置到 S 模式的 a1 寄存器中;
sbiret.error 中可能的错误码如表9,

9.2~9.5 略
第十章 系统复位扩展(EID #0x53525354 “SRST”)
系统复位扩展给 S 模式软件提供了一种系统级的重启或关闭的函数。这里的系统指的是 S 模式视角,SBI 实现可以是机器模式固件或者 hypervisor。
10.1 函数:系统复位(FID #0)
struct sbiret sbi_system_reset(uint32_t reset_type, uint32_t reset_reason)根据复位类型和原因来给系统复位,这个调用是同步,一旦成功将不再返回。
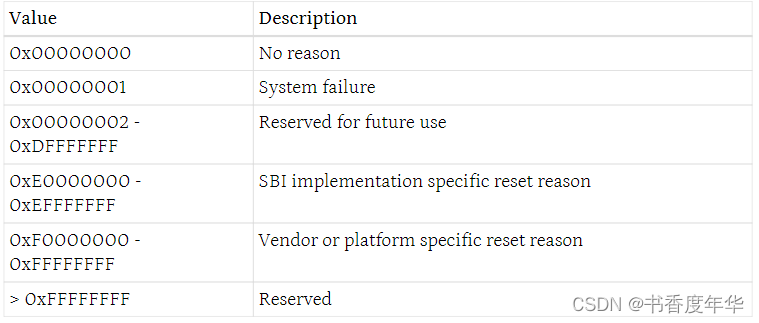
reset_type 参数是一个 32 位宽的数值,可选的数值如下:

reset_reason 是一个可选的参数,代表了复位的原因。这个参数也是 32 位宽,可选的值如下:
当 S 模式软件在本地运行时,SBI 实现是机器模式固件。在这种情况下了,关机就相当于整个系统的关机,即冷启动。另外,热重启相当于处理器核心和系统部分重启,不是整个系统。比如,一个拥有 BMC 的服务器系统,热重启并不会给 BMC 下电,但是冷重启会。
当 S 模式软件运行在虚拟机中时,SBI 实现是 hypervisor。关机、冷重启、热重启其实效果上和本地时相同,但是不会导致任何的物理电源变化。
sbiret.error 可能的返回错误码如表 12:

第十一章 性能监视器单元扩展(EID #0x505D55"PMU")
RISC-V 硬件性能计数器,如mcycle、minstret 和 mhpmcounterX CSR,可在 S 模式下使用cycle、instret和hpmccounterX CSR以只读方式访问。SBI 性能监控单元( PMU )扩展是一个为S 模式提供的接口,在机器模式(或hyper模式)协助下,配置和使用 RISC-V 硬件性能计数器。这些硬件性能计数器只能通过 mcountinhibit 和 mhpmeventX CSR 寄存器在机器模式下启动、停止或配置。因此,如果 RISC-V 平台未实现 mcountinhibit CSR,机器模式中的 SBI 实现可能会选择不允许SBI PMU扩展。
RISC-V 系统通常支持使用有限数量的硬件性能计数器(最多 64 位宽)监控各种硬件事件。此外,SBI 实现还可以提供固件性能计数器,这些计数器可以监视固件事件,例如未对齐的加载/存储指令的数量、RFENCE 的数量、IPI 的数量等,固件计数器总是 64 位宽。
SBI PMU 扩展提供:
- 为 S 模式提供接口,以访问(发现/配置) hart /固件的计数器
- 提供硬件/固件的新能计数器和事件接口,接口与 Linux perf 兼容
- 微架构原始事件编码的完全访问
为了定义 SBI PMU 的扩展调用,我们定义了一些重要的实体:counter_idx,event_idx 以及 event_data。counter_idx 是为每个硬件/固件分配的计数器逻辑号,event_idx 代表硬件/固件事件,event_data 是 64 位宽的代表硬件/固件事件的额外配置/参数。
event_idx 是一个 20 位宽的值,编码如下:
event_idx[19:16] = type event_idx[15:0] = code11.1 事件:硬件普通事件(类型 #0)
event_idx.type 为 0x0 表示所有的硬件普通事件,通过event_idx.code 来识别是什么事件
To Be Contined~
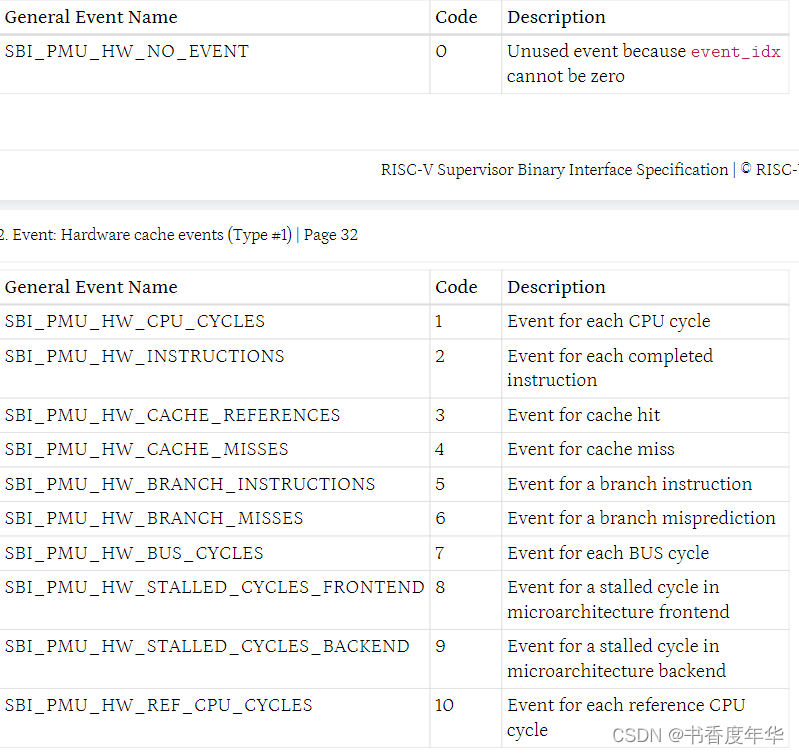
11.2 事件:硬件 cache 事件(类型 #1)
11.3 事件:硬件原始事件(类型 #2)
11.4 事件:固件事件(类型 #15)
11.5 函数:获取计数器值(FID #0)
11.6 函数:获取计数器详细信息(FID #1)
11.7 函数:发现并配置匹配计数器(FID #2)
11.8 函数:开启计数器(FID #3)
11.9 函数:停止计数器(FID #4)
11.10 函数:读取固件计数器(FID #5)
11.11 函数列表
第十二章 实验中的 SBI 扩展空间(EIDs #0x08000000-#0x08FFFFFF)
第十三章 供应商特定的扩展空间(EIDs #0x09000000-#0x09FFFFFF)
第十四章 固件提供商特定的扩展空间(EIDs #0x0A000000-#0x0AFFFFFF)
皮格马利翁效应心理学指出,赞美、赞同能够产生奇迹,越具体,效果越好~
“收藏夹吃灰”是学“器”练“术”非常聪明的方法,帮助我们避免日常低效的勤奋~







![【GO】k8s 管理系统项目16[前端部分–前端布局]](https://img-blog.csdnimg.cn/67b36bc54d784ecebc2fe3256dcc59c3.png)

